在具身智能飞速发展的当下,构建高逼真度的物理仿真环境是机器人策略学习的核心基石。然而,纵观当前的动作条件视频生成模型,整个领域仍面临几个局限:
- 视觉与时间一致性差:生成的视频往往缺乏物理真实感,容易出现物体形变或模糊;
- 控制信号脱节:抽象的稀疏控制(7-DoF)很难精准映射到复杂的2D像素中,导致预测结果容易发生动态漂移,无法精确对齐操作指令;
- 视角局限:受限于单视角观测,缺乏跨视角的一致性;
基于上述痛点,本文认为,在稀疏的动作指令和密集的2D像素之间,存在着巨大的"表征鸿沟"。为了打破这一壁垒,清华大学智能产业研究院(赵昊)团队提出了一个改进的统一框架------ORV。通过引入**"4D语义占据数据 (4D Semantic Occupancy)"**作为桥梁,ORV 充分利用了Occupancy占据场对几何噪声的天然鲁棒性,无缝整合了动作先验与视觉先验。在各大基准测试中,ORV不仅在视频生成质量上显著超越现有SOTA模型,更在下游Policy任务中展现出卓越性能。
该论文《ORV: Occupancy-centric Robot Video Generation》已被人工智能与计算机视觉领域国际学术会议CVPR2026接收。
