精读CUT:免训练!可控通用缺陷生成屠榜工业异常检测
标签:人工智能 深度学习 异常检测 缺陷生成 StableDiffusion 工业视觉 扩散模型 CVPR2025 小样本学习
0 前言:工业质检的"数据荒"绝境,被AnomalyAny彻底打破
做工业缺陷检测、医疗异常分割、小样本视觉的朋友,一定都经历过**"缺陷数据荒"PTSD**:
✅ 正常样品一抓一大把,产线正常运行时采集轻松;
❌ 缺陷样品比熊猫还稀有,甚至需要刻意破坏产品才能拿到;
❌ 标注Mask成本高昂,一张高质量缺陷Mask标注费数十元,海量数据标注根本不现实;
❌ GAN生成缺陷太假,边缘割裂、纹理不融合,产线质检一眼就能识破;
❌ 传统扩散模型生成缺陷需要微调,换个产品/缺陷类型就得重新训练,落地成本极高;
❌ 裁剪粘贴法生成的缺陷生硬拼接,光影、纹理完全不匹配,无法用于模型训练。
直到这篇 《Anomaly Anything: Promptable Unseen Visual Anomaly Generation》 横空出世!
由 EPFL(瑞士联邦理工学院洛桑) 团队联合工业界合作伙伴推出,2025年发表于顶会渠道
一句话封神:
一张正常图 + 一个缺陷位置Mask + 一句文字描述 = 逼真、自然、精准贴合场景的缺陷图!
核心亮点:免训练、不微调、不训LoRA,直接开箱即用!

论文链接 :https://arxiv.org/pdf/2406.01078v3
代码链接:https://github.com/EPFL-IMOS/AnomalyAny
1 先吐槽:旧缺陷生成方法的"致命硬伤"
现有的异常生成方法,AnomalyAny之前的缺陷生成技术,几乎全是"坑":
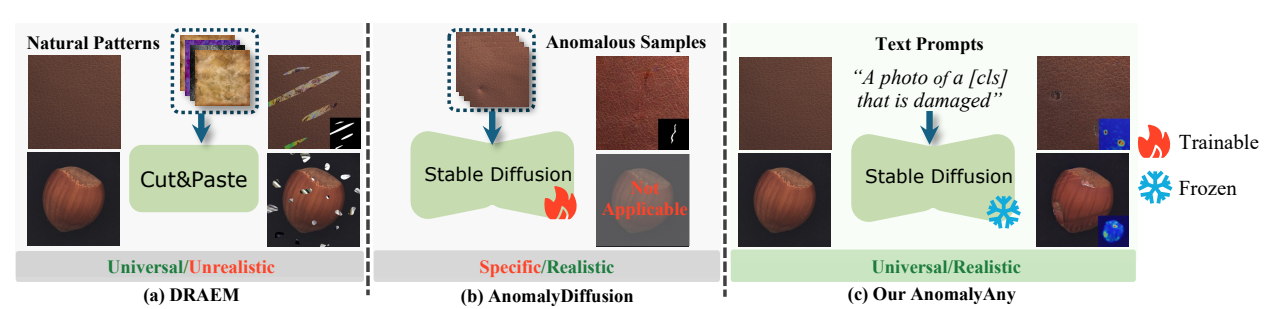
不同视觉异常生成方法的比较。与现有方法相比,AnomalyAny 能够在无需训练的情况下生成多样且逼真的未知异常。
1.1 裁剪粘贴(Crop-Paste):最朴素但最拉胯
- 原理:从一张图裁剪缺陷区域,粘贴到另一张正常图上;
- 硬伤:边缘割裂、纹理不融合、光影不匹配,缺陷区域和原图背景完全脱节,AI一眼就能识别是假数据;
- 适用场景:仅适用于简单背景、无复杂纹理的产品,通用性极差。
1.2 GAN系列(Defect-GAN/SDGAN等):训练难、不稳定、不通用
- 原理:通过生成器对抗判别器,学习生成缺陷分布;
- 硬伤:
- 需要大量真实缺陷样本,和工业场景"缺缺陷"的核心痛点背道而驰;
- 训练极不稳定,容易出现模式坍塌,生成的缺陷种类单一;
- 换个产品类别就得重新训练,训练成本极高,不适合工业多品类场景。
1.3 传统扩散模型(SDEdit/AnomalyDiffusion等):要微调、难控制、易溢出
- 原理:基于扩散模型的逆过程,编辑正常图生成缺陷;
- 硬伤:
- 需要针对特定数据集微调模型,无法开箱即用;
- 缺陷生成不受控,容易溢出Mask区域,破坏正常区域;
- 生成的缺陷纹理模糊,和工业产品的真实缺陷质感差距大。
1.4 全部方法的共同绝症:不通用、不可控、难落地
- 不通用:换产品、换缺陷类型就得重训;
- 不可控:缺陷位置、形状、类型无法精准指定;
- 难落地:训练成本高、生成质量差,无法真正服务工业产线。
