gpt-4o-mini⼤模型接⼊
ChatGPT是⼀个基于OPenAI的⼤语⾔模型(如GPT-3、GPT-4)构建的产品或服务,⼀个可以直接使⽤的聊天机器⼈应⽤,允许⽤⼾与语⾔模型进⾏交互,⽣成⽂本。
gpt-4o-mini是⼀个具体的⼤语⾔模型,是OpenAI开发的GPT系列模型中的⼀个变种,具有特定的架构和训练数据,⽤于⽣成⽂本。
gpt-4o-mini的接⼊与deepseek类似,需要调⽤官⽅提供的API,以及了解接⼝的请求和响应格式。
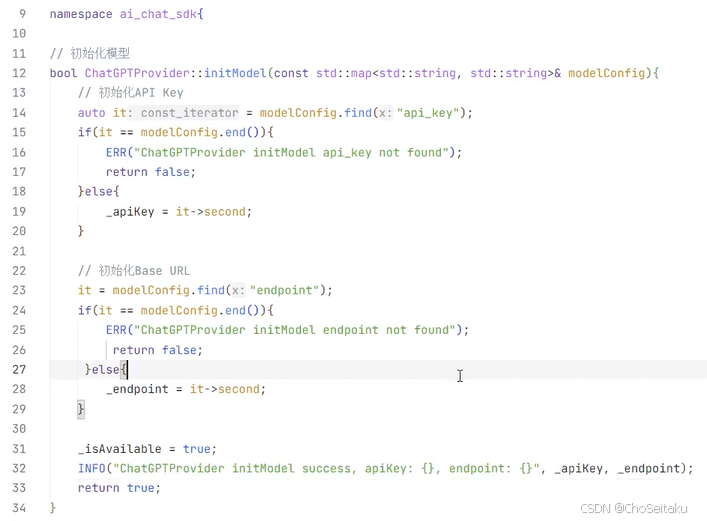
⼤模型初始化
主要设置api key以及OpenAI提供的应⽤编程接⼝的根端点(所有特定地址的起点和前缀,就像是某栋楼的地址本⾝,URL是根端点+路径+查询参数)。api key需要⾃⼰到OpenAI的官⽹申请,OpenAI提供的API根端点是:https://api.openai.com
ChatGPTProvider.h
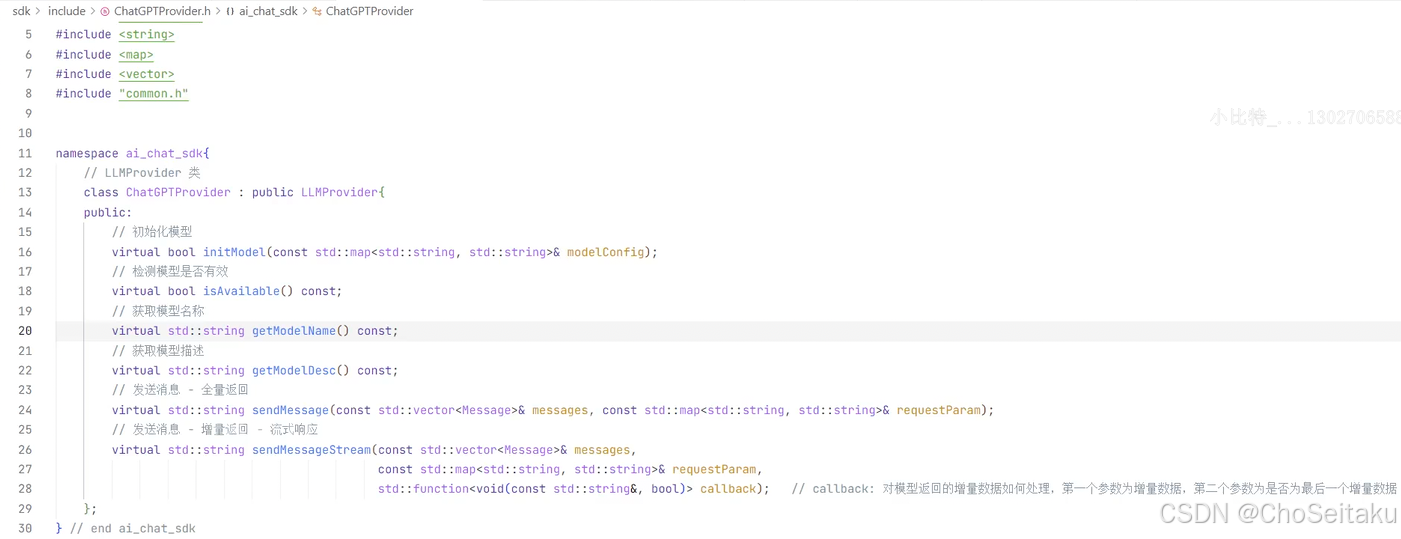
ChatGPTProvider.cpp


ChatGPT提供API
Chat Completion的官⽅参数⽂档:https://platform.openai.com/docs/api-reference/chat/create
| 参数名称 | 参数类型 | 必填 | 参数说明 |
|---|---|---|---|
| model | string | √ | 模型名称,比如:gpt-4o-mini |
| messages | array | √ | 对话历史,每条消息包含一个 role 和 content 字段 |
| temperature | number | × | 浮点数,采样温度,介于0和 2 之间,较高的值 (如 0.8) 会使输出更随机,较低的值 (如 0.2) 会使输出更集中和确定。默认值为 1 |
| top_p | number | × | 核心采样替代方法,模型会考虑概率质量最高的 top_p 的标记记过。例如:0.1 表示只考虑最高的 10% 的标记。与 temperature 二选一,避免同时设置,默认值为 1 |
| stream | boolean | × | 如果设置,将发送部分消息增量,以流式返回,默认值为 flase,即未开启 |
| stop | String or array | × | 设置停止词,遇到这些词停止生产,最多支持四个停止词,默认值 none |
| max_tokens | integer | × | 整数,⽣成内容的最⼤token数。该值OPenAI已经废弃,但是被⼤多数模型兼容 |
| max_completion_tokens | integer | × | 完成生成的 tokens 数上限,包括可见输出标记和推理标记 |
| presence_penalty | number | × | 浮点数,介于 - 2.0 和 2.0 之间。正直减少重复,负值增加重复。默认值为 0。 |
| frequency_penalty | number | × | 浮点数,数字介于 - 2.0 和 2.0 之间。正值会根据标记在文本中的现有频率对标记进行惩罚,减少模型重复相同内容的可能性。默认值为 0。 |
| n | integer | × | 生成多少回复结果。默认值为 1 |
| seed | integer | × | 如果指定,系统将尽力确定性地采样,使得具有相同 seed 和参数的重复请求应返回相同的结果 |
| tools | array | × | 模型可能调用的工具列表。目前,仅支持函数作为工具。使用此参数提供模型可以为其生成 JSON 输入的函数列表 |
| Role |
- system:给系统⼀个⻆⾊,⽐如:"你是⼀个具有⼗年C++后端开发经验的资深⼯程师"
- user:⽤⼾消息,即⽤⼾向⼤模型的提问
- assistant:助⼿消息,即⼤模型回复
- tool:⼯具调⽤,如果要⼤模型调⽤外部⼯具时使⽤,即实现Function Calling
Base url:https://api.openai.com
模型名称:gpt-4o-mini
gpt-4o-mini模型的聊天补全接⼝设置如下:
请求URL POST /v1/chat/completions
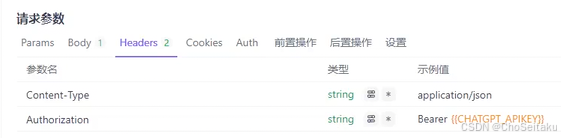
请求头参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer" + _api_key |
请求体参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| model | string | 模型名称 |
| message | array | 历史对话,内部为每个对话的 object,包含 role 和 content 两个字段 |
| temperature | string | 采样温度 |
| max_tokens | integer | 最大 tokens 数 |
返回响应 200 ok
API测试

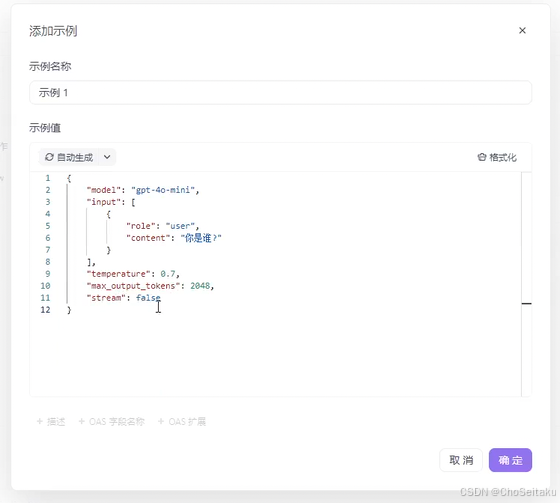
解析:
检测responseJson是否包含output字段
检测responseJson"output"是否为json数组
检测responseJson"output"是否为空
如果上述条件都成立
Json::Vaule output = responseJson["output"][0]
检测output中是否包含content字段
检测output"content"是否为数组
检测output"content"是否为空
检测output["content"][0]是否包含text字段
如果上述条件都成立
string reply = output["content"][0]["text"].asString();
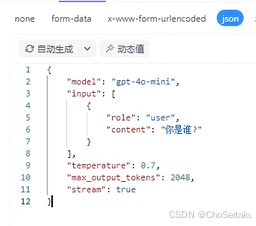

