
对于追求与用户建立长期、个性化关系的对话 Agent 而言,一个可靠的"记忆系统"是不可或缺的核心组件。然而,随着对话轮次的增加,如何有效管理和利用日益庞大的历史信息,始终是一个悬而未决的难题。现有方案大多在复杂的架构上做文章,例如引入层级化摘要、知识图谱,甚至动用强化学习来优化记忆更新,但效果往往不尽人意,系统在长对话中依然容易"失忆",遭遇"上下文稀释"(context dilution)的困境。
ArXiv URL:http://arxiv.org/abs/2604.11628v1
面对这条日益拥挤的技术路线,来自新加坡国立大学和香港科技大学的研究者们另辟蹊径,提出了一种截然不同的诊断:对话记忆的核心瓶颈或许不在于记忆架构的复杂性,而在于一个被忽视的底层现象------信号稀疏效应 (Signal Sparsity Effect)。基于这一洞察,他们设计了一个名为 Nano-Memory 的极简框架,彻底回归"检索+生成"的基础范式。该框架不依赖任何复杂的记忆组织或更新机制,仅通过两个简单而精准的操作------轮次隔离检索 (Turn Isolation Retrieval, TIR)和查询驱动剪枝(Query-Driven Pruning, QDP),就在多个基准测试中超越了诸多复杂模型,为长程对话记忆树立了一个全新的、高效的极简基线。
这项工作真正的亮点在于,它没有继续在"如何构建更精巧的记忆容器"上内卷,而是深刻地回答了"记忆中什么信息才是真正有用的"。论文指出,真正决定回复质量的"决定性证据"在海量对话历史中是极其稀疏的,而大部分内容则是冗余的噪声。因此,与其设计复杂的系统去管理这些良莠不齐的信息,不如从一开始就精准地定位信号、并无情地剔除噪声。
真正的瓶颈:被噪声淹没的"信号稀疏效应"
在深入 Nano-Memory 的具体机制前,我们必须先理解其所要解决的核心问题------信号稀疏效应。研究者通过实验发现,在长程对话的潜在知识流形(latent knowledge manifold)中,存在两大关键挑战:
-
决定性证据稀疏(Decisive Evidence Sparsity):与当前查询高度相关的关键信息,往往只存在于过去对话的极少数几个"轮次"(turn)中。随着对话历史的增长,这些关键信号点在整个信息空间中变得越来越孤立,如同大海捞针。传统的检索方法通常对整个对话"会话"(session)或大块文本进行编码和聚合,这种"平均化"或"综合化"的操作,极易将这些尖锐但稀疏的强信号淹没在大量无关信息的平均值中,导致召回失败。
-
双层冗余(Dual-Level Redundancy):噪声不仅存在,而且是系统性的,分布在两个层面。
- 会话间冗余(inter-session redundancy):在用户的全部历史记录中,大部分过去的会话与当前的新查询毫无关系。将这些无关会话纳入考虑,会严重干扰模型的判断。
