https://arxiv.org/pdf/2603.19628
摘要 --- 鲁棒的特征编码通过实现对目标外观和运动的细腻感知,构成了无人机跟踪的基础,因此在确保可靠跟踪方面起着关键作用。然而,现有的特征编码方法常常忽略了关键的照明和视点线索,而这些线索对于在具有挑战性的夜间条件下进行鲁棒感知至关重要,导致跟踪性能下降。为克服上述局限,本文提出一种双重提示驱动的特征编码方法,该方法集成了提示条件特征自适应和上下文感知提示演化,以促进领域不变的特征编码。具体而言,提出了金字塔光照提示,以提取多尺度频率感知的光照提示。动态视点提示调制可变形卷积偏移,以适应视点变化,使跟踪器能够学习视点不变特征。大量实验验证了所提出的双重提示驱动跟踪器在应对夜间无人机跟踪中的有效性。消融研究突显了DPTracker中每个组件的贡献。在不同夜间无人机跟踪场景下的真实世界测试进一步证明了其鲁棒性和实用性。代码和演示视频见:https://github.com/yihong-wang-duke/DPTracker。
I. 引言
无人机跟踪在如定位与着陆1、交通监控2和自主导航3等应用中得到了广泛采用。随着深度神经网络的进步和大规模标注数据集的出现,无人机跟踪已取得了显著的性能提升。促成这些进步的一个关键因素是更深层模型强大的特征编码能力,它通过捕获外观和运动线索来构建具有判别力的表示,从而为精确的目标定位和轨迹估计奠定基础。然而,当应用于夜间场景时,由于低光照图像中的严重光照退化和低对比度,以及无人机平台独特的空中视点,无人机跟踪仍然极具挑战性。现有最先进跟踪器在特征编码中对光照和视点线索的考虑有限,削弱了可靠特征提取,导致在
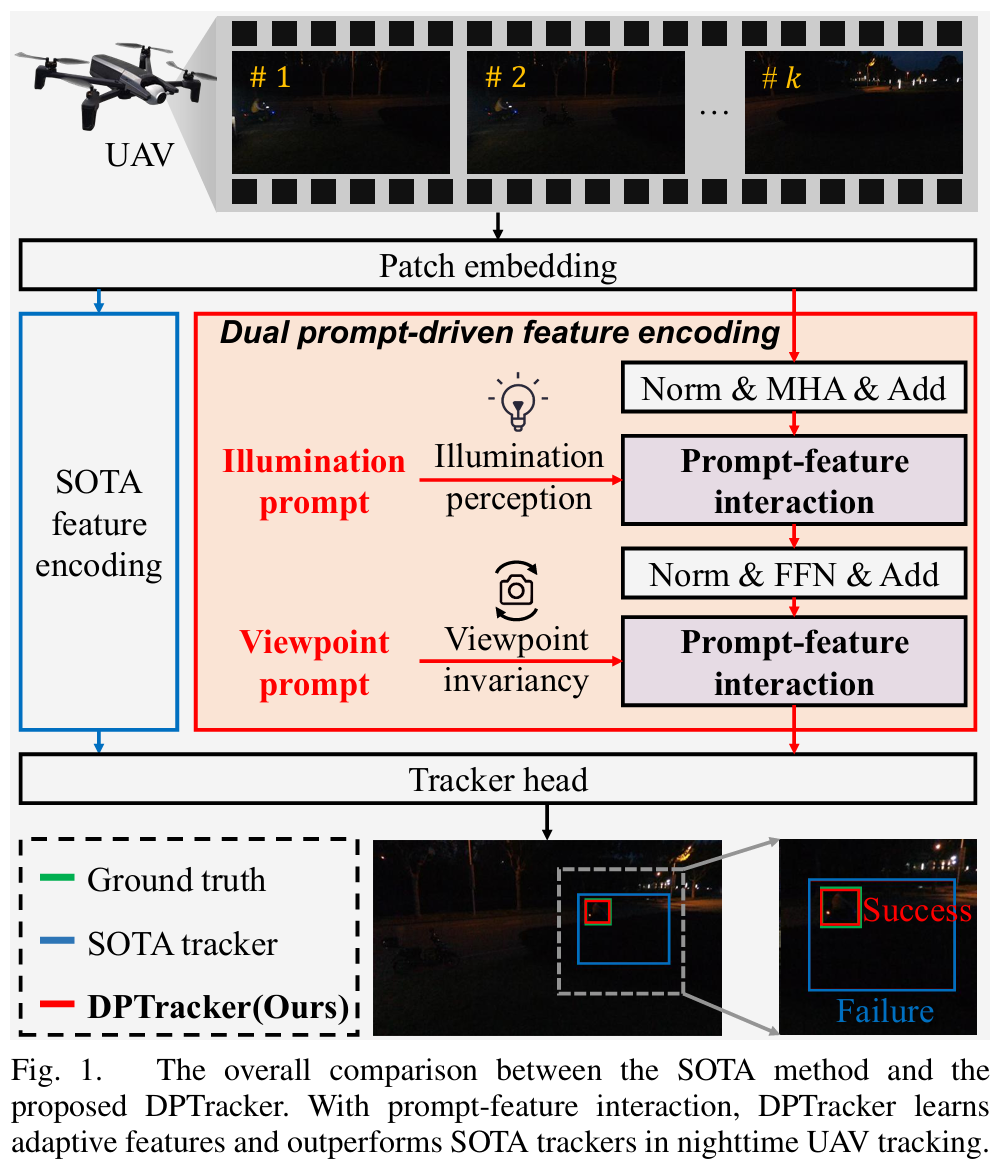
图1. 最先进方法与所提出的DPTracker的总体比较。通过提示-特征交互,DPTracker学习自适应特征,并在夜间无人机跟踪中胜过SOTA跟踪器。
基于深度学习的最新进展,许多SOTA跟踪器采用视觉Transformer 6架构,因其在建模全局依赖和空间关系方面能力强。典型的基于ViT的跟踪范式遵循三阶段流水线:图像块嵌入、特征编码和预测头。具体而言,输入图像首先被分割成不重叠的图像块,然后被线性投影为图像块嵌入。嵌入由一系列ViT块处理以提取高级特征。最后,跟踪器头解码这些特征来预测目标的位置和边界框。然而,SOTA跟踪器对于夜间无人机跟踪并不足够有效,因为它们的特征编码缺乏对领域特定挑战的鲁棒性4。在低光照条件和动态变化的空中视点下,编码后的视觉令牌往往质量下降、位置线索错位和语义一致性失真,这共同导致有偏的查询-键关系及不可靠的注意力形成。因此,有必要将光照和视点信息纳入特征编码阶段,以确保为鲁棒的夜间无人机跟踪提供可靠表示。
为解决该问题,本文提出双重提示驱动特征编码块,以将光照和视点提示语义集成到ViT骨干的特征编码中。DPBlock建立提示条件化引导,生成的提示令牌调制特征,使模型能够在退化条件下关注关键视觉线索。提示驱动的特征编码增强了模型适应低光环境和动态空中视点的表示能力,从而提高了夜间无人机跟踪场景中的鲁棒性。同时,利用中间表示通过反馈连接来优化提示令牌,使提示令牌能够基于不断演化的特征上下文动态调整,并更好地指导后续条件化。
本工作进一步设计了提示来学习捕获光照信息和编码动态空中视点特性的提示令牌,如图1所示。金字塔光照提示器受拉普拉斯金字塔7启发,设计用于从输入图像中分层提取多尺度光照特征。通过逼近拉普拉斯分解结构,该提示器捕获频率感知特征,然后将其聚合为有效表示光照条件的光照提示令牌。此外,开发了动态视点提示器以提取用于提示驱动特征编码的视点信息。该模块利用可变形卷积学习自适应偏移进行特征采样,使视点提示令牌能感知由动态无人机视点引起的几何变化,从而增强跟踪器对不同空中视角和相机姿态的适应性。本文的贡献总结如下:
- 提出一种创新的双重提示驱动特征编码方法,将提示-特征交互机制集成到ViT骨干中,实现提示令牌与视觉特征之间的显式双向自适应,以进行光照感知和视点不变的表示学习。
- 设计了一种新颖的金字塔光照提示器来近似拉普拉斯金字塔,分层生成多尺度光照特征,并进一步将其聚合为光照提示令牌。
- 提出了动态视点提示器以生成视点提示令牌,利用可变形卷积使空间采样适应不同视点。
- 在夜间无人机跟踪基准上的大量实验证明了DPTracker的有效性,而真实世界测试进一步验证了其在实际场景中的适用性和优越性能。
II. 相关工作
A. 夜间无人机跟踪
