摘要 :开发面向复杂场景的人群密度检测系统对于公共安全预警、城市精细化治理与大型活动管理具有重要价值。本文围绕"YOLOv5 至 YOLOv12 的升级演进"主线,给出一个可落地的人群密度检测工程方案:以 YOLO 系列为核心完成拥挤人群的检测计数与密度评估,并对不同版本模型在同一数据集上的精度与速度表现进行对比分析;系统端采用 Python 3.12 与 PySide6 构建桌面端可视化界面,支持图片/视频/摄像头多源输入、阈值与 IOU 调参、检测框与计数统计展示、结果导出与历史记录管理,同时引入 SQLite 实现用户注册登录与个性化配置持久化。项目配套提供完整训练与推理代码、可复现实验流程、数据集标注与划分说明,以及可直接运行的界面工程,便于读者在真实业务场景中快速复用与二次开发。
讲解视频地址: https://www.bilibili.com/video/BV1K1QuBNEfE/
文章目录
- [1. 前言综述](#1. 前言综述)
- [2. 数据集介绍](#2. 数据集介绍)
- [3. 模型设计与实现](#3. 模型设计与实现)
- [4. 训练策略与模型优化](#4. 训练策略与模型优化)
- [5. 实验与结果分析](#5. 实验与结果分析)
-
- [5.1 实验设计](#5.1 实验设计)
- [5.2 度量指标](#5.2 度量指标)
- [5.3 实验结果分析](#5.3 实验结果分析)
- [6. 系统设计与实现](#6. 系统设计与实现)
-
- [6.1 系统设计思路](#6.1 系统设计思路)
- [6.2 登录与账户管理](#6.2 登录与账户管理)
- [7. 下载链接](#7. 下载链接)
- [8. 参考文献(GB/T 7714)](#8. 参考文献(GB/T 7714))
1. 前言综述
大型公共空间的人群密度检测,直接关系到拥挤踩踏预警、交通疏导、安防巡检与城市应急调度等场景的决策时效与可靠性1。(crad.ict.ac.cn)在工程侧,"密度"往往不仅是离线统计意义上的人数估计,更是一类可被系统实时消费的风险指标:它需要在摄像头多源接入、复杂光照与遮挡、视角透视变化显著的条件下稳定输出,并与阈值告警、区域统计、结果存档与可视化交互形成闭环。老思在做这类系统时会很直观地感受到:算法指标的提升固然重要,但推理延迟、误检漏检的代价、以及部署后的可解释性与可维护性,往往决定了方案能否真正落地。
围绕"人群密度"这一任务,早期研究多采用回归或密度图思想来规避逐人检测的困难,其中代表性工作提出从点标注学习到密度映射与计数的监督框架,为后续密度估计范式奠定了基础2。(Oxford University Research Archive)随后,卷积网络通过多列结构显式建模尺度变化,使得单幅图像计数在公开数据集上取得系统性突破3。(CV Foundation)在更拥挤的场景中,采用空洞卷积扩展感受野并保持分辨率的网络进一步提升了密度图质量与计数精度4。(CVF Open Access)随着模型能力提升,数据集规模与覆盖面的瓶颈开始凸显,面向高密度与定位需求构建的大规模基准推动了"计数---定位"一体化评测,并暴露出极端密度、强遮挡与跨域泛化等难题5。(Researchr)与此同时,包含恶劣天气与多样干扰因素的无约束数据集进一步强调了真实世界分布的复杂性,使得鲁棒性与域偏移成为必须正视的问题6。(CVF Open Access)近两三年,Transformer 结构被用于引入更强的全局上下文建模能力,并在多数据集上展示了对长程依赖与密度细节的潜在优势7。(Springer)
为便于把上述研究脉络与"系统落地诉求"对齐,表1概括了典型范式在数据集侧与工程侧的关键差异(同一任务在论文评测与应用部署中的目标并不完全一致)。
表1 人群密度/计数相关代表性研究脉络与特点概览
| 范式 | 代表工作 | 典型数据集/评测侧重点 | 优势 | 主要局限 |
|---|---|---|---|---|
| 点监督到密度映射 | Lempitsky & Zisserman2 | 以点标注为核心的计数误差 | 避开逐人检测,适合极密集场景 | 难以直接给出可视化框与实例级结果 |
| 多尺度CNN密度图 | MCNN3 | ShanghaiTech 等计数基准 | 显式尺度建模,改进明显 | 结构相对重,实时性与泛化仍受限 |
| 空洞卷积密度图 | CSRNet4 | 拥挤场景密度图质量 | 感受野大、训练相对稳定 | 对极端域偏移仍敏感 |
| 大规模计数+定位基准 | NWPU-Crowd5 | 高密度范围、计数与定位 | 推动计数与定位统一评测 | 标注与训练成本高,部署域差异大 |
| 无约束复杂数据集 | JHU-CROWD6 | 天气退化、干扰样本 | 强化真实分布鲁棒性需求 | 仅计数范式难满足工程交互需求 |
| Transformer密度估计 | CounTr[7](https://link.springer.com/chapter/10.1007/978-3-031-25075-0_16 "CounTr: An End-to-End Transformer Approach for Crowd Counting and Density Estimation | Springer Nature Link") | 多数据集SOTA对比 | 全局上下文建模更强 |
与密度图回归路线相比,目标检测路线在工程端有更直接的产出形态:边界框与置信度可用于区域计数、密度分级、可视化审计与结果留存,而这些正是"完整系统"不可或缺的接口。围绕实时检测的主线,Ultralytics 在 YOLOv5 上通过工程化训练与推理栈沉淀了高可用实现,使其成为工业界与学术界常用的起点8。(Zenodo)面向产业部署,YOLOv6 从硬件友好与结构效率角度系统梳理组件设计,强调在速度---精度边界上的可控性9。(arXiv)在此基础上,YOLOv7 进一步提出可训练的"bag-of-freebies"思路,在不增加推理成本的前提下提升精度并扩大适用速度区间10。(CVF Open Access)YOLOv8 则以更通用的任务接口与更新的实现细节增强易用性,成为近年来工程侧迁移与二次开发的高频选择11。(Ultralytics Docs)在"从零训练""梯度流动与特征聚合"等关键问题上,YOLOv9 引入可编程梯度信息等设计以提升训练有效性与性能上限12。(arXiv)进一步地,YOLOv10 针对端到端部署中 NMS 带来的后处理瓶颈提出无NMS训练与结构层面的效率审视,强化了低延迟推理的工程价值13。(arXiv)在 Ultralytics 的产品化迭代线中,YOLO11 继续强调在参数量下降的同时获得精度收益,并保持跨环境部署的便利性14。(Ultralytics Docs)最新的 YOLOv12 则把注意力机制更"正面"地纳入实时检测框架,试图在速度可比的前提下获取注意力建模带来的精度增益15。(arXiv)