Responses API
对于新创建的项⽬,官⽅更推荐优先使⽤Responses API,以使⽤OpenAI平台的最新功
能。
Chat Completions API,是传统的聊天接⼝,简单好⽤,但只能处理⽂本。
Responses API:以事件驱动,⽀持多模态和复杂交互,更适合做应⽤级AI。
以下是两种不同类型API的对⽐:
| 对比维度 | Chat Completions API | Responses API |
|---|---|---|
| 定位 | 主要用于对话生成 (聊天机器人、客服问答等) | 用于多模态助手 (文本、语音、图像、函数调用等多种交互) |
| 输入 | 聊天消息数组(messages:[{role, content}]) |
统一的 input(可包含文本、音频、图像等),更灵活 |
| 输出 | 一段完整的文本回复(可流式,但只有文字) | 通过事件流(semantic events)输出:text.delta、audio.delta、completed、tool_call 等 |
| 流式能力 | 只支持文本流式(逐字符 / 逐 token 返回) | 支持多模态流式(文本、语音、工具调用、结构化消息),更细粒度 |
| 多模态支持 | 主要是文本(部分模型可输入图像) | 原生支持文本、音频、图像等,能边生成文字边输出语音 |
| 可控性 | 一次请求 = 一次完整回复,过程不可中断 | 可在生成中动态打断、分支,或让模型调用工具函数 |
| 典型场景 | 聊天机器人、FAQ、简单对话系统 | AI 助理、语音对话机器人、智能办公助手、多模态应用 |
| 生活示例 | 学生在比特答疑工具上提问: 学生:我的 oj 整题你通过部分用例,为什么? 老师:我先看下题目... 我在看下你的代码... 你代码中比较条件写错了... 应该这么写... 你先修改下试试... | 你参加一个会议,智能助理会不断抛出 "事件": ・"正在讲 PPT 第 3 页了"(output_text) ・"这里有个视频片段要放"(output_audio) ・"我需要查一下资料"(tool_call) ・"会议结束"(completed) |
| 因此现在官⽅是⽐较推荐在新项⽬中使⽤Responses API。 |
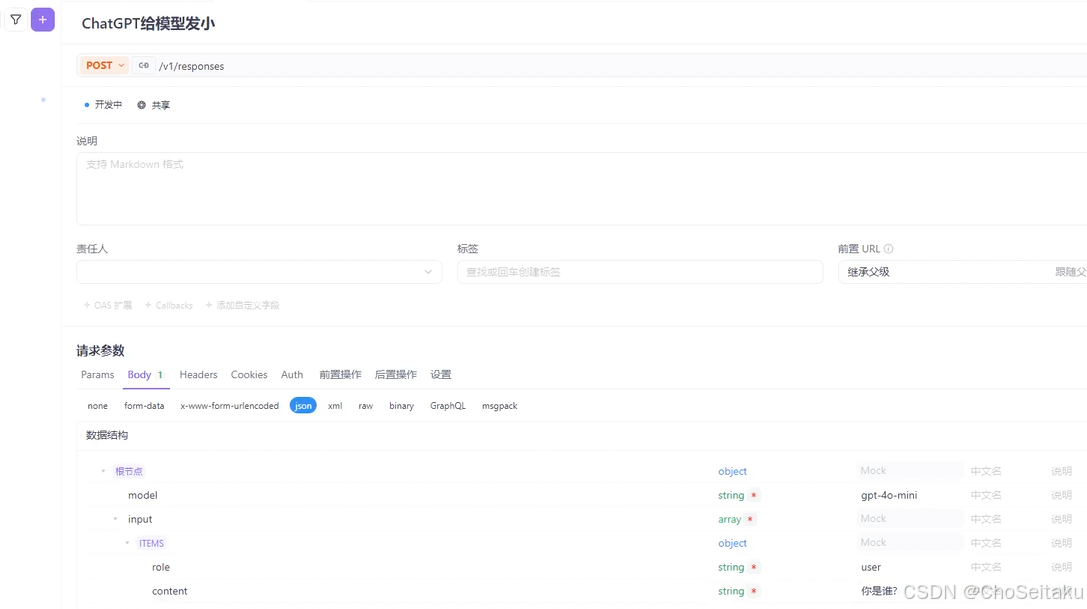
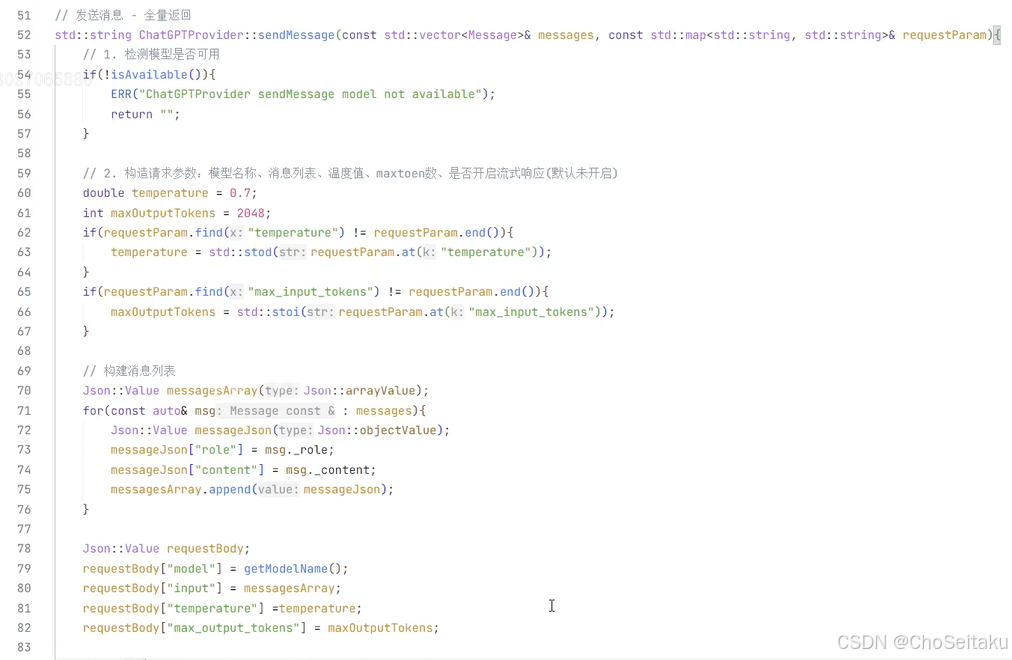
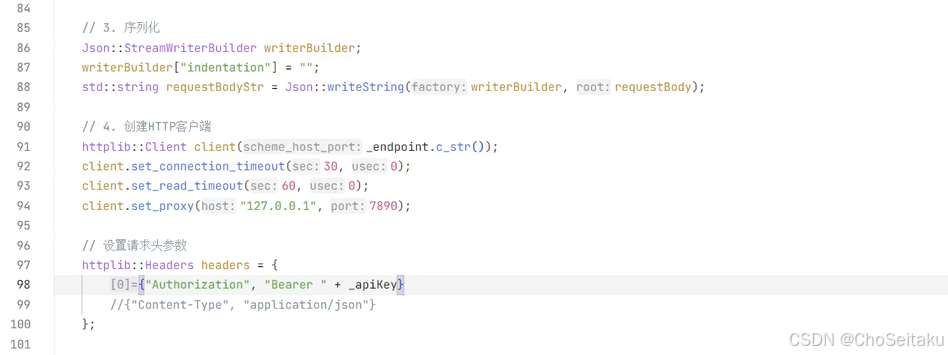
发送消息-全量消息返回
post /v1/responses
主要请求参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| model | string | 模型名称,即 gpt-4o-mini |
| input | array | 历史对话,内部为每个对话的 object,包含 role 和 content 两个字段 相当于 Chat Completions API 中的 message 数组 |
| temperature | string | 采样温度 |
| max_output_tokens | integer | 最大 tokens 数。相当于 Chat Completions API 中的 max_tokens |
| 注意: /v1/responses 并不会⾃动保存上下⽂,需要程序员在input⾥维护会话历史。 |
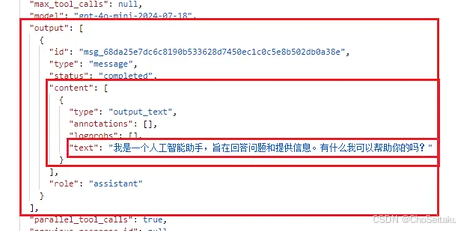
chatGPT的响应格式:
c++
{
"id": "resp_67ccd2bed1ec8190b14f964abc0542670bb6a6b452d3795b",
"object": "response",
"created_at": 1741476542,
"status": "completed",
"error": null,
"incomplete_details": null,
"instructions": null,
"max_output_tokens": null,
"model": "gpt-4.1-2025-04-14",
"output": [
{
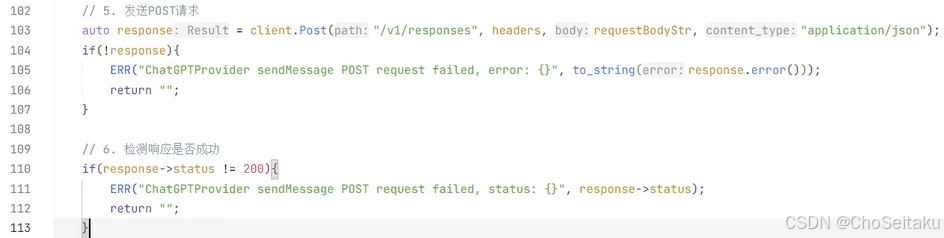
"type": "message",
"id": "msg_67ccd2bf17f0819081ff3bb2cf6508e60bb6a6b452d3795b",
"status": "completed",
"role": "assistant",
"content": [
{
"type": "output_text",
"text": "In a peaceful grove beneath a silver moon, a
unicorn named Lumina discovered a hidden pool that reflected the stars. As she
dipped her horn into the water, the pool began to shimmer, revealing a pathway
to a magical realm of endless night skies. Filled with wonder, Lumina
whispered a wish for all who dream to find their own hidden magic, and as she
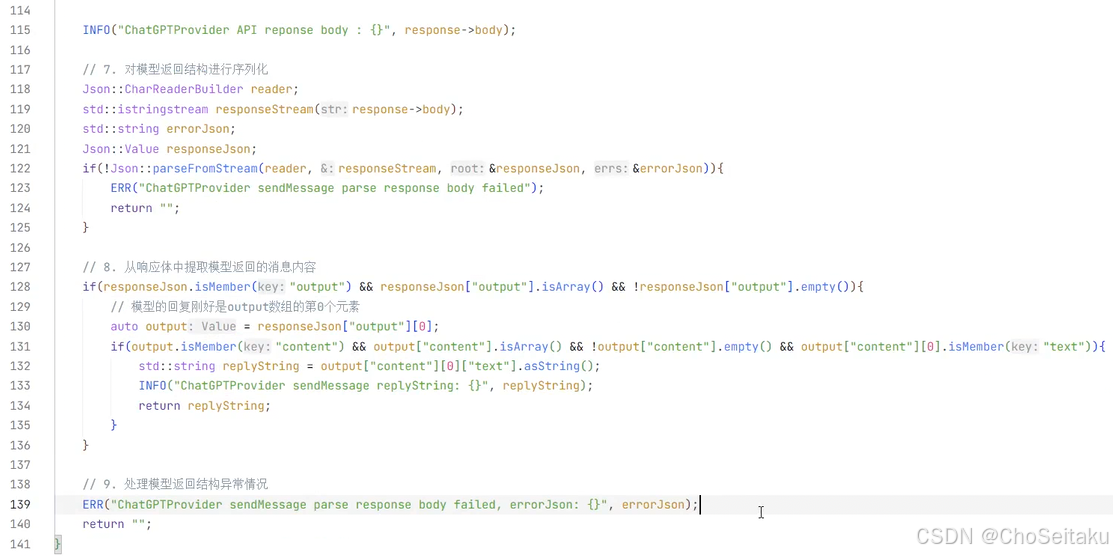
glanced back, her hoofprints sparkled like stardust.",
"annotations": []
}
]
}
],
"parallel_tool_calls": true,
"previous_response_id": null,
"reasoning": {
"effort": null,
"summary": null
},
"store": true,
"temperature": 1.0,
"text": {
"format": {
"type": "text"
}
},
"tool_choice": "auto",
"tools": [],
"top_p": 1.0,
"truncation": "disabled",
"usage": {
"input_tokens": 36,
"input_tokens_details": {
"cached_tokens": 0
},
"output_tokens": 87,
"output_tokens_details": {
"reasoning_tokens": 0
},
"total_tokens": 123
},
"user": null,
"metadata": {}
}
发送消息-全量返回测试
testLLM.cpp

