摘要:瓴岳科技原数据平台基于 Hive 与 StarRocks、Spark 多引擎协同架构,随着数据规模增长,在性能与易用性上逐渐面临瓶颈。通过引入阿里云 SelectDB,构建湖仓一体化探索分析平台,在无需迁移数据的前提下实现对 Hive 数据湖的透明加速,显著提升查询性能并简化架构,完成从多引擎协同向统一分析平台的升级。
瓴岳科技是一家以大数据与人工智能为核心的数字科技集团,旗下拥有国内产品洋钱罐与印尼市场产品 Easy Cash,致力于为全球用户提供卓越的金融科技服务。截至 2025 年,公司已服务全球超 114 家金融机构,拥有逾 1.81 亿注册用户,累计交易额突破 5400 亿元。
原数据平台采用 Hive 数据湖与多计算引擎(StarRocks / Spark)协同模式,其中 StarRocks 在部分场景中承担查询加速的能力。随着业务全球化与数据规模的迅猛增长,对查询体验及查询性能提出更高要求,原有架构在易用性、查询性能和扩展性方面逐渐暴露出瓶颈。
- 平台接入复杂:原有架构在 Hive 之上提供 StarRocks、Spark 等多套计算引擎供业务方按需选用,但不同引擎间 SQL 方言不统一、最佳实践差异大,且查询结果一致性难以保障,导致用户接入使用过程复杂。
- 查询性能受限:尽管平台已经将跨计算引擎兼容的查询自动路由至 StarRocks 进行加速,但核心探索分析场景下,复杂查询的 P95 响应时间仍高达 300 秒,严重制约数据探索效率与业务决策速度。
- 数据处理链路维护难:数据导入导出过程依赖独立的物理机资源,需通过额外的数据 ETL 工具,对大量数据进行多轮加工处理,整体链路维护复杂且存在单点故障风险。
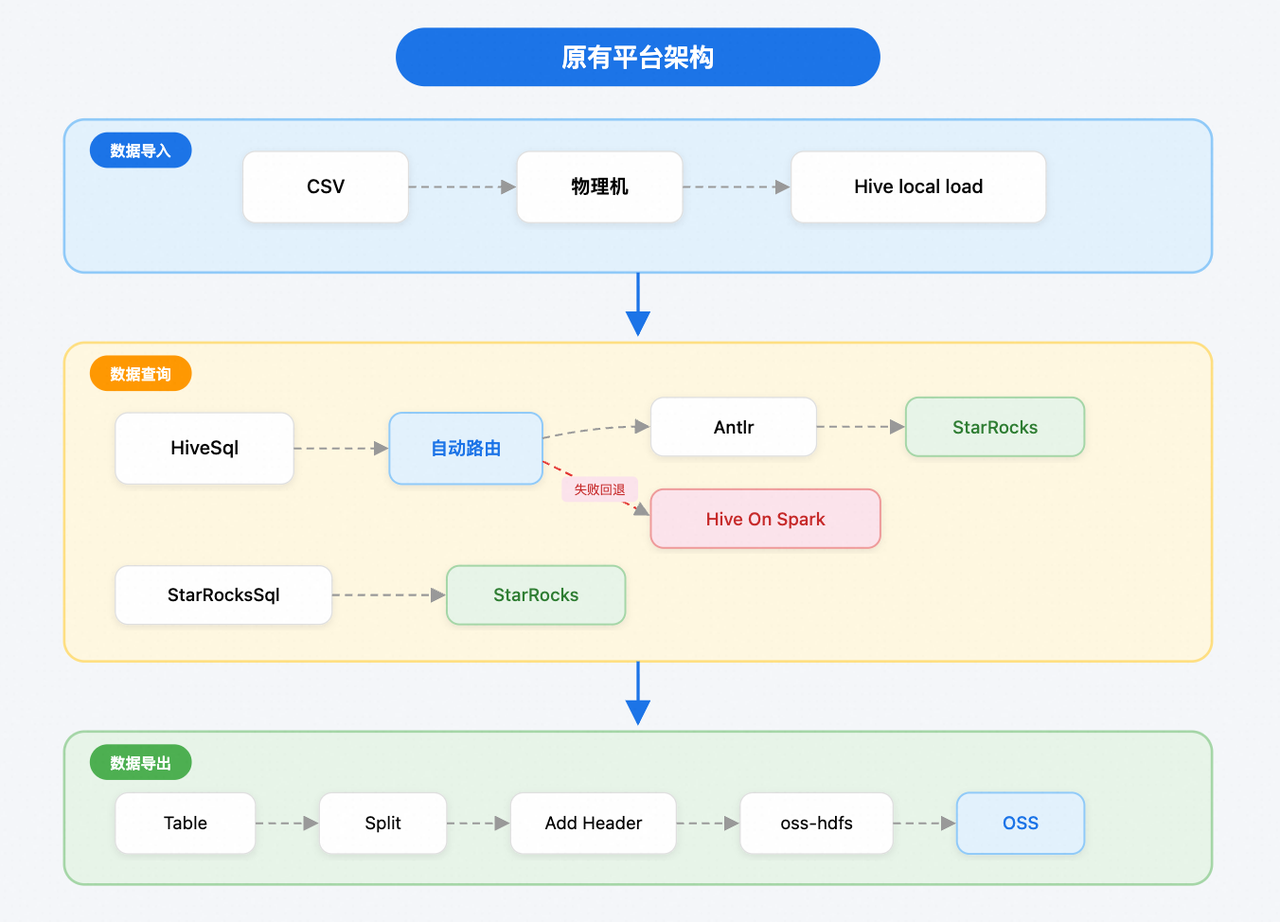