即便如此,把 YOLO 系列用于"人群密度检测系统"仍存在一组典型技术矛盾:其一,极密集场景下实例间高度重叠,检测范式天然面临召回下降与重复框并存的问题,密度分级需要对时序统计与空间聚合做稳健化处理;其二,透视畸变导致同一像素尺度对应的真实面积差异巨大,若缺乏场景标定或自适应权重,简单的"人数/面积"会产生不可控偏差;其三,现实数据分布与公开基准差异显著,摄像头高度、焦距、压缩伪影与夜间噪声都会放大域偏移;其四,系统侧还要同时满足多源输入切换、GUI 线程安全与推理线程解耦、结果持久化与可追溯等工程约束,任何单点不稳定都会在交互链路中被放大。
因此,本文(也就是老思这篇博客)的主要贡献可以概括为:面向人群密度检测这一实际需求,基于 YOLOv5--YOLOv12 进行统一训练与评测,对关键版本在精度、速度与部署便利性上的差异做可复现实验对比;围绕场景构建并标注专用数据集,完成清洗、增强与训练/验证/测试划分;同时以 PySide6 搭建完整桌面端系统,支持多源输入、结果可视化、统计分析与导出,并提供可直接复用的代码与资源包,方便读者复现与二次开发。
主要功能演示:
1)启动与登录
系统启动后首先进入登录界面,支持"登录/注册/找回或修改密码/更换头像"等基础账户能力;登录成功会自动加载该用户的历史检测记录、上次使用的模型与阈值配置,并进入主界面,保证不同用户的结果与偏好互不干扰。
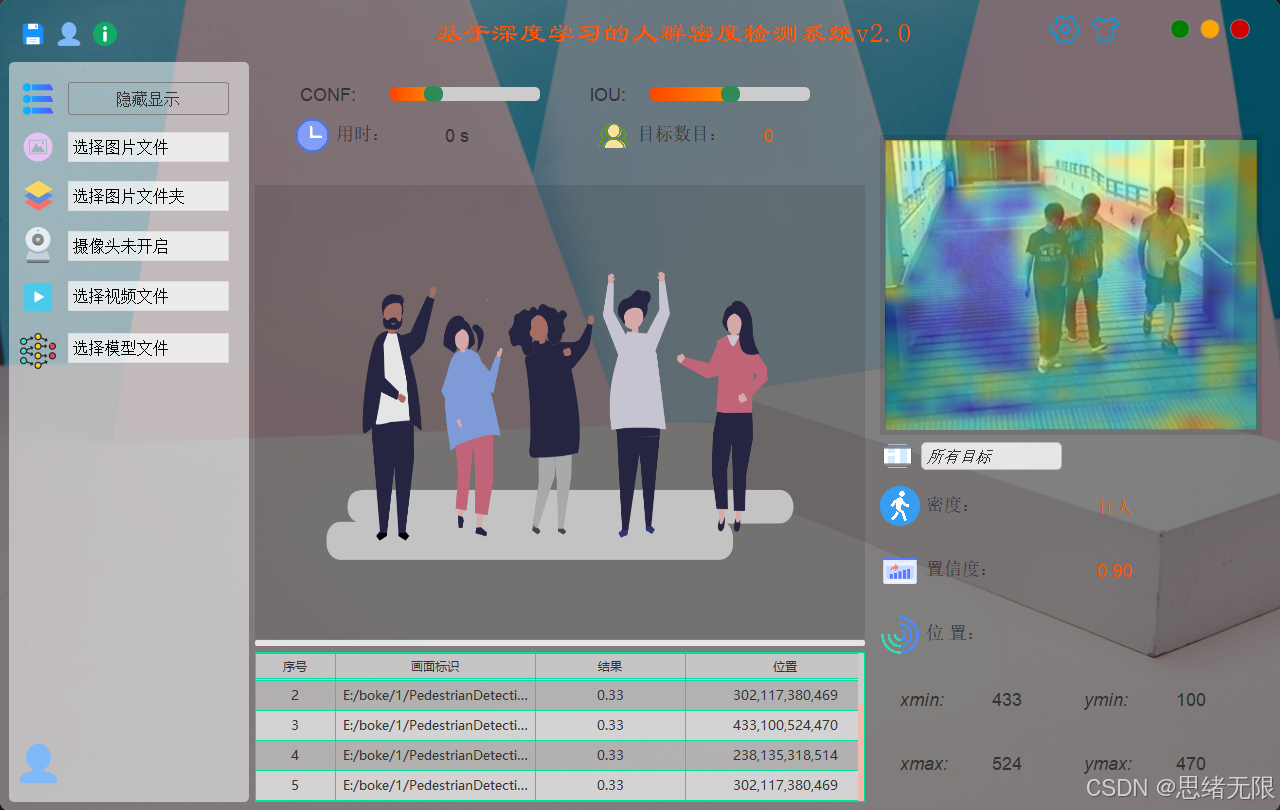
2)多源输入与实时检测(摄像头/视频/图片/文件夹)
主界面提供统一的输入源选择入口,摄像头模式下采用推理线程与界面线程解耦,实时渲染检测框、置信度与人数统计,并给出密度等级或区域密度提示;视频模式支持播放/暂停/进度拖动与逐帧刷新;图片模式用于单张精检;文件夹模式用于批量推理与汇总导出,便于快速生成阶段性统计结果。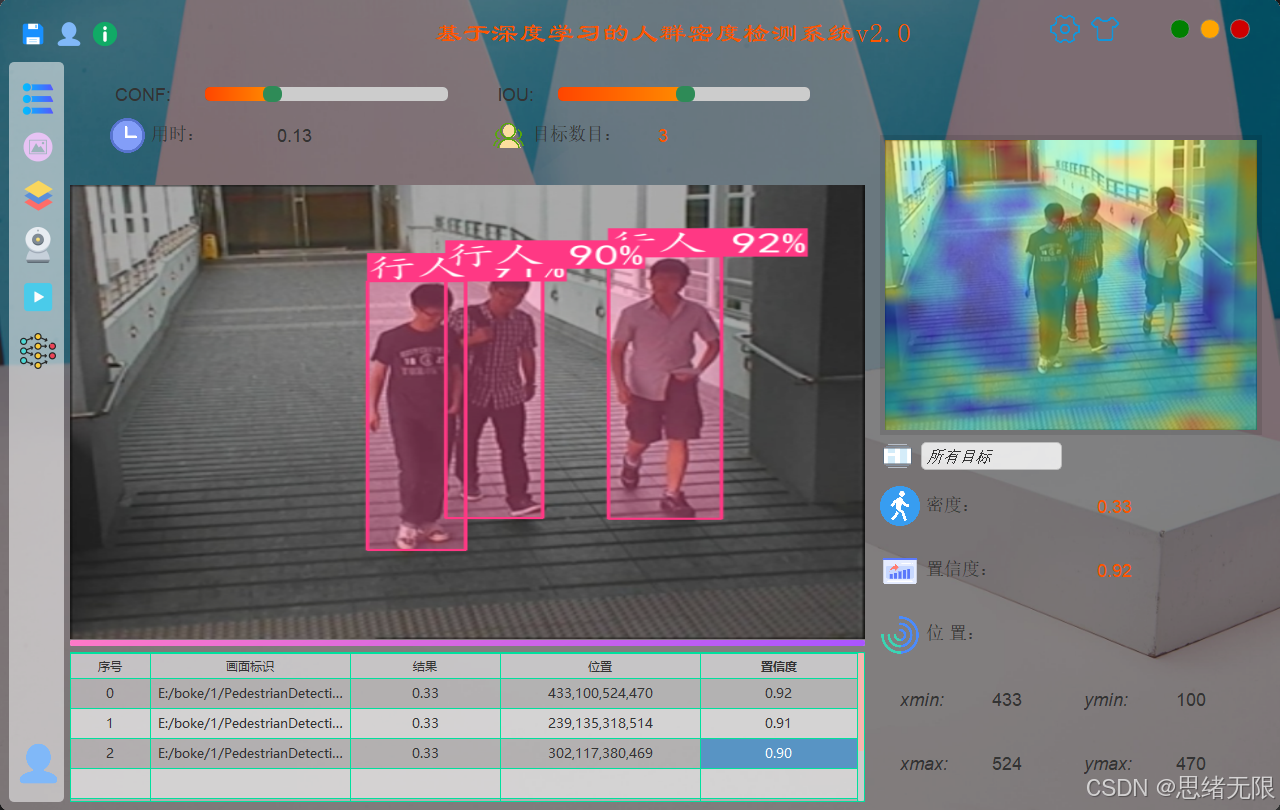
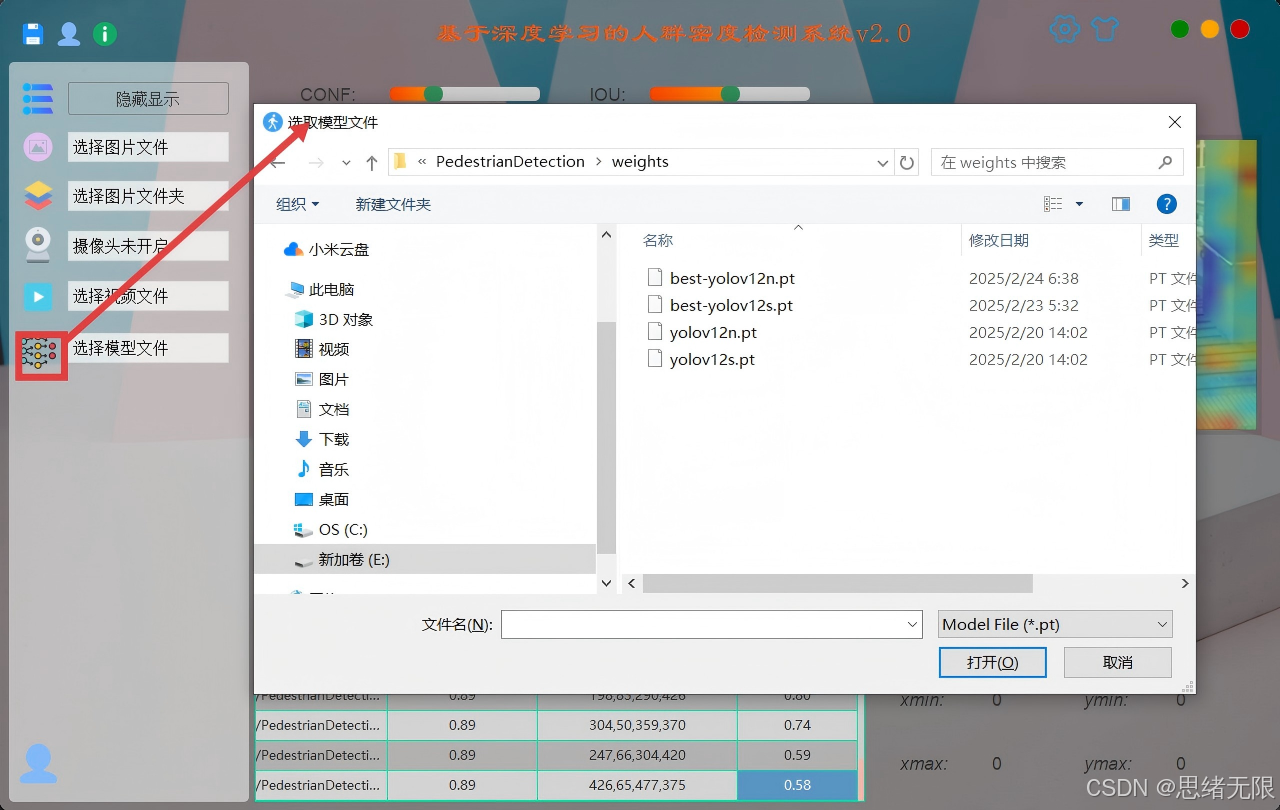
3)模型选择与对比演示
界面内置 YOLOv5--YOLOv12 的权重切换入口(也支持导入自训练权重),可在同一输入源上快速对比不同版本的检测框稳定性、漏检/误检趋势与推理帧率等表现;对比结果可通过日志与截图方式固化,便于形成可复现实验记录与工程选型依据。
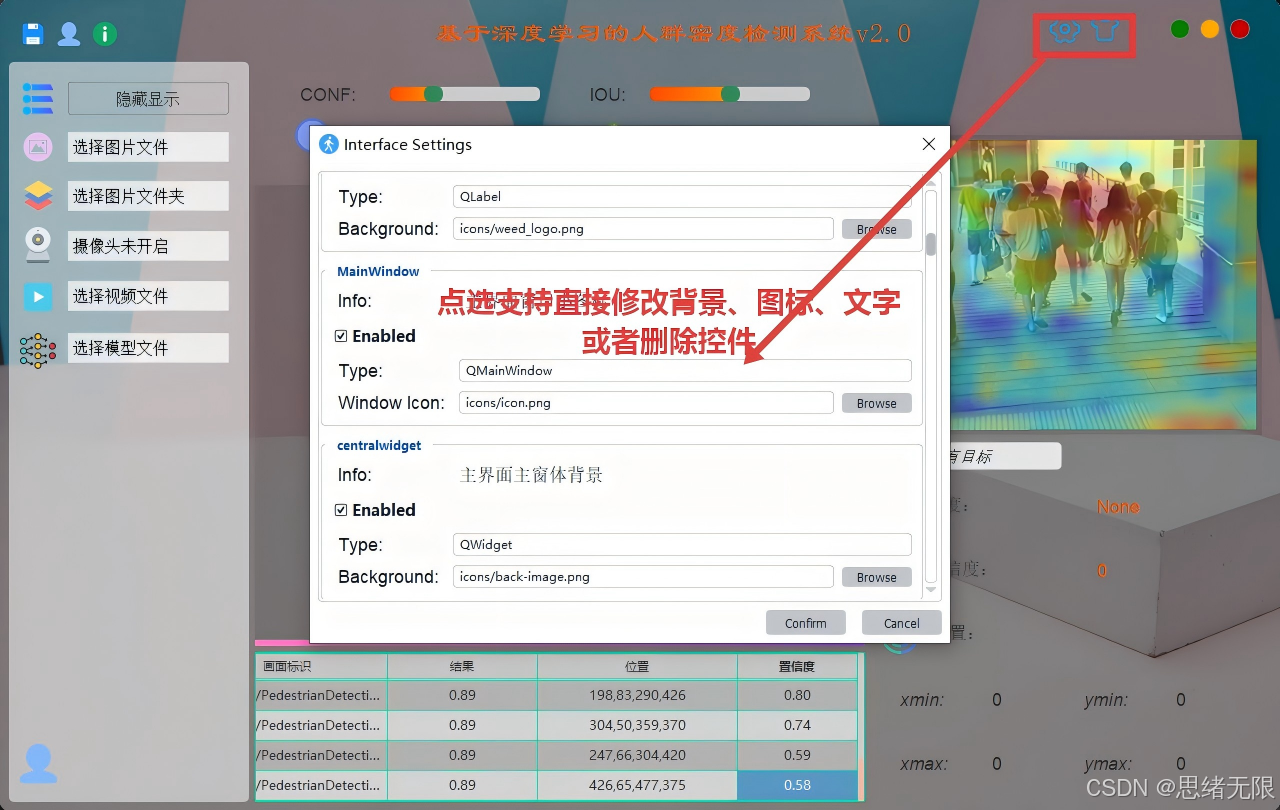
4)主题修改功能
系统提供主题快速切换与自定义能力,包括亮/暗模式、主色调与字体大小、背景图/图标资源替换等;主题配置与用户账户绑定并持久化到 SQLite,在重新登录或重启后自动恢复,确保界面风格与使用习惯一致。
2. 数据集介绍
本项目采用自建的行人检测数据集,用于支撑"检测---计数---密度分级"的人群密度分析链路。数据集共计 10,429 张图像,覆盖室内外多场景与多光照条件,画面中存在典型的遮挡、尺度剧烈变化与透视畸变等现象,这些因素会直接影响密集人群下的漏检与重复检测风险。标注层面仅设置单一目标类别 person(中文映射为"行人"),以便将任务聚焦在复杂背景下的稳健检测与后续密度统计上;全部标注以 YOLO 归一化 TXT 形式存储,适配 Ultralytics 系列训练框架。老思在数据整理阶段会优先保证标签一致性与可训练性:一方面对异常框(越界、面积趋近于 0)进行剔除与修正,另一方面保证同一场景下标注尺度标准尽量统一,从源头降低训练时的噪声梯度。
python
Chinese_name = {'person': "行人"}
从分布特性看,标注实例总量约为 2.0 × 10 4 2.0\times 10^4 2.0×104 量级,且目标框尺度呈明显的"小目标占主导"特征:宽度与高度的联合分布集中在较小范围,符合监控/街景视角下远距离行人占多数的客观规律;同时,框中心点在图像平面上的分布并非均匀,往往在中上区域更为密集,这与固定机位、地平线位置以及人群主要活动带有关。相关性图进一步显示 width 与 height 存在显著耦合,反映了透视与拍摄距离共同导致的尺度变化。训练批次可视化样例也能观察到密集遮挡、边缘截断与复杂背景纹理等困难样本,这些样本对检测器的定位精度与置信度校准提出了更高要求;因此在训练阶段建议采用 Ultralytics 默认的数据增强流程(如 Mosaic、随机仿射、HSV 抖动与随机翻转等),并在后期逐步降低强增强强度,以获得更稳定的收敛与更好的泛化表现。
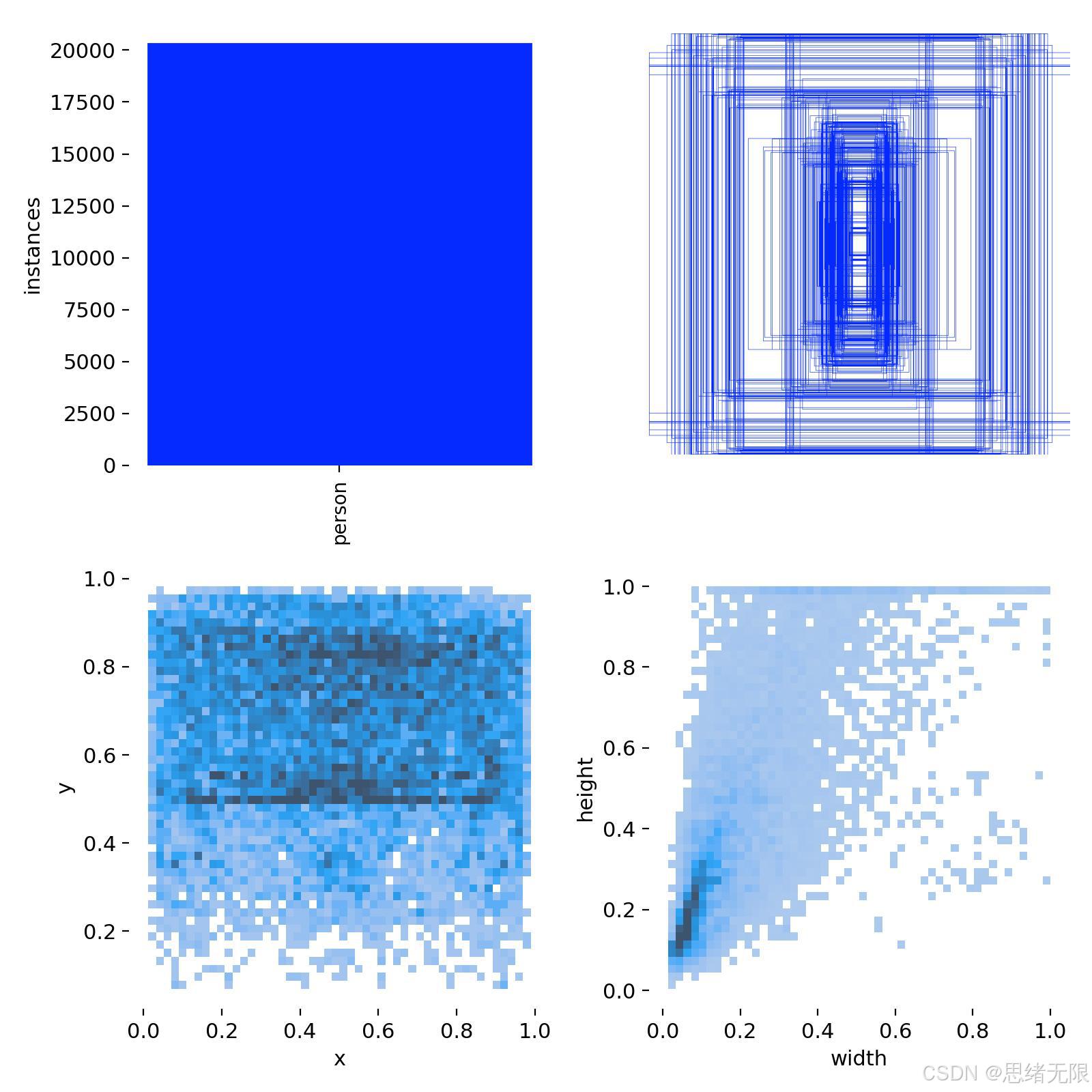
📊 数据集规格说明 (Dataset Specification)
| 维度 | 参数项 | 详细数据 |
|---|---|---|
| 基础信息 | 标注软件 | LabelImg |
| 标注格式 | YOLO TXT (Normalized) | |
| 数量统计 | 训练集 (Train) | 8,091 张 (77.56%) |
| 验证集 (Val) | 1,558 张 (14.94%) | |
| 测试集 (Test) | 780 张 (7.48%) | |
| 总计 (Total) | 10,429 张 | |
| 类别清单 | Class ID: 0 | person(行人) |
| 图像规格 | 输入尺寸 | 640 * 640 |
| 数据来源 | 混合数据集:实景采集 / 公开视频帧 (手动清洗) |
(备注:Chinese_name = { 'person': "行人" },系统界面与导出报表均以"行人"作为展示名称。)
3. 模型设计与实现
人群密度检测在工程侧通常有两条路径:一类方法直接回归密度图并对积分得到人数,优势是在极端拥挤、强遮挡时仍能保持计数稳定,但训练往往依赖点标注或密度图生成策略,且对部署实时性不友好;另一类方法将"密度"转化为"行人目标检测 + 计数/区域统计",以检测框为基本单元完成人数估计与拥挤度分级。本文项目采用后者:将单帧或视频流中的行人检测结果经过阈值筛选与后处理得到集合 B = b i i = 1 N \mathcal{B}={b_i}_{i=1}^{N} B=bii=1N,其中 b i = ( x i , y i , w i , h i , s i ) b_i=(x_i,y_i,w_i,h_i,s_i) bi=(xi,yi,wi,hi,si) 表示边界框与置信度,然后用 N N N 作为人数估计;若需要区域密度,则在给定 ROI 面积 A A A 上定义 ρ = N / A \rho=N/A ρ=N/A,并可对不同 ROI 输出分区热度与拥挤预警。该建模方式与 PySide6 的实时视频显示、交互式阈值调节、结果落库统计天然匹配,且便于在 YOLOv5--YOLOv12 之间做统一推理接口与公平对比。