CMakeLists.txt


发送消息-流式返回
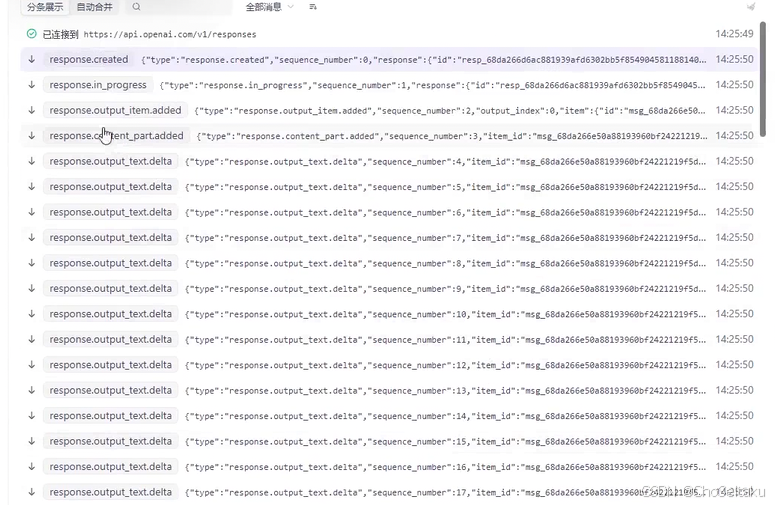
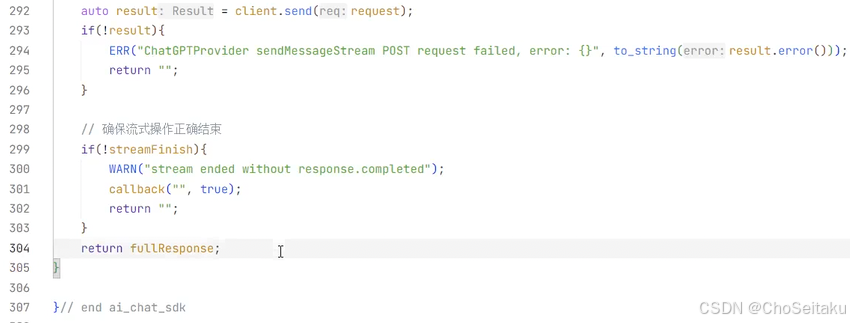
在发送 /v1/responses 如果在请求参数中带上 stream=true 时,表⽰开启流式响应。OpenAI
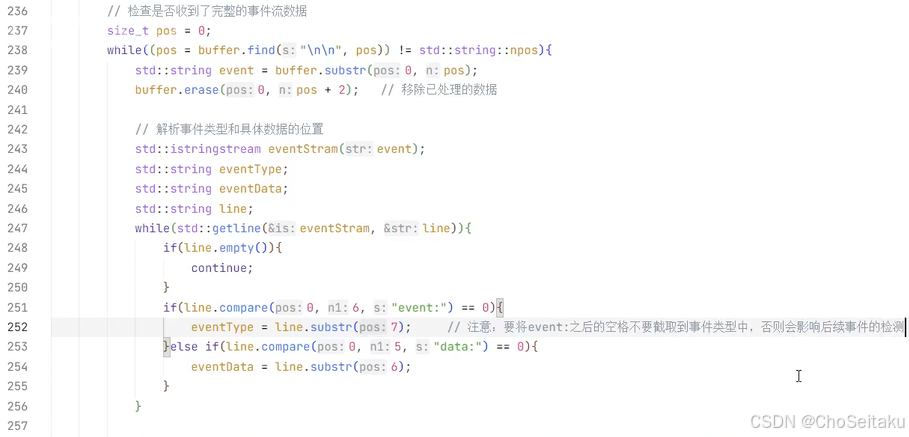
预定义了⼀些事件类型,每个响应都有特定的事件类型:

ChatGPT 的 responses API 的流式响应是基于事件机制
- response.create:表⽰响应对象创建好了
- response.in_progress:表⽰模型开始⼯作
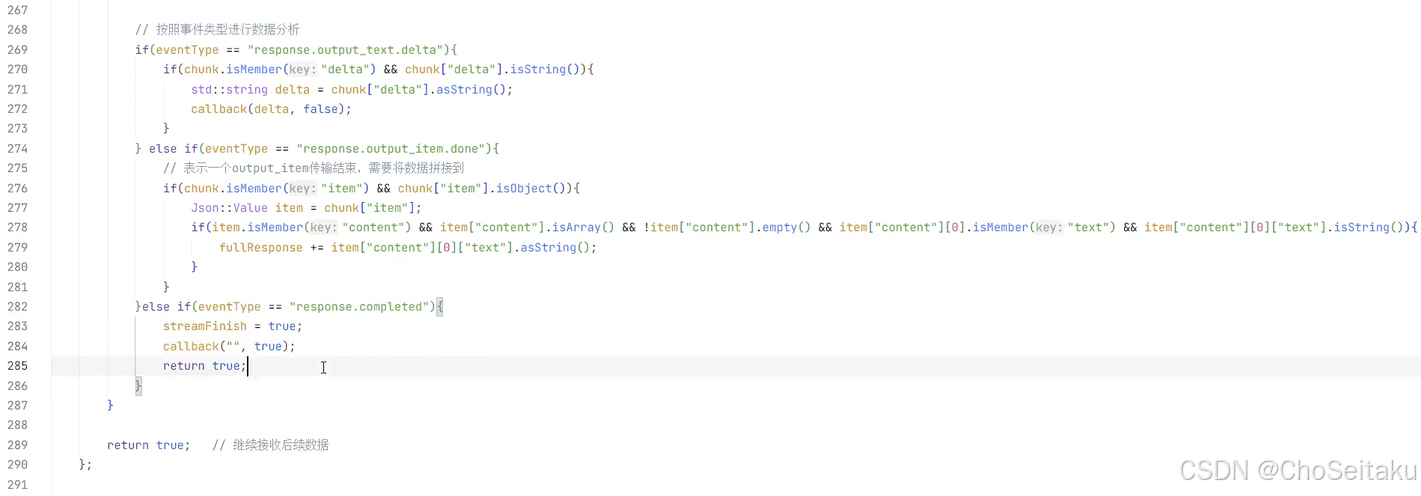
- response.output_text.delta:表⽰⼀段段⽂字实时流出
- response.output_completed:表⽰该输出块结束
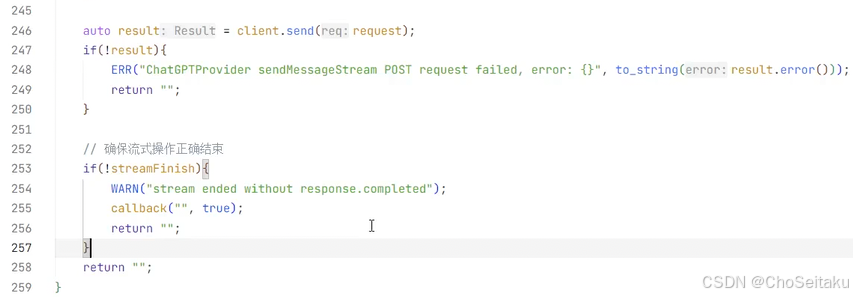
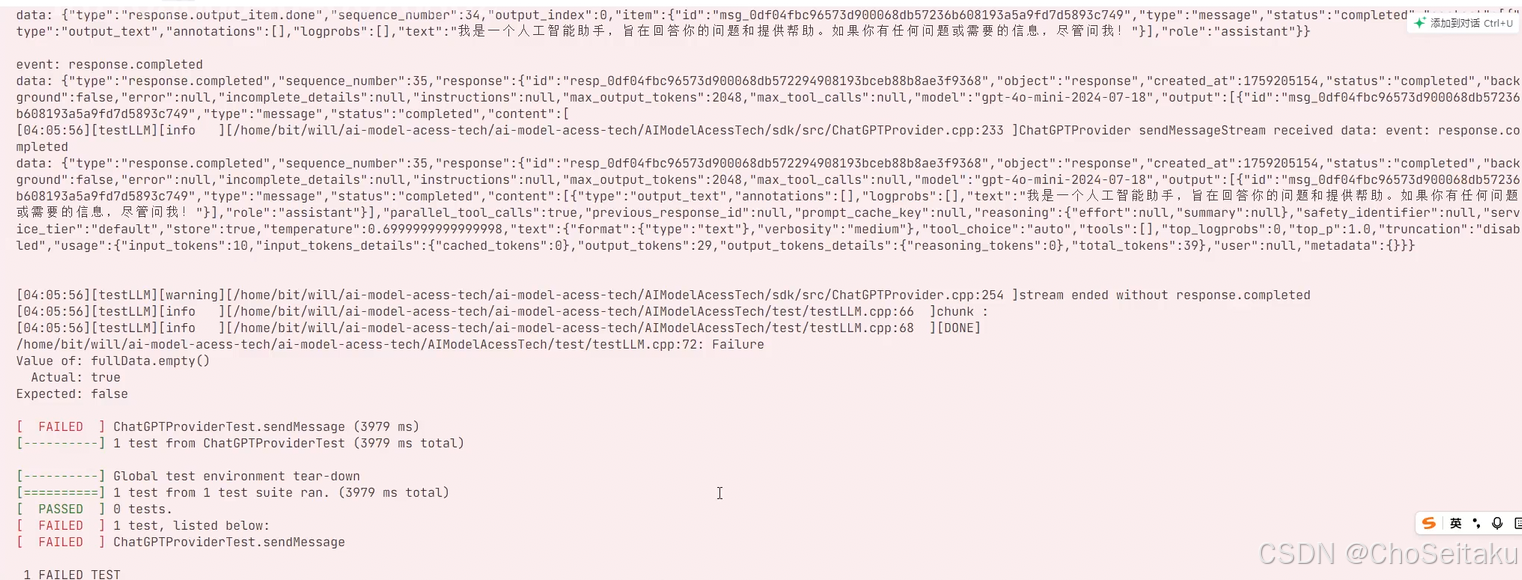
- response.completed:表⽰整个响应结束。
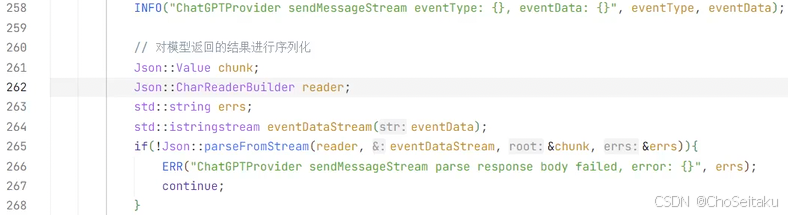
response.output_text.delta: 这个事件内容是模型返回的增量数据
response.output_item.done: 表示一个输出单元结束,一个 output item 中,在流式过程中可能会包含response.output_text.delta,包含多个增量数据的内容,当该 output item 结束的时候,会触发 response.output_item.done
response.completed: 表示整个响应已经完全生成结束,不仅仅是某个输出单元结束,所有的输出单元已经完全生成,流式过程正式结束。即在收完最后一个 response.output_item.done,才会收到 response.completed
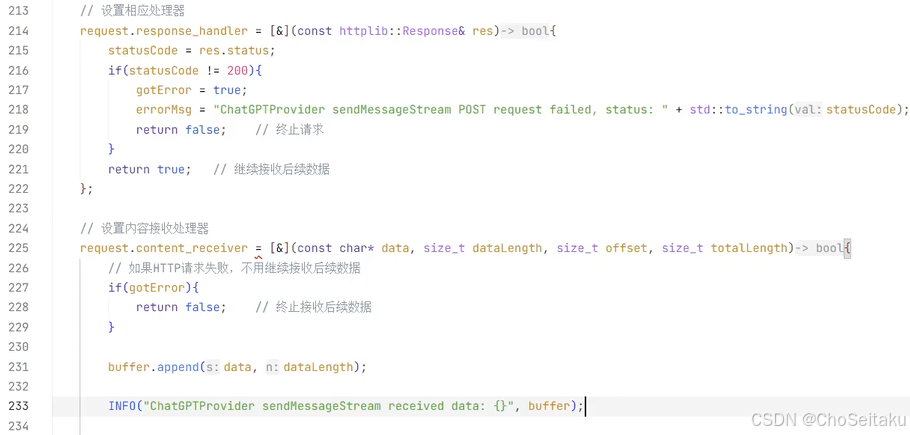
ChatGPTProvider.cpp




