YOLOv5 与 Fast R-CNN:模型原理、结构机制、核心参数、评价指标及应用场景对比分析
目标检测难的地方,不只是"能不能识别出来",还在于"速度、精度和部署成本如何平衡"。YOLOv5 代表单阶段检测思路,强调实时性和工程落地;Fast R-CNN 代表两阶段检测思路,强调候选区域建模和区域级判别。本文从原理、结构、参数、指标和应用场景五个层面展开,对两者做一篇适合初学者阅读、也能直接用于选型参考的对比分析。
1 引言:目标检测背景与技术路线
1.1 目标检测任务的定义与难点
目标检测(Object Detection)旨在对输入图像/视频中的目标实例同时完成两类预测:
- 类别识别:目标属于哪一类;
- 空间定位:目标在图像中的边界框(Bounding Box)位置与尺度。
相比图像分类只回答"是什么",目标检测还要回答"在哪里"。这带来的难点主要有四个:目标大小差异大、目标之间会遮挡、背景容易干扰判断、定位稍有偏差就会明显影响最终指标。
1.2 单阶段与两阶段:两条主线解决同一问题
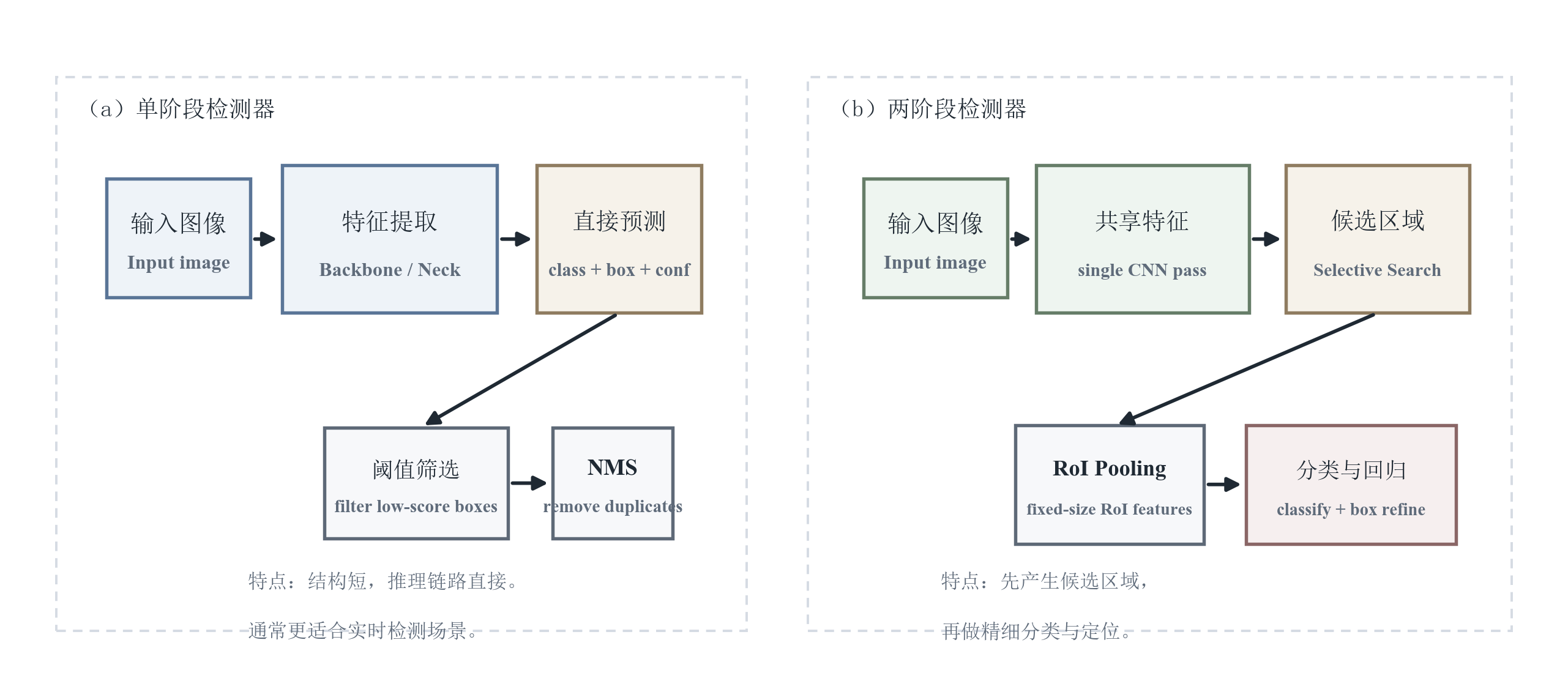
深度学习目标检测的经典分流可概括为两类范式:
- 单阶段检测器(One-Stage Detector):直接在特征图上做密集预测,同时回归边界框与类别/置信度,例如 YOLO 系列、SSD、RetinaNet。
- 两阶段检测器(Two-Stage Detector):先生成候选区域(Region Proposal),再对每个候选区域进行分类与框回归精修,例如 R-CNN 系列(R-CNN、Fast R-CNN、Faster R-CNN)。
两者的差别不只是"谁更快、谁更慢",更重要的是思路不同:单阶段方法直接在特征图上预测结果;两阶段方法先找"可能有目标的区域",再对这些区域做更细的分类和定位。
1.3 为什么对比 YOLOv5 与 Fast R-CNN
YOLOv5 与 Fast R-CNN 分别代表了目标检测中两类设计哲学:
- YOLOv5:以工程可用性与端到端高吞吐为核心目标,强调部署与速度约束下的整体最优。
- Fast R-CNN:以方法学改进为核心,强调特征共享、RoI 特征规整与多任务联合学习,对后续两阶段检测器的结构范式影响深远。
本文会按照"它是什么、为什么这样设计、会带来什么影响、适合什么场景"的顺序展开,而不是只给出简单的快慢结论。
本节小结:目标检测本质上是"分类 + 定位"的联合任务。YOLOv5 和 Fast R-CNN 的核心区别,不在名字,而在于它们解决问题的路径不同。
2 YOLOv5:定位与工程特征
2.1 YOLO 系列的基本脉络
YOLO(You Only Look Once)最早的核心思想,是把目标检测写成一次前向传播就能完成的端到端预测问题。之后的版本主要围绕以下几个方向持续改进:
- 锚框(Anchor)与多尺度特征:提高不同尺度目标的覆盖能力;
- 更强的特征融合(Feature Fusion)结构:改善小目标与复杂背景下的表征;
- 训练策略与工程细节:数据增强、损失设计、部署导出链路等。
2.2 YOLOv5 的核心定位:可训练、可部署、可裁剪
YOLOv5 通常被理解为一套以 PyTorch 为基础、工程化程度较高的目标检测框架,其价值主要体现在:
- 提供多尺度模型规模(如 n/s/m/l/x 等系列),便于在算力约束下做容量-速度折中;
- 以"Backbone--Neck--Head"模块化方式组织结构,降低替换与裁剪成本;
- 训练与部署链路相对完整,便于在真实业务中形成闭环(数据→训练→导出→加速→上线)。
2.3 相比传统两阶段方法的结构性差异
YOLOv5 与两阶段方法的差异,并不只是"少了候选区域"这么简单,更关键的是:
- 计算图的组织方式:单阶段在多尺度特征图上做密集预测;两阶段先产生候选区域,再对 RoI 做特征规整与精修。
- 误差来源:单阶段的误差更集中在密集候选与后处理抑制策略(如 NMS);两阶段的误差还包含候选区域质量与 RoI 对齐误差等。
- 工程常见约束:单阶段通常更易达到实时吞吐;两阶段往往在复杂场景下更容易获得稳定的区域级判别能力(但代价是计算开销与系统复杂度)。