从基线模型选择角度看,传统分类骨干如 ResNet、MobileNet、EfficientNet 的设计目标偏向全局语义压缩与分类判别,在密集小目标检测中常遇到两点工程矛盾:其一,高下采样比带来小目标信息损失;其二,单尺度语义对遮挡与相邻目标分离不敏感。单阶段检测器的主流做法是保留多尺度特征金字塔并用轻量颈部网络进行跨尺度融合,从而在速度与精度之间取得可部署的均衡。老思在本系统中默认选用 YOLOv12n 作为主模型:它延续 YOLO 的"Backbone--Neck--Head"范式,但将关键表征能力更多交给注意力友好结构(如 Area Attention、R-ELAN 相关聚合与卷积位置感知设计),以改善拥挤场景下的局部辨析能力,同时仍保持实时推理的工程边界。该选择与 Ultralytics 对 YOLO12 的实现与特性描述一致,且便于直接在同一代码框架中切换 YOLOv5/8/10/11 等权重完成对比实验。(Ultralytics Docs)
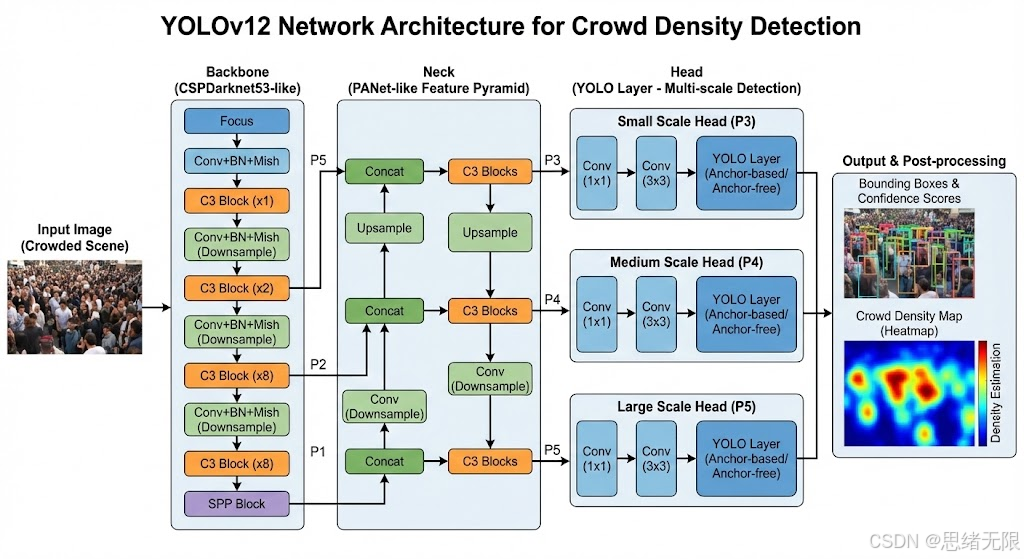
在网络结构层面,YOLO 系列的共性是"多尺度特征 + 检测头预测"。以 YOLOv5 为例,Backbone 常见为 CSPDarknet 变体,Neck 采用 SPPF 与 PAN/FPN 融合,Head 基于多尺度特征图输出分类、置信度与边界框回归;其优势是结构清晰、训练与部署生态成熟,但在行人密集区域容易出现相邻目标框竞争与小目标召回不足。YOLOv8 及其后续版本逐步强调解耦头(分类/回归分支分离)与更简洁的特征聚合单元,以提升收敛稳定性与端到端推理效率;YOLOv10 则进一步讨论 NMS-free 的端到端训练范式,减少后处理开销并降低拥挤场景中 NMS 误抑制带来的漏检风险。(Ultralytics Docs) 进入 YOLOv12,结构演进的核心在于更"注意力友好"的特征建模:文档中强调 Area Attention 将特征图划分为若干区域以降低标准自注意力的计算与访存压力,并可选用 FlashAttention 以优化显存访问;同时引入 R-ELAN 风格的聚合与残差缩放以改善深层网络的优化;并通过 7 × 7 7\times 7 7×7 可分离卷积等"位置感知"设计在不显式引入位置编码的前提下保持空间信息。对于人群密度检测,这类设计的直觉收益在于:一方面扩大有效感受野以捕捉群体结构与遮挡关系,另一方面在局部区域内提升细粒度区分能力,从而更稳健地区分紧邻行人。(Ultralytics Docs)
任务建模与损失函数方面,本项目是单类检测(person/行人),因此分类分支可视为二分类。典型 YOLO 检测训练目标可写为多任务加权和:
L = λ box L ∗ box + λ ∗ cls L ∗ cls + λ ∗ dfl L ∗ dfl , \mathcal{L}=\lambda_{\text{box}}\mathcal{L}*{\text{box}}+\lambda*{\text{cls}}\mathcal{L}*{\text{cls}}+\lambda*{\text{dfl}}\mathcal{L}*{\text{dfl}}, L=λboxL∗box+λ∗clsL∗cls+λ∗dflL∗dfl,
其中 L ∗ box \mathcal{L}*{\text{box}} L∗box 常用 IoU 类损失(如 CIoU/GIoU)刻画框的几何一致性, L ∗ cls \mathcal{L}*{\text{cls}} L∗cls 常用 BCE/CE 处理类别监督,而 L ∗ dfl \mathcal{L}*{\text{dfl}} L∗dfl(若采用分布式回归)用离散分布拟合边界距离以提升定位精度,尤其对小目标与边缘目标更敏感。对于密集行人,后处理阶段的阈值策略同样关键:设置信心阈值 τ \tau τ 与 IoU 阈值 η \eta η,得到最终计数
N = ∑ i 1 ( s i ≥ τ ) ⋅ 1 ( b i 未被抑制于 η ) , N=\sum_i \mathbf{1}(s_i\ge \tau)\cdot \mathbf{1}(b_i\ \text{未被抑制于}\ \eta), N=i∑1(si≥τ)⋅1(bi 未被抑制于 η),
在 UI 中将 τ , η \tau,\eta τ,η 暴露为可调参数,使用户能在"多检(高召回)"与"少误检(高精度)"之间做场景化权衡;若采用 YOLOv10 的端到端输出,则可以弱化或替代传统 NMS,使密集场景下的框竞争更可控。(Ultralytics Docs)
实现层面,本文将"多版本 YOLO 权重的加载、推理与后处理"封装为统一的 Detector,上层 PySide6 只关心输入源(摄像头/视频/图片/文件夹)与输出结果(绘制框、人数统计、可选 ROI 密度)。Ultralytics 文档给出了 YOLO12 的标准调用方式,工程上可将模型文件路径作为动态参数,由 UI 的下拉框或按钮触发切换;推理输出统一转为 boxes/conf/cls 三元组,再在同一套绘制与统计逻辑中复用,从而保证 YOLOv5--YOLOv12 的对比只改变"模型本体",不改变"业务逻辑"。(Ultralytics Docs)
python
# 仅展示核心推理封装思路(PySide6 侧通过信号槽把 frame 传入 infer)
from dataclasses import dataclass
from ultralytics import YOLO
import numpy as np
@dataclass
class DetResult:
boxes_xyxy: np.ndarray # (N, 4)
scores: np.ndarray # (N,)
cls: np.ndarray # (N,)
count: int # N after thresholding
class Detector:
def __init__(self, weight_path: str, device: str = "cuda:0"):
self.device = device
self.load(weight_path)
def load(self, weight_path: str):
self.model = YOLO(weight_path) # yolo5/8/10/11/12 权重在工程中统一管理
# Ultralytics 会在 predict 时自动选择 device,也可在调用时显式指定
def infer(self, frame_bgr: np.ndarray, conf: float = 0.25, iou: float = 0.7) -> DetResult:
preds = self.model.predict(source=frame_bgr, conf=conf, iou=iou, verbose=False)[0]
if preds.boxes is None or len(preds.boxes) == 0:
return DetResult(np.zeros((0, 4)), np.zeros((0,)), np.zeros((0,)), 0)
b = preds.boxes
boxes = b.xyxy.cpu().numpy()
scores = b.conf.cpu().numpy()
cls = b.cls.cpu().numpy()
