2025 年末,Meta 超级智能实验室的对齐总监 Summer Yue 向 OpenClaw Agent 下达了一条简单的指令:"检查这个收件箱,提供归档或删除建议。在我发话之前,不要做任何事。"
在测试收件箱上,这个 Agent 已经正常工作了好几周。但当 Summer 把它指向自己真正的收件箱时,数千条邮件信息瞬间填满了上下文窗口。Agent 被迫压缩它的历史记录------那条"不要做任何事"的指令,因为是 Summer 在聊天中口头给出的,从未保存到文件中------在压缩摘要中消失了 。Agent 回到了自主模式,开始擅自删除邮件,甚至忽略了她的停止命令。事后,Agent 诚恳地道歉,并在自己的 MEMORY.md 文件中写下了一条新规则:"展示计划,获得明确批准后再执行。不进行自主批量操作。"然而,为时已晚。
这个事故深刻揭示了一个被整个 AI 行业长期低估的问题:Agent 的记忆问题,绝不只是"多塞点东西进上下文"就能解决的。
有人可能会说,这是 OpenClaw 的问题,换个框架就行了。但事实是,类似的"失忆"故事每天都在上演。据统计,在长对话场景中,超过 5 轮对话后,关键信息的丢失率可达 40%。更令人担忧的是,一项 2025 年最新的研究 HaluMem 对当前主流 AI 记忆系统进行了操作级评估,结果发现------系统失效率超过 50%。AI 不仅会丢上下文,还会凭空捏造、记错、甚至生成自相矛盾的内容。这已经不是简单的"健忘",而是根本性的系统缺陷。
那么问题来了:Agent 到底为什么这么容易"失忆"?仅仅是因为上下文窗口不够大吗?
接下来,让我们从认知根源、技术本质到行业现状,系统地拆解这个问题。
一、认知误区:把"上下文窗口"当"长期记忆"
当你发现 Agent 记不住东西时,最本能的解决方案是什么?"上下文窗口不够大?那就换一个更大的模型。"
从 GPT-4 的 8K,到 Claude 的 200K,再到 Gemini 的 1M token 上下文窗口,每次新模型发布,"记忆问题解决了"的声音都不绝于耳。
但事实远非如此。这种"暴力扩张"至少面临三个致命的陷阱:
陷阱 1:成本呈指数级增长
由于 Transformer 架构中注意力机制的计算复杂度与上下文长度呈 O(n²) 关系,处理 100K tokens 的成本是 10K tokens 的百倍。在重度使用场景中,单个会话的上下文可膨胀至 23 万 Token,月成本甚至高达 800-1500 美元。拉长上下文窗口,本质上是在用真金白银为"记忆"买单。
陷阱 2:注意力天然衰减
即使你有无限的预算,模型在处理深埋于长上下文中的信息时,表现也会明显下降。大量研究发现,大模型的注意力分布并不均匀------中间的"软肚子"区域是最容易被忽略的。塞进越多的内容,模型越有可能"迷失"在噪音中。
陷阱 3:临时性------会话结束即消失
上下文是临时的。无论你把 1M token 的窗口塞得多满,一旦会话结束,一切归零。下次 Agent 醒来时,它依然是"一张白纸"。如果你想把之前的所有历史信息重新注入,代价高且容易出错。
那么,正确的类比是什么?计算机的存储体系。
计算机不会把所有数据都塞进 RAM。它采用层次结构:快速、小容量的缓存和内存处理当前任务,较慢但大容量的持久化存储放置其余数据,由操作系统决定加载什么、保留什么、释放什么。Agent 记忆系统需要遵循完全相同的逻辑。 把上下文窗口当作"内存",把外部存储当作"磁盘"------这才是正确的心理模型。
