目录
一、背景
在多宿主机Kubernetes集群部署过程中,由于各节点本地磁盘规格存在差异,导致存储资源难以统一管理。这些本地磁盘不仅无法实现跨主机共享,还会限制使用本地存储的Pod进行灵活迁移。此外,大容量的本地存储资源若未充分利用将造成严重浪费。因此,如何有效池化并高效利用这些本地磁盘资源成为集群管理的核心挑战。
二、Longhorn技术介绍
Longhorn为轻量级设计、依赖简单、部署快速,使用helm 5分钟即可完成部署,运维也较为容易,特别适合存储管理复杂度低的Kubernetes环境。部署组件后可使用block磁盘 (本人测试helm部署v1.11.1版本时无法使用block,不建议使用)或FileSystem接入存储资源(稳定无报错,推荐方法),使用方只需在创建PVC时指定storageclass为longhorn(helm部署后自动生成直接可用)即可。
cpp
#Longhorn前置准备,所有worker节点都需要开启iscsid服务
root@kubeflow-node1:~# apt install -y open-iscsi nfs-common
root@kubeflow-node1:~# systemctl enable --now iscsid
#所有worker节点需要禁用multipathd服务,避免存储冲突和数据损坏
root@kubeflow-node1:~# systemctl disable --now multipathd
root@kubeflow-node1:~# systemctl disable --now multipathd.socket
#若需要使用加密卷和 iSCSI还需要加载模块
root@kubeflow-node1:~# modprobe iscsi_tcp
root@kubeflow-node1:~# modprobe dm_mod
root@kubeflow-node1:~# tee /etc/modules-load.d/longhorn.conf <<EOF
iscsi_tcp
dm_mod
EOF
#添加helm仓库,执行helm安装命令
root@kubeflow-node1:~# helm repo add longhorn https://charts.longhorn.io
root@kubeflow-node1:~# kubectl create ns longhorn
root@kubeflow-node1:~# helm install longhorn longhorn/longhorn -n longhorn-system \
--set persistence.defaultClass=false \ #该选项定义是否作为默认SC
--set defaultClassReplicaCount=2 #该选项定义v1.11.1版本存储的副本数
#暴露longhorn-frontend服务用于Web UI页面访问管理,可修改对应SVC为NodePort模式,本次使用ingress
root@kubeflow-node1:~# kubectl -n longhorn-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
longhorn-admission-webhook ClusterIP 172.16.119.211 <none> 9502/TCP 2d3h
longhorn-backend ClusterIP 172.16.69.160 <none> 9500/TCP 2d3h
longhorn-frontend ClusterIP 172.16.104.23 <none> 80/TCP 2d3h
longhorn-recovery-backend ClusterIP 172.16.93.77 <none> 9503/TCP 2d3h