return DetResult(boxes, scores, cls, int(len(boxes)))4. 训练策略与模型优化
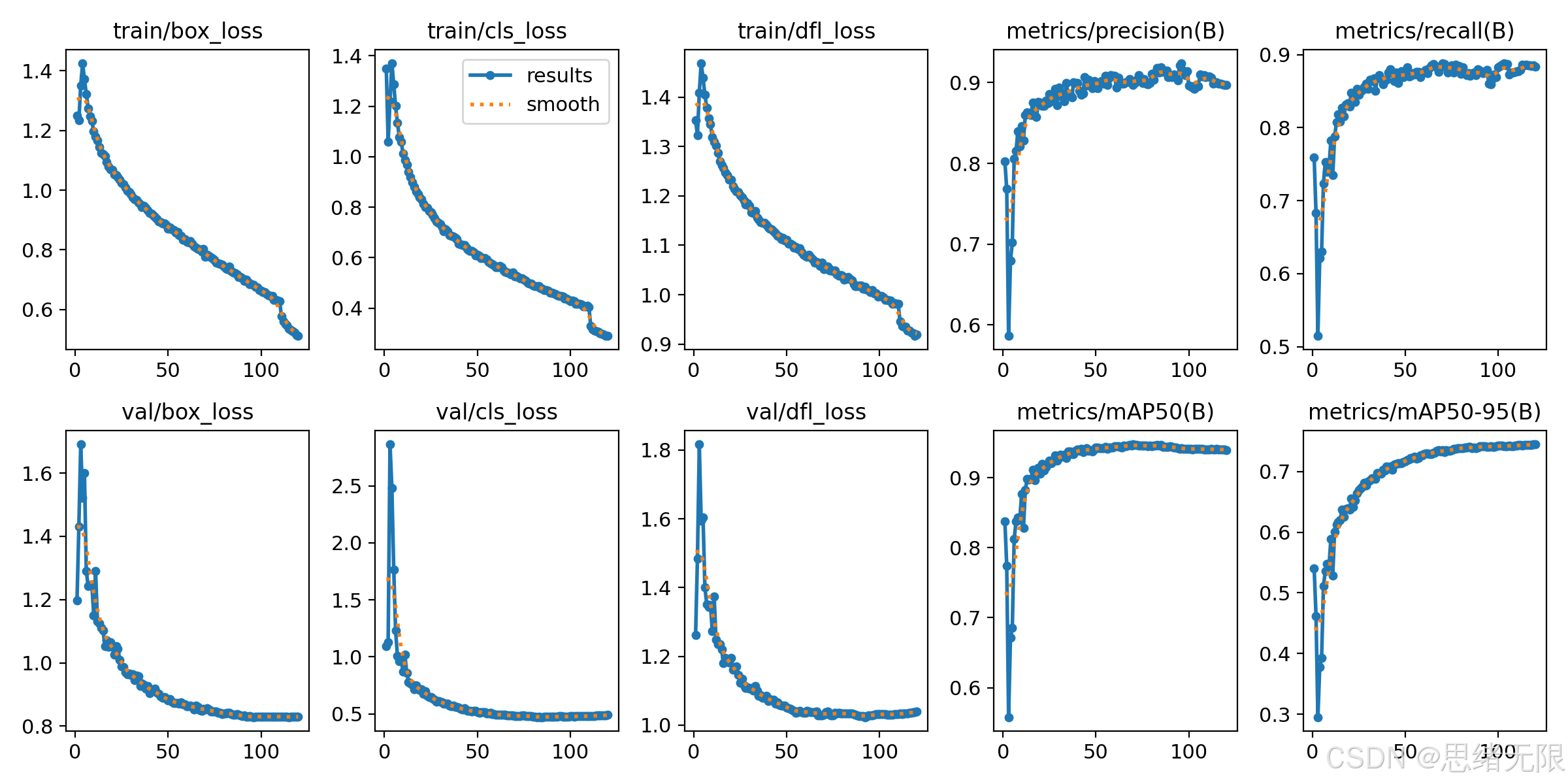
为保证 YOLOv5--YOLOv12 的对比具备可复现性与公平性,老思在训练阶段采用"同数据划分、同输入尺度、同训练轮数与增强策略"的统一设置:所有模型均以 COCO 预训练权重作为初始化(pretrained=True),在自建行人数据集上进行迁移学习与微调。硬件侧默认使用 RTX 4090(24GB)单卡训练,开启 AMP 混合精度以降低显存占用并提升吞吐;数据加载启用多进程 workers 与缓存策略,尽量减少 I/O 对迭代时间的干扰。训练过程中以验证集 mAP@50-95 作为主监控指标,并配合 early stopping(patience=50)避免过拟合拖尾,同时保存 best checkpoint 以便后续导出与系统部署。
超参数层面,输入分辨率固定为 640 × 640 640\times 640 640×640,batch 设为 16,最大训练轮数 120;学习率采用带 warmup 的衰减策略,预热阶段用线性增大稳定梯度尺度,进入主训练后用余弦退火获得更平滑的收敛曲线。若记初始学习率为 η 0 \eta_0 η0,最终学习率比例为 lrf \text{lrf} lrf,则余弦调度可写为
η ( t ) = η 0 ( lrf + 1 − lrf 2 ( 1 + cos π t T ) ) , \eta(t)=\eta_0\left(\text{lrf}+\frac{1-\text{lrf}}{2}\left(1+\cos\frac{\pi t}{T}\right)\right), η(t)=η0(lrf+21−lrf(1+cosTπt)),
其中 t ∈ 0 , T t\in0,T t∈0,T 表示训练进度。对密集行人而言,强增强(尤其 Mosaic)能显著提升小目标与遮挡情形下的泛化,但也可能在训练后期引入分布偏移,因此在最后 10 个 epoch 关闭 Mosaic(close_mosaic=10)通常能带来更稳定的定位精修。由于任务为单类检测,类别不均衡主要体现为"前景/背景比例极端失衡",因此更关键的是提升定位质量与置信度校准:训练侧依赖 IoU 类回归损失与分布式回归(若框架启用 DFL)强化边界精度;推理侧通过 UI 暴露 conf 与 iou 阈值,让用户在拥挤场景下按需调节"召回---误检"权衡,避免固定阈值在不同摄像机视角下表现不稳定。
为了让模型更适合桌面端实时系统,优化不仅发生在训练,还包括导出与部署侧的结构化压缩。训练完成后,优先将 best 模型导出到 ONNX,再按需转 TensorRT(FP16)以获得更低延迟与更稳定的帧率;若部署硬件受限,可进一步尝试 INT8 量化(需校准集)或蒸馏方案:以较大模型(如 v12s/v12m)作为 teacher,对 v12n/v8n 等轻量模型进行软目标约束,从而在参数量不显著增加的情况下提升密集遮挡样本的可分性。需要强调的是,面向人群密度检测的"计数稳定性"往往比单帧 mAP 更敏感,因此工程评估建议额外关注跨帧计数方差与阈值敏感性,并在系统端用滑动窗口或指数平滑对计数进行稳健化处理(不改变检测输出,只改善密度指标的时间一致性)。
| 名称 | 作用(简述) | 建议值(本项目默认) |
|---|---|---|
| epochs | 最多训练轮数 | 120 |
| patience | 早停耐心 | 50 |
| batch | 总批大小 | 16 |
| imgsz | 输入分辨率 | 640 |
| pretrained | 预训练权重 | true |
| optimizer | 优化器 | auto |
| lr0 | 初始学习率 | 0.01 |
| lrf | 最终学习率占比 | 0.01 |
| weight_decay | 权重衰减 | 0.0005 |
| warmup_epochs | 预热轮数 | 3.0 |
| mosaic | Mosaic 强度/概率 | 1.0 |
| close_mosaic | 后期关闭 Mosaic | 10 |
bash
# Ultralytics 系列(v8/v10/v11/v12)统一训练示例:以 yolo12n 为例
yolo detect train \
model=yolo12n.pt \
data=person_density.yaml \
imgsz=640 batch=16 epochs=120 patience=50 \
pretrained=True optimizer=auto \
lr0=0.01 lrf=0.01 momentum=0.937 weight_decay=0.0005 \
warmup_epochs=3.0 mosaic=1.0 close_mosaic=10 \
device=0 amp=True
bash
# 导出部署(示例):ONNX -> TensorRT FP16(实际命令随框架版本略有差异)
yolo export model=runs/detect/train/weights/best.pt format=onnx opset=12
yolo export model=runs/detect/train/weights/best.pt format=engine half=True5. 实验与结果分析
5.1 实验设计
本节实验围绕"人群密度检测"的工程目标展开:在同一套自建行人数据集与统一训练配置下,分别对 YOLOv5 至 YOLOv12 的轻量模型进行对比评测,重点考察其在单类行人检测任务中的检测精度、定位质量与推理效率差异。为兼顾桌面端实时性与精度上限,实验将模型划分为两组进行横向对比:其一是以 n 级别为主的轻量组(YOLOv5nu、YOLOv6n、YOLOv7-tiny、YOLOv8n、YOLOv9t、YOLOv10n、YOLOv11n、YOLOv12n),其二是以 s 级别为主的中等规模组(YOLOv5su、YOLOv6s、YOLOv7、YOLOv8s、YOLOv9s、YOLOv10s、YOLOv11s、YOLOv12s)。所有模型在相同输入尺寸 640 × 640 640\times 640 640×640、相近训练轮数与增强策略下完成训练,并在测试集上进行统一评估,以保证结论的可比性。
5.2 度量指标
检测性能采用 Precision、Recall、F1 与 mAP 作为主指标,其中 Precision 与 Recall 定义为
P = T P T P + F P , R = T P T P + F N , P=\frac{TP}{TP+FP},\qquad R=\frac{TP}{TP+FN}, P=TP+FPTP,R=TP+FNTP,
F1 反映查准与查全的折中:
F 1 = 2 P R P + R . F1=\frac{2PR}{P+R}. F1=P+R2PR.
