标签: #空间智能 #AI实体化 #三维重构 #数字孪生 #视频孪生
一、AI的"阿喀琉斯之踵":困在虚拟,不懂现实
斯坦福大学李飞飞教授曾断言:AI的下一场革命,是从"虚拟"到"实体"的迁徙 。当前AI能通过律师考试、创作诗歌、生成逼真图像,看似无所不能,却存在致命短板------缺乏物理世界的"空间智能"。它们困在数据黑盒里,能"看懂"像素,却无法理解三维空间、重力、材质与运动规律,连"拿一杯水"这种人类幼儿的简单动作都难以完成 。
这正是AI从"纸上谈兵"走向"现实落地"的核心瓶颈。无论是机器人、自动驾驶、智慧城市还是工业元宇宙,AI必须先看懂真实世界的三维结构、实时动态与物理关系,才能真正与物理世界交互、决策、行动 。
二、空间智能:AI寒武纪大爆发的核心引擎
李飞飞在《从语言到世界:空间智能是AI的下一个前沿》中明确指出:空间智能(Spatial Intelligence)是AI突破虚拟桎梏、迈向实体智能的关键 。它要求AI像人类一样:
-
感知三维:理解距离、方向、大小、深度与相对位置
-
理解物理:掌握重力、碰撞、运动轨迹、材质属性
-
实时交互:动态跟踪实体、预测行为、毫秒级响应
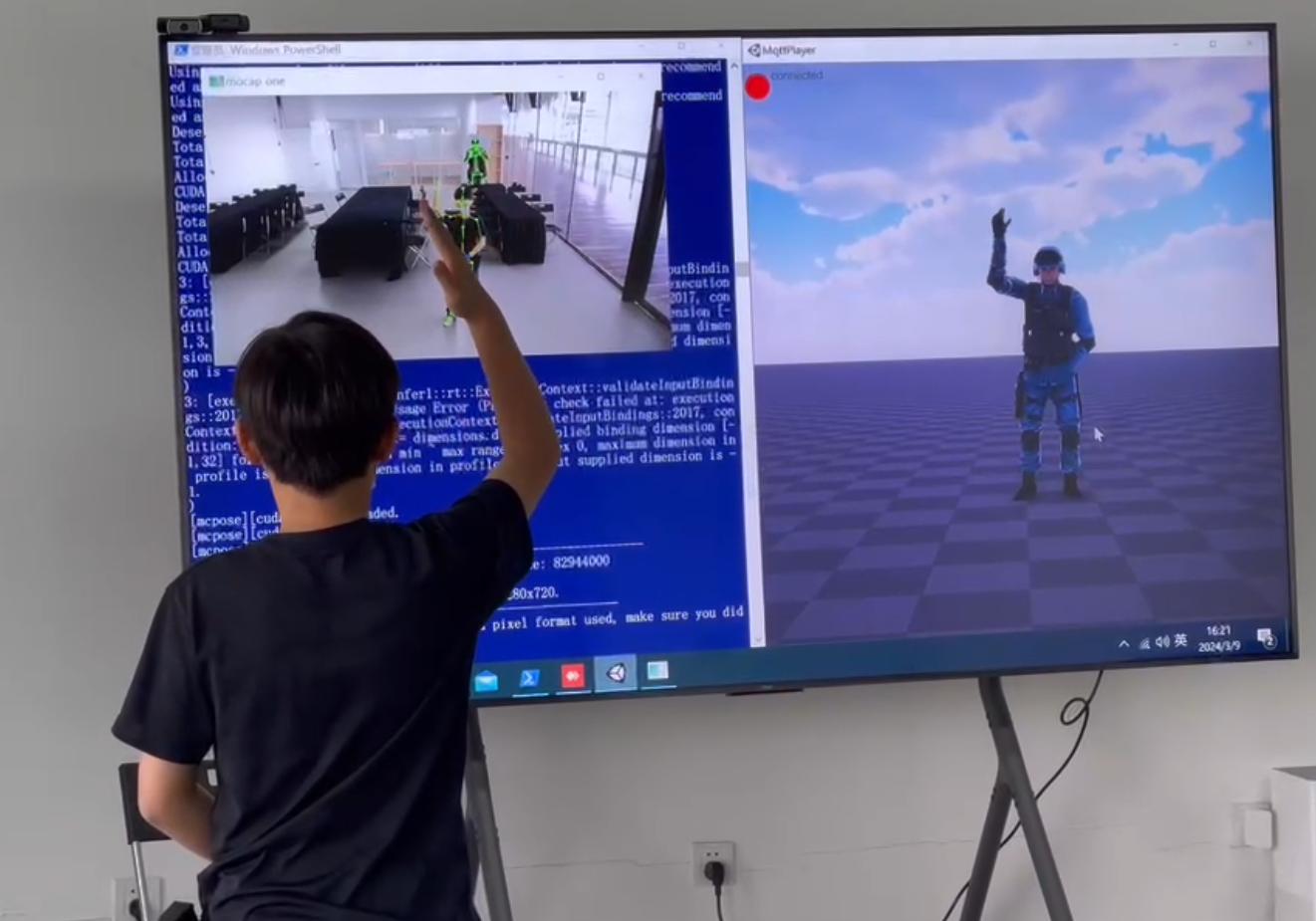
这不再是实验室概念,而是产业数字化、智能化的刚需底层能力 。谁率先攻克动态视频实时三维重构,谁就能抢占AI实体化的战略高地。
三、黎阳之光:中国原创,领跑全球实时三维重构
北京黎阳之光作为国内视频孪生与空间智能领域的领军企业,早已突破这一技术壁垒------动态视频实时三维重构技术已实现规模化落地,处于国际先进水平。
- 核心技术突破:从静态建模到动态实时映射
传统数字孪生依赖离线扫描、人工建模、静态贴图,周期长、成本高、无法同步动态目标。黎阳之光原创技术实现三大颠覆:
-
视频流实时三维化:普通监控视频直接转为动态3D模型,物理场景与数字空间毫秒级同步
-
全域高精度重构:- 工业级:0.1毫米建模精度
-
城市级:10厘米定位精度
-
无标定自适应:多摄像头自动时空校准,无需复杂安装参数
-
动态目标全追踪:人、车、物体实时三维坐标、姿态、轨迹连续稳定输出

