一句话总结
GRPO 只知道组内谁好谁坏,但丢失了排序结构。LamPO 改用两两对比的方式保留了这一信息,在各基准上一致超越了 GRPO 及其变体,并且不引入显著额外开销
- 论文标题:LamPO: A Lambda Style Policy Optimization for Reasoning Language Models
- 论文地址 :https://arxiv.org/pdf/2605.21235v1
- 作者背景:Facebook、密歇根大学、内基梅隆大学、密西西比州立大学 等
一、动机:GRPO 的均值陷阱
用强化学习提升大模型推理能力已经是主流范式。典型的流程是对同一个问题采样一组回答,用可验证的奖励(比如数学题的正确性)来优化策略。GRPO 是目前最流行的 critic-free 方法 ------ 不需要训练价值网络,只需要在组内做 z-score 归一化就能得到优势估计
但 GRPO 有一个结构性缺陷:它把整组响应压缩成两个标量(均值 μ 和标准差 σ),每个响应的优势只取决于它偏离均值多远
这意味着:
- 一个 "差一步就对" 的响应和一个 "完全跑偏" 的响应,只要奖励相同(比如都是 0),在 GRPO 眼里完全等价
- 组内响应之间 "谁比谁好、好多少" 的排序信息被彻底丢弃
在稀疏二值奖励下(对/错),这个问题尤其严重,大量错误响应拿到相同的 0 分,GRPO 无法区分它们的质量差异
二、解决方案
2.1 成对分解优势(PDA)