- 论文题目:ORV: Occupancy-centric Robot Video Generation
- 论文链接:https://arxiv.org/abs/2506.03079
- 代码地址:https://github.com/OrangeSodahub/ORV
- 项目主页:https://orangesodahub.github.io/ORV/
1. 主要方法
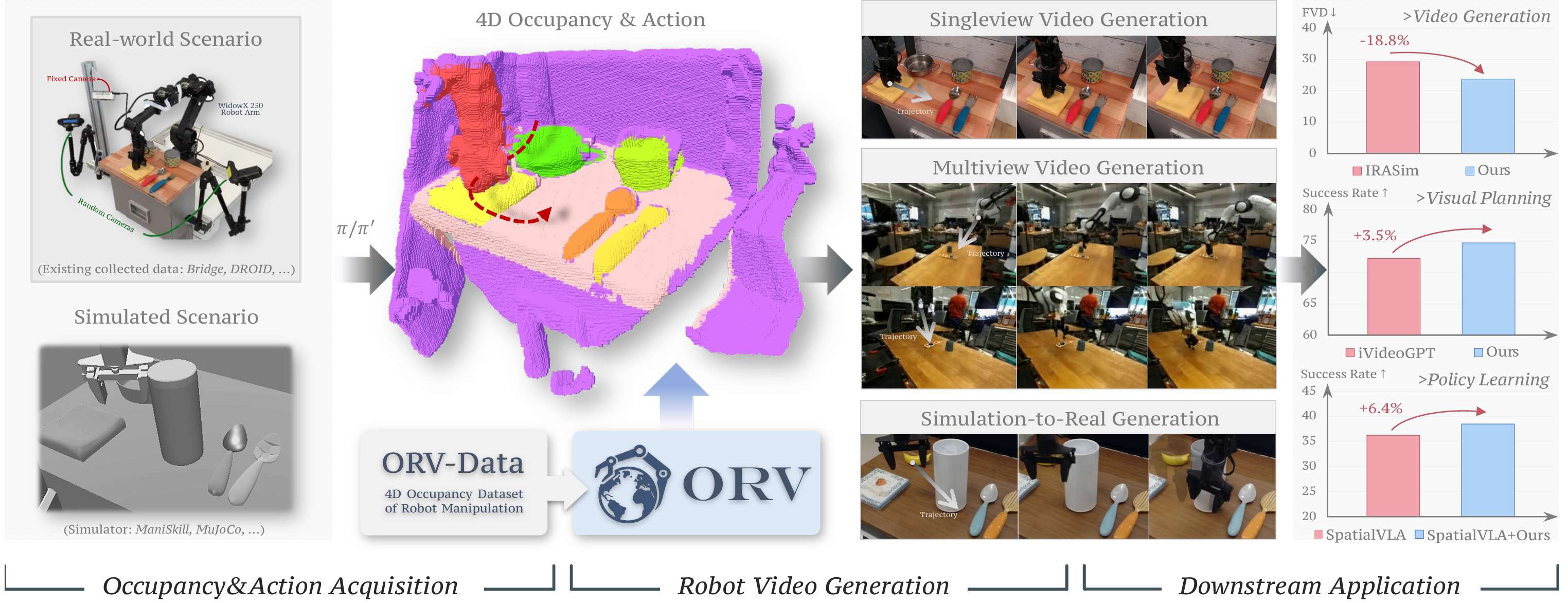
ORV的主要机制首先在于从真实世界与物理仿真器中提取的"4D语义占据序列"与"7-DoF机械臂动作"作为驱动视频生成的联合条件输入;同时,为了打破具身领域缺乏此类数据的核心瓶颈,本文专门构建了带有丰富几何与语义标注的大规模高质量数据集ORV-Data 提供训练支撑。这种条件注入机制让ORV不仅能精准合成动作对齐的单视角(Singleview)视频,还支持生成具有严格几何连贯性的多视角(Multiview)操作视频,甚至直接实现"仿真到真实(Sim-to-Real)"的高质量跨域视觉迁移。