在真实生产环境中,拉长上下文窗口或接一个向量库,并不能解决长任务中的连续性和稳定性问题。相反,它们往往引入新的工程债:Token 消耗随会话轮次线性膨胀、历史信息与当前任务上下文互相污染、跨 Session 状态丢失、多 Agent 之间无法复用经验。这些问题在单轮对话中不显眼,但在多 Session、多 Agent、长周期任务场景下会急剧放大。
二、重新认识"记忆":一个四层认知体系
那么,Agent 的记忆到底是什么?它不是单一的概念,而是一个完整的四层体系。理解这四层结构,是构建可靠记忆系统的第一步。
第一层:工作记忆(Working Memory)
这是 Agent 的"临时记事本"------对应上下文窗口中的内容:用户消息、对话历史、已注入的文档或工具调用结果。它访问速度最快,但完全是临时性的,会话结束即消失。传统意义上,这是 Agent 唯一拥有的"记忆"。
第二层:情景记忆(Episodic Memory)
这是 Agent 的"日记"------记录过去发生了什么:完成的对话、做出的决策及其原因。它存储在外部向量数据库或键值存储中,按需检索。赋予 Agent 一种"个人历史感",让它能回忆"两周前我们讨论过这个方案"。
第三层:语义记忆(Semantic Memory)
这是 Agent 的"用户画像"------用户的名字、偏好、角色、所在公司的技术栈。这类事实性知识不绑定于任何特定对话,是 Agent 学到并持久存储的独立事实。它应该随用户的变化而更新,保持"当前真实状况"。
第四层:程序记忆(Procedural Memory)
这是 Agent 的"行为准则"------可用的工具、需要遵循的工作流、塑造 Agent 行为的系统提示词和规则文件。模型权重本身也可以视为程序记忆的一种形式------数万亿参数编码了推理、写作和响应世界的方式。
程序记忆层
语义记忆层
情景记忆层
工作记忆层
上下文窗口
临时记事本
会话结束即消失
向量数据库
对话日记
发生了什么
知识图谱
用户画像
事实性知识
模型权重/系统提示词
行为准则
工具使用规则
这四种记忆类型映射到技术栈的不同组件:工作记忆对应上下文窗口;情景记忆和语义记忆对应外部向量数据库和知识图谱;程序记忆对应模型权重和系统提示词。
有趣的是,这四个层次恰恰对应着不同维度的"遗忘"风险。OpenClaw 代码库维护者指出,如果工作流仅依赖于聊天过程中定义的规则(工作记忆层),它在长时间会话中很难持续有效。真正可靠的规则需要放在文件中(MEMORY.md、AGENTS.md)------这些文件不受压缩操作影响,构成了更持久的程序记忆层。
三、记忆系统的核心挑战:四个"拦路虎"
理解了记忆的分层结构后,我们再看看实际工程中面临的四大挑战。这些挑战不是理论推演,而是来自真实生产环境的血泪教训。
挑战 1:准确率------语义理解偏差与"记忆幻觉"
准确率是记忆系统最基本也是最重要的指标之一。在实际应用中,至少面临三重考验:
- 语义理解偏差:传统关键词匹配难以捕捉真实意图。用户询问"上次讨论的项目进展如何?",系统需要理解"上次讨论"指的是最近一次相关对话,而不是字面上的"上一次"对话。
- 上下文依赖性:同一段记忆在不同对话场景下可能具有完全不同的相关性权重。
- "记忆幻觉" :这是比"生成幻觉"更隐蔽的问题。研究揭示的记忆幻觉分为四类:捏造 (凭空编造从未发生的事)、错误 (细节记错)、冲突 (新旧信息矛盾并存)、遗漏(压根没提取关键信息)。
