FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
FlashOcc: 通过通道到高度插件进行快速且内存高效的占用预测
Zichen Yu1 Changyong Shu2✉ Jiajun Deng3 Kangjie Lu2 Zongdai Liu2
Jiangyong Yu2 Dawei Yang2 Hui Li2 Yan Chen2
1Dalian University of Technology, 2Houmo AI, 3University of Adelaide
yuzichen@mail.dlut.edu.cn,jiajun.deng@adelaide.edu.au.,
{changyong.shu,kangjie.lu,zongdai.liu,jiangyong.yu,dawei.yang,hui.li,yan.chen}@houmo.ai
目录
[1 Introduction](#1 Introduction)
[1 简介](#1 简介)
[2 Related Work](#2 Related Work)
[2 相关工作](#2 相关工作)
[3 Framework 3 框架](#3 Framework 3 框架)
[3.1 Image Encoder](#3.1 Image Encoder)
[3.1 图像编码器](#3.1 图像编码器)
[3.2 View Transformer](#3.2 View Transformer)
[3.2 查看变压器](#3.2 查看变压器)
[3.3 BEV Encoder](#3.3 BEV Encoder)
[3.3BEV 编码器](#3.3BEV 编码器)
[3.4 Occupancy Prediction Module](#3.4 Occupancy Prediction Module)
[3.4 占用预测模块](#3.4 占用预测模块)
[3.5 Temporal Fusion Module](#3.5 Temporal Fusion Module)
[3.5 时态融合模块](#3.5 时态融合模块)
[4 Experiment](#4 Experiment)
[4 实验](#4 实验)
[4.1 Experimental Setup](#4.1 Experimental Setup)
[4.1 实验设置](#4.1 实验设置)
[4.2 Comparison with State-of-the-art Methods](#4.2 Comparison with State-of-the-art Methods)
[4.2 与最先进方法的比较](#4.2 与最先进方法的比较)
[4.3 Ablation Study](#4.3 Ablation Study)
[4.3 消融研究](#4.3 消融研究)
[5 Conclusion](#5 Conclusion)
[5 结论](#5 结论)
Abstract
摘要
Given the capability of mitigating the long-tail deficiencies and intricate-shaped absence prevalent in 3D object detection, occupancy prediction has become a pivotal component in autonomous driving systems. However, the procession of three-dimensional voxel-level representations inevitably introduces large overhead in both memory and computation, obstructing the deployment of to-date occupancy prediction approaches. In contrast to the trend of making the model larger and more complicated, we argue that a desirable framework should be deployment-friendly to diverse chips while maintaining high precision. To this end, we propose a plug-and-play paradigm, namely FlashOCC, to consolidate rapid and memory-efficient occupancy prediction while maintaining high precision. Particularly, our FlashOCC makes two improvements based on the contemporary voxel-level occupancy prediction approaches. Firstly, the features are kept in the BEV, enabling the employment of efficient 2D convolutional layers for feature extraction. Secondly, a channel-to-height transformation is introduced to lift the output logits from the BEV into the 3D space. We apply the FlashOCC to diverse occupancy prediction baselines on the challenging Occ3D-nuScenes benchmarks and conduct extensive experiments to validate the effectiveness. The results substantiate the superiority of our plug-and-play paradigm over previous state-of-the-art methods in terms of precision, runtime efficiency, and memory costs, demonstrating its potential for deployment. The code will be made available.
鉴于在 3D 物体检测中缓解长尾缺陷和复杂形状缺失的能力,占用预测已成为自动驾驶系统的关键组件。然而,三维体素级表示的处理不可避免地带来了内存和计算上的大量开销,阻碍了目前占用预测方法的部署。与使模型更大更复杂的趋势相反,我们认为一个理想的框架应该对各种芯片友好且保持高精度。为此,我们提出了一种即插即用的范式,即 FlashOCC,以实现快速且内存高效的占用预测,同时保持高精度。特别地,我们的 FlashOCC 基于当前的体素级占用预测方法进行了两项改进。首先,特征保持在 BEV 中,使得可以使用高效的 2D 卷积层进行特征提取。其次,引入了通道到高度的变换,将 BEV 中的输出提升到 3D 空间中。我们将 FlashOCC 应用于具有挑战性的 Occ3D-nuScenes 基准上的多种占用预测基线,并进行了广泛的实验以验证其有效性。结果证实了我们的即插即用范式在精度、运行时效率和内存成本方面优于先前的最新方法,展示了其部署的潜力。代码将公开。
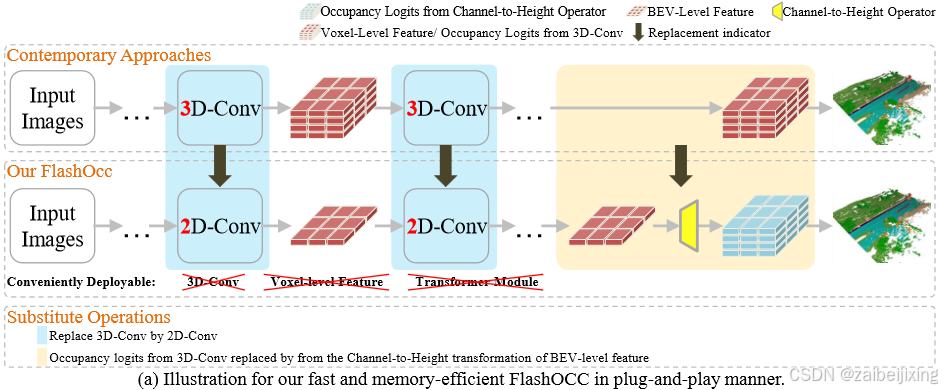
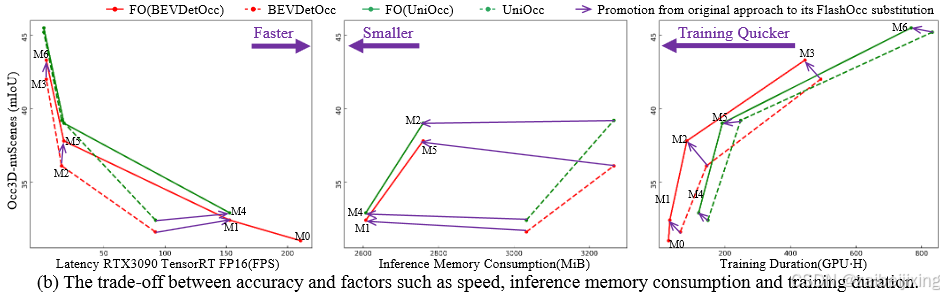
Figure 1. (a) illustrates how to achieve the proposed FlashOcc in plug-and-play manner. Contemporary approaches predict occupancy using voxel-level 3D feature processed by 3D-Conv. In contrast, our plugin substitute model achieves rapid and memory-efficient occupancy prediction by (1) replacing the 3D-Conv with 2D-Conv and (2) substituting the occupancy logits derived from the 3D-Conv with the Channel-to-Height transformation of BEV-level features acquired through 2D-Conv. The abbreviation "Conv" represents convolution. (b) exemplifies the trade-off between accuracy and factors such as speed, inference memory consumption, and training duration. The detailed configuration of M0-8 please consult to Table 2. "FO" is an acronym that stands for FlashOcc, and "FO(*****)" represents the plugin substitution for the corresponding model named with "*****". Best viewed in color.
