(承接【产品底稿 04】,从 "能入库" 到 "会用库" 的关键一步)
一、背景:从 "数据入库" 到 "数据应用"
在【产品底稿 04】中,我们完成了 CSDN 爬虫入库、MySQL 结构化存储、Milvus 向量库全链路打通,解决了文章 "从哪来、怎么存" 的问题。
但数据只存着不使用,价值发挥不出来。所以在 V1.1 阶段,我继续往下推进,实现了基于知识库的 RAG 文章仿写模块,把库里沉淀的技术文章真正用起来,完成从 "数据" 到 "应用" 的闭环。
二、整体流程架构
用户输入仿写需求 → 向量检索(Milvus)→ 召回相似文章 → 构建 Prompt → 多模型调度(DeepSeek/Ollama)→ SSE 流式输出 → 前端打字机效果
三、核心组件分工
表格
| 模块 | 核心职责 | 实现要点 |
|---|---|---|
| ArticleCopyController | 仿写接口入口 | 提供 SSE 流式接口,接收用户仿写请求 |
| AiKnowledgeService | 向量检索服务 | 基于 Embedding + Milvus 召回相似文章 |
| AiChatFacade | 多模型统一入口 | 配置切换 DeepSeek / Ollama,本地云端兼容 |
| DeepSeekAiService | 云端模型调用 | 遵循 OpenAI 协议,实现流式输出 |
| OllamaChatService | 本地模型调用 | 支持离线环境下的文本生成 |
四、关键代码实现
1. 向量检索核心(Milvus 检索相似文章)
java
运行
// 检索相似文章
public List<String> search(String query, int maxResults) {
TextSegment segment = TextSegment.from(query);
Embedding embedding = embeddingModel.embed(segment).content();
return embeddingStore.findRelevant(embedding, maxResults).stream()
.map(it -> it.embedded().text())
.toList();
}2. 仿写接口(SSE 流式输出)
java
运行
/**
* 流式仿写文章(前端打字效果)
*/
@PostMapping(value = "/generate", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> copyArticle(@RequestParam("userPrompt") String userPrompt) {
// 1. 检索相似文章
List<String> references = aiKnowledgeService.search(userPrompt, 2);
if (references.isEmpty()) {
return Flux.just("暂无参考文章,请先上传文章到知识库");
}
// 2. 构建仿写提示词
String prompt = buildCopyPrompt(userPrompt, references);
// 3. 统一AI入口
return aiChatFacade.chat(prompt);
}3. Prompt 构建(约束仿写风格)
java
运行
