文档结构
1、概念简介
Flink CDC = Apache Flink + CDC (Change Data Capture,变更数据捕获);
Flink CDC 是一套能实时监听数据库变化,并把这些变化流式处理的技术方案。
2、环境搭建
(1)Flink CDC 主文档 - 所有 Connector 总览
地址:https://nightlies.apache.org/flink/flink-cdc-docs-stable/docs/connectors/overview/
(2)Pipeline 模式支持的 Connector(YAML 用)
(3)SQL 模式支持的 CDC Source 列表
2.1、版本映射
Flink CDC 和 flink 版本本身需要兼容,具体如下:
| Flink CDC 版本 | 支持的 Flink 版本 |
|---|---|
| 3.6.x | 1.20.x, 2.2.x |
| 3.5.x | 1.19.x, 1.20.x |
| 3.4.x | 1.19.x, 1.20.x |
| 3.3.x | 1.18.x, 1.19.x, 1.20.x, 2.1.x |
| 3.2.x | 1.17.x, 1.18.x, 1.19.x, 1.20.x |
| 3.1.x | 1.16.x, 1.17.x, 1.18.x, 1.19.x |
| 3.0.x | 1.14.x, 1.15.x, 1.16.x, 1.17.x, 1.18.x |
| 2.4.x | 1.13.x, 1.14.x, 1.15.x, 1.16.x, 1.17.x |
| 2.3.x | 1.13.x, 1.14.x, 1.15.x, 1.16.x |
| 2.2.x | 1.13.x, 1.14.x |
| 2.1.x | 1.13.x |
| 2.0.x | 1.13.x |
| 1.4.0 | 1.13.x |
| 1.3.0 | 1.12.x |
| 1.2.0 | 1.12.x |
| 1.1.0 | 1.11.x |
| 1.0.0 | 1.11.x |
2.2、安装部署
下载地址:https://github.com/apache/flink-cdc/releases
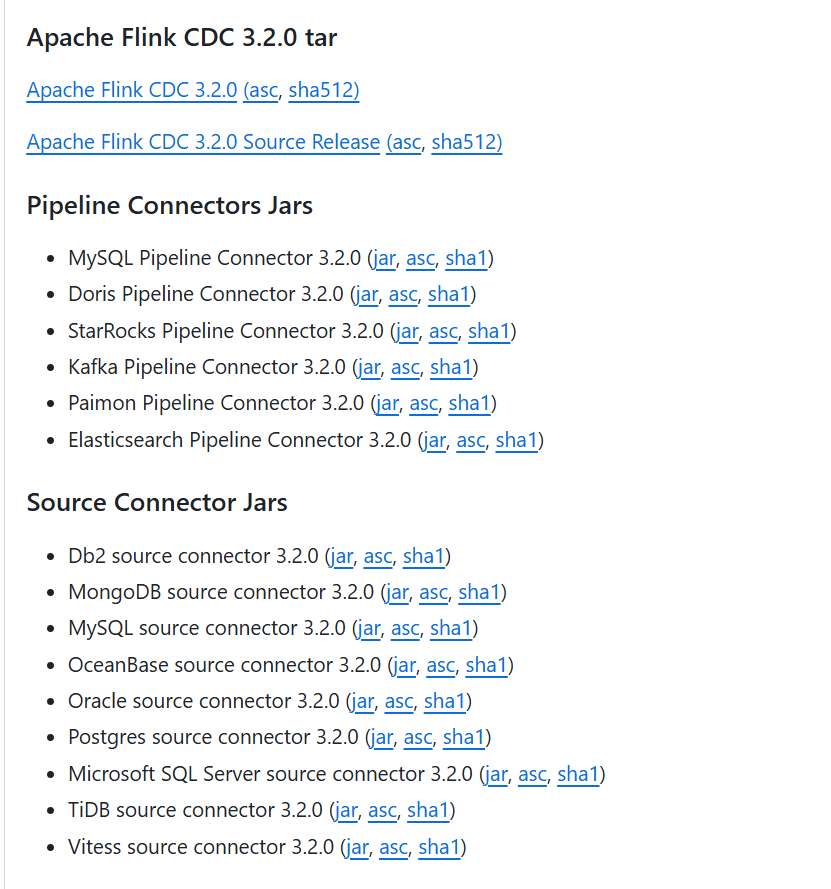
公共包(必须下载)
| 包名 | 作用 | 是否必须 |
|---|---|---|
| Apache Flink CDC 3.2.0 (tar) | 核心运行环境、启动脚本、基础依赖 | ✅ 两种模式都必须 |
分模式(按需下载)
| 模式 | 你当前场景 | 需要下载的连接器 Jar |
|---|---|---|
| Pipeline 模式(YAML 配置) | MySQL → Kafka(YAML 同步) | MySQL Pipeline Connector Jar Kafka Pipeline Connector Jar |
| Flink SQL 模式(写 SQL) | MySQL → Kafka(Flink SQL 同步) | MySQL Source Connector Jar Kafka Sink Connector Jar |
3、数据同步
3.1、pipeline模式
bash
######################################################################
# 这就是你想要的:纯配置同步 MySQL → Kafka,不用写SQL
######################################################################
source:
type: mysql
hostname: 192.168.1.100
port: 3306
username: root
password: 123456
server-id: 1
server-time-zone: Asia/Shanghai
# 同步哪些库、哪些表
database: test_db
table: user,order,product # 可以配多张表
# 或者配通配符:table-include-pattern: test_db\\..*
sink:
type: kafka
name: Kafka Sink
brokers: 192.168.1.200:9092
topic: ods_${database}_${table} # 自动按规则生成topic名
# 格式:默认就是 Debezium-JSON(before/after/op)
format: debezium-json
# 主键作为 Kafka key,保证有序
key.fields: pk
value.fields: include:.*
pipeline:
name: mysql-to-kafka
parallelism: 33.1.1、topic映射
当通过flink cdc 进行数据从数据库同步到 kafka时,flink cdc 支持三种 表和 topic 的映射方式:
1)默认格式(不指定)
源端:db.tablename
topic:db.tablename
2)自定义映射
通过 sink.tableId-to-topic.mapping 参数指定映射关系;