root@kubeflow-node1:~# cat long-ingress.yaml
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: longhorn-ui
namespace: longhorn-system
spec:
ingressClassName: nginx
rules:
- host: longhorn.test.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: longhorn-frontend
port:
number: 80
root@kubeflow-node1:~# kubectl apply -f long-ingress.yaml完成配置后通过浏览器访问longhorn.test.com如下
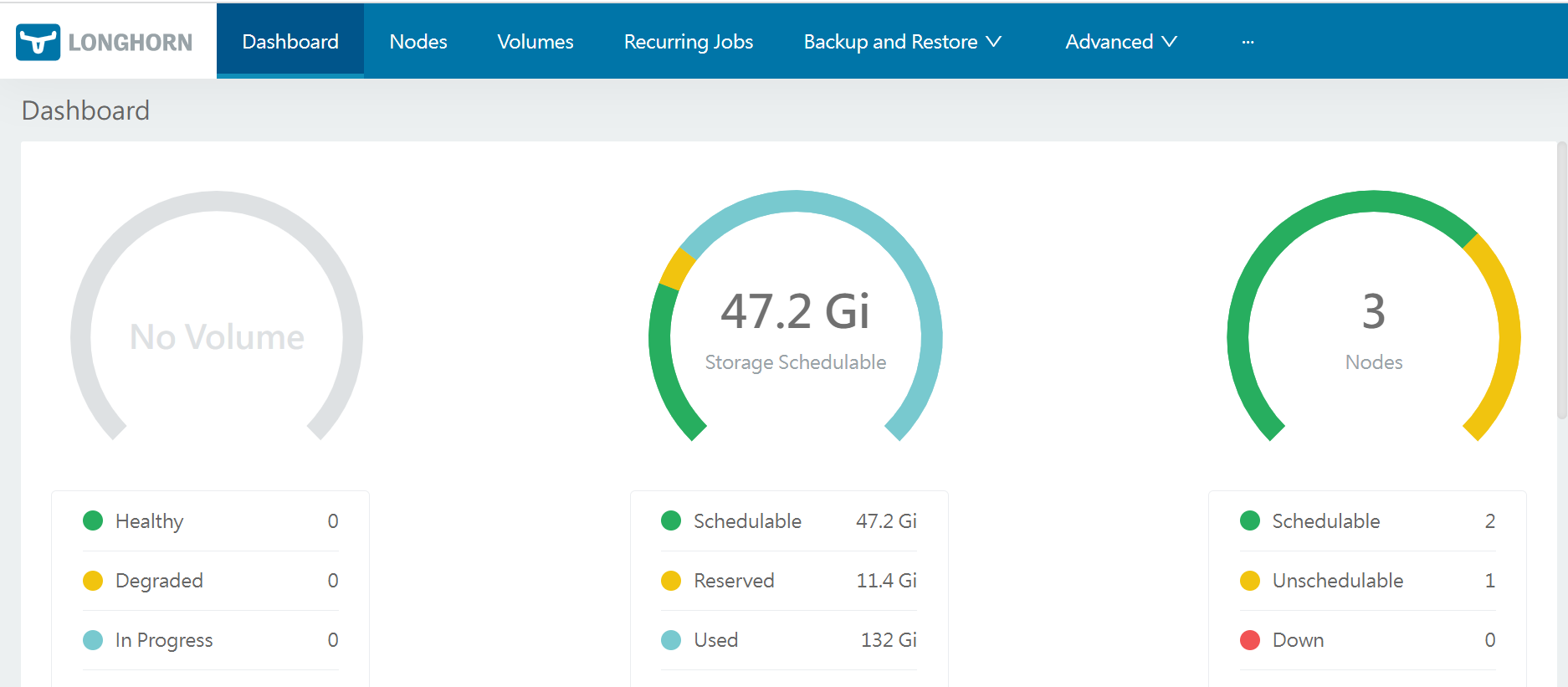
在Web UI界面只需点击Node节点即可对节点和磁盘进行管理调度,不同主机上零散的硬盘只需创建文件系统挂载在系统内,便可通过目录添加磁盘到Longhorn内。
注意事项:
1,使用FileSystem创建磁盘时,同一个node上添加的目录必须属于不同的磁盘,否则相同的文件系统 UUID会让Longhorn 判定为 "磁盘异常"→默认盘直接 NotReady + Unschedulable。
2,若要卸载longhorn需要先删除Longhorn 的 finalizer(资源保护锁),否则无法使用helm uninstall删除相关资源,删除不干净会导致部署其他版本的helm包失败。正确删除顺序如下:
cpp
#先删除finalizer(资源保护锁)
root@kubeflow-node1:~# kubectl get namespace longhorn-system -o json | jq '.spec.finalizers=[]' | kubectl replace --raw /api/v1/namespaces/longhorn-system/finalize -f -
root@kubeflow-node1:~# helm uninstall longhorn -n longhorn-system --no-hooks
#删除后建议强制清空名称空间
root@kubeflow-node1:~# kubectl delete ns longhorn-system --force --grace-period=0
root@kubeflow-node1:~# kubectl delete crd $(kubectl get crd | grep longhorn | awk '{print $1}')
#若清理crd资源卡住,可使用如下命令
root@kubeflow-node1:~# for crd in $(kubectl get crd | grep longhorn | awk '{print $1}'); do
kubectl patch crd $crd -p '{"metadata":{"finalizers":[]}}' --type=merge
kubectl delete crd $crd --force --grace-period=0
done三、Rook-Ceph技术介绍
Longhorn轻量化易于部署和管理,但是仅仅是将同一份pvc文件存放在不同节点的目录下实现多副本来保持数据的安全,存储效率低、网络依赖强,且不支持对象存储和共享文件系统。
Rook-Ceph是将数据切片存入到独立的磁盘组内,能满足企业级性能要求、存储效率高且提供丰富的存储接口,是kubeflow等高吞吐场景的首选方案。相对的其缺点也很明显,运维复杂度高、资源消耗大、部署复杂。
3.1,基本概念介绍