针对上述问题,作者提出了 LamPO(Lambda-Style Policy Optimization),它的解法很直觉:既然丢失了排序信息,那就别压缩成标量了,直接成对比较各个采样结果
对组内每个响应 o_i,LamPO 不再算它和均值的偏差,而是把它和组内所有其他响应逐一比较,汇总所有成对奖励差。优势估计的计算过程是:
- 对响应 o_i,遍历组内所有其他响应 o_j
- 计算两者的奖励差 R(o_i) - R(o_j)
- 乘以一个 "置信度权重" 后求平均
置信度权重的设计很巧妙:它是两个响应在旧策略下对数概率差的 sigmoid
如果模型当前更偏好 o_i(对数概率更高),那么 o_i vs o_j 这对比较就获得更高的权重,相当于让模型在有把握的方向上学得更用力。这个灵感来自信息检索领域的 LambdaRank ------ 这也是本文方法名称的来源
温度参数 τ 控制权重的锐度:
- τ 大时权重趋于均匀(接近 GRPO 的均值行为)
- τ 小时权重更极端,只关注少数几对比较
将组内平均换成两两比较,看起来会严重加大计算开销,因为后者是平方复杂度的操作。但好在 GRPO 中的 Group 都不大,通常只有 8~16,O(G²) 次成对比较的额外开销可以忽略不记
2.2 参考答案利用
纯正确性奖励是二值的(对/错),信号太稀疏。当训练集有参考解答时,LamPO 额外加一个 ROUGE-L F1 作为辅助奖励(生成结果和参考答案的字面重叠度)
最终奖励 = 正确性奖励 + λ_sem × ROUGE-L 奖励
