整体pipeline
bash
多帧多相机图像
↓
2D Backbone + FPN
↓
3D Query(体素 / implicit)
↓
Cross Attention(类似 DETR3D)
↓
时序对齐(ego-motion + feature warp)
↓
4D latent occupancy(coarse)
↓
Deconv / Upsample(coarse → dense)
↓
多头输出(occupancy / flow / surface / field)详细流程
初始化 3D Query:Qi=Embedding(xi,yi,zi)+learnablefeatureQ_i = Embedding(x_i, y_i, z_i) + learnable featureQi=Embedding(xi,yi,zi)+learnablefeature
对于每一个 3D Query(一个3D点):利用相机参数(内参、外参),将这个3D点投影到N个不同的2D图像平面上,得到N个对应的2D像素坐标。
从之前提取好的N个视角对应的2D特征图中,通过双线性插值,取出这N个2D坐标位置的特征值。
将这N个来自不同视角的2D特征聚合起来(常用方法:求和、求平均、注意力加权、Transformer等),形成一个融合后的特征。这个特征整合了多个视角对该3D点的"观察"。
双线性插值:
fik=bilinearsample(Fk,uk,vk)f_i^k = bilinear_{sample}(F_k, u_k, v_k)fik=bilinearsample(Fk,uk,vk)
2D Backbone提取的特征图,经过线性变换,分别作为 K和 V。
Attention融合:
Qi′=Attention(Qi,fik)Q_i' = Attention(Q_i, {f_i^k})Qi′=Attention(Qi,fik)
展开就是:
αk=softmax(Qi⋅Kk)α_k = softmax(Q_i · K_k)αk=softmax(Qi⋅Kk)
Qi′=ΣαkVkQ_i' = Σ α_k V_kQi′=ΣαkVk
交互(优化):Q与 K计算相似度(Attention Score),然后加权聚合 V,得到更新后的 Q'。
迭代:将 Q'作为新的 Q,经过多轮迭代,Q不断吸收2D特征信息,变得越来越准确。
输出:每一个3D Query 现在都附带了一个从多视角图像中提取并融合的特征。这些"携带了信息的3D点"构成了对3D场景的表示,后续可以输入给3D解码器:
如果是体素形式,可以直接渲染成体素网格。
如果是隐式形式,可以输入一个MLP来预测该点的占用值 或符号距离场值,最终通过提取占用等值面 来得到重建的3D表面。隐式形式是更为先进的做法。
体素: 构建3D场:如果是 voxel:Fi,j,k=QiLFi,j,k = Q_i^LFi,j,k=QiL -> 得到:F(x,y,z)(离散版本)
隐式:连续查询(implicit):
Fgridi,j,k=QiLF_{grid}i,j,k = Q_i^LFgridi,j,k=QiL
Q(x,y,z)=MLP(trilinear(Fgrid,x,y,z))Q(x,y,z) = MLP( trilinear(F_{grid}, x,y,z) )Q(x,y,z)=MLP(trilinear(Fgrid,x,y,z))
Cross Attention(类似 DETR3D)
投影与多尺度采样
来自上一层输出的3Dquery :
Q∈RNq×CQ ∈ ℝ^{Nq × C}Q∈RNq×C
Nq = Query数量(= voxel数 or 采样点数)
C = 特征维度(比如 128)
每个query:Qi=(xi,yi,zi,fi)Q_i = (x_i, y_i, z_i, f_i)Qi=(xi,yi,zi,fi)
多个相机特征通过FPN:
Fks∈RC×Hs×WsF_k^s ∈ ℝ^{C × H_s × W_s}Fks∈RC×Hs×Ws
k = 相机编号(N个相机)
s = FPN层级(多尺度)
在每个FPN层进行多尺度采样:fik,s=bilinearsample(Fks,uks,vks)f_i^{k,s} = bilinear_{sample}(F_k^s, u_k^s, v_k^s)fik,s=bilinearsample(Fks,uks,vks)输出:fik,s∈RCf_i^{k,s} ∈ ℝ^Cfik,s∈RC
总集合:Vi=fik,s∈R(K×S)×CV_i = {f_i^{k,s}} ∈ ℝ^{(K×S) × C}Vi=fik,s∈R(K×S)×C
最后构造QKV
qi=Wq⋅Qiq_i = W_q · Q_iqi=Wq⋅Qi
kk,s=Wk⋅fik,sk_{k,s} = W_k · f_i^{k,s}kk,s=Wk⋅fik,s
vk,s=Wv⋅fik,sv_{k,s} = W_v · f_i^{k,s}vk,s=Wv⋅fik,s
线性层:Wq,Wk,Wv∈RC×CW_q, W_k, W_v ∈ ℝ^{C × C}Wq,Wk,Wv∈RC×C
attention: 点积 scorek,s=qi⋅kk,sscore_{k,s} = q_i · k_{k,s}scorek,s=qi⋅kk,s
softmax: αk,s=softmax(scorek,s)α_{k,s} = softmax(score_{k,s})αk,s=softmax(scorek,s)
加权融合:Qi′=Σαk,s⋅vk,sQ_i' = Σ α_{k,s} · v_{k,s}Qi′=Σαk,s⋅vk,s
更新Query: Qi′∈RCQ_i' ∈ ℝ^CQi′∈RC
残差 + FFN(Transformer标准结构)
Qi=Qi+Qi′Q_i = Q_i + Q_i'Qi=Qi+Qi′
Qi=Qi+FFN(Qi)Q_i = Q_i + FFN(Q_i)Qi=Qi+FFN(Qi)
Q′∈RNq×CQ' ∈ ℝ^{Nq × C}Q′∈RNq×C: 每个3D点都"看过图像"了
问题解释
$f_i$ = "3D空间中的隐状态(latent feature)"
$F_k$ = "2D图像的观测特征(observation feature)"$Q_i = (x,y,z,f_i)$ 里的 $f_i$ 到底是什么?