2.4 典型工程优势(以"可交付"为目标的视角)
在工程项目里,YOLOv5 的优势通常表现为:
- 端到端推理链路短:便于做模型加速、批处理、并行化与边缘端部署;
- 对输入分辨率/模型规模更敏感:通过调节输入尺寸与模型规模可快速得到可接受的吞吐;
- 适配实时视频流:在监控、工业产线、机器人等场景中,吞吐与延迟往往优先于极限精度。
本节小结:YOLOv5 的优势是快、链路短、易部署;不足是对阈值和后处理更敏感,在小目标、密集目标场景下更容易出现漏检或误抑制。
3 Fast R-CNN:提出动机与方法学意义
3.1 R-CNN → Fast R-CNN → Faster R-CNN:演进关系(不混淆边界)
R-CNN 系列在两阶段检测的发展中具有清晰的递进关系:
- R-CNN(Regions with CNN features):对每个候选区域分别进行 CNN 特征提取,再分类与回归;计算重复严重、训练分阶段。
- Fast R-CNN :将整图卷积特征共享,仅对候选区域做 RoI Pooling 并在统一网络内进行分类与回归的联合训练,显著降低重复计算与训练复杂度。
- Faster R-CNN:将候选区域生成模块替换为区域提议网络(Region Proposal Network, RPN),实现候选区域的深度学习化与更紧耦合的端到端训练。
需要特别说明:Fast R-CNN 通常依赖外部候选区域算法(如 Selective Search),本身并不包含 RPN。把 Fast R-CNN 和 Faster R-CNN 混为一谈,会直接影响对其速度瓶颈和结构特点的理解。
3.2 Fast R-CNN 的提出背景:问题指向"重复计算+非联合优化"
Fast R-CNN 的提出,主要是为了解决 R-CNN 的两个核心问题:
- 重复计算:R-CNN对每个候选区域独立跑 CNN,导致同一图像的卷积计算被重复执行。
- 训练割裂:特征提取、分类器(如 SVM)与边框回归在多个阶段独立训练,难以做端到端联合优化。
3.3 相对 R-CNN 的关键改进与影响链条
Fast R-CNN 的关键改进可以映射为"机制---影响":
- 整图特征共享(Shared Convolutional Features) → 卷积仅计算一次 → 推理与训练效率显著提升;
- 感兴趣区域池化(Region of Interest Pooling, RoI Pooling) → 将任意尺寸 RoI 规整为固定尺寸特征 → 统一接入全连接层;
- 多任务联合损失(Multi-task Loss) → 分类与定位联合学习 → 训练更一致、收敛更稳定;
- (可选)全连接层压缩(Truncated SVD) → 减少全连接计算量 → 进一步加速推理。
3.4 方法学意义:两阶段范式的"结构模板"
Fast R-CNN 把两阶段检测器的核心结构模板固化为:
候选区域 → RoI 特征规整 → 分类/回归双分支 → 多任务损失。
该模板不仅影响了后续 Faster R-CNN 与其变体,也影响了大量以 RoI 为中心的实例级视觉任务(例如实例分割、关键点等)的网络组织方式。
本节小结:Fast R-CNN 的意义不在于"快到能实时",而在于它把两阶段检测从低效、割裂的流程,推进成了更清晰、更可扩展的结构范式。
4 YOLOv5 核心原理:单阶段密集预测的机制与代价
4.1 单阶段检测机制:在多尺度特征图上做密集预测
YOLOv5 会在多个尺度的特征图上直接做预测。对每个位置(以及对应锚框)同时预测:
- 边界框参数(Bounding Box Regression);
- 目标置信度(Objectness / Confidence);
- 类别概率(Class Probability)。
其关键点在于:候选框生成与分类/回归是同一前向过程中的输出,而不是显式的"先 proposal 再分类"的串行结构。
4.2 边界框回归:参数化设计为何重要
边界框回归通常不是"从零开始猜框",而是学习相对锚框的偏移量。这样做的好处是:
- 降低输出空间的自由度,改善梯度稳定性;
