目录
[高级篇 - 分布式缓存 - 01 - 今日课程介绍](#高级篇 - 分布式缓存 - 01 - 今日课程介绍)
[高级篇 - 分布式缓存 - 02-Redis 持久化 - RDB 演示](#高级篇 - 分布式缓存 - 02-Redis 持久化 - RDB 演示)
[高级篇 - 分布式缓存 - 03-Redis 持久化 - RDB 的 fork原理](#高级篇 - 分布式缓存 - 03-Redis 持久化 - RDB 的 fork原理)
[高级篇 - 分布式缓存 - 04-Redis 持久化 - AOF 演示](#高级篇 - 分布式缓存 - 04-Redis 持久化 - AOF 演示)
[高级篇 - 分布式缓存 - 05-Redis 持久化 - RDB 和 AOF的对比](#高级篇 - 分布式缓存 - 05-Redis 持久化 - RDB 和 AOF的对比)
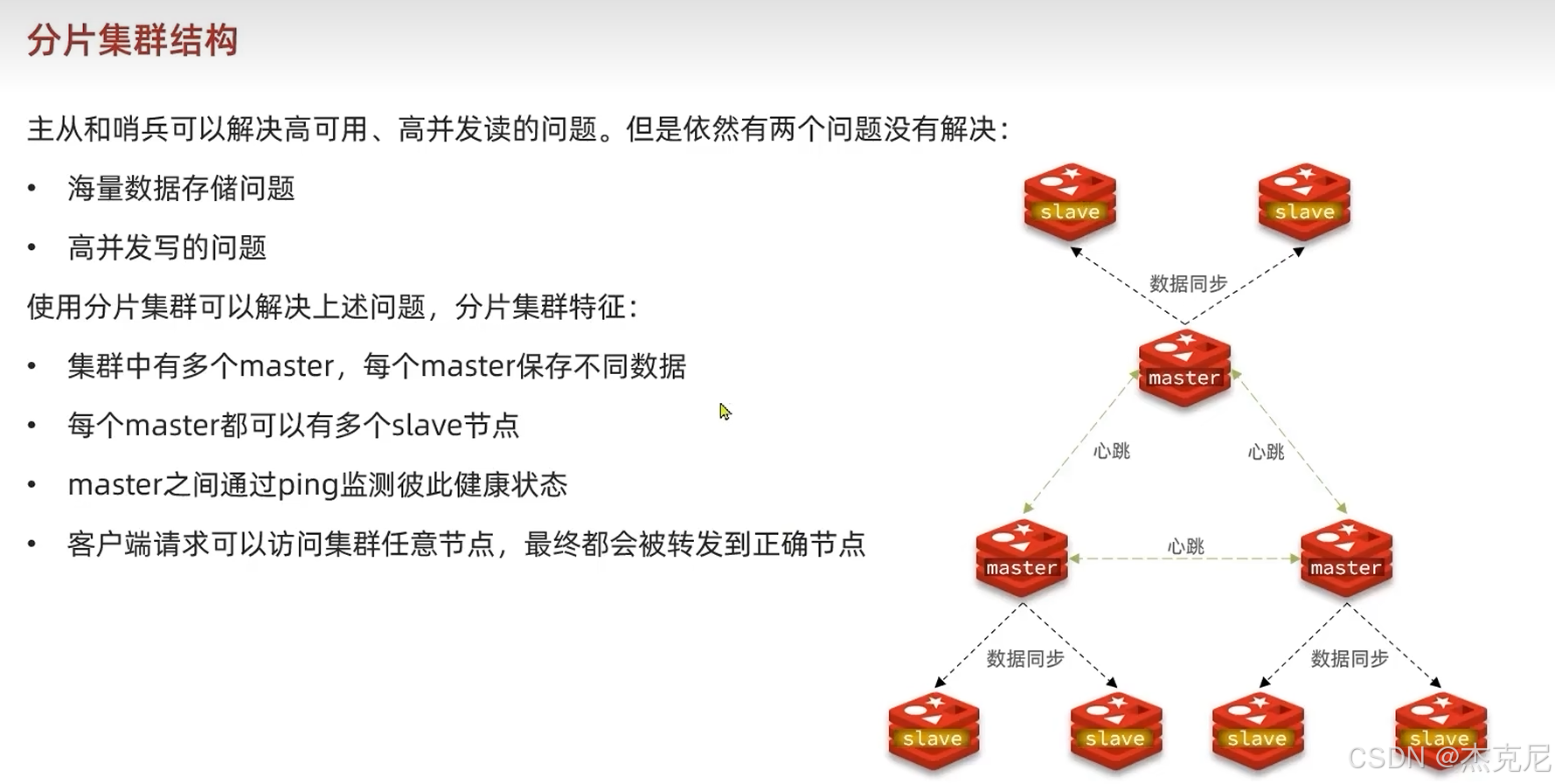