最近的夜间无人机跟踪研究分为四种范式:低光照图像增强、领域自适应、从头训练和提示微调。低光照增强方法8采用即插即用模块在跟踪前增强图像。虽然提升了视觉质量,但这种预处理与特征编码耦合松散,并常常产生次优的跟踪表示。领域自适应方法旨在以无监督方式弥合白天和夜间图像之间的分布差距。UDAT 4率先采用对抗训练来学习领域不变特征。SAM-DA 9通过基于SAM的膨胀在无监督领域自适应中提升样本质量。TDA 10将时序上下文自适应纳入领域自适应框架。然而,由于未明确建模光照和视点线索,无监督领域自适应方法往往遭受训练不稳定和鲁棒性有限的困扰。从头训练方法直接使用夜间目标检测标注训练模型。DARTer 11利用多视角特征和动态特征激活器实现更好的跟踪性能,而MambaNUT 12采用视觉Mamba架构并结合定制的数据采样和损失调度器。但是,从头训练方法耗时,且因夜间训练数据有限容易过拟合,使得学到的特征编码通用性较差。提示微调通过将任务相关先验注入特征编码,提供了一种训练高效且性能良好的替代方案。然而,现有基于提示的跟踪器的特征编码未能充分融入光照和视点信息,这反过来限制了它们在具有挑战性的夜间无人机跟踪条件下的鲁棒性。
B. 面向跟踪的提示微调
提示微调方法已成为一种有效范式,能以最小的参数开销将冻结的预训练基础模型适配到各种跟踪场景。ViPT 13和OneTracker 14引入模态相关的视觉提示来弥合多模态跟踪中的领域差距。UM-ODTrack 15进一步整合了密集时序令牌关联和门控模块,以实现自适应跨模态表示学习。MM-Track 16通过自适应传递判别线索同时保持时序一致性,增强了多模态表示的鲁棒性。MPT 17提出了一个轻量级运动提示模块,将长期轨迹信息编码到视觉嵌入空间。DCPT 18在夜间无人机跟踪中率先使用提示微调技术。它引入了一个暗度线索提示器,将抗暗知识注入冻结的白天跟踪器。然而,这些用于视觉跟踪的提示微调方法未能在特征编码中同时考虑光照条件和动态空中视点,导致夜间无人机跟踪的特征表示不足。因此,有必要开发能提取丰富光照和视点语义的提示器,以推进基于提示微调的夜间无人机跟踪。
III. 方法
本节清晰阐述所提出的方法。第III-A节介绍双重提示驱动特征编码模块,该模块实现提示条件特征自适应和上下文感知提示演化。第III-B节介绍金字塔光照提示,它提取多尺度、频率感知的光照提示令牌。第III-C节介绍动态视点提示,它自适应变形卷积核,以从无人机视角图像中捕获视点提示令牌。
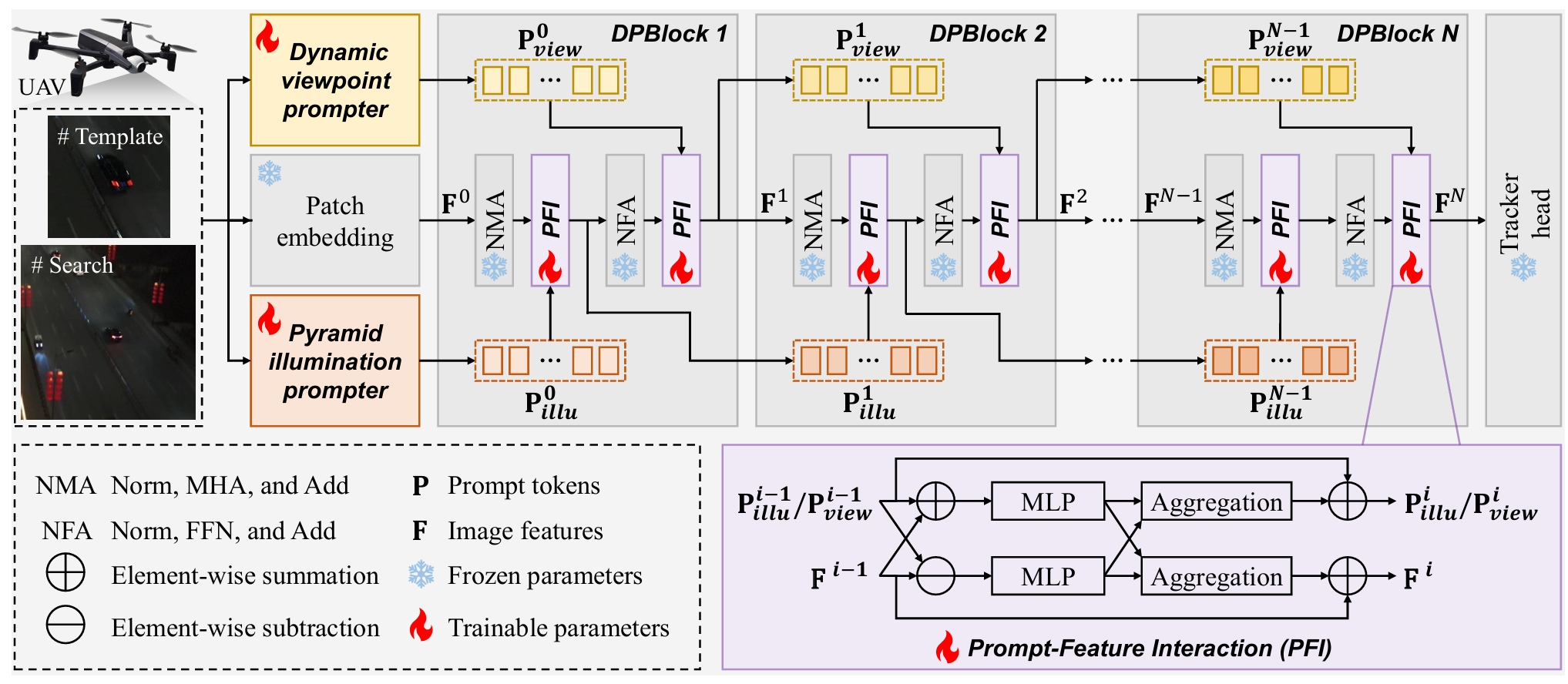
图2. DPTracker的整体模型架构。提示令牌与特征之间的交互将提示语义集成到特征中,同时更新提示令牌,从而通过更具适应性的表示来增强夜间无人机跟踪。图像来自NAT2021-test 4。
A. 双重提示驱动特征编码
为了赋予特征编码以光照和视点线索,本文提出了双重提示驱动特征编码模块。如图2所示,DPBlock在ViT结构内集成了两个提示-特征交互模块。第一个PFI模块集成在ViT的自注意力子层之后,以在低对比度背景中消除目标特征的歧义。通过注入光照感知语义,它弥补了多头注意力在光线不足环境中容易产生难以区分响应的趋势。第二个PFI模块跟随前馈子层,以培养视点不变表示。在前馈网络深化每令牌语义的同时,PFI模块修正了具有动态视点的无人机跟踪中固有的严重几何失真。具体而言,PFI由两种互补的方法组成,即提示条件特征自适应和上下文感知提示演化。提示条件特征自适应将来自提示令牌的语义线索整合到特征表示中。上下文感知提示演化则利用最新的特征上下文更新提示令牌,使其能够为特征自适应传递更精确的指导。
提示条件特征自适应结合了逐元素求和与减法,以刻画提示令牌 Pki∈RN×d\mathbf{P}_k^i\in \mathbb{R}^{N\times d}Pki∈RN×d 与特征 Fi∈RN×d\mathbf{F}^i\in \mathbb{R}^{N\times d}Fi∈RN×d 之间的相互作用,其中iii表示DPBlock的索引,k∈{illu,view}k\in \{illu,view\}k∈{illu,view} 指示提示令牌的类型。具体地,求和操作强化共享的特征流形,以建模提示与潜在表示之间的相似性,而减法操作则隔离残差的、独特的成分,以捕获它们之间的差异。然后,应用多层感知机模块来增强和放大编码的语义相似性和差异性。此过程公式化为:
Esimi=LN(MLP(Fi−1+Pki−1)),Edifi=LN(MLP(Fi−1−Pki−1)),(2)\begin{array}{rl} & {\mathbf{E}_{sim}^i = LN(MLP(\mathbf{F}^{i - 1} + \mathbf{P}k^{i - 1})),}\\ & {\mathbf{E}{dif}^i = LN(MLP(\mathbf{F}^{i - 1} - \mathbf{P}_k^{i - 1})),} \end{array} \quad (2)Esimi=LN(MLP(Fi−1+Pki−1)),Edifi=LN(MLP(Fi−1−Pki−1)),(2)
其中Esimi\mathbf{E}{sim}^iEsimi和Edifi\mathbf{E}{dif}^iEdifi表示第iii个DPBlock中的相似性感知特征和差异性感知特征,MLPMLPMLP功能为多层感知机模块,LNLNLN表示层归一化。
提示条件特征自适应进一步融入相似性线索并抑制差异性线索,确保特征表示强调与提示令牌的语义对齐。该自适应采用一种简单的加权聚合策略,公式化为:
Fi=Fi−1+αf⋅Esimi−βf⋅Edifi,(3)\mathbf{F}^i = \mathbf{F}^{i - 1} + \alpha_f\cdot \mathbf{E}{sim}^i -\beta_f\cdot \mathbf{E}{dif}^i, \quad (3)Fi=Fi−1+αf⋅Esimi−βf⋅Edifi,(3)
其中αf\alpha_fαf和βf\beta_fβf是可学习系数,决定了各成分在特征自适应中的贡献。
上下文感知提示演化利用一种类似但不对称的加权聚合方法。它减弱相似性线索并增强差异性线索,使提示令牌能够动态适应最新的特征上下文,并为后续的特征自适应提供更有效的指导。此过程公式化为:
Pi=Pi−1−αp⋅Esimi+βp⋅Edifi,(4)\mathbf{P}^i = \mathbf{P}^{i - 1} - \alpha_p\cdot \mathbf{E}{sim}^i +\beta_p\cdot \mathbf{E}{dif}^i, \quad (4)Pi=Pi−1−αp⋅Esimi+βp⋅Edifi,(4)
其中αp\alpha_pαp和βp\beta_pβp是可学习系数。
注1: 双重提示驱动特征编码方法实现了一种动态交互,其中特征从提示令牌吸收语义指导,而提示令牌基于最新的特征上下文演化,以提供更精确的自适应指导。
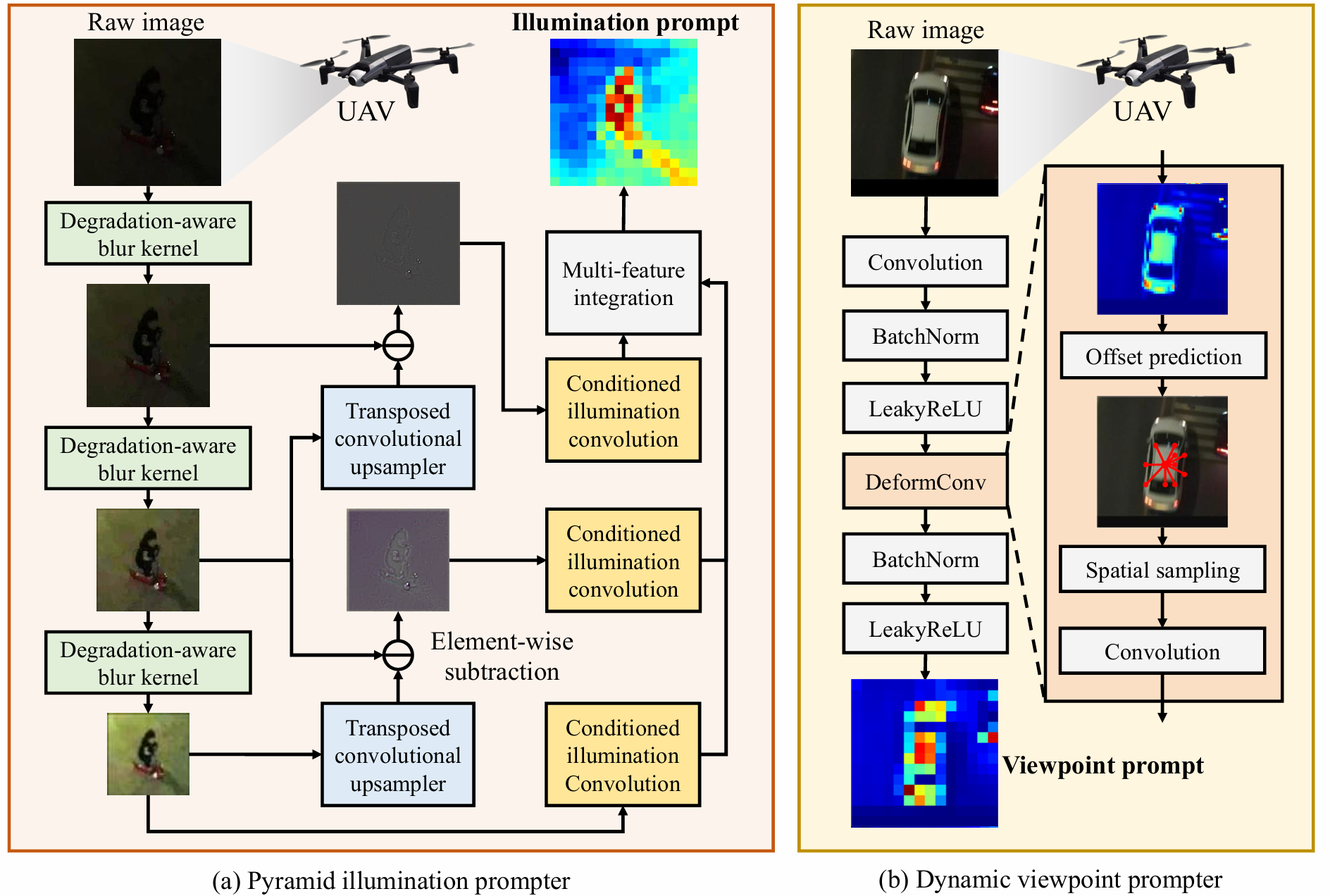
图3. 金字塔光照提示器和动态视点提示器的架构。光照提示器利用可学习的金字塔网络分解图像并聚合多尺度特征,而动态视点提示器结合标准卷积和可变形卷积,自适应捕获无人机视角下的视点信息。图像来自DarkTrack2021 8。
B. 金字塔光照提示器
为学习夜间自适应特征,提出了金字塔光照提示器,以将光照条件全面编码到光照提示令牌中。先前研究19表明,拉普拉斯金字塔的低频层编码了大量光照和对比度相关信息,而拉普拉斯金字塔的中频和高频层则侧重于结构信息。因此,拉普拉斯金字塔特别适合学习光照提示。基于此见解,PIP设计为一种分层架构,以逼近拉普拉斯金字塔结构,如图3所示。构建拉普拉斯金字塔的传统不可学习算子被可学习的卷积组件替代,以提升提示学习能力。
给定原始图像I\mathbf{I}I,PIP采用退化感知模糊核,其权重初始化为逼近高斯模糊核,这保留了手工设计的先验知识,并允许模型自适应地优化特征。PIP构建了一个受高斯金字塔启发的多尺度特征层次,公式化为:
G0=I,Gi+1=DBK(Gi),(5)\mathbf{G}0 = \mathbf{I},\quad \mathbf{G}{i + 1} = DBK(\mathbf{G}_i), \quad (5)G0=I,Gi+1=DBK(Gi),(5)
其中DBK(⋅)DBK(\cdot)DBK(⋅)表示第iii级的可学习退化感知模糊核,Gi\mathbf{G}_iGi表示模糊后的图像。
传统的上采样操作被转置卷积上采样器取代,这使得模型能够在每个尺度上学习更丰富、信息更多的光照表示。通过从对应的高频特征中减去上采样的低频特征来引入残差连接,近似每个尺度的拉普拉斯响应。整个过程公式化为:
Li=Gi−UPi(Gi+1),(6)\mathbf{L}_i = \mathbf{G}i - UP_i(\mathbf{G}{i + 1}), \quad (6)Li=Gi−UPi(Gi+1),(6)
其中UPi(⋅)UP_{i}(\cdot)UPi(⋅)表示第iii级的转置卷积上采样器,Li\mathbf{L}_iLi表示第iii级对应的拉普拉斯分量。
