目录
一.什么是Pandas
Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。
Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
用得最多的pandas对象是Series,一个一维的标签化数组对象,另一个是DataFrame,它是一个面向列的二维表结构。

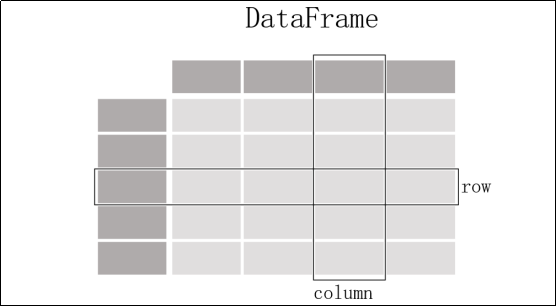
pandas兼具numpy高性能的数组计算功能以及电子表格和关系型数据库(如SQL)灵活的数据处理功能。它提供了复杂精细的索引功能,能更加便捷地完成重塑、切片和切块、聚合以及选取数据子集等操作。
pandas功能:
- 有标签轴的数据结构
在数据结构中,每个轴都被赋予了特定的标签,这些标签用于标识和引用轴上的数据元素,使得数据的组织、访问和操作更加直观和方便。(类似numpy的轴)
- 集成时间序列功能。
- 相同的数据结构用于处理时间序列数据和非时间序列数据。
- 保存元数据的算术运算和压缩。
- 灵活处理缺失数据。
- 合并和其它流行数据库(例如基于SQL的数据库)的关系操作。
pandas这个名字源于panel data(面板数据,这是多维结构化数据集在计量经济学中的术语)以及Python data analysis(Python数据分析)。
二.Pandas数据结构-Series
Series 是 Pandas 中的一个核心数据结构,类似于一个一维的数组,具有数据和索引。
Series 可以存储任何数据类型(整数、浮点数、字符串等),并通过索引来访问元素。Series 的数据结构是非常有用的,因为它可以处理各种数据类型,同时保持了高效的数据操作能力,比如可以通过索引来快速访问和操作数据。

Series 特点:
- 一维数组:Series 中的每个元素都有一个对应的索引值。
- 索引: 每个数据元素都可以通过标签(索引)来访问,默认情况下索引是从 0 开始的整数,但你也可以自定义索引。
- 数据类型: Series 可以容纳不同数据类型的元素,包括整数、浮点数、字符串、Python 对象等。(一个Series 可以同时容纳不同的数据类型,这点与numpy不同)
- 大小不变性:Series 的大小在创建后是不变的,但可以通过某些操作(如 append 或 delete)来改变。
- 操作:Series 支持各种操作,如数学运算、统计分析、字符串处理等。
- 缺失数据:Series 可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示缺失或无值。
- 自动对齐:当对多个 Series 进行运算时,Pandas 会自动根据索引对齐数据,这使得数据处理更加高效。
我们通过后续的具体学习和代码演示来体会。
我们可以使用 Pandas 库来创建一个 Series 对象,并且可以为其指定索引(Index)、名称(Name)以及值(Values)。
三.Series的创建
先安装pandas包,如果在Pycharm中加载不出来,可以通过如下命令安装:
bash
pip install pandas直接通过列表创建Series:
python
import pandas as pd
s = pd.Series([5, 6, 7, "fish"])
print(s)运行结果:

Series的字符串表现形式为:索引在左边,值在右边。由于我们没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
通过列表创建Series时指定索引:
python
import pandas as pd
s = pd.Series([4, 7, -5, 3], index=["a", "b", 1, "d"])
print(s)运行结果:

index索引也可以是不同的类型。
通过列表创建Series时指定索引和名称:
python
import pandas as pd
s = pd.Series([4, 7, -5, 3], index=["a", "b", "c", "d"], name="hello_python")
print(s)运行结果:

直接通过字典创建Series:
cpp
import pandas as pd
dic = {"a": 4, "b": 7, "c": -5, "d": 3}
s = pd.Series(dic)
print(s)运行结果:

python
import pandas as pd
dic = {"a": 4, "b": 7, "c": -5, "d": 3}
# s = pd.Series(dic)
# print(s)
s2 = pd.Series(dic, index=["a", "c"], name="aacc")
print(s2)运行结果:
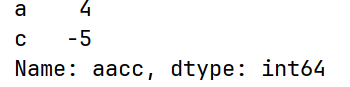
字典创建时我们可以指定index索引为哪几个,比如这里的index="a", "c"。
四.Series的常用属性
|----------------------|---------------|
| 属性 | 说明 |
| index | Series的索引对象 |
| values | Series的值 |
| ndim | Series的维度 |
| shape | Series的形状 |
| size | Series的元素个数 |
| dtype或dtypes | Series的元素类型 |
| name | Series的名称 |
| loc\[\] | 显式索引,按标签索引或切片 |
| iloc\[\] | 隐式索引,按位置索引或切片 |
| at\[\] | 使用标签访问单个元素 |
| iat\[\] | 使用位置访问单个元素 |
python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
# arrs的index索引
print(arrs.index)
for i in arrs.index:
print(i)运行结果:

