简介
在计算机视觉(CV)领域,无论是做目标检测、图像分割还是分类,PASCAL VOC(Pattern Analysis, Statistical Modelling and Computational Learning Visual Object Classes)数据集都是绕不开的经典基准。虽然现在大家动辄使用 MS COCO 甚至更大规模的数据集,但 VOC 数据集依然是很多经典算法(如 YOLO 系列、Faster R-CNN 等)验证模型有效性的首选,也是适合初学者和轻量化模型研究的标准数据集。
今天这篇文章,我们将系统梳理 PASCAL VOC 各年份版本的演进,详细拆解其标注格式,并分享下载链接与格式转换方法。
一、为什么还要了解 PASCAL VOC?
PASCAL VOC 挑战赛从 2005 年开始举办,直到 2012 年结束。它不仅提供了高质量的图像数据,还确立了评估模型性能的标准(如 mAP 指标)。
尽管挑战赛已经停办,但其建立的 20个基础类别(人、鸟、猫、牛、狗、马、羊、飞机、自行车、船、巴士、汽车、摩托车、火车、瓶子、椅子、餐桌、盆栽、沙发、显示器)以及其 XML 的标注规范,至今仍是工业界落地项目和学术界轻量化研究的标配。
二、 PASCAL VOC 历年数据集演进表
根据官方资料与历史版本对比,将 2005 年至 2012 年的数据集核心变化整理如下表:
| 年份 | 基本情况 | 任务类别 | 备注 |
|---|---|---|---|
| 2005 | 4类别:bicycles, cars, motorbikes, people 1578张图片,2209个标注 子数据集:train, validation, test | classification segmentation | 早期探索阶段。 |
| 2006 | 10类别:新增 bus, cat, cow, dog, horse, sheep 等 2618张图片,4754个标注 子数据集:train, validation, test | classification segmentation | 类别扩展,数据量初步增加。 |
| 2007 | 20类别 :固定为经典的20类(涵盖人、动物、交通工具、室内物品) 9963张图片,24640个标注 子数据集:train, validation, test | classification, segmentation, person layout | 关键节点 :最后一年公开 test 数据集;评价指标由 ROC-AUC 变为 AP;标注中增加了 truncation 标签。 |
| 2008 | 同2007的20类别 train+val 与 test 比例约为 1:1 4340张图片,10363个标注 子数据集:train, validation | classification, segmentation, person layout | 标注中添加了 Occlusion (遮挡) 标签;segmentation 和 layout 子集包含 VOC2007 的数据。 |
| 2009 | 同2007的20类别 10103张图片,23374个ROI标注,4203个segmentation标注 子数据集:train, validation, test | classification, segmentation, person layout | 从这一年开始,图像库包含前几年的图像和新图像。 |
