论文信息
- 标题:Inner Monologue: Embodied Reasoning through Planning with Language Models
- 会议:arXiv 2022
- 单位:谷歌机器人部门
- 代码:https://innermonologue.github.io
- 论文:https://arxiv.org/pdf/2207.05608
引言:机器人也能"三思而后行"
想象一下,你让机器人去厨房拿一瓶可乐。传统的机器人会怎么做?它会生成一个僵硬的计划:1. 走到厨房 2. 拿起可乐 3. 拿给你。然后就一条路走到黑------如果可乐不在桌子上,它会傻站在那里;如果第一次没拿起来,它会直接放弃;如果冰箱里只有雪碧,它完全不知道该怎么办。
但人类会怎么做?我们会有"内心独白":
"可乐不在桌子上?那看看冰箱里有没有。"
"第一次没拿起来?再试一次。"
"冰箱里只有雪碧?问问用户要不要换雪碧。"
这就是谷歌机器人团队在2022年提出的Inner Monologue(内心独白)的核心思想:让机器人也拥有这种"内心独白"能力,通过自然语言反馈形成闭环,根据环境变化动态调整计划。
之前的工作比如SayCan已经证明了大语言模型(LLM)可以作为机器人的高层规划器,但它们都是开环的------生成计划后就不管执行结果了,一旦中间出问题,整个任务就失败了。而Inner Monologue通过引入三种自然语言反馈源,让LLM能够实时感知环境变化,进行重试、重规划甚至询问用户,大大提升了机器人在复杂动态环境中的鲁棒性。
一、Inner Monologue的核心设计
Inner Monologue的整体框架如图1所示。它的核心思想非常简单:把所有的环境反馈都转换成自然语言,然后和之前的对话历史一起输入给LLM,让LLM根据完整的上下文生成下一步的动作。
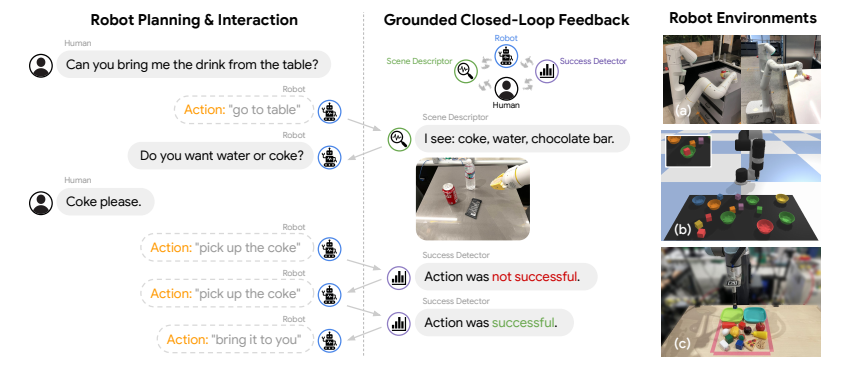
图1 Inner Monologue的整体框架(来源:论文Figure1)
从图1可以看到,整个系统由三个核心部分组成:
- 大语言模型(LLM):作为高层规划器,负责理解人类指令、生成动作计划、处理环境反馈
- 感知模块:负责将视觉信息转换成自然语言反馈,比如"我看到了可乐和雪碧"、"动作执行失败"
- 机器人技能库:包含一系列预训练的低级别技能,比如"走到桌子"、"拿起可乐",每个技能都有对应的自然语言描述
1.1 问题陈述
我们的目标是让一个具身机器人执行人类给出的自然语言指令iii。机器人只能执行技能库Π\PiΠ中的预训练技能πk\pi_kπk,每个技能都有对应的自然语言描述ℓk\ell_kℓk。规划器(也就是LLM)需要找到一个技能序列来完成指令iii。同时,规划器可以获取环境的自然语言反馈ooo,比如成功检测、场景描述、人类反馈等。我们的目标是研究LLM如何利用这些反馈来形成闭环,提升规划的鲁棒性。
1.2 三种反馈源
Inner Monologue引入了三种不同类型的自然语言反馈,如图2所示:

图2 三种类型的自然语言反馈(来源:论文Figure2)
(1)成功检测(Success Detection)
这是最基本的反馈,告诉LLM上一个动作是否成功执行。比如"动作执行成功"或"动作执行失败"。
通俗解释:这就像你做完一件事后,自己判断有没有做好。如果没做好,就再试一次。
(2)被动场景描述(Passive Scene Description)
在每一步动作执行后,自动向LLM提供当前场景的语义信息。比如"场景:桌子上有可乐、雪碧和巧克力"。
通俗解释:这就像你环顾四周,告诉自己现在周围有什么东西。
(3)主动场景描述(Active Scene Description)
LLM可以主动向环境或人类提问,获取需要的信息。比如"你想要可乐还是雪碧?",然后根据回答调整计划。
