论文信息
- 标题:DETRs Beat YOLOs on Real-time Object Detection
- 会议:CVPR 2024
- 单位:百度、北京大学
- 代码:github.com/lyuwenyu/RT-DETR
- 论文:https://arxiv.org/pdf/2304.08069.pdf
一、前言
长久以来,实时检测领域一直是YOLO家族 的天下,但它们都绕不开一个"拖油瓶"------NMS 。
NMS不仅拖慢速度,还严重影响精度稳定性。
DETR虽然完美去掉NMS,却因为速度太慢、计算太贵,从来进不了实时赛道。
直到百度提出 RT-DETR :
第一个真正做到实时、端到端、无NMS、精度速度双杀YOLO的Transformer检测器。
- RT-DETR-R50:53.1% AP,108 FPS
- RT-DETR-R101:54.3% AP,74 FPS
- 不用NMS、不用Anchor、训练更快、部署更稳
一句话总结:
RT-DETR = DETR的优雅 + YOLO的速度 + 更高的精度。
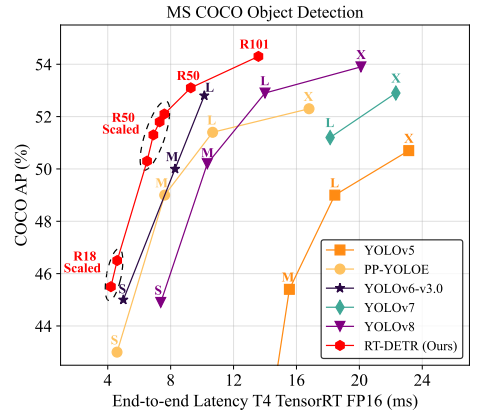
与之前那些先进的实时物体检测器相比,我们的 RT-DETR 实现了最先进的性能。
二、核心动机:NMS是实时检测的毒瘤
YOLO之所以快不上去,根本原因就是 NMS后处理。
NMS的两大原罪:
- 速度不稳定:框越多越慢,耗时不可控
- 精度不稳定:阈值敏感,调参痛苦
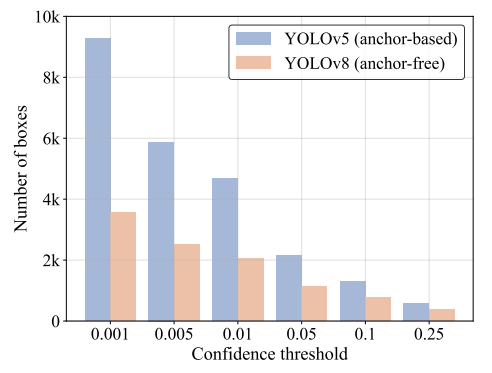
不同置信度阈值下保留的框数量。
阈值越低,框越多,NMS越慢。
图片分析:
NMS执行时间完全不可控,成为实时检测的巨大瓶颈。
表格1(来自原文Table 1)
| IoU阈值 | AP | NMS耗时(ms) | 置信度阈值 | AP | NMS耗时(ms) |
|---|---|---|---|---|---|
| 0.5 | 52.1 | 2.24 | 0.001 | 52.9 | 2.36 |
| 0.6 | 52.6 | 2.29 | 0.01 | 52.4 | 1.73 |
| 0.8 | 52.8 | 2.46 | 0.05 | 51.2 | 1.06 |
表格分析:
NMS耗时随阈值剧烈波动,精度也跟着跳变,工业部署极其不友好。
三、RT-DETR总览
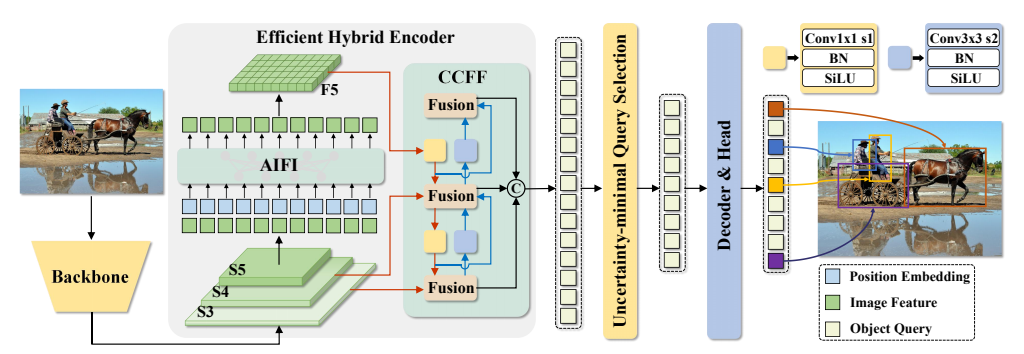
RT-DETR 的概述。我们将骨干网络的最后三个阶段的特征输入到编码器中。高效的混合编码器通过基于注意力的同尺度特征交互(AIFI)和基于卷积神经网络的跨尺度特征融合(CCFF)将多尺度特征转换为一系列图像特征。然后,不确定性最小化查询选择会选取固定数量的编码器特征作为解码器的初始对象查询。最后,带有辅助预测头的解码器会通过迭代优化对象查询来生成类别和框。
结构:
Backbone → 高效混合编码器(AIFI+CCFF) → 最小不确定性查询选择 → 解码器 → 输出
两大革命性创新:
- 高效混合编码器:把多尺度特征计算量砍半
- 最小不确定性查询选择:给解码器送最高质量的查询
四、创新1:高效混合编码器(速度核心)
DETR编码器一直是计算瓶颈,因为多尺度特征序列太长。
RT-DETR直接解耦:
- AIFI(注意力 intra-scale):只在最高层S5做自注意力
- CCFF(CNN cross-scale):用轻量CNN做跨尺度融合
公式如下:
Q=K=V=Flatten(S5) \mathcal{Q}=\mathcal{K}=\mathcal{V}=Flatten(\mathcal{S}_5) Q=K=V=Flatten(S5)