图1(a)展示了如何以即插即用方式实现所提出的FlashOcc方法。现有方法通过3D卷积处理的体素级3D特征来预测占据栅格,而本研究的插件替代模型通过以下方式实现快速且内存高效的占据预测:(1) 用2D卷积替代3D卷积;(2) 将3D卷积生成的占据逻辑值替换为通过2D卷积获取的BEV层级特征的通道-高度变换。其中"Conv"表示卷积操作。图1(b)展示了精度与速度、推理内存消耗、训练时长等因素的权衡关系。M0-8的详细配置请参考表2。"FO"是FlashOcc的缩写,"FO()"表示对名为""的对应模型进行插件替换。建议彩色查看。
1 Introduction
1 简介
3D object detection in surround-view sense plays a crucial role in autonomous driving system. Particularly, image-based 3D perception has received increasing attention from both academia and industry, owing to its lower cost compared to LiDAR-dependent solutions and its promising performance 9, 12, 16, 27, 11, 35 . Nevertheless, the 3D object detection task is limited to generate bounding boxes within predefined classes, which gives rise to two major challenges. Firstly, it encounters long-tail deficiencies, wherein unlabeled classes emerge in real-world scenarios beyond the existing predefined classes. Secondly, it faces the issue of intricate-shape absence, as complex and intricate geometry of diverse objects are not adequately captured by existing detection methods.
3D 物体检测在环绕视图感知中在自动驾驶系统中起着至关重要的作用。特别是,基于图像的 3D 感知因其与 LiDAR 依赖性解决方案相比更低的成本以及其有前景的性能而受到学术界和工业界的日益关注9, 12, 16, 27, 11, 35。然而,3D 物体检测任务仅限于在预定义类别内生成边界框,这带来了两个主要挑战。首先,它面临长尾缺陷,即在现有预定义类别之外的现实世界场景中出现未标记的类别。其次,它面临复杂形状缺失的问题,因为现有的检测方法无法充分捕捉各种物体的复杂和精细几何形状。
Recently, the emerged task of occupancy prediction addresses the aforementioned challenges by predicting the semantic class of each voxel in 3D space 14, 10, 22, 23. This approach allows for the identification of objects that do not fit into the predefined categories and labels them as general objects. By operating at the voxel-level feature, these methods enable a more detailed representation of the scene, capturing intricate shapes and addressing the long-tail deficiencies in object detection.
最近,新兴的占用预测任务通过预测三维空间中每个体素的语义类别来解决上述挑战14, 10, 22, 23。这种方法能够识别出不符合预定义类别的对象,并将其标记为一般对象。通过在体素级特征上操作,这些方法能够实现对场景的更详细表示,捕捉复杂的形状并解决目标检测中的长尾缺陷。
The core of occupancy prediction lies in the effective construction of a 3D scene. Conventional methods employ voxelization, where the 3D space is divided into voxels, and each voxel is assigned a vector to represent its occupancy status. Despite their accuracy, utilizing three-dimensional voxel-level representations introduces complex computations, including 3D (deformable) convolutions, transformer operators and so on36, 22, 28, 31, 21, 24. These pose significant challenges in terms of on-chip deployment and computational power requirements. To mitigate these challenges, sparse occupancy representation 33 and tri-perspective view representation\[\] are investigated to conserve memory resources. However, this approach does not fundamentally address the challenges for deployment and computation.
占用预测核心在于有效构建 3D 场景。传统方法采用体素化,将 3D 空间划分为体素,并为每个体素分配一个向量来表示其占用状态。尽管准确,但使用三维体素级表示会引入复杂的计算,包括 3D(可变形)卷积、变换器操作等36, 22, 28, 31, 21, 24。这些在片上部署和计算能力要求方面带来了重大挑战。为了减轻这些挑战,研究了稀疏占用表示33和三视角表示10以节省内存资源。然而,这种方法并未从根本上解决部署和计算的挑战。
Inspired by sub-pixel convolution techniques 26, where image-upsampling is replaced by channel rearrangement, thus a Channel-to-Spatial feature transformation is achieved. Correspondly, in our work, we aim to implement a Channel-to-Height feature transformation efficiently. Given the advancement in BEV perception tasks, where each pixel in the BEV representation contains information about all objects in the corresponding pillar along height dimension, we intuitively utilize Channel-to-Height transformation for reshaping the flattened BEV features into three-dimensional voxel-level occupancy logits. Consequently, we focus on enhancing existing models in a general and plug-and-play manner, instead of developing novel model architectures, as listed in Figure. LABEL:fig:fig1 (a). Detially, we direct replace the 3D convolution in contemporary methodologies with 2D convolution, and replacing the occupancy logits derived from the 3D convolution output with the Channel-to-Height transformation of BEV-level features obtained via 2D convolution. These models not only achieves best trade-off between accuracy and time-consumption, but also demonstrates excellent deployment compatibility.
受亚像素卷积技术26的启发,其中图像上采样被通道重排取代,从而实现了通道到空间的特征变换。相应地,在我们的研究中,我们的目标是高效地实现通道到高度的特征变换。鉴于在 BEV 感知任务中的进步,其中 BEV 表示中的每个像素都包含对应支柱沿高度维度的所有对象的信息,我们直观地利用通道到高度的变换将展平的 BEV 特征重塑为三维体素级的占用概率。因此,我们专注于以通用且即插即用的方式增强现有模型,而不是开发新颖的模型架构,如图中所示。LABEL:fig:fig1 (a)。具体而言,我们直接用 2D 卷积替换了现代方法中的 3D 卷积,并用通过 2D 卷积获得的 BEV 级特征的通道到高度变换替换了 3D 卷积输出的占用概率。这些模型不仅在准确性和时间消耗之间取得了最佳权衡,还展示了出色的部署兼容性。
2 Related Work
2 相关工作
Voxel-level 3D Occupancy prediction. The earliest origins of 3D occupancy prediction can be traced back to Occupancy Grid Maps (OGM) 30, which aimed to extract detailed structural information of the 3D scene from images, and facilitating downstream planning and navigation tasks. The existing studies can be classified into sparse perception and dense perception based on the type of supervision. The sparse perception category obtains direct supervision from lidar point clouds and are evaluated on lidar datasets 10. Simultaneously, dense perception shares similarities with semantic scene completion (SSC) 2, 4. Voxformer 14 utilizes 2.5D information to generate candidate queries and then obtains all voxel features via interpolation. Occ3D 31 reformulate a coarse-to-fine voxel encoder to construct occupancy representation. RenderOcc 22 extract 3D volume feature from surround views via 2D-to-3D network and predict density and label for each voxel with Nerf supervision. Furthermore, several benchmarks with dense occupancy labels are proposed 31, 28. The approaches mentioned above voxelize 3D space with each voxel discribed by a vector 24, 15, 23, 28, 22, 3, 14, as voxel-level representations with fine-grained 3D structure are inherently well-suited for 3D semantic occupancy prediction. However, the computational complexity and deployment challenges arised with voxel-based representations have prompted us to seek more efficient alternatives..
体素级别的 3D 占有率预测。3D 占有率预测的最早起源可以追溯到占有网格图(Occupancy Grid Maps,OGM)30,其旨在从图像中提取 3D 场景的详细结构信息,并促进下游规划和导航任务。现有的研究可以根据监督类型分为稀疏感知和密集感知。稀疏感知类别直接从激光雷达点云中获取监督,并在激光雷达数据集10上进行评估。同时,密集感知与语义场景补全(SSC)2, 4有相似之处。Voxformer 14利用 2.5D 信息生成候选查询,然后通过插值获得所有体素特征。Occ3D 31重新设计了从粗到细的体素编码器以构建占有率表示。RenderOcc 22通过 2D 到 3D 网络从周围视图中提取 3D 体特征,并用 Nerf 监督预测每个体素的密度和标签。此外,还提出了几个具有密集占有率标签的基准31, 28。上述方法通过将 3D 空间体素化,每个体素由向量24, 15, 23, 28, 22, 3, 14描述,因为具有精细 3D 结构的体素级表示本质上非常适合 3D 语义占用预测。然而,基于体素的表示带来的计算复杂性和部署挑战促使我们寻求更高效的替代方案。
BEV-based 3D Scene Perception. BEV-based methods employ a vector to represent the features of an entire pillar on BEV grid. Compared to voxel-based methods, it reduces feature representation in height-dimension for more computationally efficient, and also avoid the need for 3D convolutions for more deployment-friendly. Promising results have demonstrated on diverse 3d scene perceptions, such as 3D lane detection 32, depth estimation34, 3D object detection 9, 12, 19 and 3D object tracking 37. Although there are no methods performing occupancy prediction based on BEV-level features, however, BEV-level features can capture height information implicitly, which has been validated in scenarios of uneven road surfaces or suspended objects. These findings prompt us to leverage BEV-level features for efficient occupancy prediction.
