【Python】阿里云 DataWorks + ODPS + 钉钉联动实战:配合🦞全搞定
- 一、背景引言
- 二、整体流程与核心模块
- [三、🦞龙虾 + Python代码实现全流程](#三、🦞龙虾 + Python代码实现全流程)
-
- [1. 本地文件处理](#1. 本地文件处理)
- [2. 终端响应:云连接 ODPS upload 文件](#2. 终端响应:云连接 ODPS upload 文件)
- [3. 云端处理:执行代码SQL or Pyhton](#3. 云端处理:执行代码SQL or Pyhton)
- [4. 结果通知](#4. 结果通知)
-
- [4.1 系统导出](#4.1 系统导出)
- [4.2. 通知到位:打工人的觉悟](#4.2. 通知到位:打工人的觉悟)
- [5. 全流程all in](#5. 全流程all in)
- 五、总结
一、背景引言
今天聊一个很实用的场景:当电脑不在身边,如何用🦞小龙虾配合完成 本地+云端的数据任务流。
背景说明:
今天和朋友A聚餐,他临时收到领导信息,急要根据最新的一份市场信息出最新报告(报告有固定模板),但是电脑不在身边,领导要的急,要么放弃聚餐回公司 -- 太远太累,要么...
小伙伴们是否也遇到同样的情况? 遇到休息时间打扰的领导,怎么办?万一有急事呢又不好耽误...
别急🦞小龙虾来帮你!
二、整体流程与核心模块
咱们来梳理分析下,核心问题和模块链路如下:
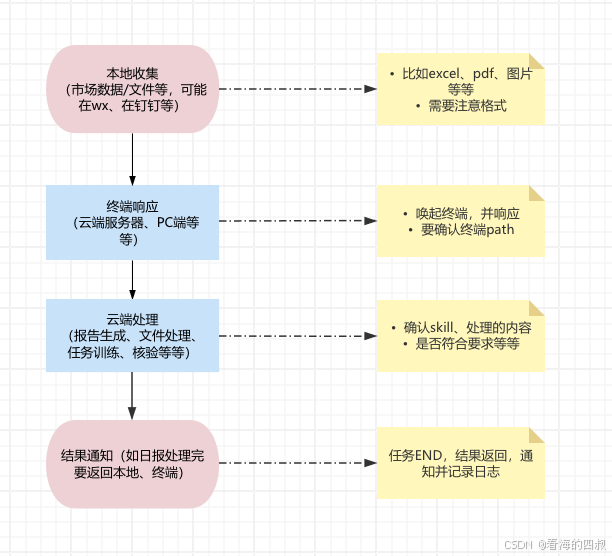
根据链路,涉及的核心工具和服务:
| 模块 | 工具/服务 | 说明 |
|---|---|---|
| 文件处理 | pandas |
读取文件、如Excel/CSV,文件清洗转换等 |
| 数据upload/计算 | pyodps-ALiYun SDK |
连接 ODPS,文件upload、ETL、download等 |
| 终端通知 | requests + sign算法 |
机器人推送 + 指定@通知 |
| 文件操作 | glob、os |
系统os 文件排查 传输等 |
三、🦞龙虾 + Python代码实现全流程
1. 本地文件处理
我们以常见的excel为例,注意:最好先转先转 CSV,因为 ODPS 的 Tunnel 上传接口对 CSV 支持最好,避免遇到编码和格式问题。
用 pandas 读 Excel 再导出 UTF-8 with BOM,确保中文不乱码:
python
import pandas as pd
import glob
import os
def excel_to_csv(input_dir, output_dir):
"""
利用🦞把手机文件传给指定目录,读取目录下指定Excel文件(这里加遍历,解决多个文件的情况),格式转化UTF-8 BOM
"""
# 匹配 xlsx 和 xls 两种格式,解决office和wps的各种问题
excel_files = glob.glob(os.path.join(input_dir, '*.xlsx')) + \
glob.glob(os.path.join(input_dir, '*.xls'))
if not excel_files:
print(f"❌ 四叔,未找到目标文件: {input_dir}")
return []
csv_files = []
for excel_file in excel_files:
try:
df = pd.read_excel(excel_file)
# 转 CSV,utf-8-sig = UTF-8 with BOM,防止 Windows 打开乱码
csv_path = os.path.join(output_dir,
os.path.splitext(os.path.basename(excel_file))[0] + '.csv')
df.to_csv(csv_path, index=False, encoding='utf-8-sig')
csv_files.append(csv_path)
print(f"✅ 四叔,转换完成: {os.path.basename(excel_file)} -> {os.path.basename(csv_path)}")
except Exception as e:
print(f"❌ 四叔,转换失败: {str(e)}")
return csv_files💡 小技巧:Excel 文件可能有合并单元格、多 sheet 等情况,
pandas默认只读第一个 sheet。如果有多 sheet 需求,可以遍历pd.ExcelFile.sheet_names逐个处理。大家可以注意下,细心不会错。
2. 终端响应:云连接 ODPS upload 文件