F5=Reshape(AIFI(Q,K,V)) \mathcal{F}_5=Reshape(AIFI(\mathcal{Q},\mathcal{K},\mathcal{V})) F5=Reshape(AIFI(Q,K,V))
O=CCFF({S3,S4,F5}) \mathcal{O}=CCFF(\{\mathcal{S}_3,\mathcal{S}_4,\mathcal{F}_5\}) O=CCFF({S3,S4,F5})
符号解释:
- S3,S4,S5\mathcal{S}_3,\mathcal{S}_4,\mathcal{S}_5S3,S4,S5:Backbone输出的三层特征
- AIFIAIFIAIFI:单尺度注意力交互
- CCFFCCFFCCFF:卷积跨尺度融合
- Flatten/ReshapeFlatten/ReshapeFlatten/Reshape:展平与恢复形状
通俗解释:
只在语义最深的特征上做注意力,剩下的融合全部用超快CNN,速度直接起飞。
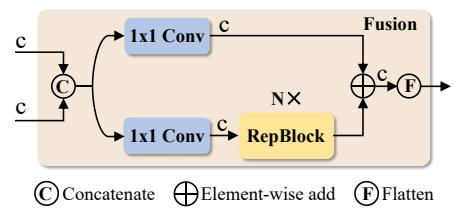
CCFF 中的融合模块。
图片3:CCFF融合块
1×1卷积 + RepBlock + 残差融合,极轻量、极高效。
五、创新2:最小不确定性查询选择(精度核心)
过去的查询选择只看分类分数 ,不管定位准不准。
RT-DETR提出:分类+定位一起评价。
不确定性公式:
U(X^)=∥P(X^)−C(X^)∥ \mathcal{U}(\hat{\mathcal{X}})=\| \mathcal{P}(\hat{\mathcal{X}})-\mathcal{C}(\hat{\mathcal{X}})\| U(X^)=∥P(X^)−C(X^)∥
符号解释:
- U\mathcal{U}U:不确定性
- P\mathcal{P}P:定位预测分布
- C\mathcal{C}C:分类预测分布
- X^\hat{\mathcal{X}}X^:编码器特征
通俗解释:
只选"分类置信度高 且 定位IoU高"的特征做查询。
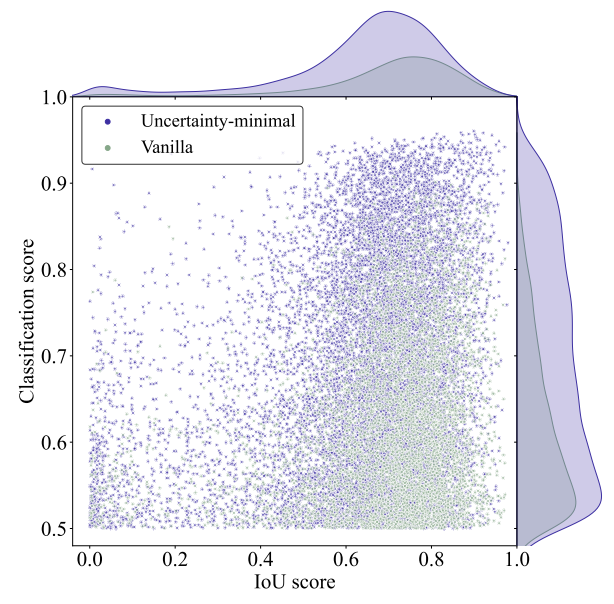
所选编码器特征的分类结果及交并比得分。紫色和绿色的点分别代表通过不确定性最小化查询选择训练得到的模型所选出的特征以及通过常规查询选择所选出的特征。
图片4:查询质量对比
紫色(RT-DETR)大量集中在右上角,代表分类准+定位准。
图片分析:
最小不确定性策略选出的查询质量远超普通方法。
六、创新3:不用重训练,动态调节速度
RT-DETR可以直接删减解码器层来提速,精度掉得极少。
- 6层解码器:最高精度
- 5层解码器:几乎不掉点
- 4层解码器:速度更快
真正工业级友好:一机多速,不用重训。
七、核心代码(PyTorch风格)
python
# ==============================
# RT-DETR 核心:高效混合编码器
# ==============================
class HybridEncoder(nn.Module):
def __init__(self, in_channels, hidden_dim, num_layers=1):
super().__init__()
# AIFI:只对 S5 做注意力
self.aifi = TransformerEncoderLayer(d_model=hidden_dim, nhead=8)
# CCFF:跨尺度卷积融合
self.ccff = CCFFModule(in_channels, hidden_dim)
def forward(self, feats):