| 2010 | 同2007的20类别 9963张图片,24640个标注,4203个segmentation 子数据集:train, validation | classification, segmentation, person layout | 计算 AP 的方法从 TREC 式变为基于所有点计算。 |
| 2011 | 同2007的20类别 11530张图片,27450个标注,5034个segmentation 子数据集:train, validation | classification, segmentation, person layout, action classification | action 类别扩展为 "10+other" 模式;layout 标签不完整(并非所有图中的 person 均被标注)。 |
| 2012 | 同2007的20类别 11530张图片,27450个标注,6929个segmentation 子数据集:train, validation | classification, segmentation, person layout, action classification | 最终版本:质量最高,使用 person 身上的参考点注释了 action 分类数据集。没有公开的 test 集。 |
💡 建议:
由于 VOC2007 之后官方不再公开 test 数据集的标签,业界在论文和工程实验中,最常用的做法是:将 VOC2007 的 train/val 与 VOC2012 的 train/val 合并进行训练与验证,最后在 VOC2007 的 test 数据集上进行测试评估。
三、 数据集内部结构与标注详解
下载解压后,会看到一个名为 VOCdevkit 的文件夹,内部结构如下:
text
VOCdevkit/
└── VOC2012/ (或 VOC2007)
├── Annotations/ # 存放目标检测的 .xml 标签文件
├── ImageSets/ # 存放各个任务的数据集划分文件 (.txt)
│ ├── Action/
│ ├── Layout/
│ ├── Main/ # 目标检测最常用的 train/val/test 划分名单
│ └── Segmentation/
├── JPEGImages/ # 所有的原始图像 (.jpg)
├── SegmentationClass/ # 语义分割的标签图像 (.png)
└── SegmentationObject/ # 实例分割的标签图像 (.png)关于 Segmentation 的调色板(Colormap)
很多人在做分割任务时,打开 SegmentationClass 里的 PNG 标签图片,会觉得它是一张张不同颜色的物体分割图片。但如果你直接用常规的 RGB 模式读取去训练模型,就会大错特错。
本质原理:
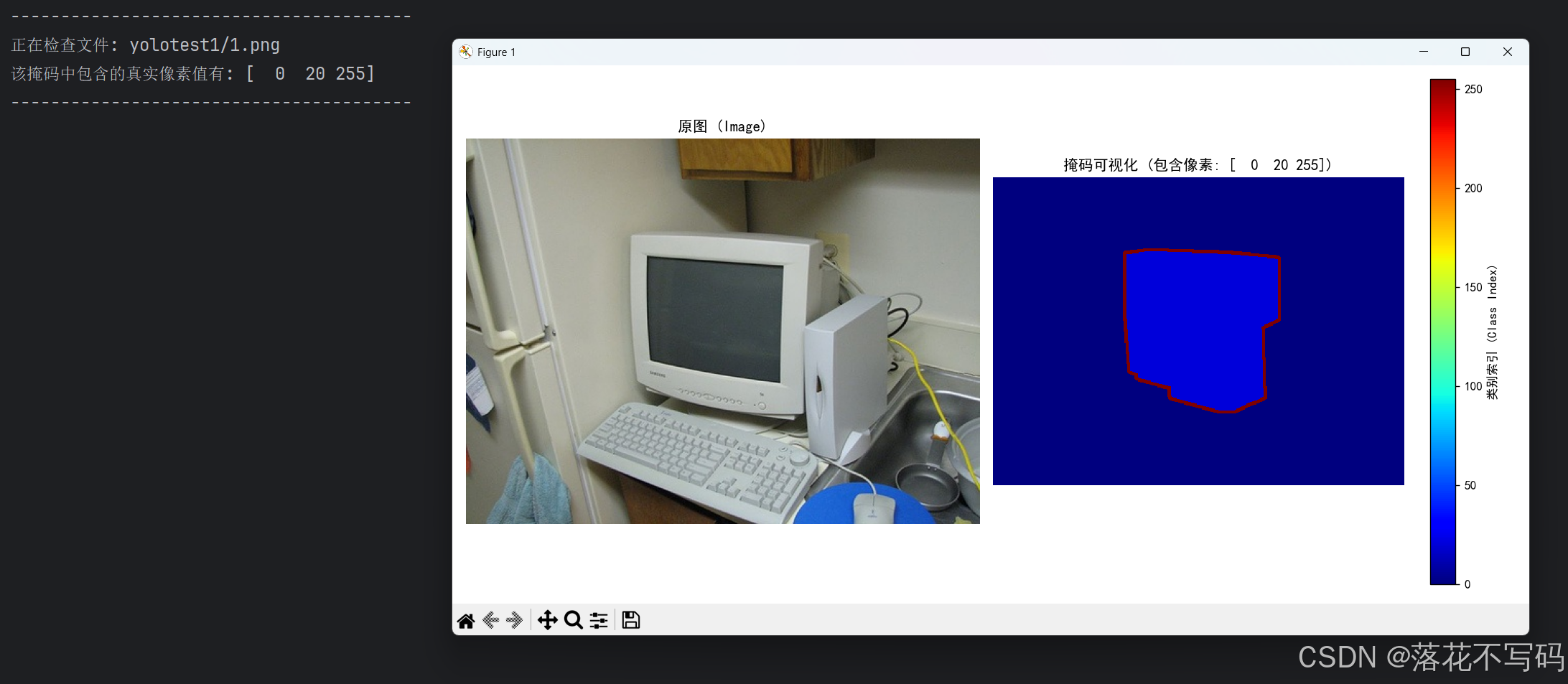
分割标签实际上是单通道的索引图像(8位灰度图),每个像素点的值是一个 0~255 的整数:
0:代表背景(Background)1 ~ 20:代表 VOC 的 20 个具体目标类别255:代表目标边界(Boundary,通常在分割模型训练时会被忽略/Mask掉)
为什么肉眼看是彩色的?