对每个拉普拉斯分量应用条件化的光照卷积层,最终的光照提示Pillu\mathbf{P}_{illu}Pillu通过沿通道维度拼接所有级别的响应生成:
Pillu0=Concat(Conv0(L0),...,Convn(Ln)),(7)\mathbf{P}{illu}^{0} = \mathrm{Concat}(Conv{0}(\mathbf{L}{0}),\ldots ,Conv{n}(\mathbf{L}_{n})), \quad (7)Pillu0=Concat(Conv0(L0),...,Convn(Ln)),(7)
其中Concat(⋅)\mathrm{Concat}(\cdot)Concat(⋅)表示通道级拼接,nnn是总尺度数。
注2: 通过以可学习且可微分的方式模拟拉普拉斯金字塔,PIP有效地捕获了多尺度光照信息。光照提示令牌对于在夜间无人机跟踪场景中使表示适应各种光照条件至关重要。
C. 动态视点提示器
夜间无人机跟踪由于空中视点固有的动态特性,面临显著的几何和语义变化。为解决此问题,引入了一种能够动态捕获几何信息的视点提示器,从而促进特征适应夜间无人机跟踪的动态视点。
如图3所示,动态视点提示器被设计为通过由粗到细的提示生成策略来学习视点提示令牌。最初,DVP采用一个标准卷积层从小的图像块中提取局部特征,捕获作为场景粗略视点提示令牌的空间结构。给定输入图像I\mathbf{I}I,粗略视点提示令牌计算如下:
Pviewc=LR(BN(Conv(I))),(8)\mathbf{P}_{view}^{c} = LR(BN(Conv(\mathbf{I}))), \quad (8)Pviewc=LR(BN(Conv(I))),(8)
其中Pviewc\mathbf{P}_{view}^{c}Pviewc表示粗略视点提示令牌,BNBNBN表示批归一化,LRLRLR表示LeakyReLU激活函数。
DVP随后应用一个可变形卷积层以进一步增强更精细的视点适应性。与具有固定网格采样的标准卷积不同,可变形卷积引入可学习的空间偏移,使得每个核位置能够自适应地从几何相关区域采样。偏移场ΔP∈\Delta P\inΔP∈ R2K×H×W\mathbb{R}^{2K\times H\times W}R2K×H×W,其中KKK是采样点数,由一个偏移生成模块从粗略视点提示令牌Pviewc\mathbf{P}_{view}^{c}Pviewc预测得到,公式化为:
ΔP=OffConv(Pviewc),ΔP={Δp1,Δp2,...,ΔpK},(10)\begin{array}{rl} & {\Delta P = OffConv(\mathbf{P}_{view}^{c}),}\\ & {\Delta P = \{\Delta p_1,\Delta p_2,\ldots ,\Delta p_K\} ,} \end{array} \quad (10)ΔP=OffConv(Pviewc),ΔP={Δp1,Δp2,...,ΔpK},(10)
其中ΔP\Delta PΔP是预测的偏移量,OffConvOffConvOffConv是偏移卷积层。每个Δpi∈R2\Delta p_i\in \mathbb{R}^2Δpi∈R2表示第iii个采样位置的偏移量。
位置p0p_0p0处的可变形卷积计算为:
R(p0)=∑k=1Kwk⋅Pviewc(p0+pk+Δpk),(11)\mathbf{R}(p_0) = \sum_{k = 1}^{K}w_k\cdot \mathbf{P}_{view}^{c}(p_0 + p_k + \Delta p_k), \quad (11)R(p0)=k=1∑Kwk⋅Pviewc(p0+pk+Δpk),(11)
其中p0p_0p0是特征图上的参考空间位置,pkp_kpk表示常规卷积核中预定义的采样位置,wkw_kwk表示第kkk个采样位置的可学习核权重,R(p0)\mathbf{R}(p_0)R(p0)是位置p0p_0p0处的输出特征。
DVP进一步应用批归一化和LeakyReLU激活来生成最终的细粒度视点提示令牌,公式化为:
Pview0=LR(BN(R)),(12)\mathbf{P}_{view}^{0} = LR(BN(\mathbf{R})), \quad (12)Pview0=LR(BN(R)),(12)
其中Pview0\mathbf{P}_{view}^{0}Pview0表示视点提示令牌。
注3: DVP通过由粗到细的优化产生包含丰富几何和语义线索的视点提示令牌。视点提示令牌为在具有挑战性的夜间无人机视点下的特征学习提供了至关重要的自适应指导。
