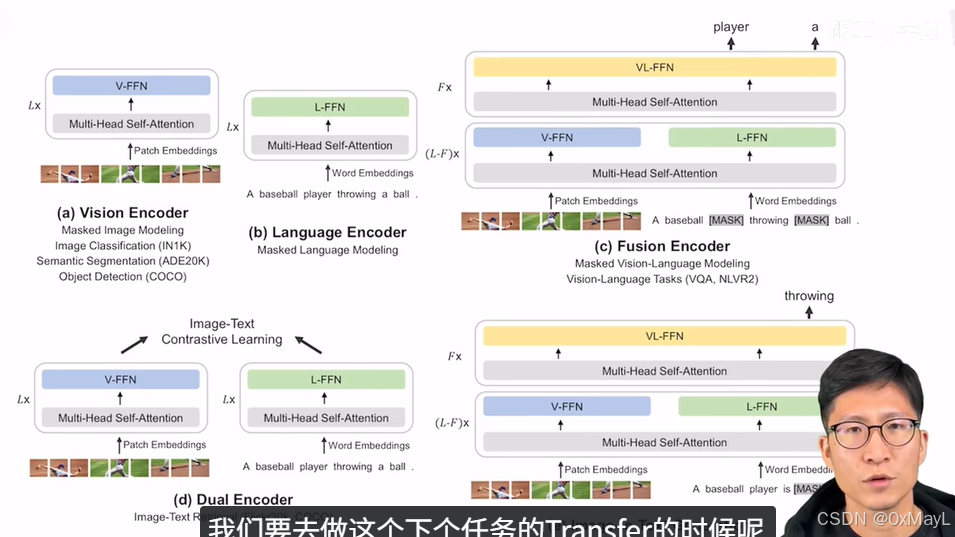
ALBEF:ALign BEfore Fusion
- 动机:预训练的视觉特征和文本特征一开始间隔很远,不利于在最后多模态的编码器进行学习(对齐)。
- 模型本质上:就是CLIP的模型,但是为了保留一个多模态的编码器,因此将BERT的模型拆分成文本和多模态编码器(使用交叉注意力对齐)。
- 三种损失:图文对比损失,图文匹配损失,语言模型损失
- 图文匹配损失:给定图像和文本,输出一个二分类值,表示是否匹配。这一步通过利用对比损失构造最难样本进行加速。
- 语言模型损失:给定图像和掩码后的文本,输出掩码处的文本 。
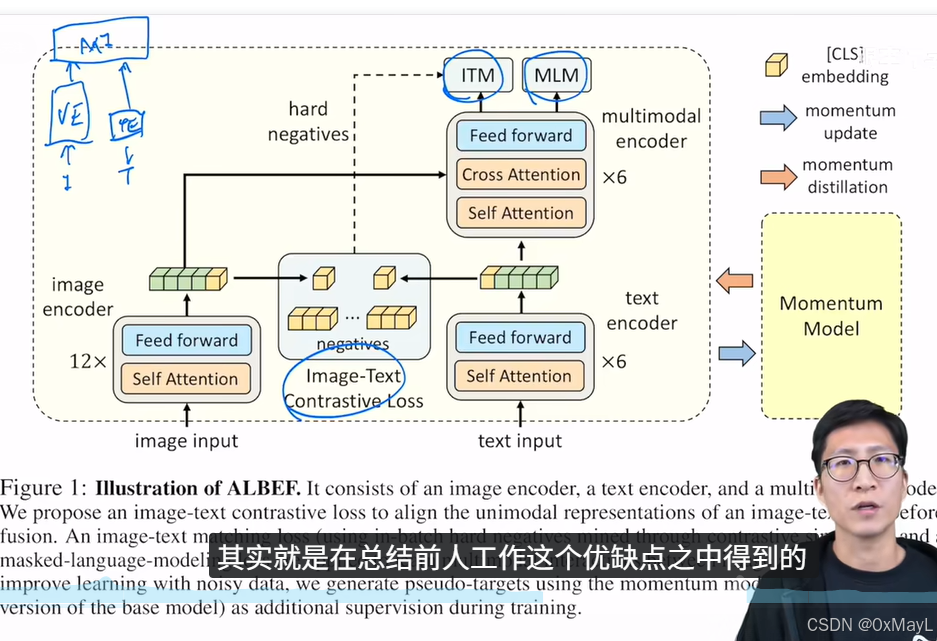
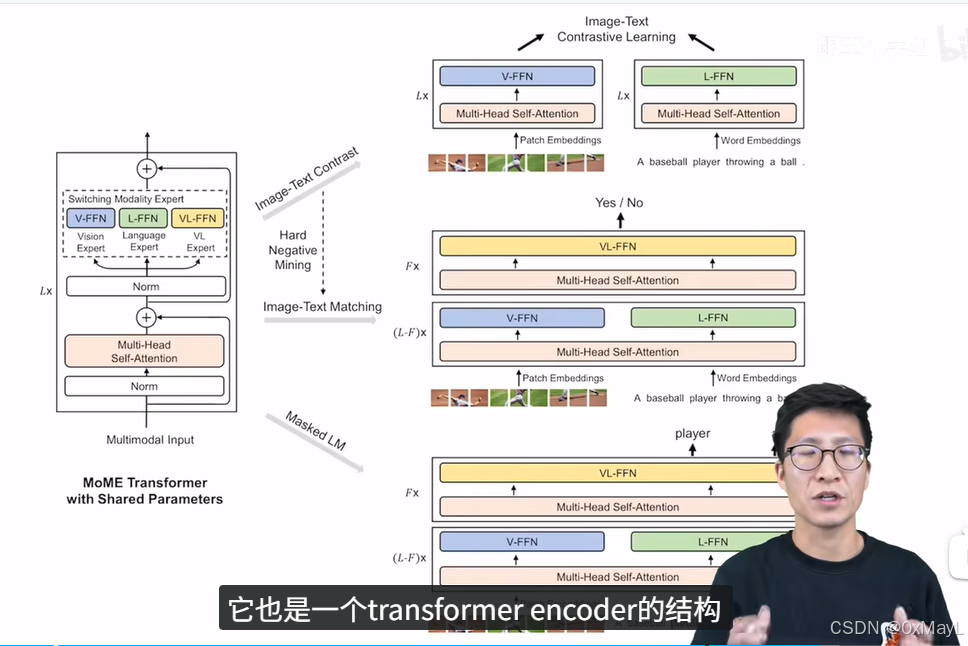
VLMO