ORV不仅在视频生成质量上大幅超越基线模型,其合成的高保真视频更化身为强大的"数据引擎",显著地提升了机器人在策略学习(Policy Learning)等下游真实任务上的执行成功率。
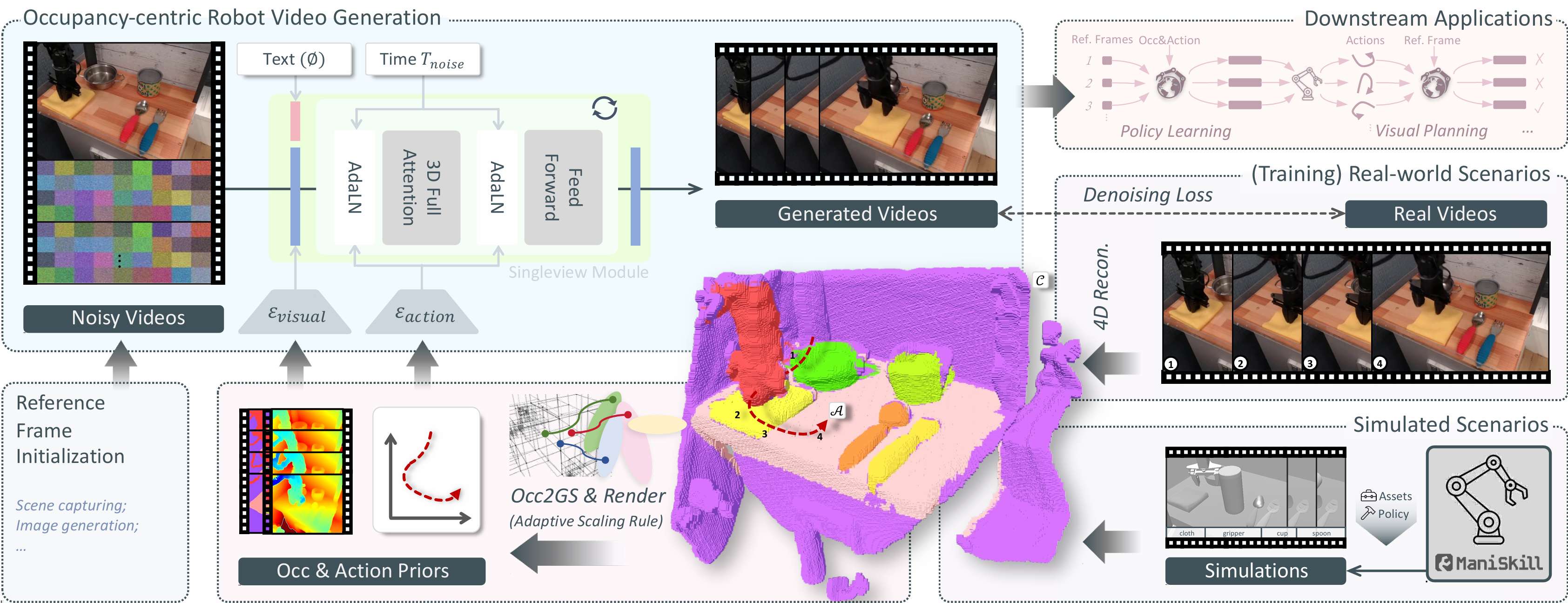
1.1 以4D占据为中心的视频生成
ORV采用基于CogVideoX (DiT)的视频扩散模型,实施两阶段监督微调(SFT)策略,将动作先验与视觉先验注入到视频生成中,主要包含了以下三个要点:
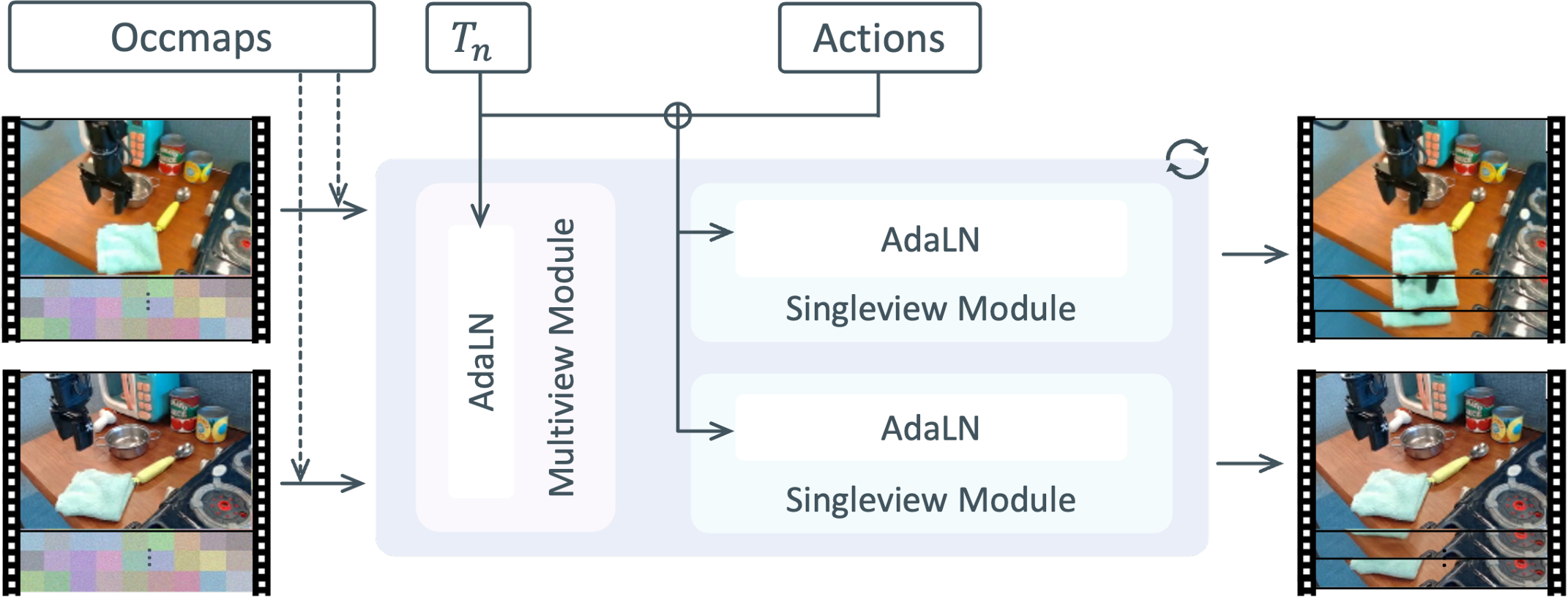
分块动作调制(Chunk-level Action Conditioning): ORV直接将7-DoF末端位姿序列作为高层控制信号,通过自适应层归一化(Action Expert AdaLN)对DiT块内的视频特征(Latents)进行调制。为了实现高维动作与视频高维特征在时间维度上的精准对齐,本文通过分块动作编码利用浅层MLP将连续的数个动作映射压缩为单一Token。进一步地,Action Expert AdaLN直接复用了预训练视觉专家模块的参数,在不增加额外计算负担的情况下实现了高效的动作控制注入。