- 让网络更容易学习不同尺度目标的相对变化;
- 与多尺度特征图结合,实现对尺度分布更稳健的覆盖。
在损失层面,现代检测器常使用基于 IoU 的回归损失(如 GIoU/DIoU/CIoU 等变体)以更直接地约束框的几何关系;其工程意义在于:在相同分类置信度下,定位误差对最终 AP/mAP 的影响会被显式放大,因此回归损失的选择会显著影响收敛速度与定位稳定性。
4.3 类别预测与目标置信度:分解式建模的含义
YOLOv5 通常将"是否有目标"与"属于什么类别"分解为两个预测:
- 目标置信度反映该位置/锚框上是否存在目标以及定位可靠性;
- 类别概率反映目标属于各类别的概率分布。
这样做的意义在于:目标置信度先负责判断"这里有没有目标",类别概率再去判断"它是什么",分工更清楚,也更利于训练。
4.4 交并比与后处理:IoU 与 NMS 的必要性与副作用
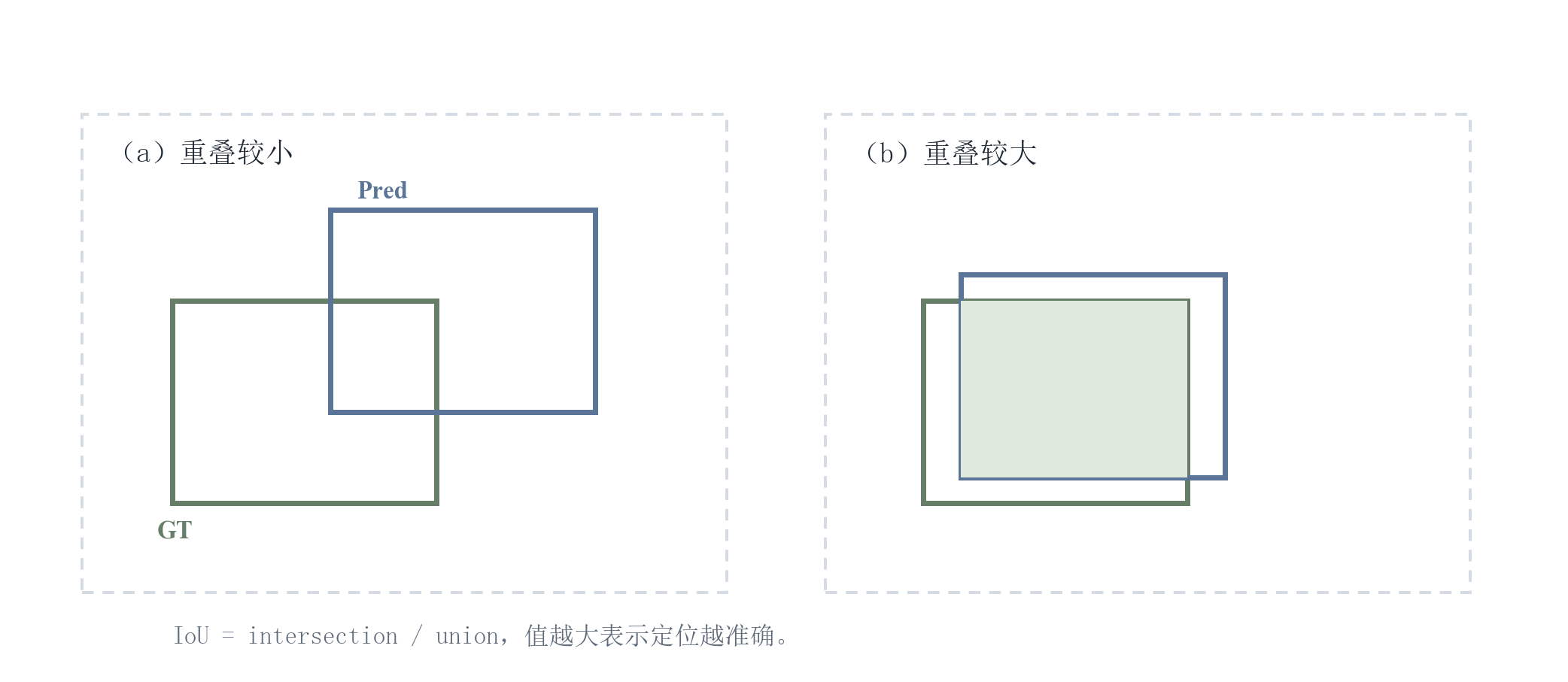
交并比(Intersection over Union, IoU)是定位质量的基本度量,描述预测框与真实框的重叠程度。IoU 不仅用于训练时正负样本匹配,也用于推理阶段的后处理。
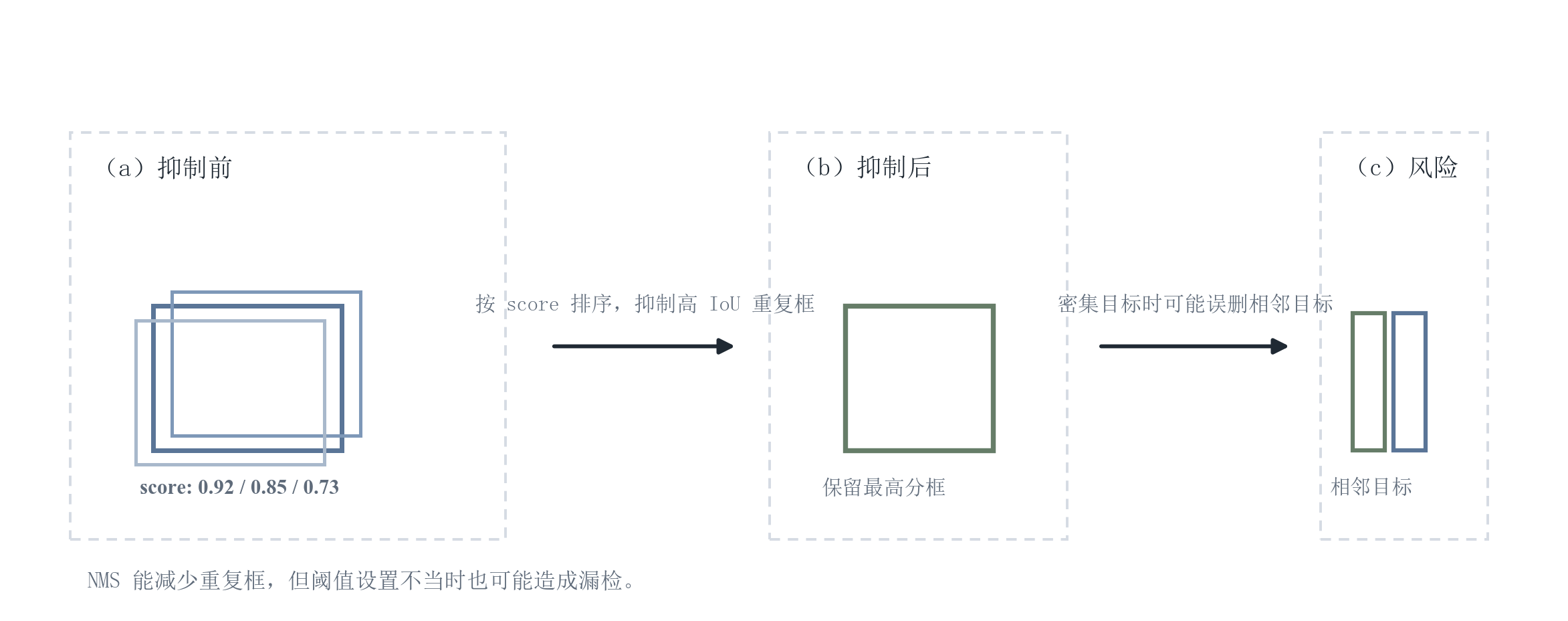
非极大值抑制(Non-Maximum Suppression, NMS)用于去除重复检测框:
- 按置信度排序候选框;
- 选择最高置信度框作为保留框;
- 抑制与其 IoU 超过阈值的其他框;
- 迭代直到候选集处理完毕。
需要注意:NMS 既是必要机制,也是误差来源之一。其典型副作用是:在密集目标、小目标邻近、遮挡严重时,合理的抑制阈值往往很难同时兼顾 Precision 与 Recall。
4.5 多尺度检测:为何能改善小目标但不能"保证"
多尺度检测的核心,是在不同分辨率的特征图上预测不同大小的目标。对小目标来说,高分辨率特征图更重要;但效果仍受以下因素限制:
- 特征融合是否把高层语义有效传递到高分辨率特征;
- 锚框/样本匹配策略是否覆盖小目标尺度分布;
- NMS 在密集小目标下的抑制冲突。
4.6 训练与推理:端到端不等于"无超参数"
YOLOv5 的训练包括数据增强、样本匹配、损失加权和学习率调度;推理则包括前向预测、阈值过滤和 NMS。
所以,"端到端"不等于"不需要调参",输入分辨率、阈值、锚框和增强策略都会明显影响结果。
本节小结:YOLOv5 的本质是"直接预测"。它速度快,但对阈值、NMS 和多尺度特征融合比较敏感。
5 Fast R-CNN 核心原理:候选区域驱动的区域级判别
5.1 候选区域:为何要先"缩小搜索空间"
候选区域(Region Proposal)的作用,是把"整张图都要检查"变成"只检查可能有目标的区域"。Fast R-CNN 常用选择性搜索(Selective Search)生成候选框,其优势在于:
- 候选区域通常具有较高召回率,可覆盖大部分真实目标;
- 后续模型可以把计算集中在候选区域上,进行更强的区域级特征判别。
但代价也很明显:候选区域生成本身不是学习得到的,而且速度不快,这也是 Fast R-CNN 难以做到高实时性的原因之一。
5.2 卷积特征共享:Fast R-CNN 的效率核心
Fast R-CNN 最关键的改进,就是"整张图只做一次卷积"。具体流程是:
输入图像 → CNN 提取整图特征图 → 将每个候选区域映射到特征图坐标系 → 从特征图中抽取该区域特征。
这一机制把 R-CNN 的"每个 proposal 跑一遍 CNN"改写为"proposal 仅做轻量 RoI 操作",从根本上消除了重复卷积计算。
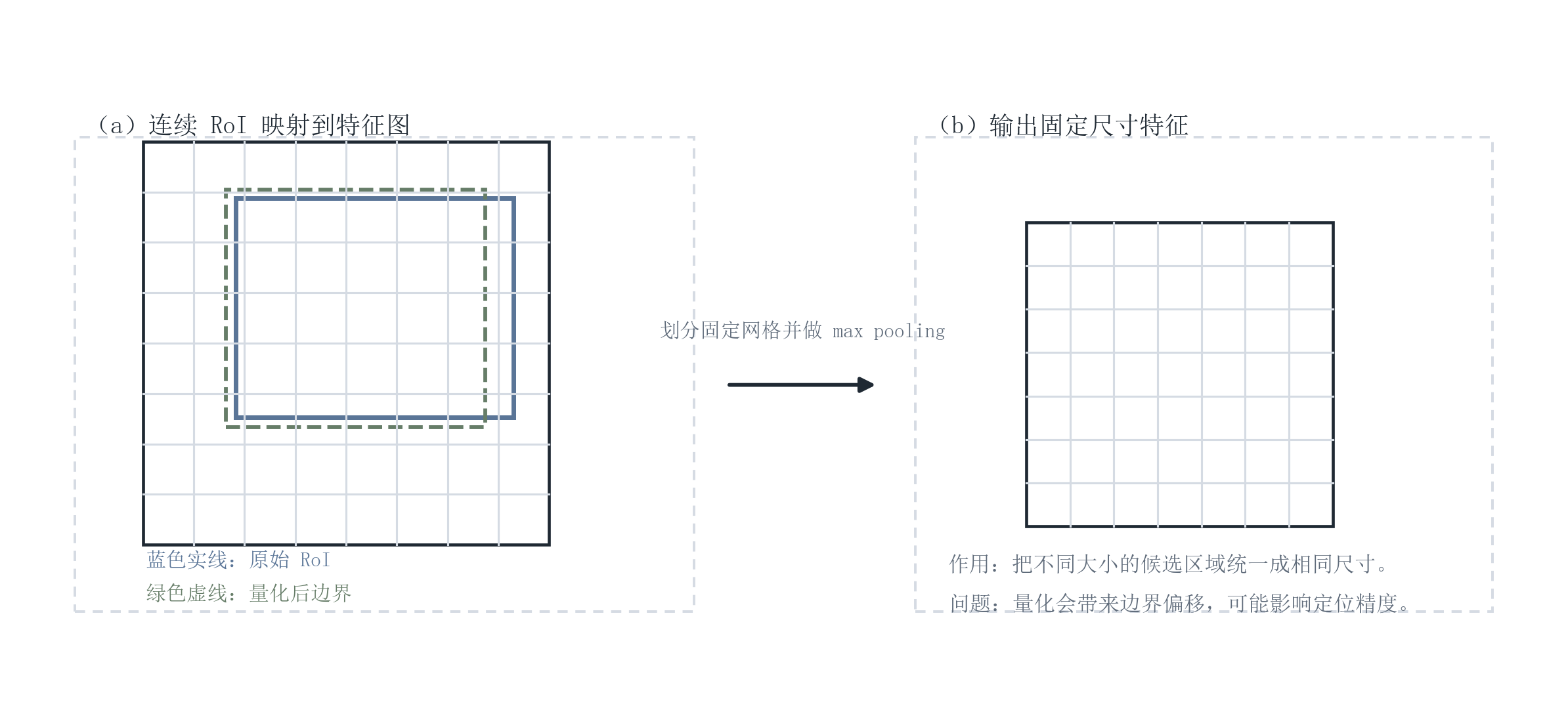
5.3 感兴趣区域池化(RoI Pooling):可计算性的代价来自量化
RoI Pooling 的目标是:将不同尺寸的候选区域统一变为固定尺寸的特征(例如 7×7),以便接入全连接层。其实现通常包含:
- 将 RoI 划分为固定网格;
- 对每个网格单元做最大池化(Max Pooling)。