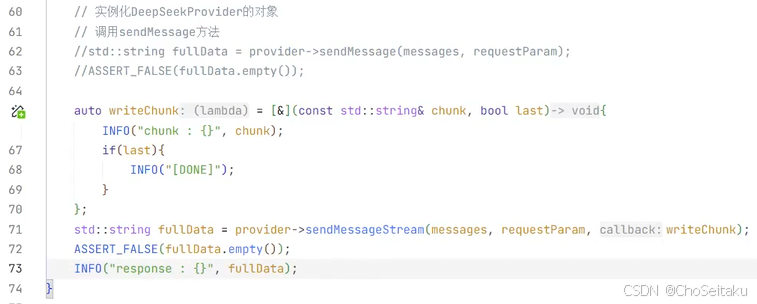
发送消息-流式返回测试
testLLM.cpp

Genimi接⼊封装
Gemini初始化
设置模型api key、base URL、模型简介等。
GeminiProvider.h

GeminiProvider.cpp


Gemini的API介绍
Gemini模型也兼容OPenAI,即可以采⽤类似OpenAI的格式访问gemini模型。
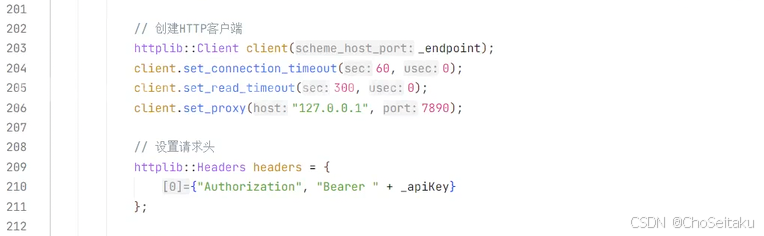
Base URL:https://generativelanguage.googleapis.com
gpt-4o-mini模型的聊天补全接⼝设置如下:
请求URL POST /v1beta/openai/chat/completions
请求头参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| Content-Type | string | application/json |
| Authorization | string | "Bearer " + _api_key |
| 请求体参数: |
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| model | string | 模型名称 |
| messages | array | 历史对话,内部为每个对话的 object,包含 role 和 content 两个字段 |
| temperature | string | 采样温度 |
| max_tokens | integer | 最大 tokens 数 |
| 响应参数: |
c++
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "我是⼀个⼤型语⾔模型,由 Google 训练。\n",
"role": "assistant"
}
}
],
"created": 1754897666,
"id": "Ap2ZaPGBEMS1nvgPu6DPwAg",
"model": "gemini-2.0-flash",
"object": "chat.completion",
"usage": {
"completion_tokens": 12,
"prompt_tokens": 3,
"total_tokens": 15
}
}与DeepSeek类似,Gemini也不会保存历史会话记录,因此在给Gemini发送请求时,需要提供之前聊天的上下⽂记录,Gemini才会根据上下⽂记录提供对应的响应。
Gemini的API测试
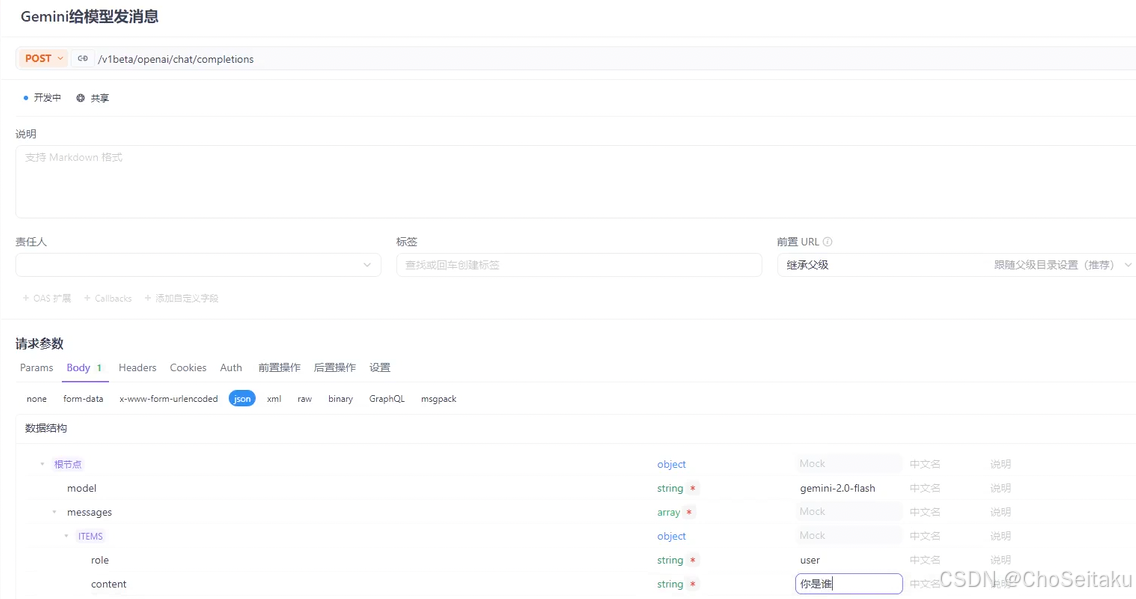


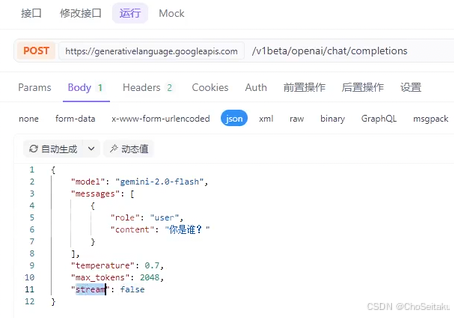
发送消息-全量返回
接⼊gemini系列模型时,google提供了专⻔的api接⼝,同时也兼容OpenAI api。为了减少复杂的实现快速接⼊,本⽂使⽤OpenAI兼容的API快速接⼊。
URL: /v1beta/openai/chat/completions
请求参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| model | string | 模型名称 |
| messages | array | 历史对话,内部为每个对话的 object,包含 role 和 content 两个字段 |
| temperature | string | 采样温度 |
| max_completion_tokens | integer | 最大 tokens 数 |
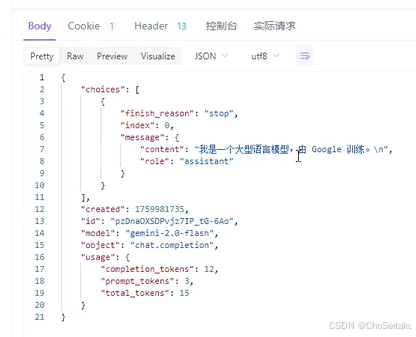
响应格式:
c++
{
"choices":[
{
"finish_reason":"stop",
"index":0,
"message":{
"content":"你好!很⾼兴为你服务。有什么我可以帮助你的吗\n",
"role":"assistant"
}
}
],
"created":1756716818,
"id":"El-1aPv6Etau1MkPr-6ymQg",
"model":"gemini-2.0-flash",
"object":"chat.completion",
"usage":{
"completion_tokens":14,
"prompt_tokens":1,
"total_tokens":15
}
}GeminiProvider.cpp
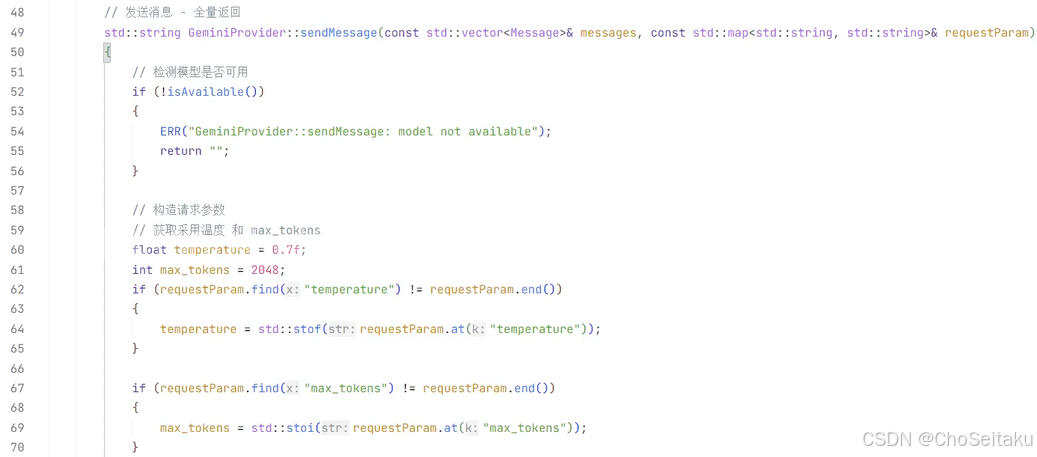
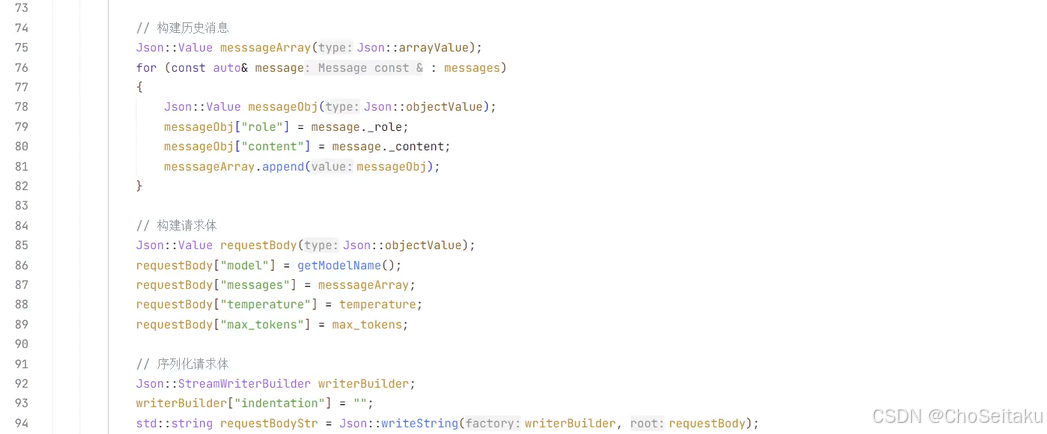
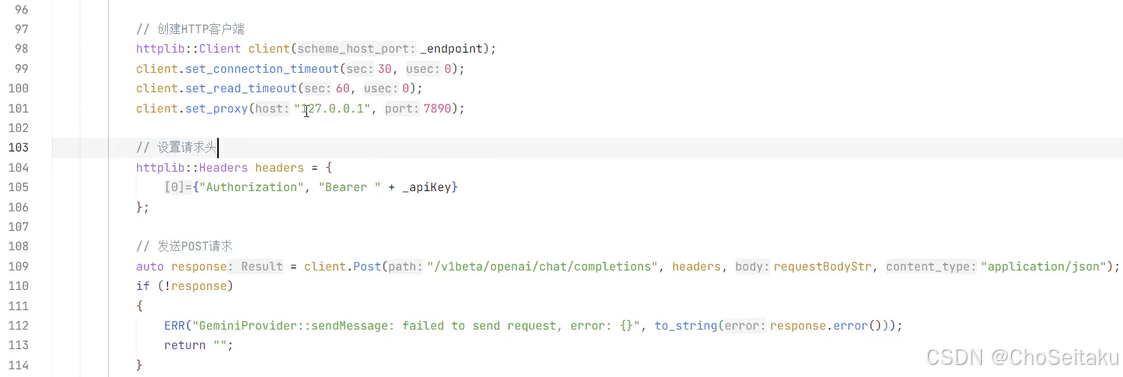