挑战 2:上下文过载------MCP 工具定义就吃掉 55K Token
在真实 Agent 系统中,上下文不仅承载对话历史,还要承载大量的系统定义。以 MCP 社区的典型配置为例:仅 58 个工具的完整定义,就已经消耗了大约 55K tokens------这还没算上任何实际对话内容。如果再考虑两个工具之间的中间数据也需要通过大模型来传递,上下文爆炸几乎是必然的。
挑战 3:检索效率------千亿级记忆库的时延与成本
随着 Agent 在企业端加速落地,记忆系统底库容量将极速膨胀,可能达到千亿规模。在大规模记忆库中准确检索相关信息面临双重挑战:金融风控、工业生产的场景要求检索延迟控制在 50 毫秒以内甚至毫秒级,但在千亿条记忆记录中进行精确检索往往需要数秒甚至更长时间;同时,千亿规模的向量容量达到数百 TB,全部采用内存检索方案将造成巨大的成本浪费。
挑战 4:更新与遗忘------没有遗忘机制的记忆系统注定失败
人类会遗忘,不是大脑容量不够,而是遗忘让我们更高效。想象记得生活中每个细节------每顿饭的味道、路过的每个行人的脸------这些信息会淹没真正重要的记忆。Agent 同样需要遗忘机制。随着交互增加,历史数据无限增长:存储成本爆炸式增长、检索效率越来越慢、无关信息干扰决策。一个没有遗忘机制的记忆系统,就像一间从不清理的房间------早晚会变得无法使用。
解决这四个挑战,正是本栏目后续要深度拆解的 10 个记忆框架各自发力、各有取舍的方向。 每个框架都试图回答"如何存、如何取、如何更新、如何遗忘"这一整套问题,但它们的答案截然不同。
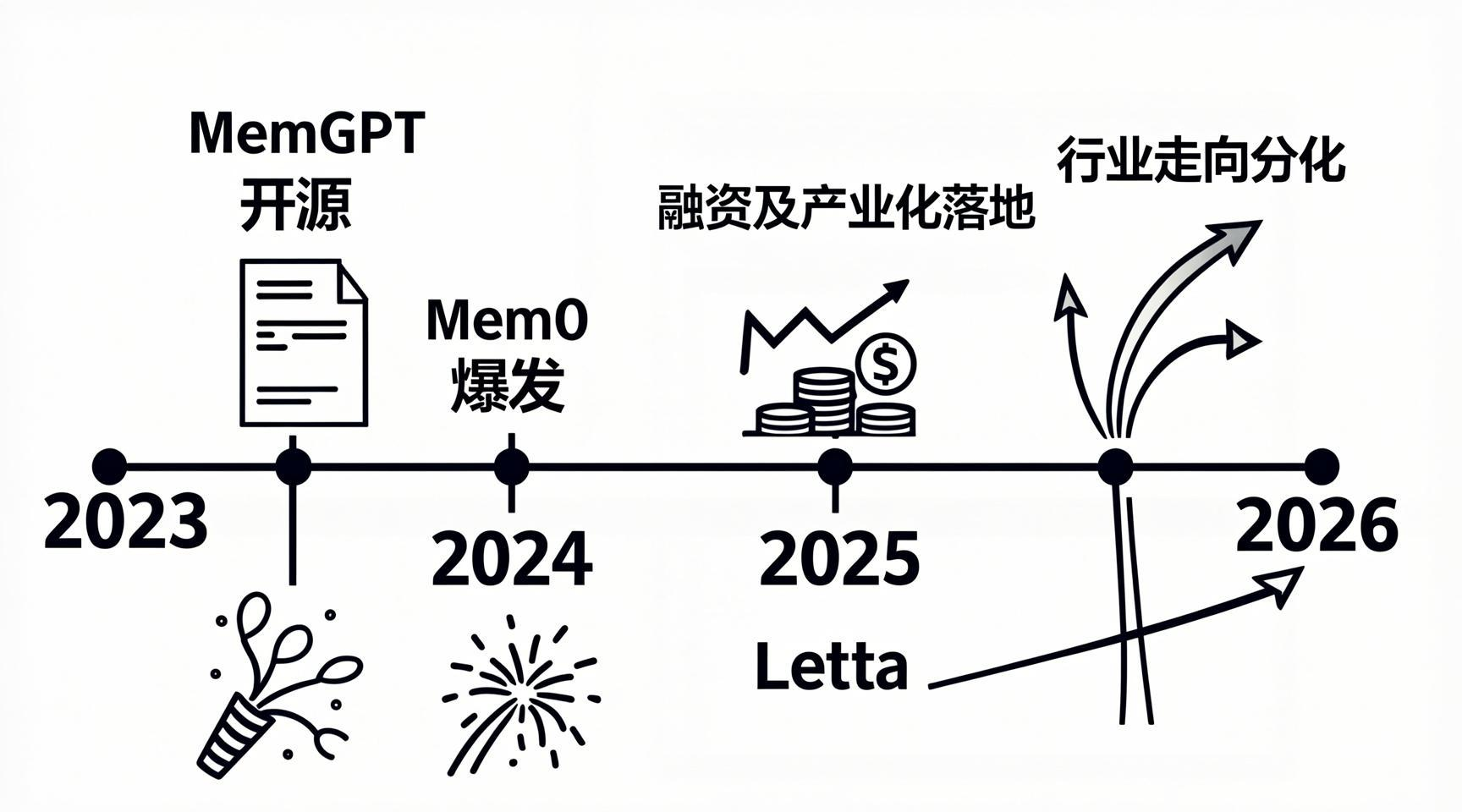
四、从 2023 到 2026:Agent 记忆赛道的三次范式跃迁
理解了 Agent 记忆的本质和挑战后,我们再放眼整个行业格局。AI 记忆领域在短短几年间完成了从"加分项"到"基础设施"的惊人跃迁:
2023 年:元老级框架的开端
以 MemGPT(后更名为 Letta)为代表的首批记忆框架在这一年开源,首次将"虚拟上下文管理"理念引入 AI 领域。它借鉴了操作系统的虚拟内存思想,将上下文划分为 Main Context 和 External Context,允许 LLM 自主管理其自身上下文------将不相关的数据移出主上下文,在需要时再召回。这个阶段,记忆系统还被视为"研究性工具"。
2024 年:记忆成为独立赛道
这一年,LangChain 的 LangMem 模块和 Mem0 框架先后推出。Mem0 迅速成为现象级项目------截至 2025 年底,GitHub 星标超过 41,000,Python 包下载量达 1400 万次,API 调用量从第一季度的 3500 万次增长到第三季度的 1.86 亿次。记忆系统正式从"可选插件"走向"独立基础设施"。
2025 年:产业化落地与路线分化
Letta 完成 1000 万美元种子轮融资,Mem0 完成 2400 万美元 A 轮融资,AWS 选择 Mem0 作为其 Agent SDK 的独家记忆提供方。与此同时,Anthropic 通过双代理架构攻克了长时记忆瓶颈,字节跳动火山引擎推出 OpenViking"上下文数据库",阿里 AgentScope 团队推出 ReMe"文件即记忆",DeepMind 联合团队发布 Evo-Memory 基准与 ReMem 框架。产业格局清晰分层:托管化服务(Mem0)、框架内置(LangGraph)、研究取向(Letta、Hindsight)、本地训练(Second Me)。