该过程会引入量化误差,所以定位到边界时可能不够精确。后续方法中的感兴趣区域对齐(Region of Interest Align, RoI Align)就是为了解决这个问题,但它不属于 Fast R-CNN 本身。
5.4 分类与边界框回归:联合建模与多任务损失
Fast R-CNN 通常包含两个输出分支:
- 分类分支:输出每个 RoI 的类别分布(包含背景类);
- 回归分支:输出边界框精修偏移量,实现定位细化。
多任务损失(Multi-task Loss)将分类与定位统一优化,常见形式为:
L = L_cls + λ · 1u≠bg · L_loc
其中 L_cls 为分类损失(如交叉熵),L_loc 为定位损失(如 Smooth L1),仅对非背景 RoI 计算定位损失。
5.5 相对 R-CNN 的效率优化逻辑:瓶颈从卷积转移到 proposal 与 RoI
Fast R-CNN 把主要计算从"逐 RoI 的卷积前向"转移到:
- 候选区域生成(Selective Search 等);
- 大量 RoI 的 RoI Pooling 与全连接分类/回归。
因此,Fast R-CNN 的速度瓶颈与工程表现高度依赖:候选区域数量、RoI 批处理策略、以及 backbone 的计算规模。
本节小结:Fast R-CNN 的本质是"候选区域→区域级判别",通过卷积特征共享显著提升了相对 R-CNN 的效率,但仍受制于外部 proposal 与大量 RoI 处理带来的吞吐瓶颈;其结构模板与多任务联合学习思想对两阶段检测器具有长期影响。
6 模型结构详解(YOLOv5):Input--Backbone--Neck--Head
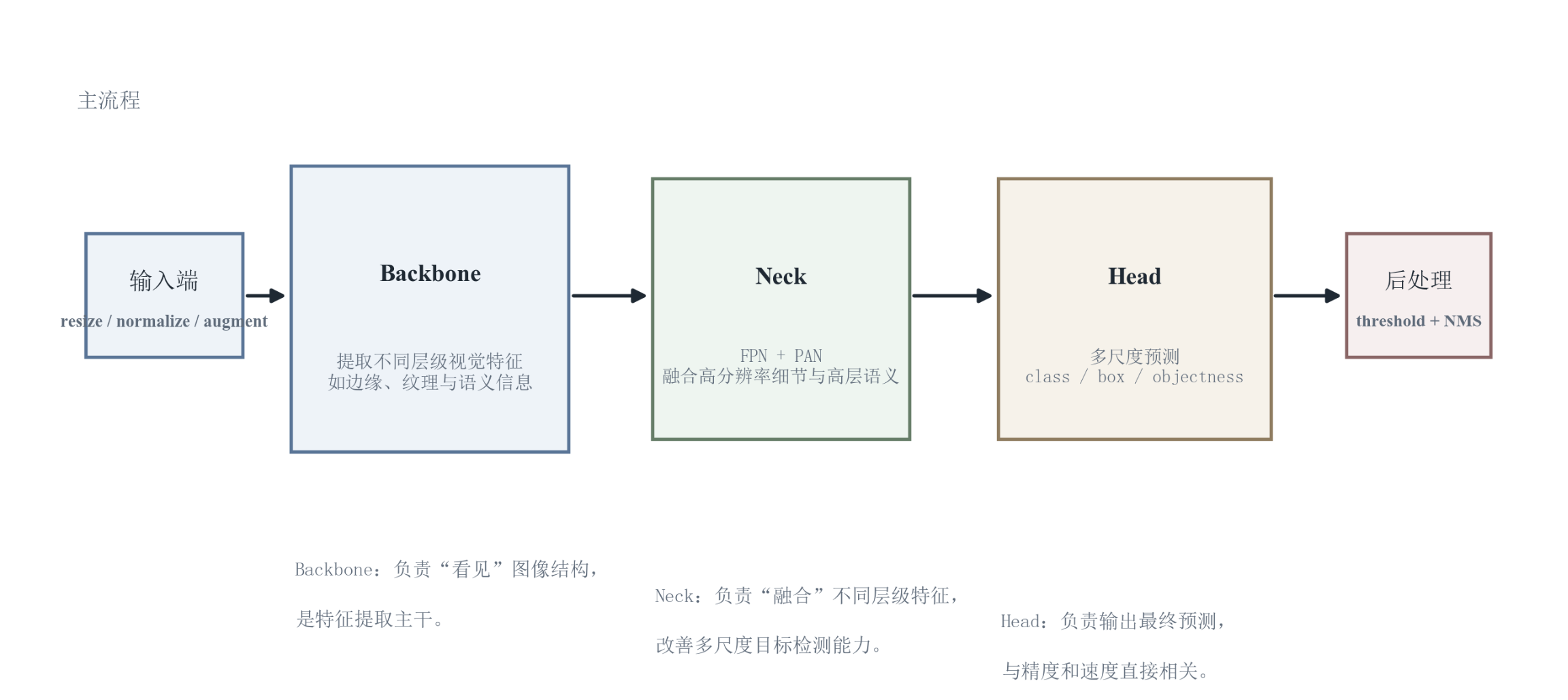
6.1 总体结构与数据流
YOLOv5 通常可分为四部分:输入(Input)、骨干网络(Backbone)、颈部网络(Neck)与检测头(Head)。其数据流可以概括为:
输入图像 → Backbone 提取多层特征 → Neck 进行多尺度特征融合 → Head 在多尺度特征图上输出密集预测 → NMS 得到最终检测框。
6.2 Input:预处理与分辨率选择的工程含义
Input 端通常包含:缩放/填充(保持比例的 letterbox)、归一化、以及训练阶段的数据增强(如 Mosaic 等)。
- 为什么重要:输入分辨率直接决定特征图空间分辨率与计算量,是速度---精度权衡的第一控制旋钮;数据增强则改变有效数据分布,影响泛化与小目标学习难度。
6.3 Backbone:表征能力与计算量的主来源
Backbone 的任务是把像素空间映射到可分离的语义特征空间。YOLOv5 常见 backbone 设计包含:
- CSP(Cross Stage Partial)类结构以降低计算冗余并改善梯度流;
- SPP(Spatial Pyramid Pooling)类模块以扩展感受野与上下文融合。
机制---影响:更强的 backbone 往往提升特征可分性,从而提升分类与定位的上限,但也显著增加 FLOPs 与延迟,进而影响实时性与边缘部署可行性。
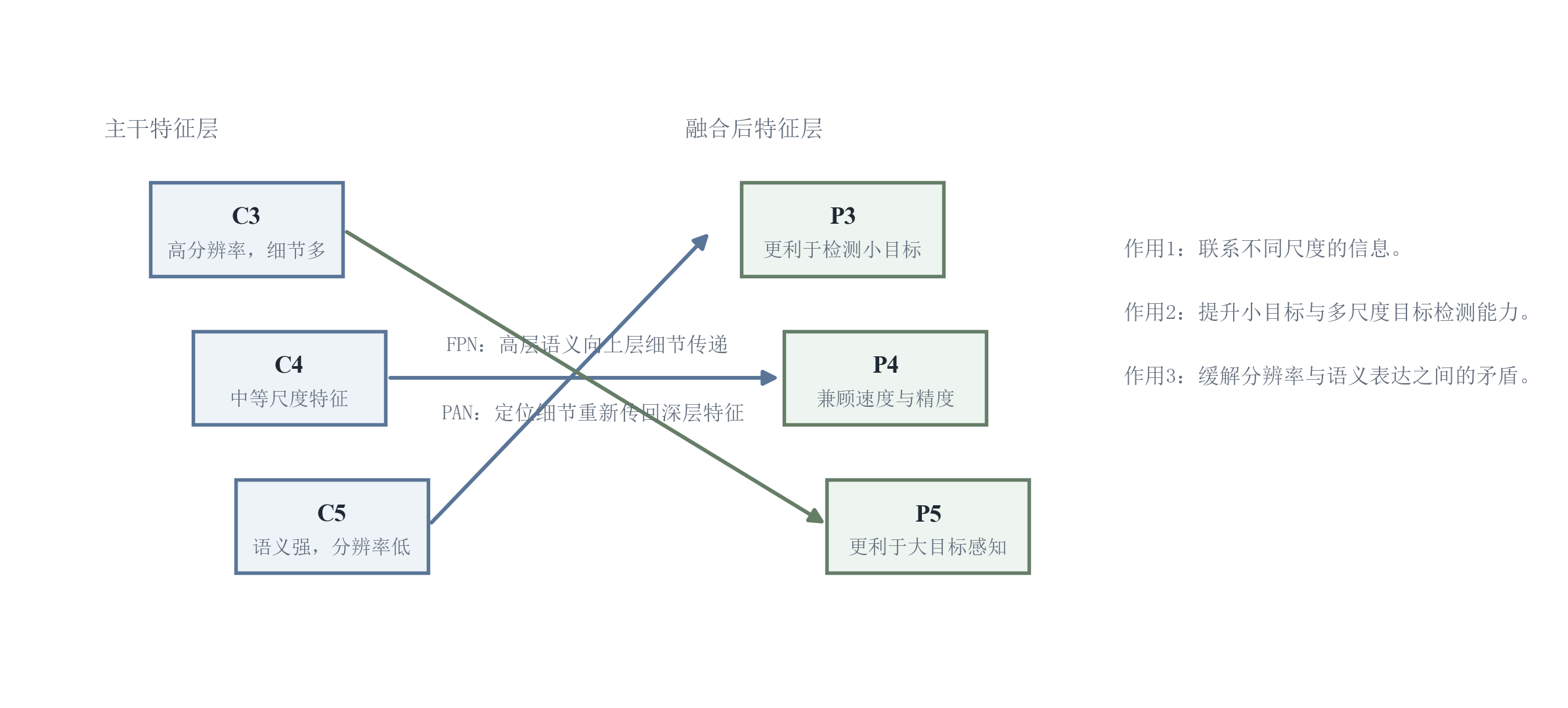
6.4 Neck:多尺度特征融合解决"语义---分辨率"矛盾
Neck 的核心目标是融合不同层级特征:
- 高层特征语义强但分辨率低;
- 低层特征分辨率高但语义弱。
特征金字塔网络(Feature Pyramid Network, FPN)与路径聚合网络(Path Aggregation Network, PAN)类路径融合常用于把语义信息回流到高分辨率特征,同时把细节信息传递到低分辨率特征,从而提升多尺度目标(尤其小目标)的可检测性。
6.5 Head:密集预测的输出组织方式
Head 在多个尺度特征图上输出每个位置/锚框的预测向量(框回归、置信度、类别)。
需要强调:密集预测意味着输出候选框数量非常大,因而推理阶段必须依赖置信度阈值过滤与 NMS 才能得到可用输出;这也是单阶段检测器对阈值策略更敏感的结构性原因。
6.6 关键设计思想小结:模块化、可裁剪、可部署
