Harness Engineering is the practice of building the infrastructure (guides, sensors, and feedback loops) that surrounds an AI model to steer its behavior, validate its outputs, and enable continuous self-improvement---essentially everything in an AI agent except the model itself.
一、问题起源:从「能跑」到「持续变好」
「让 LLM 根据自然语言生成图表代码」------这个目标听起来简单。把 API 文档塞进 prompt,初版 demo 两天就能跑起来。但真正的挑战在于:如何系统性地让生成质量持续提升?
传统做法是:人工分析失败案例 → 手动修改知识库 → 重新测试。这个流程可以工作,但它是线性的、依赖人工的、难以规模化的。
AntV chart-visualization-skills 项目的 Harness 子系统给出了一个不同的答案:把优化循环本身自动化------让 LLM 分析自己的失败,改进知识库,再重新评测。
二、架构概览:五 Agent + 控制器的闭环流水线
整个 Harness 系统由五个职责单一的 Agent 和一个 Controller 组成:
Controller Loop
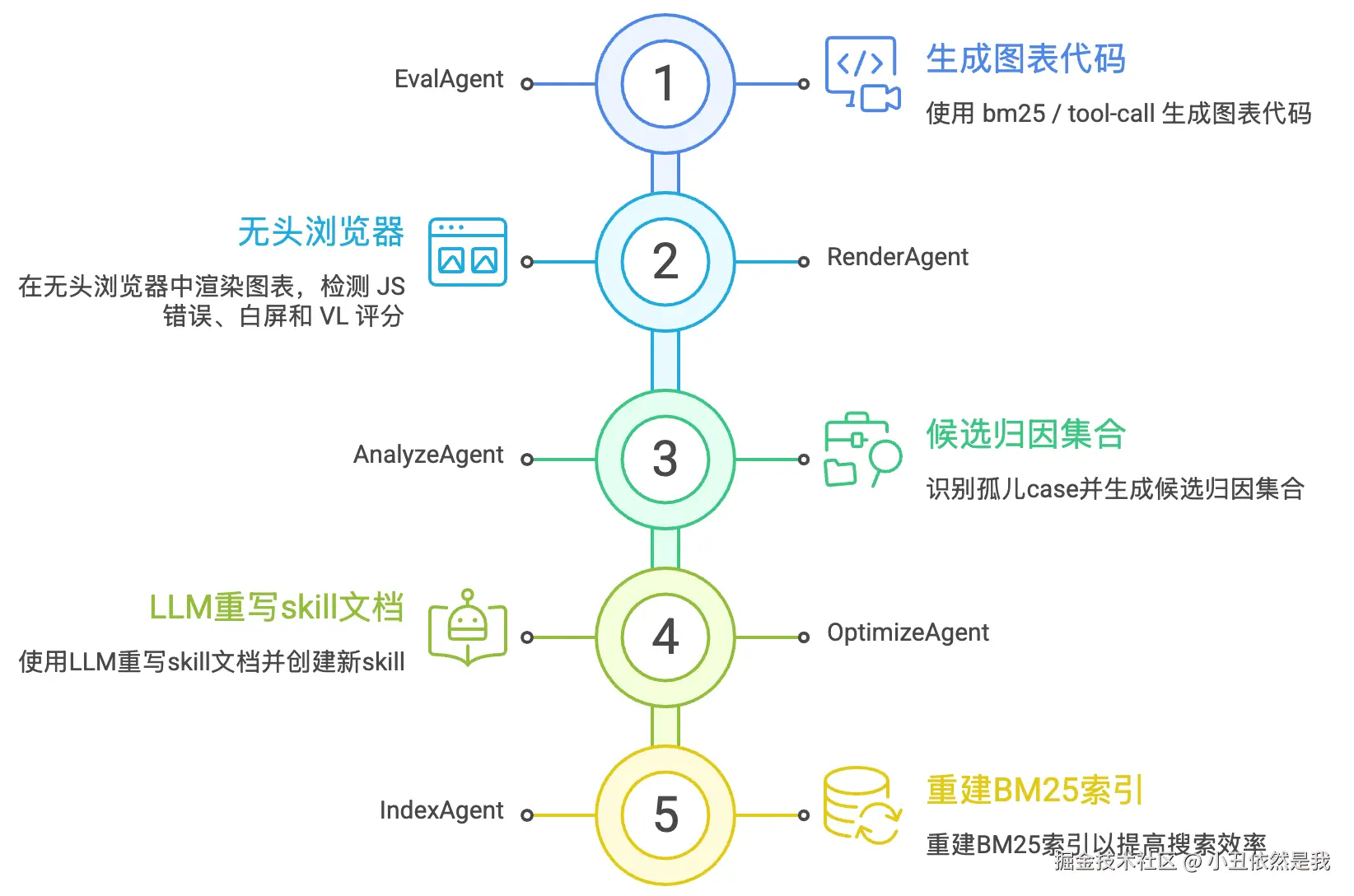
每个 Agent 职责清晰,通过 Controller 协调形成闭环:
javascript
// controller.js 核心循环
while (consecutivePasses < MAX_PASSES) {
const resultPath = await runEval(ids);
const errorCases = await renderAgent.run(resultPath);
const { skillToErrors, orphanCases } = analyzeAgent.run(errorCases);
await optimizeAgent.run(skillToErrors, { orphanCases });
await indexAgent.run();
}三、五 Agent 详解
3.1 EvalAgent
EvalAgent 负责调用 eval CLI,让 LLM 基于现有 skill 生成图表代码。支持三种检索策略:
| 策略 | 工作方式 | 适用场景 |
|---|---|---|
bm25 |
预先检索相关 skill,直接注入 prompt | 快速测试、低成本 |
tool-call |
LLM 通过多轮工具调用主动拉取 skill | 精准检索、复杂查询 |
关键设计------ --ids** 参数定向重测**:支持指定 case ID 重测,而非每次全量运行。这为后续调度逻辑奠定了基础。
3.2 RenderAgent
生成代码是否正确,最终要靠执行来验证。RenderAgent 使用 Playwright 无头浏览器实际运行代码,判断三种失败状态:
- error:JavaScript 报错,代码根本没跑起来
- blank:画布为空,代码执行了但什么都没画出来(白屏)
