题目1:斐波那契数(LeetCode 509)
- 题目描述

- 三种解法:暴搜 → 记忆化搜索 → 动态规划
1) 暴力递归(暴搜)
算法思路
递归含义:定义 dfs(n) 函数,使命是返回第 n 个斐波那契数的值。
函数体:直接套用递推公式 dfs(n) = dfs(n-1) + dfs(n-2)。
递归出口:当 n == 0 或 n == 1 时,直接返回 n(对应 F(0)=0、F(1)=1)。
cpp
int dfs(int n)
{
if (n == 0 || n == 1)
return n;
return dfs(n - 1) + dfs(n - 2);
}
int fib(int n)
{
return dfs(n);
}核心缺陷
存在大量重复计算,例如计算 F(5) 时,会多次重复计算 F(3)、F(2) 等,时间复杂度为 O(2ⁿ),效率极低。
以 n=5 为例,递归树如下:
cpp
d(5)
├─ d(4)
│ ├─ d(3)
│ │ ├─ d(2)
│ │ │ ├─ d(1)
│ │ │ └─ d(0)
│ │ └─ d(1)
│ └─ d(2)
│ ├─ d(1)
│ └─ d(0)
└─ d(3) ← 重复计算!
├─ d(2) ← 重复计算!
│ ├─ d(1)
│ └─ d(0)
└─ d(1)大量重复节点(如 d(3)、d(2)、d(1))被多次计算,导致时间复杂度指数级增长。
2) 记忆化搜索(递归优化版)
核心思想
在暴力递归的基础上,增加备忘录(数组/哈希表),存储已经计算过的斐波那契数,避免重复计算,将时间复杂度优化为 O(n)。
算法思路
步骤1:添加备忘录:创建数组 memo,用于存储已经计算过的结果,格式为 <可变参数, 返回值>,初始值设为 -1(表示未计算)。
步骤2:递归前查询备忘录:每次进入递归函数时,先检查 memon 是否已计算(不为 -1),如果已计算则直接返回 memon。
步骤3:递归出口与计算:若 n == 0 或 n == 1,直接返回 n,并将结果存入 memon。
步骤4:递归后更新备忘录:计算 dfs(n-1) + dfs(n-2),将结果存入 memon 后返回。
原理说明
添加备忘录后,计算过的节点会被缓存:
第一次计算 d(3) 时,将结果存入备忘录;
后续再遇到 d(3) 时,直接从备忘录中读取,无需重复递归。
时间复杂度从 O(2ⁿ) 优化为 O(n),每个节点仅计算一次。
cpp
// 备忘录数组,全局初始化(初始值为0,实际使用时需手动设为-1)
int memo[31];
// 记忆化搜索递归函数
int dfs(int n)
{
// 1. 先查备忘录,已计算则直接返回
if (memo[n] != -1)
{
return memo[n];
}
// 2. 递归出口:n=0或n=1时,直接返回并记录
if (n == 0 || n == 1)
{
memo[n] = n;
return n;
}
// 3. 递归计算,并将结果存入备忘录
memo[n] = dfs(n - 1) + dfs(n - 2);
return memo[n];
}
int fib(int n)
{
memset(memo,-1,sizeof(memo));
return dfs(n);
}关键问题解答
- 所有的递归(暴搜、深搜),都能改成记忆化搜索吗?
