在 Linux 内核(特别是 2.6.0 以后)中,进程状态不仅仅是几个枚举值,它被设计成一个位图(Bitmap)。这意味着一个进程可以同时处于多种状态(比如既是"可中断睡眠",又是"被跟踪")。当然可能刚接触的朋友感觉有点抽象,其实这就是内核数据结构在内存中的二进制投影;
先给一个状态转换的底层逻辑表,可以不看:
| 当前状态 | 触发事件 | 目标状态 | 内核底层动作 |
|---|---|---|---|
| Running | 请求 I/O / sleep() |
S (Sleeping) | set_current_state(TASK_INTERRUPTIBLE) -> schedule() |
| Running | 关键 I/O (如 NFS) | D (Disk) | set_current_state(TASK_UNINTERRUPTIBLE) -> schedule() |
| Running | Ctrl+Z / SIGSTOP |
T (Stopped) | set_current_state(TASK_STOPPED) -> 移出运行队列 |
| Running | exit() |
Z (Zombie) | 释放 mm_struct (内存),保留 task_struct,状态置 EXIT_ZOMBIE |
| S / D | I/O 完成中断 / 信号 | Running | wake_up_process() -> 状态置 TASK_RUNNING -> 加入运行队列 |
| Z (Zombie) | 父进程 wait() |
Dead (X) | 释放 task_struct,PID 回收 |
第一层:数据结构------进程状态在内核里长什么样?
在 Linux 内核中,进程由一个结构体描述:struct task_struct。
进程的状态,本质上就是这个结构体里的一个 long 类型的整数(位图)。
struct task_struct {
// ... 其他字段 ...
/*
* 进程状态。
* 注意:这是一个位掩码(Bitmask),意味着进程可以同时处于多种状态
* 例如:TASK_INTERRUPTIBLE | TASK_FREEZABLE
*/
volatile long state;
// ... 其他字段 ...
};底层定义的"状态位" :
内核不是用枚举,而是用二进制位来定义状态,这样支持组合。
/* 这是内核源码中的定义方式,本质是位掩码 */
#define TASK_RUNNING 0x0000 /* 运行态/就绪态 */
#define TASK_INTERRUPTIBLE 0x0001 /* 可中断睡眠 (S) */
#define TASK_UNINTERRUPTIBLE 0x0002 /* 不可中断睡眠 (D) */
#define __TASK_STOPPED 0x0004 /* 停止态 (T) */
#define __TASK_TRACED 0x0008 /* 跟踪态 (t) */
#define EXIT_ZOMBIE 0x0020 /* 僵尸态 (Z) */
#define EXIT_DEAD 0x0010 /* 死亡态 (X) */深度洞察 :
为什么 TASK_RUNNING 是 0?
- 因为在内核调度器看来,"运行"是默认状态 。只要你的
state字段里没有 设置睡眠、停止或死亡的位,调度器就认为你是TASK_RUNNING。
第二层:核心状态流转图解
我们将进程状态分为三大类:活跃(Running) 、休眠(Sleeping) 、死亡(Dead)。
1. Running(执行态与就绪态)
误区 :Running 意味着进程正在 CPU 上跑。
真相 :TASK_RUNNING 包含两个子状态:
- 正在运行:正在占用 CPU。
- 就绪 :在运行队列里排队,等待 CPU 时间片。
底层逻辑 :
Linux 的调度器(CFS)维护了一个红黑树 作为运行队列。处于 TASK_RUNNING 的进程,其 task_struct 节点就挂在这棵树上。
// 伪代码:调度器寻找下一个进程
struct task_struct *pick_next_task() {
// 从红黑树的最左边(虚拟时间最小,优先级最高)取出一个进程
// 这个进程必须是 state == TASK_RUNNING
struct task_struct *next = rb_first(&cfs_rq_tasks_timeline);
return next;
}2. Sleeping(阻塞态:S 与 D 的区别)
