一、目前痛点
很多中小公司在做定时任务时,都会遇到同一批问题:
订单状态变更、日初/日终巡检、历史数据回捞、全量扫描修复......这些任务有一个共同点:数据量大、耗时长、反馈慢。
典型痛点如下:
-
执行时间长,且执行窗口敏感
定时任务一旦跑得久,会占用核心资源,影响在线服务,甚至逼得团队在低峰时段"卡点发版/卡点执行"。
-
数据量大导致内存与超时风险
无论是全量加载还是传统分页,都可能在执行链路里触发 OOM、SQL 慢查、调度超时(如 PowerJob/XXL-Job 超时)等问题。
-
多服务部署下,任务执行效率差
低版本 MySQL 在深分页、复杂扫描上的成本很高,最终常常退化为"单机串行跑批",吞吐差、失败率高。
-
过程不可见、结果不可追
任务有没有执行?执行到哪一步?哪条数据失败?失败原因是什么?往往靠日志 grep,治理成本极高。
-
导出链路脆弱
传统 Excel 导出在大数据量下非常容易撑爆 JVM 堆内存,甚至导致服务雪崩。
二、设计思路:把一个"大任务"拆成三段能力
这套方案不是"再写一个更复杂的定时任务",而是把职责分开:
- SQL 数据分析系统:负责"查哪些数据"
- 异步导出系统:负责"把数据稳定吐出去"
- 批次处理系统:负责"按批次消费 + 记录结果 + 告警反馈"
三者合并后形成新的 TraceBatch 闭环:
任务编排(内网) -> 数据导出(OSS/FTP/SFTP) -> 批次消费(批处理系统) -> 结果追踪与告警
三、系统链路
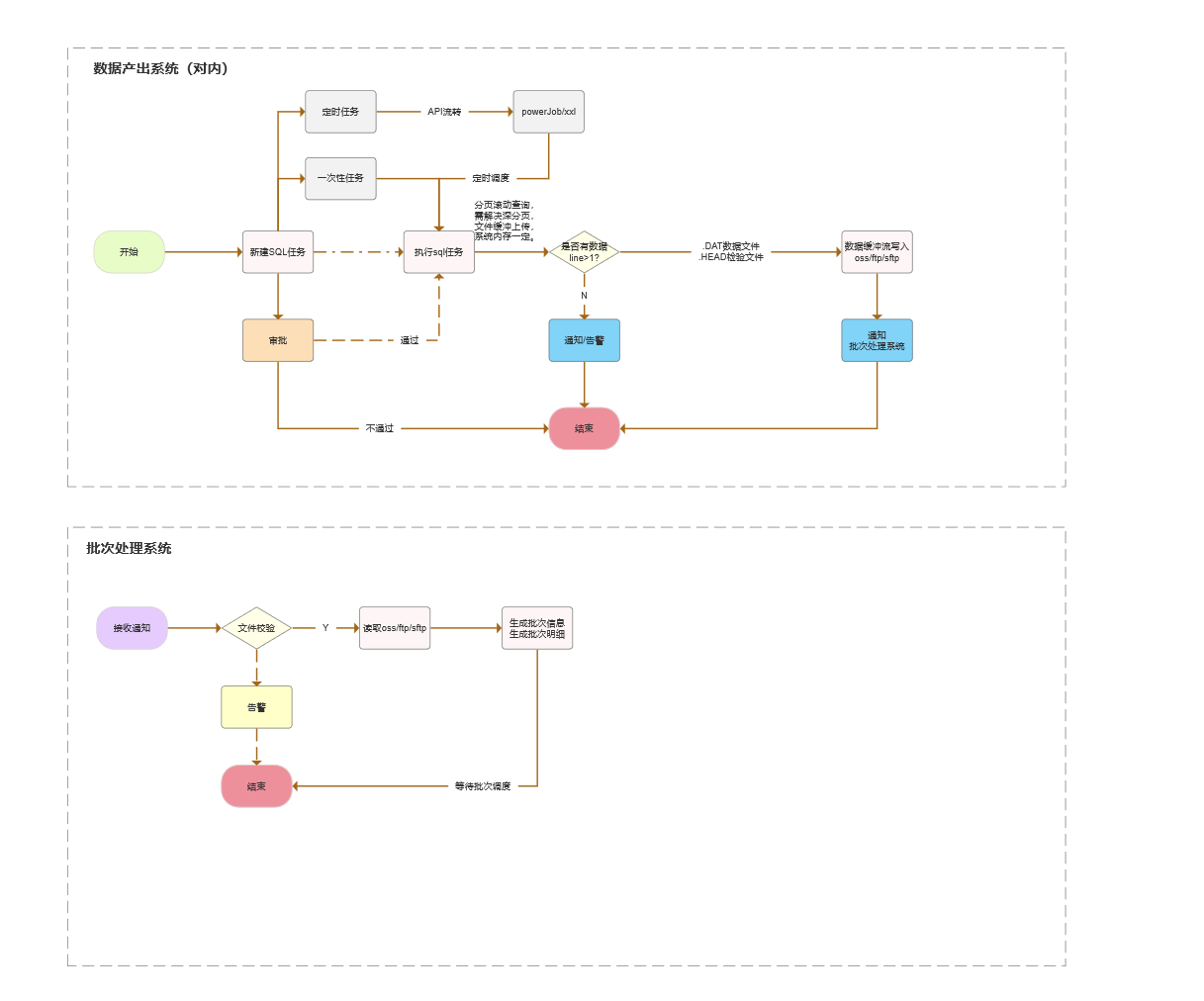
3.1 数据产出系统(对内)
- 发起任务(定时任务 / 一次性任务)。
- 新增 SQL 任务并进入审批流程。
- 审批通过后执行 SQL。
- SQL 结果按固定阈值校验(例如
size > 1进入告警,或进入下一步)。 - 通过异步导出将数据写入 DAT/CSV/TXT,上传到 OSS/FTP/SFTP。
- 通知批次处理系统拉取并消费文件。
- 数据产出系统收到结果回执,任务结束。
3.2 批次处理系统
- 接收通知(消息或回调)。
- 做文件校验(完整性、格式、重复投递)。
- 读取 OSS/FTP/SFTP 文件。
- 生成批次信息与批次明细。
- 按批次消费,逐条处理并记录成功/失败。
- 失败告警 + 回溯查询能力。
- 批次完成后回传执行状态。
一句话总结:
查询与处理解耦,导出与消费解耦,执行与追踪解耦。
四、为什么这套方案有效
4.1 业务与数据处理解耦
业务开发只关心"规则"和"处理动作",不再关心:
- 数据从哪里来(SQL、文件、消息)
- 数据怎么分页
- 失败如何重试
- 结果怎么追踪
结果是:研发效率提升,代码边界清晰,维护成本下降。
4.2 稳定性显著提升
定时任务不再承载完整业务处理链路,只负责:
- 计算查询条件