不是的,只有在递归的过程中,出现了大量完全相同的子问题时,才能用记忆化搜索的方式优化。例如斐波那契数的递归存在大量重复子问题,而普通的全排列递归没有重复子问题,无法优化。
-
带备忘录的递归 vs 带备忘录的动态规划 vs 记忆化搜索:本质是同一类思想,只是实现方式不同。
-
自顶向下 vs 自底向上:记忆化搜索是"自顶向下"(从问题拆解到子问题),动态规划是"自底向上"(从子问题递推到最终问题)。
3) 动态规划(递推版,迭代实现)
核心思想
将递归的"自顶向下"拆解,转化为"自底向上"的递推过程,用数组存储每个状态的结果,避免递归栈开销,是更高效的实现方式。
算法步骤(从递归到动态规划的转化)
|------|----------|---------------------------------|
| 递归概念 | 动态规划对应概念 | 斐波那契数的具体实现 |
| 递归含义 | 状态表示 | dpi 表示:第 i 个斐波那契数 |
| 函数体 | 状态转移方程 | dpi = dpi-1 + dpi-2 |
| 递归出口 | 初始化 | dp0 = 0,dp1 = 1 |
| 调用顺序 | 填表顺序 | 从左往右(i 从 2 到 n) |
| 返回值 | 最终结果 | dpn |
完整C语言代码
cpp
// 动态规划数组
int dp[31];
int fib(int n)
{
// 初始化
dp[0] = 0;
dp[1] = 1;
// 自底向上递推
for(int i = 2; i <= n; i++)
{
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}动态规划与记忆化搜索的本质区别
|------|---------------|---------------|
| 维度 | 记忆化搜索 | 动态规划 |
| 实现方式 | 递归(自顶向下) | 循环递推(自底向上) |
| 状态存储 | 备忘录数组 | DP数组 |
| 执行顺序 | 从 n 向下拆解到 0/1 | 从 0/1 向上递推到 n |
| 栈开销 | 存在递归栈开销 | 无递归栈开销 |
- 三种方法对比
|----------|-------|----------------|------------------------|
| 方法 | 时间复杂度 | 空间复杂度 | 核心特点 |
| 暴力递归 | O(2ⁿ) | O(n)(递归栈) | 实现简单,但重复计算多,效率极低 |
| 记忆化搜索 | O(n) | O(n)(备忘录+递归栈) | 保留递归逻辑,用备忘录优化重复计算 |
| 动态规划(迭代) | O(n) | O(n)(可优化为O(1)) | 自底向上递推,无递归栈开销,可进一步优化空间 |
- 关键知识点总结
-
斐波那契数列的定义:F(0)=0, F(1)=1, F(n)=F(n-1)+F(n-2) (n>1),核心是"前两项之和"的递推关系。
-
重复计算问题:暴力递归的核心缺陷是子问题重复计算,解决思路是"缓存已计算结果"。
-
记忆化搜索本质:是"带备忘录的递归",属于动态规划的"自顶向下"实现方式,仅在存在大量重复子问题时有效。
-
动态规划的五步法:
-
确定状态表示(对应递归含义)
-
推导状态转移方程(对应递归函数体)
-
初始化边界条件(对应递归出口)
-
确定填表顺序(对应递归调用顺序)
-
确定最终返回值(对应递归调用的返回)