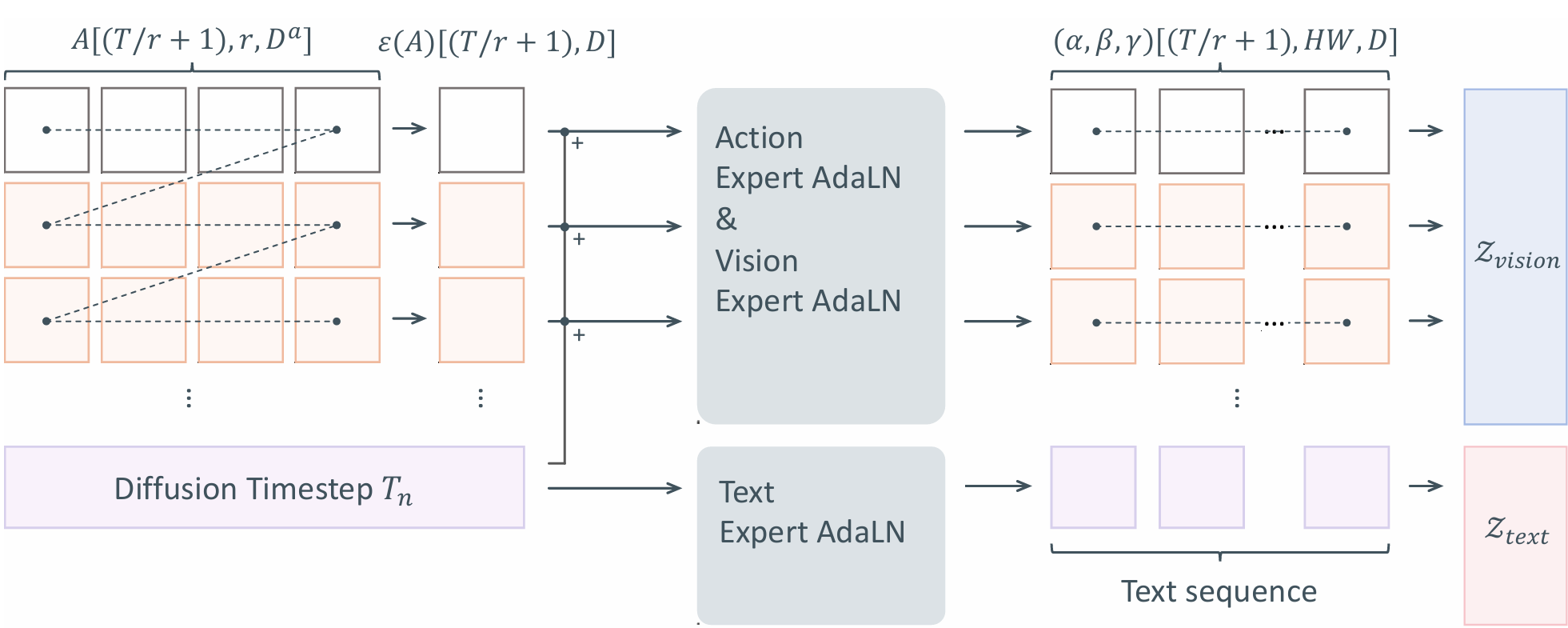
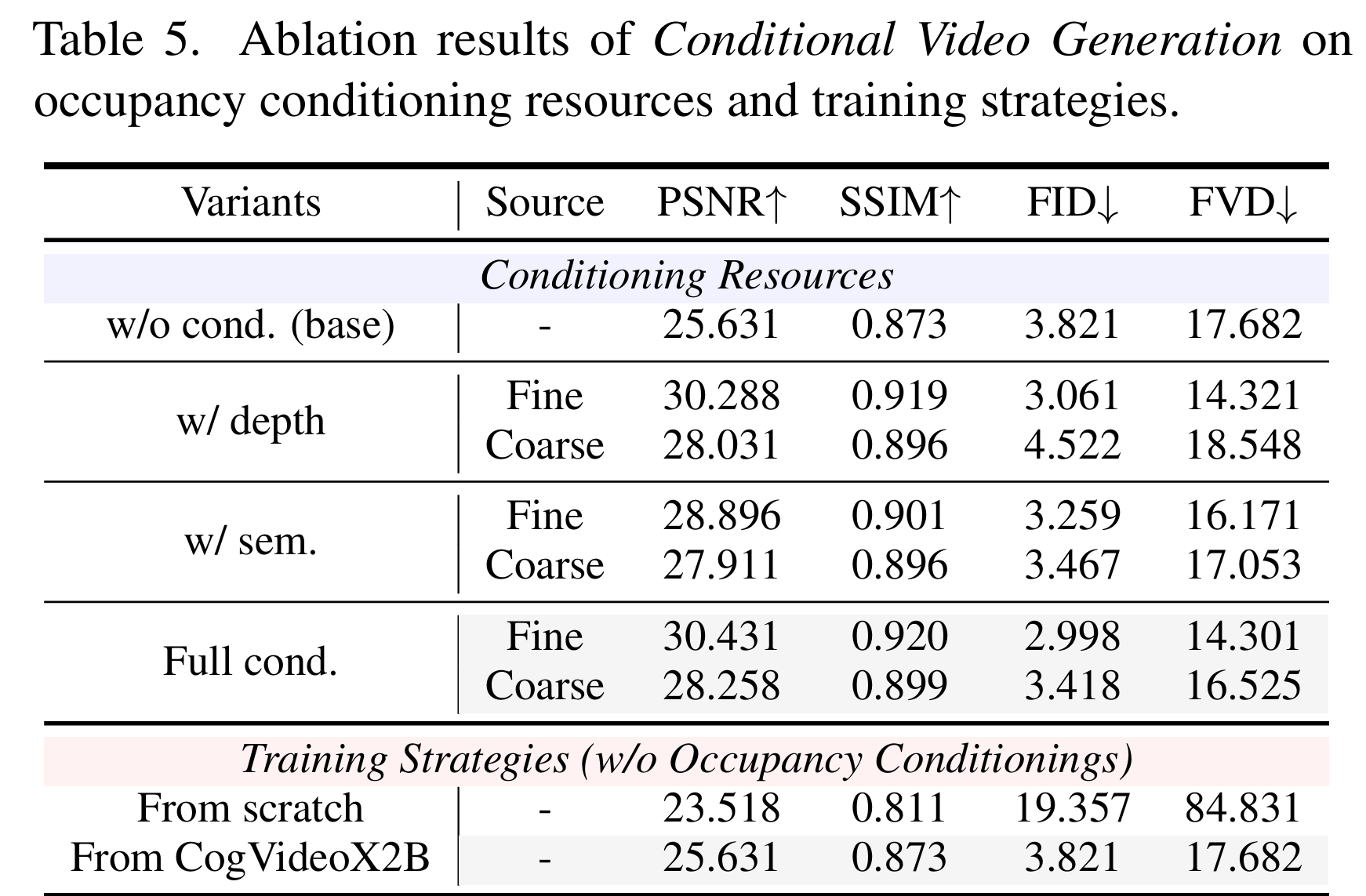
基于自适应缩放的视觉条件注入(Occupancy-derived Visual Conditioning): 将抽象的3D动作信号转化为逼真的2D像素是一项巨大的挑战,因此ORV引入了从占据场提取的像素级软视觉条件。这一过程使用极低的资源消耗将语义占据网格转换成特定视角下的条件视频,具体地,ORV为每个占据网格分配了不可学习的3D高斯溅射(Gaussian Splatting)进行渲染。在特征融合层面,ORV采用额外的MLP编码器与零初始化投影层,将视觉条件直接注入到初始噪声中,既大幅节约了显存,又避免了"软条件"破坏视频原有的潜在特征。
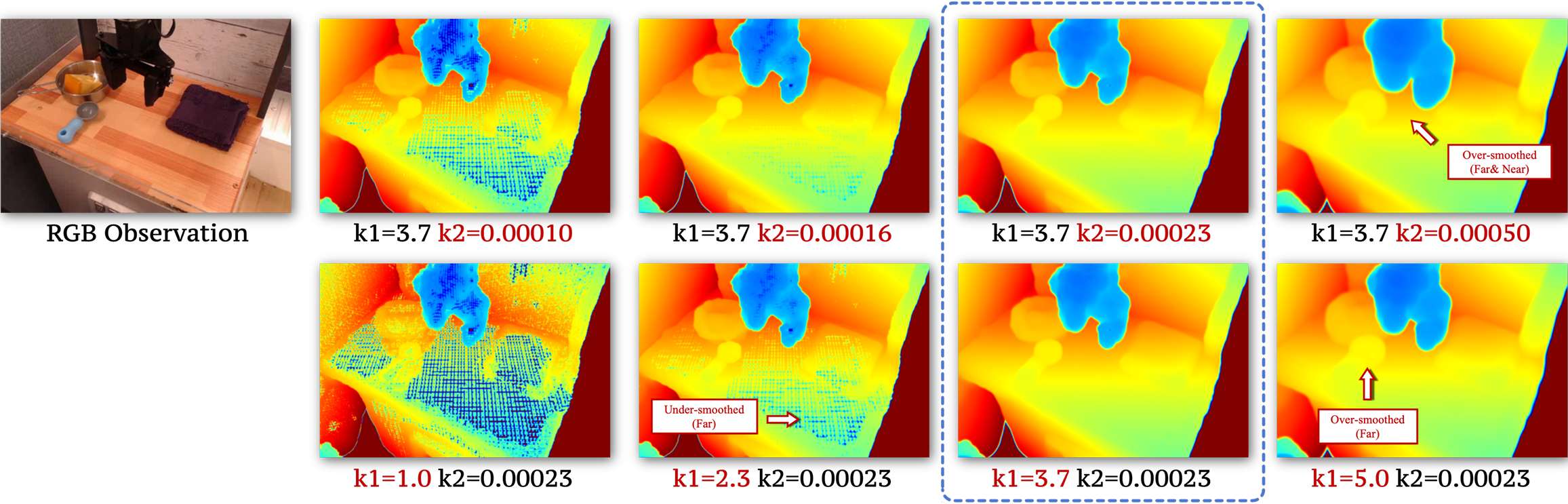
