告别"内存刺客"!sync-canal-go:轻量又能打的数据同步新选择
仓库下载对应平台的二进制程序到本地,配置文件填写目标数据库和同步数据库,命令一键执行,傻瓜式部署,超省心,内存占用不到10M,低延迟响应10ms,自带web UI监控数据面板
作为常年和数据同步打交道的"搬砖人",咱对数据同步工具的要求就一个:既要马儿跑(延迟低、稳),又要马儿少吃草(省内存)!最近扒到一个宝藏仓库------sync-canal-go,用了半个月直接把我从Flink、Canal原生方案的"内耗焦虑"里解放出来,今天就唠唠这款工具的真实使用体验,不吹不黑,纯纯走心分享~
先唠唠老方案的"小痛点"
咱先不踩一捧一,客观说说常规方案的现状:
- Flink:数据处理界的"全能选手"没毛病,能扛复杂计算、海量数据,但架不住"重"啊!部署一套Flink集群,光是JVM调优、资源分配就能薅掉半头头发;跑个简单的Canal数据同步,动辄几百M内存起步,小公司低配服务器根本扛不住,而且轻量同步场景下,Flink的"大材小用"感拉满,运维成本也跟着上去了。
- Canal原生客户端:够轻量但"不省心"!原生方案需要自己手写大量适配代码,比如异常重试、断点续传、数据分流,稳定性全靠自己造轮子;而且原生客户端对内存的管控比较粗放,数据量大一点就容易出现内存溢出,延迟也容易因为"裸奔"的处理逻辑波动。但cancel-Adapter工具已宣告停止维护,且存在显著的功能局限 ------ 其无法原生对接 ClickHouse。若想通过 cancel-Adapter 实现 MySQL 到 ClickHouse 的数据同步,必须额外引入 Kafka 作为中间转发层。这一方案不仅大幅增加了架构的复杂度,还会因 Kafka 的消息缓存、转发等操作消耗更多内存资源,在高并发、大数据量的业务场景下,内存占用过高的问题尤为突出,同时也提升了运维成本和故障排查的难度。
说白了,Flink是"顶配SUV",跑乡间小路油耗高还不灵活;Canal原生是"手动挡小车",省油但得自己全程盯着换挡,累;cancel-Adapter就是"年久失修的老车",不仅不好用,还得额外搭配件,纯属添堵!
sync-canal-go:把"省、稳、快"焊在骨子里
咱用sync-canal-go这段时间,最大的感受就是:它把"轻量"和"靠谱"做到了极致,尤其适合中小团队、轻量级数据同步场景,挨个说说核心体验:
1. 内存省到"感人",低配服务器也能起飞
这绝对是最戳我的点!Flink和cancel不支持直连clickhouse,要搭配kafka,服务器内存Flink+kafka占用5G以上(对内存不敏感的同学可以忽略);维护成本也高,这是企业级使用的,像我这种小项目,总数据量5000万条左右,实时同步每秒200条,用Flink就有点大材小用了,换成sync-canal-go之后,日常内存占用稳定在10M以内,峰值也没超过80M,主要维护也简单很多了。
