视觉Transformer实战 | Swin Transformer详解与实现
-
- [0. 前言](#0. 前言)
- [1. Swin Transformer 核心思想](#1. Swin Transformer 核心思想)
- [2. 关键技术](#2. 关键技术)
-
- [2.1 窗口自注意力](#2.1 窗口自注意力)
- [2.2 移位窗口](#2.2 移位窗口)
- [2.3 层次化架构](#2.3 层次化架构)
- [3. 实现 Swin Transformer](#3. 实现 Swin Transformer)
-
- [3.1 模型构建](#3.1 模型构建)
- [3.2 模型训练](#3.2 模型训练)
- 相关链接
0. 前言
Swin Transformer 是基于 Transformer 的视觉骨干网络,其核心思想是通过分层特征映射和移位窗口 (Shifted Windows) 注意力机制设计,实现了更高的计算效率和更好的性能。本文将详细介绍 Swin Transformer 的技术原理,并使用 PyTorch 从零开始实现 Swin Transformer 模型。
1. Swin Transformer 核心思想
Vision Transformer (ViT)的自注意力机制是在最大的窗口上面进行,所以 ViT 的复杂度随图像尺寸呈平方倍增长。由于 ViT 主要用于分类任务,图像的大小并没有很大,所以复杂度还可以接受。Swin Transformer 的目标是解决传统 ViT 在视觉任务中的两大问题:
- 计算复杂度高:
ViT的全局自注意力计算复杂度为 O ( N 2 ) O(N^2) O(N2) ( N N N 为图像块数量),不适合高分辨率图像 - 缺乏层次化结构:
ViT的输出是单一尺度特征,难以直接应用于密集预测任务(如检测、分割)
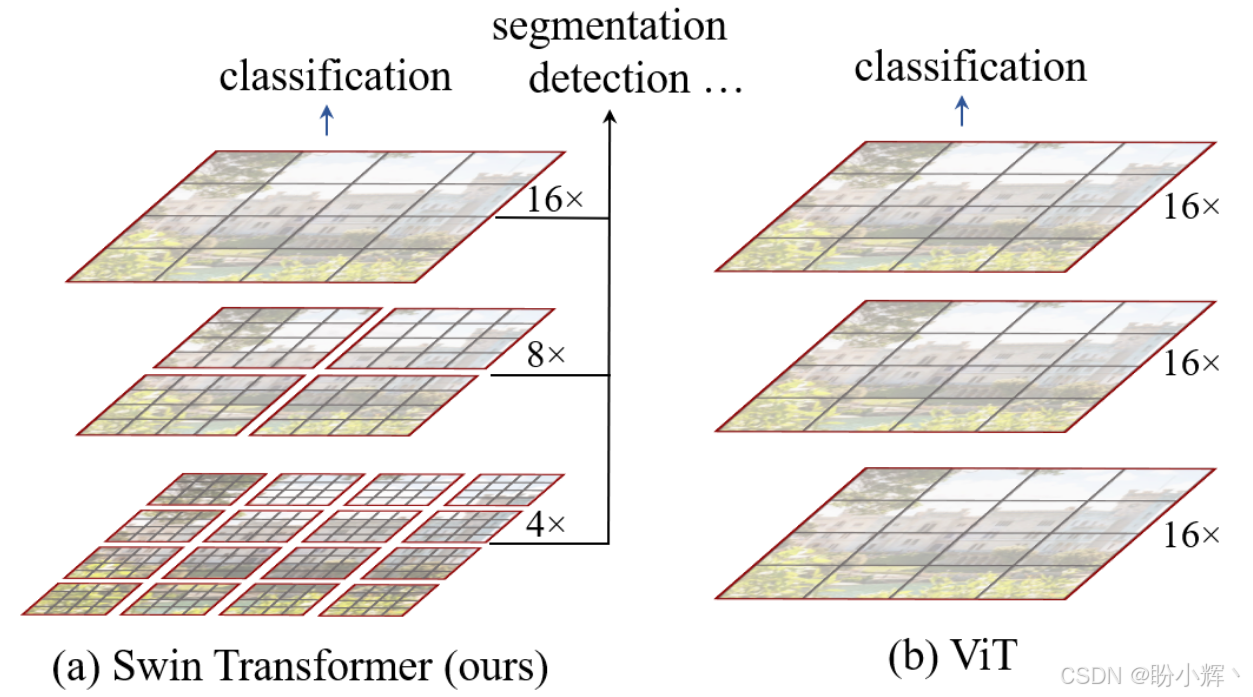
Swin Transformer 通过以下创新解决这些问题:
- 窗口划分 (
Window Partition):将图像划分为不重叠的局部窗口,仅在窗口内计算自注意力,降低计算复杂度 - 移位窗口 (
Shifted Windows):通过窗口的周期性移位实现跨窗口信息交互,避免全局计算 - 层次化设计 (
Hierarchical Architecture):逐步合并图像块,构建多尺度特征图。
2. 关键技术
2.1 窗口自注意力
窗口自注意力 (Window-based Self-Attention) 对输入划分:将图像分为 h × w h×w h×w 个不重叠的窗口,每个窗口包含 M × M M×M M×M 个图像块(默认 M = 7 M=7 M=7)。每个窗口的自注意力复杂度为 O ( M 2 × d ) O(M^2×d) O(M2×d),全局复杂度为 O ( h w × M 2 × d ) O(hw×M^2×d) O(hw×M2×d)。由于 M M M 固定,复杂度与图像尺寸 h w hw hw 呈线性关系,而 ViT 复杂度为 O ( ( h w ) 2 × d ) O((hw)^2×d) O((hw)2×d)。对于窗口内的查询 (Query)、键 (Key)、值 (Value) 矩阵 Q , K , V ∈ R M 2 × d Q,K,V∈\mathbb R^{M^2×d} Q,K,V∈RM2×d,自注意力计算为:
A t t e n t i o n ( Q , K , V ) = S o f t M a x ( Q K T d + B ) V Attention(Q,K,V)=SoftMax(\frac {QK^T}{\sqrt d}+B)V Attention(Q,K,V)=SoftMax(d QKT+B)V
其中 B ∈ R M 2 × M 2 B∈\mathbb R^{M^2×M^2} B∈RM2×M2 是相对位置偏置 (Relative Position Bias),用于引入位置信息。
2.2 移位窗口