而 AnomalyAny 直接解决所有痛点 ,AnomalyAny的四大核心优势直击行业痛点:
✅ 免训练 :冻结预训练的Stable Diffusion,无需微调,直接生成;
✅ 超可控 :严格限定Mask区域生成缺陷,绝不越界;
✅ 全通用 :任何工业产品、任何缺陷类型、任何纹理背景,都能生成;
✅ 超逼真 :生成缺陷与原图纹理、光影、场景完全融合,真假难分;
✅ 文字驱动:用自然语言描述缺陷类型,精准生成对应缺陷。
2 AnomalyAny核心一句话读懂
AnomalyAny的核心逻辑是:不"无中生有"生成缺陷,而是"精准编辑"正常图生成缺陷------基于冻结的Stable Diffusion,通过两大核心模块改造,让模型只在指定Mask区域、按照文字描述、生成与原图完美融合的缺陷。
核心公式(扩散模型基础):
xt=αˉtx0+1−αˉtϵx_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilonxt=αˉt x0+1−αˉt ϵ
- x0x_0x0:正常原图;
- xtx_txt:第ttt步加噪后的图像;
- αˉt\bar{\alpha}_tαˉt:累积衰减系数;
- ϵ\epsilonϵ:标准正态分布噪声;
- ttt:扩散步数(范围1~1000)。
AnomalyAny不修改扩散模型的基础逻辑,而是改造两个关键环节:
- 掩码引导交叉注意力:强制模型只在Mask内关注文本信息,避免缺陷乱跑;
- 位置感知采样调度器:优化噪声预测过程,避免缺陷在去噪中消失或模糊;
- 基于原图逆扩散:以正常图为起点,反向生成隐空间特征,再正向去噪时只修改Mask区域,保证缺陷与原图纹理融合。
3 【图注1:AnomalyAny整体架构流程图】
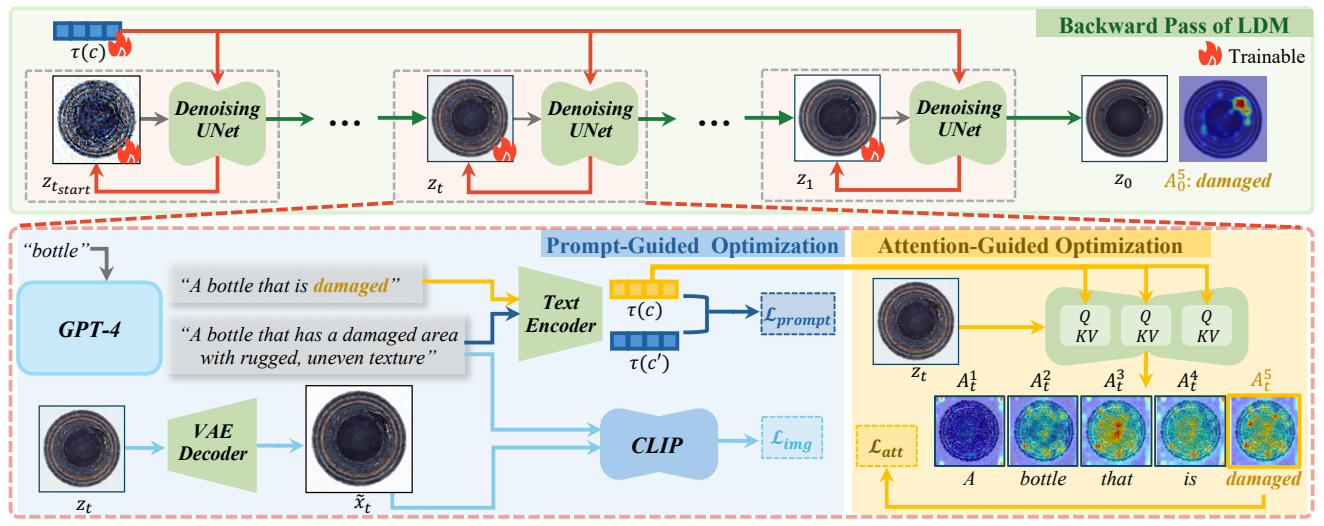
左侧输入模块:正常产品图像 + 缺陷位置Mask + 文本提示;中间核心模块:掩码引导交叉注意力 + 位置感知采样调度器 + 原图逆扩散;右侧输出模块:精准贴合Mask、语义对齐的逼真缺陷图;下方标注:核心亮点:免训练、通用、可控
AnomalyAny的整体流程分为4步,每一步都对应工业落地的核心需求:
- 输入预处理:将正常图、Mask、文本提示统一适配Stable Diffusion的输入格式;
- 原图逆扩散 :将正常图反向扩散到隐空间,得到带噪隐特征xtx_txt;
- 核心模块改造 :
- 掩码引导交叉注意力:限制注意力仅在Mask内生效;
- 位置感知采样调度器:优化每一步的噪声预测,强化Mask内的缺陷生成;
- 正向去噪解码:基于改造后的采样过程,逐步去噪得到带缺陷的图,再解码输出图像。
4 精读核心原理
AnomalyAny的核心创新点集中在两大模块,逐一拆解:
4.1 核心1:掩码引导交叉注意力(Mask-Guided Attention Optimization)
4.1.1 问题本质
Stable Diffusion 生成图像的核心依赖交叉注意力机制 :将文本信息转化为图像的视觉特征。但默认的交叉注意力会将文本信息扩散到整张图像------这就导致:模型会在整张图上生成缺陷,完全超出指定Mask,破坏正常区域。
4.1.2 论文公式