private String buildCopyPrompt(String userPrompt, List<String> referenceArticles) {
StringBuilder sb = new StringBuilder();
sb.append("请你严格按照参考文章仿写,保持结构、风格、段落、语气一致。\n");
sb.append("要求:内容完整、逻辑清晰、不编造、不跑题、不自由发挥。\n\n");
sb.append("用户需求:").append(userPrompt).append("\n\n");
sb.append("参考文章:\n");
referenceArticles.forEach(ref -> sb.append(ref).append("\n"));
sb.append("\n请直接输出仿写结果,不要标题,不要解释:");
return sb.toString();
}4. 多模型统一调度
java
运行
@Service
@RequiredArgsConstructor
public class AiChatFacade {
private final DeepSeekAiService deepSeekAiService;
private final OllamaChatService ollamaChatService;
@Value("${ai.chat-mode:deepseek}")
private String chatMode;
public Flux<String> chat(String prompt) {
if ("ollama".equals(chatMode)) {
return ollamaChatService.chat(prompt);
} else {
return deepSeekAiService.chatStream(prompt);
}
}
}五、当前效果与真实表现
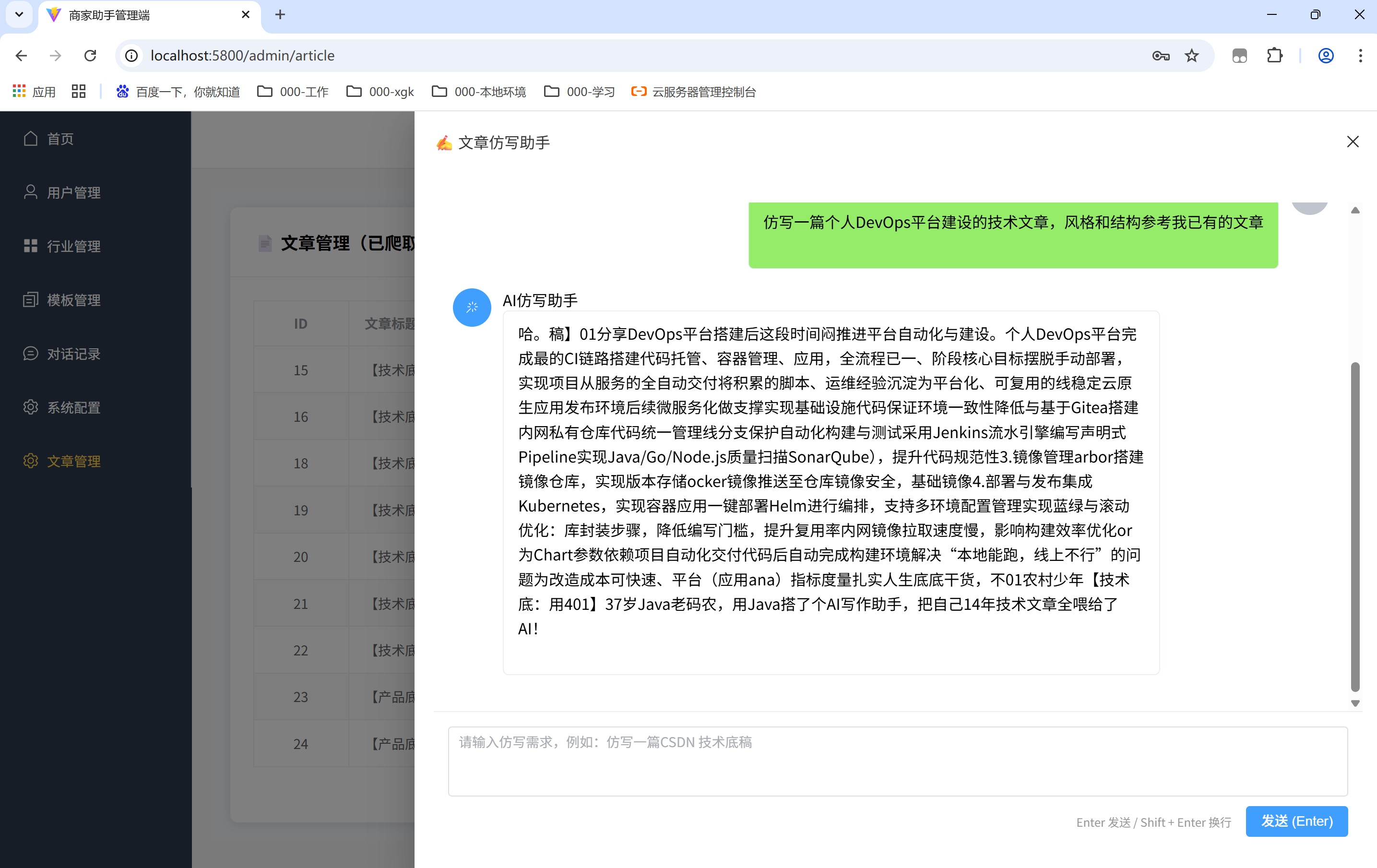
说明:目前知识库文章数量较少(不到 10 篇),向量召回的内容片段比较碎,导致 AI 仿写内容连贯性一般,属于 RAG 冷启动阶段的正常现象。
六、已实现功能
- ✅ 仿写接口全链路通
- ✅ Milvus 向量检索正常
- ✅ AI 流式输出(SSE)
- ✅ 前端打字机效果
- ✅ DeepSeek/Ollama 多模型切换
- ✅ 前后端联调成功
七、后续优化方向
- 扩充知识库文章数量,提升检索质量
- 优化文章分段策略,让召回更完整
- 精细化调优 Prompt,增强仿写风格一致性
- 完善异常处理、重连、超时保护
- 仿写结果一键保存入库,形成生成 - 复用闭环
八、总结
商助慧 V1.1 阶段,我完成了从 "数据入库" 到 "数据应用" 的关键一步,RAG 仿写模块正式打通。虽然当前生成效果一般,但流程已经完全跑通,后续只需要持续喂数据、调细节,效果会稳步提升。
整个系统越来越像一个真正可用的 AI 写作助手了。
后续会继续同步产品迭代细节,保持纯 Java 生态落地 AI 应用,一步一步把个人专属写作助手做扎实。
持续更新《人生底稿》成长史 &《技术底稿》&《产品底稿》实战干货,一起踏实成长,不焦虑、不内卷。
📚 系列导航:
【技术底稿】01:37岁老码农,用4台机器搭了套个人DevOps平台
【产品底稿01】37 岁 Java 老码农,用 Java 搭了个 AI 写作助手,把自己 14 年技术文章全喂给了 AI!