Ceph存储的核心组件OSD直接对应物理存储设备。当硬盘等设备接入后,系统会通过deviceClass对OSD进行分组管理。若不指定deviceClass,OSD将默认归入标记为hdd的组别(需注意此处的hdd仅是人工标记,并非自动识别的磁盘类型,初始配置时可混合使用SAS、HDD等多种磁盘)。
CRUSH Rule是决定数据分布策略的关键算法,它通过deviceClass标识来确定使用哪些OSD组进行数据存储。
Pool作为逻辑存储分区,实现了不同业务数据的隔离存储。多个Pool可以共享同一个CRUSH Rule,从而复用同一组OSD资源。
PG(Placement Group)是Pool内部的数据分片单元,通过将数据分散存储到多个PG中,有效解决了元数据管理的瓶颈问题。在Ceph架构中,PG是最小粒度的负载均衡和故障恢复单元。
Ceph可以提供三种存储服务类型:
1,块存储池提供虚拟硬盘,用于单客户端读写独占;
2,文件存储将Pool资源作为文件目录对外提供共享存储,用于多客户端同时读写;
3,对象存储提供S3或Swift HTTP API类型实现对象+桶的数据存储方式,用于多客户端同并发读写。
3.2,生产环境注意事项
在生产使用中要特别注意四条红线:
1,已经加入默认池(hdd)的旧盘不能改标签,一旦修改会导致PG狂动、数据大量迁移、集群长时间重平衡;
2,默认池永远是 hdd 混合池,勿动;
3,同一批次新磁盘必须全部统一标注 deviceClass标签,并确保至少三节点(每个节点至少一块盘)组成新的OSD组;
4,新的OSD组必须创建独立的CRUSH Rule,确保数据写入新的OSD组,而不是写入旧盘;
四、Rook-Ceph部署
部署rook-ceph需要至少三个worker节点,且每个节点需要至少一块干净的磁盘作为OSD设备,节点的CPU必须支持较新的CPU Flag位,部分虚拟化CPU无法支持组件的部署。
4.1,部署Rook-Ceph组件
cpp
#下载github包或者直接git clone对应版本项目
root@kubeflow-node1:~# git clone --single-branch --branch v1.19.3 https://github.com/rook/rook.git
#安装基本依赖包
root@kubeflow-node1:~# apt install -y lvm2 nfs-common ceph-common
root@kubeflow-node1:~# cd rook/deploy/examples
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f crds.yaml
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f common.yaml
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f csi-operator.yaml
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f operator.yaml
#修改cluster文件将使用所有节点、硬盘的选项改为false,并在nodes内指明使用的磁盘
root@kubeflow-node1:~/rook/deploy/examples# vim cluster.yaml
......
storage: # cluster level storage configuration and selection
useAllNodes: false
useAllDevices: false
nodes:
- name: "kubeflow-node2"
devices:
- name: "sdb"
- name: "kubeflow-node3"
devices:
- name: "sdb"
- name: "kubeflow-node4"
devices:
- name: "sdb"
- name: "sdc"
......