- 低视觉得分:图表渲染了,但通过 VL(视觉语言)模型判定与预期不符
白屏检测的重要性:白屏通常意味着数据绑定错误或 API 用法有误,但没有 JS 异常。这类问题纯靠代码静态分析抓不到,必须实际渲染后检查画布是否有像素内容。
3.3 AnalyzeAgent
把 error cases 映射到具体的 skill 文件,但这里有一个根本性的难题:一次 LLM 调用可能读取了多个 skill,你不知道是哪个 skill 导致了错误。
最朴素的归因策略是"谁最后被读就改谁",但这往往是错的。比如:LLM 先读了 bar-chart skill 拿到基础用法,再读了 color-mapping skill 调整颜色,结果最终代码在 bar chart 的数据格式上出了问题------最后读的是 color-mapping,但真正的 bug 在 bar chart skill 的示例里。
AnalyzeAgent 的做法是:收集 LLM 实际读取的所有 skill,构成候选归因集合,然后把整个集合交给 OptimizeAgent,让 OptimizeAgent 的 LLM 自己判断根因在哪里。
对于没有对应 skill 的 case,AnalyzeAgent 将其标记为 "孤儿 case"(orphanCases)。孤儿 case 的存在意味着知识库里有盲区------某些图表类型压根没有 skill 覆盖,这会触发 OptimizeAgent 的新 skill 创建流程。
3.4 OptimizeAgent
模型选择上,会区别于 Eval 阶段使用的模型,质量优先。
OptimizeAgent 对每个有问题的 skill 并行调用 LLM 重写。System Prompt 设计非常关键:
plain
当前 skill 是候选归因,不一定是真正的根本原因。
- 如果你判断该 skill 确实有问题,输出修正后的完整文档
- 如果你认为该 skill 没有问题,原样输出即可把"是否需要修改"的判断权交给 LLM,而非强制对每个候选 skill 都生成修改版本。OptimizeAgent 还支持工具调用,可以查阅本地官方文档和源码,但有路径访问白名单保护:
javascript
function assertAllowed(filePath) {
const realRoots = allowedRoots.map((r) => fs.realpathSync(path.resolve(r)));
if (!realRoots.some((r) => realPath === r || realPath.startsWith(r + path.sep))) {
throw new Error(`Access denied: ${filePath} is outside allowed ref paths.`);
}
}安全机制:
- 响应长度 < 原文件 50%:跳过(防止截断导致文档大幅缩水)
- 响应与原文完全相同:跳过(LLM 判定非根因,正确行为)
- 写入前先备份
.bak文件,失败自动还原
对于孤儿 case,OptimizeAgent 会创建全新的 skill 文件。为了让 LLM 一次生成多个 skill,设计了结构化分隔符协议:
plain
<<<SKILL_START:grouped-bar-chart>>>
---
title: Grouped Bar Chart
tags: [...]
---
# 分组柱状图
...