因为 PNG 图像头里包含了一个调色板(Colormap) 。调色板存储了 256 个 RGB 颜色值,图像在显示时,会把像素值(如类别 15)映射到调色板对应的颜色上。这种设计是方便肉眼观察标注质量。
四、 常见格式转换
从 VOC (XML) 到 YOLO (TXT)
VOC 使用的是基于 XML 的 [xmin, ymin, xmax, ymax] 绝对坐标格式。而当前主流的 YOLO 算法(如 YOLOv8、YOLO11 、YOLO26 等)需要的是 .txt 文件,格式为 [class_id, x_center, y_center, width, height] 的相对坐标(0~1之间)。
在实际部署和训练前,必须要进行格式转换。下面提供一个 xml 转换成 yolo 并划分的脚本,代码如下:
python
# -*- coding: utf-8 -*-
import os
import random
import shutil
from xml.etree import ElementTree as ET
import cv2
input_image_folder = r'E:\1-cheng\4-yolo-dataset-daizuo\multi-classify\apples2\images'
input_xml_folder = r'E:\1-cheng\4-yolo-dataset-daizuo\multi-classify\apples2\annotations'
output_folder = r'E:\1-cheng\4-yolo-dataset-daizuo\multi-classify\apples2\dataset1'
# 定义训练集和验证集的比例
train_ratio = 0.8
val_ratio = 0.2
# 获取所有的照片文件和XML文件,这些行获取了输入文件夹中所有以.jpg和.xml结尾的文件的列表。os.listdir()用于列出文件夹中的文件。
image_files = [f for f in os.listdir(input_image_folder) if f.endswith(".jpg")]
xml_files = [f for f in os.listdir(input_xml_folder) if f.endswith(".xml")]
# 创建输出文件夹
os.makedirs(os.path.join(output_folder, "images/train"), exist_ok=True)
os.makedirs(os.path.join(output_folder, "images/val"), exist_ok=True)
os.makedirs(os.path.join(output_folder, "labels/train"), exist_ok=True)
os.makedirs(os.path.join(output_folder, "labels/val"), exist_ok=True)
# 创建类别字典,用于统计每个类别的数量和记录类别顺序
class_counts = {}
class_order = []
for xml_file in xml_files:
xml_path = os.path.join(input_xml_folder, xml_file)
image_name = xml_file.replace(".xml", ".jpg")
image_path = os.path.join(input_image_folder, image_name)
if not os.path.exists(image_path):
continue
tree = ET.parse(xml_path)
root = tree.getroot()
yolo_labels = []
# 遍历XML文件中的每个<object>元素
for obj in root.findall("object"):
class_name = obj.find("name").text
if class_name not in class_counts:
class_counts[class_name] = 0
class_order.append(class_name)
class_counts[class_name] += 1
img = cv2.imread(image_path)
img_height, img_width, _ = img.shape
class_id = list(class_counts.keys()).index(class_name)
# class_id = class_order.index(class_name)
# 获取对象的边界框坐标
bbox = obj.find("bndbox")
xmin = int(bbox.find("xmin").text)
ymin = int(bbox.find("ymin").text)
xmax = int(bbox.find("xmax").text)
ymax = int(bbox.find("ymax").text)
# 计算归一化的坐标
x_center = (xmin + xmax) / (2 * img_width)
y_center = (ymin + ymax) / (2 * img_height)
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
yolo_labels.append(f"{class_id} {x_center} {y_center} {width} {height}")
# 根据指定的训练集和验证集比例,随机选择将数据分配到训练集或验证集
dataset_choice = "train" if random.uniform(0, 1) < train_ratio else "val"
