声明:
- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
先验知识:
ResNet残差网络,根据网络层数可以分为(ResNet-18、ResNet-34、ResNet-50、ResNet-101等),他和普通的CNN网络不同的地方就是他提出了一个残差的概念,解决了卷积网络在深度加深时候的梯度爆炸、梯度消失的问题
梯度消失:在反向传播的过程中,随着网络层数的增加,前几层的梯度值会变得非常小,接近于0
梯度爆炸:在反向传播过程中,随着网络层数增加,梯度值变得非常大,导致网络权重更新幅度过大,模型无法收敛
BN层的提出虽然在一定情况下解决了这个问题,但是加了BN会带来网络变得更复杂,更不容易收敛的影响。故何凯明证明了一个问题就是,只要有合适的网络结构,深的网络肯定比浅的好,残差网络孕育而生。
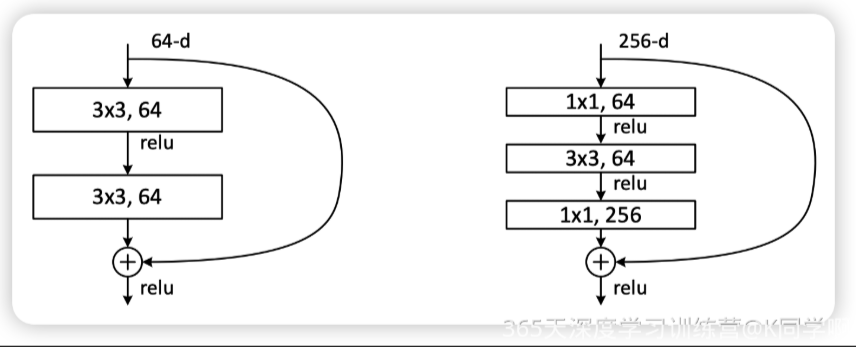
主要使用的残差单元有这两种,分别是两层的浅残差和3层的深残差。
我的环境:
Python版本:3.8.10
PyTorch版本:2.4.1+cpu
Torchvision版本:0.19.1+cpu
学习记录:
由于是刚回归Pytorch的第一篇,我会尽量讲细一点
整体流程跟tensorflow差不多的,都是初始化GPU,数据集划分处理,网络选择,训练测试函数撰写,然后正式训练,最后成果可视化
1.设置GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")2.数据导入
在数据导入的时候我们要设置一个transform,来对数据进行处理
train_transforms = transforms.Compose([
#尺寸调节
transforms.Resize((224, 224)),
#totensor类型
transforms.ToTensor(),
#归一化
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])pytorch在使用时要记得将图片变成tensor类型
然后就可以调用datasets.ImageFolder来对其进行图片批量处理了,这个函数还会生成dataset格式,就是将每个图像根据文件名自动生成标签
total_dataset = datasets.ImageFolder(data_dir, transform=train_transforms)后面经过数据集比例划分就可以调用DataLoader来生产测试集和训练集了
train_size = int(0.8 * len(total_dataset))
test_size = len(total_dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_dataset, [train_size, test_size])
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)3.网络选择
这次我们选的是自建ResNet-50
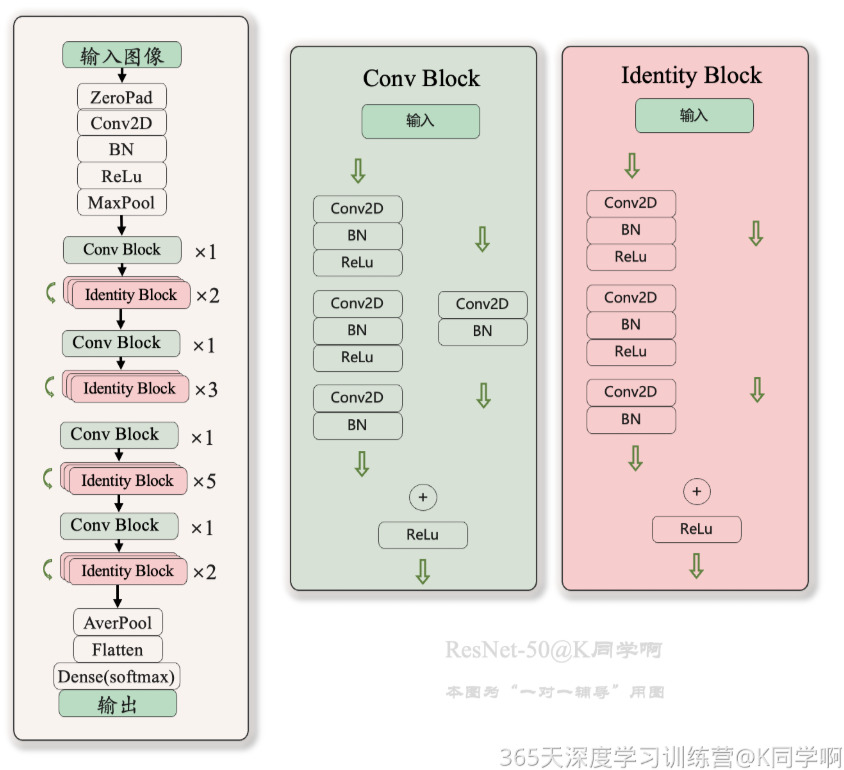
网络如图所示
因为中间反复使用卷积块和恒等块,故我们需要先将他们俩给定义了
恒等块:三层卷积后与原始值相加后通过一个激活函数
class IdentityBlock(nn.Module):
def __init__(self, in_channels, filters, kernel_size):
super(IdentityBlock, self).__init__()
#filters输入是个数组
f1, f2, f3 = filters
self.conv1 = nn.Sequential(