<<<SKILL_END>>>3.5 IndexAgent
每轮优化后重建 BM25 索引,确保下一轮 eval 能检索到最新内容。这一步看似平淡无奇,但省略则整个优化循环形同虚设------LLM 改了文档,但检索引擎用的还是旧索引。
四、Controller
4.1 终止条件:连续通过机制
javascript
while (consecutivePasses < MAX_PASSES) {
// ...
if (errorCases.length === 0) {
consecutivePasses++;
console.log(`Clean pass (${consecutivePasses}/${MAX_PASSES})`);
}
}为什么是「连续」通过而非单次通过?因为修复一个 bug 可能引入新 bug。只有连续多轮无错误,才能确信知识库质量稳定。
4.2 固定样本 + 定向重测:让「通过」有意义
问题:如何判断一轮优化真的有效?
固定样本 :第一轮确定的 case IDs 锁定为 fixedCaseIds,后续每轮用同一批 case。如果每轮随机采样,可能出现「恰好这轮都是简单 case」的假阳性。
定向重测 :每轮优化后,把失败的 case IDs 存入 priorityCaseIds,下一轮只测这些 case,快速验证修复。
配合流程:
plain
第 N 轮:全量 fixedCaseIds → [case-3, case-7, case-12] 失败
→ 优化相关 skill
→ priorityCaseIds = [case-3, case-7, case-12]
第 N+1 轮(定向):只测 [case-3, case-7, case-12] → 全部通过
→ 不计入 consecutivePasses
→ 跑完整 fixedCaseIds 确认
第 N+2 轮(全量):全量 fixedCaseIds → 全部通过 → consecutivePasses++4.3 Worktree 隔离 + Baseline 对比
所有 skill 优化操作在独立的 git worktree 上进行,优化完成后对比 worktree 和 main 分支,这防止了「修好 A 但引入 B 的回归」,因为每个 skill 可能被多个 case 使用。
五、Memory 系统:跨轮次的持久化学习
每一轮优化的信息不应该随着进程退出而消失。Memory 系统实现了跨轮次的记忆持久化:
javascript
// memory.js
class HarnessMemory {
// 记录错误
recordErrors(skillPath, errorCases, iteration) {
const history = this._skill(skillPath);
for (const c of errorCases) {
history.errors.push({
caseId: c.id,
errorType: this._errorType(c),
query: c.query,
iteration,
ts: Date.now(),
});
}
this._save();
}
// 记录优化动作
recordOptimization(skillPath, errorCases, iteration) { /* ... */ }
// 生成历史摘要注入 LLM prompt
getOptimizationContext(skillPath) { /* ... */ }
}5.1 持续错误类型高亮
getOptimizationContext 会高亮持续出现的错误类型(在 ≥2 轮中出现),相当于给 LLM 提供「重点关注清单」:
plain
【历史优化记录 --- bar-chart-grouped.md】
共优化 3 次,累计错误 7 条。
- 第 2 轮:3 个错误,类型:blank, TypeError: ...
- 第 3 轮:2 个错误,类型:blank
⚠️ 持续出现的错误类型(跨多轮未解决):blank5.2 原子写入
javascript
_save() {
const tmp = `${this._path}.tmp`;
fs.writeFileSync(tmp, JSON.stringify(this._data, null, 2));
fs.renameSync(tmp, this._path); // POSIX 原子操作
}5.3 路径归一化
解决 worktree 和主仓库绝对路径不同的问题:
javascript
_normalizeKey(skillPath) {
if (path.isAbsolute(skillPath)) {
return path.relative(PROJECT_ROOT, skillPath);
}
return skillPath;
}这确保同一个 skill 文件在不同环境下被视为同一条记录。
六、模式的通用性
如何为一个 SKILL 系统建立知识库质量的持续改进机制。这个问题不局限于图表生成。任何「LLM + 结构化知识库」的系统都面临同样挑战------代码生成工具、客服 FAQ、法律/医疗垂直领域的专业知识库。
核心模式可以抽象为:
plain
评测(量化当前质量)
→ 执行验证(在真实环境中验证)
→ 分析归因(定位到具体文档)
→ LLM 优化(驱动文档改进)
→ 重索引(让改动立即生效)
→ 循环这条流水线的前提是:「评测」和「执行验证」这两步可以自动化。
对图表生成,Playwright 无头浏览器就是执行环境;对其他场景,你需要找到对应的自动验证方式。
七、结语
Harness 系统的代码量并不大,但它把一个复杂的质量优化问题拆解成了五个职责清晰的 Agent,用一套严谨的调度逻辑把它们串联起来,通过 **Feedforward **和 **Feedback **进行相关指引和校正。
Feedforward :skills/ 目录提供结构化知识,通过 BM25/tool-call 策略注入 prompt;
Feedback:RenderAgent 检测 JS 错误/白屏/低视觉评分,AnalyzeAgent 归因,OptimizeAgent 重写文档。
如果文章对你有用,别忘了给个小星星。