答:初始化时$f_i = learnable embedding$(随机初始化),
这时,$f_i$和图像一点关系都没有,经过 Cross Attention 之后:
$f_i$ ← 融合了多视角图像信息,$f_i$ = "这个3D位置的语义 + 几何 + 时序信息":
即 世界在(x,y,z)这个位置的"内部状态表示"。$F_k$ 是什么?
答:$F_k(u,v)$ = 图像在像素(u,v)的特征时序对齐(ego-motion + feature warp)
目的:把历史特征变换到当前时刻的坐标系,再做融合
- 当前帧的每个位置,应该从上一帧的哪里取值
对当前 BEV 每个像素:(i,j)→(xt,yt)(i, j) → (x_t, y_t)(i,j)→(xt,yt),再转换为物理坐标
xt=(i−cx)⋅r;yt=(j−cy)⋅r,r为分辨率x_t=(i−c_x)⋅r;y_t=(j−c_y)⋅r,r为分辨率xt=(i−cx)⋅r;yt=(j−cy)⋅r,r为分辨率
(xsrc,ysrc)=Tt→t−1(xt,yt)(x_{src}, y_{src}) = T_{t \to t-1}(x_t, y_t)(xsrc,ysrc)=Tt→t−1(xt,yt) :我们把"warp"变成了一个函数:输出坐标 → 输入坐标
-
把这个函数离散化成 grid
grid(i,j)=(xsrc,ysrc)grid(i,j)=(x_{src},y_{src})grid(i,j)=(xsrc,ysrc):得到一个张量B, H, W, 2,表示输出每个位置,要去输入 feature 的哪个位置取值转换成 grid_sample 的 normalized grid,因为 PyTorch 要求:x∈−1,1
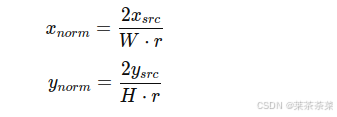
得到:gridb,i,j=(xnorm,ynorm)gridb, i, j = (x_{norm}, y_{norm})gridb,i,j=(xnorm,ynorm)
-
已知输入 feature + 采样坐标(grid),怎么得到输出?
output(i,j)=input(grid(i,j))output(i,j)=input(grid(i,j))output(i,j)=input(grid(i,j))
python
warped_bev = F.grid_sample(
bev_{t-1},
grid,
mode='bilinear',
padding_mode='zeros'
)- 将对齐后的历史与当前观测融合
- BEV_t=α⋅current+(1−α)⋅history
- concat + CNN
- attention(BEVFormer)
- GRU / temporal encoder
4D latent occupancy(coarse)
升维到 3D(lifting)
BEV → voxel / volume
得到 coarse latent occupancy
4D tensor: T, X, Y, Z, C,这就是:coarse 4D latent field
它在系统里的作用(非常关键)
- 提供"全局时空上下文"
比如:
被遮挡的车 → 还能记住
行人运动 → 连续轨迹 - 作为 fine occupancy 的先验
coarse → refine → fine occupancy - coarse latent 会学到:
motion pattern
temporal consistency
为什么叫 latent?
因为:
它不是直接预测occupied / free,而是:
feature embedding → 再 decode 成 occupancy
Deconv / Upsample(coarse → dense)
目标:coarse feature → dense occupancy
一般使用插值,DConv,Implicit decoding等方法