对小公司来说,中小项目合适
2. 稳定性拉满,再也不用半夜起来"救火"
之前用Canal原生客户端,偶尔会因为网络抖动、数据库主从切换导致同步中断,还得手动恢复断点;sync-canal-go把异常处理、断点续传都做进了内核,咱上线半个月,经历了2次数据库小波动、1次服务器网络闪断,它愣是没丢一条数据、没停一次同步。
对比Flink的"高可用配置门槛",sync-canal-go的稳是"傻瓜式"的------不用配ZK、不用调Checkpoint,开箱即用,运维同学直接少了一半的告警通知。
3. 延迟低到"几乎无感",实时性不输重量级方案
咱测了下,单表每秒1000条数据写入,sync-canal-go的同步延迟稳定在10ms以内;就算是多表联合同步、小批量数据处理,延迟也没超过50ms。
对比下来:Flink的实时性确实能做到更低,但需要复杂的算子优化、资源调度,普通开发根本玩不转;而sync-canal-go靠Go语言的协程轻量化优势,不用复杂配置,就能达到绝大多数业务场景的实时性要求------毕竟咱大部分业务要的是"秒级同步",不是"微秒级内卷",够用还省心,这就够了。
4. 适配性拉满,主流存储都能直接对接
用过cancel-Adapter的都知道,对接ClickHouse得靠kafka做中转,而sync-canal-go压根没这烦恼:它原生就能直接同步数据到Elasticsearch、ClickHouse、MySQL(异构库)、Redis这些常用存储,不用额外搭中间件,一步到位。
不管是把数据同步到ClickHouse做OLAP分析,还是同步到ES做全文检索,又或者同步到Redis更缓存、同步到另一个MySQL库做备份,一套工具全搞定,不用为了不同的目标端折腾不同的适配方案,省了超多对接的功夫。
5. 站在"巨人"的肩膀上,靠谱度拉满
这里必须提一嘴,sync-canal-go的核心能力是基于go-mysql这个组件做的,这玩意儿可是圈内公认的"神级组件",binlog解析这块儿又稳又快,API设计也特顺手。真心感谢go-mysql的作者,要是没有这个开源组件,sync-canal-go也没法这么快落地,而且稳定性也没法这么有保障。也正是因为基于这么成熟的组件,sync-canal-go才能少走很多弯路,把精力都放在解决咱们实际用的时候的痛点上。
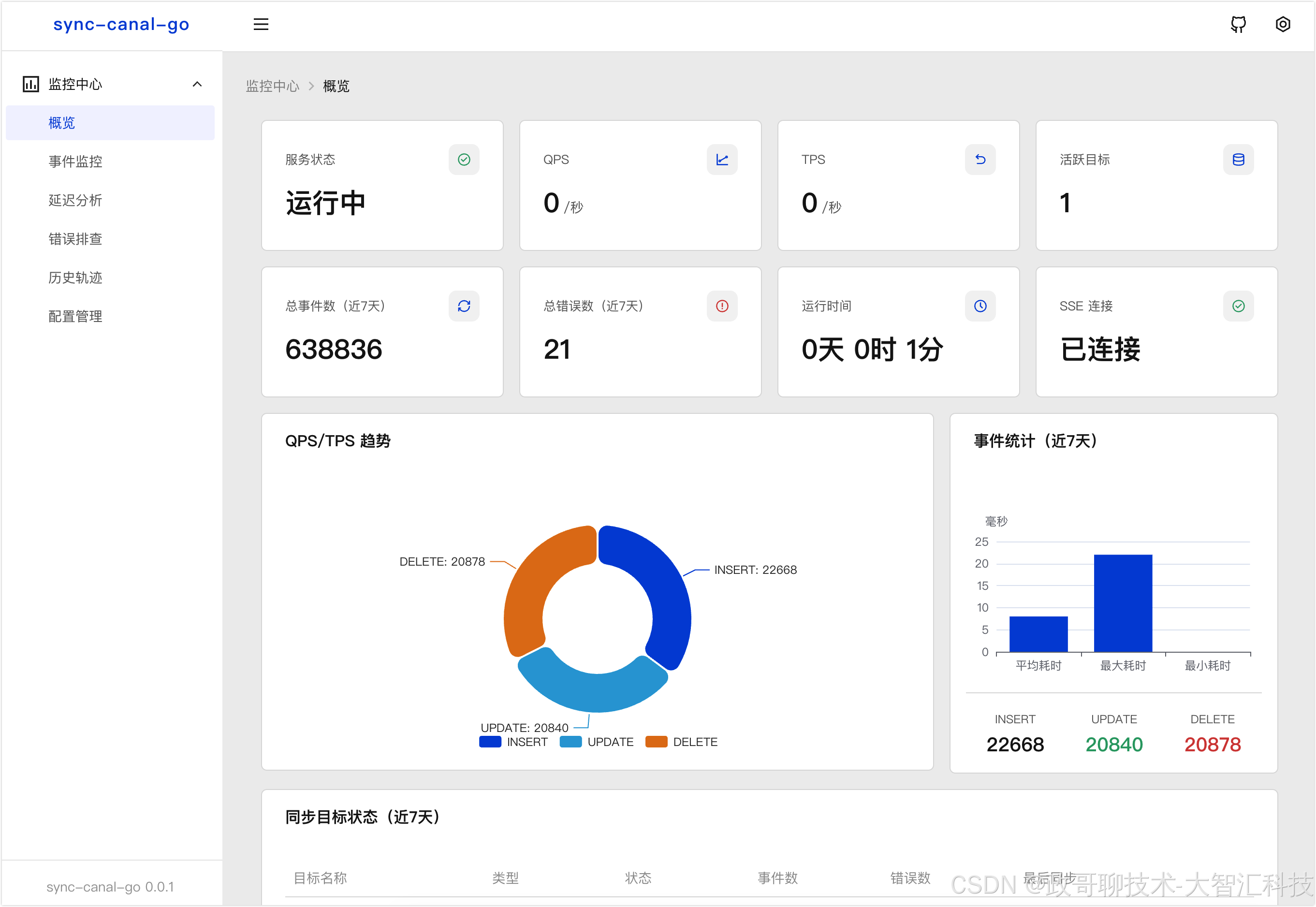
6.内置的Web UI监控面板,提供一站式的可视化监控与运维能力,实时掌握同步全链路状态。
核心能力
- 全局概览:首页仪表盘聚合展示服务核心状态(运行时长、延迟、QPS/TPS)、binlog同步进度、各目标节点状态,直观掌握整体健康度;