- 触发导出
- 发出通知
耗时与资源占用明显下降。
异步导出采用流式写出(BufferedWriter / 流式游标),内存基本可控;任务激增时可通过队列削峰。
4.3 可观测、可追溯
批次系统保留:
- 批次主记录(batch)
- 明细记录(item)
- 错误码与失败原因
- 告警通知记录
做到"每条数据可回放、每次任务可复盘"。
4.4 数据可备份、可补偿
导出文件天然形成"冷备份",批次失败时可以二次回放。
相比"任务失败后只能重跑整条 SQL",补偿粒度更细、成本更低。
五、关键实现细节(实战建议)
5.1 SQL 分析层:先做"可执行性"再做"业务性"
建议对 SQL 做三类治理:
- 风险拦截:禁止无条件全表扫描、禁止无索引排序分页、禁止危险 DML。
- 成本评估:执行前估算行数与扫描成本,超阈值走审批。
- 参数化执行:统一模板 + 变量,避免拼接 SQL 注入风险。
5.2 异步导出层:放弃"大而全 Excel",拥抱"流式文本"
大批量导出建议统一 CSV/DAT/TXT:
- 使用游标/分段查询 + 缓冲流逐行写出。
- 单文件过大时自动分片(如 10w 行/片)。
- 统一上传到 OSS/FTP/SFTP,返回文件 URI 与元数据。
好处是:
内存占用常量级、吞吐可预估、失败可重试。
5.3 批次消费层:主表 + 明细表双轨
推荐模型:
batch_task:批次级状态(待处理/处理中/完成/失败)batch_item:明细级状态(成功/失败/重试中)
核心能力:
- 幂等校验(同一业务键不重复处理)
- 明细失败重试(指数退避)
- 失败阈值告警(如失败率 > 5%)
5.4 告警与通知
建议至少包含:
- 任务启动告警(可选)
- 超时告警
- 失败率告警
- 文件校验失败告警
- 批次完成回执(成功/部分失败/失败)
通知渠道可接企业微信、钉钉、飞书机器人。
六、"缺点"与改进方案
缺点 1:批次数据备份会增加存储成本
解决思路:
- 设定分层留档策略:
- 明细数据保留 30~90 天
- 汇总数据保留 180~365 天
- 冷热分层:热库查近 30 天,历史归档到对象存储或冷表。
- 对明细参数(JSON)做压缩存储。
缺点 2:系统链路变长,治理复杂度上升
解决思路:
- 统一任务协议(taskId、batchId、fileUri、checksum)。
- 统一状态机(INIT/RUNNING/SUCCESS/PARTIAL_FAIL/FAIL)。
- 统一可观测面板(QPS、耗时、失败率、积压量)。
七、适用场景
以下场景非常适合 TraceBatch:
- 日初/日终巡检
- 历史订单修复
- 批量状态同步
- 大促后数据回补
- 大体量导出与离线加工
不建议用于:
- 强实时、低延迟(毫秒级)联机交易链路
- 需要强一致事务闭环的核心支付扣减流程