[高级篇 - 分布式缓存 - 06-Redis 主从 - 主从集群结构](#高级篇 - 分布式缓存 - 06-Redis 主从 - 主从集群结构)
[高级篇 - 分布式缓存 - 07-Redis 主从 - 搭建主从集群](#高级篇 - 分布式缓存 - 07-Redis 主从 - 搭建主从集群)
[高级篇 - 分布式缓存 - 08-Redis 主从 - 主从的全量同步原理](#高级篇 - 分布式缓存 - 08-Redis 主从 - 主从的全量同步原理)
[高级篇 - 分布式缓存 - 09-Redis 主从 - 增量同步原理](#高级篇 - 分布式缓存 - 09-Redis 主从 - 增量同步原理)
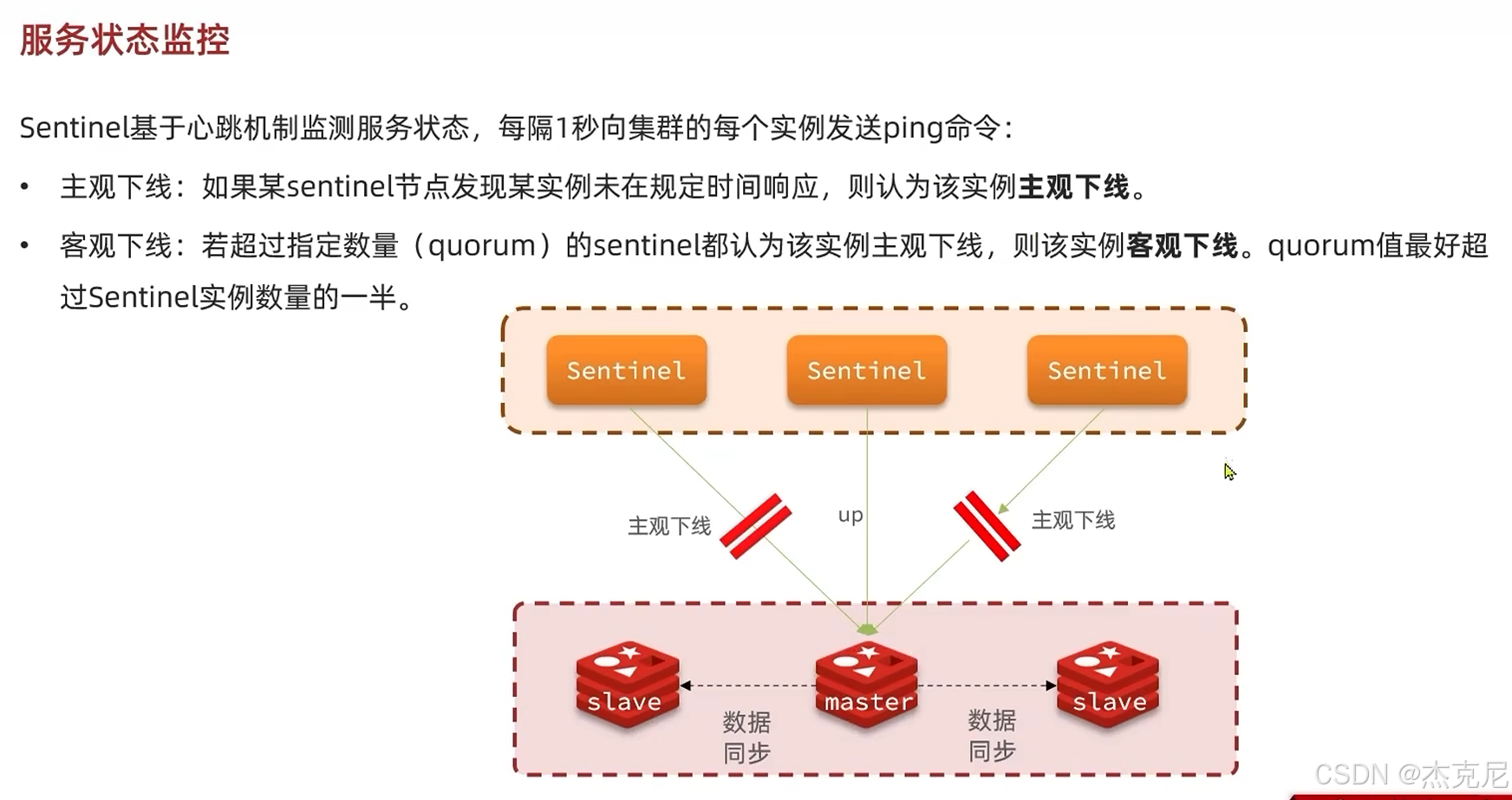
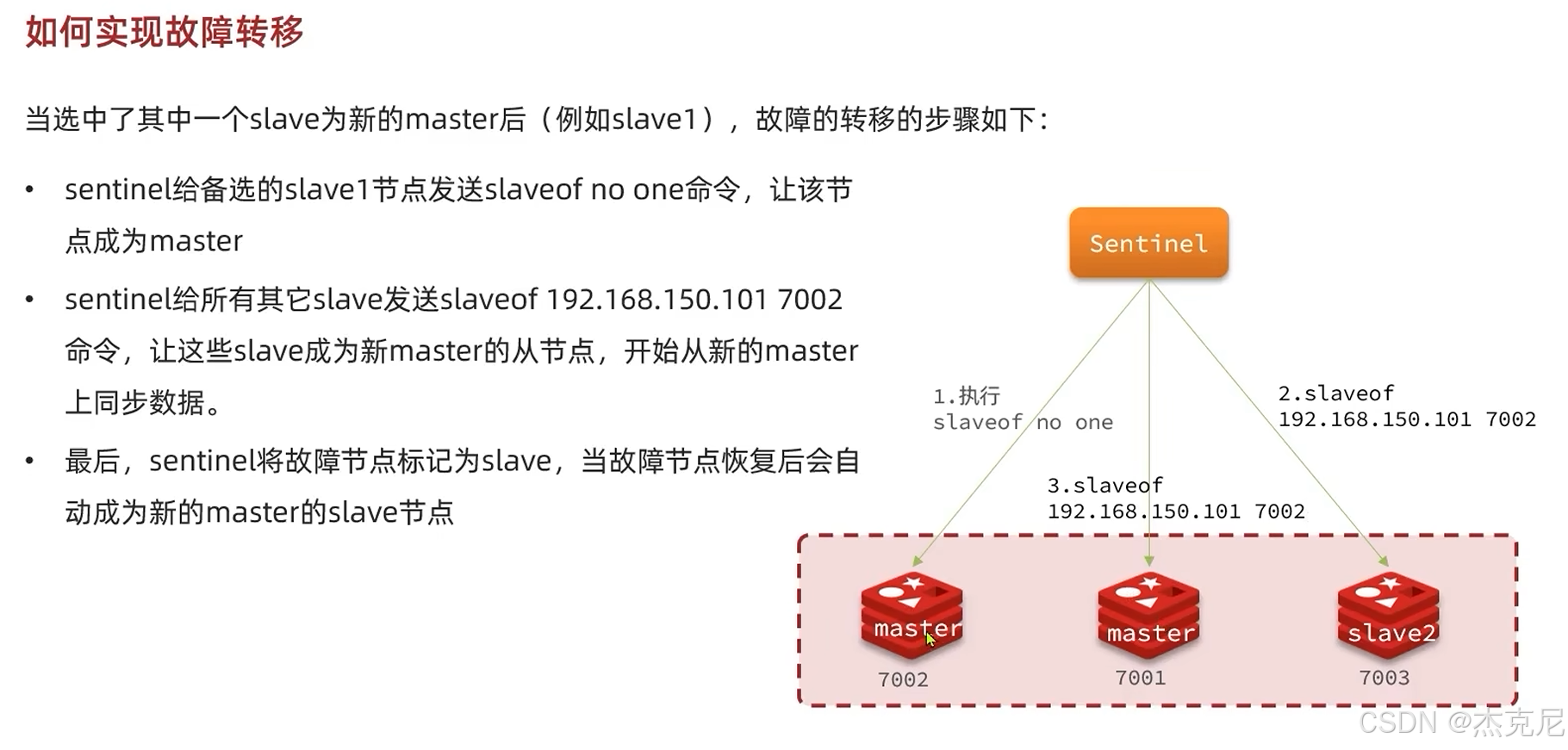
[高级篇 - 分布式缓存 - 10-Redis 哨兵 - 哨兵的作用和工作原理](#高级篇 - 分布式缓存 - 10-Redis 哨兵 - 哨兵的作用和工作原理)