python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
# arrs的values值
print(arrs.values)运行结果:
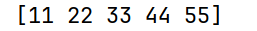
python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
# arrs的ndim维度
print(arrs.ndim)运行结果:
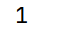
python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
# arrs的shape形状
print(arrs.shape)运行结果:
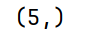
python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
# arrs的size元素个数
print(arrs.size)运行结果:
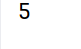
python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
# arrs的元素类型
print(arrs.dtype)运行结果:
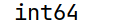
python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
# arrs的name
print(arrs.name)运行结果:

python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
# arrs的loc[]显式标签(index)索引或切片
print(arrs.loc["b"])
print("---------------------")
print(arrs.loc["b":"d"]) # 左闭右闭区间运行结果:

python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
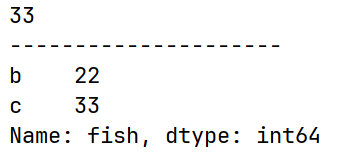
# arrs的iloc[]隐式索引(位置索引或切片)
print(arrs.iloc[2])
print("---------------------")
print(arrs.iloc[1:3]) # 左闭右开区间运行结果:
python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
# arrs的at[]标签(index)访问单个元素
print(arrs.at["c"])运行结果:
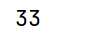
python
import pandas as pd
arrs = pd.Series([11, 22, 33, 44, 55], name="fish", index=["a", "b", "c", "d", "e"])
# arrs的iat[]位置访问单个元素
print(arrs.iat[4])运行结果:
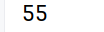
五.Series的常用方法
|-----------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 方法 | 说明 |
| head() | 查看前n行数据,默认5行 |
| tail() | 查看后n行数据,默认5行 |
| isin() | 元素是否包含在参数集合中 |
| isna() | 元素是否为缺失值(通常为 NaN 或 None) |
| sum() | 求和,会忽略 Series 中的缺失值 |
| mean() | 平均值 |
| min() | 最小值 |
| max() | 最大值 |
| var() | 方差 |
| std() | 标准差 |
| median() | 中位数 |
| mode() | 众数(出现频率最高的值),如果有多个值出现的频率相同且都是最高频率,这些值都会被包含在返回的 Series 中 |
| quantile(q,interpolation) | 指定位置的分位数 q的取值范围是 0 到 1 之间的浮点数或浮点数列表,如quantile(0.5)表示计算中位数(即第 50 百分位数); interpolation:指定在计算分位数时,如果分位数位置不在数据点上,采用的插值方法。默认值是线性插值 'linear',还有其他可选值如 'lower'、'higher'、'midpoint'、'nearest' 等 |
| describe() | 常见统计信息 |
| value_count() | 每个元素的个数 |
| count() | 非缺失值元素的个数,如果要包含缺失值,用len() |
| drop_duplicates() | 去重 |
| unique() | 去重后的数组 |
| nunique() | 去重后元素个数 |
| sample() | 随机采样 |
| sort_index() | 按索引排序 |
| sort_values() | 按值排序 |