#bias=False, 不使用偏执函数(有批归一化了)
nn.Conv2d(in_channels, f1, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(f1),
#节约内存
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(f1, f2, kernel_size=kernel_size, stride=1, padding='same', bias=False),
nn.BatchNorm2d(f2),
nn.ReLU(inplace=True)
)
self.conv3 = nn.Sequential(
nn.Conv2d(f2, f3, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(f3)
)
#先加后激活,保留通路的线性特征
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
#先加后激活
out += identity
out = self.relu(out)
return out卷积块:一条路卷三次,一条路卷一次,最后相加后激活
class ConvBlock(nn.Module):
def __init__(self, in_channels, filters, kernel_size, stride=2):
super(ConvBlock, self).__init__()
f1, f2, f3 = filters
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, f1, kernel_size=1, stride=stride, padding=0, bias=False),
nn.BatchNorm2d(f1),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(f1, f2, kernel_size=kernel_size, stride=1, padding='same', bias=False),
nn.BatchNorm2d(f2),
nn.ReLU(inplace=True)
)
self.conv3 = nn.Sequential(
nn.Conv2d(f2, f3, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(f3)
)
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, f3, kernel_size=1, stride=stride, padding=0, bias=False),
nn.BatchNorm2d(f3)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
shortcut = self.shortcut(identity)
out += shortcut
out = self.relu(out)
return out接下来就可以写resnet-50了
class ResNet50(nn.Module):
def __init__(self, num_classes=3):
super(ResNet50, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False, padding_mode='zeros'),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.conv2 = nn.Sequential(