YOLOv5 的结构价值更多体现在:把检测过程组织为可替换模块(Backbone/Neck/Head)与可规模化配置(模型大小、输入分辨率、导出后端),便于在"资源---精度---吞吐"的约束下做工程最优。
本节小结:YOLOv5 的结构核心是"多尺度特征融合 + 多尺度密集预测"。Backbone 决定上限、Neck 决定多尺度适配、Head 决定输出形式与后处理敏感性;工程上输入分辨率、模型规模与部署后端共同决定最终可交付性能。
7 模型结构详解(Fast R-CNN):Proposal--RoI Pooling--双分支输出
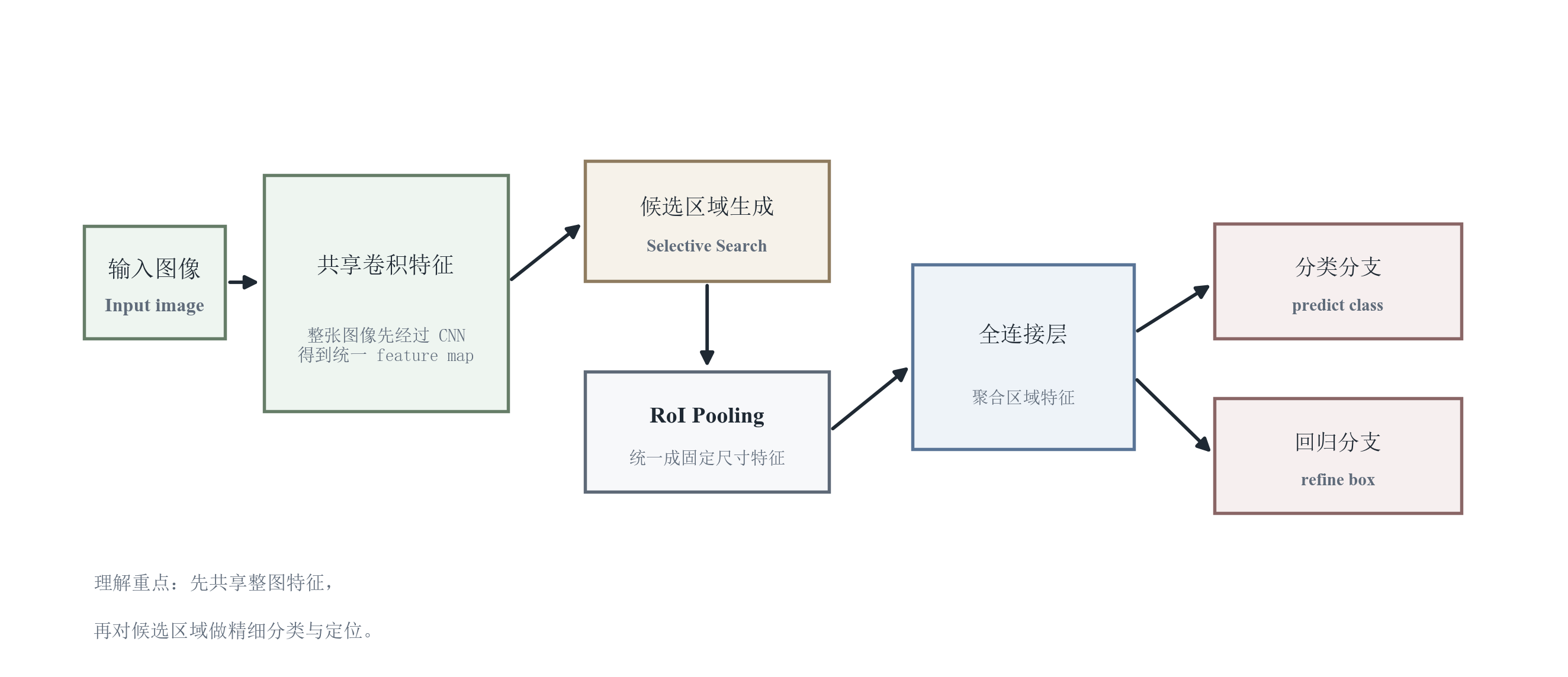
7.1 整体前向流程概览
Fast R-CNN 的前向流程可概括为:
输入图像 → CNN 提取整图特征图 → 外部算法生成候选区域(proposal) → 将 proposal 映射到特征图坐标 → RoI Pooling 得到固定尺寸 RoI 特征 → 全连接层 → 分类分支与回归分支输出。
7.2 输入图像与卷积特征提取:一次卷积,多次 RoI
卷积特征提取阶段对整图执行一次 CNN 前向,得到共享特征图。其关键工程意义是:
- 卷积是最昂贵的计算环节之一,整图共享可显著降低重复计算;
- 共享特征图使得所有候选区域处于同一语义空间,便于统一训练与比较。
7.3 候选区域映射:坐标系一致性是正确性的前提
proposal 通常在原图坐标系产生,需要映射到特征图坐标系(按 stride 缩放),才能从特征图裁剪 RoI 区域。该步骤的误差会放大到定位输出,尤其在小目标上更敏感。
7.4 RoI Pooling:固定尺寸 RoI 特征的"接口层"
RoI Pooling 作为接口层把变长 RoI 变为定长特征张量,使得后续全连接分类/回归成为可能。
其设计动机是"统一输入维度",代价是量化引入的对齐误差;这也是两阶段检测器在结构层面更关注对齐精度的原因之一。
7.5 全连接层与双分支输出:区域级判别与精修
全连接层在 RoI 级别聚合特征后分出两个分支:
- 分类分支输出类别概率(含背景);
- 回归分支输出边界框偏移量用于精修。
这体现了两阶段方法的核心思想:先缩小搜索范围,再对重点区域做更精细的判断。
本节小结:Fast R-CNN 的结构以 RoI 为中心组织计算:卷积共享提升效率,RoI Pooling提供固定维度接口,双分支输出实现分类与定位精修。其速度上限受 proposal 生成与 RoI 数量影响,精度表现则高度依赖 proposal 质量与 RoI 对齐误差控制。
8 核心参数(超参数)与调参逻辑:从定义到影响
这一节不只解释参数是什么,也说明参数为什么重要、改大改小会带来什么影响。
8.1 YOLOv5 关键参数(训练与推理)
| 参数 | 定义 | 作用机制 | 调整影响(训练/推理/效果) |
|---|---|---|---|
| 输入尺寸(img_size) | 训练/推理的输入分辨率 | 改变特征图分辨率与候选密度 | 增大:小目标更易被表征,但计算量与延迟上升;减小:吞吐提升但定位变粗 |
| 模型规模(n/s/m/l/x 等) | 网络深度/宽度的配置 | 改变表征容量与计算量 | 规模增大:上限通常更高但更慢、更耗显存;规模减小:更易部署但可能欠拟合复杂场景 |
| 锚框(anchors) | 先验框尺寸集合 | 影响正样本匹配与回归难度 | 与数据尺度不匹配会导致回归困难与召回下降;通常需结合数据集分布调整/自适应 |
| 置信度阈值(conf_thres) | 过滤低置信度候选的阈值 | 控制候选进入 NMS 的数量 | 提高:Precision 可能上升但 Recall 下降;降低:Recall 上升但误检与 NMS 冲突增大 |
| NMS IoU 阈值(iou_thres) | NMS 的抑制阈值 | 控制重复框抑制强度 | 降低:抑制更强,密集目标更易漏检;提高:保留更多框,重复框风险上升 |
| 学习率(learning_rate)与调度 | 参数更新步长及其变化策略 | 决定收敛速度与稳定性 | 过大易震荡/发散,过小收敛慢;调度影响最终收敛点与泛化 |