- 会话内冗余(intra-session redundancy):即便我们找到了一个相关的会话,其内部也充斥着大量的"对话填充物"(conversational filler),例如问候、确认、口头禅和与核心信息无关的闲聊。这些内容会稀释关键信息的浓度,增加生成模型的处理负担。

图 1: 不同类型的对话记忆方法。Nano-Memory 属于显式记忆中的检索生成范式,但其核心思想是简化而非复杂化。
这两个现象共同构成了"信号稀疏效应",它意味着在长程对话中,有价值信息的信噪比会急剧下降。这不仅让检索器难以"找到"正确的信息,也让生成器难以"理解"和"利用"这些信息。以往的方法试图通过构建复杂的层级结构或摘要来对抗这种信息熵增,但 Nano-Memory 认为,更直接的解决方式是"提纯"而非"组织"。
Nano-Memory 的两步解决之道:精准定位与极致剪枝
针对上述诊断,Nano-Memory 的设计思路清晰而直接:第一步,用最敏锐的方式捕捉稀疏的决定性证据;第二步,用最彻底的方式清除双层冗余。这分别对应了它的两大核心组件:TIR 和 QDP。
第一步:轮次隔离检索 (TIR) ------ 锁定最强信号
传统检索方法通常将一个完整的对话会话 cic_ici 编码成一个向量,然后与查询向量进行比较。这种方式的问题在于,会话内部的高度相关信号会被大量无关内容"平均掉"。
TIR 彻底改变了这种范式。它不再为整个会话打分,而是为会话中的每一个轮次 tjt_jtj 单独打分。具体来说,当一个新查询 u∗u^*u∗ 到来时,TIR 会计算它与历史中每一个 对话轮次的相似度。然后,对于每一个历史会话 cic_ici,TIR 会找出该会话中得分最高的那个轮次,并将这个最高分 作为整个会话 cic_ici 的最终得分。最后,系统会召回得分最高的 Top-k 个会话。
Score(ci,u∗)=maxtj∈ciSimilarity(tj,u∗) \text{Score}(c_i, u^*) = \max_{t_j \in c_i} \text{Similarity}(t_j, u^*) Score(ci,u∗)=tj∈cimaxSimilarity(tj,u∗)
这种"最大激活"(max-activation)策略的妙处在于,它能极其灵敏地捕捉到"决定性证据稀疏"的信号。只要一个会话中哪怕只有一个轮次与当前查询高度相关,这个会话就能凭借这一个"高光时刻"脱颖而出,而不会因为其他无关轮次的存在而被埋没。它解决了在茫茫大海中"发现"信号的问题。
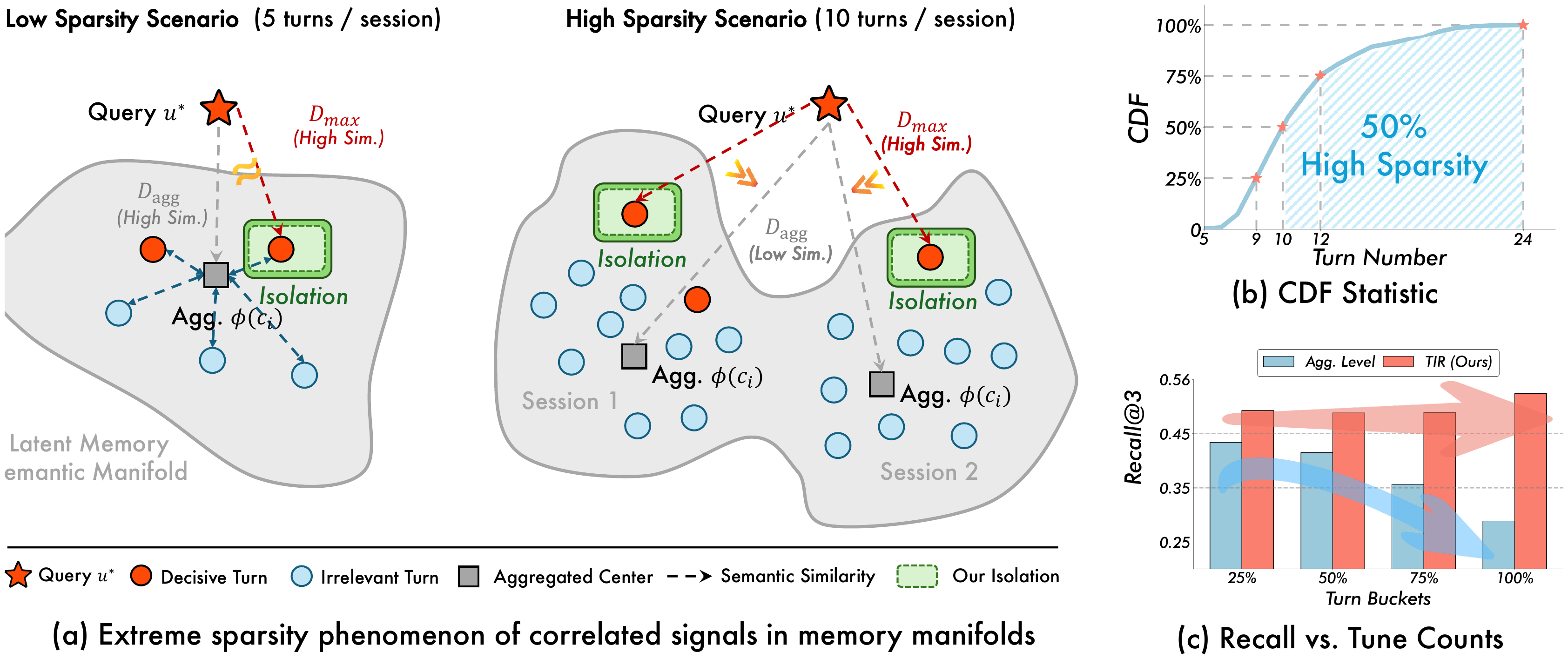
图 2: TIR 机制(c)在不同会话长度百分位上的性能表现。与基线方法(a, b)相比,TIR 的检索性能几乎不受对话历史增长的影响,表现出卓越的稳定性,有效解决了因上下文扩展导致的信号稀释问题。