IV. 实验
A. 实现细节
基于现有SOTA通用目标跟踪模型AVTrack 5和OSTrack 20基线开发的模型分别表示为DPTracker-T和DPTracker-B。训练使用混合的白天和夜间目标跟踪数据。白天训练数据包括GOT-10K 29、LASOT 30、COCO 31和TrackingNet 32,而夜间训练数据集包括ExDark 33、Shift 34和BDD100K 35。模型使用分类和回归损失训练30个轮次,采用AdamW 36优化器,在2块NVIDIA A100 GPU上进行。初始学习率设置为0.0004,在第24轮次时衰减10%。
B. 总体性能评估
如表I所示,在三个基准4, 8, 22上进行了实验,将所提出的方法与SOTA跟踪器进行全面评估。提供每个序列第一帧的边界框。
UAVDark135 22是一个广泛认可的基准,专为评估低光照无人机场景下的目标跟踪性能而设计,包含135个视频序列。与相似模型大小的SOTA跟踪器相比,DPTracker-T在所有三个指标上均取得最佳整体性能,精确度为56.8%56.8\%56.8%,归一化精确度为51.8%51.8\%51.8%,成功率为45.6%45.6\%45.6%,超越了其他SOTA轻量级跟踪方法。随着跟踪器规模增大,DPTracker-B以72.3%72.3\%72.3%的精确度、65.2%65.2\%65.2%的归一化精确度和58.1%58.1\%58.1%的成功率,创下了新的最先进结果。与SOTA方法18相比,DPTracker-B在三个指标上分别提升了+2.0%+2.0\%+2.0%、+1.3%+1.3\%+1.3%和+1.0%+1.0\%+1.0%,显示出在鲁棒性和准确性方面的显著增益。如图4所示,可视化结果表明了DPTracker-B在夜间无人机跟踪中的卓越能力。
DarkTrack2021 8是一个权威数据集,包含110个序列,被广泛用于评估夜间条件下的无人机跟踪。与相似大小的跟踪器相比,DPTracker-T在所有三个评估指标上实现了更优性能,达到59.1%59.1\%59.1%精确度、51.9%51.9\%51.9%归一化精确度和46.5%46.5\%46.5%成功率,超过了所有竞争跟踪方法。当扩展到更大跟踪器时,DPTracker-B以69.8%69.8\%69.8%精确度、62.2%62.2\%62.2%归一化精确度和55.8%55.8\%55.8%成功率超越了其他模型。与SOTA跟踪器18相比,DPTracker-B在三个指标上分别实现了+2.7%+2.7\%+2.7%、+2.3%+2.3\%+2.3%和+2.1%+2.1\%+2.1%的相对提升,突显了其在夜间无人机跟踪中的鲁棒性和强适应性。
NAT2021-test 4是一个大规模基准,包含180个视频序列。当与类似规模的跟踪器评估时,DPTracker-T以65.4%65.4\%65.4%的精确度、53.8%53.8\%53.8%的归一化精确度和47.5%47.5\%47.5%的成功率实现了新的最先进性能。随着跟踪器规模增加,DPTracker-B在所有跟踪器中表现最佳,精确度为73.9%73.9\%73.9%,归一化精确度为62.5%62.5\%62.5%,成功率为55.9%55.9\%55.9%。这些一致的提升证实了所提方法在跨各种挑战性场景的夜间无人机跟踪中的有效性。

图4. DPTracker-B与其他顶级跟踪器4, 9, 18, 20, 21的跟踪结果可视化。序列选自UAVDark135 22。所提出的DPTracker-B在多样的夜间无人机跟踪场景下,展现出更鲁棒和精确的跟踪性能。
C. 基于属性的评估
为了进一步研究在不同夜间无人机跟踪挑战下的跟踪鲁棒性,如图5所示,对八个关键因素进行了基于属性的评估:纵横比变化、背景杂乱、相机运动、光照变化、低环境强度、部分遮挡、相似目标和视点变化。DPTracker-T在相似模型规模的跟踪器中实现了最鲁棒的性能,在低环境强度下为44.1%44.1\%44.1%,在光照变化下为44.7%44.7\%44.7%。DPTracker-B也展现了在光照相关挑战下的显著优势,在低环境强度场景下取得最高成功率51.3%51.3\%51.3%,在光照变化场景下为52.9%52.9\%52.9%。除光照鲁棒性外,DPTracker也在其余属性上持续超越其他跟踪器,具有显著优势。这些结果验证了所提方法在应对夜间无人机跟踪场景挑战中的有效性。
D. 消融研究