| 批量大小(batch_size) | 每次迭代的样本数 | 影响梯度估计噪声与显存 | 增大:训练更稳定但显存占用更高;过小:收敛不稳需配合学习率调整 |
| 数据增强(Mosaic/MixUp 等) | 训练时的样本变换策略 | 改变有效数据分布 | 通常提升泛化与小目标鲁棒性,但可能增加训练不稳定与收敛时间;需与数据域一致 |
8.2 Fast R-CNN 关键参数(训练与推理)
| 参数 | 定义 | 作用机制 | 调整影响(训练/推理/效果) |
|---|---|---|---|
| 候选区域数量(#proposals) | 每张图的 proposal 数 | 决定 RoI 级别计算规模与召回上限 | 增大:Recall 可能上升但速度明显下降;过少:易漏检,尤其小目标/遮挡目标 |
| 候选区域生成方法 | Selective Search 等 | 决定 proposal 的质量与分布 | proposal 质量决定检测上限;域外场景下 proposal 可能系统性偏移 |
| RoI Pooling 输出尺寸 | RoI 规整后的特征分辨率 | 决定 RoI 特征表达粒度 | 增大:保留更多空间细节但计算上升;过小:细节丢失影响定位/小目标 |
| 正负样本 IoU 阈值 | 判定 RoI 为正/负样本的 IoU 规则 | 影响训练样本分布 | 阈值更严:正样本更少但更"干净";更松:正样本更多但噪声增大 |
| 骨干网络(backbone) | VGG/ResNet 等 | 决定特征表达与计算量 | 更强 backbone 提升上限但增加延迟;需与 RoI 数量共同考虑 |
| NMS 阈值 | 输出框去重的阈值 | 控制重复框抑制强度 | 与 YOLO 类似:阈值越低抑制越强,密集目标更易漏检 |
| RoI batch 采样策略 | 每次迭代采样的 RoI 数与比例 | 控制类别不平衡与学习稳定性 | 采样不当会导致背景主导或正样本过少,影响收敛与召回 |
8.3 调参的"因果链"建议(可复用)
调参时,建议先看现象,再决定改哪个参数:
- 漏检多:优先检查输入分辨率、proposal 数量(两阶段)、conf_thres 与 NMS 阈值(单阶段)、以及小目标尺度覆盖(anchors/特征融合)。
- 误检多:优先检查 conf_thres、分类头的类别不均衡、以及训练数据负样本定义与标注一致性。
- 密集场景重复框/互相抑制:把 NMS 阈值视为结构性开关,必要时采用更细粒度的类别/场景策略。
本节小结:参数不是孤立的数字,而是控制模型行为的"旋钮"。看懂参数与现象之间的关系,调参才会更高效。
9 输出指标体系:如何读懂"精度、速度与成本"
指标的作用,不是简单给模型排个名次,而是帮助我们理解模型到底强在哪里、弱在哪里。
9.1 指标说明表(Precision/Recall 到 mAP)
| 指标 | 含义(简化定义) | 主要用途 | 指标高低如何解释 | 比较时的注意事项 |
|---|---|---|---|---|
| 精确率(Precision, P) | 预测为正的样本中有多少是真的 | 控制误检 | 高:误检少 | 易受阈值影响,必须说明阈值策略 |
| 召回率(Recall, R) | 真实为正的样本中有多少被检出 | 控制漏检 | 高:漏检少 | 同样受阈值与 NMS 影响,需结合 P 一起读 |
| F1 值(F1-score, F1) | P 与 R 的调和平均 | 综合权衡 | 高:整体更均衡 | 不同任务对 P/R 权重不同,F1并非通用最优目标 |
| 交并比(Intersection over Union, IoU) | 预测框与真实框的重叠程度 | 衡量定位质量、匹配正负样本 | 高:定位更准 | IoU 对小目标更敏感;不同数据集/标注规范会影响可比性 |
| 平均精度(Average Precision, AP) | P--R 曲线下的面积(按某 IoU 阈值) | 类别级精度评价 | 高:该类别检测更好 | AP 依赖阈值扫描与 IoU 设定,需说明 IoU 条件 |