连接阿里云 ODPS 需要三样东西:AccessKey ID、AccessKey Secret 和project name ,这部分在【Python】Python解决阿里云DataWorks导出数据1万条限制的问题 中已经详细讲过,不再赘述。
python
from odps import ODPS
ACCESS_ID = 'AccessKeyId'
ACCESS_KEY = 'AccessKeySecret'
PROJECT_NAME = 'project name'
ENDPOINT = 'http://service.cn-shanghai.maxcompute.aliyun.com/api'
# 建立连接
odps = ODPS(ACCESS_ID, ACCESS_KEY, PROJECT_NAME, endpoint=ENDPOINT)上传文件之前,先对文件进行处理,再逐个文件写入 ODPS 表,并加上字段映射。这里用的是 ODPS表字段 → Excel列名 的反向映射,保证上传的数据字段名和目标表对齐:
python
# 字段映射:Excel列名 -> ODPS表字段名 这里也可以自定义一个find_column 关键词遍历对比
FIELD_MAPPING = {
'字段1': 'xxx',
'字段2': 'xxx',
'字段3': 'xxx',
'...':'...'
}
def upload_to_odps(odps, csv_files, table_name, field_mapping):
"""
先 TRUNCATE 表确保信息干净,上传 CSV 数据到 ODPS
具体的大家根据情况定义即可
"""
try:
# 清空目标表,防止历史数据残留
print(f"📤 清空表ing {table_name}...")
odps.execute_sql(f"TRUNCATE TABLE {table_name}")
print(f"✅ 四叔,表已清空")
# 逐个 CSV 上传
for csv_file in csv_files:
df = pd.read_csv(csv_file, encoding='utf-8-sig')
# 反转映射
reverse_mapping = {v: k for k, v in field_mapping.items()}
df_renamed = df.rename(columns=reverse_mapping)
# 只保留目标表定义的字段,防止多余列报错
columns_to_keep = [col for col in field_mapping.keys()
if col in df_renamed.columns]
df_final = df_renamed[columns_to_keep]
print(f"📤 正在上传: {os.path.basename(csv_file)}")
odps.write_table(table_name, df_final)
print(f"✅ 上传成功")
return True
except Exception as e:
print(f"❌ 四叔,ODPS 操作失败: {str(e)}")
return False⚠️ 注意:ODPS 上传对字段类型和顺序敏感,字段映射一定要提前确认好,不然容易报
Column xxx not found或类型不匹配的错误。
3. 云端处理:执行代码SQL or Pyhton
upload目标文件后,在 ODPS 里可以执行代码了。代码逻辑根据业务需求来定,并获取执行状态。
python
SQL_SCRIPT = """
XXXXXXX 这里放你的代码 以SQL为例
;
"""
def execute_sql_script(odps, sql_script):
"""
执行 SQL 脚本,完成后获取状态,避免时间等待
"""
try:
instance = odps.execute_sql(sql_script)
instance.wait_for_success() # 阻塞等待 SQL 完成
print(f"✅ 四叔,SQL 执行成功")
return True
except Exception as e:
print(f"❌ 四叔,SQL 执行失败: {str(e)}")
return False🎯 划重点:
wait_for_success()建议加,作为判断代码是否执行的标准,避免队列wait or faile
4. 结果通知
4.1 系统导出
代码执行完后,根据结果导出。因为遇到过特殊情况,这里顺带做了一个字段清洗,处理掉 HTML 标签等非法字符,避免 Excel 打开报格式错误。这部分可以看【Python】Python解决阿里云DataWorks导出数据1万条限制的问题 。
4.2. 通知到位:打工人的觉悟
作为打工人,完成任务更何况是加班完成的,必须通知到群啊!