因此,团队目前亟需构建一个能够兼容现有 Hive 生态的统一查询入口(即屏蔽底层多引擎差异,统一以 Hive SQL 作为访问方式),又能提供较 StarRocks 更优的极速查询体验,以支持洋钱罐团队从数据探索到可视化分析的全球一体化探索分析平台演进。
为什么选择阿里云 SelectDB?
2025 年 3 月,在评估多个技术方案后,瓴岳科技团队最终将SelectDB 全新湖仓一体架构确定为核心破局方案。其不仅在查询加速能力上更胜于 StarRocks,更从架构层面实现统一查询入口与数据湖能力的全面释放,提供了面向数据湖的统一分析能力。其核心能力主要体现在:
- Hive 透明加速能力:SelectDB 通过 Hive Catalog 直接对接 Hive 数据湖,无需任何数据迁移;同时高度兼容 Hive SQL 方言,查询结果与原引擎保持一致。使平台在不改变数据存储形态的前提下实现统一查询入口与业务无感切换,从而实现数据不动、查询升级。
- 极致查询性能:基于对 Hive 的高度兼容性,更多业务查询可无缝路由至高性能的 SelectDB 计算引擎。在无需额外数据导入的前提下,相较原有 StarRocks 架构进一步释放查询性能,支撑高频交互式分析场景,平台整体查询效率可实现大幅提升。
- 湖仓一体与存算分离:云原生存算分离架构与湖仓数据互通能力,使数据持续沉淀于 Hive,而计算统一收敛至 SelectDB,形成统一的湖仓分析架构,既能灵活应对业务峰谷,也显著降低数据链路复杂度与运维成本。
基于以上优势,团队正式立项引入 SelectDB。在落地过程中,为确保平滑过渡,我们构建了完整的线上 SQL 回放与结果一致性验证体系,并与 SelectDB 技术团队紧密协作,针对 Hive Catalog 的查询性能与兼容性进行了深度优化。历经两个月开发与两周灰度测试,新平台已在国内和印尼两地全面上线。
