本文是 2022 年 WWW 会议(CCF A 类顶会)发表的加密流量分类领域里程碑式论文,首次针对加密流量特性设计了专属 Transformer 预训练架构,在 VPN/Tor/TLS1.3 等高隐蔽加密流量分类任务上实现了 SOTA 突破,尤其对工业界 VPN 检测落地具有极强的指导价值。
标题与作者信息
原文标题:ET-BERT: A Contextualized Datagram Representation with Pre-training Transformers for Encrypted Traffic Classification
直译 :ET-BERT:面向加密流量分类的、基于预训练 Transformer 的上下文感知数据报表示模型核心解读:
- 模型命名 ET-BERT,全称
Encrypted Traffic Bidirectional Encoder Representations from Transformer,对标 NLP 领域的 BERT,做了加密流量领域的原生适配。 - 核心创新点:上下文感知的数据报级表示 、流量专属预训练任务 、预训练 + 微调的两阶段范式,解决了传统加密流量分类方法泛化性差、依赖大量标注数据、无法适配新型加密协议的核心痛点。
作者与单位:中国科学院信息工程研究所、中国科学院大学网络空间安全学院,均为国内网络安全领域顶尖科研机构,研究成果具备极强的工程落地性与学术权威性。
摘要(ABSTRACT)逐句精读
-
Encrypted traffic classification requires discriminative and robust traffic representation captured from content-invisible and imbalanced traffic data for accurate classification, which is challenging but indispensable to achieve network security and network management.
- 逐句解读:加密流量分类需要从内容不可见、数据分布不平衡的流量数据中,提取具备区分度和鲁棒性的流量表示,才能实现精准分类;这一任务极具挑战,同时也是网络安全与网络管理不可或缺的核心能力。
- 核心价值:点明了加密流量分类的两大核心痛点 ------载荷加密无明文 、真实场景数据长尾不平衡,也是传统方法的核心瓶颈。
-
The major limitation of existing solutions is that they highly rely on the deep features,which are overly dependent on data size and hard to generalize on unseen data.
- 逐句解读:现有方案的核心局限在于,高度依赖深度特征,而这类特征过度依赖标注数据规模,在未见过的未知数据上泛化能力极差。
- 核心价值:精准指出了传统监督深度学习方法的致命缺陷 ------ 对标注数据量要求极高,新型 VPN / 加密协议出现后,模型直接失效。
-
How to leverage the open-domain unlabeled traffic data to learn representation with strong generalization ability remains a key challenge.
- 逐句解读:如何利用开放域无标注流量数据,学习具备强泛化能力的流量表示,仍是该领域的核心挑战。
- 核心价值:提出了本文要解决的核心科学问题,也是预训练范式的核心优势 ------ 用海量无标注数据学习通用表示,摆脱对标注数据的强依赖。
-
In this paper, we propose a new traffic representation model called Encrypted Traffic Bidirectional Encoder Representations from Transformer (ET-BERT), which pre-trains deep contextualized datagram-level representation from large-scale unlabeled data.
- 逐句解读:本文提出了全新的流量表示模型 ET-BERT,能够从大规模无标注数据中,预训练得到深度上下文感知的数据报级流量表示。
- 核心价值:提出了模型核心框架,首次将预训练范式原生适配到加密流量分类场景,而非直接套用 NLP 的 BERT 模型。
-
The pre-trained model can be fine-tuned on a small number of task-specific labeled data and achieves state-of-the-art performance across five encrypted traffic classification tasks, remarkably pushing the F1 of ISCX-VPN-Service to 98.9% (5.2%↑), Cross-Platform (Android) to 92.5% (5.4%↑), CSTNET-TLS 1.3 to 97.4% (10.0%).
- 逐句解读:预训练完成的模型,仅需少量任务专属的标注数据微调,就能在 5 个加密流量分类任务上达到 SOTA 效果;其中,VPN 流量分类数据集 ISCX-VPN-Service 的 F1 值提升至 98.9%,相对之前 SOTA 提升 5.2 个百分点;安卓跨平台应用分类提升 5.4 个百分点;TLS1.3 加密流量分类提升 10 个百分点。
- 核心价值:给出了模型的核心性能指标,尤其在 VPN 检测场景实现了突破性提升,完美匹配用户的 VPN 检测需求;同时证明了模型在新型加密协议(TLS1.3)上的超强适配能力。
-
Notably, we provide explanation of the empirically powerful pre-training model by analyzing the randomness of ciphers. It gives us insights in understanding the boundary of classification ability over encrypted traffic.