这是最考验系统稳定性的地方。进程为什么要睡眠?因为要等待资源(磁盘IO、网络包、用户输入)。
S 态(TASK_INTERRUPTIBLE):
-
原理:进程说"我去睡觉,如果有数据来了叫醒我,或者有人给我发信号(如 Ctrl+C)也叫醒我"。
-
代码实现:
// 内核代码逻辑
set_current_state(TASK_INTERRUPTIBLE); // 设置状态位
if (resource_available) {
set_current_state(TASK_RUNNING); // 资源有了,变回运行态
} else {
schedule(); // 放弃CPU,把自己从运行队列移除,进入休眠
}
D 态(TASK_UNINTERRUPTIBLE):
-
原理 :进程说"我在处理关键硬件交互(如 NFS 挂载、磁盘写回),千万别打扰我,发信号也没用,必须等硬件操作完成"。
-
为什么会有 D 态? 如果进程在操作硬件寄存器时被打断,硬件状态机可能会死锁。D 态是为了保护硬件一致性。
-
恐怖之处 :
kill -9发送的是SIGKILL,但处于 D 态的进程收不到信号,因为它根本不会去检查信号队列,直到它自己醒来。// 模拟 D 态逻辑
void wait_for_disk_io() {
set_current_state(TASK_UNINTERRUPTIBLE); // 设置不可中断// 即使此时有信号 Pending,schedule() 也不会处理信号 // 它只会等待磁盘中断 handler 来唤醒它 schedule(); // 只有磁盘中断发生,调用 wake_up_process() 才会回到这里}
3. Zombie(僵尸态)
原理 :进程死了(调用了 exit()),内核回收了它的内存、文件句柄,但保留了 task_struct 。
为什么? 父进程需要读取子进程的退出码(是正常退出还是报错退出)。
底层数据结构 :
此时,task_struct 中的 exit_code 字段有效,但 mm_struct(内存描述符)已经被释放。
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork();
if (pid > 0) {
// 父进程:睡觉,不调用 wait() 回收子进程
sleep(100);
} else {
// 子进程:退出
// 内核会释放子进程内存,但保留 task_struct,状态置为 EXIT_ZOMBIE
exit(0);
}
return 0;
}第三层:状态切换的底层机制------上下文切换
进程状态的变化,本质上是寄存器 和内存指针 的切换。一场**"数据搬运"** 和**"现场保护"**的精密手术
第一层:什么是"上下文"?
上下文(Context) ,本质上就是CPU 寄存器里存的数据。
想象你在玩单机游戏(进程A),突然妈妈叫你去洗碗(发生中断/调度)。为了回来能接着玩,你必须记住:
- 你现在的血量、蓝量(通用寄存器)。
- 你站在地图的哪个坐标(程序计数器 PC)。
- 你的背包里有什么(栈指针 SP)。
- 甚至你的浮点运算状态(浮点寄存器)。
上下文切换 = 把当前寄存器里的值保存到内存 + 把内存里的值恢复到寄存器
1. 从 Running 到 Sleeping(主动放弃)
中断 或系统调用 触发,当进程调用 read() 或 sleep() 时:
-
CPU 陷入内核态,保存当前的
PC程序计数器和PSW状态字,跳转到内核的中断处理程序。 -
修改状态 :
current->state = TASK_INTERRUPTIBLE; -
加入等待队列:把自己挂到某个资源(如磁盘缓冲区)的等待链表上。
-
调度 :调用
schedule()。- 保存当前 CPU 上下文(EIP, ESP 等寄存器)到内核栈,最终存入进程 A 的
task_struct结构体中。 - 从运行队列(红黑树)中摘除自己。
- 调度器(CFS)运行队列挑选下一个进程,恢复它的上下文。O(log N) 的复杂度
// 这是一个宏,最终展开为汇编代码
// prev_task: 当前进程(要被切走的)
// next_task: 下一个进程(要切过来的)
#define switch_to(prev, next, last)
do {
// 1. 保存浮点状态(FPU/SIMD)
// 如果进程用了浮点运算,这部分数据很大,切换开销很大
if (static_cpu_has(X86_FEATURE_FPU)) {
__switch_fpu(&prev->thread.fpu);
}
// 2. 切换页表(内存管理)
// 这是进程切换最贵的操作!