阿里云数据库 SelectDB 植根于开源 Apache Doris 的坚实基础,深度融合云随需而用的特性,依托阿里云基础设施,构建起云原生存算分离的全新架构,面向企业海量数据的实时分析需求,提供极速实时、湖仓融合统一、简单易用的云上数仓服务。阿里云 selectdb 的链接:https://www.aliyun.com/product/selectdb?utm_content=g_1000410296
基于 SelectDB 全新探索分析平台
新平台的核心是基于 SelectDB 云服务搭建的存算分离架构。计算层由 SelectDB 替换原有 StarRocks,作为统一的高性能查询引擎,存储层则继续沿用 Hive。通过 SelectDB 的 Hive Catalog 功能,实现了对 Hive 数据的"所见即所得"查询,无需复杂的数据同步。
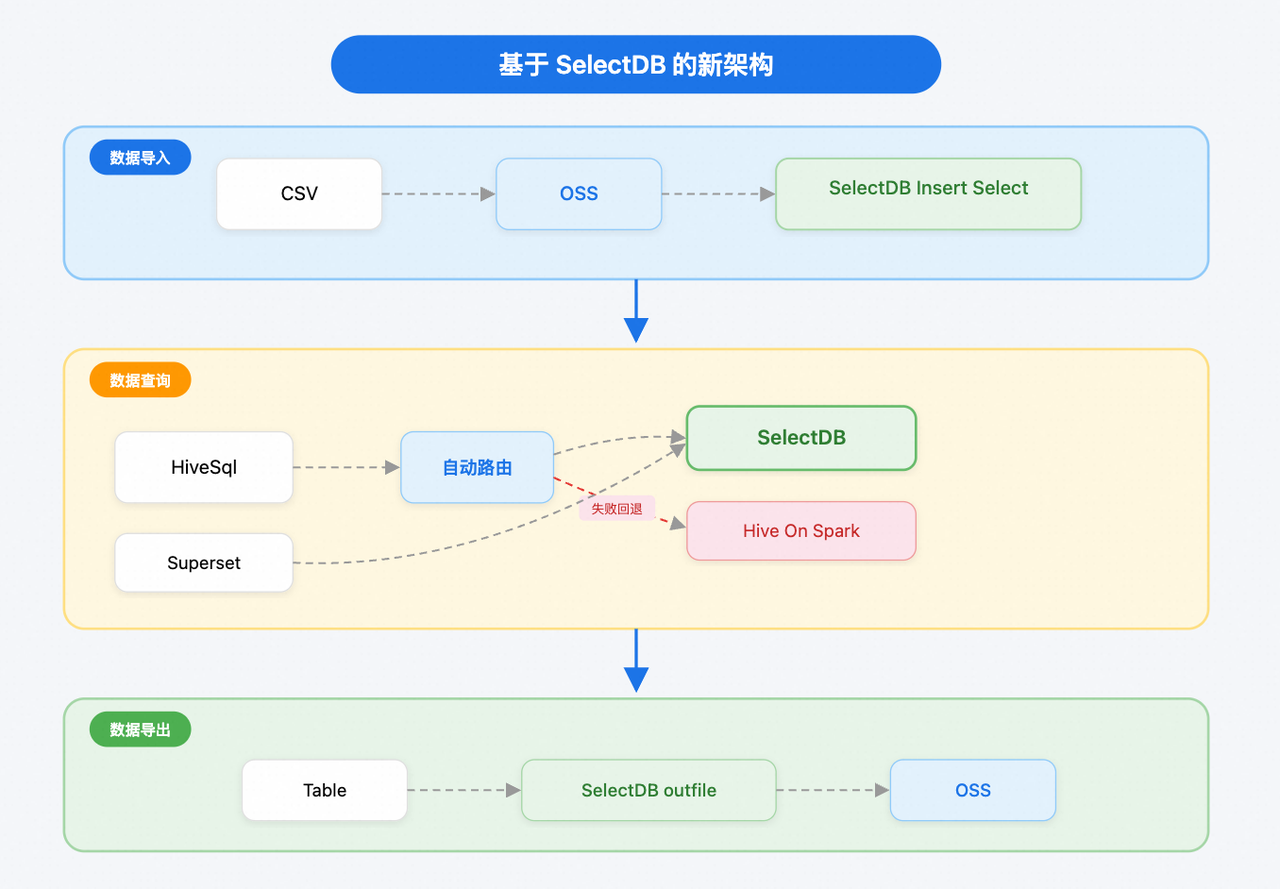
新平台架构清晰覆盖数据全生命周期,具体可分为以下三层:
- 数据导入:优化 CSV 导入流程,从依赖物理机与 Hive 命令的复杂链路,转变为数据直传对象存储(OSS),由 SelectDB 通过
INSERT INTO SELECT方式高效写入 Hive,实现服务与物理机解耦,并支持 K8s 弹性伸缩。 - 数据查询:统一查询语言为 Hive SQL,并构建智能自动路由策略。路由基于函数兼容性判断、集群负载情况及表扫描量(超过 5TB 则保护性回退)三个核心策略,使查询路由比例从 60%提升至 95%,是探索分析整体性能提升的关键。
- 数据导出:利用 SelectDB 的
OUTFILE功能,将原先需要创建临时表、手动拆分文件、补全文件头等多步复杂操作,简化为一步到位的导出指令,导出 P95 时间从 300 秒优化至 20 秒。