为研究每个组件的有效性,针对PFI、PIP和DVP,使用两个评估指标进行了消融实验:精确度和成功率,如表II所示。为验证提示驱动特征编码中的PFI模块,将提示替换为图像块嵌入模块。使用PFI带来了+5.3%+5.3\%+5.3%和+4.5%+4.5\%+4.5%的显著相对增益,表明PFI能有效增强夜间无人机跟踪的特征编码。PIP和DVP提供细粒度的优化,进一步校准和打磨学习到的表示。利用PIP进一步在这两个指标上实现了71.9%71.9\%71.9%和57.8%57.8\%57.8%的性能,凸显了其提供多尺度频率感知光照提示的能力。
表 I 在UAVDARK135 22、DARKTRACK2021 8和NAT2021-test 4基准上的跟踪性能比较。所提出的DPTRACKER-B和DPTRACKER-T以显著优势超越其他跟踪器。
| 方法 | 来源 | UAV | UAVDark135 22 | DarkTrack2021 8 | NAT2021-test 4 | 参数量 (M) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec. | Norm.Prec. | Succ. | Prec. | Norm.Prec. | Succ. | Prec. | Norm.Prec. | Succ. | ||||
| SiamAPN 23 | ICRA 21 | ✓ | 42.4 | 39.5 | 30.1 | 41.9 | 37.9 | 30.7 | 55.8 | 41.8 | 33.7 | 15.2 |
| SiamAPN++ 24 | IROS 21 | ✓ | 42.3 | 39.1 | 32.5 | 48.3 | 43.5 | 36.5 | 60.8 | 48.4 | 40.8 | 15.4 |
| TCTrack 25 | CVPR 22 | ✓ | 48.8 | 45.4 | 36.2 | 53.5 | 46.8 | 39.3 | 61.2 | 46.8 | 39.4 | 10.4 |
| TCTrack++ 26 | TPAMI 23 | ✓ | 47.7 | 44.5 | 37.0 | 56.4 | 48.8 | 42.1 | 61.7 | 48.1 | 40.8 | 15.2 |
| AVTrack-ViT 5 | ICML 24 | ✓ | 56.1 | 51.0 | 44.8 | 56.1 | 49.4 | 44.4 | 61.7 | 50.6 | 44.3 | 20.9 |
| DPTracker-T | Ours | ✓ | 56.8 | 51.8 | 45.6 | 59.1 | 51.9 | 46.5 | 65.4 | 53.8 | 47.5 | 21.6 |
| SiamBAN 21 | CVPR 20 | ✓ | 62.1 | 55.3 | 47.5 | 56.9 | 50.3 | 43.1 | 64.7 | 50.9 | 43.7 | 53.9 |
| SiamRPN+±RBO 27 | CVPR 22 | ✓ | 63.3 | 57.6 | 49.5 | 58.5 | 52.9 | 45.2 | 68.2 | 54.8 | 46.9 | 54.0 |
| UDAT-BAN 4 | CVPR 22 | ✓ | 63.3 | 56.6 | 47.9 | 56.4 | 50.0 | 42.1 | 69.4 | 54.6 | 46.9 | 55.1 |
| OSTrack 20 | ECCV 22 | ✓ | 67.8 | 61.6 | 55.0 | 66.0 | 58.9 | 52.9 | 72.2 | 60.9 | 53.9 | 92.1 |
| SAM-DA 9 | ICARM 23 | ✓ | 62.3 | 56.2 | 47.9 | 59.2 | 52.9 | 45.4 | 67.0 | 53.6 | 46.0 | 53.9 |
| SmallTrack 28 | TGRS 23 | ✓ | 65.6 | 52.3 | 44.9 | 56.0 | 49.7 | 42.5 | 65.6 | 52.3 | 44.9 | 53.9 |
| DCPT 18 | ICRA 24 | ✓ | 70.3 | 63.9 | 57.1 | 67.1 | 59.9 | 53.7 | 69.4 | 58.4 | 52.0 | 92.9 |
| DPTracker-B | Ours | ✓ | 72.3 | 65.2 | 58.1 | 69.8 | 62.2 | 55.8 | 73.9 | 62.5 | 55.9 | 94.0 |