- 优化拓展:动态规划可进一步优化空间,只需保留前两项的值,将空间复杂度从O(n)降至O(1):
cpp
int fib(int n) {
if(n == 0) return 0;
if(n == 1) return 1;
int a = 0, b = 1, c;
for(int i = 2; i <= n; i++){
c = a + b;
a = b;
b = c;
}
return b;
}- 从递归到动态规划的转化技巧:先写出暴力递归函数;分析递归的含义、函数体、出口;对应转化为动态规划的状态表示、转移方程、初始化。
题目2:不同路径(LeetCode 62)
- 题目描述

- 三种解法思路梳理
题目给出了三种逐步优化的解法:暴力递归 → 记忆化搜索 → 动态规划,我们逐一拆解:
1) 暴力递归(暴搜)
核心逻辑
递归含义:定义函数 dfs(i, j),返回从 0, 0 位置走到 i, j 位置的不同路径数量。
函数体逻辑:到达 i, j 只能从上方 i-1, j 或左方 i, j-1 移动而来,因此路径数为两者之和:
dfs(i, j) = dfs(i-1, j) + dfs(i, j-1)
递归出口
当下标越界(i < 1 或 j < 1,注:代码中从1开始索引),返回 0(无有效路径);
当位于起点 1, 1(对应原网格的 0,0),返回 1(只有1种方式:原地不动)。
问题:存在大量重复子问题(如计算 dfs(2,2) 时,会重复计算 dfs(1,2) 和 dfs(2,1)),时间复杂度为指数级 O(2^{m+n}),无法通过大数据用例。
cpp
class Solution {
public:
int uniquePaths(int m, int n)
{
return dfs(m, n);
}
int dfs(int i, int j)
{
if (i == 0 || j == 0)
return 0;
if (i == 1 && j == 1)
return 1;
return dfs(i - 1, j) + dfs(i, j - 1);
}
};2) 记忆化搜索(递归+备忘录)
核心优化思路:为了解决暴力递归的重复计算问题,增加一个备忘录(memo),存储已经计算过的 dfs(i, j) 结果,避免重复计算。
步骤:
-
初始化一个二维数组 memo,大小为 (m+1) × (n+1),初始值全为0;
-
每次进入递归时,先检查 memoij 是否不为0:
若不为0,直接返回 memoij;
若为0,计算 dfs(i, j) 的结果,并将结果存入 memoij,再返回。
时间复杂度:优化为 O(m×n),每个子问题只计算一次。
cpp
class Solution {
public:
int uniquePaths(int m, int n)
{
vector<vector<int>> memo(m + 1, vector<int>(n + 1));
return dfs(m, n, memo);
}
int dfs(int i, int j, vector<vector<int>>& memo)
{
if (memo[i][j] != 0)
{
return memo[i][j];
}
if (i == 0 || j == 0)
return 0;
if (i == 1 && j == 1)
{
memo[i][j] = 1;
return 1;
}
memo[i][j] = dfs(i - 1, j, memo) + dfs(i, j - 1, memo);