- 逐句解读:值得注意的是,本文通过分析密码算法的随机性,为预训练模型的优异效果提供了理论解释,为理解加密流量分类能力的边界提供了理论洞察。
- 核心价值:区别于纯工程类论文,本文不仅做了效果提升,还从密码学底层解释了 "为什么加密流量能被分类",为模型提供了理论支撑。
-
The code is available at: https://github.com/linwhitehat/ET-BERT.
- 核心价值:论文开源了完整代码,可直接复现、二次开发,为工业界落地提供了直接的工程参考。
1. 引言(INTRODUCTION)逐句精读
1.1 研究背景与痛点
-
Network traffic classification, aiming to identify the category of traffic from various applications or web services, is an important technique in network management and network security 4, 34.
- 解读:网络流量分类的目标是识别不同应用 / 服务的流量类别,是网络管理与安全的核心技术,明确了研究的应用场景。
-
Recently, traffic encryption has been widely utilized to protect the privacy and anonimity of Internet users. However, it also brings great challenges to traffic classification since the malware traffic and the cybercriminals can evade the surveillance system by privacyenhanced encryption techniques, such as Tor, VPN, etc.
- 解读:流量加密广泛用于用户隐私保护,但也给流量分类带来巨大挑战 ------ 恶意流量、网络犯罪可通过 VPN、Tor 等强加密技术规避监控,直接点明了 VPN 检测的现实合规需求。
-
Traditional methods capture patterns and keywords in the data packets from the payload, called deep packet inspection (DPl), fail to apply to the encrypted traffic.
- 解读:传统 DPI 方法依赖载荷中的明文模式和关键词,完全无法适用于加密流量,对应之前调研的规则型检测的核心局限。
-
Furthermore, due to the rapid development of encryption technology, traffic classification methods for a specific kind of encrypted traffic cannot adapt well to the new environment or unseen encryption strategies 29.
- 解读:加密技术快速迭代,针对特定加密流量的分类方法,无法适配新环境、未知加密策略,泛化能力差。
-
Therefore, how to capture the implicit and robust patterns in the diverse encrypted traffic and support accurate and generic traffic classification is essential to achieve high network security and effective network management.
- 解读:再次点明核心研究目标 ------ 在多样化加密流量中捕捉隐式、鲁棒的模式,实现精准、通用的流量分类,是网络安全与管理的核心需求。
1.2 现有方法演进与缺陷
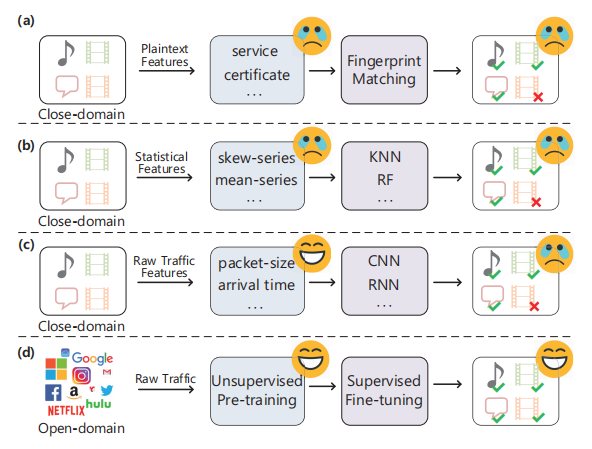
论文将加密流量分类方法分为 4 代,对应 Figure 1 的四类方案:
-
第一代:明文指纹匹配(Figure 1 (a))
- 原文:Early works 37 leverage the remaining plaintext in the encrypted traffic (e.g. certificates) to construct the fingerprint and conduct fingerprint matching for classification. However, these methods are not applicable to the newly emerging encrypted techniques (e.g. TLS 1.3) since the plaintext becomes more sparse or obfuscated.
- 解读:利用加密流量中剩余的明文(如 TLS 证书、JA3 指纹)构建指纹库匹配;缺陷是面对 TLS1.3 等新型加密技术,明文越来越少,完全失效。
-
第二代:统计特征 + 传统机器学习(Figure 1 (b))
- 原文:To this end, some works 27, 36 extract the statistical feature and employ classical machine learning algorithms to handle the encrypted traffic without plaintext. These methods highly rely on expert-designed features and have limited generalization ability.