[高级篇 - 分布式缓存 - 11-Redis 哨兵 - 搭建哨兵集群](#高级篇 - 分布式缓存 - 11-Redis 哨兵 - 搭建哨兵集群)
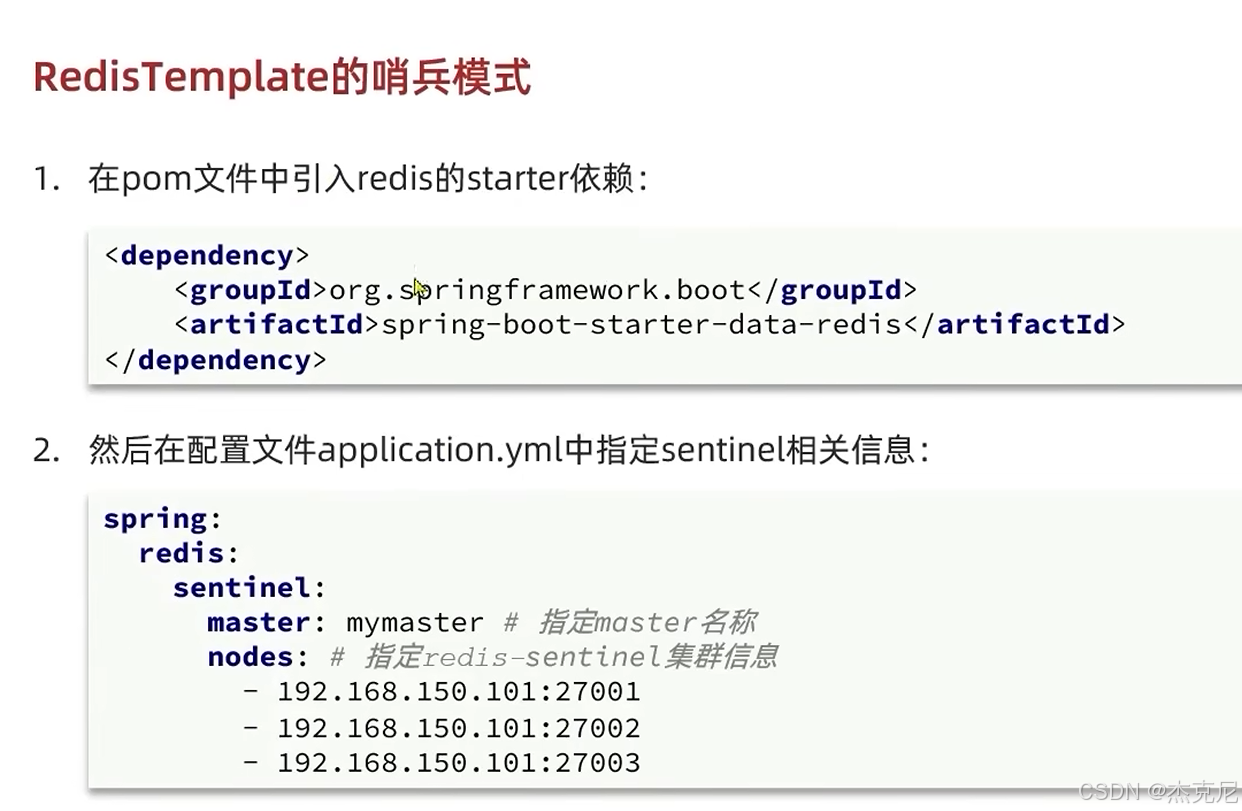
[高级篇 - 分布式缓存 - 12-Redis 哨兵 - RedisTemplate连接哨兵](#高级篇 - 分布式缓存 - 12-Redis 哨兵 - RedisTemplate连接哨兵)
[高级篇 - 分布式缓存 - 13-Redis 分片集群 - 搭建分片集群](#高级篇 - 分布式缓存 - 13-Redis 分片集群 - 搭建分片集群)
[高级篇 - 分布式缓存 - 14-Redis 分片集群 - 散列插槽](#高级篇 - 分布式缓存 - 14-Redis 分片集群 - 散列插槽)
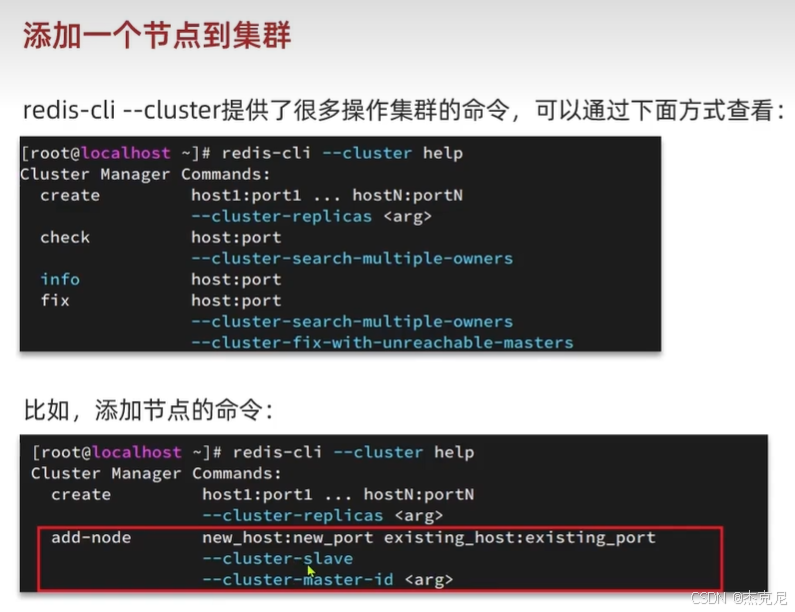
[高级篇 - 分布式缓存 - 15-Redis 分片集群 - 集群伸缩](#高级篇 - 分布式缓存 - 15-Redis 分片集群 - 集群伸缩)