#使用命令创建cluster后
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f cluster.yaml
#部署dashboard服务便于管理,由于集群已有ingress和cert-manage故部署dashboard-ingress
#首先获取admin密码
root@kubeflow-node1:~/rook/deploy/examples# kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
#通过下列命令可知,默认cluster文件已开启dashboard服务只需暴露给外部即可访问
root@kubeflow-node1:~/rook/deploy/examples# kubectl -n rook-ceph get svc | grep dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr-dashboard ClusterIP 172.16.126.158 <none> 8443/TCP 5d23h
#由于服务端口使用的8443,因此要先创建issuer资源
root@kubeflow-node1:~/rook/deploy/examples# cat self-issuer.yaml
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: self-issuer
namespace: rook-ceph
spec:
selfSigned: {}
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f self-issuer.yaml
root@kubeflow-node1:~/rook/deploy/examples# cat ceph-dashboard-cert.yaml
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: ceph-dashboard-cert
namespace: rook-ceph
spec:
secretName: ceph-dashboard-tls
dnsNames:
- other.test.com
issuerRef:
name: self-issuer
kind: Issuer
group: cert-manager.io
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f ceph-dashboard-cert.yaml
#有证书后指明证书使用ingress部署资源
root@kubeflow-node1:~/rook/deploy/examples# cat dashboard-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: rook-ceph-mgr-dashboard
namespace: rook-ceph # namespace:cluster
annotations:
kubernetes.io/tls-acme: "true"
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
nginx.ingress.kubernetes.io/server-snippet: |
proxy_ssl_verify off;
spec:
ingressClassName: "nginx"
tls:
- hosts:
- ceph.test.com
secretName: ceph-dashboard-tls
rules:
- host: ceph.test.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: rook-ceph-mgr-dashboard
port:
name: https-dashboard