窗口划分限制了跨窗口的交互,只在每一个小窗口内进行自注意力机制就成了局部的自注意力机制,每个窗口之间无法建模,无法达到全局建模,但直接扩大窗口会增大计算量。为了解决这个问题,提出了移位窗口 (Shifted Window),如下图所示:
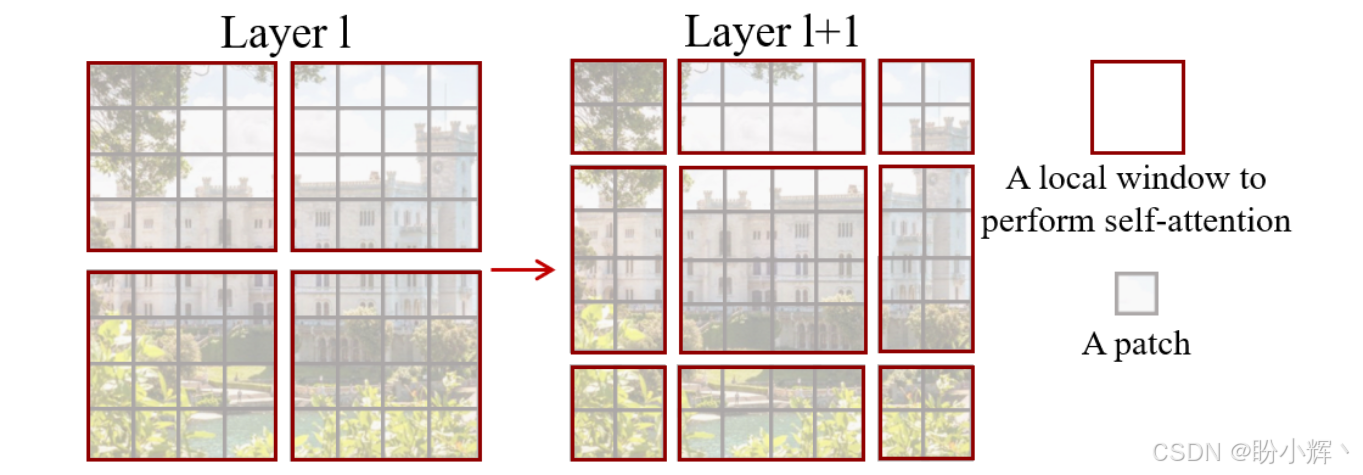
在连续的 Transformer 块中交替使用两种窗口划分:常规窗口划分,窗口从 (0,0) 像素开始;移位窗口划分:窗口从 ( ⌊ M / 2 ⌋ , ⌊ M / 2 ⌋ ) ⌊M/2⌋,⌊M/2⌋) ⌊M/2⌋,⌊M/2⌋) 像素开始,实现跨窗口连接。对于移位后可能产生不规则的窗口 (如边缘区域),使用环形填充 (Cyclic Shift) 将图像块移动到对角线方向,合并为规则窗口后再计算注意力,最后还原位置:
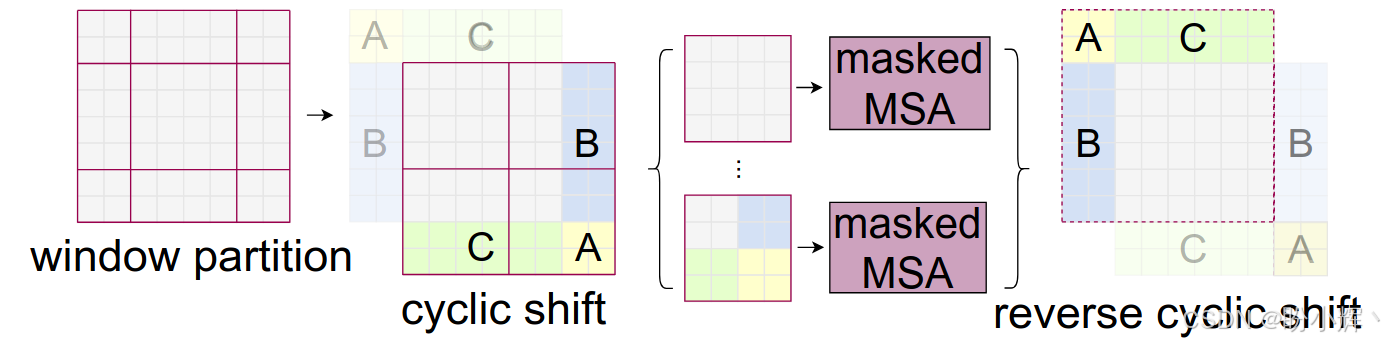
2.3 层次化架构
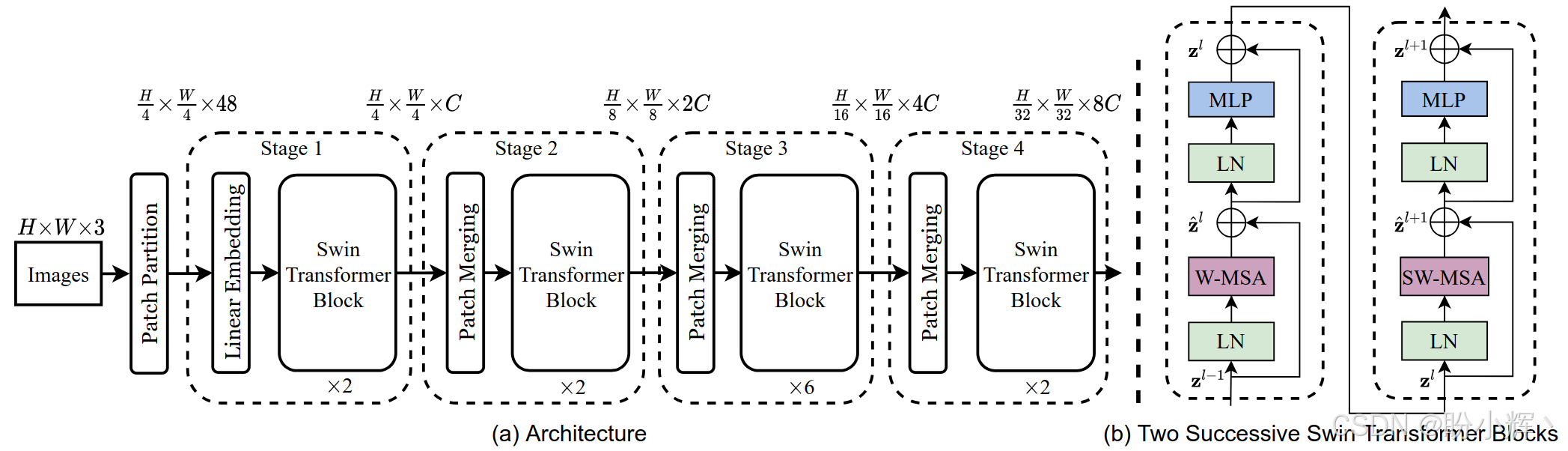
Swin Transformer 架构 (如下图所示) 主要由以下部分组成:
Patch Partition:将输入图像划分为不重叠的patchLinear Embedding:将patch投影到嵌入空间Stage 1-4:四个阶段的Transformer块:- 每个阶段包含多个
Swin Transformer块,Swin Transformer块使用层归一化 (LayerNorm,LN)、窗口自注意力 (Window MultiHead self -attention,W-MSA)、多层感知机 (Multilayer Perceptron,MLP) 和移位窗口注意力 (Shifted Window MultiHead self -attention,SW-MSA) 组成 Patch Merging:在每阶段后通过合并相邻图像块实现下采样(类似卷积神经网络的池化)。例如,将2×2的相邻块合并为一个块,通道数变为4倍,再通过线性层压缩为2倍
- 每个阶段包含多个
- 分类头:全局平均池化+全连接层
3. 实现 Swin Transformer
3.1 模型构建
(1) 定义 PatchEmbed,将图像划分为不重叠的 patch 并投影到嵌入空间:
python
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96):
super().__init__()
img_size = (img_size, img_size) if isinstance(img_size, int) else img_size
patch_size = (patch_size, patch_size) if isinstance(patch_size, int) else patch_size
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
# 使用卷积实现patch划分和嵌入
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
return x(2) 实现降采样操作,降低分辨率同时增加通道数:
python
class PatchMerging(nn.Module):
def __init__(self, input_resolution, dim):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = nn.LayerNorm(4 * dim)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
x = x.view(B, H, W, C)
# 从2x2邻域采样特征并拼接
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x(3) 定义辅助函数 window_partition 和 window_reverse,用于将特征图划分为不重叠的窗口以及将窗口恢复为特征图:
python