另外,本文通过一种自适应缩放机制(Adaptive Scaling) 来解决高斯尺度导致的透视失真(近大远小的极化问题):通过规则 σ = k 2 ⋅ z ^ k 1 \sigma=k_{2}\cdot\hat{z}^{k_{1}} σ=k2⋅z^k1(如上图,其中 z ^ \hat{z} z^ 为规范化深度, k 1 k_1 k1 和 k 2 k_2 k2 分别控制远平面和近平面的缩放行为)。具体推导过程请参考论文附录内容。
多视角一致性合成(ORV-MV)与虚实迁移(ORV-S2R): ORV-MV在原有的单视角模块(时间注意力机制)之前引入了特定的多视角模块(视角注意力机制)。在此架构下,单视角模块负责处理文本、动作和占据图条件;而多视角模块则完全剥离动作先验,专注于处理跨视角之间的特征对应关系,从而生成具备一致性的多视角操作视频。
此外,由于占据表征对底层几何噪声具有天然的鲁棒性,它能够桥接真实世界中的嘈杂表面与物理仿真器中的平滑参数化网格。利用物理仿真器(如ManiSkill、MuJoCo)低成本提供的深度与语义占据先验,ORV-S2R能够直接渲染出高逼真度的真实世界操作视频,这样的方法路径能够有效缓解长期面临的数据稀缺难题。
1.2 4D占据网格数据构建