基于 BEV 的3D场景感知。基于 BEV 的方法使用一个向量来表示 BEV 网格上整个柱状体的特征。与基于体素的方法相比,它在高度维度上减少了特征表示,从而提高了计算效率,并且避免了对 3D 卷积的需求,从而提高了部署的友好性。在各种 3D 场景感知任务中,如 3D 车道检测32、深度估计34、3D 目标检测9, 12, 19和 3D 目标跟踪37中,已经展示了有希望的结果。尽管目前还没有基于 BEV 级特征进行占用预测的方法,但 BEV 级特征可以隐式地捕捉高度信息,这在路面不平整或悬挂物体的场景中已经得到验证。这些发现促使我们利用 BEV 级特征进行高效的占用预测。
Efficient Sub-pixel Paradigm. The sub-pixel convolution layer first proposed in image super-resolution 26 is capable of super-resolving low resolution data into high resolution space with very little additional computational cost compared to a deconvolution layer. The same idea has also been applied on BEV segmentation 17, wherein the segmentation representation of an 8×8 grid size is described by a segmentation query, thus only 625 seg queries are used to predict the final 200×200 BEV segmentation results. Based on the aforementioned approaches, we propose the Channel-to-Height transformation as an efficient method for occupancy prediction, wherein the occupancy logits are directly reshaped from the flattened BEV-level feature via the Channel-to-Height transform. To the best of our knowledge, we are the pioneers in applying the sub-pixel paradigm to the occupancy task with utilizing BEV-level features exclusively, while completely eschewing the use of computational 3D convolutions.
高效的亚像素范式。亚像素卷积层最初在图像超分辨率26中提出,能够将低分辨率数据超分辨率为高分辨率空间,与反卷积层相比,计算成本非常低。这一想法也应用于 BEV 分割17,其中大小为 8×8 的网格的分割表示由一个分割查询描述,因此仅使用 625 个 seg 查询来预测最终的 200×200 BEV 分割结果。基于上述方法,我们提出了通道到高度的变换作为占用预测的高效方法,其中占用对数直接通过通道到高度变换从展平的 BEV 级特征重塑。据我们所知,我们是第一个将亚像素范式应用于仅使用 BEV 级特征的占用任务,同时完全摒弃了计算 3D 卷积的使用。
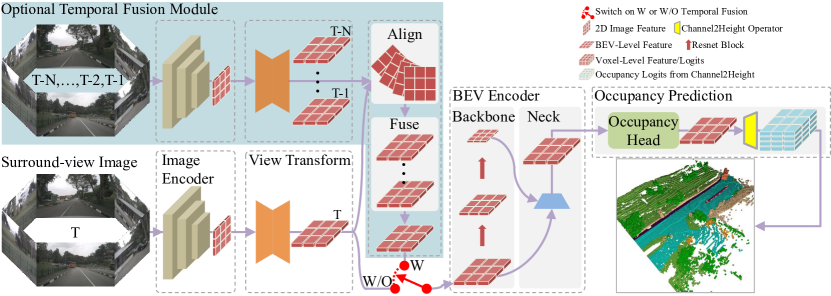
Figure 1: The diagram illustrates the overarching architecture of our FlashOcc, which is best viewed in color and with zoom functionality. The region designated by the dashed box indicates the presence of replaceable modules. The feature shapes of each replaceable module are denoted by icons representing 2D image, BEV-level, and voxel-level features, respectively. The light blue region corresponds to the optional temporal fusion module, and its utilization is contingent upon the activation of the red switch.
图 1:该图展示了 FlashOcc 的整体架构,建议使用彩色和缩放功能查看。虚线框标识的区域表示可替换模块的存在。每个可替换模块的特征形状由代表 2D 图像、BEV 级别和体素级别特征的图标表示。浅蓝色区域对应于可选的时间融合模块,其使用取决于红色开关的激活。
3 Framework
3 框架
FlashOcc represents a pioneering contribution in the field by successfully accomplishing real-time surround-view 3D occupancy prediction with remarkable accuracy. Moreover, it exhibits enhanced versatility for deployment across diverse on-vehicle platforms, as it obviates the need for costly voxel-level feature procession, wherein view transformer or 3D (deformable) convolution operators are avoided. As denoted in Figure1. , the input data for FlashOcc consists of surround-view images, while the output is dense occupancy prediction results. Though our FlashOcc focuses on enhancing existing models in a general and plug-and-play manner, it can still be compartmentalized into five fundamental modules: (1) A 2D image encoder responsible for extracting image features from multi-camera images. (2) A view transformation module that facilitates the mapping from 2D perceptive-view image features into 3D BEV representation. (3) A BEV encoder tasked with processing the BEV feature information (4) Occupancy prediction module that predicts segmentation label for each voxel. (5) An optional temporal fusion module designed to integrate historical information for improved performance.
FlashOcc 在实时环绕视图 3D 占用预测领域做出了开创性的贡献,并以卓越的准确性取得了成功。此外,它还展示了在各种车载平台上部署的增强灵活性,因为它消除了对昂贵的体素级特征处理的需求,避免了使用视图变换器或 3D(可变形)卷积运算符。如图 1 所示,FlashOcc 的输入数据包括环绕视图图像,输出则是密集的占用预测结果。尽管我们的 FlashOcc 旨在以通用的即插即用方式增强现有模型,但它仍然可以分解为五个基本模块:(1)一个负责从多摄像头图像中提取图像特征的 2D 图像编码器。(2)一个视图变换模块,促进从 2D 感知视图图像特征到 3D BEV 表示的映射。(3)一个 BEV 编码器,负责处理 BEV 特征信息(4)占用预测模块,预测每个体素的分割标签。(5)一个可选的时间融合模块,旨在整合历史信息以改善性能。
3.1 Image Encoder
3.1 图像编码器
The image encoder extracts the input images to high-level features in perception-view. Detailly, it utilizes a backbone network to extract multi-scale semantic features, which are subsequently fed into a neck module for fusion, thereby the semantic information with diverse granularities are fully exploited. The classic ResNet 8 and strong SwinTransformer 18 is commonly chosen as the backbone network. ResNet's multiple residual-block design enables the elegant acquisition of feature representations with rich and multi-granularity semantic information. Swin Transformer introduces a hierarchical structure that divides the input image into small patches and processes them in a progressive manner. By utilizing a shifted window mechanism, SwinTransformer achieves high efficiency and scalability while maintaining competitive performance on various benchmarks. As for the neck module, the concise FPN-LSS 9, 25 was selected. It integrates the fine-grained features with directly upsampled coarse-grained features. In fact, as the proposed paradigm that is never limited to a specific architecture, thus the backbone network can be replaced with other advanced models, such as SwinTransformer 18, Vit 5. And the neck module can also be substituted with other competitive variants, such as NAS-FPN 7, BiFPN 29.