精度评估同时报告 m A P @ 0.5 mAP@0.5 mAP@0.5 与 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95:前者更偏向"是否检测到",后者对框的几何质量更敏感,能更细致地区分模型在拥挤遮挡与小目标条件下的定位能力。效率侧统计了预处理、推理与后处理耗时,并用三者之和近似单帧端到端延迟(Total),辅以参数量(Params)与计算量(FLOPs)刻画模型复杂度。需要说明的是,本次耗时统计来自评测日志中记录的设备信息(NVIDIA GeForce RTX 3070 Laptop GPU,8GB),因此时间结论应理解为"在该硬件与评测实现下的相对比较",但不同模型之间的相对排序仍具有较强参考价值。
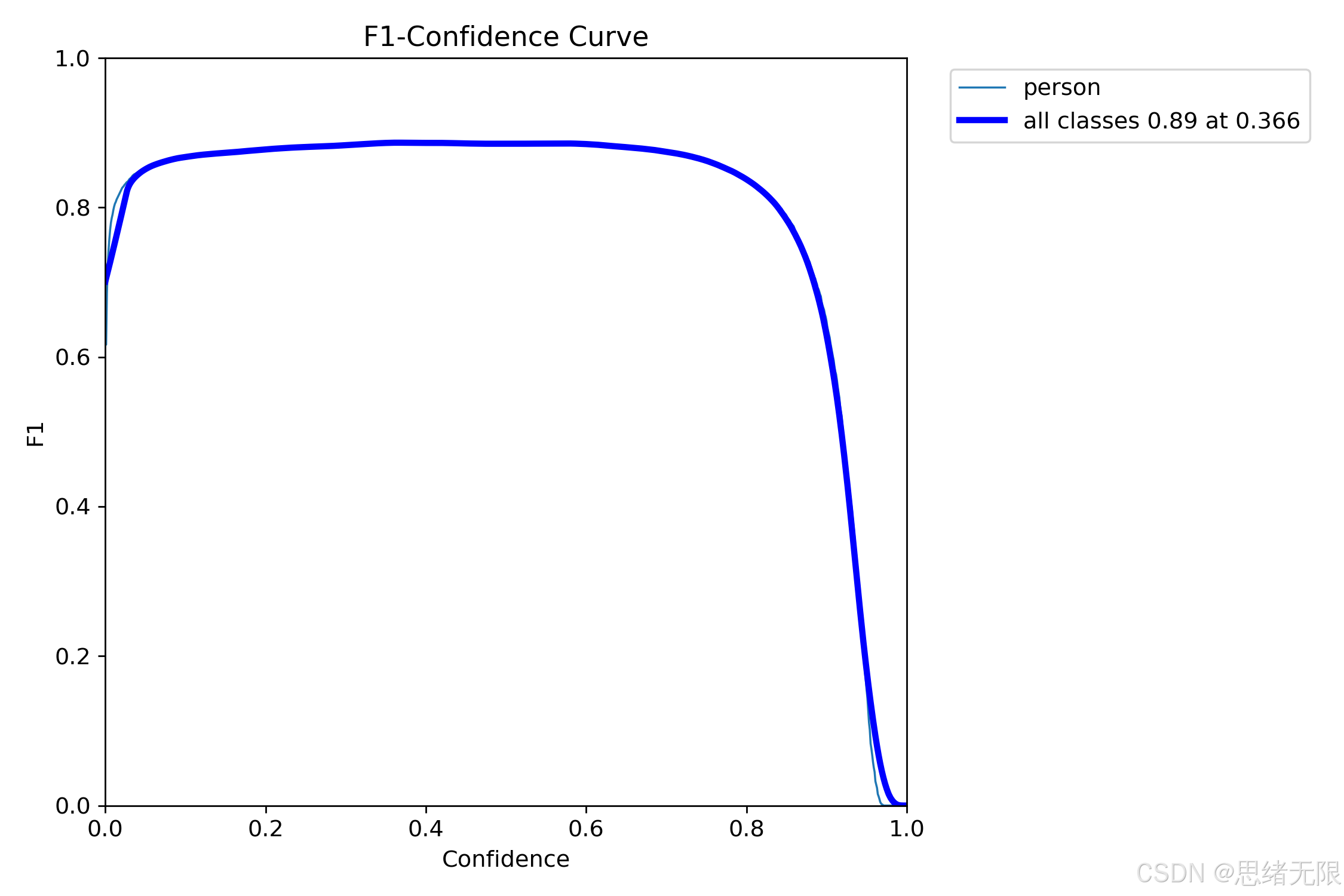
与工程应用直接相关的一点是:人群密度检测最终输出的是"人数/密度等级",阈值策略会显著影响计数稳定性。因此本节除报告固定阈值下的检测指标外,还结合 F1--Confidence 曲线讨论置信度阈值的推荐取值区间,为后续 GUI 默认参数提供依据(对应"F1-Confidence Curve"图)。
5.3 实验结果分析
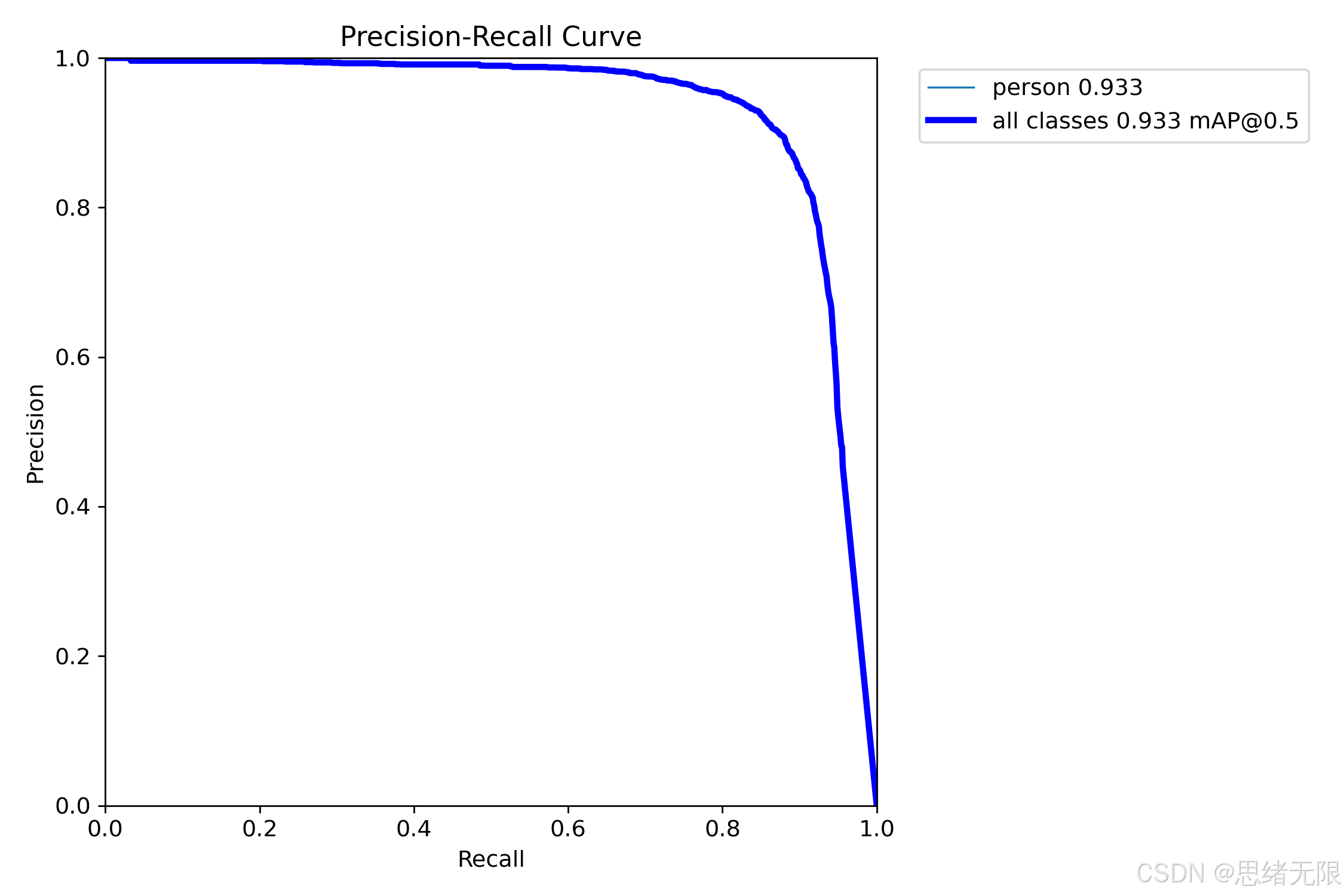
从阈值敏感性看,F1--Confidence 曲线呈现出较宽的"高性能平台区",在 conf ≈ 0.366 \text{conf}\approx 0.366 conf≈0.366 处取得全类最优 F1 ≈ 0.89 \approx 0.89 ≈0.89,随后在高阈值区域出现明显坠落。这一现象说明:当阈值过高时,Recall 会因漏检迅速下降,从而导致 F1 崩塌;而在中等阈值范围内,Precision 的提升不足以抵消 Recall 的损失。对桌面端实时密度统计而言,老思更倾向把默认阈值设置在 0.35 0.35 0.35 左右,并在 UI 中允许用户按场景微调(例如夜间噪声较大时提高阈值抑制误检,极密集场景则适度降低阈值以减少漏检造成的系统性低估)。该结论与 PR 曲线在高召回端精度下降的形态一致:当 Recall 逼近 1.0 时,Precision 会出现快速下滑,提示"追求极端召回"往往意味着更高的误检代价(对应"Precision-Recall Curve"图)。
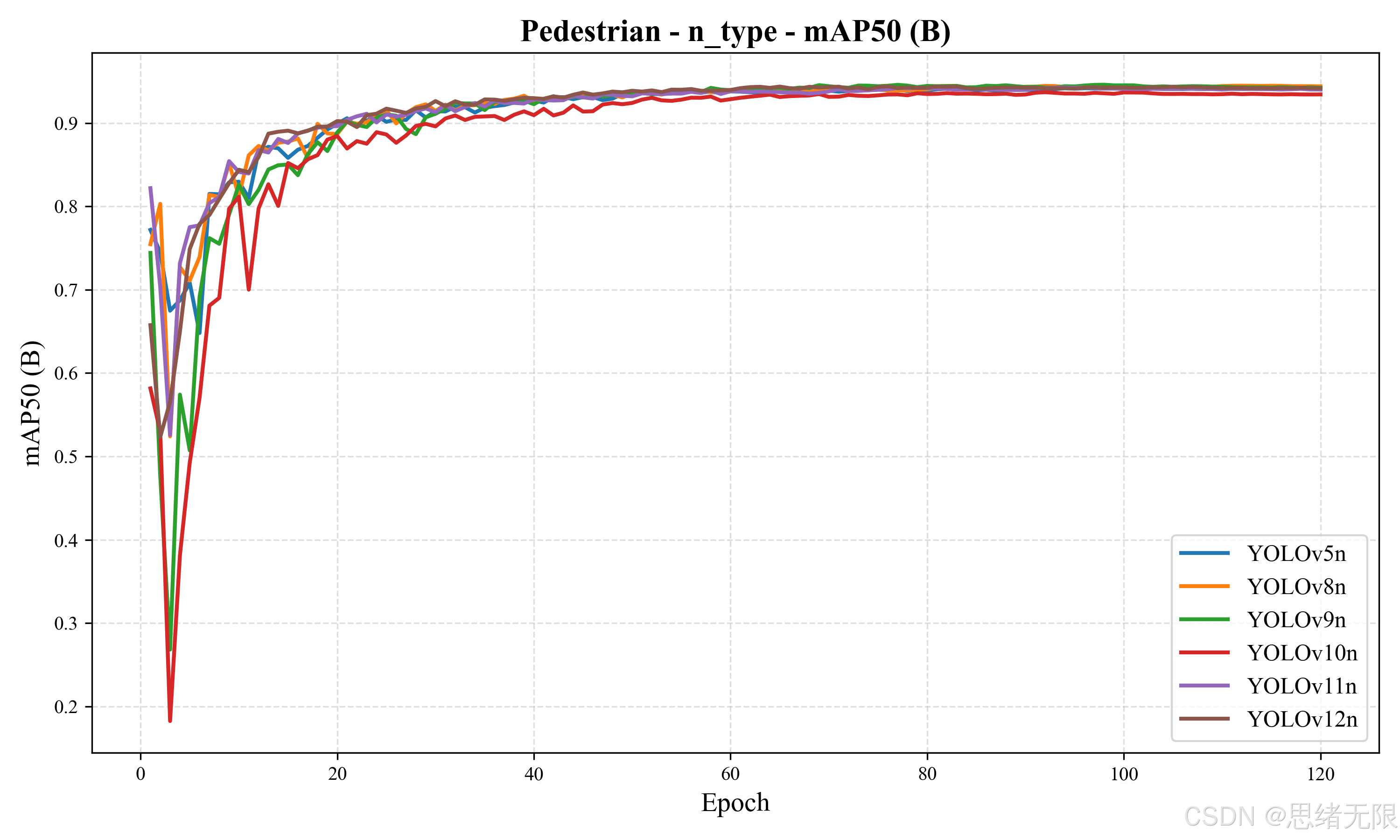
轻量组(n-type)对比结果如"Pedestrian - n_type: F1 & mAP50 Comparison"与"Average PR Curves - Pedestrian (n_type)"所示,各模型在单类行人任务上整体都达到了较高水平, m A P @ 0.5 mAP@0.5 mAP@0.5 基本集中在 0.932--0.945 区间,差异并不夸张,这意味着在当前数据分布下"能否检出"已接近饱和,更值得关注的是定位质量、推理延迟与对高遮挡样本的稳定性。从表中可见,YOLOv8n 同时取得 n 组最高的 m A P @ 0.5 = 0.945 mAP@0.5=0.945 mAP@0.5=0.945 与最高的 F 1 = 0.890 F1=0.890 F1=0.890,并且端到端延迟最低(Total ≈ 10.17 \approx 10.17 ≈10.17 ms),属于"精度与速度同时占优"的选择;YOLOv6n 的 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95 达到 0.730,在严格 IoU 阈值下的定位质量更强,但其 m A P @ 0.5 mAP@0.5 mAP@0.5 与 F1 略低,体现为"框更准但检出收益有限"的特征。YOLOv12n 在 m A P @ 0.5 : 0.95 = 0.728 mAP@0.5:0.95=0.728 mAP@0.5:0.95=0.728 上同样表现突出,说明注意力友好结构可能对小目标定位的边界质量有正贡献,但其推理耗时较 v8n 更高(Total ≈ 15.75 \approx 15.75 ≈15.75 ms),在实时 UI 中需要结合实际帧率目标权衡。另一个值得注意的现象是 YOLOv10n 的后处理耗时显著更低(PostTime ≈ 0.63 \approx 0.63 ≈0.63 ms),这与其端到端设计减少传统后处理瓶颈的工程目标相吻合;不过在本数据集上它的总体精度并未体现出优势( m A P @ 0.5 = 0.934 mAP@0.5=0.934 mAP@0.5=0.934, F 1 = 0.882 F1=0.882 F1=0.882),更适合作为"高并发或低延迟优先"的备选而非精度首选。
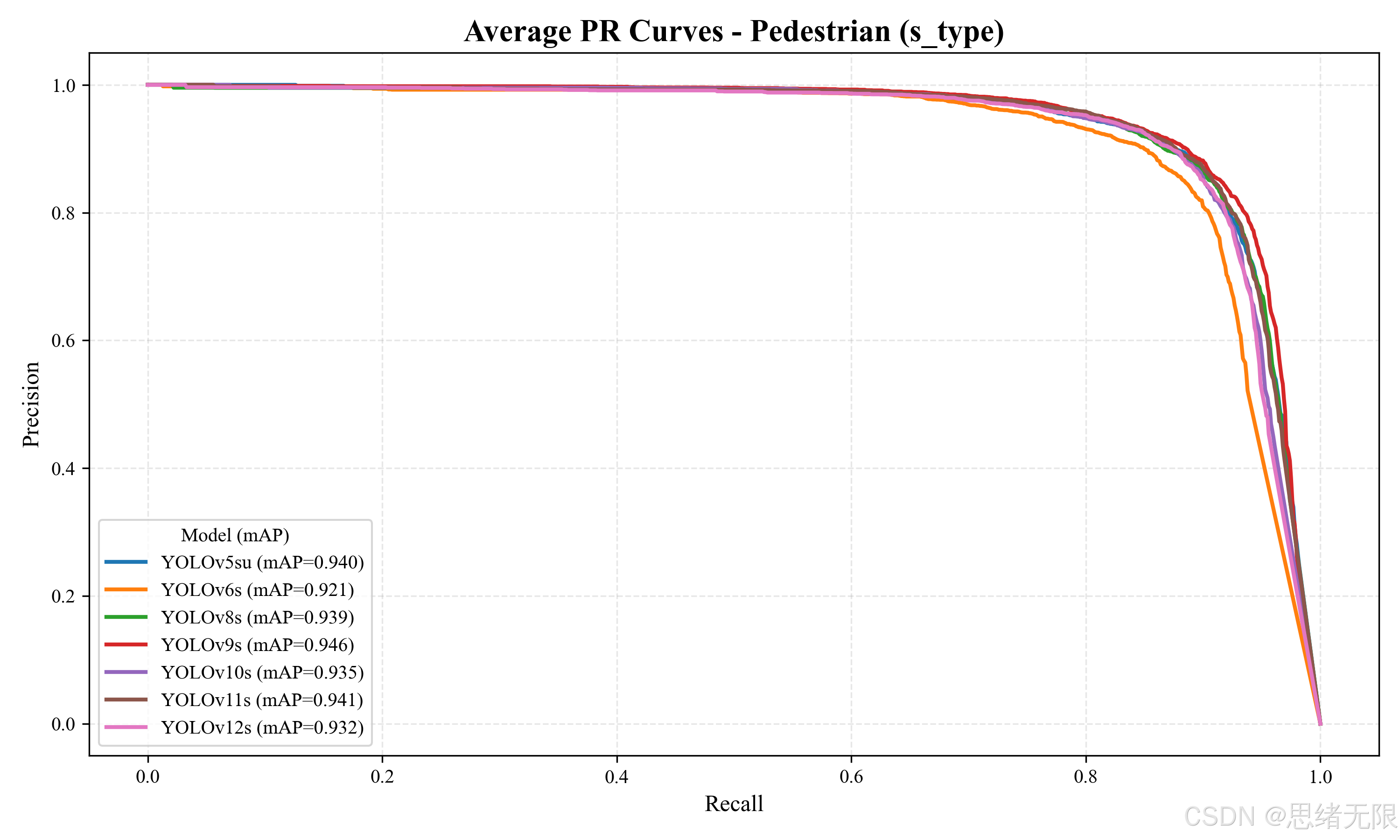
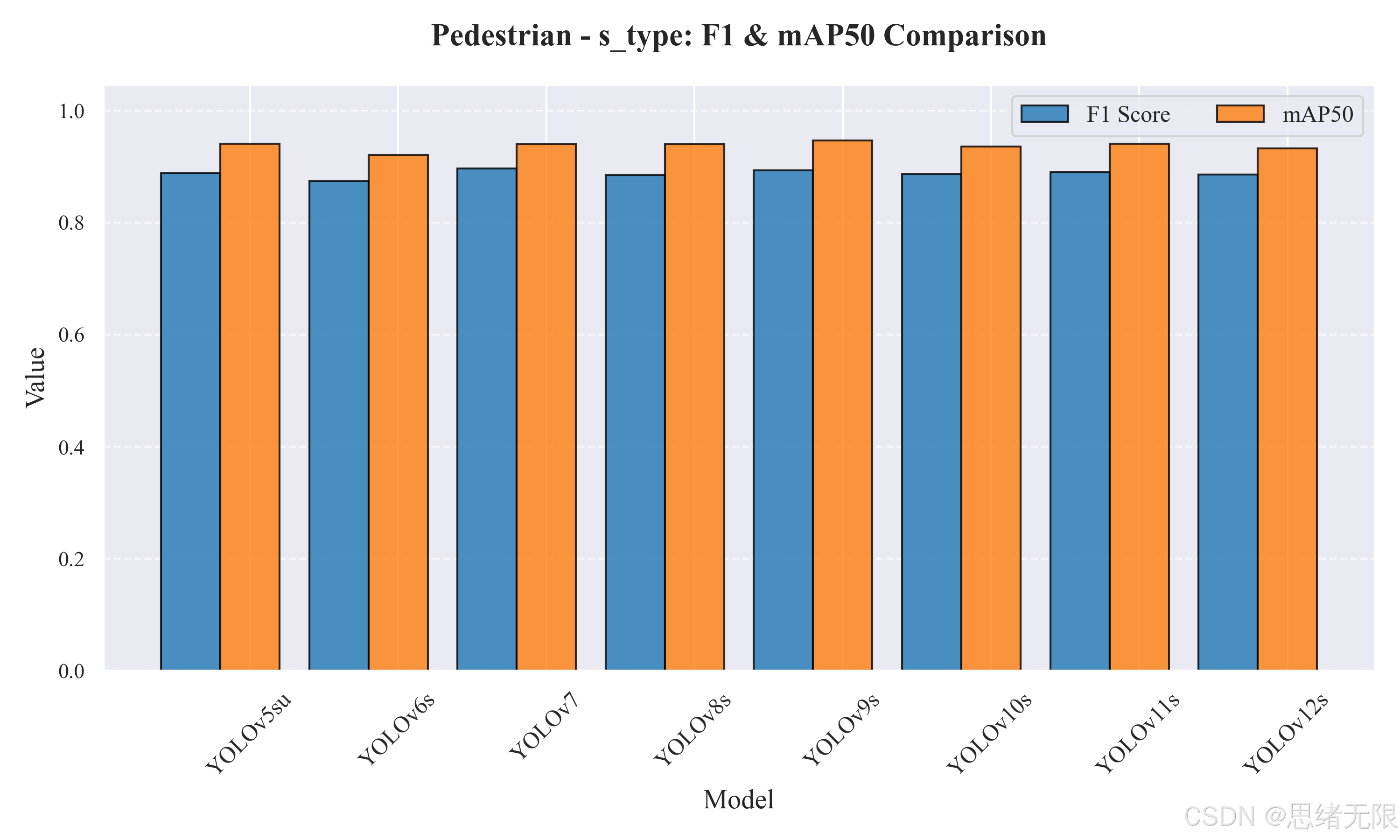