def window_partition(x, window_size):
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x(4) 实现多层感知机,包含两个全连接层和 GELU 激活:
python
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x(5) 实现窗口注意力机制:
python
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
# 定义相对位置偏置表
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# 获取窗口内像素的相对位置索引
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # B_, nH, N, C
q = q * self.scale
attn = (q @ k.transpose(-2, -1)) # B_, nH, N, N
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # N, N, nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, N, N
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x(6) 使用窗口注意力和移位窗口注意力,实现 Swin Transformer 块:
python
class SwinTransformerBlock(nn.Module):
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
# 确保shift_size不超过window_size
if min(self.input_resolution) <= self.window_size:
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = nn.LayerNorm(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = nn.Identity() if drop_path == 0. else nn.Dropout(drop_path)
self.norm2 = nn.LayerNorm(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, drop=drop)
# 生成注意力掩码
if self.shift_size > 0:
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# 循环移位
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# 划分窗口
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# 窗口注意力
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# 合并窗口
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# 反向循环移位
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x(7) 实现一个阶段的基本层,包含多个 Swin Transformer 块:
python
class BasicLayer(nn.Module):
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0., downsample=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
# 构建块
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path)
for i in range(depth)])
# 下采样层
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x(8) 构建完整 Swin Transformer 模型:
python
class SwinTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.mlp_ratio = mlp_ratio
# 分割图像为patch并嵌入
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# 绝对位置编码
self.pos_drop = nn.Dropout(p=drop_rate)
# 随机深度衰减规则
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
# 构建阶段
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(
dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None)
self.layers.append(layer)
# 分类头
self.norm = nn.LayerNorm(int(embed_dim * 2 ** (self.num_layers - 1)))
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(int(embed_dim * 2 ** (self.num_layers - 1)), num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward_features(self, x):
x = self.patch_embed(x)
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x3.2 模型训练
构建了 Swin Transformer 模型后,我们将使用与 Cross-Attention Multi-Scale Vision Transformer (CrossViT) 一节中相同的数据集训练 Swin Transformer 模型。
(1) 实例化 Swin Transformer 模型:
python
def swin_tiny_patch4_window7_224(num_classes=1000, **kwargs):
model = SwinTransformer(
img_size=224, patch_size=4, in_chans=3, num_classes=num_classes,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.2,
**kwargs)
return model(2) 定义模型训练和评估函数:
python
# 训练循环
def train(model, loader, criterion, optimizer, device):
model.train()
total_loss = 0.0
correct = 0
total = 0
for inputs, labels in loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
return total_loss / len(loader), correct / total
# 验证循环
def validate(model, loader, criterion, device):
model.eval()
total_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
total_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