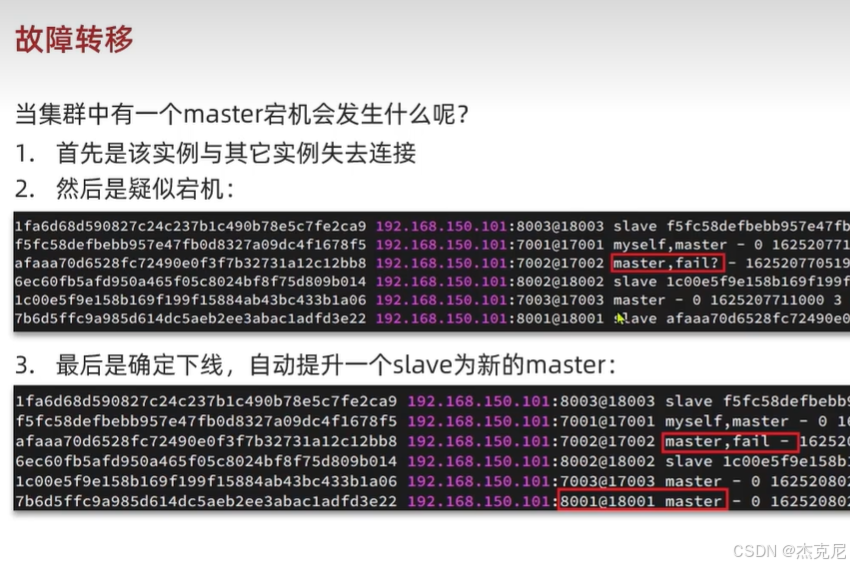
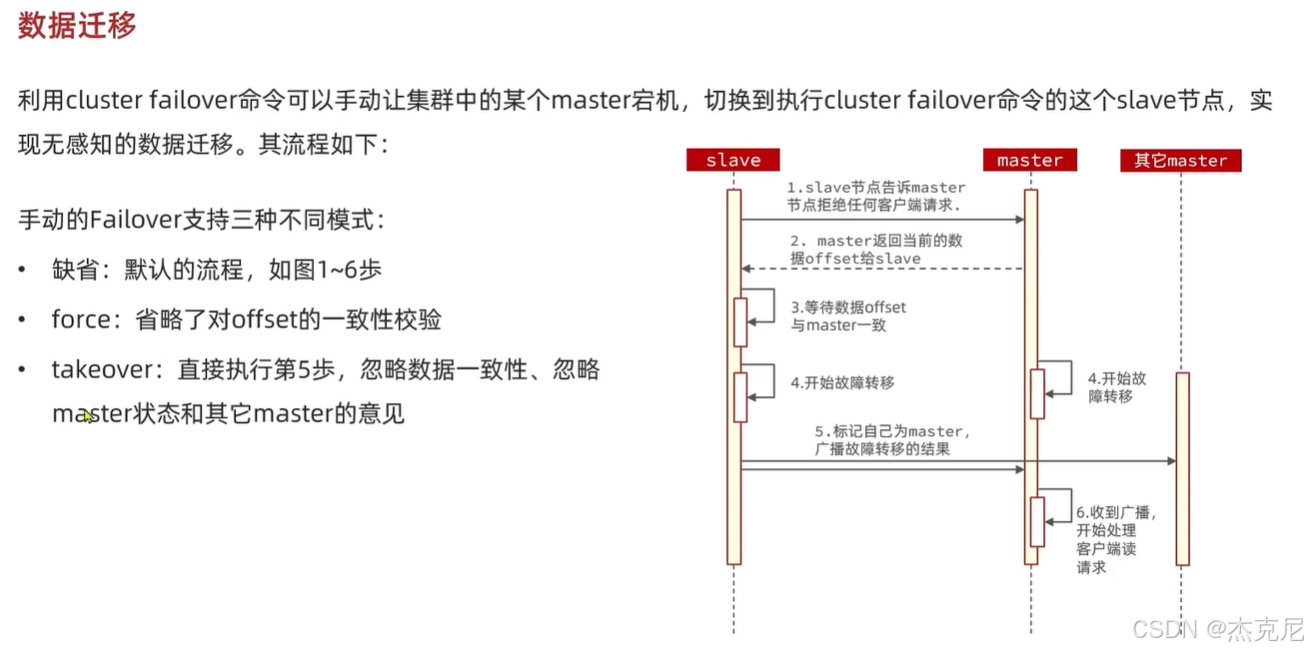
[高级篇 - 分布式缓存 - 16-Redis 分片集群 - 故障转移](#高级篇 - 分布式缓存 - 16-Redis 分片集群 - 故障转移)
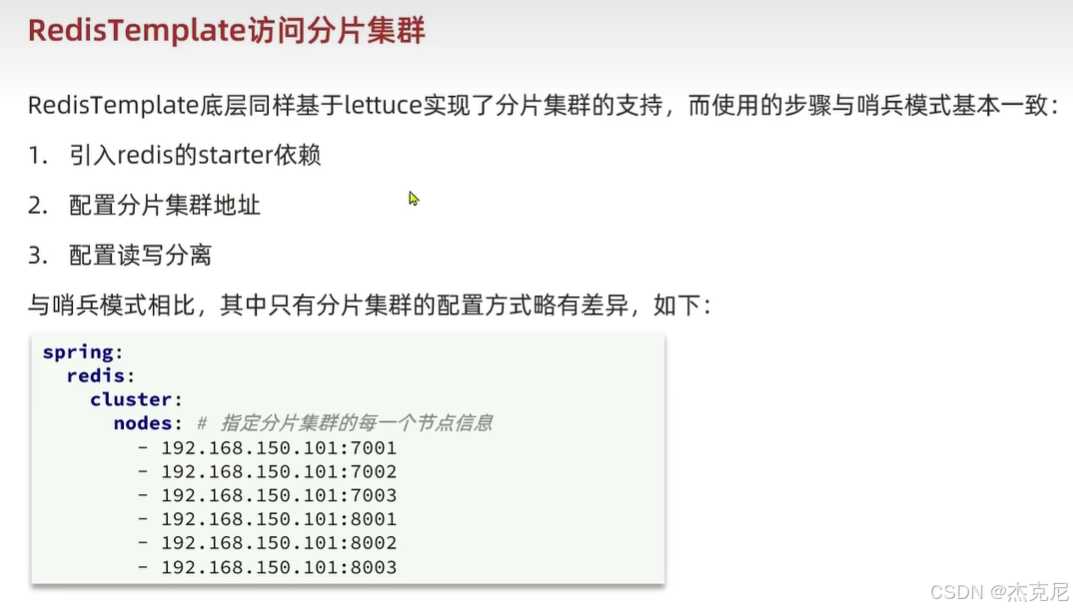
[高级篇 - 分布式缓存 - 17-Redis 分片集群 - RedisTemplate访问分片集群](#高级篇 - 分布式缓存 - 17-Redis 分片集群 - RedisTemplate访问分片集群)
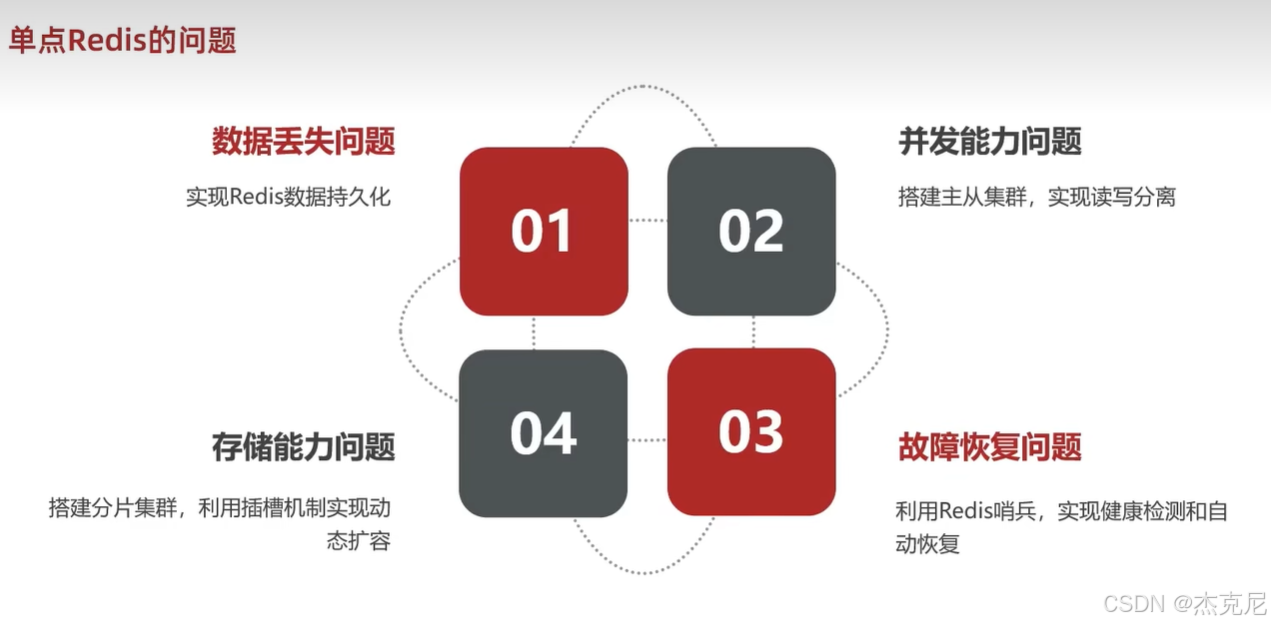
高级篇 - 分布式缓存 - 01 - 今日课程介绍

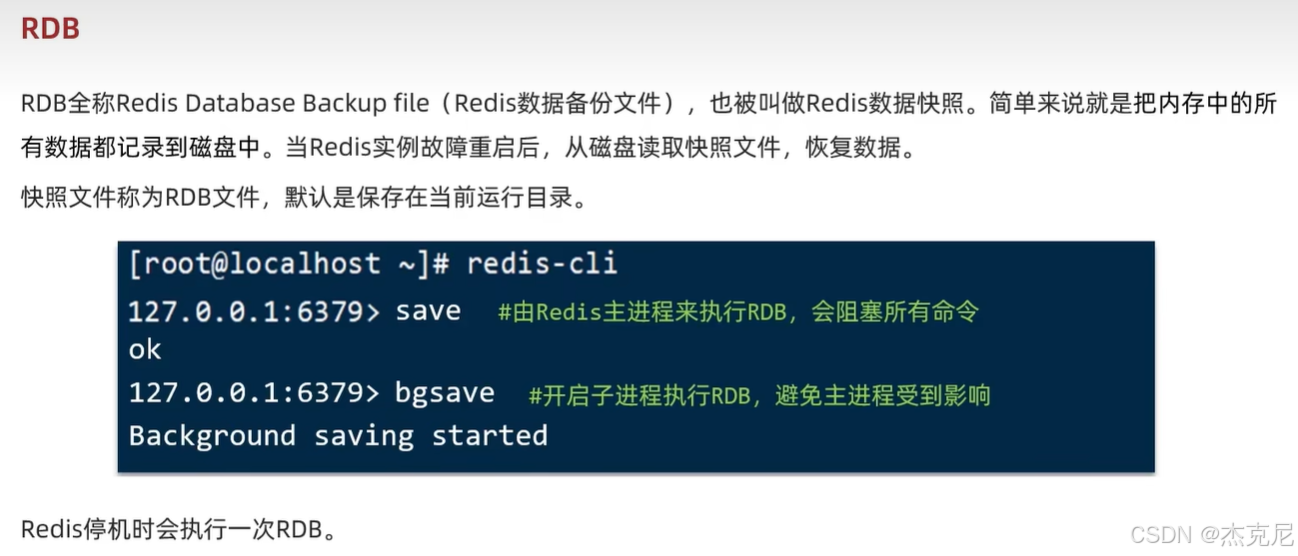
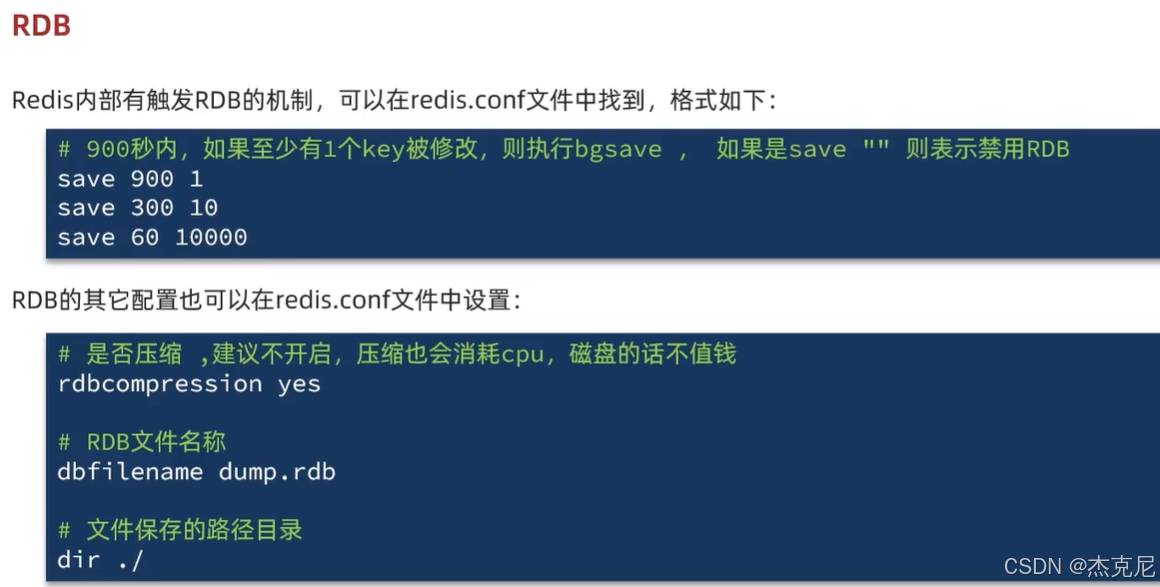