bash
source:
type: mysql
tables: mydb.user, mydb.order, mydb.product
sink:
type: kafka
properties.bootstrap.servers: kafka:9092
# 核心映射配置
sink.tableId-to-topic.mapping: >
mydb.user:ods_user;
mydb.order:ods_order;
mydb.product:ods_product说明:这种格式下,表和topic 的映射规则只能是一一映射,无法进行一些复杂的或者批量映射以及正则匹配映射;
3)route 规则(最灵活)
yaml
source:
type: mysql
tables: app_db.*
sink:
type: kafka
properties.bootstrap.servers: kafka:9092
# 路由映射
route:
- source-table: app_db.orders
sink-table: kafka_ods_orders
- source-table: app_db.shipments
sink-table: kafka_ods_shipments
- source-table: app_db.products
sink-table: kafka_ods_product- 整库同步
yaml
route:
- source-table: test_db\..* # 正则匹配 test_db 所有表(官方语法)
sink-table: ods_test_db_<> # 目标 Topic/表名
replace-symbol: <> # 官方占位符(<> 替换为原表名)
description: 整库同步加前缀(官方标准写法)- 分表合并
yaml
route:
- source-table: test_db\.order_\d+ # 正则匹配 order_01、order_02...(官方)
sink-table: ods_test_db_order_all # 合并到同一个目标
description: 分表合并(官方核心场景)说明:Flink CDC 3.1.0 支持通过 route 将多个分表合并为一个目标表;
- 正则捕获组
yaml
route:
- source-table: test_db\.t_(.*) # 捕获 t_ 后内容(官方捕获组语法)
sink-table: ods_$1 # $1 = 捕获组(官方引用)
description: 去掉前缀 t_(官方高级用法)官方说明:
正则捕获组可以实现(批量去掉前缀 / 重命名)功能更高级;
(.*):正则捕获组(官方支持)
$1:引用第一个捕获组(官方标准)
效果:t_user → ods_user、t_order → ods_order
- 多规则优先级
yaml
route:
# 规则1:VIP表特殊路由(优先)
- source-table: test_db\.vip_user
sink-table: ods_vip_user_special
description: VIP表单独映射
# 规则2:其余表通用规则
- source-table: test_db\..*
sink-table: ods_test_db_<>
replace-symbol: <>
description: 普通表通用路由3.2、flink-sql模式
- sql 模式
bash
-- 1. MySQL 源表
CREATE TABLE mysql_user (
id INT,
name STRING,
phone STRING,
create_time TIMESTAMP,
PRIMARY KEY (id) NOT ENFORCED -- 必须声明主键!
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.1.100',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'test_db',
'table-name' = 'user'
);
-- 2. Doris 目标表
CREATE TABLE doris_user (
id INT,
name STRING,
phone STRING,
create_time TIMESTAMP,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'doris',
'fenodes' = '192.168.1.200:8030',
'table.identifier' = 'ods_db.user_table',
'username' = 'root',
'password' = '',
'sink.label-prefix' = 'doris_user_label',
'sink.enable-2pc' = 'false',
'sink.buffer-count' = '10000',
'sink.buffer-flush.interval' = '1s'
);
-- 3. 同步
INSERT INTO doris_user
SELECT * FROM mysql_user;