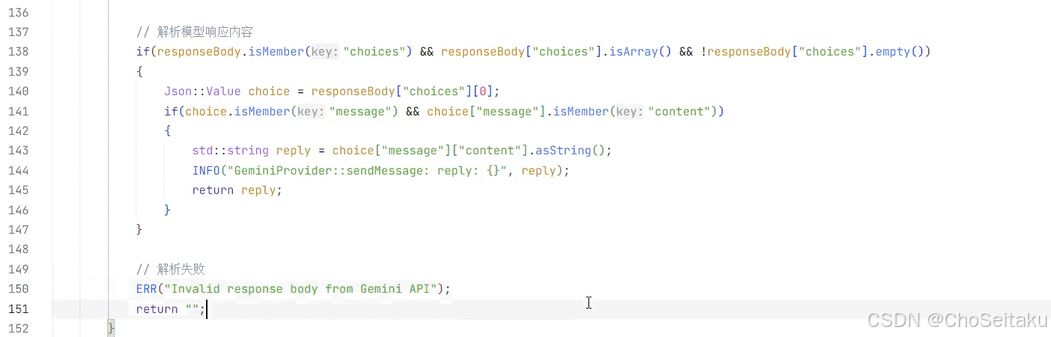
发送消息-全量返回测试
testLLM.cpp

CMakeLists.txt

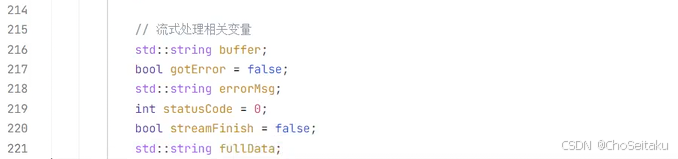
发送消息-流式返回
URL: /v1beta/openai/chat/completions
请求参数:
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
| model | string | 模型名称 |
| messages | array | 历史对话,内部为每个对话的 object,包含 role 和 content 两个字段 |
| temperature | string | 采样温度 |
| max_tokens | integer | 最大 tokens 数 |
| stream | boolean | 是否开启流式响应,默认为 false |
| 响应格式: |
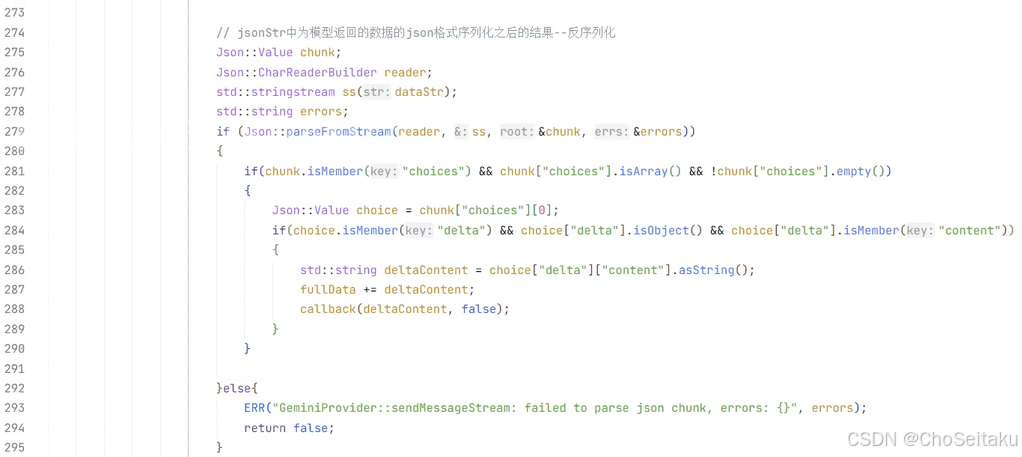
c++
data: {
"choices":[
{
"delta":{
"content":" 通常",
"role":"assistant"
},
"index":0
}
],
"created":1756720923,
"id":"Gm-1aKjSM-ag7dcP77rtoAs",
"model":"gemini-2.0-flash",
"object":"chat.completion.chunk"
} .
..
data: {
"choices":[
{
"delta":{
"content":"你在研究股票市场吗? (提⽰: Shanghai Stock Exchange)\n\n⼀旦你提供了更多信息,我就能给出更精确的解释\n",
"role":"assistant"
},
"finish_reason":"stop",
"index":0
}
],
"id": "Gm-1aKjSM-ag7dcP77rtoAs",
"model": "gemini-2.0-flash",
"object": "chat.completion.chunk"
}
data: [DONE]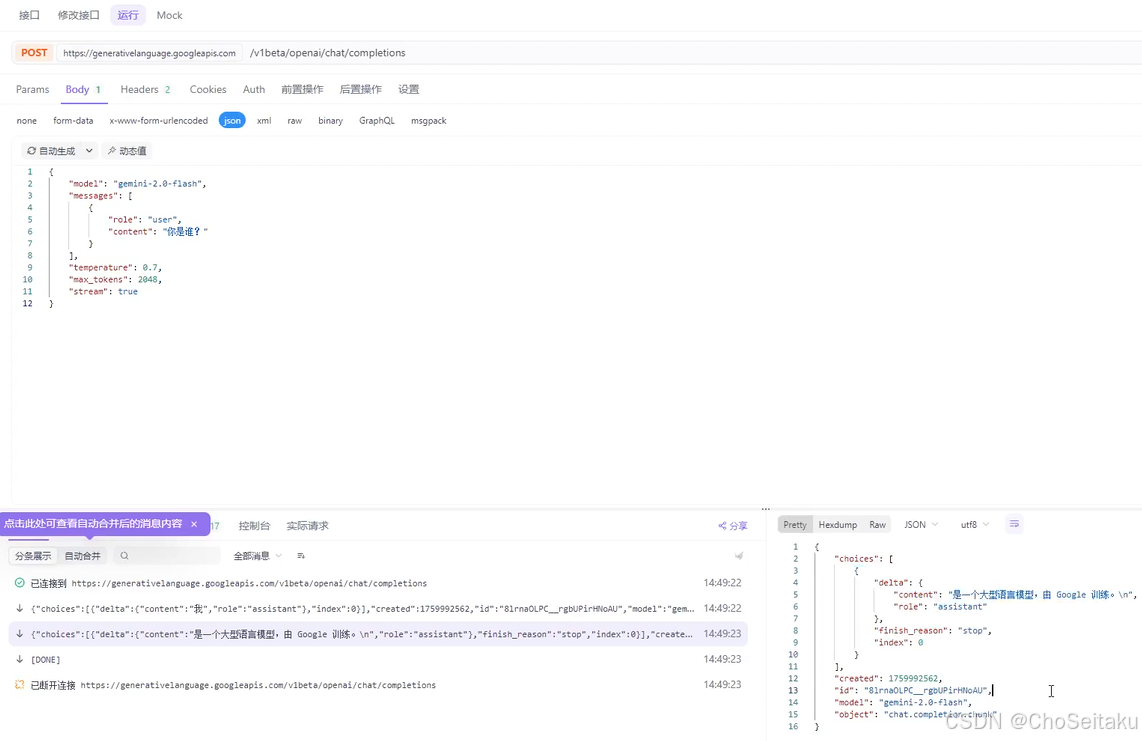
GeminiProvider.cpp