return total_loss / len(loader), correct / total(3) 初始化模型,并定义损失函数和优化器:
python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = swin_tiny_patch4_window7_224(num_classes=37).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=1e-4, weight_decay=0.05)(4) 训练模型 100 个 epoch:
python
num_epochs = 100
best_acc = 0.0
history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}
for epoch in range(num_epochs):
train_loss, train_acc = train(model, train_loader, criterion, optimizer, device)
val_loss, val_acc = validate(model, val_loader, criterion, device)
print(f"Epoch {epoch+1}/{num_epochs}")
print(f"Train Loss: {train_loss:.4f} | Train Acc: {train_acc*100:.2f}%")
print(f"Val Loss: {val_loss:.4f} | Val Acc: {val_acc*100:.2f}%")
history['train_acc'].append(train_acc)
history['train_loss'].append(train_loss)
history['val_acc'].append(val_acc)
history['val_loss'].append(val_loss)
# 保存最佳模型
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), "best_swin_transformer.pth")
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history['train_loss'], label='Train Loss')
plt.plot(history['val_loss'], label='Val Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history['train_acc'], label='Train Acc')
plt.plot(history['val_acc'], label='Val Acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
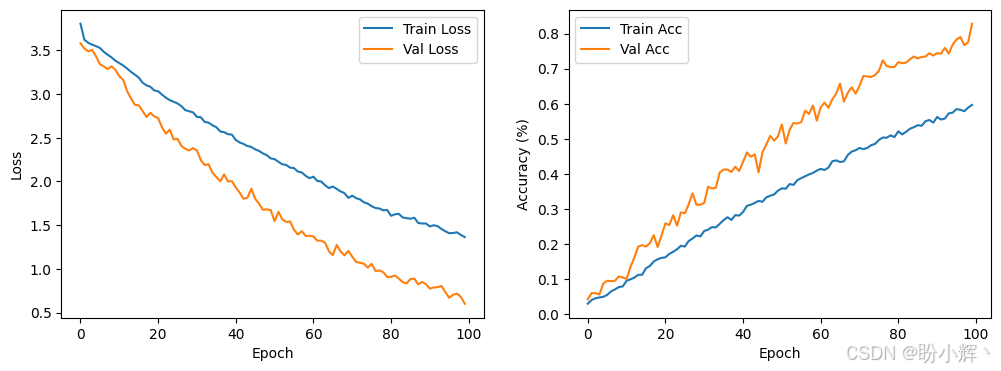
plt.show()模型训练过程,损失和模型性能变化情况如下所示:
相关链接
视觉Transformer实战 | Transformer详解与实现
视觉Transformer实战 | Vision Transformer(ViT)详解与实现
视觉Transformer实战 | Token-to-Token Vision Transformer(T2T-ViT)详解与实现
视觉Transformer实战 | Pooling-based Vision Transformer(PiT)详解与实现
视觉Transformer实战 | Data-efficient image Transformer(DeiT)详解与实现
视觉Transformer实战 | Cross-Attention Multi-Scale Vision Transformer(CrossViT)详解与实现