- 解读:提取包长、包间隔等统计特征,用随机森林 / XGBoost 等机器学习模型分类;缺陷是高度依赖专家设计的人工特征,新加密协议出现后,特征直接失效,泛化能力差。
-
第三代:监督深度学习(Figure 1 (c))
- 原文:Recently, deep learning methods 21, 22 automatically learn complicated patterns from the raw traffic, and achieve remarkable performance improvement. However, these methods highly rely on the amount and distribution of labelled training data, which is easy to cause model bias and hard to adapt to newly emerged encryption.
- 解读:用 CNN/RNN 等深度学习模型,从原始流量中自动学习特征,无需人工特征工程;缺陷是高度依赖标注数据的数量和分布,容易产生模型偏差,无法适配新出现的加密技术,小样本场景效果极差。
-
第四代:预训练范式(Figure 1 (d),本文方案)
- 原文:Pre-training based methods adopt large unlabeled data to learn the unbiased data representations. Such data representations can be easily transferred to the downstream tasks by fine-tuning on limited amount of labeled data. In the field of encrypted traffic classification, the most recent work 13 directly applies the pre-training technique and obtains obvious improvement on VPN traffic classification, but it lacks a pre-training task designed for traffic and a reasonable input representation to demonstrate the effect of the pre-training model.
- 解读:预训练方法用大规模无标注数据学习无偏的通用表示,仅需少量标注数据微调就能迁移到下游任务;现有预训练工作(PERT)直接套用 NLP 模型,没有针对流量特性做专属设计,限制了泛化能力,这也是本文要解决的核心问题。
1.3 本文核心贡献
论文明确了 3 大核心贡献:
- 提出了面向加密流量分类的预训练框架,利用大规模无标注加密流量,学习通用的数据报级表示,适配一系列加密流量分类任务。
- 设计了两个流量专属的自监督预训练任务:掩码 BURST 模型(MBM)、同源 BURST 预测(SBP),同时捕捉字节级和 BURST 级的上下文关联,学习通用流量表示。
- 模型在 5 大类加密流量分类任务上达到 SOTA 效果,包括 VPN 流量分类、Tor 流量分类、TLS1.3 流量分类等,相比现有工作最大提升 10 个百分点;同时通过密码算法随机性分析,为模型效果提供了理论解释。
2. 相关工作(RELATED WORK)逐句精读
2.1 加密流量分类相关研究
论文将现有加密流量分类研究分为 3 类,并逐一指出其缺陷:
- 指纹构建方法:代表工作 FlowPrint,利用证书、设备、时间特征构建指纹;缺陷是指纹在 VPN 等虚拟网络中极易被篡改,且依赖明文信息,TLS1.3 场景下失效。
- 统计机器学习方法:代表工作 AppScanner、CUMUL、BIND,利用人工设计的统计特征训练传统机器学习模型;缺陷是难以设计通用特征,无法适配海量复杂应用,泛化能力差。