中等规模组(s-type)的对比在"Pedestrian - s_type: F1 & mAP50 Comparison"与"Average PR Curves - Pedestrian (s_type)"中更加清晰地呈现出"精度上限与速度代价"的交换关系。YOLOv9s 取得全组最高的 m A P @ 0.5 = 0.947 mAP@0.5=0.947 mAP@0.5=0.947,同时 F 1 = 0.893 F1=0.893 F1=0.893 也位于前列,说明其在检出与误检控制上更均衡,但推理耗时明显增加(Total ≈ 22.17 \approx 22.17 ≈22.17 ms),对于高帧率摄像头或多路视频同时接入的桌面应用,算力占用会更敏感。YOLOv11s 的 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95 达到 0.745,是 s 组中定位质量最强的模型之一,提示其对边界细节的拟合更稳定;在密度系统的 ROI 计数或后续跟踪模块中,这类"更高 IoU 质量"的收益往往比单纯 m A P @ 0.5 mAP@0.5 mAP@0.5 更可感知。YOLOv7 的 F1 达到 0.896,为 s 组最高,体现出较强的召回能力,但其模型规模与推理成本也最大(Params 36.9M,Total ≈ 29.52 \approx 29.52 ≈29.52 ms),更适合离线统计或精度优先的场景。若以实时性为第一目标,YOLOv8s 的 Total 仅约 11.39 ms,为 s 组最快,且 m A P @ 0.5 mAP@0.5 mAP@0.5 仍保持在 0.940 左右,是"稳定实时 + 足够精度"的典型选项。
从训练动态看,两组的 m A P @ 0.5 mAP@0.5 mAP@0.5 曲线均呈现"前期快速提升、后期边际收益递减"的规律(对应两张 "mAP50(B) vs Epoch" 图),大约在前 20 个 epoch 内即可越过 0.90,60 epoch 后进入平台期,后续提升主要体现在小幅的定位精修与波动收敛上。结合 "results.png" 中 train/val 损失与 precision/recall 的走势,可以看到训练过程整体稳定、验证曲线与训练曲线未出现明显背离,说明在当前数据规模与增强设置下并未出现严重过拟合;这也侧面支持在工程训练中启用 early stopping 或减少后期轮数,以换取更高的训练效率。
综合以上结果,如果系统以"单路/多路实时摄像头 + UI 流畅交互"为核心诉求,老思更建议默认采用 YOLOv8n(或 YOLOv8s)作为前端实时模型,并在界面中提供一键切换到 YOLOv11s/YOLOv9s 以满足"定位更准/精度更高"的需求;当场景极端拥挤、对漏检更敏感时,可结合 F1--Confidence 曲线将默认 conf \text{conf} conf 设在 0.35--0.40 区间,并在密度统计侧引入时间平滑,以降低阈值波动对人数曲线的影响。
表 5-1 n-type 模型测试集性能与效率对比( 640 × 640 640\times 640 640×640)
| Model | Params(M) | FLOPs(G) | Total(ms) | Precision | Recall | F1 Score | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 10.94 | 0.914 | 0.863 | 0.888 | 0.941 | 0.712 |
| YOLOv6n | 4.3 | 11.1 | 10.34 | 0.902 | 0.863 | 0.882 | 0.932 | 0.730 |
| YOLOv7-tiny | 6.2 | 13.8 | 21.08 | 0.891 | 0.887 | 0.889 | 0.942 | 0.679 |
| YOLOv8n | 3.2 | 8.7 | 10.17 | 0.899 | 0.881 | 0.890 | 0.945 | 0.725 |
| YOLOv9t | 2.0 | 7.7 | 19.67 | 0.908 | 0.871 | 0.889 | 0.943 | 0.727 |
| YOLOv10n | 2.3 | 6.7 | 13.95 | 0.908 | 0.857 | 0.882 | 0.934 | 0.726 |
| YOLOv11n | 2.6 | 6.5 | 12.97 | 0.894 | 0.878 | 0.886 | 0.940 | 0.725 |
| YOLOv12n | 2.6 | 6.5 | 15.75 | 0.900 | 0.879 | 0.889 | 0.942 | 0.728 |
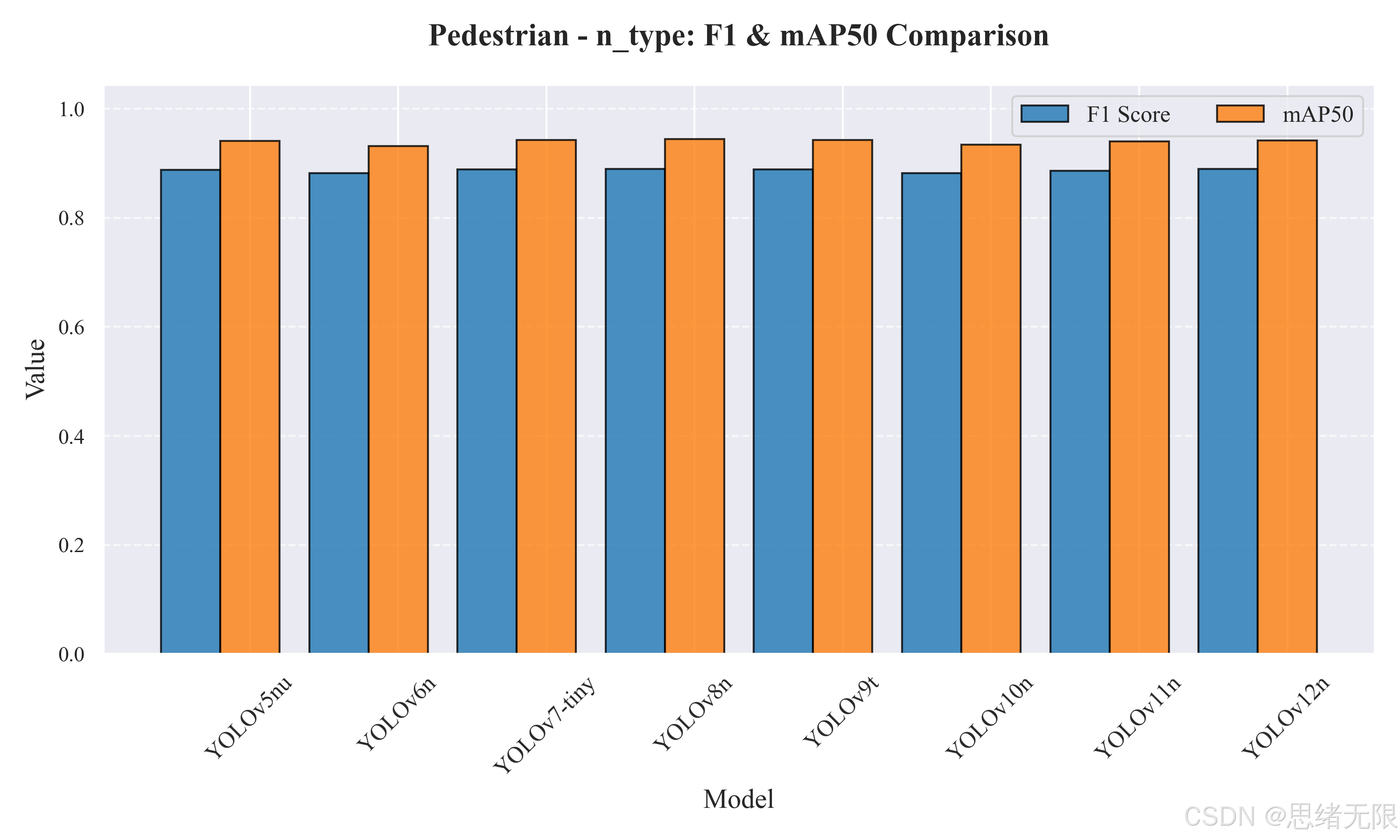
表 5-2 s-type 模型测试集性能与效率对比( 640 × 640 640\times 640 640×640)
| Model | Params(M) | FLOPs(G) | Total(ms) | Precision | Recall | F1 Score | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|---|