- 动机:同一双塔模型(CLIP,视觉和文本编码器完全独立且分开);单塔模型(有一个多模态编码器,推理速度)
- 模型:MOE的架构,只不过MOE换成模态的专家FFN,有一个负责模态融合FFN(VL-FFN)
- 采用共享注意力权重,分阶段训练单一模态,多模态的训练方式。

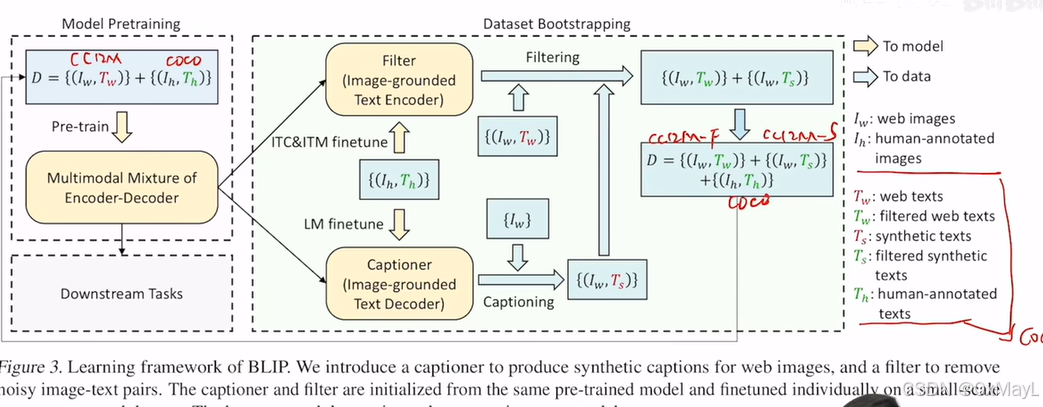
BLIP
- 动机:之前工作不能直接实现 的多模态的文本生成(只有解码器),且数据大多数存在图文不匹配问题。
- 模型:借鉴了VLMO的思路,多一个文本模态的解码器,不同模态的编码器架构有一点不同,但是关键是共享大多数参数 。
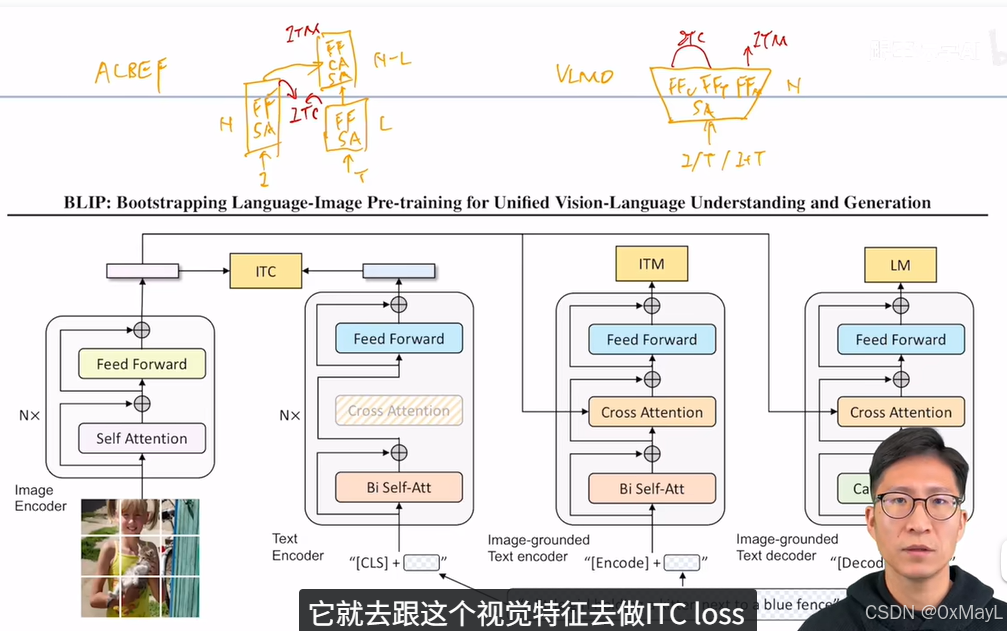
- 自举的方式筛选和增强数据。
BEIT-3
- 动机:利用掩码语言损失来直接进行损失计算 。同一个多个模态间的计算。