- 监督深度学习方法:代表工作 DF、FS-Net、Deeppacket,用 CNN/RNN 从原始流量中自动学习特征;缺陷是依赖大量标注数据,在不平衡数据中学习到有偏表示,小样本场景效果差。
2.2 预训练模型相关研究
- 预训练模型在 NLP、CV 领域取得了巨大突破,核心优势是利用无标注数据学习鲁棒的特征表示,在少量标注数据下就能适配下游任务。
- 加密流量领域的首个预训练工作 PERT,直接将 ALBERT 迁移到加密流量分类,在 VPN 数据集上取得了一定效果,但没有针对流量特性设计专属的输入表示和预训练任务,在 TLS1.3 等新型加密协议上泛化能力极差。
- 底层理论支撑:虽然加密载荷没有语义,但不同密文之间存在随机性差异,加密流量并非完全随机,存在隐式模式,这是预训练模型能学习到有效表示的底层基础。
3. ET-BERT 模型核心架构逐句精读
3.1 整体架构
- 模型采用 **「预训练 + 微调」两阶段核心架构 **:
- 预训练阶段:用大规模无标注加密流量,学习通用的、上下文感知的数据报级表示;
- 微调阶段:针对特定下游任务(如 VPN 分类),用少量标注数据微调全模型参数,适配目标任务。
- 加密流量与自然语言的核心差异:无人类可理解的语义,无显式语义单元,因此不能直接套用 BERT,必须做原生适配。
- ET-BERT 的三大核心创新组件:
- Datagram2Token 模块:将加密流量转换为保留传输模式的类语言 token,作为模型输入;
- 两个流量专属预训练任务:MBM 和 SBP,从传输上下文(而非语义上下文)中学习流量表示;
- 两种微调策略:包级微调、流级微调,适配不同粒度的分类场景。
- 模型主干配置:12 层 Transformer 块,每个自注意力层 12 个注意力头,token 嵌入维度 768,最大输入长度 512,与 BERT-base 配置一致,兼顾效果与工程落地性。
3.2 Datagram2Token 流量表示方法
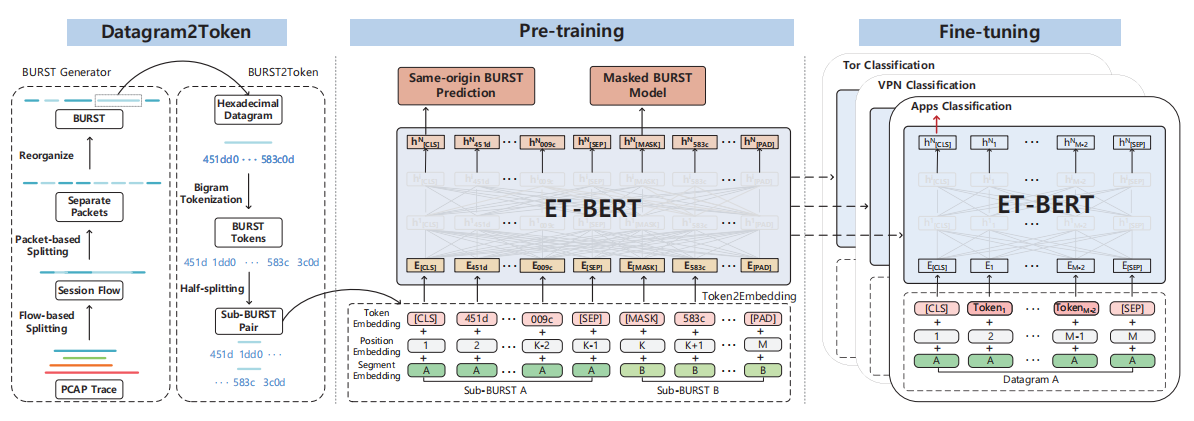
该模块是模型的输入基础,核心解决 "如何将二进制加密流量转换为 Transformer 可处理的 token 序列" 的问题,分为 3 个步骤:
3.2.1 BURST 生成器(BURST Generator)
- BURST 定义:单一会话流中,来自同一方向(客户端→服务端 / 服务端→客户端)、时间相邻的网络数据包集合。
- 底层逻辑:Web 应用的 DOM 结构、内容加载顺序(文本→图片→视频),会直接体现在网络传输的 BURST 结构中,不同应用 / 协议的 BURST 结构存在本质差异,是加密流量的核心隐式特征。
- 数学定义:先通过五元组(源 IP / 端口、目的 IP / 端口、协议)拆分出单一会话流,再将流拆分为单向的 BURST 集合,公式如下:BURST =\left\{ \begin{array} {l}{B^{src}=\{ p_{m}^{src},m\in \mathbb {N}^{+}\} }\\ {B^{dst}=\{ p_{n}^{dst},n\in \mathbb {N}^{+}\right\} \end{array} \right.其中,Bsrc是源到目的的 BURST,Bdst是目的到源的 BURST,m/n 是对应方向的最大单向包数量。
3.2.2 BURST2Token
- 核心目标:将二进制 BURST 转换为固定字典的 token 序列。
- 编码方式:采用二元语法(bi-gram) 编码十六进制的 BURST 序列,每个单元由相邻的两个字节组成;再通过字节对编码(BPE)生成 token,token 取值范围 0-65535,字典大小 65536,完美适配两个字节的所有可能取值。
- 特殊 token 设计(与 BERT 对齐,适配预训练任务):
[CLS]:分类标记,序列第一个 token,最终隐藏状态用于表示整个序列,完成分类任务;[SEP]:分隔标记,用于分隔两个子 BURST;[PAD]:填充标记,将序列补齐到固定长度 512;[MASK]:掩码标记,用于 MBM 预训练任务。
- 预处理:将一个 BURST 平均拆分为两个子 BURST(sub-BURST A/B),用
