一、实验目的
利用有穷自动机FA开展指定高级程序设计语言(如C语言)的词法分析、设计及实现。能够正确掌握有穷自动机词法分析的技术原理及方法,针对C语言的不同单词,开展单词识别模型设计及词法分析处理。
自主查阅参考资料,结合12章有穷自动机的课堂讲解,利用高级程序设计语言(编码语言不限制,如C/C++/java/Python等)开展词法分析器设计及编码实践,分析结果、撰写实验报告。
二、实验环境(仪器设备、软件等)
1、机房电脑 Window10
2、Dev-C++/ Eclipse等
三、实验原理(或要求)
( 1 )待识别的 C 语言单词类型包括:
关键字、标识符、常量(包括整型、浮点型等)、运算符、界符等;
关键字:if, else, while, for等
...
( 2 )不同类型单词有穷自动机状态转换图 DFA 。
词法分析是编译原理中的一个关键阶段,它主要负责将输入的源代码字符串分解成一系列的标记(tokens),这些标记是源代码的基本构成元素。
( 3 )词法分析的实验内容及原理:
①词法分析器的核心功能
编译过程的第一步是进行词法分析,词法分析程序的功能是:扫描源程序字符,按语言的词法规则识别出各类单词或符号,并将有关字符组合成为单词并输出,同时进行词法检查。
单词符号的形式为:Token 二元组 ( 单词符号种别 / 类型,属性值 )
②根据有穷自动机状态转换图进行单词识别。
确定有穷自动机DFA在编译原理中的一个实际应用例子是识别源代码中的关键字。
四、实验步骤
(1)识别C语言的不同单词状态状态转换图DFA如下:(见文末链接)
(2)实验中采用的不同类型单词的种别码表;(见文末链接)
|---|
| |
| |
(3)词法分析器主要函数、变量说明及算法流程图。(见文末链接)
主要函数说明:
initKeywords() 初始化关键字映射表,建立关键字到种别码的关系
initOperators() 初始化运算符映射表,建立运算符到种别码的关系
initDelimiters() 初始化界符映射表,建立界符到种别码的对应关系
Lexer::advance() 读取下一个字符,处理行号计数
关键变量说明:
基于FA的词法分析的模型设计思路:(见文末链接)
算法流程图:(见文末链接)
(4)词法分析器完整代码(见文末链接)
核心数据结构:Token结构体:存储词法单元的三元组;三个符号表:关键字、运算符、界符的映射表
五、记录与处理
① 数据1:
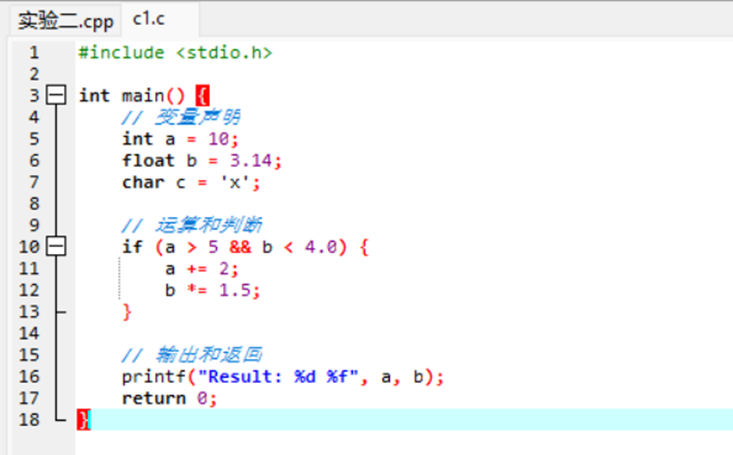
词法分析结果:
测试结果都与预期结果一致。
六、思考与总结
实验过程中,我通过设计和实现DFA状态转换图,掌握了如何识别不同类型的单词,如关键字、标识符、常量、运算符和界符等,我还学会了如何处理空白字符、注释以及错误处理机制。我掌握了DFA在词法分析中的应用原理和方法,并生成了对应的Token序列,最终测试结果都与预期结果
七、成果文件提取链接
通过网盘分享的文件:
链接: https://pan.baidu.com/s/1grJ6ohwR_svNbvH2pk5igg?pwd=mj2u 提取码: mj2u