| 平均精度均值(mean Average Precision, mAP) | 多类别 AP 的平均 | 总体检测效果 | 高:总体更好 | 类别不均衡时需结合每类 AP 与业务重要类别解读 |
| mAP@0.5 | 在 IoU=0.5 条件下的 mAP | 更"宽松"的定位评价 | 高:在宽松定位下效果好 | 不能代表严格定位能力 |
| mAP@0.5:0.95 | 在多个 IoU 阈值上取平均的 mAP | 更严格、综合的定位+分类评价 | 高:定位更稳定、整体更强 | 往往更能区分定位质量,但也更难提升 |
9.2 速度与成本指标:FPS、延迟、参数量与 FLOPs
| 指标 | 含义 | 用途 | 解释方式 | 注意事项 |
|---|---|---|---|---|
| 每秒帧数(Frames Per Second, FPS) | 每秒处理帧数 | 吞吐评估 | 高:吞吐强 | 受 batch、硬件、输入尺寸、后处理影响,必须说明测试条件 |
| 推理延迟(Latency) | 单次推理耗时(含/不含后处理) | 实时性评估 | 低:响应快 | 实时系统更关注 P99 延迟;需明确是否包含 NMS/预处理 |
| 参数量(#Params) | 模型权重数量 | 存储与部署评估 | 小:模型更轻 | 参数少不必然快;算子类型与内存访问也关键 |
| 浮点运算量(Floating Point Operations, FLOPs) | 浮点运算量的近似度量 | 计算复杂度对比 | 小:理论计算更少 | 与真实延迟不完全等价,需结合硬件与算子实现 |
9.3 指标之间的结构性关系(避免误读)
- 在相同训练数据与标注质量下,mAP@0.5:0.95 更敏感于定位误差;因此两模型在 mAP@0.5 接近时,mAP@0.5:0.95 的差异往往反映了定位稳定性差异。
- FPS 与延迟不是同一指标:批处理可提高 FPS 但可能提高单帧延迟;实时系统通常以延迟与抖动为主。
- NMS 与阈值策略会同时影响 Precision 与 Recall,因此任何指标对比都应说明推理时的阈值设置,否则结论不可复现。
本节小结:看指标时,至少要同时关注精度、速度和成本,不能只盯住某一个数字。
10 YOLOv5 与 Fast R-CNN 的优劣比较:区分理论、工程与应用结论
10.1 对比表(按常见约束给出"通常趋势")
| 维度 | YOLOv5(单阶段) | Fast R-CNN(两阶段) | 机制层解释(为什么) |
|---|---|---|---|
| 检测速度/吞吐 | 通常更高 | 通常更低 | 单阶段密集预测+短链路;Fast R-CNN含 proposal 与大量 RoI 处理 |
| 推理延迟 | 通常更低(取决于后处理) | 通常更高 | proposal 与 RoI 级别计算带来额外串行开销 |
| 精度(总体) | 典型任务中表现良好 | 典型任务中通常更稳健 | 两阶段区域级判别与精修更直接,尤其在复杂背景下 |
| 小目标/密集目标 | 依赖多尺度与阈值策略,可能受 NMS 抑制影响 | 在 proposal 质量良好时更有优势 | 显式 RoI 机制更利于局部判别;单阶段易受密集抑制冲突 |
| 部署难度 | 通常更低 | 通常更高 | 端到端链路与生态更成熟;Fast R-CNN系统更复杂且吞吐受 proposal 影响 |
| 训练成本 | 中等(端到端但超参数较多) | 中等到较高(proposal/采样/两分支) | 两阶段需要更细的样本定义与 RoI 采样策略 |
| 推理成本 | 通常更低 | 通常更高 | RoI 数量与 FC 计算带来额外成本 |
| 资源消耗 | 可通过模型规模与输入尺寸控制 | 对 proposal 数量与 backbone 更敏感 | 两阶段的"RoI 维度"增加了计算与内存压力 |
| 工业应用适配 | 实时与边缘端更常用 | 离线高精度分析更常见 | 工业现场更偏实时与可部署;离线分析更容忍高成本 |
| 学术研究适配 | 适合工程化基线与部署研究 | 适合方法学对比与两阶段改进 | Fast R-CNN结构清晰、可解释性更强,便于做消融与结构替换 |