[SEP]分隔,为 SBP 预训练任务做准备。
3.2.3 Token2Embedding
- 每个 token 的最终表示,由三个嵌入向量相加得到,维度均为 768:
- Token 嵌入:来自 token 查找表,表示 token 本身的字节模式特征;
- 位置嵌入:表示 token 在序列中的位置信息,捕捉流量的时序关联;
- 片段嵌入:区分 token 属于 sub-BURST A 还是 sub-BURST B,适配 SBP 预训练任务。
- 微调阶段,将单个包或单条流表示为一个片段,输入模型完成分类。
3.3 预训练阶段:两个流量专属自监督任务
预训练的总损失为两个任务的损失之和:L=LMBM+LSBP,同时优化两个任务,让模型同时学习字节级上下文关联和 BURST 级传输结构关联。
3.3.1 掩码 BURST 模型(Masked BURST Model, MBM)
- 核心目标:捕捉同一个 BURST 内,不同数据报字节之间的上下文依赖关系,对标 BERT 的掩码语言模型(MLM),但适配流量特性。
- 实现方式:输入序列中的每个 token,有 15% 的概率被随机掩码;被选中的 token,80% 替换为
[MASK],10% 替换为随机 token,10% 保持不变。 - 训练目标:模型需要基于上下文,预测掩码位置的原始 token,学习双向上下文表示。
- 损失函数:负对数似然损失,公式如下:LMBM=−∑i=1klog(P(MASKi=token∣X;θ))其中,θ是模型可训练参数,X是掩码后的输入表示,MASKi是第 i 个位置的掩码 token。
3.3.2 同源 BURST 预测(Same-origin BURST Prediction, SBP)
- 核心目标:捕捉 BURST 内部的传输结构关联,学习前后子 BURST 之间的依赖关系,对标 BERT 的下一句预测(NSP),但针对流量传输特性做了专属设计。
- 实现方式:二分类任务,输入两个子 BURST,预测它们是否来自同一个原始 BURST;50% 的概率输入同源的连续子 BURST(正样本),50% 的概率输入来自不同 BURST 的随机子 BURST(负样本)。
- 训练目标:模型需要判断两个子 BURST 是否同源,学习流量传输的结构模式。
- 损失函数:负对数似然损失,公式如下:LSBP=−∑j=1nlog(P(yj∣Bj;θ))其中,Bj是子 BURST 对,yj是同源标签(0 = 同源,1 = 不同源)。
3.3.3 预训练数据集
- 总规模:约 30GB 无标注流量数据,其中 15GB 来自公开数据集,15GB 来自中国科技网(CSTNET)被动采集的真实流量;
- 协议覆盖:包含 QUIC、TLS、FTP、HTTP、SSH 等常见网络协议,保证预训练表示的通用性。
3.4 微调阶段
- 微调可行性:
- 预训练学到的是与流量类别无关的通用表示,可适配任何类别的加密流量;
- 模型输入是数据报字节级,下游的包分类、流分类任务都可转换为对应 token 序列输入;
[CLS]token 的输出可直接用于分类任务,无需修改模型结构。
- 两种微调策略:
- 包级微调(ET-BERT (packet)):以单个数据包为输入,适配细粒度分类场景,验证模型对极小粒度数据的适配能力;
- 流级微调(ET-BERT (flow)):以单条流中连续 5 个包的拼接序列为输入,用于和现有方法做公平对比,适配工业界主流的流分类场景。
- 微调成本:远低于预训练,单块 GPU 即可完成,工业界落地时,针对特定 VPN 分类任务,仅需少量标注数据就能快速适配。
4. 实验(EXPERIMENTS)逐句精读
4.1 实验设置
4.1.1 下游任务与数据集
论文在5 大类加密流量分类任务、7 个数据集上完成了全面验证,其中核心是 VPN 分类任务,完全匹配用户需求:
| 任务编号 | 任务名称 | 核心目标 | 数据集 | 规模 |
|---|---|---|---|---|
| Task1 | 通用加密应用分类(GEAC) | 标准加密协议下的应用分类 | Cross-Platform(iOS/Android) | 196/215 个应用,4.8 万 + 条流 |