高级篇 - 分布式缓存 - 02-Redis 持久化 - RDB 演示
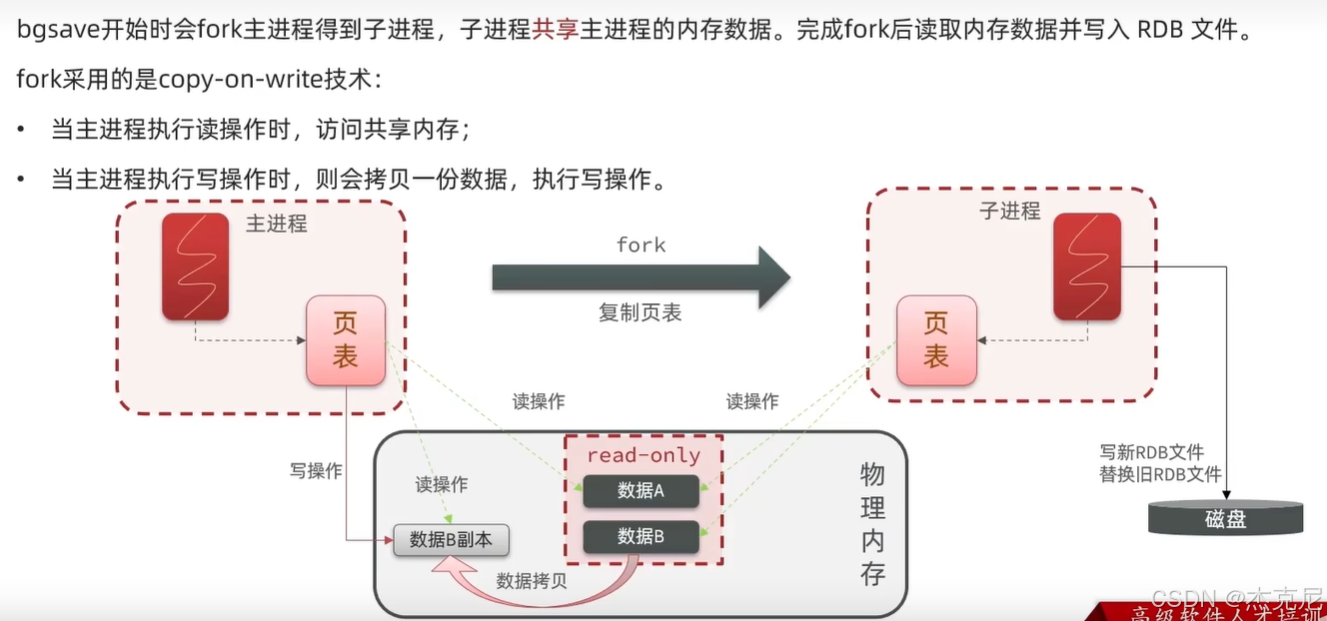
高级篇 - 分布式缓存 - 03-Redis 持久化 - RDB 的 fork原理

高级篇 - 分布式缓存 - 04-Redis 持久化 - AOF 演示
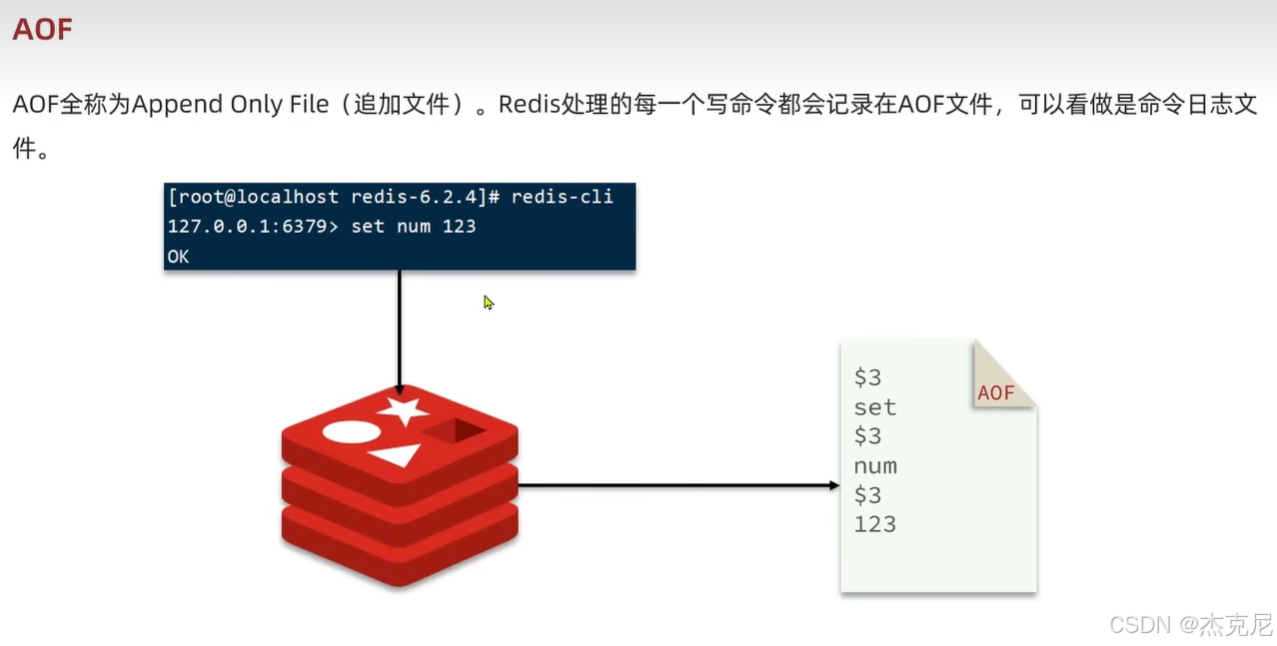


高级篇 - 分布式缓存 - 05-Redis 持久化 - RDB 和 AOF的对比
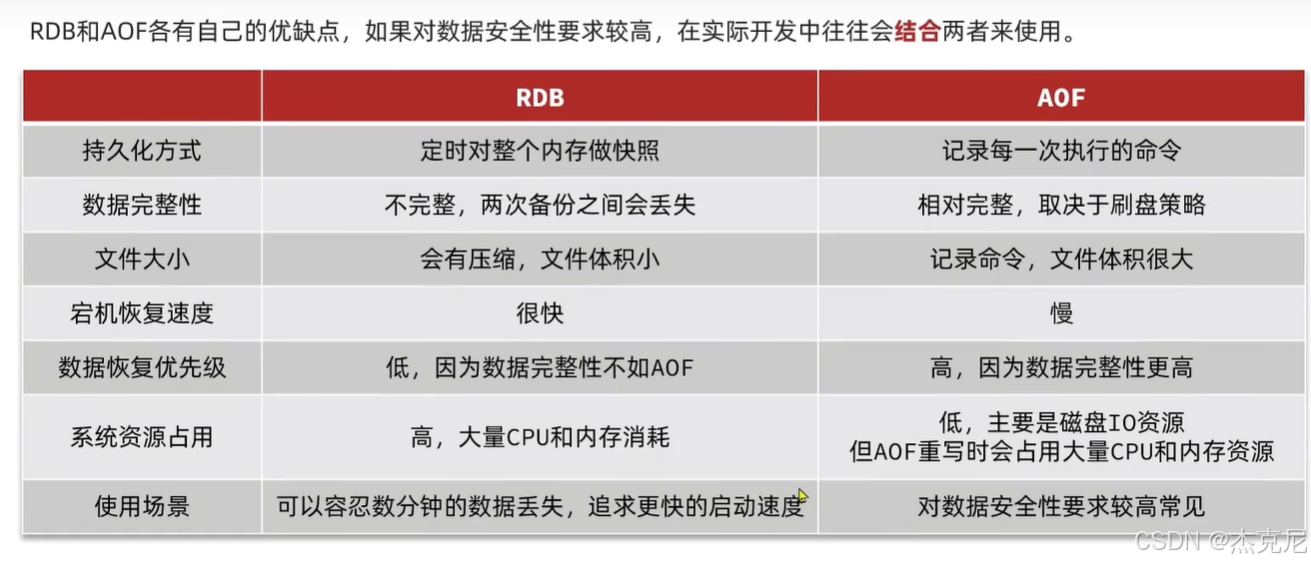
高级篇 - 分布式缓存 - 06-Redis 主从 - 主从集群结构
高级篇 - 分布式缓存 - 07-Redis 主从 - 搭建主从集群

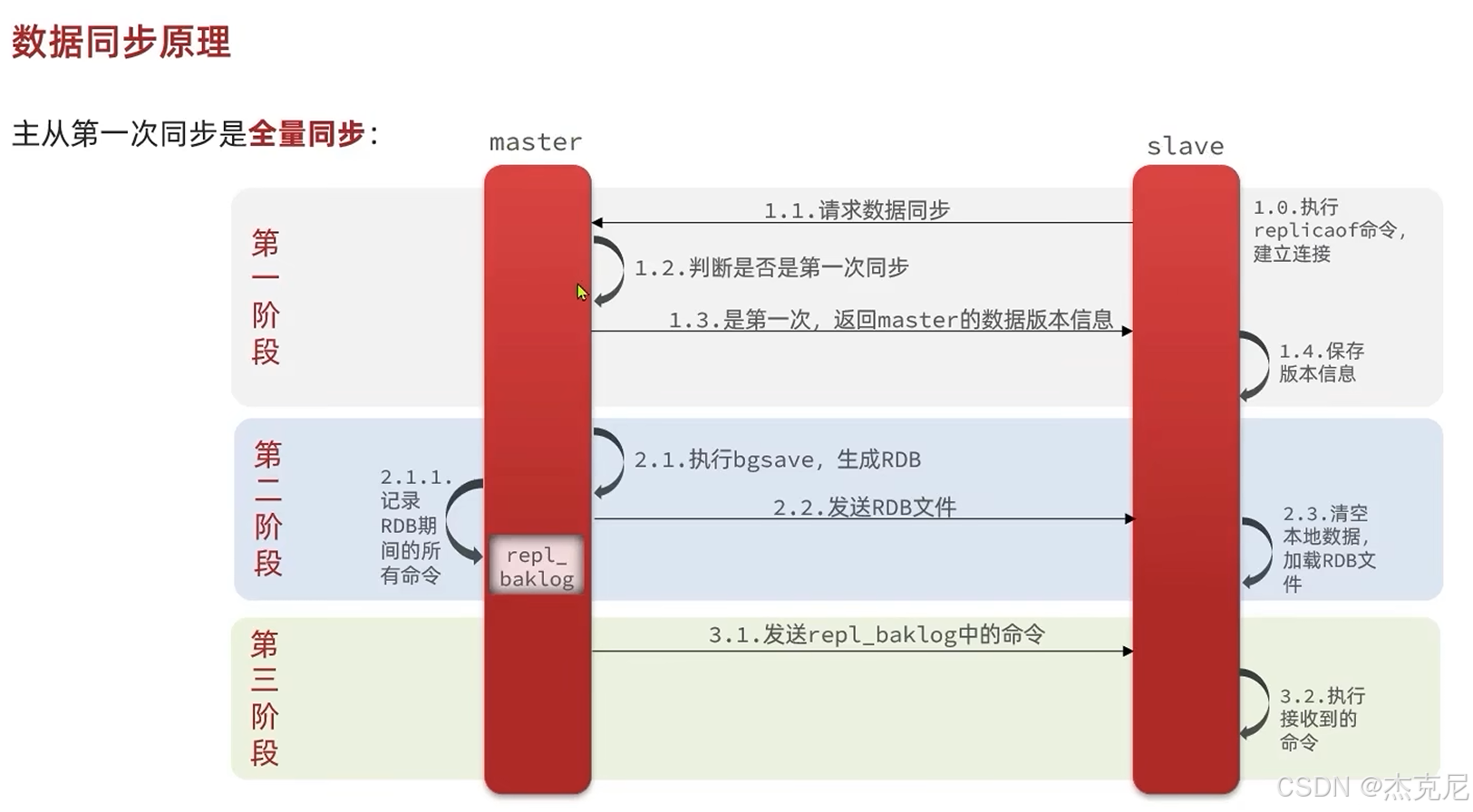
高级篇 - 分布式缓存 - 08-Redis 主从 - 主从的全量同步原理