// 如果是线程切换,这一步可以跳过(因为共享内存)
if (static_branch_unlikely(&switch_mm_cond)) {
switch_mm(&prev->active_mm, &next->active_mm, next);
}
// 3. 真正的寄存器切换
// 这是一个内联汇编,它会修改栈指针和指令指针
// 一旦执行这里,代码流就"穿越"到另一个进程了
__switch_to_asm(prev, next);
} while (0) - 保存当前 CPU 上下文(EIP, ESP 等寄存器)到内核栈,最终存入进程 A 的
2. 从 Sleeping 到 Running(被动唤醒)
当硬件中断(如网卡收到包)发生时:
- 切换地址空间 :如果 A 和 B 是不同的进程,它们的内存是隔离的。CPU 必须切换页表。
- 跳转执行 :把进程 B 之前保存的寄存器值读出来,塞回 CPU 寄存器。
- 进程切换时,TLB 必须清空(或标记失效)
- CPU 有个叫 TLB(快表) 的缓存,记录"虚拟地址 -> 物理地址"的映射
- 新进程运行初期,所有的内存访问都会导致 TLB Miss,CPU 必须去查慢得多的页表,甚至访问内存:
- L1/L2/L3 缓存失效
- 进程 A 的数据在 L3 缓存里热乎着呢。
- 进程 B 来了,它的数据不在缓存里,它开始疯狂加载自己的数据,把 A 的数据挤出去。
- 等 A 再次运行时,缓存全空,必须从内存重新加载。这叫冷启动。
- 关键指令 :执行一条汇编指令
iret(或iretq),CPU 瞬间跳回到进程 B 上次被中断的地方继续执行。
-
中断处理:CPU 暂停当前进程,执行中断服务程序。
-
唤醒 :中断程序调用
wake_up_process(target_task)。target_task->state = TASK_RUNNING;- 将
target_task插入 CPU 的运行队列(红黑树)。
-
返回:中断结束,如果唤醒的进程优先级更高,调度器会立即触发上下文切换。
伪汇编代码演示
rdi = prev (旧进程), rsi = next (新进程)
__switch_to_asm:
# 1. 保存旧进程的栈指针
movq %rsp, TASK_threadsp(%rdi)# 2. 加载新进程的栈指针 movq TASK_threadsp(%rsi), %rsp # 3. 保存旧进程的基址指针 movq %rbp, TASK_threadbp(%rdi) # 4. 加载新进程的基址指针 movq TASK_threadbp(%rsi), %rbp # 5. 保存其他通用寄存器 (r12-r15 等) 到旧进程的内核栈 pushq %rbx pushq %r12 ... # 6. 从新进程的内核栈恢复寄存器 popq %r15 popq %r14 ... popq %rbx # 7. 返回(注意!这里的 ret 会跳转到新进程的指令指针) # 因为栈指针 %rsp 已经在第2步换成了新进程的栈 # 而新进程栈顶压入的地址,正是它上次被挂起的地方 ret
总结:全生命周期状态机图
为了让你彻底看懂,找了一张底层流转图:
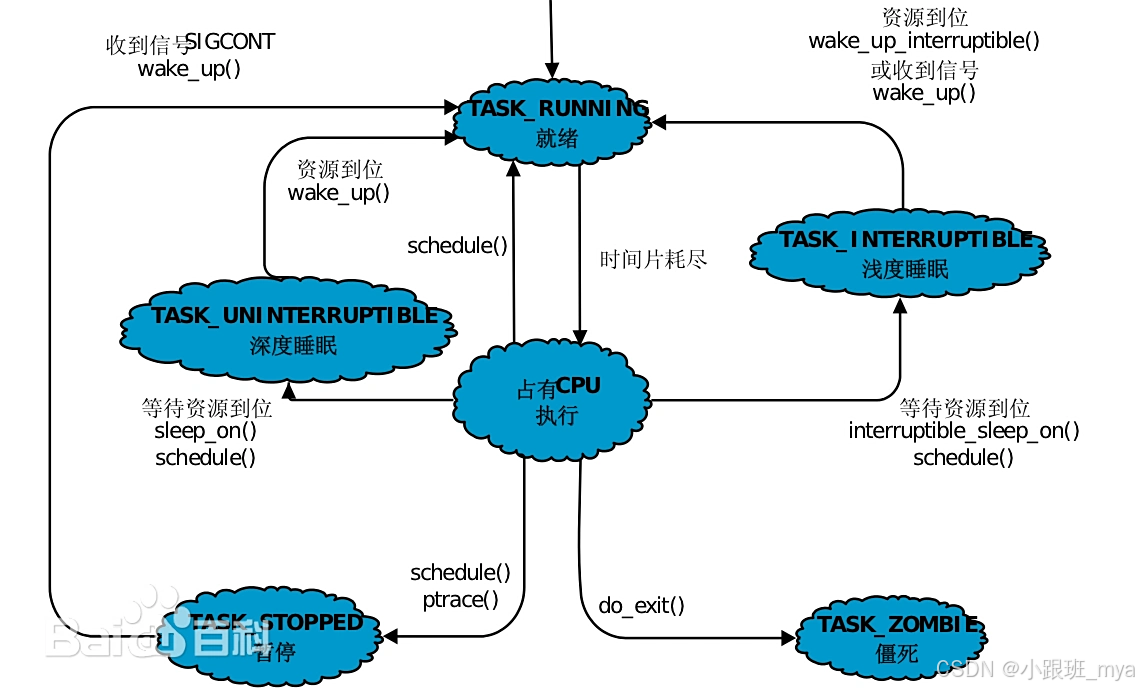
架构师视角的总结:
- R 态 不代表高性能,如果 R 态进程过多且 CPU 使用率低,说明发生了锁竞争(都在抢 CPU 时间片,导致上下文切换频繁)。
- D 态 是运维的噩梦。如果你发现系统里有 D 态进程,通常意味着底层存储(磁盘/NFS)挂了,除了重启或修复硬件,软件层面几乎无解。
- Z 态 不可怕,可怕的是父进程不写
wait(),导致内核内存泄漏(task_struct泄露)。