# 将图像和YOLO标签写入文件,将图像复制到相应的训练集或验证集文件夹中,并将YOLO标签写入相应的文本文件中。
shutil.copy(image_path, os.path.join(output_folder, f"images/{dataset_choice}/{image_name}"))
with open(os.path.join(output_folder, f"labels/{dataset_choice}/{xml_file.replace('.xml', '.txt')}"), "w") as label_file:
label_file.write("\n".join(yolo_labels))
# 输出每个类别的数量
for class_name, count in class_counts.items():
print(f"类别: {class_name}, 总数: {count}")
# 输出类别的顺序列表
print("类别顺序:", class_order)使用 YOLO 系列做分割(如 YOLO26-seg, YOLO11/v8-seg)
YOLO 家族的分割模型,底层逻辑是基于多边形(Polygon)的实例分割,而不是逐像素的分类。它不接受 PNG 格式的掩码图像作为标签,而是要求你把分割边界转换成和目标检测非常相似的 .txt 文本格式。
YOLO 分割标签的格式长这样:
[类别ID] [x1] [y1] [x2] [y2] ... [xn] [yn] (坐标全部归一化到 0~1 之间)
做法:
写一个脚本,读取 SegmentationClass 中的 PNG 图片,提取出对应颜色的区域,使用 OpenCV 找到该区域的外接轮廓点,最后将这些轮廓点的坐标写入 TXT 文件中。
下面提高一个将 Mask 轮廓提取并转换为 Polygon 坐标的核心代码参考:
python
import cv2
import numpy as np
def extract_polygons_from_mask(mask_path):
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
polygons = []
for contour in contours:
if len(contour) < 3:
continue
contour = contour.flatten().tolist()
polygons.append(contour)
return polygons可以参考网上的其他人的转换方法
使用传统语义分割网络(如 U-Net, DeepLab, Mask2Former)
这类纯语义分割网络,损失函数(通常是 Cross Entropy Loss)要求的目标标签并不是 RGB 图片,而是一个二维的张量(Tensor) 。在这个张量里,每一个像素点的位置上存放的应该是一个类别的数字索引(比如:背景是 0,飞机是 1,自行车是 2,忽略的边界是 255)。所以该数据集通常不需要转换文件格式,但必须在 Dataloader 中正确读取(将伪彩色转回类别索引)
如果在 Dataloader 里直接用 cv2.imread(img_path) 去读这张图,OpenCV 默认会把它读成 3 通道的 RGB 数组(例如背景变成 [0,0,0],某类别变成 [128,0,0]),这时候直接送进损失函数就会直接报错。
你需要做的:
在编写 PyTorch/TensorFlow 的 Dataset 脚本时,确保使用单通道模式读取,并提取它的原始索引值。以 PIL.Image为例子:
python
from PIL import Image
import numpy as np
import torch
def load_segmentation_mask(mask_path):
mask_img = Image.open(mask_path)
mask_array = np.array(mask_img)
mask_tensor = torch.from_numpy(mask_array).long()
return mask_tensor小结
- 做 YOLO: 写个 Python 脚本批量把 PNG 转成 TXT 轮廓,然后抛弃 PNG。
- 做 U-Net 等传统分割: 保留 PNG 不动,但在写
Dataset类的时候,一定要打印一下读取出来的label矩阵,确认里面是不是只有0-20和255这几个离散的数字,如果发现矩阵形状是(H, W, 3)或者里面有128这种颜色值,那就是读错了。
五、 数据集下载链接
由于国外官网经常抽风或者下载极慢,建议使用国内常用的镜像源下载。
官方原链:
-
VOC 2007 Train/Val:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar -
VOC 2007 Test:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar -
VOC 2012 Train/Val:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar

国内高速镜像(推荐清华源或阿里源):
目前国内许多高校和公共开放平台(如 OpenDataLab 等)都托管了 VOC 数据集的快速下载包,大家可以在这些平台上直接检索 "PASCAL VOC" 获取满速下载体验。
飞桨平台搜索下载: https://aistudio.baidu.com/datasetdetail/159243/
六、 结语
PASCAL VOC 虽已是十几年前的产物,但它的标注规范深深影响了后来的视觉生态。无论是做模型剪枝、量化测试,还是新架构的快速验证,VOC 依然是最高效的试金石。
弄懂它的目录结构、理解单通道调色板机制、掌握 XML 到 TXT/JSON 的转换,是每一个踏入 CV 领域的开发者必修的内功。希望这篇文章能帮你少走弯路!