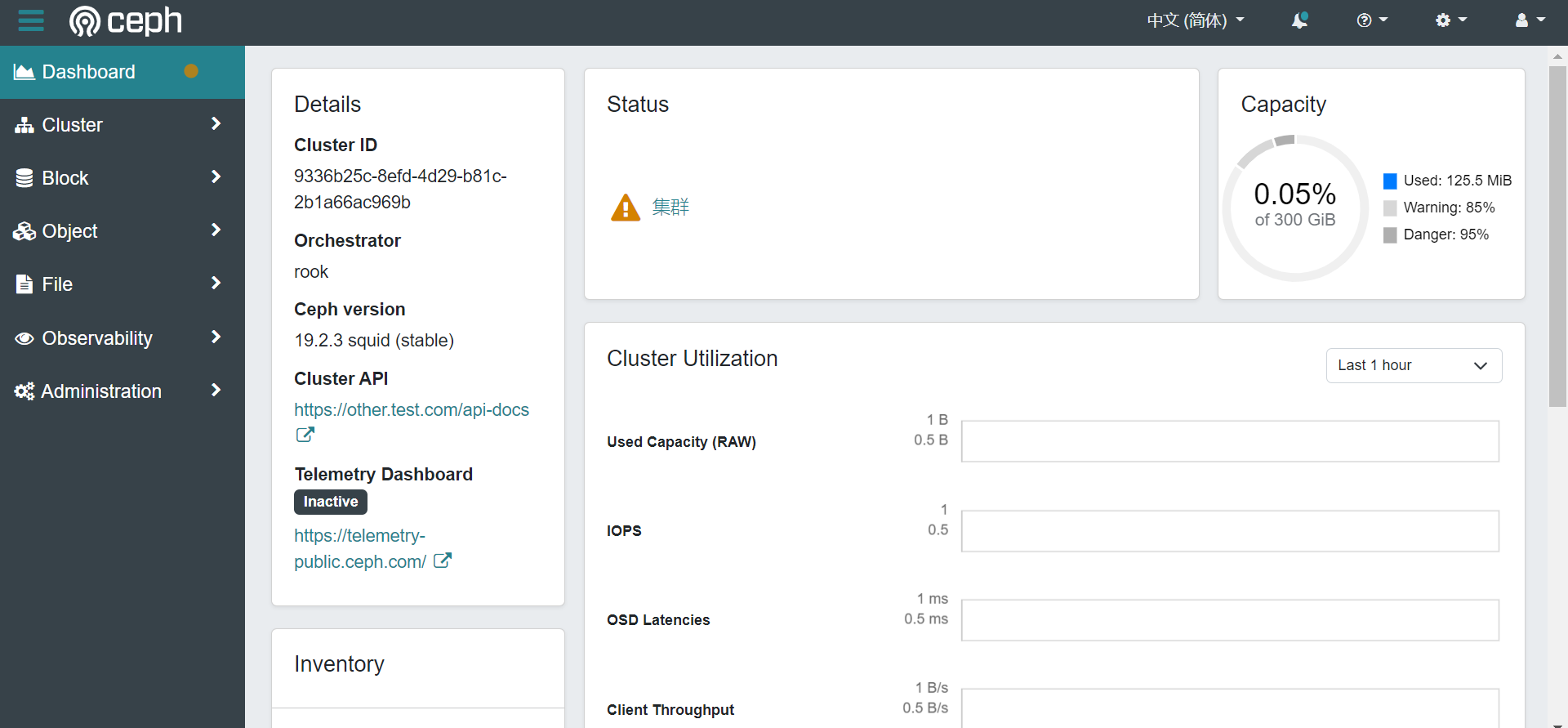
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f dashboard-ingress.yaml本地做好域名解析后访问域名https://ceph.test.com即可查看Rook-Ceph集群(由于mon节点所在的操作系统磁盘空间不足,此处产生了dashboard报警;生产环境请确保/var/lib/rook空间充足,否则系统盘空间不足时mon服务可能会自动停止服务)。
4.2,部署块存储和文件系统存储池
cpp
#部署ceph调试工具
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f toolbox.yaml
#部署块存储类型SC
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f csi/rbd/storageclass
root@kubeflow-node1:~/rook/deploy/examples# kubectl -n rook-ceph get CephBlockPool
NAME PHASE TYPE FAILUREDOMAIN AGE
replicapool Ready Replicated host 7d20h
root@kubeflow-node1:~/rook/deploy/examples# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 6d2h
#部署文件系统类型的SC
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f filesystem.yaml
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f csi/cephfs/storageclass.yaml
root@kubeflow-node1:~/rook/deploy/examples# kubectl -n rook-ceph get CephFilesystem
NAME ACTIVEMDS AGE PHASE
myfs 1 7d20h Ready
root@kubeflow-node1:~/rook/deploy/examples# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 6d2h
rook-cephfs rook-ceph.cephfs.csi.ceph.com Delete Immediate true 6d2h
如上即完成了调用默认OSD类型的块存储和文件系统存储池创建,使用已创建的SC类型即可创建PVC给Pod调用。
需要注意在rook v1.19版本内,不需要 手动创建 CRUSH Rule,当你在 Pool 定义中指定deviceClass时,Rook Operator 会自动生成对应的 CRUSH Rule(默认命令规则:<pool-name>_rule)。在创建存储类型时只需指定deviceClass即可实现存储池对特定OSD的调用。
cpp
#通过explain命令可以得知块存储池和文件存储池不支持crushRule参数,只有deviceClass
root@kubeflow-node1:~/rook/deploy/examples# kubectl explain CephBlockPool.spec.crushRule
GROUP: ceph.rook.io
KIND: CephObjectStore
VERSION: v1
error: field "crushRule" does not exist
root@oa-test-node1:~# kubectl explain CephBlockPool.spec.crushRule
GROUP: ceph.rook.io
KIND: CephBlockPool
VERSION: v1