这不是用 ROUGE-L 替代正确性判断,只是在 "全错" 的组里提供更细粒度的区分信号。消融实验显示去掉它会掉约 1.3 分,说明在稀疏奖励场景下确实有帮助,但核心改进来自 PDA 本身
三、实验结果
3.1 主结果
三个模型家族(Qwen3-1.7B、Qwen3-4B、Phi-4-mini),四个推理基准(AIME24、AIME25、MATH-500、GPQA-Diamond)。
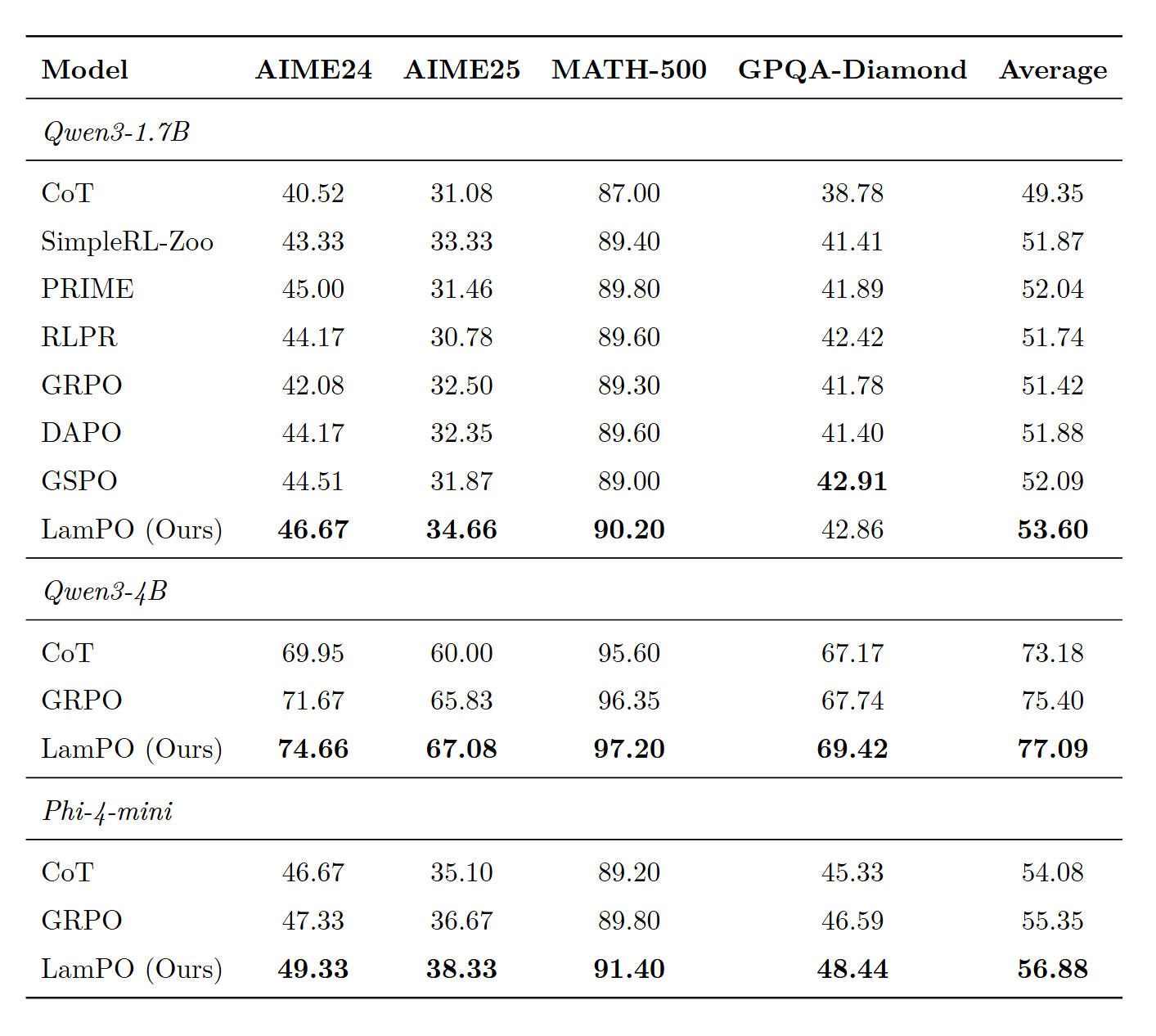
以 Qwen3-1.7B 模型为例,LamPO 在 AIME24 上比 GRPO 提升 4.59 分,比次优方法(GSPO)提升 2.16 分。竞赛数学题上的提升最明显,这正是 "部分正确响应" 最有价值的场景。其他模型上也有类似结论
3.2 超参数
对于两个超参数,作者的测试结果如下
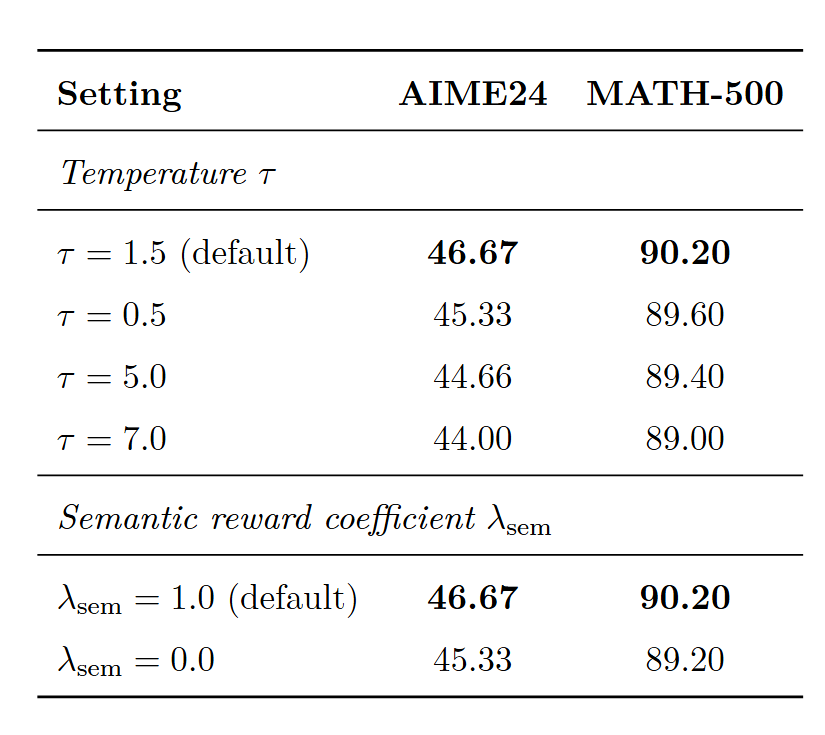
τ 太小使权重过于敏感,太大则抹平了成对区分度;去掉 ROUGE-L 辅助奖励掉约 1.3 分,说明 PDA 是主要收益来源
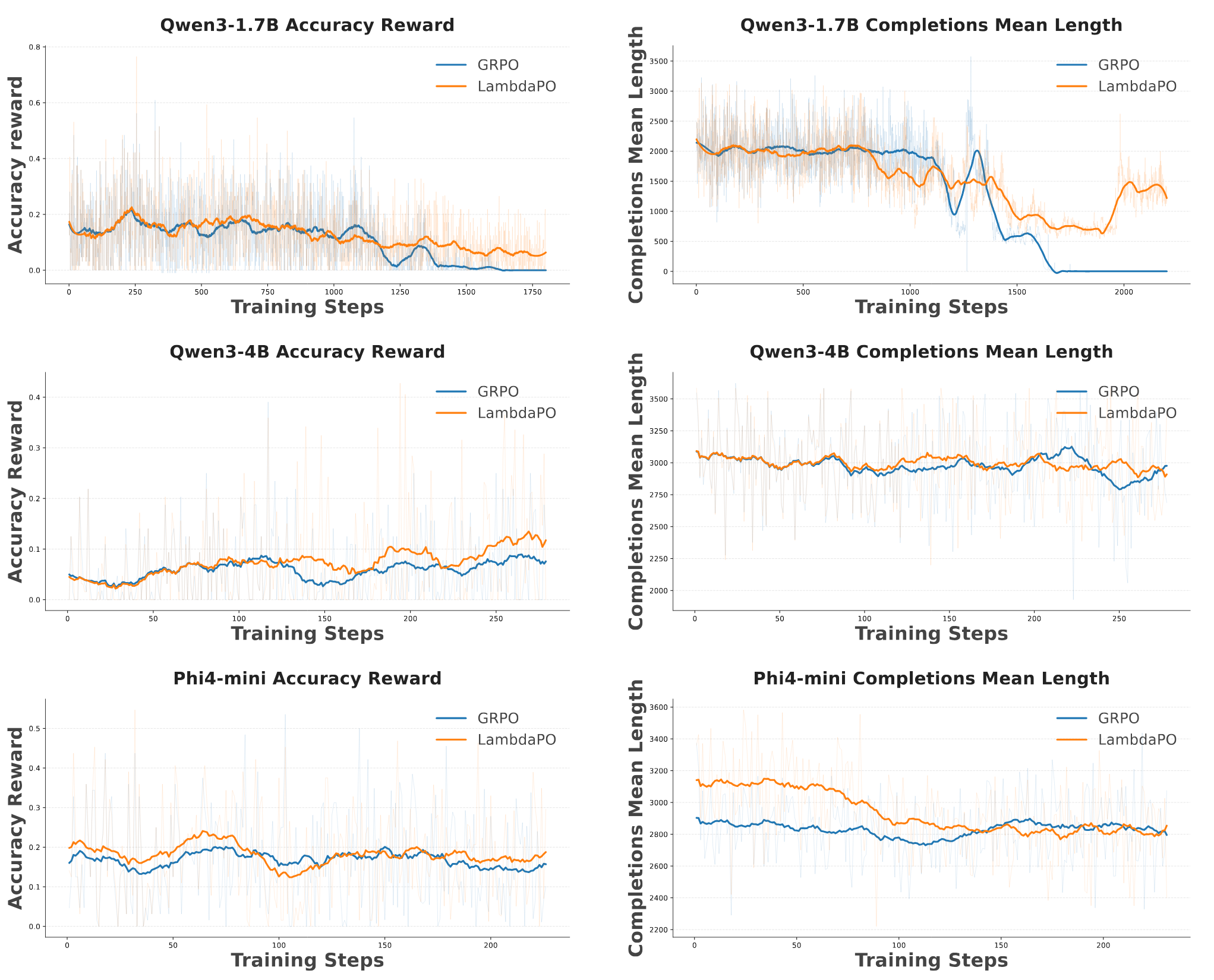
3.3 训练动态
训练曲线显示 LamPO 的奖励提升更平滑,生成长度更稳定。成对比较提供的梯度信号比标量偏差更结构化,减少了因 "组统计量波动" 导致的训练震荡
四、局限性
此方法依赖可靠的奖励信号,如果奖励模型本身有噪声,成对差异可能放大奖励误差