10.2 如何理解这张对比表
读这类对比时,建议记住三句话:
- YOLOv5 更像"直接做题",流程短,通常更快;
- Fast R-CNN 更像"先圈重点,再认真做题",通常更细;
- 真正选型时,不能只看精度,还要看算力、延迟和部署难度。
本节小结:YOLOv5 和 Fast R-CNN 的差别,本质上是"直接预测"和"候选区域判别"的差别。前者更适合追求效率,后者更适合强调区域级分析。
11 典型应用场景分析:适配性来自约束条件而非模型名称
11.1 场景选型建议表(给出"为什么")
| 场景 | 通常更优先的选择 | 原因(机制→约束→结论) | 风险点/补充说明 |
|---|---|---|---|
| 实时监控(视频流) | YOLOv5 | 吞吐与延迟优先;链路短、易加速 | 密集人群/遮挡需谨慎调 NMS 与阈值;可结合跟踪缓解 |
| 工业质检(产线) | 视约束而定:实时优先选 YOLOv5,精度/可解释优先可考虑两阶段 | 产线多为固定视角,吞吐硬约束常见;但细粒度缺陷可能需要更强区域判别 | 两阶段需保证 proposal 覆盖缺陷区域;单阶段需保证小目标尺度覆盖与标注一致性 |
| 自动驾驶/机器人视觉 | 多数实时链路更偏 YOLOv5;需要精细区域分析时可引入两阶段 | 实时性与稳定性强约束;边缘算力受限 | 复杂场景需更严格的鲁棒性评估(光照、运动模糊、域迁移) |
| 边缘端部署(嵌入式) | YOLOv5(小模型) | 模型可裁剪、推理后端丰富、部署链路成熟 | 需评估量化/加速后精度损失与算子兼容性 |
| 离线图像分析(批处理) | Fast R-CNN 更常见(或其两阶段后续体系) | 可容忍更高计算成本以换取更稳定的区域级判别与定位精修 | 若 proposal 生成耗时高,可考虑更现代的两阶段实现(但本文不展开) |
| 学术研究基线构建 | 两者均可:工程基线选 YOLOv5,方法学/消融选 Fast R-CNN | YOLOv5适合做部署与效率研究;Fast R-CNN适合做结构消融与机制验证 | 论文写作需明确评价指标、IoU阈值、后处理与训练细节以保证可复现性 |
本节小结:场景选型的关键不是"谁更强",而是"你的约束是什么"。如果更看重实时性和部署效率,通常优先考虑 YOLOv5;如果更看重区域级精细判别,可以优先考虑 Fast R-CNN。
12 总结与选型建议:用需求类型形成闭环
12.1 本质差异(用一句话概括)
- YOLOv5:在多尺度特征图上做密集预测,通过阈值过滤与 NMS 把大量候选压缩为最终结果,优势在吞吐与部署闭环。
- Fast R-CNN:以候选区域为中心做区域级判别与边框精修,优势在结构可解释性与区域级建模范式,但受制于 proposal 与 RoI 处理的吞吐瓶颈。
12.2 四类需求下的选型建议(工程实践视角)
| 需求类型 | 优先建议 | 关键理由 | 落地时优先关注 |
|---|---|---|---|
| 实时优先 | YOLOv5 | 端到端链路短,吞吐与延迟更易达标 | 输入尺寸、模型规模、后处理耗时、P99延迟 |
| 精度优先 | 倾向 Fast R-CNN(或两阶段体系) | RoI 级别判别与精修更直接 | proposal 覆盖率、RoI 对齐误差、类别不均衡与采样策略 |
| 算力受限 | YOLOv5 小模型 | 可裁剪、可量化、部署生态更成熟 | 量化/加速后的算子兼容与精度回退、内存占用 |
| 研究验证 | 视研究目标选择:结构消融选 Fast R-CNN,部署效率选 YOLOv5 | 两阶段便于做机制对照,单阶段便于做系统优化 | 评价协议(IoU阈值、后处理)、训练细节与可复现性说明 |
12.3 学习路径建议(从机制到实践)
如果目标是建立长期可迁移的能力,建议的学习顺序是:
指标体系(IoU/AP/mAP)→ 单/两阶段范式差异 → RoI 机制与后处理 → 训练细节与超参数因果链 → 场景约束下的选型与部署。
本节小结:选型不是在模型名字之间"站队",而是在真实约束下做取舍。先看场景,再看指标,最后再决定模型,思路会更清楚。