return memo[i][j];
}
};3) 动态规划(递推)
动态规划是记忆化搜索的"迭代版",将递归的自顶向下改为自底向上,避免递归栈开销。
对应关系(递归 → 动态规划)
|-------|-------------------------------------------------------|
| 递归概念 | 动态规划对应实现 |
| 递归含义 | 状态表示:dpij 表示从 0,0 走到 i-1j-1 的路径数 |
| 函数体逻辑 | 状态转移方程:dpij = dpi-1j + dpij-1 |
| 递归出口 | 初始化:dp11 = 1(起点路径数为1) |
实现步骤
-
定义二维 dp 数组,大小为 (m+1) × (n+1)(为了和递归索引对齐,避免边界处理麻烦);
-
初始化起点:dp11 = 1;
-
按行/列遍历网格,依次计算每个位置的路径数(跳过起点);
-
最终 dpmn 即为从左上角到右下角的路径总数。
时间复杂度:O(m×n),空间复杂度 O(m×n) 。
cpp
class Solution
{
public:
int uniquePaths(int m, int n)
{
// 动态规划实现(迭代版)
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
dp[1][1] = 1; // 初始化起点路径数为1
for(int i = 1; i <= m; i++)
{
for(int j = 1; j <= n; j++)
{
if(i == 1 && j == 1) continue; // 跳过起点,避免覆盖
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m][n];
}
};题目3:最长递增子序列(LeetCode 300)
- 题目描述

- 三种解法思路梳理
题目给出了三种逐步优化的解法:暴力递归 → 记忆化搜索 → 动态规划,我们逐一拆解:
1) 暴力递归(暴搜)
核心逻辑
递归含义:定义函数 dfs(i),返回以 i 位置为起点的最长递增子序列的长度。
函数体逻辑:遍历 i 后面的所有位置 j,如果 numsj > numsi,说明 numsj 可以接在 numsi 后面,此时以 i 为起点的子序列长度为 1 + dfs(j)。取所有可能情况的最大值,就是 dfs(i) 的结果。
递归出口:题目描述中提到"因为我们是判断之后再进入递归的,因此没有出口",实际隐含的终止条件是:当 i 是数组最后一个元素时,dfs(i) = 1(子序列只有自身)。
问题
存在大量重复子问题(如计算 dfs(0) 时,会重复计算 dfs(2)、dfs(3) 等多次),时间复杂度为指数级 O(2^n),无法通过大数据用例。
cpp
class Solution {
public:
int lengthOfLIS(vector<int>& nums)
{
int ret = 0;
for (int i = 0; i < nums.size(); i++)
{
ret = max(ret, dfs(i, nums));
}
return ret;
}
int dfs(int pos, vector<int>& nums)
{
int ret = 1;
for (int i = pos + 1; i < nums.size(); i++)