- 技术原理:多视图几何+深度学习+时空融合
黎阳之光技术架构完全自主可控,核心流程:
-
多机协同采集:全域摄像头多角度同步视频输入
-
特征实时提取:AI算法识别边缘、角点、轮廓、关键特征点
-
三维坐标计算:多视图立体匹配(MVS)+三角测量,生成3D点云与模型
-
时空统一融合:全局坐标系校准、动态更新、误差优化
-
实体智能决策:基于三维坐标实现行为分析、距离判断、异常预警
四、技术价值:让AI真正"看懂"物理世界
- 破解AI"数字幻觉"
传统AI易出现空间错乱、比例失调、物理违背。黎阳之光三维重构基于真实物理世界数据,让AI获得可靠空间常识,从"猜测"走向"精准计算"。
- 赋能千行百业实体智能化
-
智慧城市/安防:长安街等重大场景实现毫米级追踪、零盲区管控,异常行为精准识别
-
智慧交通:车辆三维轨迹、车距、姿态实时感知,支撑车路协同、事故预警
-
智慧水利:南水北调等工程实现雷视融合三维安防,误报率<0.5次/天
-
工业互联网:产线设备、工件三维实时建模,质检、安全、运维智能化
-
应急救援:浓烟、黑暗、复杂环境下三维空间重建,辅助决策与搜救
- 中国原创,打破国际垄断
技术100%自主知识产权,累计60余项专利,多项成果经权威鉴定为国际先进水平。摆脱对国外三维软件依赖,筑牢数字安全底座。
五、空间智能时代:中国技术站在世界前沿
李飞飞所预言的AI从虚拟到实体的革命已到来 。当全球还在实验室探索空间智能时,黎阳之光已实现工程化、规模化、产品化落地。
这不仅是技术突破,更是中国AI从"跟随"到"引领"的标志性跨越:
-
从语言智能走向空间智能
-
从虚拟生成走向实体理解
-
从单点算法走向全域物理映射
六、结语:实体智能,未来已来
AI的终极使命是服务现实、改造世界 。没有空间智能,AI永远是虚拟世界的"聪明囚徒"。
黎阳之光动态视频实时三维重构,正是打开物理世界的钥匙------让AI真正拥有三维感知、物理理解、实时交互的能力。
下一个十年,空间智能将引爆AI实体化寒武纪大爆发 。中国技术已率先起跑,以自主创新、硬核落地、全球引领的姿态,定义AI与物理世界融合的新未来。
北京黎阳之光------让AI看懂世界,让智能扎根实体。