以钉钉为例:最后一步,推送钉钉群机器人通知。钉钉自定义机器人支持签名验证 机制,需要把当前时间戳 + 密钥做 HMAC-SHA256 签名,具体内容之前在Python Mac 钉钉机器人推送 中也给大家讲过啦。
🔒 安全性提醒:这里还是提醒下,AccessKey 和钉钉 Webhook 地址属于敏感信息,不要硬编码在代码里 。建议放到环境变量或
.env文件中,代码里用os.getenv()读取,防止泄露。
5. 全流程all in
把上面所欲步骤串联起来,就是一个完整的**【Python】阿里云 DataWorks + ODPS + 钉钉联动实战 + 🦞 全流程**。
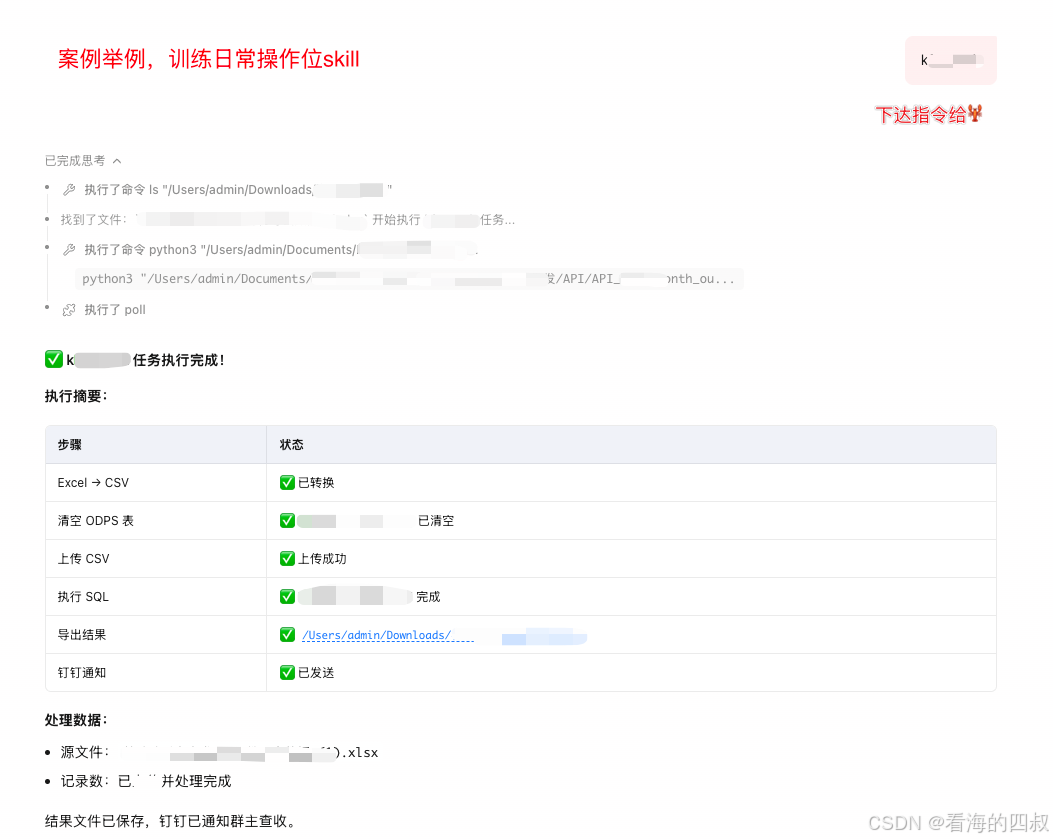
最终只需要一条指令给到🦞,它就能帮你完成以上所有工作。(附案例截图)
🎯 小tips:由于钉钉没法个人直接通过api传输文件,所以最后@完你老板后, 需要借助🦞将文件传到终端。
python
def main():
# 链接云odps
odps = ODPS(ACCESS_ID, ACCESS_KEY, PROJECT_NAME, endpoint=ENDPOINT)
# ① 文件处理
csv_files = excel_to_csv(INPUT_DIR, OUTPUT_DIR)
# ②③ upload文件
upload_to_odps(odps, csv_files, UPLOAD_TABLE_NAME, FIELD_MAPPING)
# ④ 执行代码任务
execute_sql_script(odps, SQL_SCRIPT)
# ⑤ 导出结果
export_from_odps(odps, EXPORT_TABLE_NAME, EXPORT_OUTPUT_DIR, EXPORT_FILENAME)
# ⑥ 系统通知
send_dingtalk_notification(DINGTALK_WEBHOOK, DINGTALK_SECRET, DINGTALK_AT_MOBILE)
print("✅ 四叔,全部流程执行完成!")
if __name__ == '__main__':
main()五、总结
今天咱们把整个链路拆开讲了,朋友A看完操作,直夸666,不带电脑也不怕领导下班打扰了!
当然,AI自动化的前提是:
- 积累才是王道。平时多积累,多学习,才能在关键时候派上用,临时抱佛脚,AI也不是万能的。
- 挖掘场景。多发现业务和生活的场景需求,训练成skills,能达到事半功倍的效果。以后的AI一定是skills的时代。