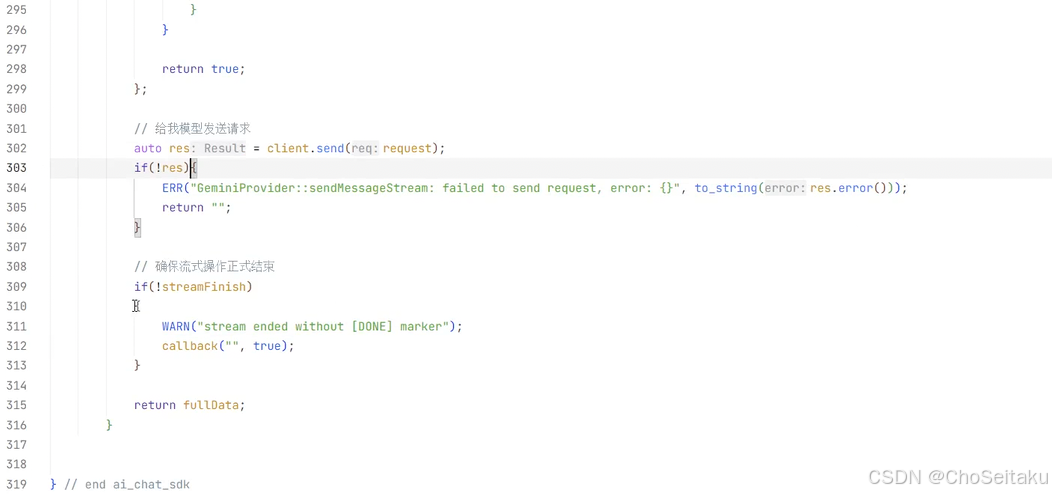
发送消息-流式返回测试
testLLM.cpp

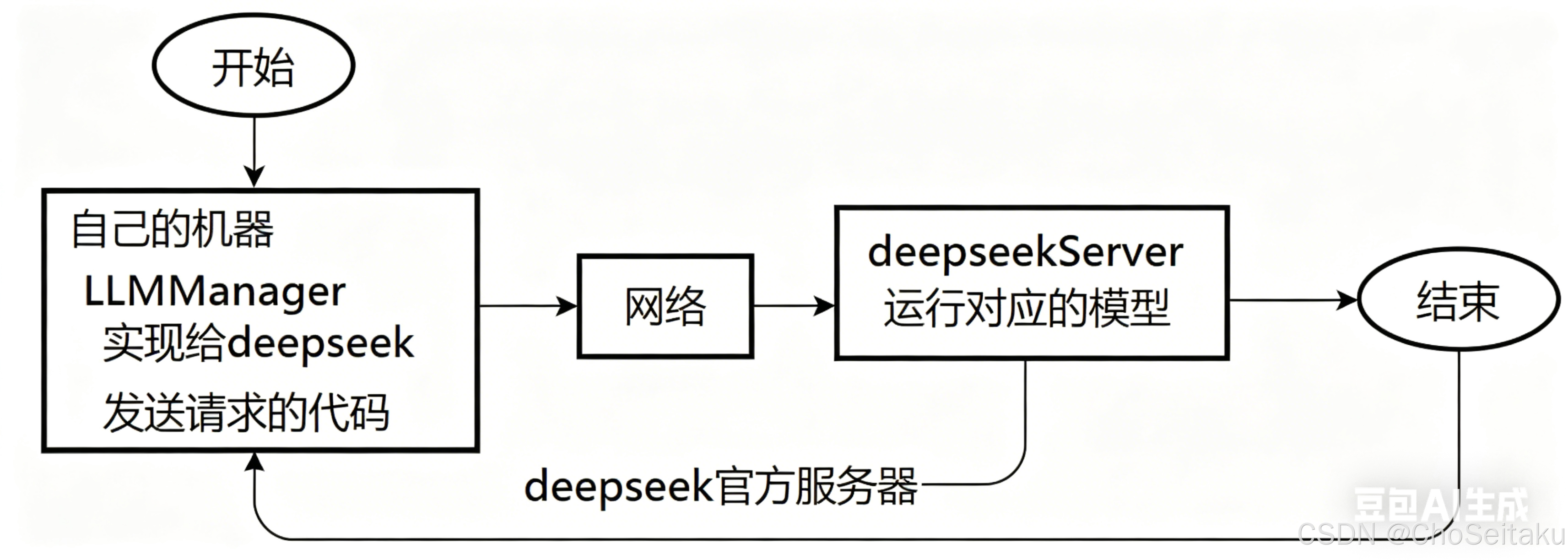
Ollama本地接⼊Deepseek
如果不使用第三方工具,如何自己在本地搭建大语言模型?
- 下载模型
需要知道到哪里去下载模型?一般在 Hugging Face Hub、ModelScope、官方模型仓库中
https://huggingface.co/ https://www.modelscope.cn/models
根据自己的需求 以及 硬件环境下载适合的模型
模型下载到本地之后是否就可以直接运行呢?不是的,模型不是一个可执行程序,下载模型实际是下载了一堆文件 - 下载一个推理引擎,推理引擎本质是一个专门的模型执行器,它负责:加载模型权重、处理输入文本、执行数学计算、生成输出文本等
llama.cpp 或者 Transformer,都是开源的推理引擎 - 还需要编写加载 / 推理代码。即实现一个简单的 python 或 C++ 程序与模型进行交互
为什么需要本地接⼊⼤模型
各⼤模型⼚商已经提供了⽹⻚版的⼤模型使⽤服务,⽐如DeepSeek、ChatGPT等,⽤⼾直接在⽹⻚上提问,就能得到需要的答案,为什么还要本地接⼊⼤模型呢?
使⽤云端⼤模型的优点
- 效果强:云端算⼒⾜、模型⼤,输出质量通过⾼于本地模型
- 即开即⽤:⽆需下载和配置,注册后即可使⽤
- ⾃动升级:官⽅会不断更新和优化模型
- 插件⽣态:ChatGPT plus、Gemini Advanced等往往⾃带额外功能
使⽤云端⼤模型的缺陷
- 隐私⻛险:输⼊的数据会传送到云端,虽然⼤⼚承诺,但仍有顾虑。许多⾏业(如医疗、⾦融、法律、政府)的数据⾼度敏感,法律禁⽌将数据上传到第三⽅。⽽且企业内部的战略⽂档、代码库、设计图等核⼼资产,如果通过API发送给第三⽅,存在泄露的⻛险
- 费⽤问题:⼤规模调⽤API需要付费,费⽤可能很⾼。虽然官⽹按token收费看起来单价不⾼,但对于⾼频使⽤的企业或个⼈开发者来说,⻓期积累的成本⾮常巨⼤
- ⽹络依赖:需要⽹络,有时访问受限,延迟⾼。在⽆⽹络请求下⽆法使⽤,⽐如保密单位、偏远地区等,⽽且⽹络⾼峰期可能还会遇到⽆法响应情况
- 可控性差:⽆法选择模型版本的内部细节,⽐如调整参数、控制模型输出格式、集成⾃定义函数等本地部署⼤模型优点
- 隐私保护:数据完全在本地处理,不会上传云端
- 零调⽤费⽤:模型下载后随便⽤,不会产⽣API调⽤费⽤
- 离线可⽤:没有⽹络也能⽤,⾮常适合边缘场景
- 灵活可控:可以随时切换模型,甚⾄加载⾃⼰的训练模型
本地部署⼤模型的缺陷
- 硬件要求⾼:对显卡、内容要求⽐较⾼
- 效果有限:在低成本下效果有限
- 初始成本⾼:模型下载很⼤,运⾏时占⽤资源多
因此对于普通⽤⼾和⾮敏感任务,直接使⽤官⽹的云端服务是最简单、最经济的选择。
但对于企业、有隐私或特殊需求的⽤⼾,就需要本地部署⼤模型。
本地接⼊⼤模型步骤

Ollama介绍
Download Ollama on Windows
Ollama官方
官方仓库
Ollama是⼀个开源的⼤型语⾔模型服务⼯具,旨在帮助⽤⼾快速在本地运⾏⼤模型。通过简单的安装指令,⽤⼾可以通过⼀条命令轻松启动和运⾏开源的⼤型语⾔模型。它提供了⼀个简洁易⽤的命令⾏界⾯和服务器,专为构建⼤型语⾔模型应⽤⽽设计。⽤⼾可以轻松下载、运⾏和管理各种开源LLM。
与传统LLM需要复杂配置和强⼤硬件不同,Ollama能够让⽤⼾在消费级的PC上体验LLM的强⼤功能。
Ollama会⾃动监测本地计算资源,如有GPU的条件,会优先使⽤GPU的资源,同时模型的推理速度也更快。如果没有GPU条件,直接使⽤CPU资源。
Ollama特点:
- 开源免费:Ollama及其⽀持的模型完全开源且免费,⽤⼾可以随时访问和使⽤这些资源,⽽⽆需⽀付任何费⽤。
- 简单易⽤:Ollama⽆需复杂的配置和安装过程,只需⼏条简单的命令即可启动和运⾏,为⽤⼾节省了⼤量时间和精⼒。
- ⽀持多平台:Ollama提供了多种安装⽅式,⽀持Mac、Linux和Windows平台,并提供Docker镜像,满⾜不同⽤⼾的需求。
- 模型丰富:Ollama⽀持包括DeepSeek-R1、Llama3.3、Gemma2、Qwen2在内的众多热⻔开源LLM,⽤⼾可以轻松⼀键下载和切换模型,享受丰富的选择。
- 功能⻬全:Ollama将模型权重、配置和数据捆绑成⼀个包,定义为Modelfile,使得模型管理更加简便和⾼效。
- ⽀持⼯具调⽤:Ollama⽀持使⽤Llama 3.1等模型进⾏⼯具调⽤。这使模型能够使⽤它所知道的⼯具来响应给定的提⽰,从⽽使模型能够执⾏更复杂的任务。
- 资源占⽤低:Ollama 优化了设置和配置细节,包括GPU使⽤情况,从⽽提⾼了模型运⾏的效率,确保在资源有限的环境下也能顺畅运⾏。
- 隐私保护:Ollama所有数据处理都在本地机器上完成,可以保护⽤⼾的隐私。
- 社区活跃:Ollama拥有⼀个庞⼤且活跃的社区,⽤⼾可以轻松获取帮助、分享经验,并积极参与到模型的开发和改进中,共同推动项⽬的发展。
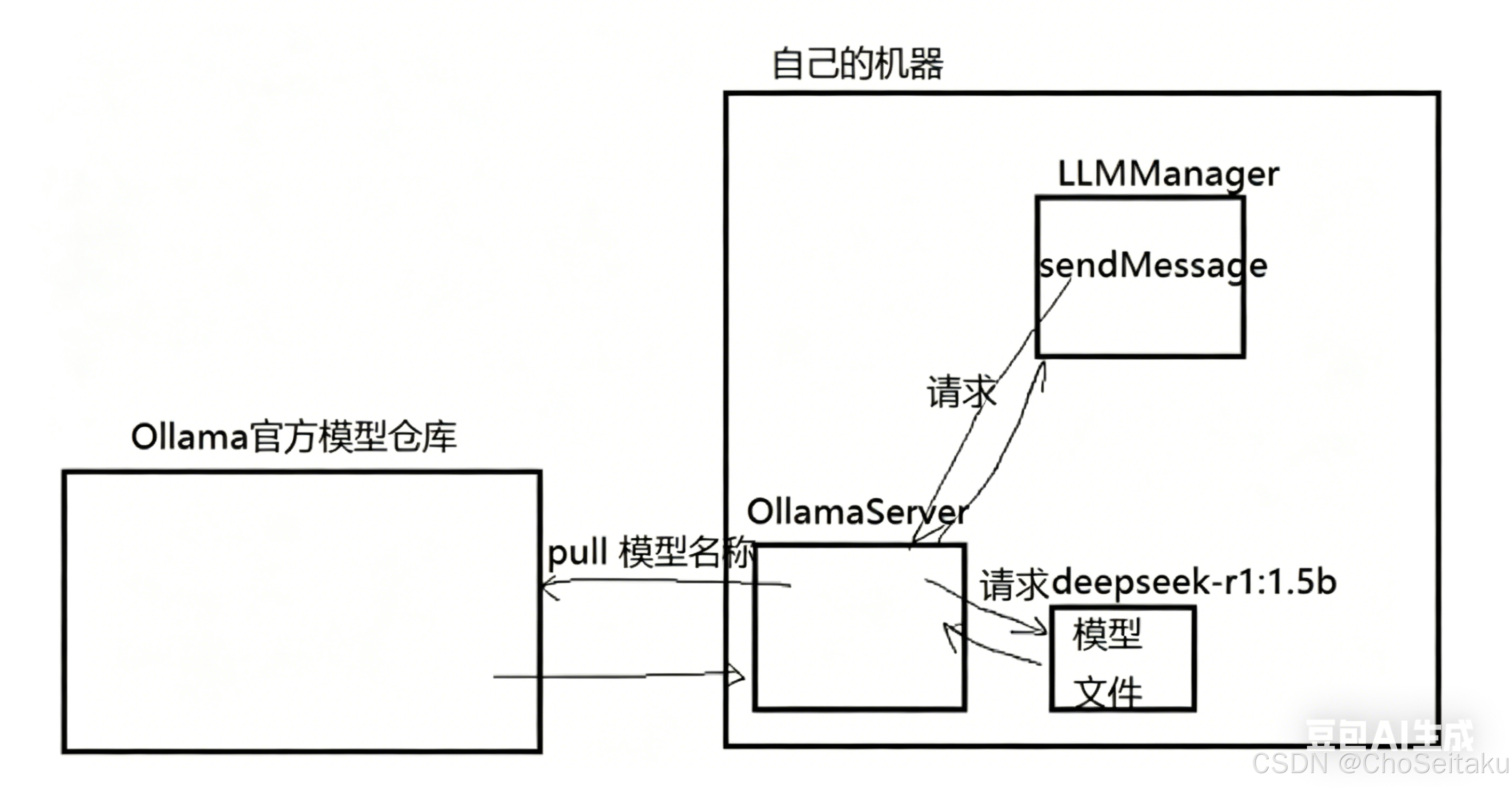
第一次给 ollama 服务器发送请求时,ollama 服务器会解析出模型名称
如果发现模型没有运行,ollama 服务器会将模型加载到内存运行起来
ollama 服务器会将用户发送的模型参数转给模型
第二次给模型发送请求时,ollama 直接将请求转给大模型
ubuntu下Ollama的安装和使用