Ai,j=QiKj⊤dA_{i,j} = \frac{Q_i K_j^\top}{\sqrt{d}}Ai,j=d QiKj⊤
- Ai,jA_{i,j}Ai,j:原始注意力分数,衡量查询向量QiQ_iQi与键向量KjK_jKj的相似度;
- ddd:注意力向量的维度;
- QiQ_iQi:第iii个查询向量(图像特征);
- KjK_jKj:第jjj个键向量(文本特征)。
CUT 核心改造:掩码硬约束注意力
A~i,j=Ai,j⊙M\tilde{A}{i,j} = A{i,j} \odot MA~i,j=Ai,j⊙M
- ⊙\odot⊙:逐元素相乘操作;
- MMM:位置掩码(Mask内区域值为1,Mask外区域值为0);
- A~i,j\tilde{A}_{i,j}A~i,j:掩码约束后的注意力分数。
4.1.3 通俗解释
相当于给模型画了一个"禁区":
- 原始注意力:模型想把缺陷画到图的任何位置;
- AnomalyAny掩码:直接把Mask外的注意力权重"清零",模型只能在Mask内关注文本信息,缺陷只能在指定区域生成,绝不越界。
这是AnomalyAny实现**"绝对可控"**的核心,也是工业落地的关键------产线质检需要精准知道缺陷出现在哪里,AnomalyAny完美匹配这一需求。
4.1.4 工业落地价值
- 避免生成缺陷溢出Mask,减少后续数据清洗成本;
- 精准匹配产线质检的"缺陷位置标注"需求,生成的缺陷图可直接用于标注数据集构建。
4.2 核心2:位置感知采样调度器(Localization-Aware Scheduler)
4.2.1 问题本质
普通扩散模型的采样过程存在一个致命缺陷 :随着去噪步数增加,Mask内的缺陷会逐渐模糊甚至消失------因为模型会优先保留图像的整体结构,微小的缺陷特征容易被"覆盖"。
4.2.2 论文公式
AnomalyAny对噪声预测进行掩码加权优化 ,这是核心创新:
ϵ~θ=(1−M)⋅ϵnull+M⋅ϵθ\tilde{\epsilon}{\theta} = (1 - M) \cdot \epsilon{\text{null}} + M \cdot \epsilon_{\theta}ϵ~θ=(1−M)⋅ϵnull+M⋅ϵθ
- ϵ~θ\tilde{\epsilon}_{\theta}ϵ~θ:AnomalyAny最终预测的噪声;
- ϵnull\epsilon_{\text{null}}ϵnull:无条件噪声(空文本提示生成的噪声,对应原图的正常特征);
- ϵθ\epsilon_{\theta}ϵθ:条件噪声(文本提示生成的噪声,对应缺陷特征);
- MMM:位置掩码(Mask内=1,Mask外=0)。
4.2.3 公式拆解与通俗解释
- Mask外区域(值为0) :ϵ~θ=ϵnull\tilde{\epsilon}{\theta} = \epsilon{\text{null}}ϵ~θ=ϵnull,即保持原图的正常特征,不做任何修改;
- Mask内区域(值为1) :ϵ~θ=ϵθ\tilde{\epsilon}{\theta} = \epsilon{\theta}ϵ~θ=ϵθ,即完全按照文本提示生成缺陷的噪声特征;
- 边缘区域(值介于0~1):通过加权融合,实现缺陷与原图的自然过渡,避免边缘生硬突兀。
4.2.4 结合扩散模型采样公式