第二步:查询驱动剪枝 (QDP) ------ 为生成器扫清障碍
通过 TIR,我们成功召回了 Top-k 个最可能包含关键信息的会话。但这只解决了"可达性"(accessibility)问题,还没完全解决"理解"(understanding)问题。这些召回的原始会话片段仍然充满了"双层冗余"------不仅可能包含被误召回的整个会话,每个会话内部也充斥着大量与当前查询无关的对话填充物。
如果直接将这些原始文本拼接起来作为上下文喂给生成模型,模型将耗费大量精力去消化和过滤这些噪声,最终影响生成质量。
QDP 的任务就是进行一次彻底的"净化"。它将 TIR 召回的 Top-k 会话内容和当前查询 u∗u^*u∗ 一同交给一个语言模型(可以是轻量级模型),并给出一个明确的指令,要求它执行两项任务:
- 识别并丢弃与当前查询完全无关的整个会话。
- 在保留的会话中,删除所有不包含回答查询所需信息的句子或段落。
最终,QDP 输出一个精简、高密度的"证据集"(evidence set),其中只包含回答当前问题最核心的信息。这个过程相当于在生成之前,先做了一次由查询驱动的、动态的上下文压缩和提纯。它直接解决了"双层冗余"问题,极大地降低了生成模型的负担。
图 3: QDP 的有效性分析。与仅召回包含真实答案的会话(Hit Only)相比,经过 QDP 剪枝后(图中 Nano-Memory),F1 分数从 17.07 提升到 22.66,证明 QDP 不仅能定位到正确会话,还能通过有效去除会话内冗余来最大化记忆的效用。
实验结果:大道至简,效果为王
Nano-Memory 的理念听起来很直观,但它真的比那些精心设计的复杂系统更有效吗?论文通过在 LoCoMo 等多个长程对话基准上的详尽实验,给出了肯定的答案。
1. 检索与生成性能双双胜出:
在检索阶段,TIR 的表现在多个指标上远超基线。例如,在 LoCoMo 数据集上,TIR 的 Recall@3 指标比最强的基线高出 22% 以上,证明其发现关键信息的能力更强。在最终的问答生成任务上,完整的 Nano-Memory 框架(TIR + QDP)在 F1、BLEU、ROUGE 等多个自动评估指标以及 GPT-4o 作为裁判的人工评估中,都稳定地超越了 A-Mem、RAPTOR 等一系列以复杂性著称的先进模型。
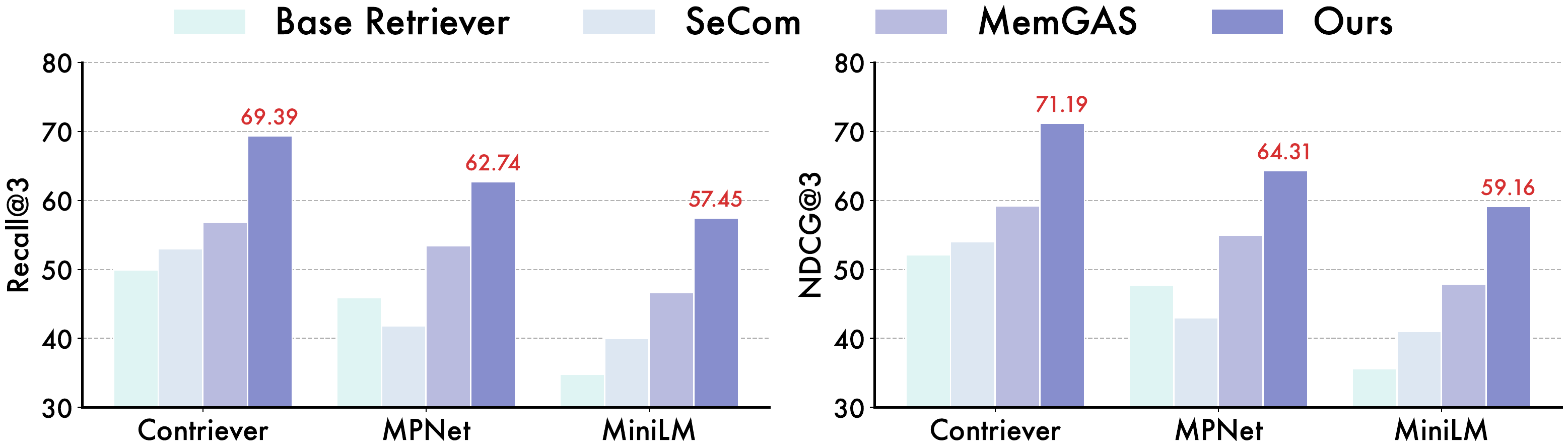
图 5: Nano-Memory 的通用性分析。无论搭配 Contriever、MPNet 还是 MiniLM 等不同的检索器,Nano-Memory(橙色条)相比基线(蓝色条)和最强对比模型(灰色条)都有显著的性能提升。
2. 惊人的通用性:
Nano-Memory 的强大之处不仅在于其效果,更在于其普适性。
- 跨 LLM 骨干:无论是使用 GPT-4o-mini 这样的闭源模型,还是 Llama、Qwen 等开源模型作为生成器,Nano-Memory 都能带来一致的显著性能提升。