ConvBlock(64, [64, 64, 256], kernel_size=3, stride=1),
IdentityBlock(256, [64, 64, 256], kernel_size=3),
IdentityBlock(256, [64, 64, 256], kernel_size=3)
)
self.conv3 = nn.Sequential(
ConvBlock(256, [128, 128, 512], kernel_size=3),
IdentityBlock(512, [128, 128, 512], kernel_size=3),
IdentityBlock(512, [128, 128, 512], kernel_size=3),
IdentityBlock(512, [128, 128, 512], kernel_size=3)
)
self.conv4 = nn.Sequential(
ConvBlock(512, [256, 256, 1024], kernel_size=3),
IdentityBlock(1024, [256, 256, 1024], kernel_size=3),
IdentityBlock(1024, [256, 256, 1024], kernel_size=3),
IdentityBlock(1024, [256, 256, 1024], kernel_size=3),
IdentityBlock(1024, [256, 256, 1024], kernel_size=3),
IdentityBlock(1024, [256, 256, 1024], kernel_size=3)
)
self.conv5 = nn.Sequential(
ConvBlock(1024, [512, 512, 2048], kernel_size=3),
IdentityBlock(2048, [512, 512, 2048], kernel_size=3),
IdentityBlock(2048, [512, 512, 2048], kernel_size=3)
)
self.avgpool = nn.AvgPool2d(kernel_size=7, stride=7, padding=0)
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
model = ResNet50(num_classes=3).to(device)看一眼参数吧
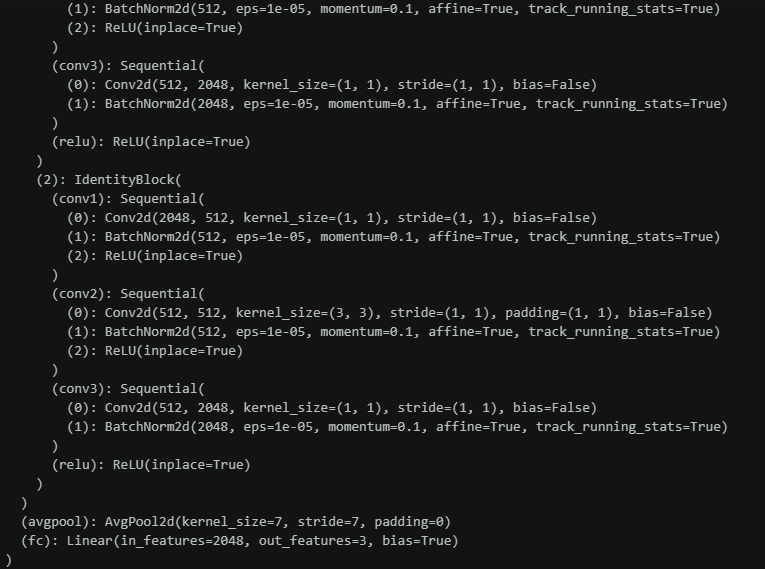
import torchsummary as summary
summary.summary(model, (3, 224, 224))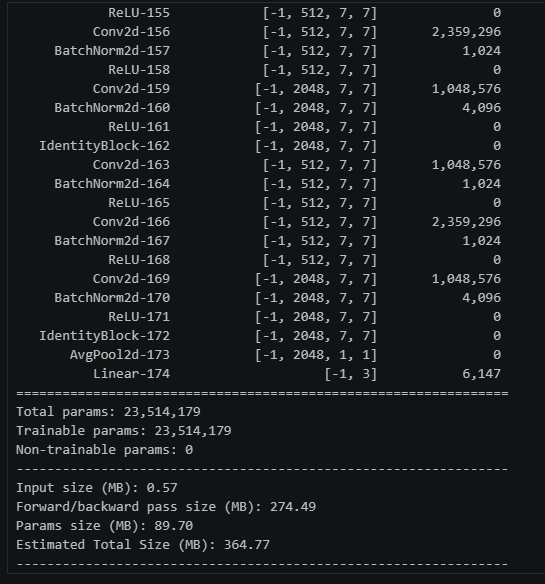
50层是指卷积层+开头的和结尾的fc层
4.训练测试函数
训练测试函数核心在于前向传播与反向传播和todevice
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, correct = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
# 前向传播
pred = model(X)
loss = loss_fn(pred, y)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss /= num_batches
correct /= size
return train_loss, correct
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
return test_loss, correct5.开始训练!