Ollama常⽤指令
| 命令 | 描述 |
|---|---|
| ollama server | 启动 Ollama |
| ollama show | 显示模型信息 |
| ollama run | 运行模型 |
| ollama stop | 停止正在运行的模型 |
| ollama pull | 从 ollama 官方维护的模型库中拉去模型 ollama 官方维护的模型库 |
| ollama list | 列出所有可用模型 |
| ollama ps | 列出正在运行模型 |
| ollama rm | 删除模型 |
| ollama help | 显示任意命令的帮助信息 |
| 标志 | 描述 |
|---|---|
| -h、--help | 显示 Ollama 的帮助信息 |
| -v、--version | 显示版本信息 |
注意: ollama server 启动的是⼀个前台进程,终端关闭进程也就关闭了。在⽣产环境中,推荐使⽤ systemctl 来管理 Ollama 服务,该种⽅式下 Ollama 服务在后台运⾏,即使终端关闭服务仍会继续运⾏。
c
> sudo systemctl start ollama # 启动服务
> sudo systemctl stop ollama # 停⽌服务
> sudo systemctl status ollama # 查看服务状态
> sudo systemctl restart ollama # 重启服务


Ollama 服务启动之后,查看ollama服务运⾏情况:
c
ps -ef | grep ollama

可以看到,Ollama监听localhost的11434端⼝,因此在模型接⼊时endpoint可设置为:


c
bit@bit08:~/.ollama$ sudo ls -l /usr/share/ollama/.ollama/models
total 8
drwxr-xr-x 2 ollama ollama 4096 Sep 2 04:30 blobs
drwxr-xr-x 3 ollama ollama 4096 Sep 2 04:30 manifestsblobs/⽬录下存储模型的实际权重数据⽂件,⽂件名是 sha256-<哈希值> ,⽤来保证唯⼀性和去重。
manifests/⽬录下存储模型的清单信息,包括模型的metadata(名称、版本、描述等信息)、依赖关系和模型运⾏的参数配置。
当在终端运⾏ ollama run deepseek-r1:7b 命令时,Ollama⾸先查看 manifests/ ⽬录,找到deepseek-r1:7b 的清单⽂件,根据清单⽂件中的哈希值,找到blobs/⽬录中对应的模型⽂件,加载并运⾏模型。
windows下Ollama的安装和使用
在浏览器中输⼊: http://localhost:11434 ,看到 Ollama is running 时说明ollama服务已经启动了。
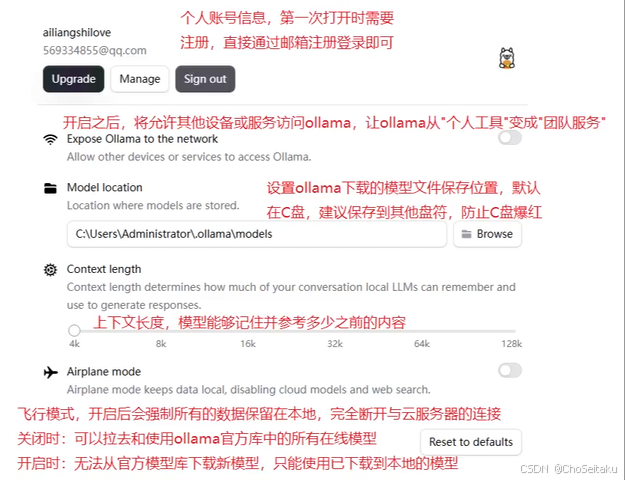
win10中,ollama安装好之后会带⼀个图形化界⾯:
环境变量
| 参数 | 标识与配置 |
|---|---|
| OLLAMA_MODELS | 表示模型文件的存放目录,默认目录为当前用户目录即 C:\Users\%username%.ollama\models,建议放在其他盘(如 D:\ApplyTool\ProgramTool\ollama\models) |
| OLLAMA_HOST | 表示 ollama 服务监听的网络地址,默认为 127.0.0.1 如果想要允许其他电脑访问 Ollama(如局域网中的其他电脑),建议设置成 0.0.0.0 |
| OLLAMA_PORT | 表示 ollama 服务监听的默认端口,默认为 11434 如果端口有冲突,可以修改设置成其他端口(如 8080 等) |
| OLLAMA_ORIGINS | 表示 HTTP 客户端的请求来源,使用半角逗号分隔列表 如果本地使用不受限制,可以设置成星号 * |
| OLLAMA_KEEP_ALIVE | 表示大模型加载到内存中后的存活时间,默认为 5m 即 5 分钟 (如纯数字 300 代表 300 秒,0 代表处理请求响应后立即卸载模型;任何负数则表示一直存活) 建议设置成 24h,即模型在内存中保持 24 小时,提高访问速度 |
| OLLAMA_NUM_PARALLEL | 表示请求处理的并发数量,默认为 1(即单并发串行处理请求) 建议按照实际需求进行调整 |
| OLLAMA_MAX_QUEUE | 表示请求队列长度,默认值为 512 建议按照实际需求进行调整,超过队列长度的请求会被抛弃 |
| OLLAMA_DEBUG | 表示输出 Debug 日志,应用研发阶段可以设置成 1(即输出详细日志信息,便于排查问题) |
| OLLAMA_MAX_LOADED_MODELS | 表示最多同时加载到内存中模型的数量,默认为 1(即只能有 1 个模型在内存中) |
通过Ollama初始化模型
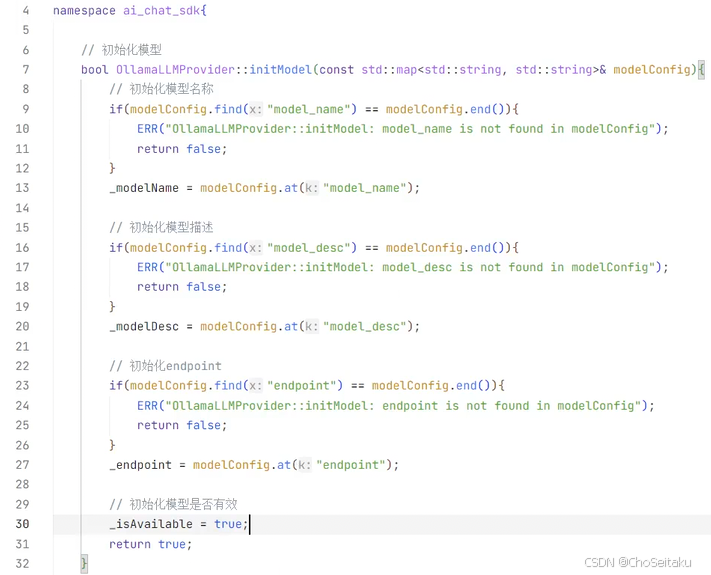
由于现在是通过Ollama本地接⼊某个⼤模型,Ollama实际是在本地搭建了⼀个服务器,⽤⼾可以通过Ollama下载需要接⼊的模型,Ollma会替⽤⼾管理模型,并真正和⼤模型对接,⽤⼾通过Ollama提供的HTTP接⼝访问。⽤⼾向⼤模型发的消息实际是,先发给Ollama服务器,Ollama服务器将消息发给⼤模型,⼤模型响应之后,Ollama再将消息返回给⽤⼾,⽤⼾不直接和⼤模型交互,因此初始化时不需要设置api key进⾏⾝份认证。
注意:本地部署可以在⾃⼰的本地机器上,也可以在企业⾃⼰的局域⽹或云服务器上。
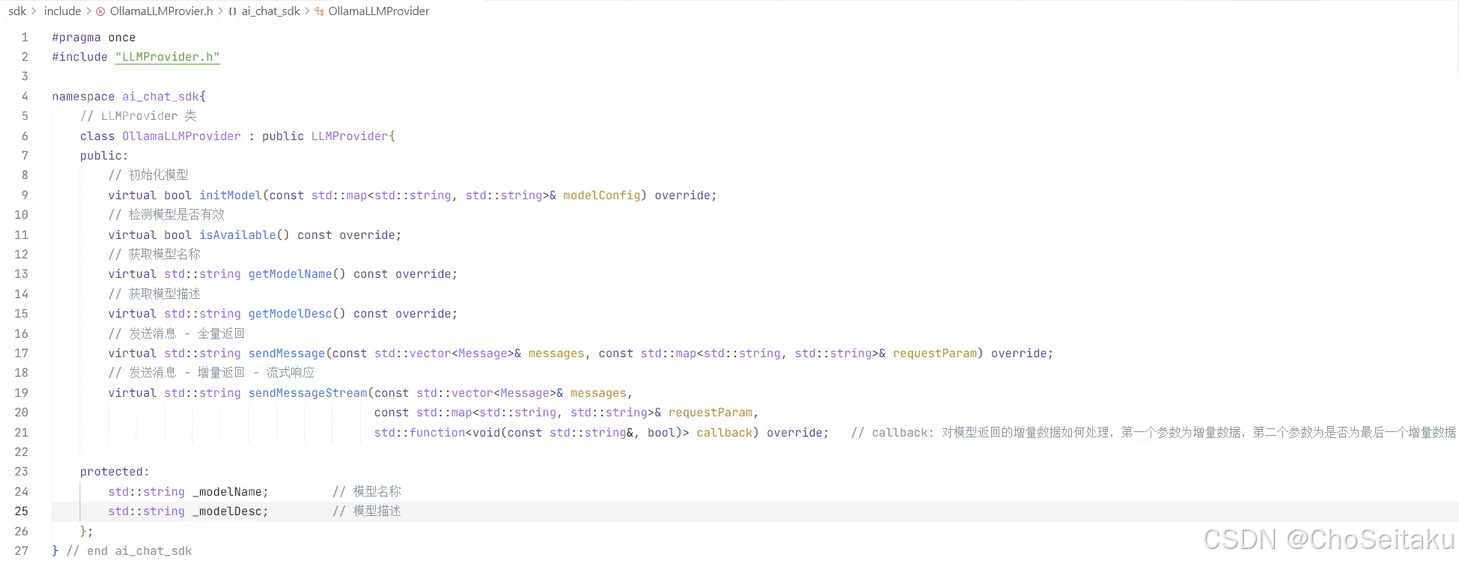
Ollama可以接⼊许多⼤模型,具体接⼊那个⼤模型看⽤⼾选择,因此需加⼊_model_name和_model_desc来保存接⼊的⼤模型的名称和描述信息。
OllamaLLMProvider.h
发送消息-全量消息
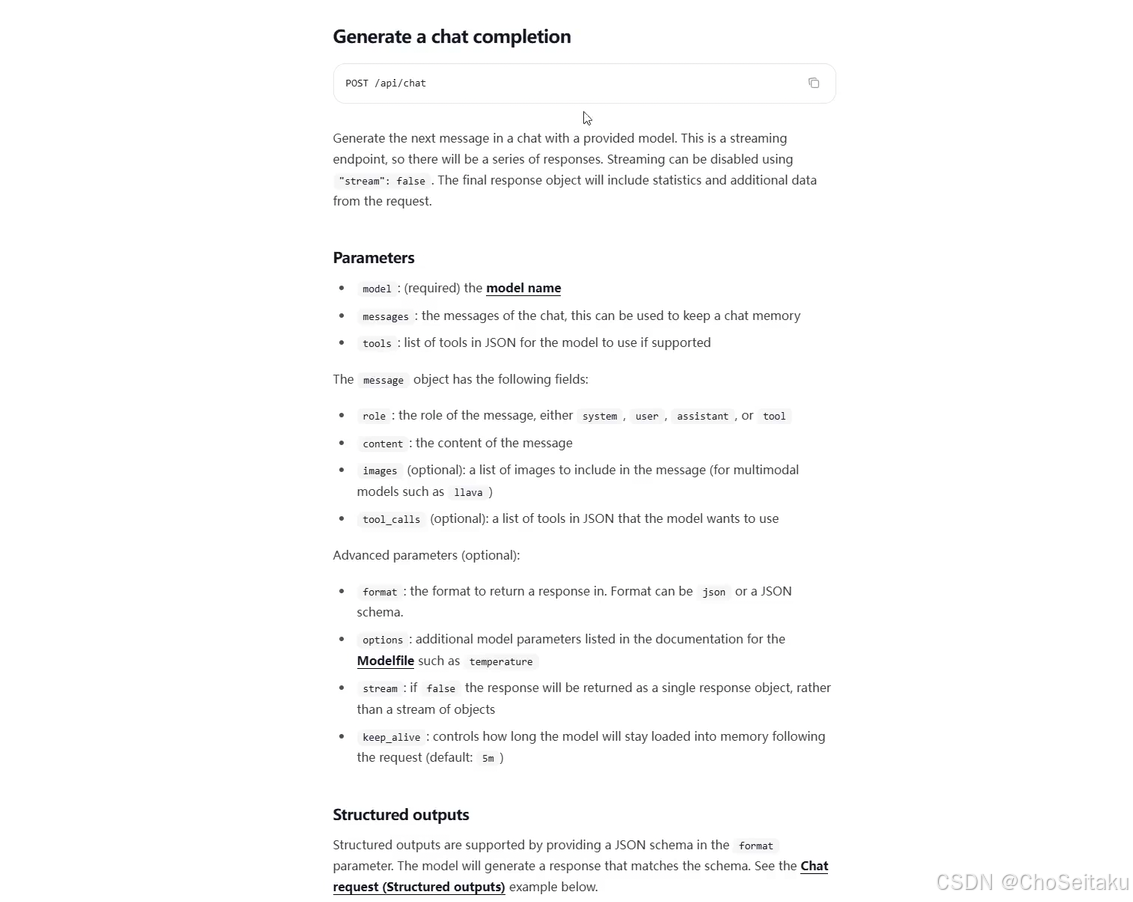
发送全量消息接⼝:
URL: /api/chat
参数:
model : 模型名称。
message : 消息列表,包含历史消息
stream : 是否开启流式响应,true开启,false关闭,默认开启流式响应
options : json对象,设置⼀些⾼级的可选参数,⽐如:temperature、最⼤tokens数。注意:
Ollama的最⼤ tokens字段为num_ctx启动ollama之后,在终端中使⽤bash给ollama发送请求:
# 使⽤curl给ollama发送请求
curl -s -X POST "http://127.0.0.1:11434/api/chat" -H "Content-Type:
application/json" -d '{"model" : "deepseek-r1:1.5b", "stream" : false,
"messages" : [{"role" : "user", "content" : "你是谁?"}], "options" :
{"temperature" : 0.7, "num_ctx" : 2048}}'
# 模型响应
{
"model":"deepseek-r1:1.5b",
"created_at":"2025-09-02T09:24:03.117965426Z",
"message":{
"role":"assistant",
"content":"\n\n\u003c/think\u003e\n\n你好!很⾼兴⻅到你,有什么我可以帮忙的吗?"
},
"done_reason":"stop",
"done":true,
"total_duration":24879553617,
"load_duration":97011891,
"prompt_eval_count":2,
"prompt_eval_duration":133646497,
"eval_count":181,
"eval_duration":24647987800
}OllamaLLMProvider.cpp