| Task2 | 加密恶意软件分类(EMC) | 区分加密的恶意 / 良性流量 | USTC-TFC | 20 个类别,9853 条流 |
| Task3 | VPN 加密流量分类(ETCV) | 分类 VPN 与非 VPN 流量、VPN 应用分类 | ISCX-VPN-Service/App | 12/17 个类别,6000 + 条流 |
| Task4 | Tor 加密应用分类(EACT) | 分类 Tor 网络的加密应用流量 | ISCX-Tor | 16 个类别,3021 条流 |
| Task5 | TLS1.3 加密应用分类(EAC-1.3) | 分类 TLS1.3 协议的加密应用流量 | CSTNET-TLS1.3(自建) | 120 个应用,4.6 万 + 条流 |
- 伦理说明:数据采集经过伦理审查,完全被动采集,无个人可识别信息,符合采集网络的用户协议。
4.1.2 数据预处理
- 过滤噪声:移除 ARP、DHCP 等与传输内容无关的数据包;
- 关键操作:移除以太网头、IP 头、TCP 头中的端口信息,避免 IP / 端口这些强识别信息带来的有偏干扰,保证模型学习到的是加密载荷本身的模式,而非易篡改的头部信息,这是模型泛化能力强的核心原因之一;
- 数据集划分:按 8:1:1 的比例划分为训练集、验证集、测试集,微调阶段每个类别最多选取 500 条流、5000 个包,模拟真实场景的有限标注数据。
4.1.3 评估指标与实现细节
- 评估指标:准确率(AC)、精确率(PR)、召回率(RC)、宏平均 F1 值(核心指标,避免数据不平衡带来的结果偏差);
- 预训练超参数:batch size=32,总步数 50 万,学习率 2e-5,warmup 比例 0.1;
- 微调超参数:AdamW 优化器,训练 10 个 epoch,流级学习率 6e-5,包级学习率 2e-5,batch size=32,dropout=0.5;
- 实验环境:Pytorch 1.8.0 + UER 预训练工具库,NVIDIA Tesla V100S GPU。
4.2 与 SOTA 方法的对比结果
论文对比了 4 大类 11 种主流方法,包括指纹方法、统计机器学习方法、监督深度学习方法、预训练方法 PERT,核心结果如下:
| 任务场景 | 数据集 | ET-BERT 最优 F1 值 | 相对之前 SOTA 提升幅度 |
|---|---|---|---|
| VPN 流量分类 | ISCX-VPN-Service | 98.90% | +5.20% |
| VPN 应用分类 | ISCX-VPN-App | 99.37% | +1.72% |
| 安卓应用分类 | Cross-Platform(Android) | 92.50% | +5.40% |
| Tor 应用分类 | ISCX-Tor | 99.21% | +4.41% |
| TLS1.3 应用分类 | CSTNET-TLS1.3 | 97.41% | +10.00% |
| 恶意软件分类 | USTC-TFC | 99.30% | +0.20% |
核心结论解读:
- ET-BERT 在所有任务上均达到 SOTA 效果,尤其在 VPN、TLS1.3 等高隐蔽加密流量场景,提升幅度极大,完美解决了工业界 VPN 检测的核心痛点;
- 模型不依赖任何明文信息,仅通过加密载荷就能实现精准分类,在 TLS1.3 加密 SNI 的场景下,依然能保持极高的分类精度;
- 相比直接套用预训练模型的 PERT,ET-BERT 在所有数据集上均有显著提升,证明了针对流量特性的专属设计的必要性。
4.3 消融实验
论文在 ISCX-VPN-App 数据集上完成了消融实验,验证了每个核心组件的贡献:
| 实验编号 | 实验设置 | F1 值 | 相对完整模型下降幅度 | 核心结论 |
|---|---|---|---|---|
| 完整模型 | ET-BERT(packet) | 93.95% | - | 基准性能 |
| 1 | 移除 SBP 任务 | 89.98% | -3.97% | SBP 任务对分类有显著贡献 |