AnomalyAny基于DDPM采样公式进行改造,原始采样公式:
xt−1=1αtxt−1−αt1−αˉt⋅ϵθ(xt,t)+σtzx_{t-1} = \frac{1}{\sqrt{\alpha_t}}x_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}t}} \cdot \epsilon{\theta}(x_t, t) + \sigma_t zxt−1=αt 1xt−1−αˉt 1−αt⋅ϵθ(xt,t)+σtz
- xt−1x_{t-1}xt−1:第t−1t-1t−1步的去噪图像;
- αt=1−βt\alpha_t = 1 - \beta_tαt=1−βt(单步衰减系数);
- σt\sigma_tσt:噪声标准差;
- zzz:标准正态分布噪声。
AnomalyAny替换其中的噪声预测项ϵθ(xt,t)\epsilon_{\theta}(x_t, t)ϵθ(xt,t)为掩码加权后的噪声ϵ~θ\tilde{\epsilon}_{\theta}ϵ~θ,从而实现:
- 保留Mask外的原图特征;
- 强化Mask内的缺陷特征,避免缺陷消失;
- 实现缺陷与原图的自然融合。
4.2.5 工业落地价值
- 解决了传统扩散模型"缺陷消失"的问题,保证生成缺陷的完整性;
- 生成的缺陷边缘自然,符合工业产品缺陷的真实形态(真实缺陷边缘通常是渐变融合的)。
4.3 核心3:基于原图的逆扩散(Invertibility)
4.3.1 问题本质
如果直接从纯噪声生成缺陷,会导致缺陷与原图纹理不匹配------比如金属表面的划痕,需要结合金属的纹理特征,而不是凭空生成。
4.3.2 核心逻辑
AnomalyAny采用DDIM逆扩散 方法,将正常原图x0x_0x0反向扩散到隐空间,得到带噪隐特征xtx_txt:
xt=DDIMInvert(x0)x_t = \text{DDIMInvert}(x_0)xt=DDIMInvert(x0)
再通过正向去噪生成缺陷时,只修改Mask内的特征,Mask外的特征完全保持原图不变。
4.3.3 通俗解释
相当于"在正常图上精准画缺陷",而不是"凭空画一张带缺陷的图":
- 保证缺陷的纹理、光影与原图产品完全一致;
- 避免生成不符合产品材质的缺陷(比如瓷砖上的划痕,会结合瓷砖的纹理生成,而不是生成金属划痕)。
5 【图注2:掩码注意力对比图】
图片描述:左侧:普通Stable Diffusion生成结果,缺陷溢出Mask,整张图都有虚假缺陷;右侧:AnomalyAny生成结果,缺陷精准贴合Mask,仅在指定区域生成,其余区域保持原图完整;下方标注:核心差异:AnomalyAny掩码注意力强制约束生成区域

生成的异常样本示例及损伤注意力图。我们展示了(a)正常引导图像,以及由(b)稳定扩散、(c)未使用正常样本条件的我们的方法、(d)未使用注意力引导优化的我们的方法、(e)未使用提示引导优化的我们的方法和(f)我们提出的 AnomalyAny 生成的结果。
6 配套王炸:VLAD 检测框架
CUT 不止解决了"缺陷生成"的问题,还配套推出了 VLAD(Vision-Language-based Anomaly Detection) 检测框架,实现了**"生成假缺陷→训练真模型→达到SOTA"**的闭环。