{
if (nums[i] > nums[pos])
{
ret = max(ret, dfs(i, nums) + 1);
}
}
return ret;
}
};2) 记忆化搜索(递归+备忘录)
核心优化思路:为了解决暴力递归的重复计算问题,增加一个备忘录(memo),存储已经计算过的 dfs(i) 结果,避免重复计算。
步骤:
-
初始化一个一维数组 memo,大小为 n,初始值全为0;
-
每次进入递归时,先检查 memopos 是否不为0:
若不为0,直接返回 memopos;
若为0,计算 dfs(pos) 的结果,并将结果存入 memopos,再返回。
时间复杂度:优化为 O(n^2),每个子问题只计算一次。
cpp
class Solution {
public:
int lengthOfLIS(vector<int>& nums)
{
int n = nums.size();
vector<int> memo(n);
int ret = 0;
for (int i = 0; i < n; i++)
{
ret = max(ret, dfs(i, nums, memo));
}
return ret;
}
int dfs(int pos, vector<int>& nums, vector<int>& memo)
{
if(memo[pos] != 0) return memo[pos];
int ret = 1;
for (int i = pos + 1; i < nums.size(); i++)
{
if (nums[i] > nums[pos])
{
ret = max(ret, dfs(i, nums, memo) + 1);
}
}
memo[pos] = ret;
return ret;
}
};3) 动态规划(递推)
动态规划是记忆化搜索的"迭代版",将递归的自顶向下改为自底向上,避免递归栈开销。
对应关系(递归 → 动态规划)
|-------|--------------------------------------------------------------------------------|
| 递归概念 | 动态规划对应实现 |
| 递归含义 | 状态表示:dpi 表示以 i 位置为终点的最长递增子序列的长度 |
| 函数体逻辑 | 状态转移方程:dpi = max(dpi, dpj + 1)(其中 j > i 且 numsj > numsi) |
| 递归出口 | 初始化:dpi = 1(每个元素自身是长度为1的子序列) |
实现步骤
-
定义一维 dp 数组,大小为 n,初始值全为1(每个元素自身是长度为1的子序列);
-
从后往前遍历数组(i 从 n-1 到 0);
-
对于每个 i,遍历 j 从 i+1 到 n-1:若 numsj > numsi,则更新 dpi = max(dpi, dpj + 1);
-
遍历过程中记录 dp 数组的最大值,即为答案。
时间复杂度:O(n^2),空间复杂度 O(n)。
cpp
class Solution
{
public:
// 动态规划实现(迭代版)
int lengthOfLIS(vector<int>& nums)
{
int n = nums.size();
vector<int> dp(n, 1); // 初始化:每个元素自身长度为1
int ret = 0;
// 填表顺序:从后往前
for(int i = n - 1; i >= 0; i--)