| YOLOv5su | 9.1 | 24.0 | 12.24 | 0.898 | 0.878 | 0.888 | 0.941 | 0.726 |
| YOLOv6s | 17.2 | 44.2 | 12.26 | 0.900 | 0.849 | 0.874 | 0.921 | 0.735 |
| YOLOv7 | 36.9 | 104.7 | 29.52 | 0.893 | 0.900 | 0.896 | 0.940 | 0.726 |
| YOLOv8s | 11.2 | 28.6 | 11.39 | 0.889 | 0.881 | 0.885 | 0.940 | 0.733 |
| YOLOv9s | 7.2 | 26.7 | 22.17 | 0.907 | 0.880 | 0.893 | 0.947 | 0.741 |
| YOLOv10s | 7.2 | 21.6 | 14.19 | 0.910 | 0.864 | 0.887 | 0.936 | 0.742 |
| YOLOv11s | 9.4 | 21.5 | 13.47 | 0.909 | 0.871 | 0.890 | 0.941 | 0.745 |
| YOLOv12s | 9.3 | 21.4 | 16.74 | 0.898 | 0.875 | 0.886 | 0.933 | 0.739 |
6. 系统设计与实现
6.1 系统设计思路
本系统面向"人群密度检测"的桌面端落地需求,整体采用分层与解耦的架构:界面层由 Ui_MainWindow 负责按钮、标签、表格与主题资源的呈现,控制层由 MainWindow 统一承载槽函数、状态机与会话管理,处理层以 Detector 封装模型加载、推理与后处理逻辑。老思在工程实现中刻意把"可变"的部分(模型权重、阈值、输入源)收敛为可配置项,把"稳定"的部分(推理接口、结果数据结构、渲染/导出流程)固化为统一管线,从而保证 YOLOv5--YOLOv12 的切换不会引入额外业务差异,便于做公平对比与长期维护。

多源输入采用一致的帧级接口:摄像头与视频在后台线程中持续产生帧并通过 Qt 信号槽发送到推理线程,图片与文件夹则以任务队列方式触发单次/批量推理;推理端输出统一的 boxes/conf/cls 与派生统计(人数、ROI 密度、密度等级、FPS),再回传给 UI 线程进行绘制与交互更新。为避免界面卡顿,推理与渲染严格线程隔离,UI 仅消费结构化结果并做轻量绘制,同时在播放控制(暂停/继续/进度)与阈值调参(Conf/IoU)上采用即时生效策略,使"检测---计数---密度展示"在交互链路内保持低延迟闭环。
结果管理采用"文件导出 + SQLite 持久化"并行:导出侧支持保存带框图片、推理后视频与统计报表,数据库侧以用户为命名空间存储账号信息、主题与参数偏好、历史检测记录与摘要统计,保证多用户下的隔离性与可追溯性。系统默认以 YOLOv12n 作为主模型,同时提供权重导入与一键切换入口,便于在同一界面中快速对比不同 YOLO 版本在密集遮挡、小目标场景中的稳定性差异,并把对比结论直接沉淀为工程选型配置。
图 系统流程图
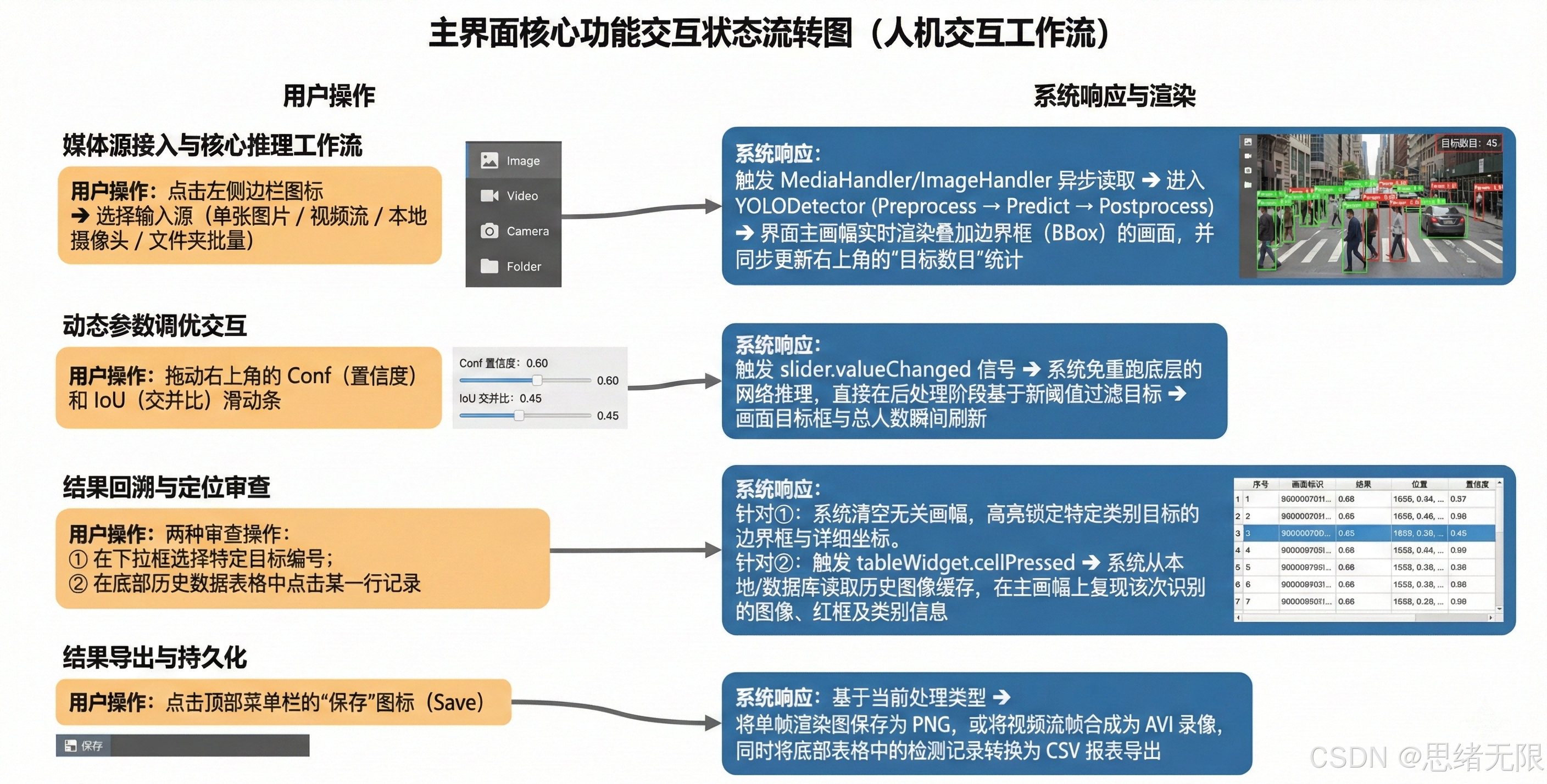
图注:系统从初始化到多源输入,完成预处理、推理与界面联动,并通过交互形成闭环。
6.2 登录与账户管理
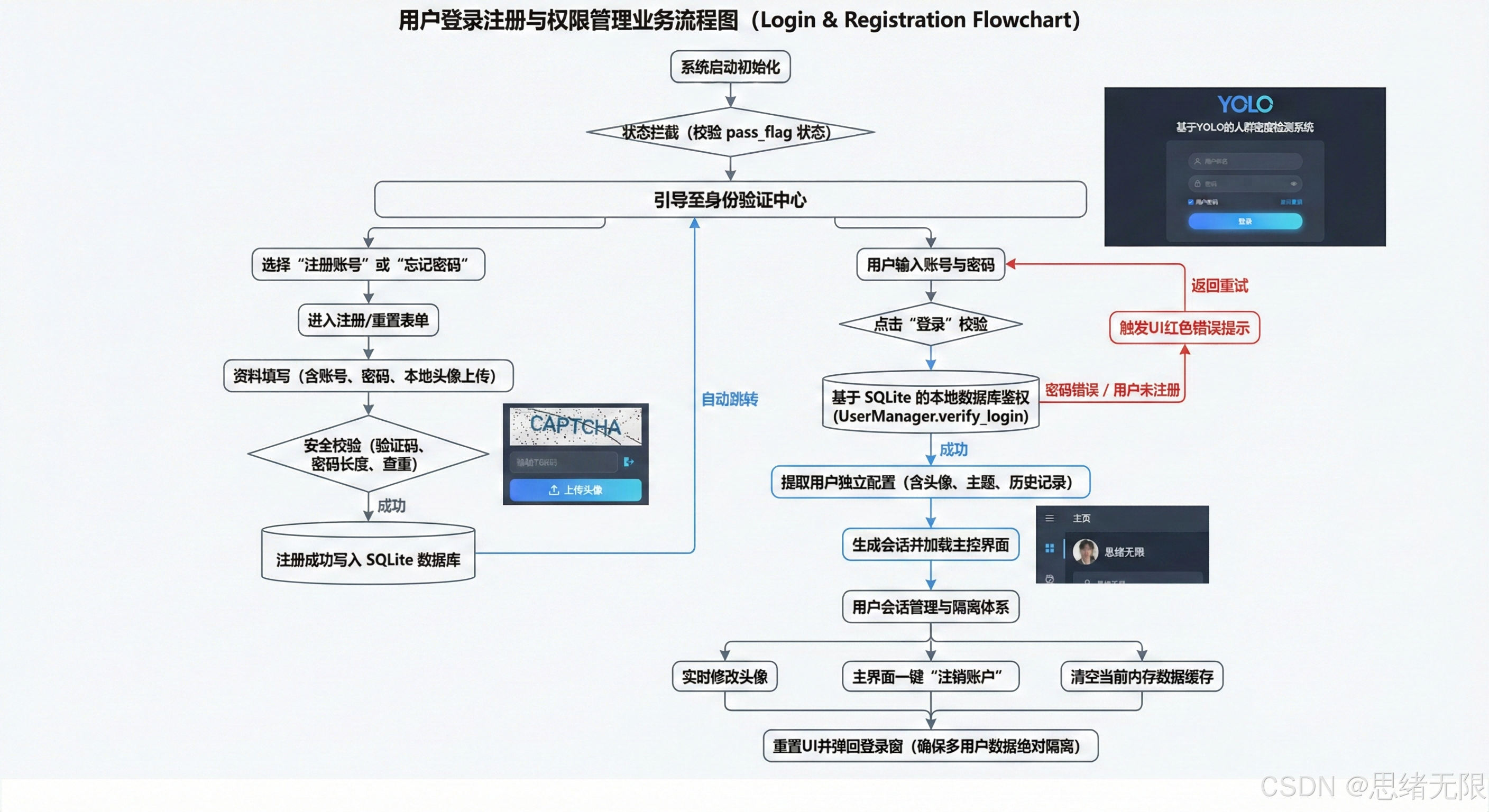
登录与账户管理模块以 PySide6 的界面交互为入口、以 SQLite 为持久化载体,将"身份校验---个性化配置---历史结果回溯"串成稳定链路:用户在登录成功后自动加载其专属阈值、主题与既往检测记录,使同一套检测系统在多用户、多场景下保持一致的使用体验与数据隔离;注册流程把新用户信息写入数据库并回到登录入口,登录流程通过查询与校验建立会话并进入主界面,与主检测管线共享统一的状态管理;在主界面中进行头像、密码与偏好更新时,系统同步写回数据库以保证重启后的可恢复性;注销与切换账号则显式清理会话并返回登录界面,从而在工程层面实现"用户空间、结果空间、配置空间"的持久化与可追溯,避免密度统计与导出记录在多人协作场景下发生混淆。
7. 下载链接
若您想获得博文中涉及的实现完整全部资源文件 (包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
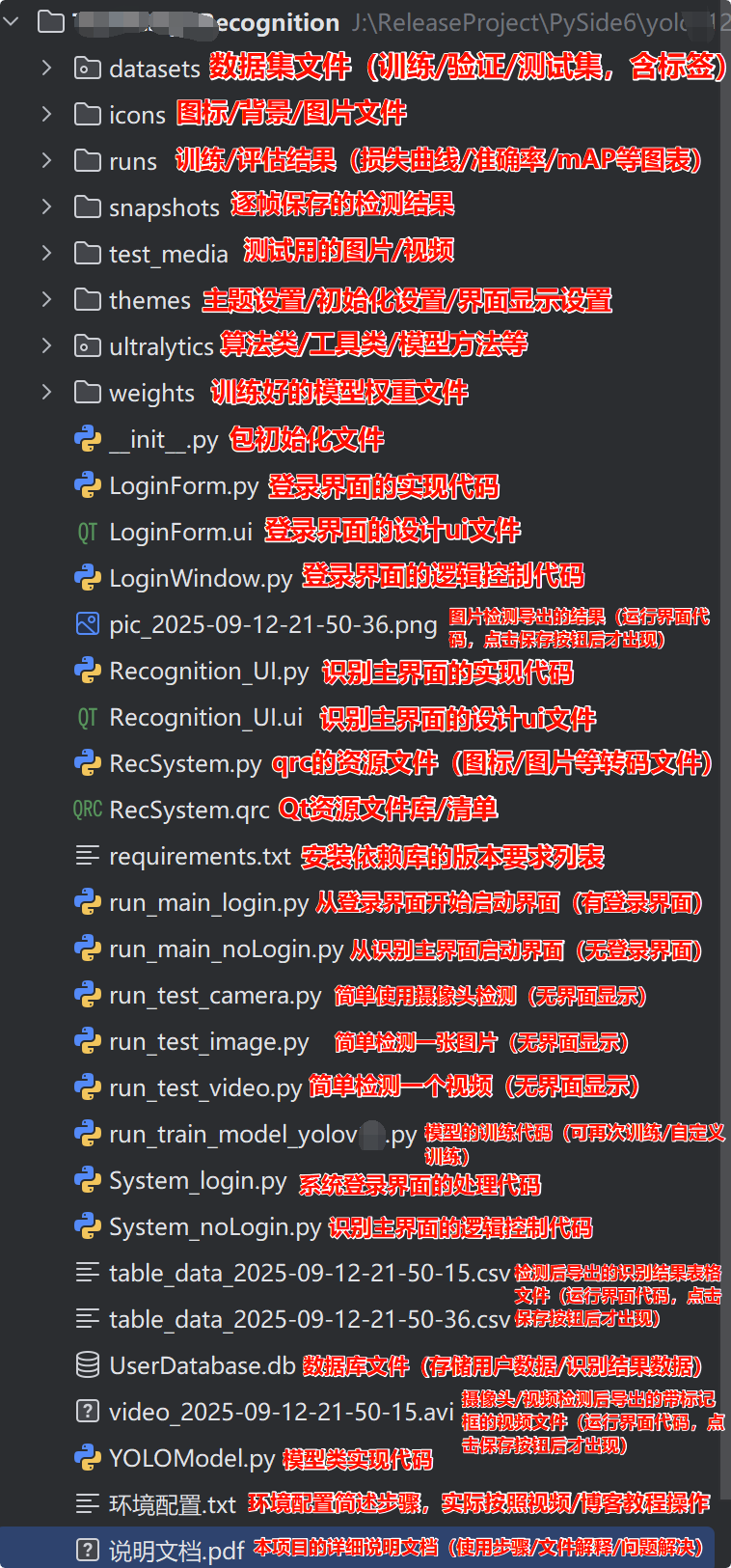
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件请见项目介绍及功能演示视频处给出:➷➷➷
项目介绍地址: https://my.feishu.cn/wiki/FJmPwnoBbiycnWkx2RXc4LkYnYg
讲解视频地址: https://www.bilibili.com/video/BV1K1QuBNEfE/