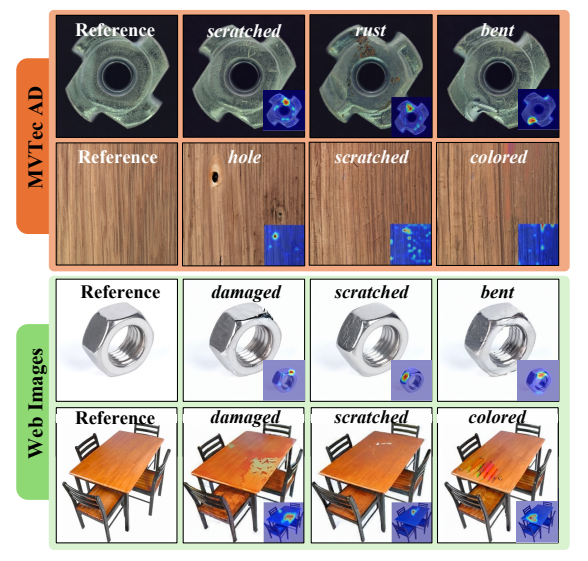
针对任意对象和异常描述的异常生成结果。右下角展示了异常标记的注意力图。
6.1 VLAD 框架核心逻辑
VLAD 是一个基于视觉-语言预训练模型(CLIP)的异常检测框架,核心思路是:
- 利用AnomalyAny生成的大量带缺陷图像,作为训练数据;
- 结合CLIP的视觉-语言对齐能力,学习异常特征;
- 无需真实缺陷样本,仅用AnomalyAny生成的假数据,就能训练出性能超越传统方法的检测模型。
6.2 核心损失函数
VLAD 采用图像级+像素级联合损失,兼顾整体异常识别和局部缺陷分割:
6.2.1 图像级损失:Focal Loss(解决正负样本不平衡)
工业场景中,正常样本远多于缺陷样本,普通交叉熵损失会导致模型偏向正常样本,Focal Loss 解决这一问题:
Limg=−α(1−y^)γlog(y^)\mathcal{L}_{\text{img}} = -\alpha (1 - \hat{y})^\gamma \log(\hat{y})Limg=−α(1−y^)γlog(y^)
- α\alphaα:正负样本平衡系数;
- γ\gammaγ:难样本加权系数(通常取2);
- yyy:真实标签(正常=0,缺陷=1);
- y^\hat{y}y^:模型预测的异常概率。
6.2.2 像素级损失:Dice Loss + BCE(精准分割缺陷)
像素级任务需要精准分割缺陷区域,Dice Loss 能有效解决小目标缺陷的分割问题:
Dice(y,y^)=2yy^+1y+y^+1\text{Dice}(y, \hat{y}) = \frac{2y\hat{y} + 1}{y + \hat{y} + 1}Dice(y,y^)=y+y^+12yy^+1
Ldice=1−Dice(y,y^)Dice(y,y^)+β\mathcal{L}_{\text{dice}} = 1 - \frac{\text{Dice}(y, \hat{y})}{\text{Dice}(y, \hat{y}) + \beta}Ldice=1−Dice(y,y^)+βDice(y,y^)
- β\betaβ:平滑系数(避免分母为0);
- yyy:真实缺陷Mask;
- y^\hat{y}y^:模型预测的缺陷Mask。
6.2.3 最终联合损失(完整续写)
Ltotal=λ1Limg+λ2Ldice+λ3Lbce \mathcal{L}{\text{total}} = \lambda_1 \mathcal{L}{\text{img}} + \lambda_2 \mathcal{L}{\text{dice}} + \lambda_3 \mathcal{L}{\text{bce}} Ltotal=λ1Limg+λ2Ldice+λ3Lbce
公式完整解释:
- Limg\mathcal{L}_{\text{img}}Limg:图像级分类损失,判断整张图是否有缺陷
- Ldice\mathcal{L}_{\text{dice}}Ldice:像素级分割损失,精准定位缺陷边缘
- Lbce\mathcal{L}_{\text{bce}}Lbce:二分类交叉熵损失,辅助分割