总而言之,该架构下无需数据迁移即实现资源的弹性伸缩,且数据只在 Hive 中存储一份,省掉耗时且冗余的数据同步过程,极大简化了数据流转链路。目前,SelectDB 集群计算资源超 1000 Core,缓存数据量超 100 TB,日均查询量超 500 万次,P95 响应时间相比之前的 StarRocks 降低 90%+ 至 20 秒。
该方案提供了一种面向 Hive 数据湖的统一分析平台升级路径,可为具备类似数据架构的企业提供参考借鉴。尤其适用于已构建 Hive 数据湖、存在多引擎协同且平台复杂度较高,并面临数据规模持续增长的数据团队,具备良好的通用性与可复制性。
核心实践及优化经验
01 Hive 方言兼容:实现平滑迁移与高效查询
为确保用户无需改变查询习惯,平滑无感迁移至 SelectDB,我们在 Hive 方言兼容性上实施了一套完整方案。
关键措施
在 Hive 方言兼容性方面,我们采取了多项措施,实现了 98% 的 Hive 方言兼容性,为业务无感迁移奠定了基础。
- 函数回测:建立了包含 100+ 个核心用例的回测框架,可在 5 分钟内完成全量运行。该框架确保了开发流程的质量:任何对 SelectDB 修改都需通过修改前后的回测对比,保证每次迭代都正向演进。
- Hive UDF 验证:针对数十个关键业务 UDF,进行了集中的注册兼容性测试与结果验证。结果表明,绝大多数 UDF 可无缝迁移,仅少数涉及 Bitmap 函数或动态参数等高级特性的 UDF 尚待支持。
- 线上 SQL 回放:建立了自动化流程,每天回放前一天的线上 SQL,对比 SelectDB 与 Hive 的执行结果。任何不一致案例都会与 SelectDB 技术团队协同分析解决,提前化解潜在的数据差异风险。
- 标准数据集性能验证:基于线上数千条 SQL 的统计,构建了包含 20 个标准数据集,通过多轮性能验证。最终结果显示,其中约 12 个数据集的性能超越了 StarRocks,并符合上线标准。