图像编码器将输入图像提取为感知视图中的高级特征。具体而言,它利用主干网络提取多尺度语义特征,然后将这些特征输入颈部模块进行融合,从而充分利用具有不同粒度的语义信息。经典的 ResNet 8 和强大的 SwinTransformer 18 通常被选为主干网络。ResNet 的多个残差块设计能够优雅地获取具有丰富多粒度语义信息的特征表示。Swin Transformer 引入了一种分层结构,将输入图像划分为小补丁并按顺序处理。通过利用移位窗口机制,SwinTransformer 实现了高效率和可扩展性,同时在各种基准上保持具有竞争力的性能。至于颈部模块,选择了简洁的 FPN-LSS 9, 25。它将细粒度特征与直接上采样的粗粒度特征相结合。事实上,作为一种不受限于特定架构的提议范式,因此主干网络可以被其他先进模型替换,例如 SwinTransformer 18、Vit 5。颈部模块也可以被其他具有竞争力的变体替换,例如 NAS-FPN 7、BiFPN 29。
3.2 View Transformer
3.2 视图变换器
The view transformer is a crucial component in surround-view 3D perception system, it maps the 2D perceptive-view feature into BEV representation. Lift-splat-shot (LSS) 25, 9 and Lidar Structure (LS) 13 have been widely used in recent work. LSS leverages pixel-wise dense depth prediction and camera in/extrinsic parameters to project image features onto a predefined 3D grid voxels. Subsequently, pooling operations are applied along the vertical dimension (height) to obtain a flatten BEV representation. However, LS relies on the assumption of uniformly distributed depth to transfer features, which results in feature misalignment and subsequently causes false detections along camera-ray direction, though the computational complexity decreases.
视图变换器是环绕视图 3D 感知系统中的关键组件,它将 2D 感知视图特征映射到 BEV(鸟瞰图)表示。Lift-splat-shot(LSS)25, 9和 Lidar Structure(LS)13在最近的工作中被广泛使用。LSS 利用逐像素的密集深度预测和相机内外参来将图像特征投影到预定义的 3D 网格体素上。随后,沿垂直维度(高度)进行池化操作以获得扁平化的 BEV 表示。然而,LS 依赖于均匀分布深度的假设来传递特征,这导致特征错位,并沿着相机射线方向产生错误的检测,尽管计算复杂度降低了。
3.3 BEV Encoder
3.3 BEV 编码器
The BEV encoder enhances the coarse BEV feature obtained through view transformation, resulting in a more detailed 3D representation. The architecture of the BEV encoder resembles that of image encoder, comprising a backbone and a neck. We adopt the setting outlined in section 3.1. The issue of center features missing 6 (for LSS) or aliasing artifacts (for LS) is improved via feature diffusion after several blocks in the backbone. As illustrated in Figure. 1, two multi-scale features are integrated to enhance the representation quality.
BEV 编码器通过视图变换获得的粗略 BEV 特征进行增强,从而得到更详细的 3D 表示。BEV 编码器的架构类似于图像编码器,由主干和颈部组成。我们采用第 3.1 节中概述的设置。中心特征缺失的问题6(对于 LSS)或混叠伪影(对于 LS)通过主干中几个块的特征扩散得到改善。如图 1 所示,通过集成两种多尺度特征来增强表示质量。
3.4 Occupancy Prediction Module
3.4 占用预测模块
As depicted in Figure. 1, the BEV feature obtained from the neck for occupancy is fed into an occupancy head. It consists of a multi-layer convolutional network 1, 23, 22 or complex multi-scale feature fusion module 15, the latter exhibits a superior global receptive field, enabling a more comprehensive perception of the entire scene, while also providing finer characterization of local detailed features. The resulting BEV feature from the occupancy head is then passed through the Channel-to-Height module. This module performs a simple reshape operation along the channel dimension, transforming the BEV feature from a shape of B×C×W×H to occupancy logits with a shape of B×C∗×Z×W×H, where B, C, C∗, W, H, and Z represent the batch size, the channel number, the class number, the number of x/y/z dimensions in the 3D space respectively, and C=C∗×Z.
如图1所示,从颈部获取的 BEV 特征用于占用率,并将其输入到占用头中。它由一个多层卷积网络1,23,22或复杂的多尺度特征融合模块15组成,后者具有优越的全局感受野,能够更全面地感知整个场景,同时提供对局部细节特征的更精细表征。然后,来自占用头的BEV特征通过 Channel-to-Height模块。该模块在通道维度上执行简单的重塑操作,将 BEV 特征从形状 B×C×W×H 转换为形状为 B×C∗×Z×W×H 的占用对数,其中 B 、 C 、 C∗ 、 W 、 H 和 Z 分别表示批量大小、通道数、类别数以及 3D 空间中的 x / y / z 维度, C=C∗×Z 。
3.5 Temporal Fusion Module
3.5 时态融合模块
The temporal fusion module is designed to enhance the perception of dynamic objects or attributes by integrating historical information. It consists of two main components: the spatio-temporal alignment module and the feature fusion module, as depicted in Figure 1. The alignment module utilizes ego information to align the historical BEV features with the current LiDAR system. This alignment process ensures that the historical features are properly interpolated and synchronized with the current perception system. Once the alignment is performed, the aligned BEV features are passed to the feature fusion module. This module integrates the aligned features, taking into consideration their temporal context, to generate a comprehensive representation of the dynamic objects or attributes. The fusion process combines the relevant information from the historical features and the current perception inputs to improve the overall perception accuracy and reliability.
时间融合模块旨在通过整合历史信息来增强对动态对象或属性的感知能力。它由两个主要组件组成:时空对齐模块和特征融合模块,如图 1 所示。对齐模块利用自我信息将历史 BEV 特征与当前 LiDAR 系统进行对齐。这一对齐过程确保历史特征能够被正确地插值和与当前感知系统同步。一旦对齐完成,对齐后的 BEV 特征将传递给特征融合模块。该模块整合对齐后的特征,同时考虑其时间上下文,以生成动态对象或属性的全面表示。融合过程结合历史特征和当前感知输入的相关信息,以提高整体感知的准确性和可靠性。
4 Experiment
4 实验
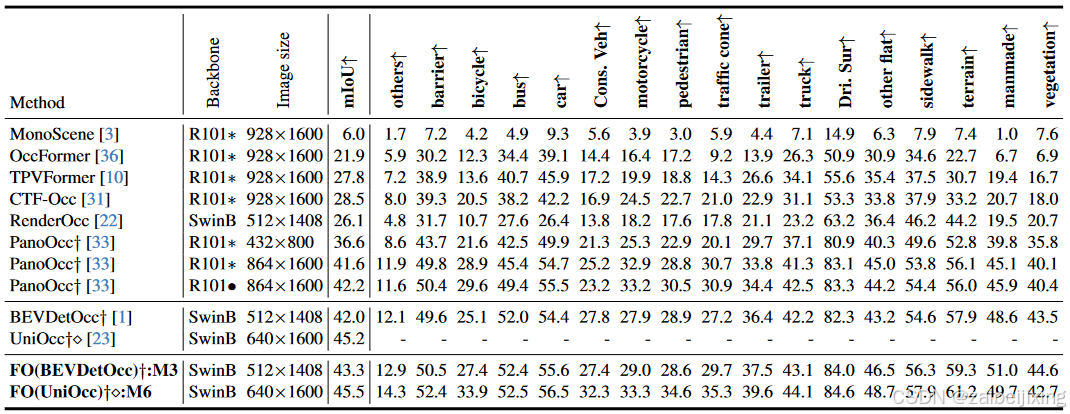
Table 1: 3D occupancy prediction performance on the Occ3D-nuScenes valuation dataset. The symbol ∗ indicates that the model is initialized from the pre-trained FCOS3D backbone. "Cons. Veh" represents construction vehicle, and "Dri. Sur" is short for driveable surface. "Train. Dur." is an abbreviation for training duration. "Mem." represents memory consumption during inference. ∙ means the backbone is pretrained by the nuScense segmentation. The frame per second (FPS) metric is evaluated using RTX3090, employing the TensorRT benchmark with FP16 precision. "FO" is an acronym that stands for FlashOcc, and "FO(*****)" represents the plugin substitution for the corresponding model named with "*****". † denotes the performance is reported with utilization of camera mask during training. The symbol ⋄ means the utilization of class-balance weight for occupancy classification loss.