# feats: (S3, S4, S5)
s3, s4, s5 = feats
# AIFI 只处理 S5
s5_flat = s5.flatten(2).permute(2, 0, 1)
s5_enhanced = self.aifi(s5_flat)
s5_enhanced = s5_enhanced.permute(1, 2, 0).view_as(s5)
# CCFF 跨尺度融合
out = self.ccff([s3, s4, s5_enhanced])
return out
# ==============================
# 最小不确定性查询选择
# ==============================
class MinUncertaintyQuerySelection(nn.Module):
def forward(self, feats, cls_scores, box_preds):
# 计算不确定性:分类与定位差异
uncertainty = torch.abs(cls_scores - box_preds.sigmoid())
# 选不确定性最小的 Top-K 特征
_, indices = uncertainty.topk(300, dim=1, largest=False)
return feats.gather(1, indices), box_preds.gather(1, indices)八、实验结果(最强表格合集)
8.1 实时检测器大比拼
表格2(来自原文Table 2)
| 模型 | Backbone | AP | FPS |
|---|---|---|---|
| YOLOv5-L | - | 49.0 | 54 |
| YOLOv8-L | - | 52.9 | 71 |
| RT-DETR-R50 | R50 | 53.1 | 108 |
| RT-DETR-R101 | R101 | 54.3 | 74 |
结论:
RT-DETR精度、速度、参数全面超越所有YOLO L/X型号。
8.2 编码器消融实验
表格3(来自原文Table 3)
| 编码器变种 | AP | 延迟(ms) |
|---|---|---|
| A | 43.0 | 7.2 |
| B | 44.9 | 11.1 |
| C | 45.6 | 13.3 |
| D | 46.4 | 12.2 |
| Ds5 | 46.8 | 7.9 |
| E(RT-DETR) | 47.9 | 9.3 |
结论:
只对S5做注意力+CNN融合,速度提升35%,精度还涨。
8.3 查询选择消融
表格4(来自原文Table 4)
| 查询策略 | AP | 高分特征占比 |
|---|---|---|
| 普通 | 47.9 | 0.35% |
| 最小不确定性 | 48.7 | 0.82% |
结论:
高质量查询直接带来**+0.8 AP**。
8.4 解码器动态速度调节
表格5(来自原文Table 5)
| 解码器层数 | AP | 延迟(ms) |
|---|---|---|
| 6层 | 53.1 | 9.3 |
| 5层 | 53.0 | 8.8 |
| 4层 | 52.7 | 8.3 |
| 2层 | 51.6 | 7.5 |
结论:
从6层减到5层,精度几乎不掉,速度明显更快。
九、全文总结
RT-DETR是首个真正实时的端到端Transformer检测器,用极简设计解决三大痛点:
- 去掉NMS,推理稳定、速度可预测
- 高效混合编码器,Transformer实时化
- 最小不确定性查询,大幅提升精度
- 动态解码器,不用重训自由调速
最终:
RT-DETR在速度、精度、部署性上全面超越YOLO,
正式宣告:DETR时代降临实时检测!