| 2 | 移除 MBM 任务 | 84.62% | -9.33% | MBM 任务是模型的核心,贡献最大 |
| 3 | 预训练不用 BURST 结构 | 92.58% | -1.37% | BURST 结构能有效提升模型效果 |
| 4 | 流级微调(连续包输入) | 73.87% | - | 流级基准性能 |
| 5 | 拼接流微调(PERT 方案) | 69.61% | -4.26% | 本文的流微调策略优于 PERT |
| 6 | 移除预训练,直接监督训练 | 56.38% | -37.57% | 预训练是模型效果的核心支撑,小样本场景下价值极大 |
4.4 可解释性分析
论文的核心亮点之一,不仅做了效果提升,还从密码学底层解释了模型生效的原因:
- 随机性分析:理想加密算法生成的密文应具备完全随机性(最大熵),但通过 NIST 的 15 组随机性测试发现,AES、ChaCha20、RC4、3DES 等常用加密算法,均无法实现完全随机,不同加密算法、不同应用的加密实现,存在显著的随机性差异,这是加密流量能被分类的底层理论基础。
- 密码算法的影响:数据集包含的密码算法随机性越弱、波动越大,模型的分类效果越好;例如 VPN、Tor 数据集包含随机性较弱的 RC4、3DES 算法,模型 F1 值均接近 100%,进一步验证了模型的底层逻辑。
4.5 小样本场景分析
工业界落地的核心痛点是标注数据稀缺,论文专门做了小样本场景验证:
- 实验设置:在 ISCX-VPN-Service 数据集上,分别用全量、40%、20%、10% 的标注数据训练模型,对比性能变化。
- 核心结果:
- ET-BERT (packet) 在 10% 标注数据下,F1 值仍达到 91.55%;
- 传统监督深度学习方法 Deeppacket,在 10% 标注数据下,性能下降 40.22%;
- 核心结论:ET-BERT 在小样本场景下具备极强的鲁棒性,完美适配工业界真实场景 ------ 很难获取大量标注的 VPN 流量数据,仅需少量标注就能实现极高的检测精度。
5. 讨论与局限性
- 泛化性挑战:互联网服务内容随时间变化,加密流量特征会发生漂移,固定数据训练的模型会面临性能衰减;未来 TLS1.3 的 ECH 机制会加密 SNI,导致流量标注难度大幅提升,论文提出了主动访问打标、进程标识符打标两种应对方案。
- 预训练安全性挑战:模型依赖干净的预训练数据,攻击者可通过投毒预训练数据,植入后门,欺骗微调后的模型;目前加密流量的预训练投毒攻击尚未有相关研究,是未来的风险点。
6. 结论
- 本文提出了 ET-BERT 预训练模型,首次针对加密流量特性设计了原生的 Transformer 预训练架构,通过大规模无标注数据学习通用的流量表示,仅需少量标注数据微调,就能适配多个加密流量分类场景。
- 模型在 5 大类加密流量分类任务上达到 SOTA 效果,在 VPN 流量分类、TLS1.3 流量分类等高难度场景,实现了突破性提升,最大提升幅度达 10 个百分点。
- 论文通过密码算法随机性分析,为模型效果提供了理论解释,明确了加密流量分类的能力边界。
- 未来工作将聚焦模型的零样本新类别预测能力,以及抵抗样本攻击的鲁棒性。
对工业界 VPN 检测落地的核心价值总结
- 解决核心痛点:完美解决了传统 VPN 检测方法对高隐蔽、混淆 VPN 流量检测能力不足、泛化性差、依赖大量标注数据的核心痛点,在 VPN 标准数据集上 F1 值达到 98.9%,远超现有方案。
- 适配新型加密协议:在 TLS1.3、Reality 等新型加密伪装场景下,依然能保持极高的检测精度,解决了传统方法对新型 VPN 协议适配慢的问题。
- 极低的落地成本:预训练模型开源,仅需少量标注的 VPN 流量数据微调,就能快速适配企业 / IDC / 运营商的 VPN 检测场景,无需大量人工特征工程。
- 可解释、可合规:模型具备完整的可解释性,能输出分类的核心依据,同时完整留存流量元数据,满足合规监管的取证要求。
- 工程化适配性强:模型可通过量化、剪枝实现轻量化,适配网关、防火墙等边缘设备的实时推理需求,可直接融入之前调研的工业界 VPN 检测架构,作为高隐蔽 VPN 流量的兜底检测引擎。