目录
一、前言
当我们学习机器学习、数据分析或者人工智能时,经常会听到一个词:
PCA
Principal Component Analysis
主成分分析很多教程上来就是一堆公式:
协方差矩阵
特征值
特征向量
降维让人看得云里雾里。
实际上,PCA背后的思想非常简单:
在大量数据中,找到最重要的信息方向,保留这些方向,丢弃不重要的信息。
而这些最重要的方向:
就是主成分(Principal Component)二、什么是主成分
假设我们收集了一批学生的数据:
| 身高 | 体重 |
|---|---|
| 170 | 60 |
| 175 | 65 |
| 180 | 70 |
| 185 | 75 |
如果把这些数据画到坐标系中:
*
*
*
*会发现:
数据并不是随机分布而是沿着某个方向排列。
这个方向:
最能反映数据变化趋势这就是:
第一主成分简单理解:
主成分
=
数据最主要的变化方向三、为什么需要主成分
现实项目中经常遇到:
100个特征
500个特征
1000个特征例如:
用户画像:
年龄
收入
学历
消费金额
浏览记录
点击次数
购买次数
...特征越多:
计算越慢
存储越大
容易过拟合但很多特征其实高度相关。
例如:
身高
腿长通常同时增长。
那么:
保存两个特征
意义不大因此希望:
压缩数据
减少维度
保留主要信息这就是PCA存在的意义。
四、主成分的直观理解
假设数据如下:
身高
体重绘制后:
*
*
*
*
*可以看到:
数据主要沿对角线方向分布因此:
对角线方向
就是第一主成分而垂直方向:
变化很小因此:
信息较少这部分通常会被舍弃。
五、主成分分析(PCA)的核心思想
PCA本质上做了两件事:
第一步
寻找:
数据变化最大的方向得到:
第一主成分第二步
寻找:
与第一主成分垂直
且变化第二大的方向得到:
第二主成分依次类推。
整体流程:
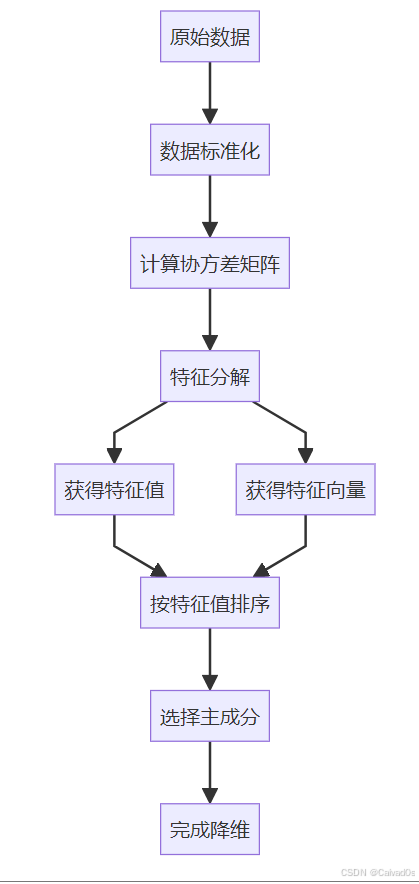
六、主成分和特征值的关系
上一篇文章讲过:
A × v = λ × v其中:
v
特征向量
λ
特征值在PCA中:
特征向量
=
主成分方向而:
特征值
=
该方向的重要程度例如:
特征值:
100
20
5
1说明:
第一个方向最重要因为:
100 >> 20 >> 5 >> 1七、如何选择主成分
假设得到:
特征值:
100
20
5
1总信息量:
100 + 20 + 5 + 1
= 126第一主成分贡献率:
100 / 126
≈ 79%前两个主成分:
(100 + 20) / 126
≈ 95%说明:
前两个主成分
已经保留95%的信息因此:
后两个方向可以舍弃八、PCA为什么能降维
假设原始数据:
100个特征经过PCA:
保留前10个主成分变成:
10个特征这样:
维度降低90%但:
大部分信息仍然保留因此:
训练速度更快
存储更少
泛化能力更强九、Python实现PCA
安装依赖:
pip install scikit-learn导入数据:
python
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
print(X.shape)输出:
(150,4)表示:
150条数据
4个特征进行PCA降维:
python
from sklearn.decomposition import PCA
pca = PCA(
n_components=2
)
X_new = pca.fit_transform(X)
print(X_new.shape)输出:
(150,2)说明:
4维
↓
2维成功降维。
十、查看主成分
查看主成分方向:
python
print(
pca.components_
)输出类似:
[
[0.36 0.08 0.85 0.35]
[-0.65 -0.73 0.17 0.07]
]每一行:
代表一个主成分十一、查看解释方差比例
查看信息保留率:
python
print(
pca.explained_variance_ratio_
)输出:
[0.92 0.05]表示:
第一主成分
保留92%信息
第二主成分
保留5%信息总计:
97%说明:
2个主成分
已经代表原始数据十二、PCA的应用场景
图像压缩
原始图片:
1920 × 1080数据量巨大。
利用PCA:
保留主要信息
压缩图片人脸识别
经典算法:
EigenFace就是利用:
PCA提取主要特征。
数据可视化
例如:
100维数据无法直接观察。
通过PCA:
100维
↓
2维即可绘图展示。
机器学习预处理
训练模型前:
删除冗余特征
减少噪声
降低维度提升训练效率。
十三、PCA的优点
降低维度
减少特征数量提高训练速度
减少计算量去除噪声
保留主要信息
舍弃次要信息防止过拟合
减少无关特征十四、PCA的缺点
可解释性下降
降维后:
主成分
不再对应具体业务字段信息损失
降维过程中:
部分信息被舍弃只适合线性关系
复杂非线性问题:
效果有限十五、总结
主成分分析(PCA)是机器学习和数据分析中最重要的降维方法之一。
核心思想:
寻找数据变化最大的方向
↓
保留这些方向
↓
舍弃不重要方向
↓
完成降维其中:
主成分
=
数据最重要的变化方向而:
特征值
=
该方向的重要程度可以这样理解:
原始数据
像一堆杂乱信息
PCA
帮助我们找到最重要的信息主干因此,无论是机器学习、图像处理、推荐系统还是数据可视化,PCA都是必须掌握的经典算法之一。