底层实现逻辑
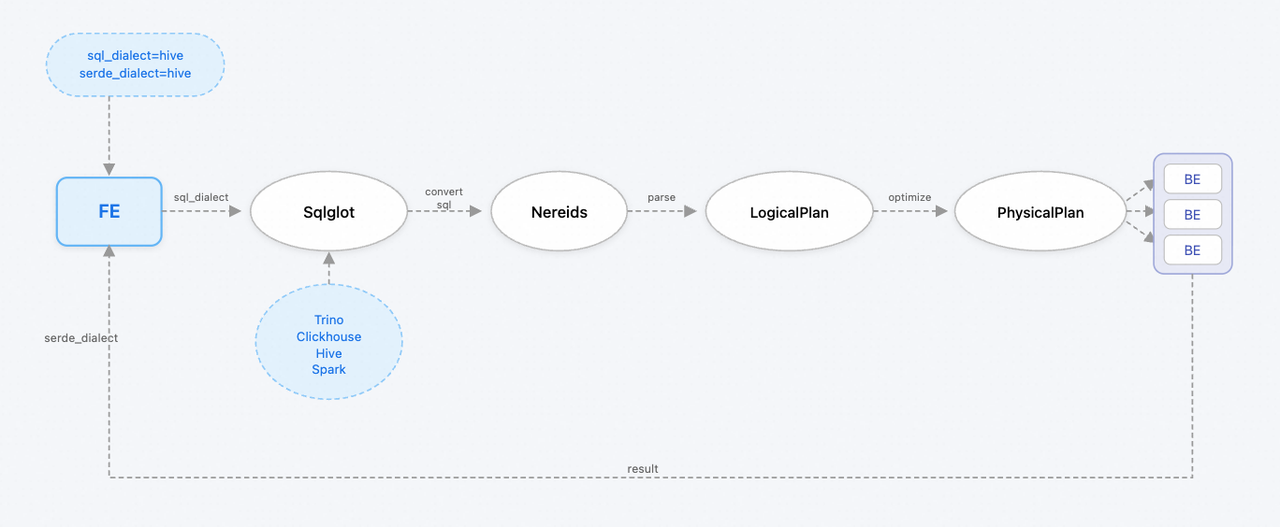
SelectDB 通过sql_dialect与serde_dialect核心参数控制方言转换。流程如下:
- SQL 语句通过
SQL dialect发送到sqloglot(一款开源 SQL 转换器)进行方言改写。 - 改写后的 SQL 会被传送至 SelectDB 的 nereids 进行语法解析。
- 解析器生成逻辑计划,经优化器转化为物理执行计划,分发至各后端节点(BE)执行。
- 最终,
serde_dialect参数控制结果集的展示格式(如小数位数、布尔值形式等),确保输出符合预期。
通过这两个参数,SelectDB 实现了完整的方案转换逻辑,确保了查询的兼容性和执行效率。
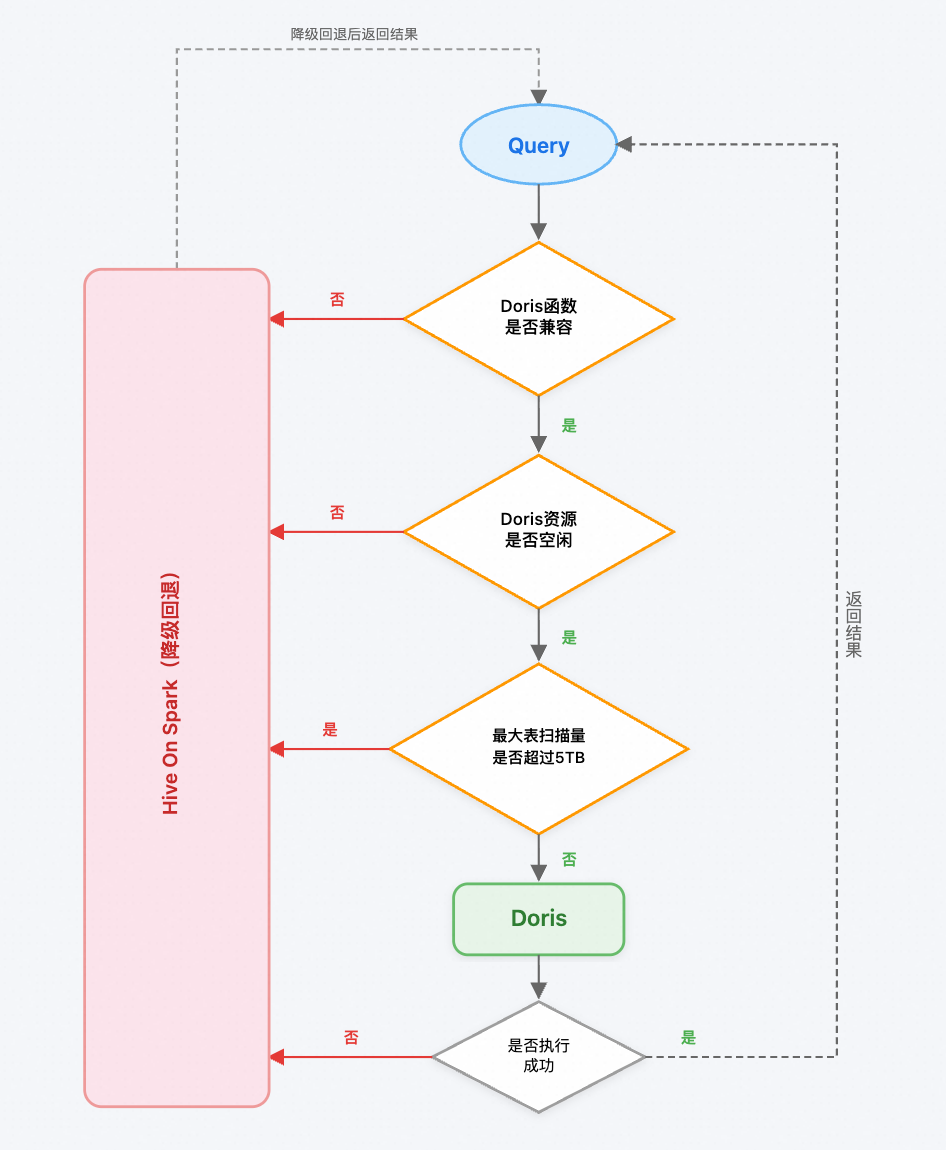
02 智能查询路由:兼顾性能与稳定
-
在统一入口下,我们设计了三层智能路由策略,在提升性能的同时保障集群稳定:
-
兼容性判断:优先判断 SQL 中使用的函数或语法是否被 SelectDB 支持。得益于 98%的兼容率,绝大多数查询可直达 SelectDB。不兼容时将进行回退至 Hive on Spark。
-
资源监控:实时感知 SelectDB 集群负载。在集群繁忙时,将查询自动回退,避免过载。
-
过载保护:当单表扫描量预估超过 5TB 时,查询将被回退,以保障 SelectDB 集群资源稳定运行。
这些回退策略将在查询日志中明确记录,用户可据此判断当前的集群资源状态或识别不兼容的函数,并进行相应的修改。
通过以上策略的实施,自动路由的上线使我们的路由比例从原先的 60% 提升至 95%。
03 Hive 数据加速,查询性能数量级提升