- 跨检索器骨干:将底层的检索模型从 Contriever 换成 MPNet 或 MiniLM,TIR 依然能稳定地超越其他检索策略。
- 跨查询类型:在处理事实、关系、时序等不同类型的查询时,Nano-Memory 均表现最佳。尤其是在对时间信息要求极为严格的"时序"类查询上,其性能提升幅度最大(相对增益 39.7%),这直接暴露了传统聚合方法在压缩上下文时容易丢失精确时序信息的致命缺陷。
3. 卓越的效率:
"极简"不仅是理念,也带来了实实在在的效率优势。消融实验显示,在 LoCoMo 数据集上,仅使用 TIR 召回原始会话,输入给生成器的平均 Token 数为 2685;而加入了 QDP 进行剪枝后,平均 Token 数骤降至 1403,减少了近一半。这意味着在提升回复质量的同时,Nano-Memory 还大幅降低了推理成本和延迟,这在实际应用中是极具吸引力的优点。更有趣的是,实验证明,执行 QDP 任务的剪枝模型并不需要和最终的生成模型一样强大,即便是 3B 级别的轻量级模型也能胜任,进一步提升了整体框架的性价比。
图 9: QDP 机制分析。使用 Qwen2.5-3B、Llama-3.2-3B 和 Phi-3-mini-128k 等不同规模的轻量级模型执行剪枝任务时,Nano-Memory 的最终生成性能依然保持稳健,证明该剪枝机制具有良好的通用性,不依赖于特定的强大模型。
结论与启示
Nano-Memory 的工作为深陷"架构军备竞赛"的对话记忆研究领域,提供了一股清流。它雄辩地证明,与其不断堆叠复杂的模块来管理日益臃肿的记忆,不如回归本源,重新审视信息本身的价值。
这篇论文的核心贡献可以归结为两点:
- 提出了一个深刻的诊断:首次清晰地定义并验证了"信号稀疏效应"(包括决定性证据稀疏和双层冗余)是导致长程对话记忆失败的关键瓶颈。
- 提供了一个极简的解决方案:通过 TIR 的最大激活策略精准定位稀疏信号,再通过 QDP 的查询驱动剪枝彻底清除冗余噪声,用最少的组件实现了最佳的效果。
这项工作启示我们,在设计大模型应用,尤其是 RAG 系统时,上下文的"质量"远比"数量"重要。一个经过精心提纯、信噪比极高的短上下文,其效果可能远胜于一个未经处理、冗长但充满噪声的长上下文。Nano-Memory 所倡导的"先定位、后剪枝"的理念,不仅为对话 Agent 的记忆系统设计提供了新思路,也对所有依赖外部知识进行生成的任务具有普遍的借鉴意义。
当然,作者也坦言了该框架的局限性,例如其本质上仍是一种被动的、响应式的记忆范式,缺乏主动进行知识整合与自我演化的能力。未来的研究方向或许会将这种高效的在线剪枝机制与离线的、自主的知识重构相结合,打造出更加主动和智能的记忆系统。但无论如何,Nano-Memory 已经证明,有时候,回归基础,把最简单的事情做到极致,就是通往成功的捷径。