{
for(int j = i + 1; j < n; j++)
{
if(nums[j] > nums[i])
{
dp[i] = max(dp[i], dp[j] + 1);
}
}
ret = max(ret, dp[i]); // 更新全局最大值
}
return ret;
}
};题目4:猜数字大小 II(LeetCode 375)
- 题目描述
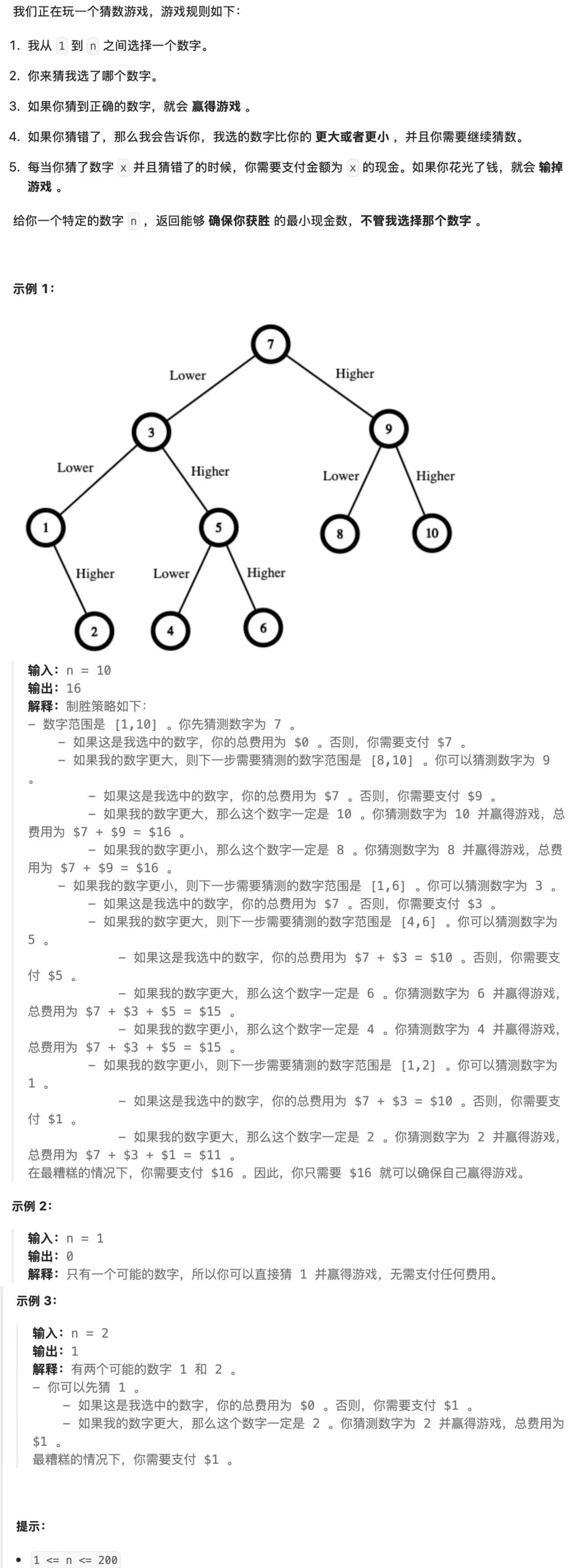
- 解法:暴搜 → 记忆化搜索
1) 暴搜(递归)
递归含义:给 dfs 一个使命,给他一个区间 left, right,返回在这个区间上能完胜的最小费用。
函数体:选择 left, right 区间上的任意一个数作为头结点,然后递归分析左右子树。求出所有情况下的最小值。
递归出口:当 left >= right 的时候,直接返回 0。
2) 记忆化搜索
加上一个备忘录 memo201201。
每次进入递归的时候,去备忘录里面看看;每次返回的时候,将结果加入到备忘录里面。
cpp
class Solution {
int memo[201][201];
public:
int getMoneyAmount(int n)
{
return dfs(1, n);
}
int dfs(int left, int right)
{
if (left >= right)
return 0;
if (memo[left][right] != 0)
return memo[left][right];
int ret = INT_MAX;
for (int head = left; head <= right; head++) // 选择头结点
{
int x = dfs(left, head - 1);
int y = dfs(head + 1, right);
ret = min(ret, head + max(x, y));
}
memo[left][right] = ret;
return ret;
}
};区间DP + 记忆化深度优先搜索,属于区间类最优决策问题,核心:保证最坏情况下花费最少金钱
递归状态定义 dfs(left, right)
含义:在数字区间 left, right 中,确保猜对数字,需要准备的最小保底花费
递归终止条件 if (left >= right) return 0;当区间只有一个数或者区间无效时,不需要猜测,花费为0。
记忆化剪枝原理 if (memoleftright != 0) return memoleftright;二维数组 memoleftright 缓存已经计算过的区间答案,避免大量重复递归计算,把暴力指数级复杂度优化为多项式复杂度。
核心循环逻辑 for (int head = left; head <= right; head++) 遍历当前区间内每一个数字 head,假设本次优先猜测这个数。
状态转移拆解
-
x = dfs(left, head - 1) 猜测head错误,目标数字在左侧区间的最小花费
-
y = dfs(head + 1, right) 猜测head错误,目标数字在右侧区间的最小花费
-
max(x , y) 题目要求必须保证绝对获胜,所以要考虑最坏情况,取左右两边花费更大的那一个
-
head + max(x, y) 猜错当前数字需要支付 head 金额,加上后续区间最坏花费