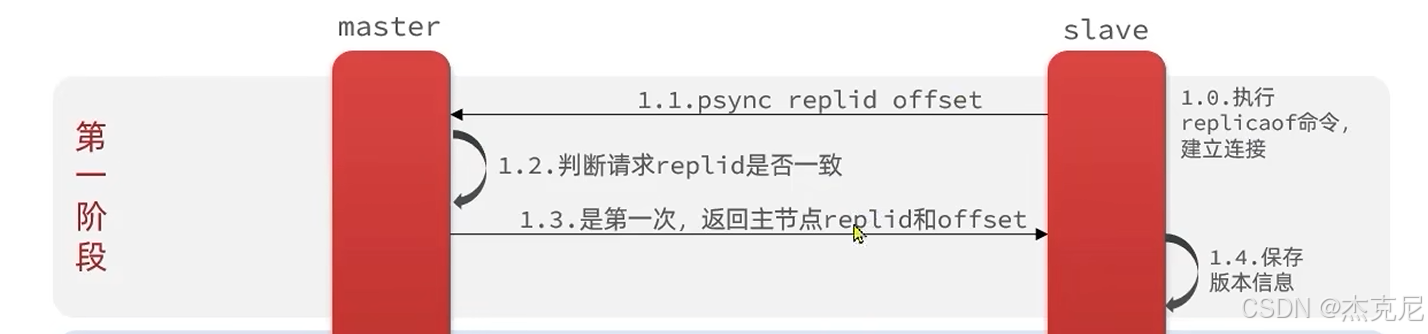

高级篇 - 分布式缓存 - 09-Redis 主从 - 增量同步原理
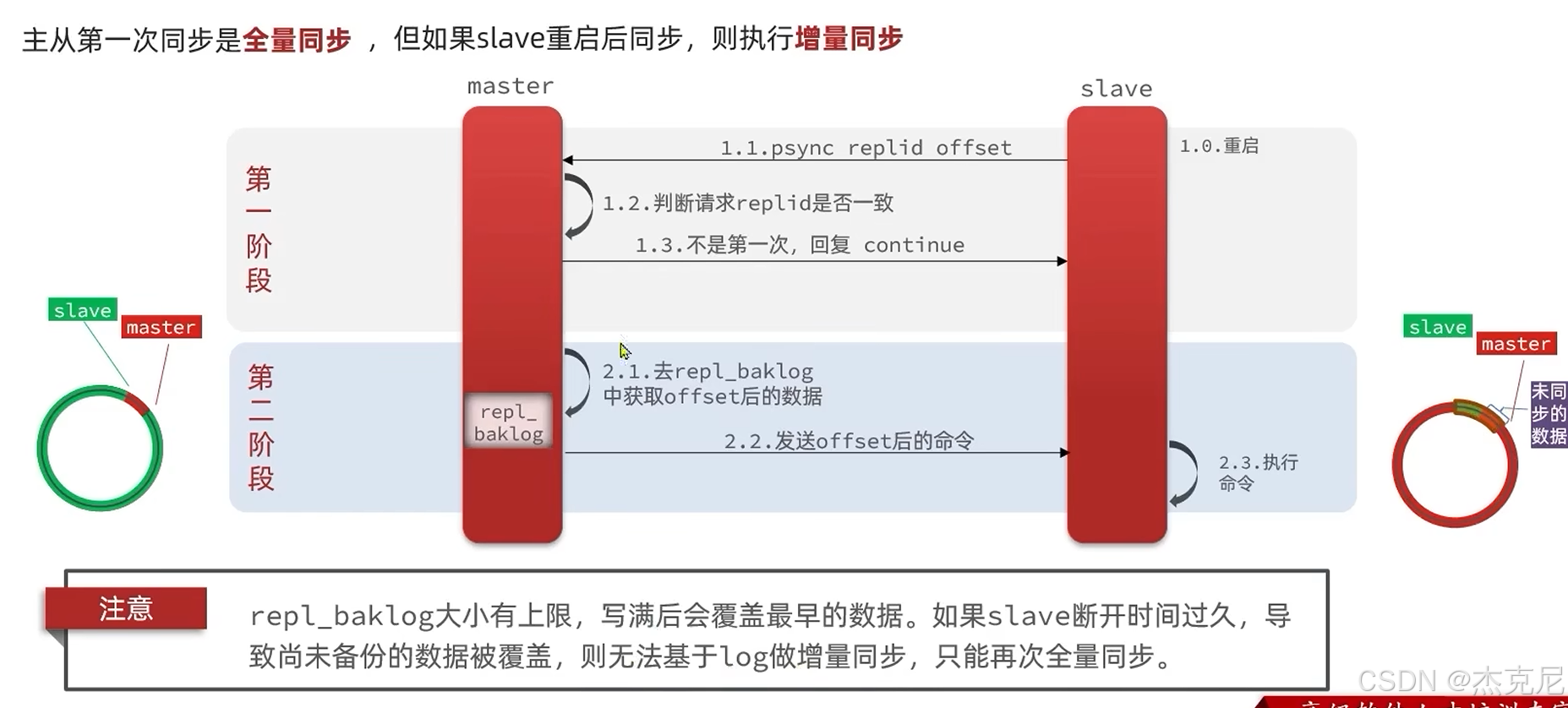
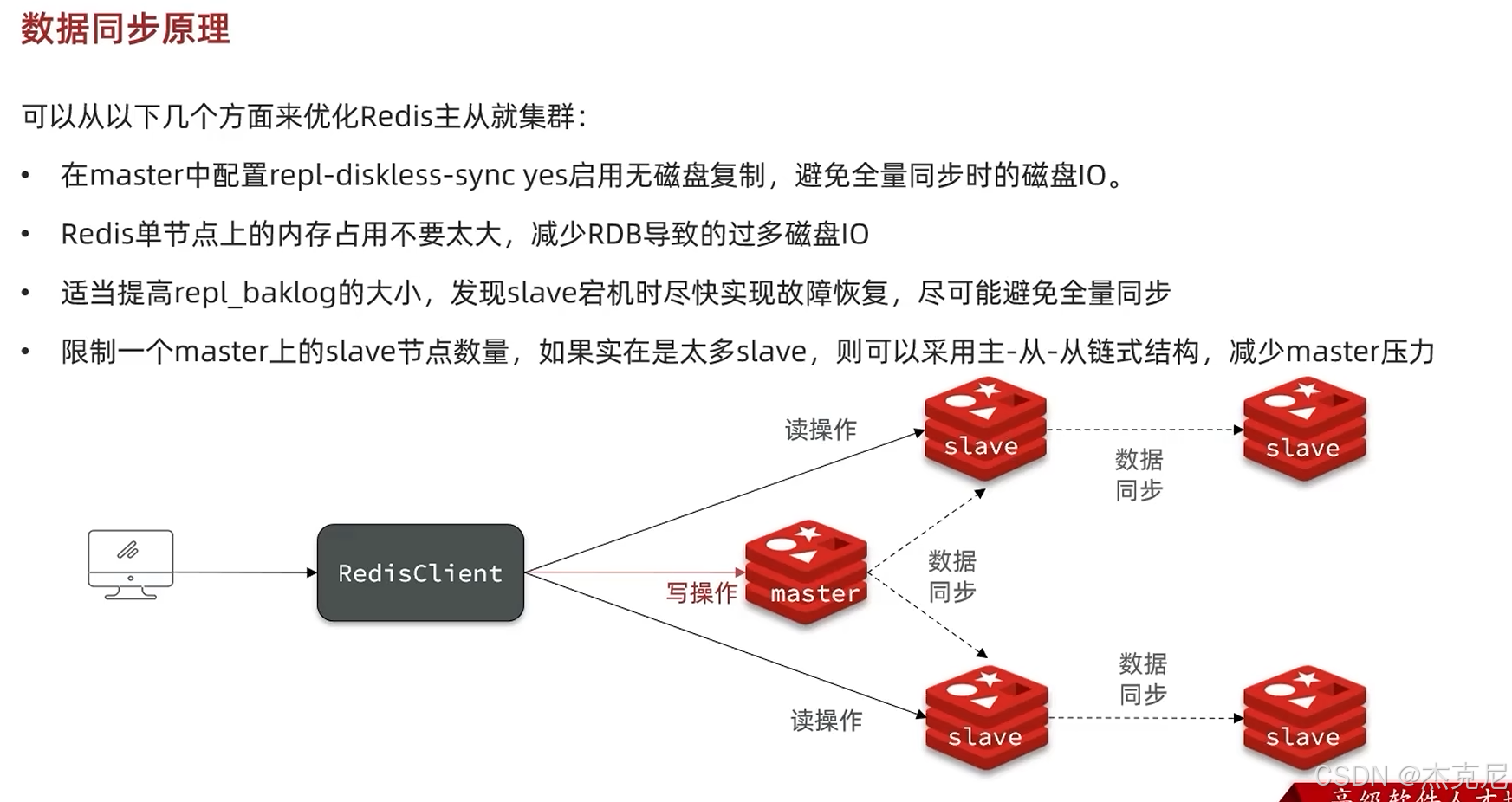

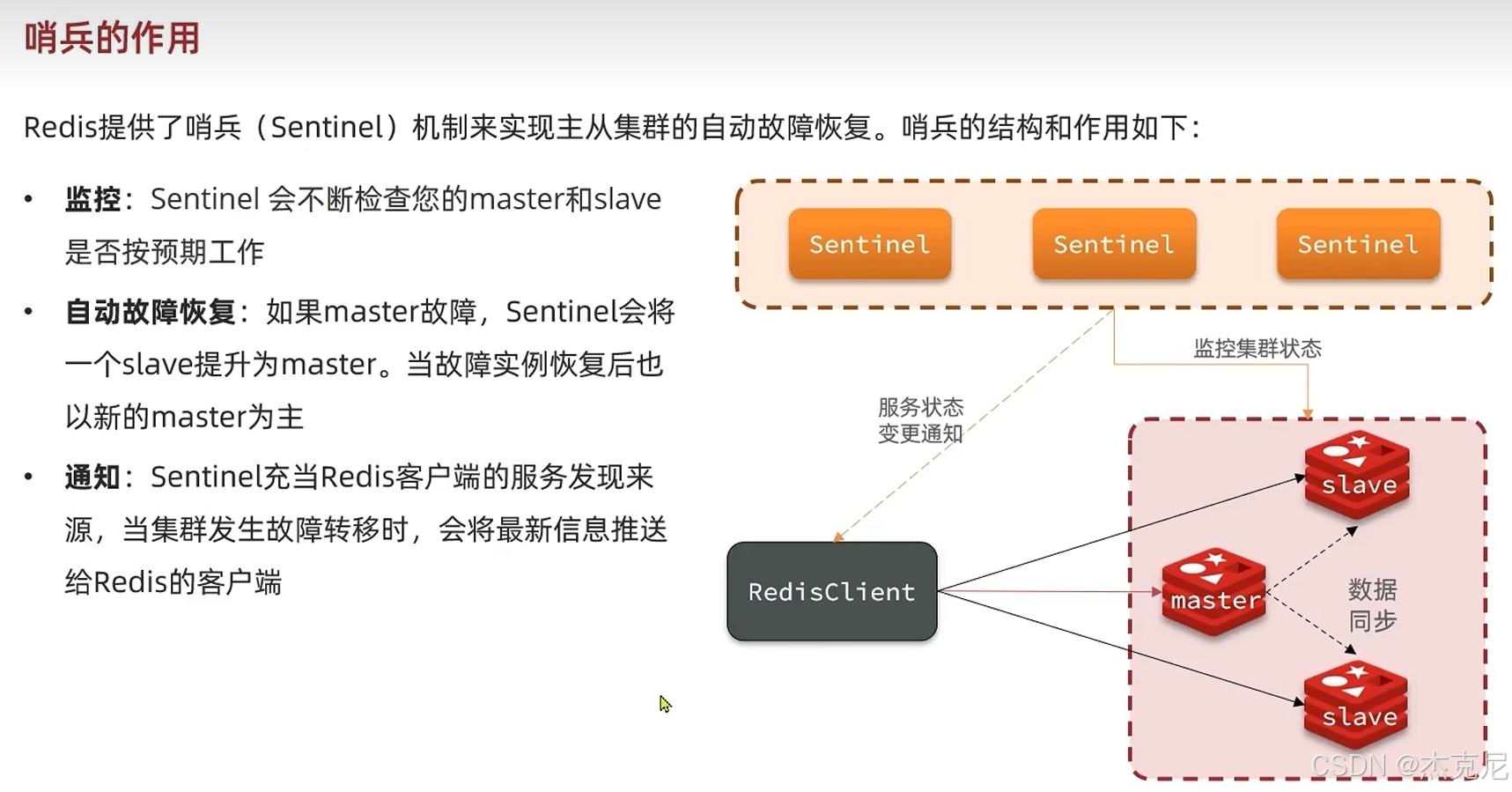
高级篇 - 分布式缓存 - 10-Redis 哨兵 - 哨兵的作用和工作原理

高级篇 - 分布式缓存 - 11-Redis 哨兵 - 搭建哨兵集群


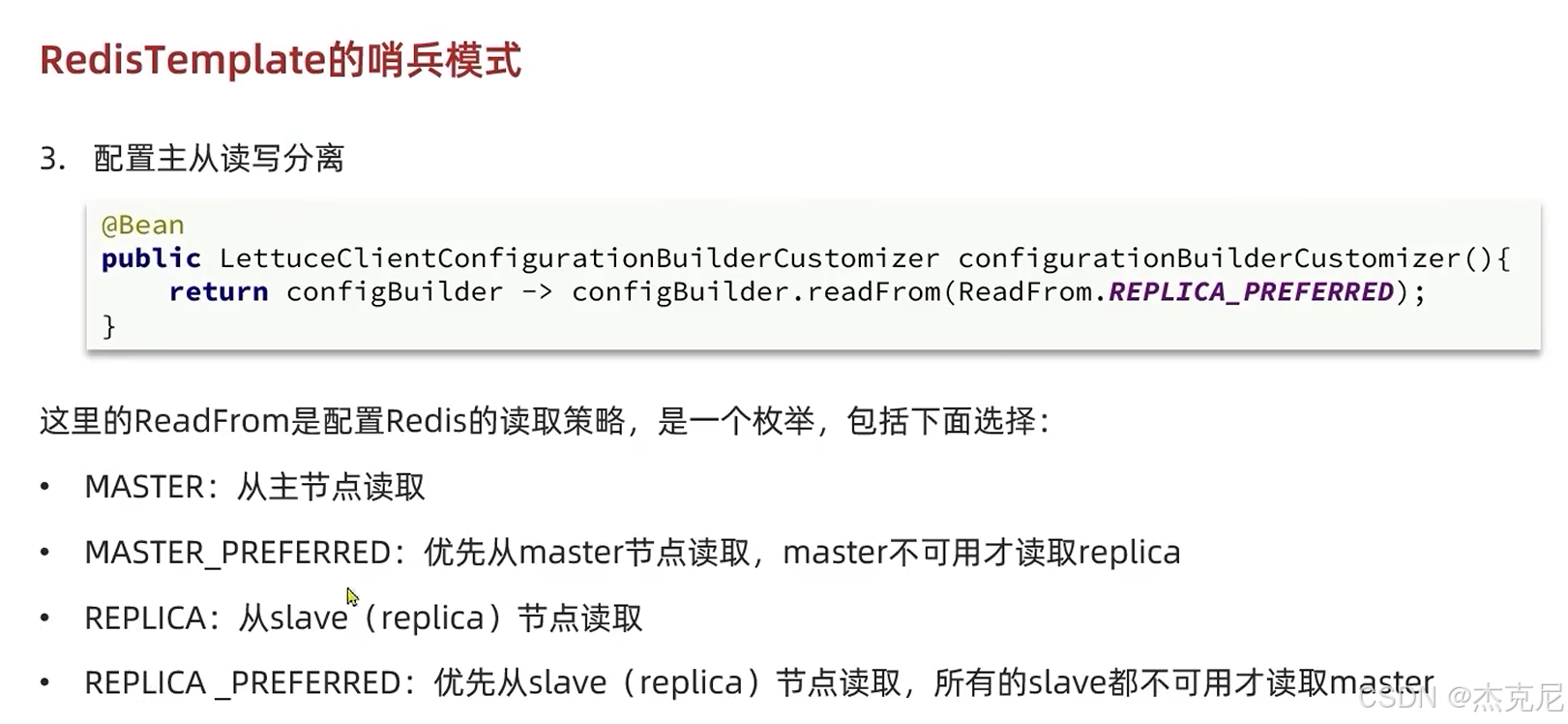
高级篇 - 分布式缓存 - 12-Redis 哨兵 - RedisTemplate连接哨兵
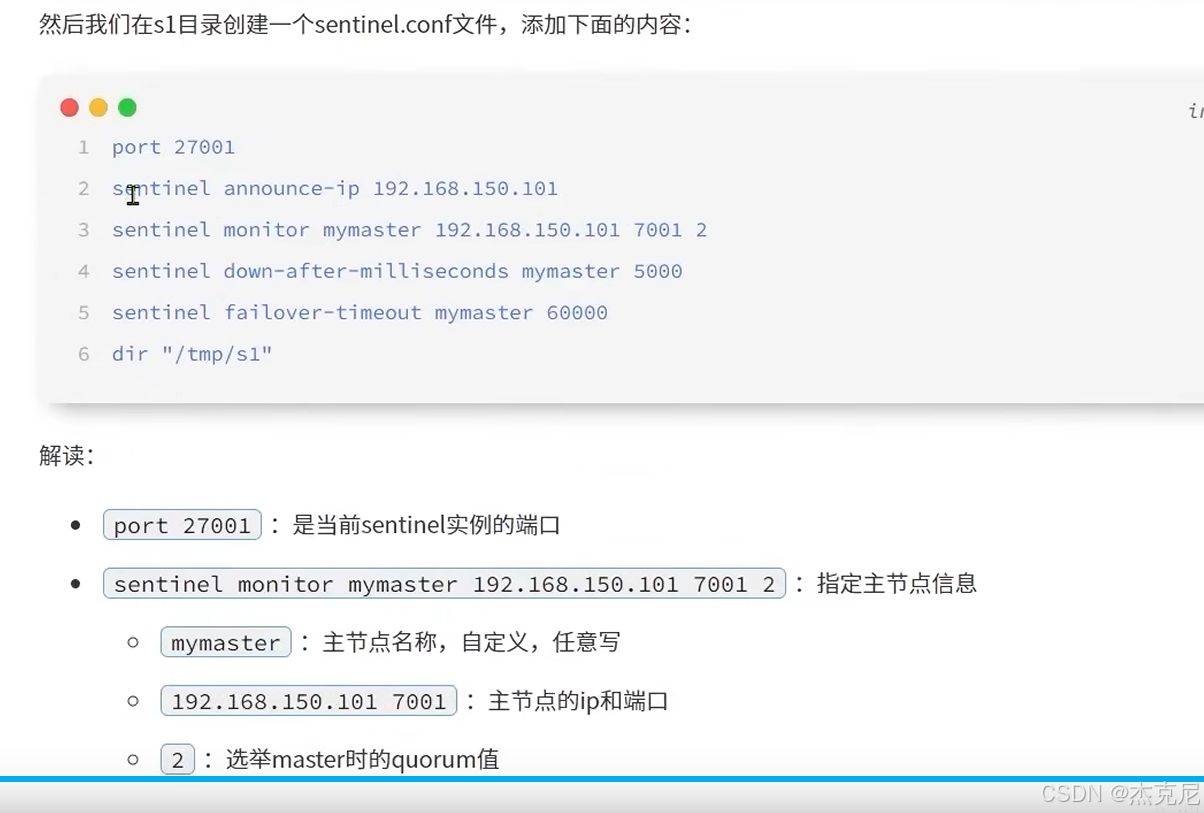
高级篇 - 分布式缓存 - 13-Redis 分片集群 - 搭建分片集群


高级篇 - 分布式缓存 - 14-Redis 分片集群 - 散列插槽
问题:哨兵集群和分片集群各自解决了什么?


高级篇 - 分布式缓存 - 15-Redis 分片集群 - 集群伸缩

高级篇 - 分布式缓存 - 16-Redis 分片集群 - 故障转移


高级篇 - 分布式缓存 - 17-Redis 分片集群 - RedisTemplate访问分片集群
末尾页
本文介绍了Redis分布式缓存的高级内容,主要包括Redis持久化(RDB和AOF)、主从集群搭建与同步原理、哨兵集群的作用与搭建、分片集群的架构与故障转移等。课程详细演示了RDB和AOF持久化方式的实现原理及对比,讲解了主从集群的全量同步和增量同步机制,分析了哨兵集群在故障转移中的作用,并指导如何搭建分片集群及实现集群伸缩。最后还介绍了如何使用RedisTemplate连接哨兵集群和访问分片集群。这些内容全面覆盖了Redis在分布式环境下的高可用和扩展性解决方案。
一、基础认知类(必问)
1. 什么是 Redis 分片集群?和哨兵模式、单节点有什么核心区别?