为了支持ORV模型训练,本文设计了一套自动化数据构建流水线,从现有的主流纯视频机器人操作数据集(如BridgeDataV2、DROID和RT-1)中提炼出高质量的4D占据数据。该流水线主要包含以下两个关键步骤:
**统一的语义标签空间构建(Semantics Labeling):**在机器人操作中,准确预测下一帧动态的前提是理解不同物体(如刚体、关节体或可变形体)的物理行为特征。为此,本文利用视觉语言模型(VLM)对视频关键帧中的物体类别进行文本识别,并通过K-means聚类在超过15万个标签中提取出约50个类别的数据集级语义空间。随后,借助Grounding DINO和SAM2等方法,在连续的视频帧中提取并跟踪实例,将其精准映射到统一的语义类别中,确保了物体在时间维度上的一致性。
**4D语义占据数据构建(Occupancy Generation):**对于缺乏深度信息的RGB视频,本文首先使用免位姿输入的重建方法(MonST3R)以及稠密化操作(NKSR)重建4D点云。随后,将点云在规范空间中进行体素化(Voxelize),并通过多数投票机制(majority voting)为每个体素分配投影后的语义标签,从而生成包含丰富几何与语义信息的4D占据场。为了保证训练数据质量,在将数据输入模型之前通过RAFT光流对帧间一致性较差的渲染数据进行过滤。

2. 实验结果
为了全面验证ORV框架的有效性,本文在三个真实世界机器人数据集(BridgeData V2、DROID、RT-1)上进行实验评估,任务涵盖了条件视频生成、视觉规划以及策略学习等重要任务。
2.1 高保真视频生成
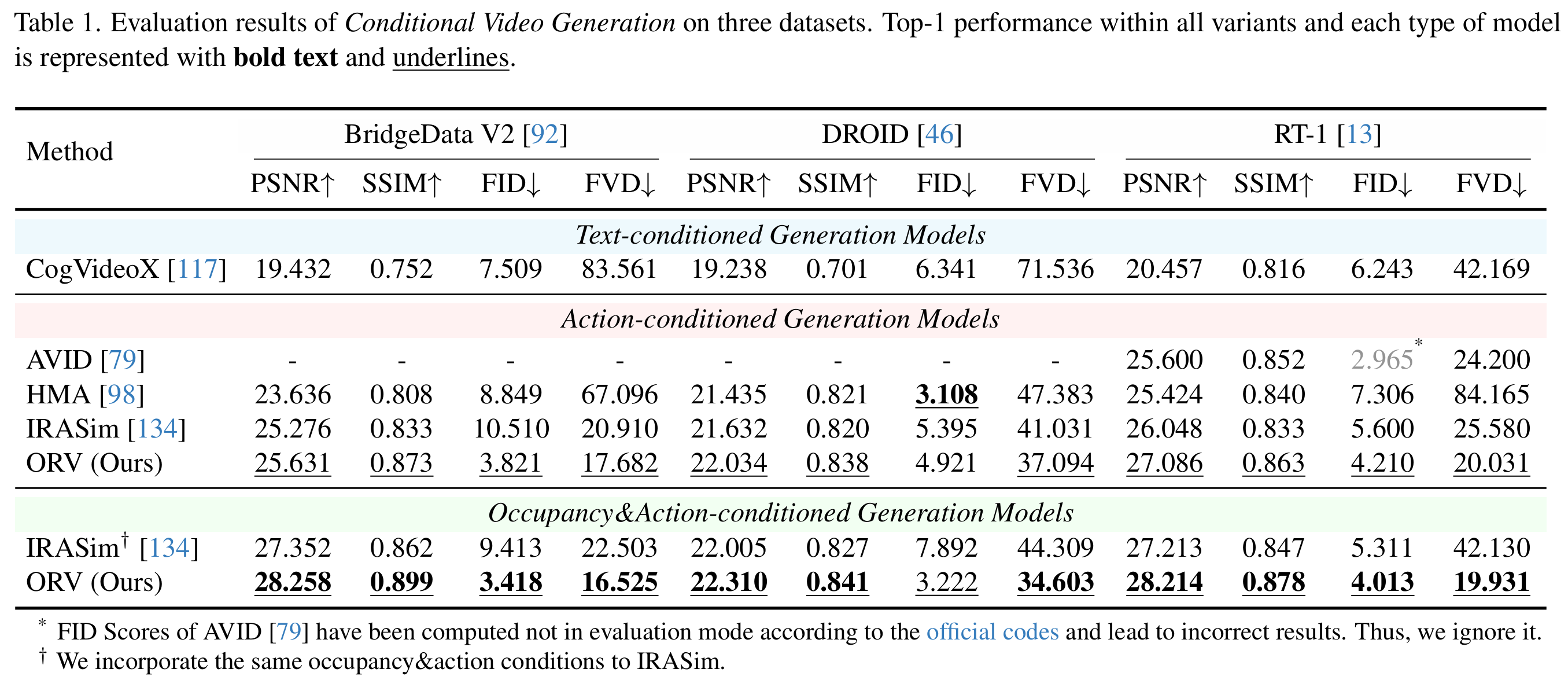
定量结果: 在视频生成质量方面,ORV显著优于所有测试的基线模型(如下表)。在衡量视频时空连贯性的核心指标FVD(Fréchet Video Distance)上,以BridgeDataV2数据集为例,ORV将FVD从动作条件模型IRASim的41.031大幅降低至16.525;在画面逼真度与结构一致性方面,ORV在PSNR、SSIM和FID指标上同样表现出色。例如,在BridgeDataV2数据集上,ORV的PSNR达到了28.258,比同样引入了占据先验的IRASim变体(27.352)有明显提升,SSIM也从0.86提升到了0.899.