表 1:Occ3D-nuScenes 评估数据集上的3D占用预测性能。符号 ∗ 表示模型从预训练的 FCOS3D 主干初始化。"Cons. Veh"代表施工车辆,"Dri. Sur"是可行驶表面的缩写。"Train. Dur."是训练持续时间的缩写。"Mem."表示推理过程中的内存消耗。 ∙ 表示主干通过 nuScense 分割进行预训练。每秒帧数(FPS)指标使用 RTX3090 评估,采用 TensorRT 基准测试,使用 FP16 精度。"FO"是 FlashOcc 的缩写,"FO(*****)"表示用"*****"命名的相应模型的插件替换。 † 表示在训练中利用相机掩码进行性能报告。符号 ⋄ 表示使用类别平衡权重进行占用分类损失。
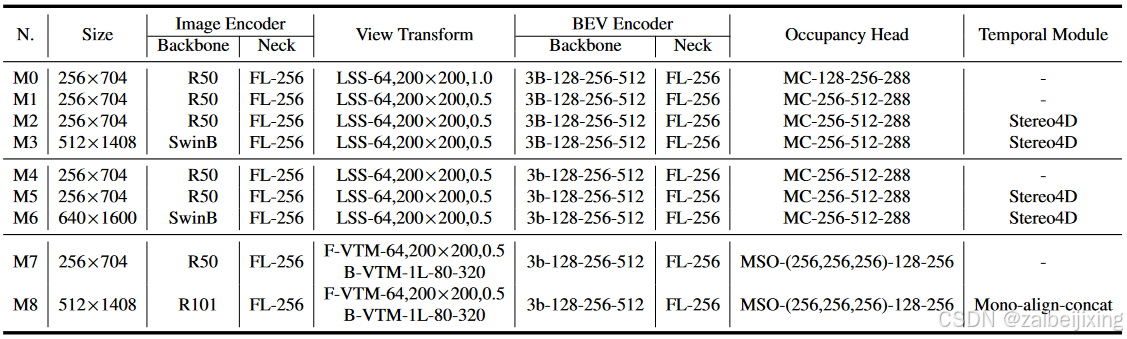
Table 2: Detail settings for various methodologies. The suffix "-number" signifies the count of channels within this module, while "number×number" denotes the size of image or feature. "3B" and "1L" are abbreviations for 3 bottleNeck and 1 transformer layer respectively. "BE" is short for bevformer encoder. "MC" represnets multi-convolution Head. "FL" is short for FPN LSS. ",number" indicates the resolution of depth bin. F-VTM and B-VTM denotes forward projection and depth-aware backward projection in 15 respectively. MSO refers to the multi-scale occupancy prediction head described in 15, and the suffix "-(number,...,number)" indicates the list of channel number for the multi-scale input featuers. Stereo4D refers to the utilization of stereo volume to enhance the depth prediction for LSS, without incorporating BEV feature from previous frame. Mono-align-concat signifies the utilization of mono depth prediction for LSS, where the bev feature from the history frame is aligned and concatenated along the channel.
表 2:各种方法的详细设置。后缀"-number"表示该模块内的通道数,而"number × number"表示图像或特征的大小。"3B"和"1L"分别是 3 个瓶颈层和 1 个变换器层的缩写。"BE"是 bevformer 编码器的缩写。"MC"代表多卷积头。"FL"是 FPN LSS 的缩写。",number"表示深度 bin 的分辨率。F-VTM 和 B-VTM 分别表示15中的前向投影和深度感知后向投影。MSO 指的是15中描述的多尺度占用预测头,后缀"-(number,...,number)"表示多尺度输入特征的通道数列表。Stereo4D 指的是利用立体体积来增强 LSS 的深度预测,而不包含前一帧的 BEV 特征。Mono-align-concat 表示使用单目深度预测来增强 LSS,其中来自历史帧的 BEV 特征被对齐并沿通道连接。
In this section, we first detail the benchmark and metrics, as well as the training details for our FlashOcc in Section. 4.1. Then, Section. 4.2 present the main results of our FlashOcc with fair comparison to other state-of-the-art methods on occupancy prediction. After that, we conduct extensive ablative experiments to investigate the effectiveness of each component in our proposed FlashOcc in Section. 4.3..
在本节中,我们首先详细介绍了基准和指标,以及我们 FlashOcc 的训练细节,见第 4.1 节。然后,第 4.2 节展示了我们 FlashOcc 的主要结果,并与在占用预测方面的其他最先进方法进行了公平比较。之后,我们在第 4.3 节进行了广泛的消融实验,以研究我们提出的 FlashOcc 中每个组件的有效性。
4.1 Experimental Setup
4.1 实验设置
Benchmark. We conducted occupancy on the Occ3D-nuScenes 31 datasets. The Occ3D-nuScenes dataset comprises 700 scenes for training and 150 scenes for validation. The dataset covers a spatial range of -40m to 40m along the X and Y axis, and -1m to 5.4m along the Z axis. The occupancy labels are defined using voxels with dimensions of 0.4m×0.4m×0.4m for 17 categories. Each driving scene contains 20 seconds of annotated perceptual data captured at a frequency of 2 Hz. The data collection vehicle is equipped with one LiDAR, five radars, and six cameras, enabling a comprehensive surround view of the vehicle's environment. As for evaluation metrics, the mean intersection-over-union (mIoU) over all classes is reported.
我们在 Occ3D-nuScenes 31数据集上进行了占用率测试。Occ3D-nuScenes 数据集包含 700 个训练场景和 150 个验证场景。该数据集在 X 轴和 Y 轴上覆盖了-40m 到 40m 的空间范围,在 Z 轴上覆盖了-1m 到 5.4m 的空间范围。占用率标签使用尺寸为 0.4m×0.4m×0.4m 的体素定义,涵盖了 17 个类别。每个驾驶场景包含 20 秒的标注感知数据,以 2 Hz 的频率捕获。数据收集车辆配备了一个 LiDAR、五个雷达和六个摄像头,能够提供车辆周围环境的全面视图。对于评估指标,报告了所有类别的平均交并比(mIoU)。
Training Details. As our FlashOcc is designed in a plug-and-play manner, and the generalization and efficiency are demonstrated on diverse mainstream voxel-based occupancy methodologies, i.e. BEVDetOcc 1, UniOcc 23 and FBOcc 15. For a fair comparison, the training details are following the origin mainstream voxel-based occupancy methodologies strictly. As the channel number would be altered when replacing 3D convolution by 2D convolution, the detail architectures of respective plugin substitutions are presented in Table. 2. In the "Method" column of each experimental table, we use a ":" to associate each plugin substitution with its corresponding structure, i.e., M0-8. All models are traind using the AdamW optimizer 20, wherein a gradient clip is applied with learning rate 1e-4, with a total batch size of 64 distributed across 8 GPUS. The total training epoch for BEVDetOcc and UniOcc is set to 24, while FBOcc is trained for 20 epoch only. Class-balanced grouping and sampling is not used in all experiments.
训练细节。由于我们的 FlashOcc 设计为即插即用的方式,并且在多种主流基于体素的占用方法上展示了泛化和效率,即 BEVDetOcc 1、UniOcc 23和 FBOcc 15。为了公平比较,训练细节严格遵循原始主流基于体素的占用方法。由于在用 2D 卷积替换 3D 卷积时通道数会改变,各插件替换的详细架构在表 2 中展示。在每个实验表的"方法"列中,我们使用":"将每个插件替换与其对应的结构相关联,即 M0-8。所有模型都使用 AdamW 优化器20进行训练,其中应用了梯度裁剪,学习率为 1e-4,总批量大小为 64,分布在 8 个 GPU 上。BEVDetOcc 和 UniOcc 的总训练周期设置为 24,而 FBOcc 仅训练 20 个周期。在所有实验中未使用类平衡分组和采样。
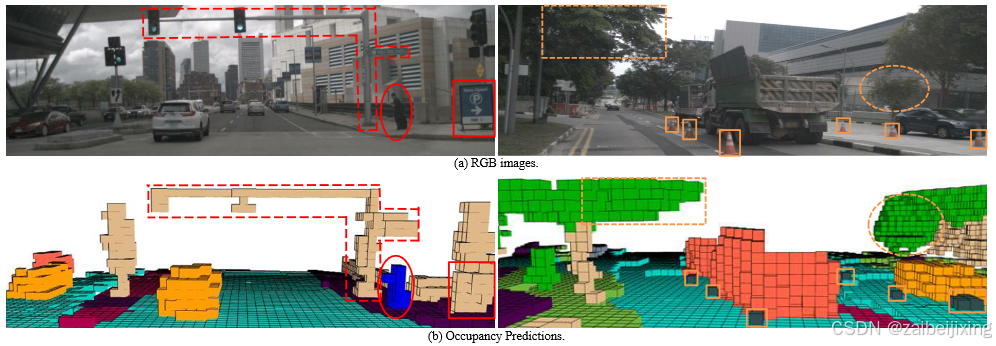
Figure 3: Qualitative results on Occ3D-nuScenes. Note that the perception range in Occ3D-nuScenes spans from -40m to 40m along the X and Y axes, and from -1m to 5.4m along the Z axis. Consequently, objects located outside of this range are not predicted.