最优决策选取 ret = min(ret, head + max(x, y)); 枚举所有猜测点,在所有最坏方案里,挑选花费最小的策略
缓存保存结果 memoleftright = ret; 将当前区间的最优解存入备忘录,后续直接复用
为什么要用 max 再用 min?
-
max:规避最坏运气,保证无论答案在哪都能赢
-
min:主动选择最优猜测方案,压缩成本,这是本题最核心的解题思想。
题目5:矩阵中的最长递增路径(LeetCode 329)
- 题目描述
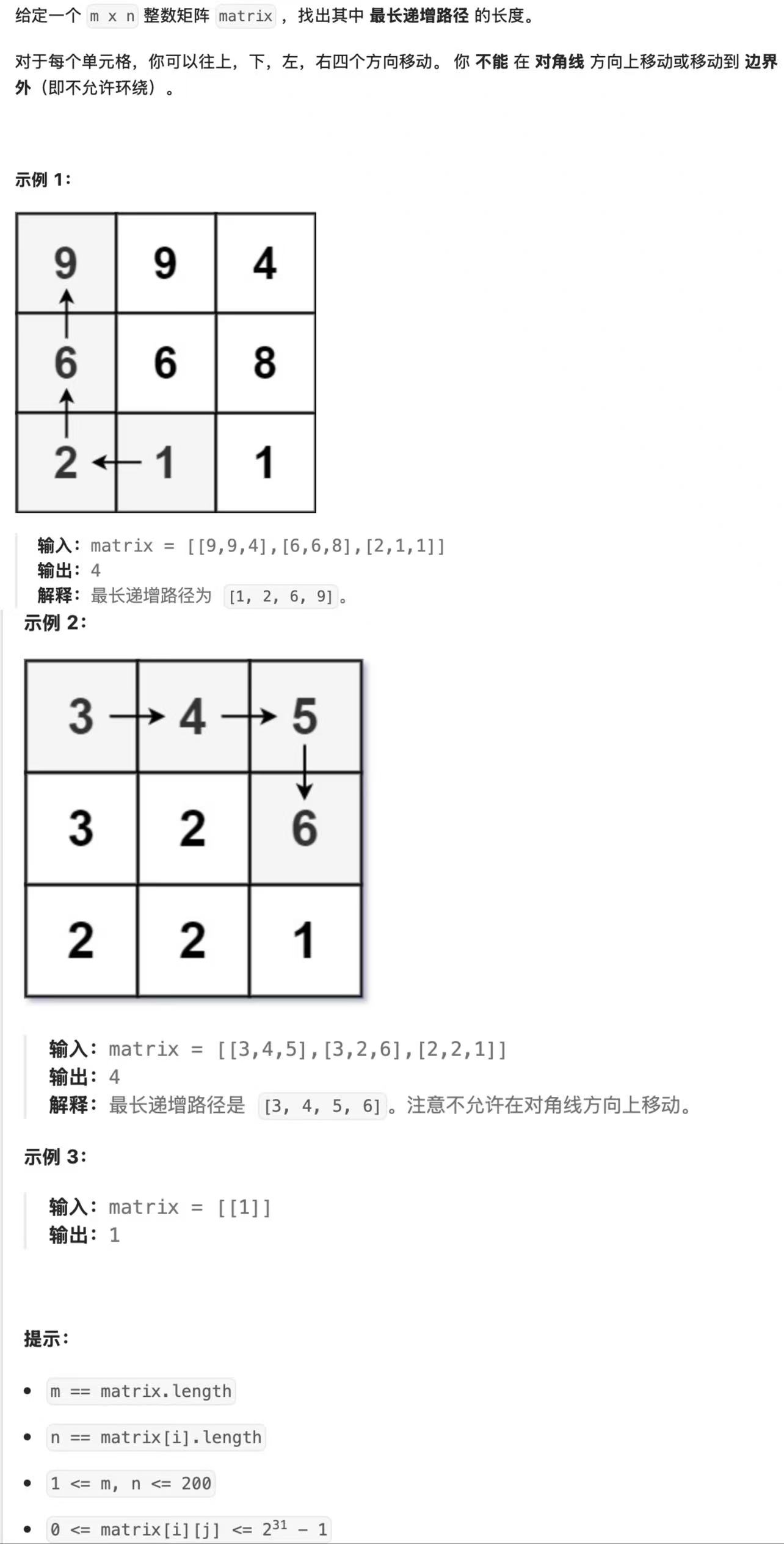
- 解法:暴搜 → 记忆化搜索
1) 暴搜(DFS)
递归含义:给 dfs 一个使命,给他一个下标 i, j,返回从这个位置开始的最长递增路径的长度。
函数体:上下左右四个方向瞅一瞅,哪里能过去就过去,统计四个方向上的最大长度。
递归出口:因为我们是先判断再进入递归,因此没有出口。
2) 记忆化搜索
加上一个备忘录 memo201201。
每次进入递归的时候,去备忘录里面看看;每次返回的时候,将结果加入到备忘录里面。
cpp
class Solution
{
int m, n;
int dx[4] = {0, 0, 1, -1};
int dy[4] = {1, -1, 0, 0};
int memo[201][201];
public:
int longestIncreasingPath(vector<vector<int>>& matrix)
{
int ret = 0;
m = matrix.size(), n = matrix[0].size();
for (int i = 0; i < m; i++)
for (int j = 0; j < n; j++)
{
ret = max(ret, dfs(matrix, i, j));
}
return ret;
}
int dfs(vector<vector<int>>& matrix, int i, int j)
{
if (memo[i][j] != 0)
return memo[i][j];
int ret = 1;
for (int k = 0; k < 4; k++)
{
int x = i + dx[k], y = j + dy[k];
if (x >= 0 && x < m && y >= 0 && y < n && matrix[x][y] > matrix[i][j])
{
ret = max(ret, dfs(matrix, x, y) + 1);
}
}
memo[i][j] = ret;
return ret;
}
};- 核心知识点总结
这两道题都是典型的 记忆化搜索(DFS + 备忘录) 问题,核心思路一致:
1) 递归定义子问题
猜数字:dfs(left, right) 表示区间 left, right 内的最小成本。
矩阵路径:dfs(i, j) 表示从 (i, j) 出发的最长递增路径长度。
2) 状态转移
猜数字:枚举当前猜的数字 head,取左右子问题的最坏情况(max(x,y))加上当前成本 head,再取所有枚举中的最小值。
矩阵路径:遍历四个方向,若下一个位置值更大,则递归求解并更新当前位置的最大路径长度。
3) 备忘录优化
用二维数组 memo 存储已经计算过的子问题结果,避免重复计算,将时间复杂度从指数级降到多项式级。
猜数字:memoleftright 存储区间结果。
矩阵路径:memoij 存储每个位置的结果。