在 SelectDB on Hive 架构下,我们通过多层缓存机制实现了查询性能的数量级提升,核心场景查询从分钟级缩短至秒级。
缓存机制与配置
目前,集群缓存总容量超过 100TB,命中率长期保持在 90% 以上,这意味着大多数场景都能有效利用缓存资源。而关键配置在于 Hive Catalog 的精细化缓存控制:通过设置不同的 TTL,我们平衡了数据新鲜度与缓存效率。用户也可通过REFRESH命令主动刷新缓存。
SQL
CREATE CATALOG hive_catalog PROPERTIES (
"type" = "hms",
"schema.cache.ttl-second" = "60",
"partition.cache.ttl-second" = "0",
"hive.metastore.uris" = "thrift://127.0.0.1:9083",
"get_schema_from_table" = "true",
"file.meta.cache.ttl-second" = "0"
);以 LDFI 数据为例,我们首先将 Parquet 文件拆分为多个块(Block)。查询时,系统首先在本地磁盘的 LRU 缓存中寻找这些数据块。若命中,则直接返回;若未命中,则从 HDFS 读取,并在查询完成后异步缓存至本地 LRU,供后续使用。
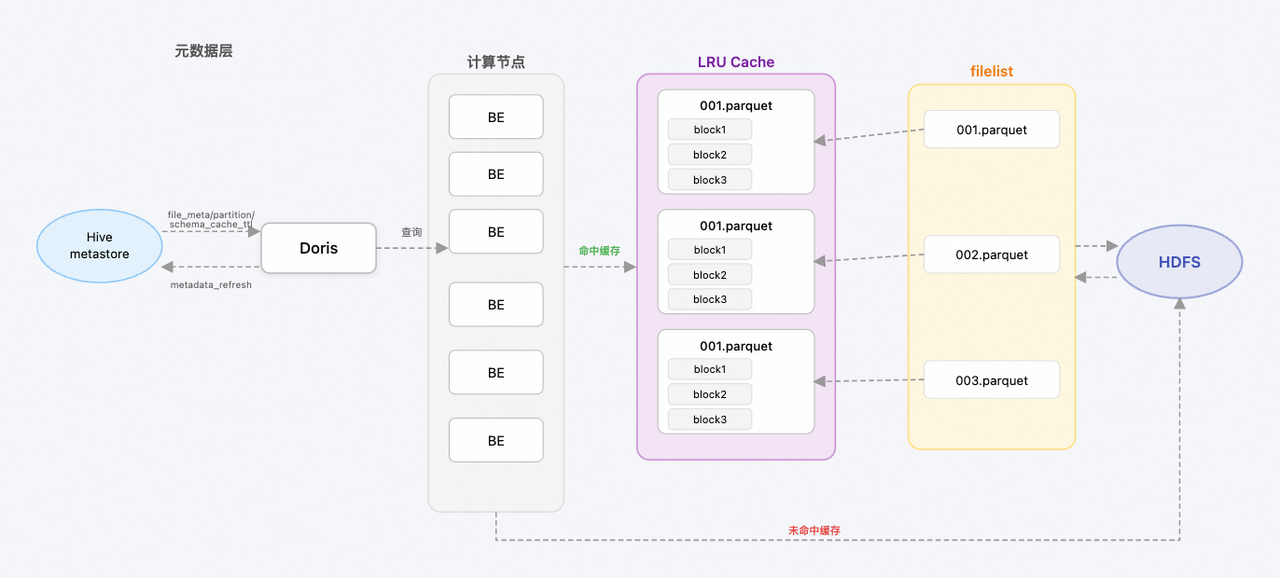
04 全链路优化提速
除此之外,SelectDB 的引入使文件上传、数据导出、DQC 等方面的性能都得到巨大的性能提升,具体来看:
- 在数据导入方面:SelectDB 通过
INSERT INTO hive_table SELECT * FROM OSS_FILE命令,可将 CSV 经 OSS 直接高效写入 Hive 表,导入 P95 时间从 200 秒优化至 30 秒。 - 在数据导出方面,利用 SelectDB 原生的