通俗解释:这就像你遇到不确定的事情时,主动问别人的意见。
1.3 闭环规划流程
Inner Monologue的完整规划流程是一个完美的闭环,和人类的思考过程几乎一模一样:
- 接收人类指令
- LLM根据指令和当前上下文生成下一步动作
- 机器人执行这个动作
- 感知模块生成自然语言反馈
- 将反馈添加到上下文中
- 回到步骤2,直到任务完成
二、惊人的实验结果
研究人员在三个完全不同的环境中测试了Inner Monologue的性能,结果都非常惊艳。
2.1 模拟桌面重排任务
第一个实验是在Ravens模拟环境中进行的桌面重排任务,比如"把所有方块放到不匹配颜色的碗里"。实验结果如表1所示:
表1 模拟桌面重排任务的成功率(来源:论文Table1)
| 任务类型 | CLIPort | CLIPort+oracle | Object+LLM | Object+Success | Object+Scene |
|---|---|---|---|---|---|
| 见过的任务 | 24.0% | 74.0% | 80.0% | 90.0% | 94.0% |
| 没见过的任务 | 0.0% | 0.0% | 20.0% | 70.0% | 86.0% |
结果分析:
- 传统的CLIPort在没见过的任务上成功率为0,完全无法泛化
- 只加入物体识别(Object+LLM),未见任务成功率提升到20%
- 加入成功检测(Object+Success),成功率飙升到70%
- 再加入任务进度场景描述(Object+Scene),成功率达到了惊人的86%!
这充分证明了闭环反馈的重要性。特别是在未见任务上,Inner Monologue的泛化能力远超传统方法。
2.2 真实桌面重排任务
第二个实验是在真实的UR5e机器人上进行的桌面重排任务,包括3块积木堆叠和食物/调味品分类。实验结果如表2所示:
表2 真实桌面重排任务的成功率(来源:论文Table2)
| 任务 | Object LLM | Object | Success | Object+Success |
|---|---|---|---|---|
| 完成3块积木堆叠 | 20% | 40% | 40% | 100% |
| 分类水果和瓶子 | 20% | 50% | 40% | 80% |
| 平均 | 20% | 45% | 40% | 90% |
结果分析:
- 开环的Object LLM平均成功率只有20%
- 单独加入物体识别或成功检测,成功率提升到40-45%
- 同时加入两种反馈,平均成功率达到了90%!
在真实环境中,由于感知噪声和执行误差,开环方法的表现非常差。而Inner Monologue通过闭环反馈,能够自动重试失败的动作,大大提升了鲁棒性。
2.3 真实厨房移动操作任务
第三个实验是在真实的办公室厨房中进行的移动操作任务,使用的是谷歌的Everyday Robots机器人。这个实验对比了Inner Monologue和之前的SayCan方法,结果如表3所示:
表3 真实厨房移动操作任务的成功率(来源:论文Table3)
| 方法 | 无干扰 | 有干扰 |
|---|---|---|
| SayCan | 65% | 0% |
| Inner Monologue (w/ Success) | 75% | 50% |
| Inner Monologue (w/ Success+Object) | 80% | 75% |
结果分析:
- 在没有干扰的情况下,Inner Monologue已经比SayCan表现更好
- 在有干扰的情况下(比如故意让动作失败),SayCan的成功率直接降到了0%,因为它没有重试机制
- 而Inner Monologue通过成功检测和物体识别反馈,能够自动重试和重规划,成功率仍然保持在75%!