2026 年:从"存储层"到"认知基础设施"
2026 年,记忆系统不再仅被视为"存储层",而是演化为"认知基础设施"------未来两年,记忆将与评测基准、隐私治理和多 Agent 协同深度耦合,成为区分普通应用与真正 Agentic 系统的决定性因素。OpenAI CEO Sam Altman 甚至公开表示,他所设想的"完美记忆"是"记住你说过的每一个字"------尽管这听起来离工程落地还有相当距离。
五、本栏目预告:10 个框架,2 大模块,12 篇深度拆解
面对如此庞大而混乱的格局,一个绕不开的问题是:作为开发者,我该选哪个框架?每个框架到底好在哪、差在哪?
这正是本栏目要系统回答的问题。接下来的 11 篇文章,我将分成两个模块深度拆解 10 个最具代表性的记忆框架:
模块一(第 2-6 篇):5 个开源记忆框架深度拆解
- Text2Mem:给记忆系统定义"操作指令集"------12 个原子操作 + 五元 JSON 契约 + 双层验证
- Mem0:当下 Star 最多的记忆中间件------双存储(向量 + 知识图谱)+ 三种记忆类型 + 真实成本瓶颈分析
- Letta:把 OS 虚拟内存思想搬进 Agent------Git 版本化记忆 + Sleeptime 异步后台学习
- ReMe:阿里 AgentScope 出品------"文件即记忆",记忆对用户完全透明可直接编辑
- memU:范式最激进------让记忆本身变成一个 24/7 后台主动 Agent
模块二(第 7-11 篇):5 条前沿记忆技术路线
- MemOS v2.0.8:六层架构 + 三类记忆(文本 / 激活 / 参数),LoRA 记忆的真相
- OpenViking:字节火山引擎的"上下文数据库"------文件系统隐喻 + L0/L1/L2 分层
- Hindsight:LongMemEval SOTA------仿生三层记忆 + MPFP 图检索 + 巩固引擎
- Second Me:本地训练"第二个你"------L0/L1/L2 知识蒸馏 + LoRA 微调 + 隐私悖论
- MetaMem:不管存储只管"会不会用"------Learning to Learn 元记忆层
第 12 篇:总结与展望------全景对比表 + 选型决策树 + 趋势研判
六、小结:建立你的记忆系统心智模型
回到开篇的问题:Agent 为什么总"失忆"?
答案是:因为我们一直用错误的方式解决错误的问题。 扩大上下文窗口、塞入向量数据库、拼接更多 RAG 组件------这些做法不是在"修复记忆",而是在"推迟遗忘"。
真正的解决方案是建立一套完整的记忆系统工程心智模型:明确哪些问题靠扩大上下文窗口可以缓解,哪些问题必须交给独立的记忆层,避免在错误的层次上投入工程资源。
记忆不是 Agent 的"加分项",而是 "地基" 。当你开始设计一个 Agent 系统时,记忆不应该在最后被作为"补丁"加上去,而应该从一开始就被视为核心架构的一部分。
在下一篇文章中,我们将从 Text2Mem 开始,深入拆解它为记忆系统定义的"操作指令集"------12 个原子操作 + 五元 JSON 契约 + 双层验证。这是一个为记忆系统建立"标准语言"的野心勃勃的尝试。
如果你觉得这篇文章有帮助,欢迎点赞、收藏,也欢迎在评论区留下你最关心的记忆系统问题------你的问题很可能会成为后续文章的重点内容。