图3:Occ3D-nuScenes 上的定性结果。注意,Occ3D-nuScenes 的感知范围沿 X 轴和 Y 轴从-40m 延伸到 40m,沿 Z 轴从-1m 延伸到 5.4m。因此,位于该范围之外的物体不会被预测。
4.2 Comparison with State-of-the-art Methods
4.2 与最先进方法的比较
We evaluate our plugin FlashOcc on BEVDetOcc 1 and UniOcc 23, and also compare the performance of our plugin substitutions with popular existing approaches, i.e. MonoScene 3, TPVFormer 10, OccFormer 36, CTF-Occ 31, RenderOcc 22 and PanoOcc 33. As listed in Table. 1, 3D occupancy prediction performances on the Occ3D-nuScenes valuation dataset are listed. Both the results with ResNet-101 and SwinTransformer-Base are evaluated. Our plug-and-play implementation of FlashOcc demonstrates improvement of 1.3 mIoU on BEVDetOcc. Additionally, the 0.3 mIoU enhancement on UniOcc further highlights the channel-to-height's ability to preserve voxel-level information within BEV feature, as the rendering supervision in UniOcc need fine-grained volume representation. These results demonstrate the efficacy and generalizability of our proposed FlashOcc approach. In addition, our FO(BEVDetOcc) surpasses the state-of-the-art transformer-based PanoOcc approach by 1.1 mIoU, further demonstrating the superior performance of our approach.
我们在 BEVDetOcc 1 和 UniOcc 23 上评估了我们的插件 FlashOcc,并且还比较了我们的插件替换与流行的现有方法的性能,即 MonoScene 3、TPVFormer 10、OccFormer 36、CTF-Occ 31、RenderOcc 22 和 PanoOcc 33。如表 1 所示,Occ3D-nuScenes 评估数据集上的 3D 占有率预测性能被列出。我们评估了使用 ResNet-101 和 SwinTransformer-Base 的结果。我们即插即用的 FlashOcc 实现在 BEVDetOcc 上展示了 1.3 mIoU 的改进。此外,UniOcc 上的 0.3 mIoU 提升进一步突出了通道到高度在 BEV 特征中保留体素级信息的能力,因为 UniOcc 中的渲染监督需要精细的体积表示。这些结果证明了我们提出的 FlashOcc 方法的有效性和通用性。此外,我们的 FO(BEVDetOcc) 比基于 transformer 的最新 PanoOcc 方法高出 1.1 mIoU,进一步证明了我们方法的优越性能。
The qualitative visualization of FO(BEVDetOcc) is illustrated in Figure. 2, the traffic signal crossbar spanning over the road (indicated by the red dashed line) and the tree extending above the road (indicated by the orange dashed line) can both be effectively voxelized via our FO(BEVDetOcc), thus demonstrating the preservation of height information. With regards to the voxel description of pedestrians (indicated by the red ellipse), a forward protruding voxel at the chest signifies the mobile holded by the person, while the voxel extending behind the leg represents the suitcase pulled by the person. Furthermore, the small traffic cones are also observed in our predicted occupancy results (indicated by the solid orange rectangles). These findings collectively emphasize the outstanding capability of our FlashOcc in accurately capturing intricate shapes.
FO(BEVDetOcc)的定性可视化如图 2 所示,横跨道路的交通信号杆(由红色虚线表示)和延伸到道路上方的树木(由橙色虚线表示)都可以通过我们的 FO(BEVDetOcc)有效地体素化,从而证明了高度信息的保留。关于行人的体素描述(由红色椭圆表示),胸部突出的体素表示人手持的物品,而腿后延伸的体素表示人拖着的行李箱。此外,我们预测的占用结果中还观察到了小交通锥(由实橙色矩形表示)。这些发现共同强调了我们 FlashOcc 在准确捕捉复杂形状方面的卓越能力。
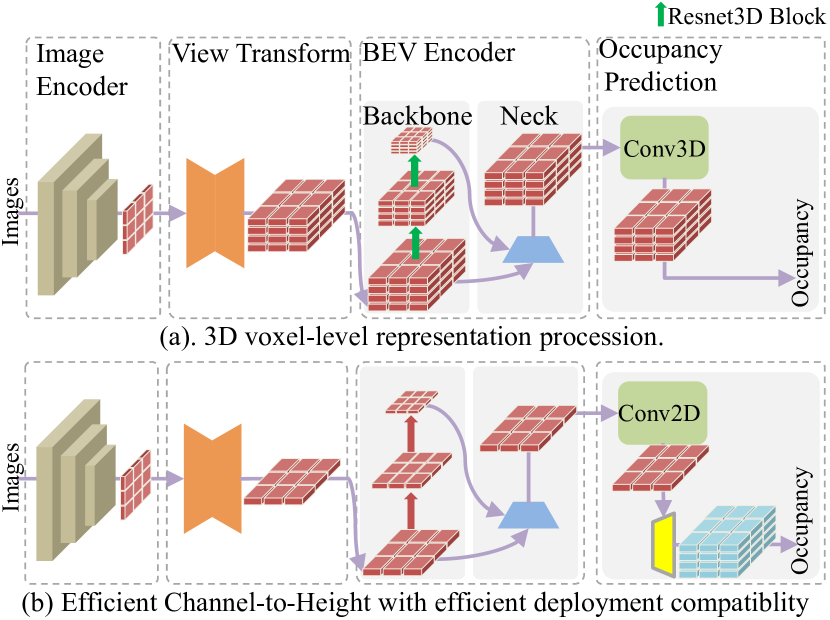
Figure 4: Architecture comparion between 3D voxel-level representation procession and ours plugin substitution. Apart from the instructions provided for the Resnet3D Block, all remaining icons comply with the guidelines presented in Figure LABEL:fig:fig1 and Figure 1.
图4:3D 体素级表示处理与我们的插件替换之间的架构比较。除了为 Resnet3D Block 提供的说明外,所有剩余的图标均符合图 LABEL:fig:fig1 和图 1 中提供的规定。
4.3 Ablation Study
4.3 消融研究
We conduct ablative experiments to demonstrate the efficacy of each component in our plugin substitution. Unless stated otherwise, all experiments employ ResNet-50 as the backbone network with a input image resolution of 704 x 256. The spatial representation of 3D space is discretized into a grid size of 200 × 200 × 1. The model are all pretrained on 3D object detection tasks.