error: field "crushRule" does not exist
root@kubeflow-node1:~/rook/deploy/examples# kubectl explain CephBlockPool.spec.deviceClass
GROUP: ceph.rook.io
KIND: CephBlockPool
VERSION: v1
FIELD: deviceClass <string>
DESCRIPTION:
The device class the OSD should set to for use in the pool
root@kubeflow-node1:~/rook/deploy/examples# kubectl explain CephFilesystem.spec.dataPools.crushRule
GROUP: ceph.rook.io
KIND: CephFilesystem
VERSION: v1
error: field "crushRule" does not exist
root@kubeflow-node1:~/rook/deploy/examples# kubectl explain CephFilesystem.spec.dataPools.deviceClass
GROUP: ceph.rook.io
KIND: CephFilesystem
VERSION: v1
FIELD: deviceClass <string>
DESCRIPTION:
The device class the OSD should set to for use in the pool
#部署文件存储测试PVC和Pod
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f csi/cephfs/pvc.yaml
root@kubeflow-node1:~/rook/deploy/examples# cat csi/cephfs/pvc.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cephfs-pvc
labels:
group: snapshot-test
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: rook-cephfs
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f csi/cephfs/pod.yaml若直接通过 example/storageclass.yaml 部署存储类(SC),由此 SC 创建的 PVC 将默认挂载到现有 myfs 存储卷中的 csi 子卷组。此时生成的 PVC 实际上对应 myfs 卷下 csi 子卷组生成的csi-vol-XXX子卷下的文件夹(如下图所示)。
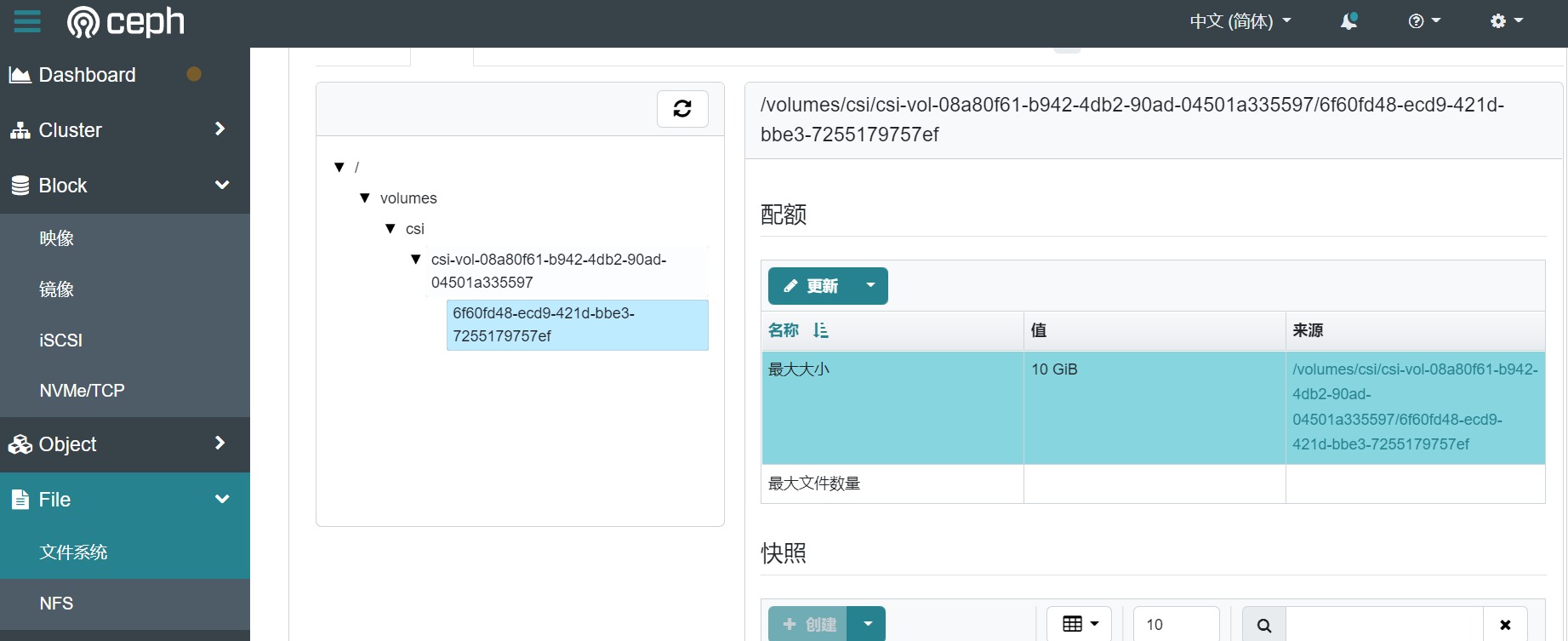
4.3,部署对象存储池
Rook-Ceph 的对象存储基于 Ceph RADOS Gateway (RGW) 实现,提供 S3 兼容 和 Swift 兼容的对象存储接口。Rook 作为 Kubernetes 上的编排器,简化了 RGW 的部署和管理。
CephBlockPool: 是Ceph 底层的RADOS 池(块 / 对象 / 文件共用),真正存放数据 / 元数据的物理存储单元,此处定义deviceClass实现对特定OSD的调用;
CephObjectStore: 是一个完整的对象存储实例,有两种模式使用独立池或共享池;
CephObjectRealm: 是全局命名空间域,是跨集群、跨 ZoneGroup 的全局唯一命名空间,单集群默认自动创建;
CephObjectZoneGroup:是Realm下的区域组,负责控制Zone间的同步策略,单集群隐式;