OUTFILE功能,将此前繁琐的导出流程(涉及创建临时表、手动拆分文件、补全表头等)简化为一步指令,使导出P95 时间从 300 秒降至 20 秒。 - 在数据质量检查上(DQC)上,SelectDB on Hive 通过任务分组与并发控制,高效调度大量校验任务,使 DQC 任务执行 P95 时间从原来的 2600 秒(约 43 分钟)骤降至 25 秒,提升超百倍。同时,为避免超大校验任务挤占集群资源,设计了降级方案,可自动切换至 Spark 引擎。
结束语
通过引入阿里云 SelectDB 构建新一代探索分析平台,不仅实现了性能的显著提升,更完成了从"多引擎协同 + 查询加速"到"湖仓一体 + 统一分析平台"的关键演进。成功构建了一个兼容现有生态、查询极速、体验流畅的全球一体化探索分析平台。未来,瓴岳科技将会进一步探索 SelectDB 的能力:
- 应用异步物化视图:
- 面向报表与看板场景,提供开箱即用的数据集加速能力,极大提升查询性能。
- 依托 SelectDB 内置智能调度引擎,实现增量数据的自动化、定时化更新,保障数据时效性。
- 支持自动查询路由,用户查询无需改写即可命中最优物化视图,实现透明加速。
- 推行 Serverless:
- 通过 Serverless 产品形态,实时应对业务流量潮汐,实现资源秒级按需分配,显著降低成本。
- 面向高优先级批处理任务,通过自动资源扩容,保障大数据量作业稳定高效完成,提升平台 SLA。
- 探索 AI 应用:
- 在 ChatBI 场景探索向量混合检索,增强自然语言交互的数据探索能力与智能水平。
- 在 Data Agent 领域集成 SelectDB MCP,打造基于统一数据服务的智能体生态,赋能自动化分析与决策。