我们进行消融实验以展示插件替换中每个组件的有效性。除非另有说明,所有实验均采用 ResNet-50 作为主干网络,输入图像分辨率为 704 x 256。3D 空间的几何表示被离散化为 200 × 200 × 1 的网格大小。所有模型都在 3D 目标检测任务上进行了预训练。
Efficient Channel-to-Height Devoid of Complex 3D Convolution Computation. We employ the Channel-to-Height operation at the output of the occupancy head, whereby the 2D feature is directly reshaped into 3D occupancy logits. This process does not involve explicit height-dimension representation learning. From an intuitive standpoint, accurate 3D occupancy prediction necessitates a voxel-aware representation in three dimensions, involving complex 3D computations, as extensively discussed in prior research 28, 33, 22. To ensure a fair comparison, we choose BEVDetOcc 1 without temporal module as the voxel-level competitor. As illustrated in Figure. 3. We decrease the grid size along the z-axis of the LSS to 1 and replace the 3D convolution in BEVDetOcc with 2D counterparts. Additionally, Channel-to-Height transformation is plugged at the output of the model. The comparative results are presented in Table 3. Our M0 method, despite incurring a mere 0.6 mIoU performance degradation, achieves a speedup of more than twofold, surpassing the baseline method operated at 92.1 FPS with a rate of 210.6 FPS. And our M1 module demonstrates superior performance, achieving a significant 0.8 mIoU improvement with a faster FPS of 60.6Hz compared to the 3D voxel-level representation approach. These outcomes further highlight the efficient deployment compatibility of our proposed Channel-to-Height paradigm, which eliminates the need for computational 3D voxel-level presentation procession.
高效的通道到高度操作,无需复杂的 3D 卷积计算。我们在占用头的输出处采用通道到高度操作,将 2D 特征直接重塑为 3D 占用对数。这个过程不涉及显式的高度维度表示学习。从直观上看,准确的 3D 占用预测需要在三个维度上的体素感知表示,涉及复杂的 3D 计算,如之前的研究28, 33, 22中广泛讨论的那样。为了确保公平比较,我们选择没有时间模块的 BEVDetOcc 1作为体素级竞争对手。如图 3 所示,我们将 LSS 的网格大小沿 z 轴减小到 1,并用 2D 卷积替换 BEVDetOcc 中的 3D 卷积。此外,我们在模型的输出处插入通道到高度变换。比较结果见表 3。尽管我们的 M0 方法仅导致 0.6 mIoU 的性能下降,但实现了超过两倍的加速,以 210.6 FPS 的速度超过了以 92.1 FPS 运行的基线方法。我们的 M1 模块展示了卓越的性能,与 3D 体素级表示方法相比,实现了显著的 0.8 mIoU 提升,并且帧率更快,达到 60.6Hz。这些结果进一步突显了我们提出的通道到高度范式的有效部署兼容性,该范式消除了计算 3D 体素级表示过程的需要。
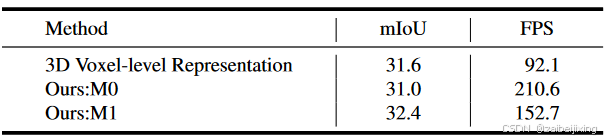
Table 3: Comparison between 3D voxel-level representation procession and efficient Channel-to-Height. The FPS are test on RTX3090 by tensorrt with fp16 precision.
表3:3D 体素级表示处理与高效通道到高度的比较。FPS 在 RTX3090 上使用 tensorrt 以 fp16 精度测试。
Generalizable FlashOcc on Diverse Methodologies. In order to demonstrate the generalization of our plug-and-play FlashOcc, we aim to achieve convincing results by applying it on popular 3D convolution-based occupancy models like BEVDetOcc 1, RenderOcc 22, and FBOcc 15. Specifically, we replace the 3D convolutions in these models with 2D convolutions, and substitute the occupancy logits obtained from the original model's final output with the occupancy logits obtained through the Channel-to-Height transformation. The comparative results are presented in Table 4, our method showcases superior performance. Detailly, our plugin substitution, FO(BEVDetOcc), surpasses the original BEVDetOcc by 1.7 mIoU, our FO(UniOcc) incurs a mere 0.2 mIoU performance degradation compared to the original UniOcc, and our FO(FBOcc) acheves a 0.1 mIoU improvement compared to the origin FBOcc, the aforementioned experimental results demonstrate significant improvements or remain comparable. These findings across various methodologies provide further demonstration for the efficacy of our generalizable approach, which eliminates the requirement for computationally intensive 3D voxel-level presentation processing while ensures optimal performance.
在多样化方法上的可泛化 FlashOcc。为了展示我们即插即用的 FlashOcc 的泛化能力,我们旨在通过在流行的基于 3D 卷积的占有模型(如 BEVDetOcc 1、RenderOcc 22和 FBOcc 15)上应用它来获得令人信服的结果。具体而言,我们用 2D 卷积替换这些模型中的 3D 卷积,并用通过通道到高度变换获得的占有对数替换原始模型最终输出的占有对数。比较结果如表 4 所示,我们的方法展示了优越的性能。详细来说,我们的插件替换 FO(BEVDetOcc)比原始的 BEVDetOcc 提高了 1.7 mIoU,我们的 FO(UniOcc)与原始 UniOcc 相比仅导致 0.2 mIoU 的性能下降,而我们的 FO(FBOcc)与原始 FBOcc 相比提高了 0.1 mIoU。上述实验结果展示了显著的改进或保持可比性。这些跨各种方法的发现进一步证明了我们可泛化方法的有效性,该方法消除了计算密集的 3D 体素级表示处理要求,同时确保了最佳性能。
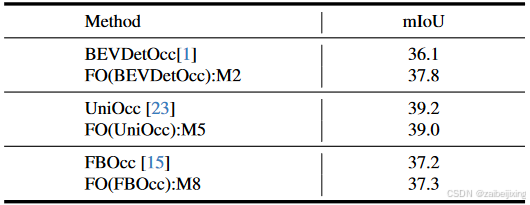
Table 4: Generalization demonstration of our plug-and-play FlashOcc on various popular voxel-level occupancy methodologies. The FPS are test on RTX3090 by tensorrt with fp16 precision. The abbreviation "FO" represent FlashOcc respectively.
表4:我们即插即用的 FlashOcc 在各种流行的体素级占有率方法上的泛化演示。FPS 是在 RTX3090 上使用 tensorrt 以 fp16 精度测试的。缩写"FO"分别代表 FlashOcc。
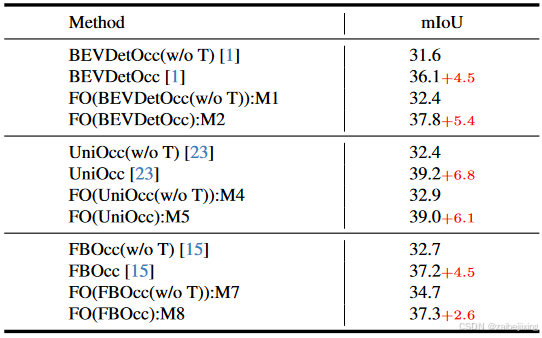
Table 5: Demonstration for consistent improvement in Temporal Module. "w/o T" denotes for without temporal module.
表5:展示时间模块一致性改进的示例。"w/o T"表示不使用时间模块。
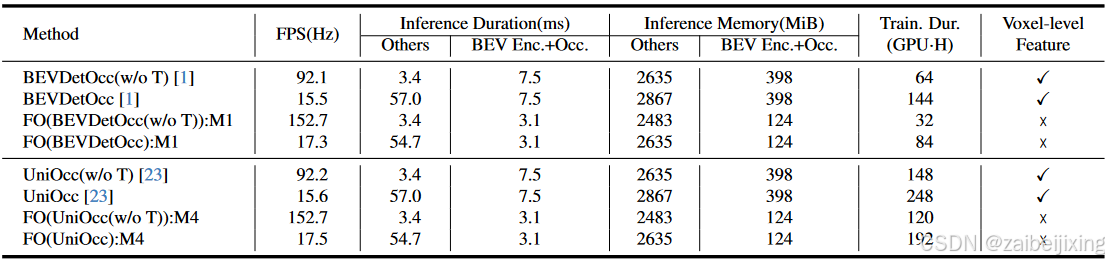
Table 6: Analysis of Resource Consumption during training and deployment. The FPS are test on single RTX3090 by tensorrt with fp16 precision. "Train. Dur." is short for training duration. "Enc.", "Occ." and "Feat" represent encoder, occupancy prediction and feature respectively. "GPU⋅H" denotes "1 GPU × 1 Hour".