CephObjectZone:是多站点数据分区,可以挂载多个CephObjectStore;当ceph为单站点时,Zone完全由store托管,不可复用;当ceph为多站点时CephObjectStore 挂载到 CephObjectZone(Zone 是数据所有者,Store 是网关入口),即先创建CephObjectZone负责创建或指定dataPool、metadataPool,CephObjectStore不再自建池而是配置spec.zone.name:<zone-name>。
Ceph 对象存储的核心架构可概括为:元数据池(metadataPool)负责存储用户、桶、权限及对象索引等元数据信息,数据池(dataPool)负责存储实际对象数据,Gateway(RGW)作为 Rados 网关层,定义对外服务实例数量、访问协议与访问入口,默认启用 S3 与 Admin API,Swift 协议需显式开启。
在单实例多对象存储场景下,通常定义共享池让CephObjectStore调用,实现多个对象存储通过RADOS名称空间实现底层数据的隔离。
在多实例与资源调度场景下,CephObjectZone 可通过 deviceClass / CRUSH 规则指定数据落盘策略,自动管理所属存储池,无需手动创建 CephBlockPool,创建 CephObjectStore 时只需指定zone-name;每个对象存储实例对应独立的 Gateway 配置,支持差异化设置实例副本数、协议开关与访问策略,实例间通过【物理池级 + 逻辑命名空间 + 跨集群 / 站点】实现强三层隔离。
核心隔离机制:
第一层:独立存储池(物理隔离)
每个 CephObjectZone 在创建时,必须、自动、独占创建专属 metadataPool 和 dataPool (Rook 由 Zone CR 直接定义池配置),不共享、不复用任何其他 Zone 的存储池。同集群不同 Zone 的数据分属完全独立的 RADOS 池,无 Namespace 前缀叠加,底层 PG/OSD/IO 资源天然隔离。
第二层:Zone 级全局命名空间隔离
多站点通过 Realm → ZoneGroup → Zone 层级划分全局命名空间:
1,同一 Realm 内共享全局用户 / 桶命名空间(可跨 Zone 同步);
2,不同 Realm 之间:用户、桶、数据、权限 100% 完全隔离,无任何互通;
3,同一 ZoneGroup 内多 Zone:数据异步复制、用户 / 桶元数据同步(灾备 / 双活);
4,不同 ZoneGroup:命名空间独立、数据不自动同步。
第三层:RGW 实例与访问入口隔离
每个 CephObjectStore 绑定专属 Zone,S3 请求仅路由至所属 Zone 的 RGW,无法访问、枚举其他 Zone 的桶 / 对象 / 用户,S3 层呈现完全独立的对象存储服务实例。
关于共享池和多实例的区别:在访问隔离层面表现一致:均具备独立 RGW 入口、独立 S3 命名空间、独立用户体系,S3 可见域完全隔离。
核心差异在于底层数据隔离级别:共享池模式只依靠RADOS Namespace实现逻辑隔离,底层存储池、PG、OSD 资源共享;Zone 模式为每个区域分配独立的元数据池与数据池,实现物理资源级别的强隔离。
若需实现数据分层存储与灵活放置,可基于不同磁盘类型(SSD、SAS、HDD)创建多组 CephBlockPool,在单个对象存储中配置默认元数据池与默认数据池,同时通过 Pool Placement 策略绑定额外数据池与存储分级标识,客户端可通过标准 S3 Storage-Class 指定数据放置目标,实现冷热数据分离、性能分级与设备差异化调度,在单一网关入口下完成多池数据的自动路由与隔离管理。
cpp
#如果需要单一对象存储,只是创建一个使用专用Ceph池的本地对象存储,直接使用example的object文件即可完成部署,可根据实际情况修改名称空间和名称
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f object.yaml
#若需要多个对象存储共用一个池,可创建共享池让多个对象存储调用该池通过RADOS