| replace() | 用指定值代替原有值 |
| to_frame() | 将Series转换为DataFrame |
| equals() | 判断两个Series是否相同 |
| keys() | 返回Series的索引对象 |
| corr() | 计算与另一个Series的相关系数 默认使用皮尔逊相关系数(Pearson correlation coefficient)来计算相关性。要求参与比较的数组元素类型都是数值型。 当相关系数为 1 时,表示两个变量完全正相关,即一个变量增加,另一个变量也随之增加。 当相关系数为 -1 时,表示两个变量完全负相关,即一个变量增加,另一个变量随之减少。 当相关系数为 0 时,表示两个变量之间不存在线性相关性。 例如,分析某地区的气温和冰淇淋销量之间的关系 |
| cov() | 计算与另一个Series的协方差 |
| hist() | 绘制直方图,用于展示数据的分布情况。它将数据划分为若干个区间(也称为 "bins"),并统计每个区间内数据的频数。 需要安装matplotlib包 |
| items() | 获取索引名以及值 |
两种空对象None 和np.nan的区别:
None:Python 空对象,不能运算,判空用is Nonenp.nan:浮点空值,运算结果为nan,判空用np.isnan()None会让数组变object,np.nan保持数值类型np.nan≠np.nan,None==None- 数值数据用
np.nan,非数值用None - Pandas 数值列
None自动转np.nan - 通用判空用
pd.isna(),兼容两种空值
以下为常用方法代码演示:
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# head() 默认查看前5行数据
print(arrs.head())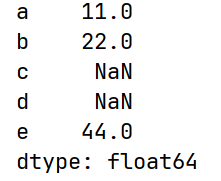
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# tail() 查看后3行数据
print(arrs.tail(3))
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# isin() 元素是否包含在参数集合中,返回一个Series
print(arrs.isin([11]))
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# isna() 元素是否为缺失值(通常为NaN或None)
print(arrs.isna())
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# sum() 会忽略Series中的缺失值
print(arrs.sum())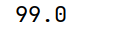
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# mean() 平均值,忽略缺失值
print(arrs.mean()) # 99 / 4 == 24.75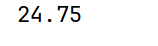
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# min() 最小值,忽略缺失值
print(arrs.min())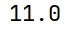
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# max() 最大值,忽略缺失值
print(arrs.max())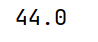
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# var() 方差,忽略缺失值
print(arrs.var())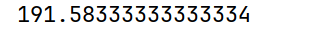
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# std() 标准差,忽略缺失值
print(arrs.std())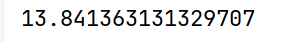
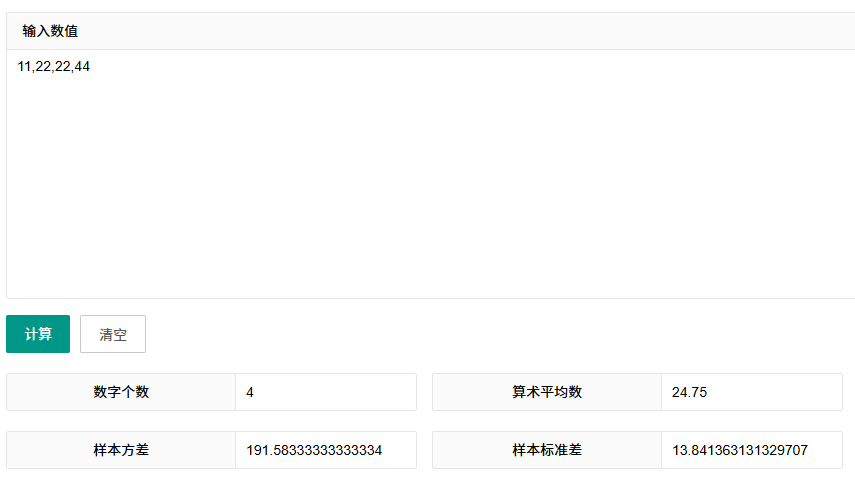
计算器验证方差和标准差:
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# median() 中位数,忽略缺失值
print(arrs.median())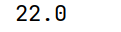
这里除去缺失值,剩下4个数,偶数个数,那么中位数有两个,都是22,平均下来也是22。
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# mode() 众数,忽略缺失值
print(arrs.mode())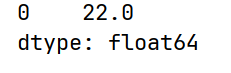
quantile(q,interpolation),interpolation默认为'linear':arrs.quantile(0.25)图例:

下面讲解interpolation的常用5种选项和结果:
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# quantile(q,interpolation),默认为'linear'
print(arrs.quantile(0.25))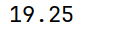
结果解释(权重计算):

python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# quantile(q,interpolation),默认为'linear'
print(arrs.quantile(0.25, interpolation='lower'))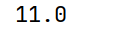
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# quantile(q,interpolation),默认为'linear'
print(arrs.quantile(0.25, interpolation='higher'))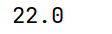
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# quantile(q,interpolation),默认为'linear'
print(arrs.quantile(0.25, interpolation='midpoint'))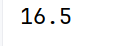
结果解释:

python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# quantile(q,interpolation),默认为'linear'
print(arrs.quantile(0.25, interpolation='nearest'))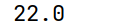
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# 常见统计信息
print(arrs.describe())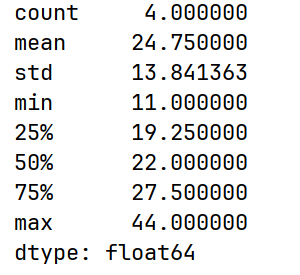
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# value_counts() 每个元素的个数
print(arrs.value_counts())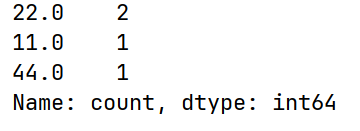
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# count() 非缺失值元素的个数,如果要包含缺失值,用len()
print(arrs.count())
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# drop_duplicates() 去重
print(arrs.drop_duplicates())
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# unique 去重后的数组
print(arrs.unique())
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# nunique() 去重后元素的个数 11 22 44
print(arrs.nunique())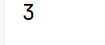
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# sample() 随机采样
print(arrs.sample())
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# sort_index() 按索引排序
print(arrs.sort_index())
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# sort_values() 按值排序
print(arrs.sort_values())
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# replace() 用指定值代替原有值
print(arrs.replace(22, 'haha'))
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# to_frame() 将series转换为DataFrame,DataFrame在下一篇讲
print(arrs.to_frame())
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# keys() 返回Series的索引对象
print(arrs.keys())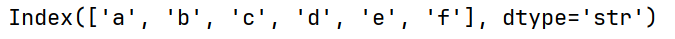
python
import pandas as pd
import numpy as np
arrs = pd.Series([11,22,np.nan,None,44,22],index=['a','b','c','d','e','f'])
# items() 获取索引名以及值
for i,v in arrs.items():
print(i,v)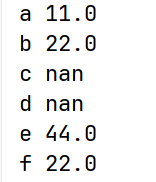
python
import pandas as pd
import numpy as np
# equals() 判断两个Series是否相同
arr1 = pd.Series([1,2,3])
arr2 = pd.Series([1,2,3])
print(arr1.equals(arr2))
python
import pandas as pd
import numpy as np
# equals() 判断两个Series是否相同
arr1 = pd.Series([1,2,3])
arr2 = pd.Series([1,2,3])
# print(arr1.equals(arr2))
# corr() 计算与另一个Series的相关系数
# arr1.corr(arr2):由于 arr1 和 arr2 的值完全相同,它们之间是完全正相关的,
# 因此相关系数为 1。
# arr1.corr(arr3):arr1 的值是递增的,而 arr3 的值是递减的,它们之间是完全
# 负相关的,所以相关系数为 -1。
# arr1.corr(arr4):arr1 和 arr4 的值都是递增的,且变化趋势一致,它们之间是
# 完全正相关的,相关系数为 1。
# arr5.corr(arr6):arr5 和 arr6 的值之间没有明显的线性关系,它们的相关系数
# 为 0。
arr3 = pd.Series([3,2,1])
arr4 = pd.Series([6,7,8])
arr5 = pd.Series([1, -1, 1, -1])
arr6 = pd.Series([1, 1, -1, -1])
print(arr1.corr(arr2))
print(arr1.corr(arr3))
print(arr1.corr(arr4))
print(arr5.corr(arr6))
相关系数就是用来衡量两个变量线性相关程度强弱与方向 的数值,范围在 -1 到 1 之间。
python
import pandas as pd
import numpy as np
arr1 = pd.Series([1,2,3])
arr3 = pd.Series([3,2,1])
# cov() 计算与另一个Series的协方差
# 协方差用于衡量两个变量的总体误差,其值的正负表示两个变量的变化方向关系:
# 正值表示同向变化,负值表示反向变化。
print(arr1.cov(arr3))协方差用于衡量两个变量总体误差的同向 / 反向变化趋势,只反映相关方向,不体现强度。
协方差和相关系数的区别:
- 协方差:看同向还是反向变化 ,受量纲(单位)影响,所以数值大小无法直接说明线性相关强弱(除非同类型同单位数据) ,只能判断方向是同向还是反向。
- 相关系数:是标准化后的协方差 ,消除量纲(单位),直接表示线性相关强弱与方向,范围固定在 -1,1。
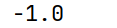
python
import pandas as pd
import numpy as np
# hist() 绘制直方图
arr7 = pd.Series([3,2,1,1,1,2,2])
# 绘制直方图
# 直方图(Histogram)是一种用于展示数据分布的统计图表,它通过将数据划分为
# 若干个连续的区间( bins ),统计每个区间内数据的频数或频率,并用矩形条的
# 高度表示该区间的数值分布情况
arr7.hist(bins=3)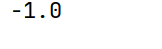
这里需要后面学到并安装matplotlib包才能展示出直方图。
六.Series的布尔索引
可以使用布尔索引从Series中筛选满足某些条件的值。
python
import pandas as pd
import numpy as np
s = pd.Series({"a":-1.2, "b":3.5, "c":6.8, "d":2.9})
bools = s > s.mean()
print(bools)
python
import pandas as pd
import numpy as np
s = pd.Series({"a":-1.2, "b":3.5, "c":6.8, "d":2.9})
bools = s > s.mean()
# print(bools)
print(s[bools])
七.Series与Series运算
会根据标签索引进行对位计算,索引没有匹配上的会用NaN填充。
python
import pandas as pd
import numpy as np
s1 = pd.Series([1, 1, 1, 1])
s2 = pd.Series([2, 2, 2, 2], index=[1, 2, 3, 4])
print(s1 + s2)