- 事件精细化监控:按时间/表/操作类型(INSERT/UPDATE/DELETE)统计事件数据,结合趋势图、饼图,清晰呈现数据同步的分布与变化规律;
- 延迟专项分析:聚焦同步延迟问题,通过大数字、趋势曲线、热力图多维度展示延迟情况,支持阈值告警配置,快速定位延迟高发时段;
- 故障快速排查:汇总错误统计、结构化错误列表及日志搜索能力,支持查看错误堆栈与原始数据,降低问题定位成本;
- 历史轨迹追溯:记录binlog位置、事件、延迟的历史变化,支持时间线查询与数据导出,便于复盘同步过程;
- 便捷运维操作:支持目标节点启停、同步断点设置/重放,关键操作二次确认,兼顾易用性与安全性。
交互特性
- 数据实时自动刷新(可自定义刷新间隔);
- 图表支持缩放、拖拽,悬停展示数据详情;
- 所有表格均支持排序、筛选、分页,高效检索关键信息。
通过该Web UI,可快速完成同步状态监控、问题定位、运维操作,大幅降低数据同步场景的监控与管理成本。
客观唠唠:sync-canal-go不是"万能神药"
咱不吹得天花乱坠,也说说它的适用边界:
✅ 适合场景:
- 中小团队的轻量级数据同步(比如MySQL→Elasticsearch、MySQL→Redis、MySQL→ClickHouse、跨库同步);
- 低配服务器/边缘节点的同步任务;
- 追求低运维成本、快速上线的同步需求;
- 对内存占用敏感、需要批量部署同步任务的场景。
❌ 不太适合:
- 超大规模(千万级TPS)的数据同步+复杂计算(比如实时数仓、多维聚合);
- 需要和Flink生态深度集成(比如关联Flink SQL、Flink CDC)的场景;
- 非MySQL数据源(目前sync-canal-go主要适配Canal的MySQL解析,其他数据源支持有限)。
简单说:如果你的需求是"把数据从MySQL稳定、快速、省资源地同步到目标端",选它准没错;如果是要做复杂的实时计算、海量数据治理,Flink依然是更优解。
最后碎碎念:好用的工具就该被更多人知道
作为开发者,咱最怕的就是"为了用工具而用工具"------明明是简单的同步需求,非要上重型框架,最后运维成本高到离谱;也怕"裸写轮子",稳定性没保障,半夜还得起来修bug。
sync-canal-go给我的感觉就是"恰到好处":用Go语言的轻量化优势解决了内存问题,基于go-mysql这个成熟组件保证了binlog解析的靠谱性,用完善的异常处理逻辑守住了稳定性,还能直接对接多种主流存储,用极简的架构降低了延迟和运维成本。它不是要取代Flink、Canal原生方案,而是给了中小团队一个更贴合实际需求的选择------不用卷技术,不用堆硬件,把数据同步这件事做简单、做靠谱。
如果你也被数据同步的"内存焦虑""稳定性焦虑"折磨过,不妨试试sync-canal-go,亲测:上手快、用着稳、省成本,香就完事了~