名称空间实现逻辑隔离,在spec.deviceClass内定义调用的OSD
root@kubeflow-node1:~/rook/deploy/examples# cat object-shared-pools.yaml
......
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: rgw-root
namespace: rook-ceph # namespace:cluster
spec:
name: .rgw.root
failureDomain: host
deviceClass: SAS
replicated:
......
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f object-shared-pools.yaml
#直接使用example的object-a文件即可创建对象存储调用共享池
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f object-a.yaml
#若需要使用对象存储强隔离性可部署多实例,如下例子代表部署了一个叫multi-instance-store的全局作用
域,只创建了一个zonegroup叫multi-instance-store,其下有一个名为multi-instance-store的zone,
有三个对象存储调用这个zone,各自开启了不同协议的
root@kubeflow-node1:~/rook/deploy/examples# kubectl apply -f object-multi-instance-test.yaml
#如下可知在yaml文件的spec.dataPool.deviceClass可指明调用的OSD
root@kubeflow-node1:~/rook/deploy/examples# kubectl explain CephObjectZone.spec.dataPool.deviceClass
GROUP: ceph.rook.io
KIND: CephObjectZone
VERSION: v1
FIELD: deviceClass <string>
DESCRIPTION:
The device class the OSD should set to for use in the pool五、总结
| 维度 | Rook-Ceph | Longhorn |
|---|---|---|
| 定位 | 全功能分布式存储(Ceph)+ K8s 编排 | 云原生分布式块存储 |
| 架构复杂度 | 高(Mon/Mgr/OSD/MDS/RGW 多组件) | 低(控制器 + 副本 + 实例管理器) |
| 部署难度 | 中高(需裸盘、网络、资源规划) | 低(Helm/Kubectl 一键部署) |
| 支持协议 | 块(RBD)、文件(CephFS)、对象(RGW) | 仅块(iSCSI) |
| 资源开销 | 高(单节点约 1-2GB 内存) | 低(单节点约 200-400MB 内存) |
| 性能特点 | 高吞吐、高 IOPS,适合大规模并发 | 低延迟、稳定,适合中小规模读写 |
| 适用规模 | 中大型集群、多业务、多协议场景 | 中小集群、纯 K8s 块存储需求 |
| 运维门槛 | 高(需 Ceph 专业知识) | 低(Web UI + 声明式配置) |
部署建议:
仅需kubernetes块存储如 MySQL、PostgreSQL、Redis、CI/CD 等有状态应用,追求极简部署与运维,需要用较少的资源在较短的时间内使用,推荐使用Longhorn;
若需要同时支持块 、文件、对象多协议等,或者有大规模数据湖、AI 训练、日志集中存储等高吞吐场景,推荐使用Rook-Ceph。
如果在不接入 Kubernetes 集群的情况下实现主机集群管理,并需要池化本地磁盘资源,可考虑采用 glusterfs 或 moosefs 技术方案,这些分布式文件系统的部署流程较为简便且不需对接Kubernetes集群。