这是最令人震撼的结果。在真实的动态环境中,干扰是不可避免的。开环的SayCan在遇到干扰时完全无能为力,而Inner Monologue却能像人类一样灵活应对。
2.4 令人惊喜的涌现能力
除了基本的重试和重规划能力,Inner Monologue还涌现出了很多论文中没有明确提到的能力,如图5所示:
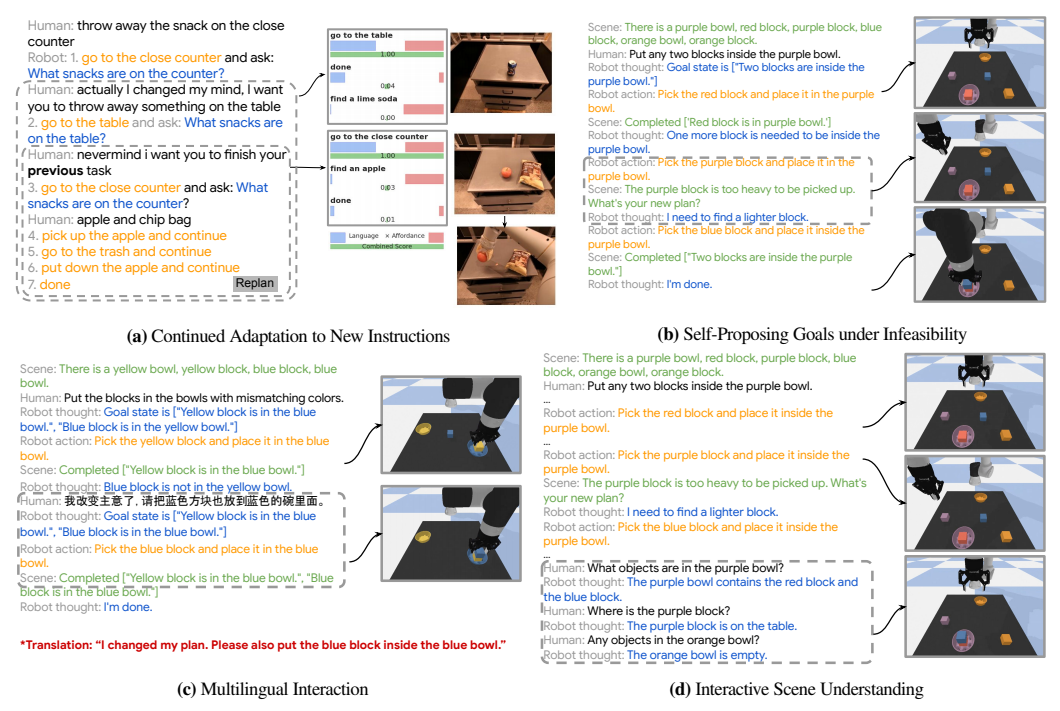
图5 Inner Monologue的涌现能力(来源:论文Figure5)
这些能力完全是大语言模型自带的,不需要任何额外的训练:
- 持续适应新指令:在任务执行过程中,人类可以随时改变目标,机器人会自动调整计划。比如你让机器人拿可乐,中途说"算了,拿雪碧吧",机器人会立刻切换目标。
- 自我提出目标:当原目标无法实现时,机器人会主动提出替代方案。比如"紫色方块太重了,我拿蓝色方块可以吗?"