功能效果展示视频:YOLOv5至YOLOv12升级:交通标志识别系统的设计与实现(完整代码+界面+数据集项目)
环境配置博客教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
或者环境配置视频教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境依赖配置教程
数据集标注教程(如需自行标注数据):数据标注合集
8. 参考文献(GB/T 7714)
1 余鹰, 朱慧琳, 钱进, 潘诚, 苗夺谦. 基于深度学习的人群计数研究综述J. 计算机研究与发展, 2021, 58(12): 2724-2747.
2 LEMPITSKY V, ZISSERMAN A. Learning to count objects in imagesC//Advances in Neural Information Processing Systems. 2010.
3 ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural networkC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 589-597.
4 LI Y, ZHANG X, CHEN D. CSRNet: Dilated convolutional neural networks for understanding the highly congested scenesC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 1091-1100.
5 WANG Q, GAO J, LIN W, et al. NWPU-Crowd: A Large-Scale Benchmark for Crowd Counting and LocalizationJ. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(6): 2141-2149.
6 SINDAGI V A, YASARLA R, PATEL V M. Pushing the frontiers of unconstrained crowd counting: New dataset and benchmark methodC//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 1221-1231.
7 BAI H, HE H, PENG Z, et al. CounTr: An End-to-End Transformer Approach for Crowd Counting and Density EstimationC//Computer Vision -- ECCV 2022 Workshops. Cham: Springer, 2023: 207-222.
8 JOCHER G. Ultralytics YOLOv5EB/OL. Zenodo, 2020. (2020-06-22)2026-02-12.
9 ZHANG B, LI H, LI S, et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial ApplicationsEB/OL. arXiv:2209.02976, 2022. (2022-09-07)2026-02-12.
10 WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectorsC//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 7464-7475.
11 Ultralytics. Ultralytics YOLOv8EB/OL. (2023-01-10)2026-02-12.
12 WANG C Y, YEH I H, LIAO H Y M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient InformationEB/OL. arXiv:2402.13616, 2024. (2024-02-21)2026-02-12.
13 WANG A, CHEN H, LIU L, et al. YOLOv10: Real-Time End-to-End Object DetectionEB/OL. arXiv:2405.14458, 2024. (2024-05-23)2026-02-12.
14 Ultralytics. Ultralytics YOLO11EB/OL. (2024-)2026-02-12.
15 TIAN Y, YE Q, DOERMANN D. YOLOv12: Attention-Centric Real-Time Object DetectorsEB/OL. arXiv:2502.12524, 2025. (2025-02-18)2026-02-12.