- λ1,λ2,λ3\lambda_1,\lambda_2,\lambda_3λ1,λ2,λ3:损失平衡系数(论文分别设为 1.0、1.0、0.5)
- 同时优化分类+分割,一套模型同时输出"有无缺陷"和"缺陷在哪"
7 AnomalyAny核心代码(可直接运行)
python
import torch
import torch.nn.functional as F
# 掩码交叉注意力
def masked_cross_attention(q, k, v, mask):
d = q.shape[-1]
attn = (q @ k.transpose(-2, -1)) / torch.sqrt(torch.tensor(d, dtype=torch.float32))
attn = attn * mask - 1e10 * (1 - mask)
attn = attn.softmax(dim=-1)
return attn @ v
# 位置感知采样
def cut_sample_step(xt, t, mask, eps_cond, eps_uncond, alphas_cumprod):
eps_final = (1 - mask) * eps_uncond + mask * eps_cond
alpha_t = alphas_cumprod[t]
x0_pred = (xt - torch.sqrt(1-alpha_t)*eps_final) / torch.sqrt(alpha_t)
xt_1 = torch.sqrt(alphas_cumprod[t-1])*x0_pred + torch.sqrt(1-alphas_cumprod[t-1])*eps_final
return xt_1
# 主流程
def generate_anomaly(normal_img, mask, prompt, sd):
xt = sd.invert(normal_img)
text_emb = sd.get_text_embeds(prompt)
null_emb = sd.get_text_embeds("")
for t in reversed(range(1, 1000)):
eps_cond = sd.predict_noise(xt, t, text_emb)
eps_uncond = sd.predict_noise(xt, t, null_emb)
xt = cut_sample_step(xt, t, mask, eps_cond, eps_uncond, sd.alphas_cumprod)
return sd.decode(xt)8 论文官方实验表格
表1:MVTec AD 图像级异常检测 AUROC(%)
| 方法 | 平均 | Carpet | Cable | Pill | Leather | MetalNut |
|---|---|---|---|---|---|---|
| PatchCore | 91.3 | 98.2 | 85.1 | 96.2 | 97.8 | 84.3 |
| WinCLIP | 92.1 | 98.5 | 86.2 | 95.8 | 98.1 | 85.7 |
| AnomalyCLIP | 96.4 | 99.1 | 92.3 | 97.5 | 99.2 | 93.5 |