解析:
- 单节点:单个 Redis 实例,存在性能瓶颈、单点故障风险,无法支撑大规模数据。
- 哨兵模式:主从 + 哨兵监控,解决单节点故障,但主节点性能仍有限,数据容量受单节点内存限制。
- 分片集群 :将数据按规则拆分到多个 Redis 节点(分片),每个节点存储部分数据,同时支持主从复制、故障转移,兼具水平扩容 和高可用 。核心区别:分片集群支持分布式存储(数据分散在多节点)、可线性扩容,而单节点 / 哨兵模式数据集中在单主节点,容量 / 性能受单体限制。
2. Redis 分片集群的核心架构是什么?包含哪些组件?
解析:
- 核心组件:多个 Redis 节点(主 + 从)、集群管理模块、客户端路由 / 分片策略。
- 架构逻辑:
- 数据按哈希槽 / 一致性哈希拆分,每个节点负责一部分槽位 / 数据;
- 每个主节点配从节点,实现主从复制、故障转移;
- 客户端通过集群管理工具(如 Redis 集群客户端)感知节点分布,路由请求到对应节点。
3. 为什么需要 Redis 分片集群?适用什么场景?
解析:
- 核心需求:
- 单节点内存不足,数据量超过单机承载(如百万级用户数据、海量缓存);
- 高并发读写,单节点性能瓶颈,需要水平扩容提升吞吐量;
- 追求高可用,避免单节点故障导致服务不可用。
- 适用场景:社交 / 电商缓存、实时数据统计、用户行为分析等大数据量 + 高并发场景。
二、原理实操类(项目高频)
1. Redis 分片集群的数据分片策略有哪些?常用的是哪种?
解析:
- 常见策略:
- 哈希槽(Slot)策略 :Redis 官方集群默认方案,固定分配 16384 个槽位,每个节点负责部分槽位,数据按
CRC16(key) % 16384映射到对应槽位; - 一致性哈希:将数据和节点映射到 0~2^32 的环形空间,新增 / 删除节点仅影响相邻节点,数据迁移量小;
- 范围分片:按数据范围拆分(如 ID 1-10000 存节点 A,10001-20000 存节点 B),适合有序数据场景。
- 哈希槽(Slot)策略 :Redis 官方集群默认方案,固定分配 16384 个槽位,每个节点负责部分槽位,数据按
- 常用方案:哈希槽策略(Redis 官方支持,社区成熟,适配分布式场景)。
2. 结合你的项目,Redis 集群中数据迁移是如何实现的?扩容时如何保证业务不中断?
解析:
- 数据迁移原理:
- 新增节点时,集群会将部分槽位 / 数据从原有节点迁移到新节点;
- 迁移过程中,源节点和目标节点通过增量同步(Redis 复制机制)完成数据同步,同时客户端请求会被临时路由到源节点 / 目标节点。
- 业务不中断方案:
- 采用在线扩容:先添加从节点,完成数据同步后提升为主节点,无缝替换旧节点;
- 客户端支持集群路由感知:节点变更时自动更新路由信息,无需人工干预;
- 利用 Redis 的管道 / 批量操作减少迁移对业务的影响(可选)。
3. 项目中用到的 Redis 集群,如何保证数据一致性?和单机模式有什么不同?
解析:
- 集群数据一致性核心:
- 主从复制:主节点数据同步到从节点,保证副本数据一致;
- 故障转移:主节点故障时,从节点自动提升为主节点,保证服务可用;
- 槽位管理:槽位分配固定,数据迁移时原子性完成,避免数据丢失 / 重复。
- 与单机差异:
- 单机仅需保证自身数据一致;集群需保证多节点间数据分布一致、路由正确,同时处理跨节点数据同步问题;
- 集群需额外考虑槽位迁移、节点发现、故障感知,一致性保障逻辑更复杂。
4. 结合你项目中的 Java+Redis 场景,如何通过代码操作 Redis 分片集群?(核心配置 / 代码示例)
解析:以 Spring Boot 为例,核心配置 + 代码如下:
java
运行
// 1. 核心配置(application.yml)
spring:
redis:
cluster:
nodes: 192.168.1.10:6379,192.168.1.11:6379,192.168.1.12:6379 # 集群节点列表
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 2
// 2. Java代码操作(StringRedisTemplate)
@Autowired
private StringRedisTemplate redisTemplate;
// 示例:存储数据(自动路由到对应节点)
public void setClusterData(String key, String value) {
redisTemplate.opsForValue().set(key, value);
}
// 示例:读取数据
public String getClusterData(String key) {
return redisTemplate.opsForValue().get(key);
}- 关键:Spring Boot 会自动根据
spring.redis.cluster.nodes配置创建集群连接,无需手动处理路由,底层通过 Lettuce 实现集群感知。
三、故障排查类(高频踩坑)
1. Redis 分片集群出现节点宕机,会触发什么流程?如何排查和恢复?
解析:
- 故障触发流程:
- 主节点宕机 → 哨兵 / 集群监控模块检测到心跳中断 → 触发故障转移;
- 从节点提升为新主节点 → 更新集群槽位路由 → 客户端感知新节点;
- 原主节点恢复后,作为从节点同步新主节点数据。
- 排查步骤:
- 检查节点存活:
redis-cli -h 节点IP -p 端口 ping; - 查看集群状态:
redis-cli -c -h 节点IP -p 端口 cluster info; - 查看日志:
tail -f /var/log/redis/redis-server.log,定位宕机原因(内存溢出、网络故障等)。
- 检查节点存活:
- 恢复方案:
- 若节点可恢复:重启节点,加入集群完成同步;
- 若节点不可恢复:新增节点替换,迁移槽位数据。
2. 集群中出现数据倾斜(某节点内存占用过高),是什么原因?如何解决?
解析:
- 核心原因:
- 哈希算法不合理:导致部分 key 集中在少数节点(如 key 前缀一致,哈希结果集中);
- 业务数据分布不均:某类业务数据量远大于其他;
- 扩容不及时:新增节点后,槽位 / 数据未均衡迁移。
- 解决方案:
- 优化 key 设计:避免 key 前缀一致,增加随机后缀(如
user:1001:info→user:1001_abc:info); - 更换分片策略:改用一致性哈希 + 虚拟节点,打散数据分布;
- 在线扩容:新增节点,触发槽位 / 数据均衡迁移。
- 优化 key 设计:避免 key 前缀一致,增加随机后缀(如
3. Redis 集群中跨节点事务 如何处理?为什么不能直接用MULTI/EXEC?
解析:
- 核心问题:Redis 原生
MULTI/EXEC仅支持单节点原子性,集群中多个节点的命令无法通过原生事务保证原子性。 - 处理方案:
- 业务层面:通过分布式锁(如 Redisson)保证多节点操作的原子性;
- 技术层面:若必须保证原子性,可将相关数据存储在同一个节点(通过 key 分片策略控制),再用单节点事务;
- 补充:Redis 集群不支持
WATCH命令,需业务层自行处理并发问题。
四、优化策略类(进阶加分)
1. 如何优化 Redis 分片集群的性能?从客户端、服务端、架构三个维度分析。
解析:
- 客户端维度:
- 采用连接池复用连接(如 Lettuce 连接池),减少连接开销;
- 批量操作:用
pipeline/transaction减少网络交互(如批量写入 / 读取); - 本地缓存:热点数据加本地缓存(如 Caffeine),减少 Redis 请求。
- 服务端维度:
- 优化内存配置:合理设置
maxmemory,避免频繁淘汰; - 禁用无用功能:关闭
RDB/AOF(若对数据可靠性要求低),提升性能; - 网络优化:部署在同一局域网,减少网络延迟。
- 优化内存配置:合理设置
- 架构维度:
- 读写分离:读请求路由到从节点,减轻主节点压力;
- 冷热数据分离:热点数据存集群,冷数据存独立 Redis 实例;
- 分片优化:根据业务数据量调整分片数量,避免分片过多 / 过少。
2. Redis 集群的数据持久化如何配置?和单节点有什么不同?
解析:
- 集群持久化配置:与单节点一致,支持
RDB、AOF、RDB+AOF三种模式,配置文件redis.conf中设置即可。 - 核心差异:
- 集群中每个节点独立配置持久化策略,需保证所有节点配置一致,避免数据恢复不一致;
- 集群数据迁移时,持久化文件需同步到所有节点,避免故障恢复时数据丢失;
- 生产环境建议:
RDB+AOF混合模式,兼顾数据恢复速度和可靠性。
3. 结合你的项目,Redis 集群如何做监控和告警?(面试可答)
解析:
- 监控工具:
- 官方工具:
redis-cli --stat(实时状态)、redis-cli info(详细指标); - 第三方工具:Prometheus+Grafana(采集集群指标,如内存、QPS、响应时间)、Redis Sentinel(监控集群健康状态);
- 自定义监控:通过 Java 代码调用
RedisInfo接口,采集指标接入公司监控平台。
- 官方工具:
- 告警策略:
- 阈值告警:内存使用率超过 80%、节点宕机、QPS 突增;
- 业务告警:数据写入失败、集群扩容失败等;
- 通知方式:钉钉 / 企业微信机器人、邮件、短信(核心故障)。
4. 项目中如果需要扩容 Redis 集群,具体步骤是什么?如何保证数据不丢失?
解析:以新增节点为例,核心步骤如下:
- 部署新节点:安装 Redis,配置与集群一致(端口、密码、内存等);
- 加入集群:执行
redis-cli --cluster add-node 新节点IP:端口 现有节点IP:端口; - 槽位迁移:执行
redis-cli --cluster reshard 现有节点IP:端口,选择待迁移槽位,分配给新节点; - 数据同步:集群自动将旧节点数据迁移到新节点,同步完成后,槽位分布均衡;
- 验证:查看集群状态
redis-cli --cluster check 现有节点IP:端口,确认节点正常、数据完整。
- 数据不丢失保障:
- 迁移过程采用增量同步,先同步存量数据,再同步增量数据,避免遗漏;
- 迁移期间,客户端请求会被临时路由到源节点 / 目标节点,不影响业务读写;
- 迁移完成后,可通过
redis-cli --cluster check验证数据完整性。