定性表现: 如下图展示的条件视频生成结果所示,ORV在单视角、多视角以及虚实迁移任务中均展现出了卓越的生成能力:
- 高保真单视角视频生成:在BridgeV2数据集的对比中,基线模型(IRASim)在机械臂操作时出现了明显的物体形变,而ORV则完美还原了真实的物理交互过程;
- 高一致性多视角视频生成:以图中右侧的"折叠布料"任务为例,ORV能够同步生成三个视角的视频 。在处理这类复杂的动态形变时,模型依然保持了极高的跨视角几何连贯性。
- 高质量的虚实迁移(Sim-to-Real):如图左下方所示,利用图像生成引擎(如ControlNet)生成初始帧后,ORV能够直接利用物理仿真器提取的参数化占据地图,将其无缝扩展为具备真实纹理与光影的高保真现实操作视频。

2.2 增强视觉规划
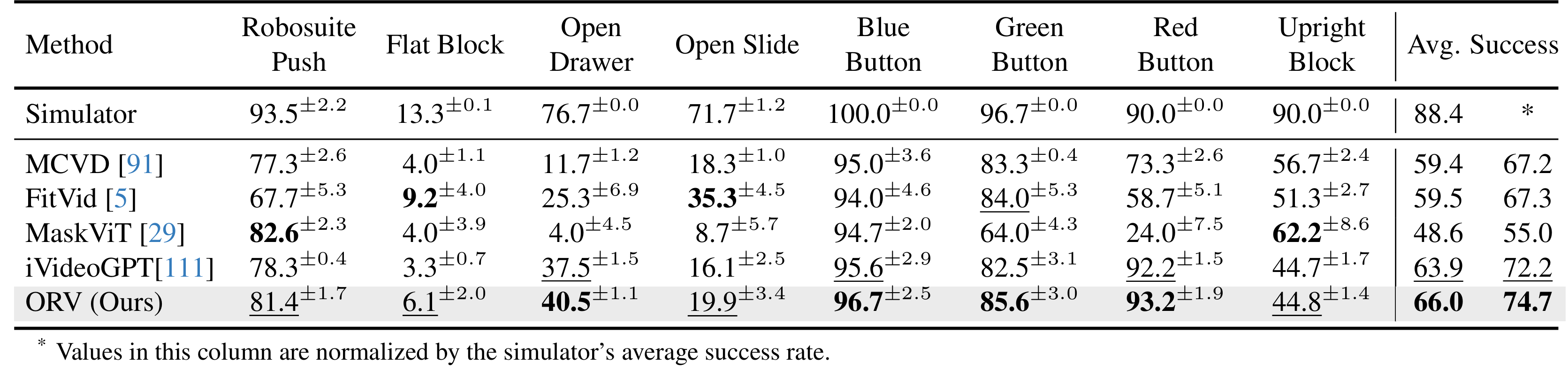
为了展示 ORV 在严格遵循动作指令方面的控制能力,本文在基于动作的视觉规划基准测试 V P 2 VP^2 VP2 上对其进行了评估 。如下表数据所示,ORV 的平均规划成功率达到了 66.0%,显著超越了 iVideoGPT、MCVD 和 FitVid 等主流视频预测基线模型。
2.3 作为数据引擎提升策略学习
除了生成高质量的视觉画面,ORV框架可以作为强大的"数据引擎",为机器人策略学习(Policy Learning)直接提供增广数据。在真实世界中收集多样化的机器人操作数据成本极为高昂,而ORV通过泛化能力,能够有效实现"外观随机化(Appearance Randomization)"。如下图所示,对于靠同一个物理操作轨迹,OR能够能生成多样化的操作视频。

为了验证合成数据对下游策略模型的实际增益,团队在 SimplerEnv-WidowX 物理仿真基准上进行了全面评估。实验将 ORV的增广数据加入训练集,对两个基线VLA模型进行同规格训练(结果如下表):
- RoboVLM:平均任务成功率从 29.8% 跃升至 33.9%(相对提升约 13.7%)。
- SpatialVLA:平均任务成功率从 36.2% 提升至 38.5%(相对提升约 6.5%)。
这一结果充分证明ORV生成框架能够作为高效的数据引擎进而间接提升机器人策略学习。
3. 总结
ORV 提出了一个突破性的以4D Occupancy为中心的解耦架构,成功打破了稀疏控制与密集视觉之间的表征壁垒。其卓越的视觉保真度、跨视角几何一致性以及对下游策略学习的显著增益,为具身智能领域的仿真与生成模型研究提供了极具价值的新范式。
未来,团队将继续探索结合在线4D占据预测技术,摆脱对离线数据的依赖,并引入更细粒度的全身关节动作表征,向着"超长视野(Long-horizon)复杂任务的实时闭环预测"这一终极目标迈进!
重磅!
全网首个!具身智能开源知识库来啦(技术/产业/投融资/上下游)
推荐阅读
VLA+RL方向首个系统教程来啦!Online RL/Offline RL/test time RL等~
我们用低成本的机械臂完成pi0/pi0.5/GR00T/世界模型等VLA任务~
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~