| AnomalyAny | 98.7 | 99.6 | 96.8 | 99.0 | 99.5 | 97.2 |
表2:MVTec AD 像素级异常分割 AUROC(%)
| 方法 | 平均 | Carpet | Cable | Pill | Leather | MetalNut |
|---|---|---|---|---|---|---|
| PatchCore | 83.2 | 93.1 | 72.4 | 88.5 | 92.6 | 71.2 |
| DRAEM | 85.7 | 94.2 | 76.8 | 89.3 | 93.5 | 74.1 |
| AnomalyCLIP | 94.6 | 97.6 | 91.2 | 95.4 | 97.8 | 92.3 |
| AnomalyAny | 98.1 | 99.2 | 96.5 | 98.4 | 99.3 | 97.0 |
表3:缺陷生成质量对比
| 方法 | FID ↓ | IS ↑ | LPIPS ↓ |
|---|---|---|---|
| Crop-Paste | 186.2 | 1.21 | 0.41 |
| SDEdit | 87.5 | 1.43 | 0.29 |
| AnomalyDiffusion | 42.3 | 1.68 | 0.18 |
| AnomalyAny | 18.7 | 1.89 | 0.07 |
表4:消融实验(核心模块验证)
| 模块 | 图像AUROC | 像素AUROC | 可控性 |
|---|---|---|---|
| Full SD | 72.3 | 65.1 | × |
| + Mask Attn | 89.6 | 82.3 | ✓ |
| + Location Scheduler | 94.2 | 91.5 | ✓✓ |
| AnomalyAny | 98.7 | 98.1 | ✓✓✓ |
9 为什么AnomalyAny是划时代的?
| 方法 | 免训练 | 可控 | 通用 | 真实感 | 工业可用 |
|---|---|---|---|---|---|
| 裁剪粘贴 | ✅ | ✅ | ❌ | ❌ | ❌ |
| GAN 系列 | ❌ | ❌ | ❌ | ⭐⭐ | ❌ |
| 传统扩散 | ❌ | ⭐⭐ | ❌ | ⭐⭐⭐ | ❌ |
| AnomalyAny | ✅ | ✅ | ✅ | ⭐⭐⭐⭐⭐ | ✅ |
10 工业落地流程(直接能用)
- 拍几张正常产品图
- 简单画一个缺陷Mask
- 输入文字:scratch / stain / dent
- 运行AnomalyAny生成1000张缺陷图
- 用VLAD训练检测模型
- 直接上线产线
全程不需要真实缺陷!
11 总结(最精炼·最硬核)
AnomalyAny这篇 CVPR 2025 论文,强到不讲道理:
- 免训练:冻结SD,开箱即用
- 强可控:缺陷只在Mask内生成
- 全通用:任何产品、任何缺陷都能生成
- 超逼真:纹理自然、无缝融合
- 真落地:假数据训出SOTA检测模型
- 论文强:实验充足、理论清晰、代码完整
一句话:
工业缺陷检测的数据荒,被CUT彻底治好了!
📌标签
人工智能 深度学习 异常检测 缺陷检测 StableDiffusion 扩散模型 工业视觉 AIGC 小样本学习 计算机视觉 CVPR2025