表6:训练和部署过程中的资源消耗分析。FPS 是在单个 RTX3090 上使用 tensorrt 以 fp16 精度测试的。"Train. Dur."是训练持续时间的缩写。"Enc."、"Occ."和"Feat"分别代表编码器、占用预测和特征。"GPU ⋅ H"表示"1 GPU × 1 Hour"。
Consistent Improvement on Temporal Fusion. Temporal augmentation is an essential tool in 3D perception for enhancing performance. To demonstrate the comparable performance of our plug-and-play FlashOcc before and after incorporating the temporal module compared to the original voxel-based approach, we conducted experimental validation using well-established temporal configurations of mainstream models as listed in Table. 5. Compared to the baseline method BEVDetOcc, our FlashOcc exhibits improvements of 0.8 mIoU and 1.7 mIoU on both the non-temporal and temporal variants, respectively. Additionally, while the baseline method only achieves a 4.5 mIoU improvement when incorporating temporal information, our FlashOcc achieves a superior increase of 5.4 mIoU. In term of the baseline method UniOcc, our FlashOcc achieves a 0.5 mIoU improvement on the non-temporal approach. And when temporal information is introduced, we observe a significant increase of 6.1 mIoU, this improvement aligns with the temporal enhancement observed in the baseline method. As for the baseline method FBOcc, our FlashOcc achieves improvements of 2.0 mIoU and 0.1 mIoU on the non-temporal and temporal approaches, respectively. Moreover, in the temporal method, we observe an overall increase of 2.6 mIoU. However, the temporal improvement in our FlashOcc is not as significant as that of the baseline method. This is primarily due to the substantial improvement achieved by our non-temporal approach compared to the baseline method. In conclusion, our FlashOcc demonstrates significant improvements when temporal information is introduced, compared to the non-temporal approach. Additionally, our FlashOcc achieves notable improvements or comparable performance compared to the baseline method in both the without and with temporal module configuration.
在时间融合上的持续改进。时间增强是 3D 感知中提升性能的重要工具。为了展示我们的即插即用 FlashOcc 在加入时间模块前后与原始基于体素的方法相比的可比性能,我们使用表5 中列出的主流模型的成熟时间配置进行了实验验证。与基线方法 BEVDetOcc 相比,我们的 FlashOcc 在非时间和时间变体上分别提高了 0.8 mIoU 和 1.7 mIoU。此外,当基线方法仅通过引入时间信息实现 4.5 mIoU 的改进时,我们的 FlashOcc 实现了更优的 5.4 mIoU 的提升。至于基线方法 UniOcc,我们的 FlashOcc 在非时间方法上实现了 0.5 mIoU 的改进。而当引入时间信息时,我们观察到显著的 6.1 mIoU 的提升,这一改进与基线方法中观察到的时间增强一致。至于基线方法 FBOcc,我们的 FlashOcc 实现了 2.0 mIoU 和 0.在非时域和时域方法上分别展示 1 mIoU。此外,在时域方法中,我们观察到总体提高了 2.6 mIoU。然而,在我们的 FlashOcc 中,时域改进并不像基线方法那样显著。这主要是由于我们的非时域方法相对于基线方法取得了显著的改进。总之,与非时域方法相比,引入时域信息时,我们的 FlashOcc 展示了显著的改进。 此外,我们的 FlashOcc 在没有和有时间模块配置的情况下,与基线方法相比都取得了显著改进或可比性能。
Analyzation for Resource Consumption. The performance of FlashOcc across diverse configurations has been validated in aforementioned paragraph, the resource consumption during model training and deployment will be further analyzed. Following the setting in Table. 5, we provide details on FPS, inference duration, inference memory consumption and training duration for each method. Given the constrained applicability of our plugin, which exclusively impacts BEV encoder and occupancy head, we classify these two constituents as a distinct module to be examined. Meanwhile, the residual components, namely the image encoder and view transform, constitute a self-contained module referred to as "others" for analytical purposes.
资源消耗分析。如前所述,FlashOcc 在各种配置下的性能已经得到验证,接下来将进一步分析模型训练和部署过程中的资源消耗。按照表 5 中的设置,我们将提供每种方法的 FPS、推理时间、推理内存消耗和训练时间的详细信息。鉴于我们的插件在适用性方面的限制,它仅影响 BEV 编码器和占用头,我们将这两个组件分类为一个单独的模块进行分析。同时,剩余的组件,即图像编码器和视图变换,构成了一个自包含的模块,称为"其他",用于分析目的。
In the case of BEVDetOcc, the utilization of our FlashOcc results in a notable reduction of 58.7% in the inference duration of BEV encoder and occupancy prediction head, decreasing from 7.5 ms to 3.1 ms. At the same time, the inference memory consumption experiences a substantial savings of 68.8% from 398 MiB to 124 MiB. The training duration is reduced from 64 to 32 and from 144 to 84 respectively, for the experimental settings without and with temporal fusion module. Moreover, owing to the temporal methodology implemented in BEVDetOcc is stereo matching, the "others" module exhibits notably longer inference time when operating in the temporal configuration. Nonetheless, the adoption of a channel-wise grouped matching mechanism results in a comparatively reduced memory overhead. Similar conclusions were obtained on UniOcc as well, as it shares a similar model structure with BEVDetOcc. However, the integration of Rendering Supervision in UniOcc introduces a significant increase in training duration.
在 BEVDetOcc 的情况下,使用我们的 FlashOcc 将 BEV 编码器和占用预测头的推理时间显著减少了 58.7%,从 7.5 ms 减少到 3.1 ms。同时,推理内存消耗也大幅节省了 68.8%,从 398 MiB 减少到 124 MiB。对于不带和带有时间融合模块的实验设置,训练时间分别从 64 减少到 32,从 144 减少到 84。此外,由于 BEVDetOcc 中的时间方法论是立体匹配,"others"模块在时间配置下表现出明显更长的推理时间。然而,采用逐通道分组匹配机制会导致相对减少的内存开销。UniOcc 上也得出了类似的结论,因为它与 BEVDetOcc 共享相似的模型结构。然而,UniOcc 中集成的渲染监督引入了训练时间的显著增加。
5 Conclusion
5 结论
In this paper, we introduce a plug-and-play approach called FlashOCC, which aims to achieve fast and memory-efficient occupancy prediction. It directly replaces 3D convolutions in voxel-based occupancy approaches with 2D convolutions, and incorporates the Channel-to-Height transformation to reshape the flattened BEV feature into occupancy logits. The effectiveness and generalization of FlashOCC have been demonstrated across diverse voxel-level occupancy prediction methods. Extensive experiments have demonstrated the superiority of this approach over previous state-of-the-art methods in terms of precision, time consumption, memory efficiency, and deployment-friendly. To the best of our knowledge, we are the first in applying the sub-pixel paradigm (Channel-to-Height) to the occupancy task with utilizing BEV-level features exclusively, completely avoiding the use of computational 3D (deformable) convolutions or transformer modules. And the visualization results convincingly demonstrate that FlashOcc successfully preserves height information. In our future work, we will explore the integration of our FlashOcc into the perception pipeline of autonomous driving, aiming to achieve efficient on-chip deployment.
本文介绍了一种即插即用的称为 FlashOCC 的方法,旨在实现快速且内存高效的占有率预测。它直接用 2D 卷积替换基于体素的占有率方法中的 3D 卷积,并结合通道到高度变换将展平的 BEV 特征重塑为占有率对数。FlashOCC 在各种体素级占有率预测方法中展示了其有效性和泛化能力。广泛的实验证明了该方法在精度、时间消耗、内存效率和部署友好性方面优于先前的最新方法。据我们所知,我们是首次将亚像素范式(通道到高度)应用于仅使用 BEV 级特征的占有率任务,完全避免了使用计算量大的 3D(可变形)卷积或变换器模块。可视化结果有力地证明了 FlashOcc 成功保留了高度信息。在未来的工作中,我们将探索将 FlashOcc 集成到自动驾驶感知流水线中,旨在实现高效的芯片部署。