选择后优化器和损失函数就可以开始训练了
import copy
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0001)
loss_fn = nn.CrossEntropyLoss()
num_epochs = 10
train_loss_history = []
train_acc_history = []
test_loss_history = []
test_acc_history = []
best_acc = 0.0
for epoch in range(num_epochs):
model.train()
train_loss, train_acc = train(train_dl, model, loss_fn, optimizer)
train_loss_history.append(train_loss)
train_acc_history.append(train_acc)
model.eval()
test_loss, test_acc = test(test_dl, model, loss_fn)
test_loss_history.append(test_loss)
test_acc_history.append(test_acc)
if test_acc > best_acc:
best_acc = test_acc
best_model_wts = copy.deepcopy(model.state_dict())
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = 'Epoch [{}/{}], LR: {:.6f}, Train Loss: {:.4f}, Train Acc: {:.4f}, Test Loss: {:.4f}, Test Acc: {:.4f}'
print(template.format(epoch+1, num_epochs, lr, train_loss, train_acc,
test_loss, test_acc))
PATH = '../model/resnet50.pth'
torch.save(best_model_wts, PATH)
print('DONE')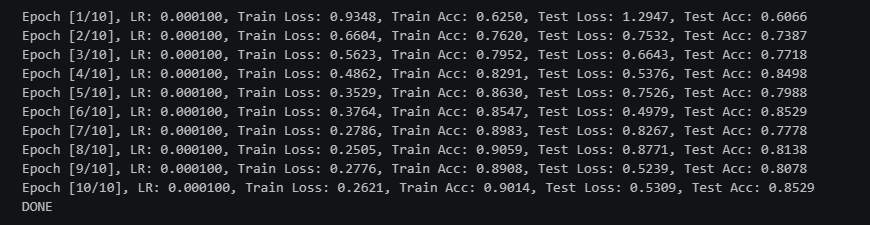
6.数据可视化
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
from datetime import datetime
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
epochs = range(1, num_epochs + 1)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs, train_loss_history, label='训练损失')
plt.plot(epochs, test_loss_history, label='测试损失')
plt.title('训练和测试损失')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs, train_acc_history, label='训练准确率')
plt.plot(epochs, test_acc_history, label='测试准确率')
plt.title('训练和测试准确率')
plt.xlabel(current_time)
plt.legend()
plt.show()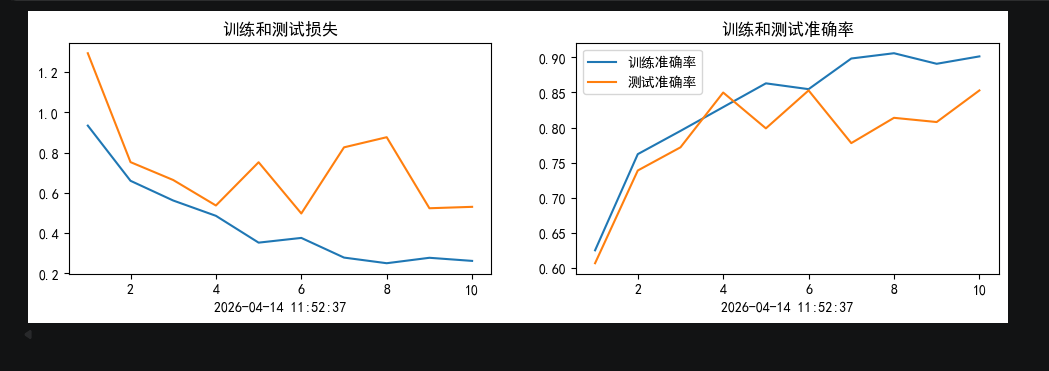
总结:
这一节我们重新回到了Pytorch环境进行训练,在该环境下可以调用OpenCV等图像处理库。并且了解了ResNet 这个经典的CNN网络结构,并完成了他的搭建与训练。