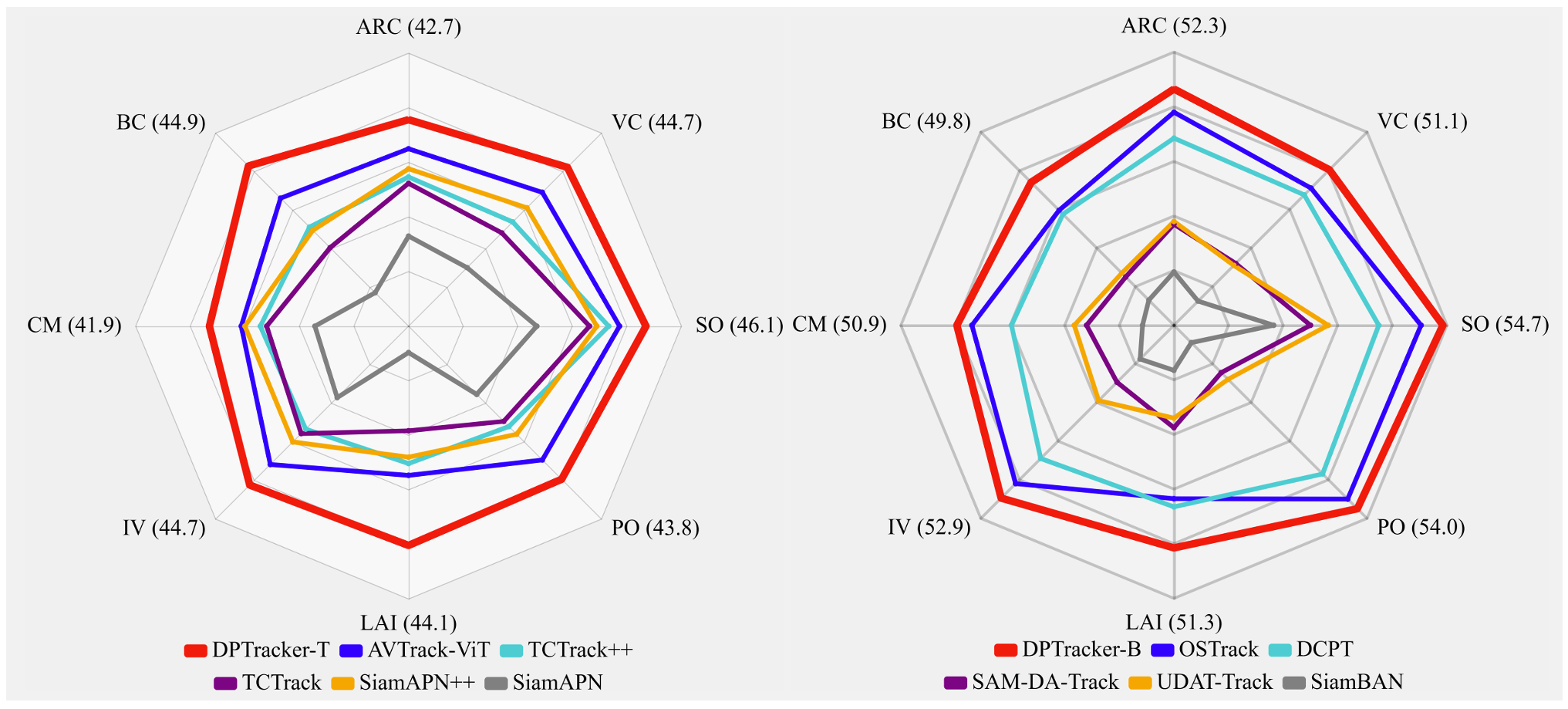
图5. 基于属性的跟踪性能评估。如左图所示,DPTracker-T在NAT2021-test 4的所有8个属性上始终取得最佳性能,超越了其他5个轻量级跟踪器5, 23-26。在右图中,DPTracker-B相比其他表现良好的跟踪器4, 9, 18, 20, 21,也展示了显著的性能提升。
此外,融入DVP在这两个指标上分别取得了72.3%72.3\%72.3%和58.1%58.1\%58.1%的性能,证明了通过使模型能够捕获跨空中视角的视点不变特征,增强了鲁棒性。这些结果证实了PFI、PIP和DVP共同促进了鲁棒的夜间无人机跟踪。
E. 真实世界测试
为评估真实世界性能,一台配备NVIDIA RTX 3080Ti GPU的工作站作为地面控制站。Parrot无人机以每秒10帧的速度捕获图像,并通过WiFi传输至GCS。在初始帧手动初始化目标边界框后,跟踪器保持54 FPS的实时推理速度,便于连续定位目标并将目标位置传回无人机。如图6所示,跟踪性能使用中心位置误差进行评估,低于20的值被视为成功定位。所提出的DPTracker-T展示了在不同的夜间条件下的可靠跟踪。测试1在低环境光照下进行,目标的局部出视野进一步加剧了跟踪难度。测试2的主要挑战是相机运动,它导致了显著的轨迹变化和外观模糊。测试3涉及一个以背景杂乱为特征的街道穿行场景。所提出的跟踪器在具有挑战性的夜间场景下展示了鲁棒的跟踪性能。
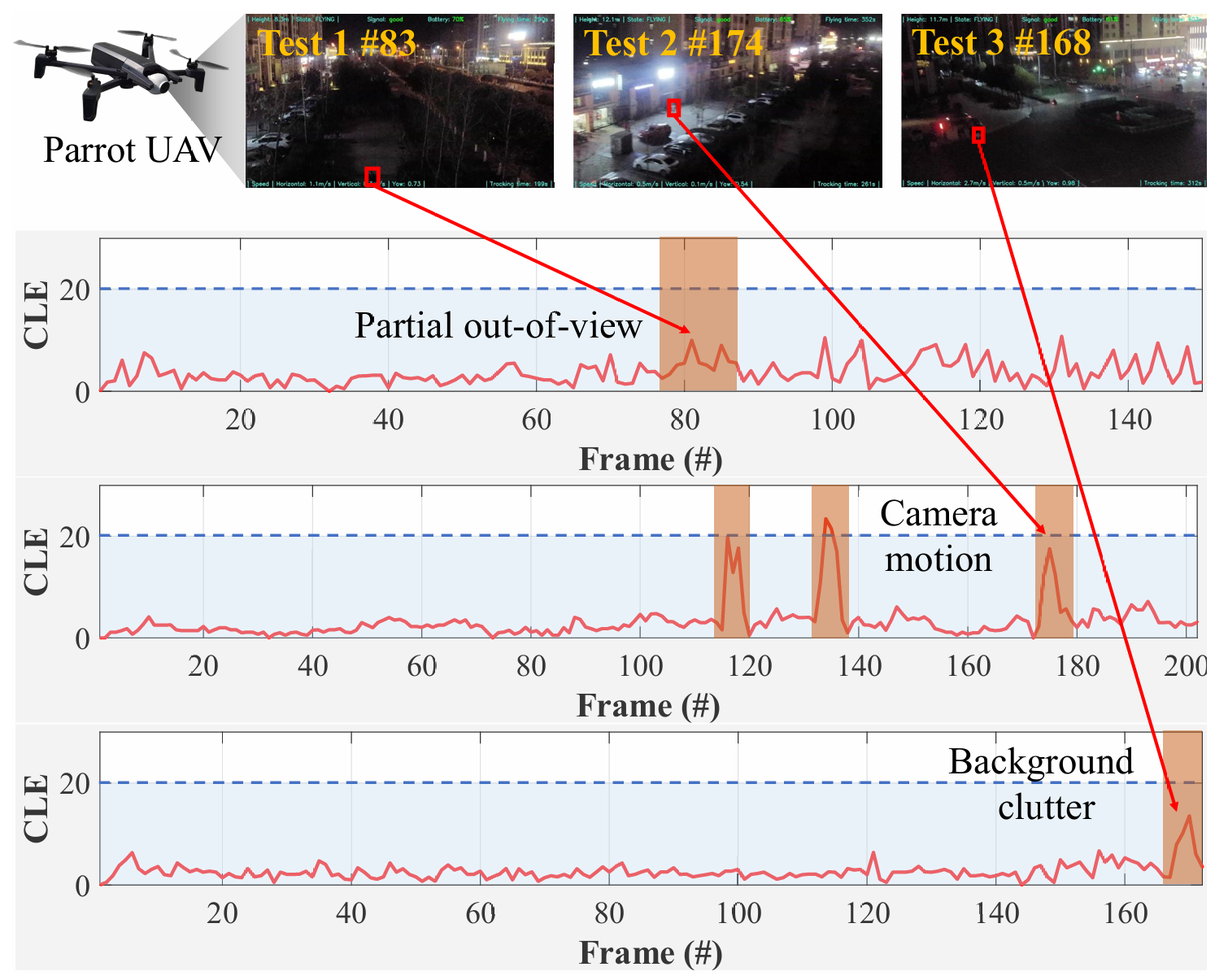
图6. 夜间条件下真实世界无人机跟踪测试。蓝色区域(CLE小于20)被视为成功跟踪情况,而橙色区域代表具有挑战性的跟踪条件。
V. 结论
表 II
关于PFI、PIP和DVP的消融研究。在UAVDARK135上的性能验证了各组件的贡献。
| PFI | PIP | DVP | Prec. (%) | Δ (%) | Suc. (%) | Δ (%) |
|---|---|---|---|---|---|---|
| X | X | X | 67.8 | - | 55.0 | - |
| ✓ | X | X | 71.4 | +5.3 | 57.5 | +4.5 |
| ✓ | ✓ | X | 71.9 | +6.0 | 57.8 | +5.1 |
| ✓ | ✓ | ✓ | 72.3 | +6.6 | 58.1 | +5.6 |
本工作提出了一种双重提示驱动特征编码方法,为夜间无人机跟踪学习光照和视点自适应表示。提示-特征交互在加强提示与视觉特征之间的相互适应以增强表示鲁棒性方面起着核心作用。构建于此交互方法之上,金字塔光照提示和动态视点提示进一步增强了模型适应复杂光照条件和动态视点变化的能力。全面的实验和消融。
参考文献
1 J. Gonzalez-Trejo, D. Mercado-Ravell, I. Becerra, and R. Murrieta-Cid, "On the Visual-Based Safe Landing of UAVs in Populated Areas: A Crucial Aspect for Urban Deployment," IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 7901-7908, 2021.
2 B. Tian, Q. Yao, Y. Gu, K. Wang, and Y. Li, "Video Processing Techniques for Traffic Flow Monitoring: A Survey," in Proceedings of the International IEEE Conference on Intelligent Transportation Systems (ITSC), 2011, pp. 1103-1108.
3 X. Xiao, J. Dufek, T. Woodbury, and R. Murphy, "UAV Assisted USV Visual Navigation for Marine Mass Casualty Incident Response," in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017, pp. 6105-6110.