给Ollama服务器发送请求时可能会失败
- 尝试将代理关闭,不运行clash工具,+/.bashrc文件中添加的代理相关的环境变量屏蔽掉
- 如果bashrc文件修改了,重新加载该文件才能生效,source ~/.bashrc
- 如果还是不行,检查curl工具是否还在走代理,如果走代理将代理屏蔽掉
查看有没有走代理





发送消息-全量消息测试
testLLM.cpp

CMakeLists.txt

发送消息-流式响应
URL: /api/chat
参数:
model : 模型名称。
message : 消息列表,包含历史消息
stream : 是否开启流式响应,true开启,false关闭,默认开启流式响应
options : json对象,设置⼀些⾼级的可选参数,⽐如:temperature、最⼤tokens数。注意:
Ollama的最⼤ tokens字段为num_ctx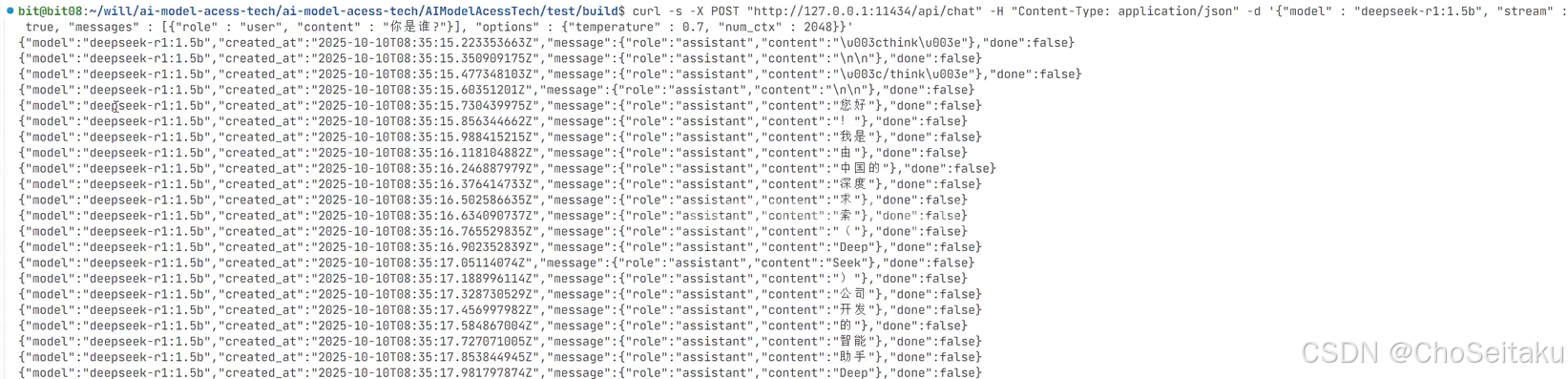
对⽐DeepSeek的直接响应格式,可以看出Ollama对DeepSeek返回的结果进⾏了简化处理
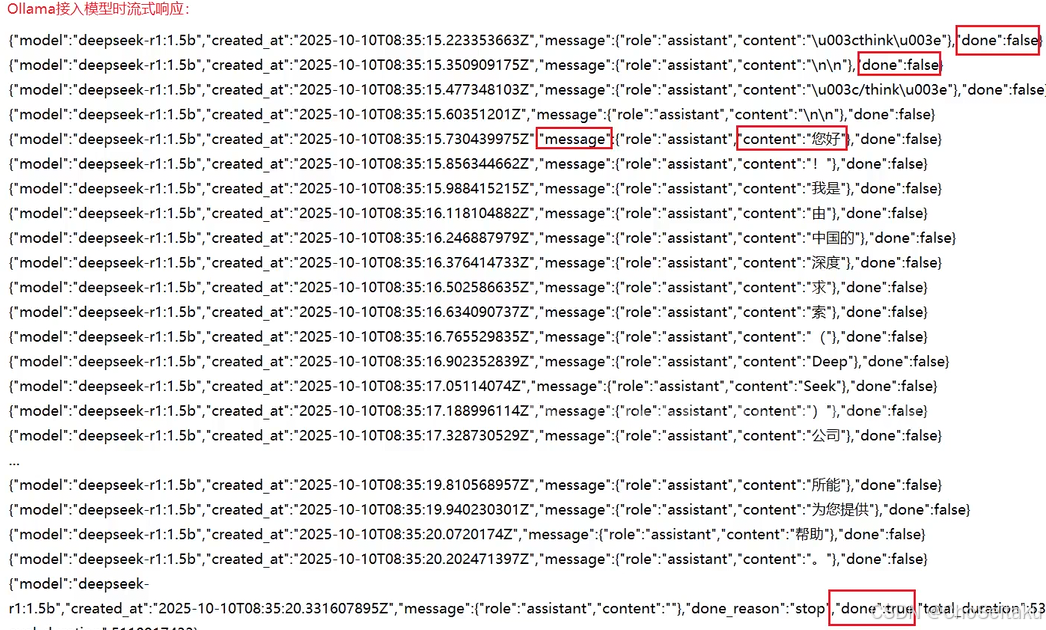
done字段为false,说明模型返回的增量数据还没有结束
done字段为true,表明模型返回的增量数据已经结束了
OllamaLLMProvider.cpp

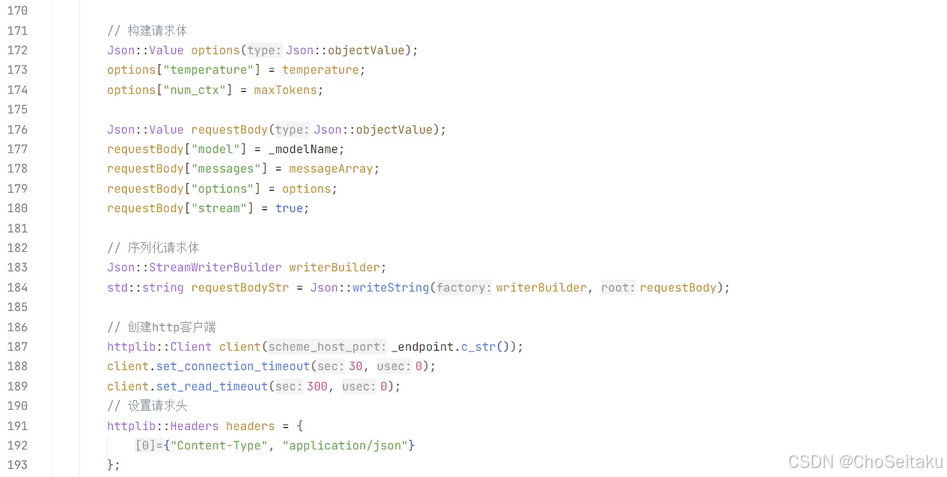




发送消息-流式响应测试
testLLM.cpp