- 多语言交互:机器人可以理解多种语言的指令,比如中文、英文等。
- 交互式场景理解:任务完成后,你可以问机器人"碗里有什么?",它会根据之前的动作和反馈回答你的问题。
三、核心代码实现(简化版)
下面是一个极度简化的Inner Monologue实现,展示了它的核心闭环逻辑:
python
import openai
import time
class InnerMonologueRobot:
"""
简化版Inner Monologue机器人
核心逻辑:LLM规划 -> 执行动作 -> 获取反馈 -> 更新上下文 -> 重新规划
"""
def __init__(self, openai_api_key):
openai.api_key = openai_api_key
self.context = [] # 对话上下文,存储所有的指令、动作和反馈
# 系统提示词,告诉LLM它的角色和任务
self.system_prompt = """
你是一个机器人规划器。你的任务是根据人类的指令和环境反馈,生成下一步的动作。
你可以执行以下动作:
- go_to(location): 走到指定位置
- pick_up(object): 拿起指定物体
- put_down(object, location): 把物体放到指定位置
- ask(question): 向人类提问
- done(): 任务完成
每次只生成一个动作。如果动作执行失败,重试一次;如果还是失败,考虑其他方案或询问人类。
"""
def add_to_context(self, role, content):
"""添加内容到上下文"""
self.context.append({"role": role, "content": content})
def call_llm(self):
"""调用大语言模型生成下一步动作"""
messages = [{"role": "system", "content": self.system_prompt}] + self.context
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0
)
return response.choices[0].message.content.strip()
def execute_action(self, action):
"""执行动作并返回反馈(这里用模拟的反馈)"""
print(f"执行动作: {action}")
time.sleep(1)
# 模拟动作执行结果,有30%的概率失败
import random
if random.random() < 0.3:
return "动作执行失败"
else:
if action.startswith("go_to"):
location = action.split("(")[1].split(")")[0]
return f"成功到达{location}"
elif action.startswith("pick_up"):
obj = action.split("(")[1].split(")")[0]
return f"成功拿起{obj}"
elif action.startswith("put_down"):
obj, location = action.split("(")[1].split(")")[0].split(", ")
return f"成功把{obj}放到{location}"
elif action.startswith("ask"):
question = action.split("(")[1].split(")")[0]
print(f"机器人问: {question}")
return input("你的回答: ")
elif action == "done()":
return "任务完成"
else:
return "未知动作"
def run(self, instruction):
"""运行机器人,执行给定的指令"""
self.add_to_context("user", instruction)
print(f"收到指令: {instruction}")
while True:
# 调用LLM生成下一步动作
action = self.call_llm()
self.add_to_context("assistant", action)
# 如果动作是done(),任务结束
if action == "done()":
print("任务完成!")
break
# 执行动作并获取反馈
feedback = self.execute_action(action)
self.add_to_context("user", feedback)
print(f"反馈: {feedback}")
# 测试代码
if __name__ == "__main__":
robot = InnerMonologueRobot("你的OpenAI API密钥")
robot.run("帮我从厨房拿一瓶可乐")代码说明:
- 这个简化版实现了Inner Monologue的核心闭环逻辑
- 用OpenAI的GPT-3.5-turbo作为LLM规划器
- 动作执行和反馈是模拟的,实际使用时可以替换成真实的机器人控制代码和感知模块
- 当动作执行失败时,LLM会自动重试,这完全是它自己学会的,不需要任何额外的提示!
四、局限性与未来展望
虽然Inner Monologue取得了非常好的效果,但它仍然有一些局限性:
- 依赖高质量的自然语言反馈:目前的场景描述和成功检测还需要人工标注或专门训练的模型。未来可以用更强大的视觉语言模型(比如GPT-4V)来自动生成高质量的自然语言反馈。
- LLM可能会忽略反馈:在某些情况下,LLM可能会忽略环境反馈,继续执行原来的计划。这可以通过更好的提示词工程或微调来改善。
- 上下文长度限制:目前的LLM上下文长度有限,无法处理非常长的任务。未来随着上下文长度的增加,这个问题会得到解决。
- 低级别技能的限制:机器人的最终表现还是受限于低级别技能的能力。如果低级别技能本身无法完成某个动作,再聪明的规划器也没用。
未来的研究方向包括:
- 用视觉语言模型完全替代人工标注的反馈
- 让LLM能够学习新的低级别技能
- 引入强化学习,让机器人通过试错来改进自己的规划
- 提升LLM的长上下文推理能力
五、总结
Inner Monologue是机器人领域的一个重要突破。它证明了用自然语言作为机器人的"内心独白",可以让大语言模型成为一个强大的闭环规划器。
通过引入简单的自然语言反馈,Inner Monologue解决了之前开环规划方法的鲁棒性问题,让机器人能够在复杂动态的真实环境中灵活应对各种情况。更重要的是,它不需要任何额外的训练,只需要用少量的提示词就能让LLM具备这种能力。
这篇论文向我们展示了通用基础模型在机器人领域的巨大潜力。未来,随着基础模型能力的不断提升,我们离真正的通用机器人会越来越近。