4 J. Ye, C. Fu, G. Zheng, D. P. Paudel, and G. Chen, "Unsupervised Domain Adaptation for Nighttime Aerial Tracking," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 8896-8905.
5 Y. Li, M. Liu, Y. Wu, X. Wang, X. Yang, and S. Li, "Learning Adaptive and View-Invariant Vision Transformer for Real-Time UAV Tracking," in Proceedings of the International Conference on Machine Learning (ICML), 2024, pp. 28403-28420.
6 A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale," in Proceedings of the International Conference on Learning Representations (ICLR), 2020, pp. 1-22.
7 P. J. Burt and E. H. Adelson, "The Laplacian Pyramid as a Compact Image Code," in Readings in Computer Vision, 1987, pp. 671-679.
8 J. Ye, C. Fu, Z. Cao, S. An, G. Zheng, and B. Li, "Tracker Meets Night: A Transformer Enhancer for UAV Tracking," IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 3866-3873, 2022.
9 C. Fu, L. Yao, H. Zuo, G. Zheng, and J. Pan, "SAM-DA: UAV Tracks Anything at Night with Sam-Powered Domain Adaptation," in Proceedings of the International Conference on Advanced Robotics and Mechatronics (ICARM), 2024, pp. 31-38.
10 C. Fu, Y. Wang, L. Yao, G. Zheng, H. Zuo, and J. Pan, "Prompt-Driven Temporal Domain Adaptation for Nighttime UAV Tracking," in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 9706-9713.
11 X. Li, X. Li, and S. Hu, "DARTer: Dynamic Adaptive Representation Tracker for Nighttime UAV Tracking," in Proceedings of the International Conference on Multimedia Retrieval (ICMR), 2025, pp. 1998-2002.
12 Y. Wu, X. Yang, X. Wang, H. Ye, D. Zeng, and S. Li, "MambaNUT: Nighttime UAV Tracking via Mamba and Adaptive Curriculum Learning," arXiv e-prints:2412.00626, pp. 1-8, 2024.
13 J. Zhu, S. Lai, X. Chen, D. Wang, and H. Lu, "Visual Prompt Multi-Modal Tracking," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 9516-9526.
14 L. Hong, S. Yan, R. Zhang, W. Li, X. Zhou, P. Guo, K. Jiang, Y. Chen, J. Li, Z. Chen et al., "OneTracker: Unifying Visual Object Tracking with Foundation Models and Efficient Tuning," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 19079-19091.
15 Y. Zheng, B. Zhong, Q. Liang, S. Zhang, G. Li, X. Li, and R. Ji, "Towards Universal Modal Tracking with Online Dense Temporal Token Learning," IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1-18, 2025.
16 B. Xu, R. Hou, T. Ren, and G. Wu, "Visual and Memory Dual Adapter for Multi-Modal Object Tracking," arXiv preprint arXiv:2506.23972, pp. 1-12, 2025.
17 J. Zhao, X. Chen, Y. Yuan, M. Felsberg, D. Wang, and H. Lu, "Efficient Motion Prompt Learning for Robust Visual Tracking," arXiv preprint arXiv:2505.16321, pp. 1-18, 2025.
18 J. Zhu, H. Tang, Z.-Q. Cheng, J.-Y. He, B. Luo, S. Qiu, S. Li, and H. Lu, "DCPT: Darkness Clue-Prompted Tracking in Nighttime UAVs," in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 7381-7388.
19 M. Afifi, K. G. Derpanis, B. Ommer, and M. S. Brown, "Learning Multi-Scale Photo Exposure Correction," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 9157-9167.
20 B. Ye, H. Chang, B. Ma, S. Shan, and X. Chen, "Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework," in Proceedings of the European Conference on Computer Vision (ECCV), 2022, pp. 341-357.
21 Z. Chen, B. Zhong, G. Li, S. Zhang, R. Ji, Z. Tang, and X. Li, "SiamBAN: Target-Aware Tracking with Siamese Box Adaptive Network," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 4, pp. 5158-5173, 2022.
22 B. Li, C. Fu, F. Ding, J. Ye, and F. Lin, "All-Day Object Tracking for Unmanned Aerial Vehicle," IEEE Transactions on Mobile Computing, vol. 22, no. 8, pp. 4515-4529, 2022.
23 C. Fu, Z. Cao, Y. Li, J. Ye, and C. Feng, "Siamese Anchor Proposal Network for High-Speed Aerial Tracking," in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 510-516.
24 Z. Cao, C. Fu, J. Ye, B. Li, and Y. Li, "SiamAPN++: Siamese Attentional Aggregation Network for Real-Time UAV Tracking," in Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 3086-3092.
25 Z. Cao, Z. Huang, L. Pan, S. Zhang, Z. Liu, and C. Fu, "TCTrack: Temporal Context for Real-Time UAV Tracking," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 1478-1488.
26 Z. Cao, Z. Huang, L. Pan, S. Zhang, Z. Liu, and C. Fu, "TCTrack++: Strengthened Temporal Context for Real-Time UAV Tracking," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 8, pp. 10316-10333, 2023.
27 D. Guo, J. Wang, Y. Cui, Z. Wang, and S. Chen, "SiamCAR: Siamese Fully Convolutional Classification and Regression for Visual Tracking," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 6269-6277. (注:原文参考文献27为 SiamRPN+±RBO 但出处可能有误,此处按原文翻译)
28 Y. Li, C. Fu, F. Ding, Z. Huang, and G. Lu, "SmallTrack: Wavelet-Enhanced Siamese Network for Small UAV Tracking," IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1-17, 2023, Art no. 5612017.
29 L. Huang, X. Zhao, and K. Huang, "GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 5, pp. 1562-1577, 2021.
30 H. Fan, L. Lin, F. Yang, P. Chu, G. Deng, S. Yu, H. Bai, Y. Xu, C. Liao, and H. Ling, "LaSOT: A High-Quality Benchmark for Large-Scale Single Object Tracking," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5374-5383.
31 T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, "Microsoft COCO: Common Objects in Context," in Proceedings of the European Conference on Computer Vision (ECCV), 2014, pp. 740-755.
32 M. Muller, A. Bibi, S. Giancola, S. Alsubaihi, and B. Ghanem, "TrackingNet: A Large-Scale Dataset and Benchmark for Object Tracking in the Wild," in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 300-317.
33 Y. P. Loh and C. S. Chan, "Getting to Know Low-light Images with the Exclusively Dark Dataset," Computer Vision and Image Understanding, vol. 178, pp. 30-42, 2019.
34 Z. Sun and S. S. Ge, "SHIFT: A Synthetic Hierarchical Object Detection Dataset," in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 14219-14225.
35 F. Yu, H. Chen, X. Wang, W. Xian, Y. Chen, F. Liu, V. Madhavan, and T. Darrell, "BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2636-2645.
36 I. Loshchilov and F. Hutter, "Decoupled Weight Decay Regularization," in Proceedings of the International Conference on Learning Representations (ICLR), 2019, pp. 1-18.