简历内容
针对商家信息、热门菜品等高频访问数据,构建基于 Redis 的缓存方案。通过合理设置缓存过期时间,采用缓存预热机制,规避了缓存穿透、缓存击穿和缓存雪崩等问题。此外,采用 "更新数据库后主动删除缓存" 策略,保障数据一致性。
知识回顾
一、添加缓存
这部分很简单,就是在更新数据库之前先去查询缓存,不必多言
二、缓存更新策略
1、内存淘汰
redis内存不足时自动淘汰;
2、超时剔除
给redis设置过期时间ttl;
3、主动更新
手动调用方法把缓存中的数据删掉,下次重新缓存;
4、最佳实践方案
(1)低一致性需求:使用Redis自带的内存淘汰机制;
(2)高一致性需求:主动更新,并以超时剔除作为兜底方案;
<1>读操作: 缓存命中则直接返回, 缓存未命中则查询数据库,并写入缓存,设定超时时间;
<2>写操作: 先写数据库,然后再删除缓存,要确保数据库与缓存操作的原子性;
三、缓存穿透
1、定义
客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
2、解决办法
(1)缓存空对象
实现简单,维护方便;额外的内存消耗、可能造成短期的不一致;
(2)布隆过滤
本质:在缓存前再加一层过滤器,拦截空值;
内存占用较少,没有多余key;实现复杂、存在误判可能;
(3)其他解决办法
增强id的复杂度,避免被猜测id规律;加强用户权限校验;做好热点参数的限流;做好数据的基础格式校验。
三、缓存雪崩
1、定义
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
2、解决办法
给不同的Key的TTL添加随机值;用Redis集群提高服务的可用性;给缓存业务添加降级限流策略;给业务添加多级缓存;
其中给缓存业务添加降级限流策略是可以解决所有缓存问题的,一般作为保底方案;
四、缓存击穿
1、定义
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
记忆技巧:击穿是一个东西导致的,雪崩是全体崩塌,穿透是没有值,像隐身一样直接穿过去了;
2、解决办法
热点key失效导致无数请求到达数据库,那解决办法就是一个线程赶紧创建缓存,其他的稍微等等,等到缓存创建出来。就不会都去访问数据库了。
(1)互斥锁
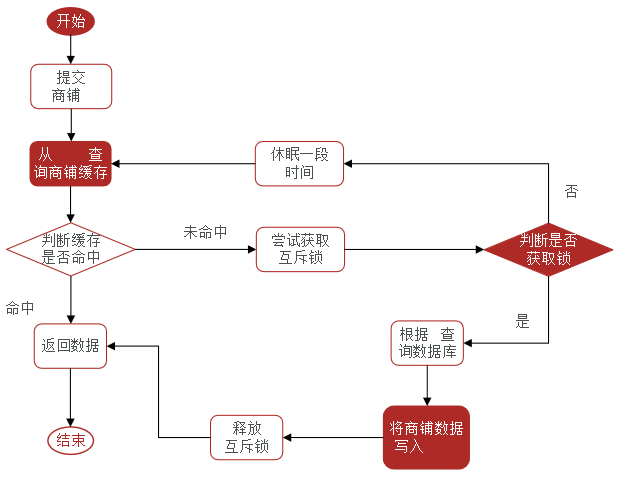
优点:保证一致性;实现简单;没有额外的内存消耗;
缺点:线程需要等待,性能受影响;可能有死锁风险;
(2)逻辑过期
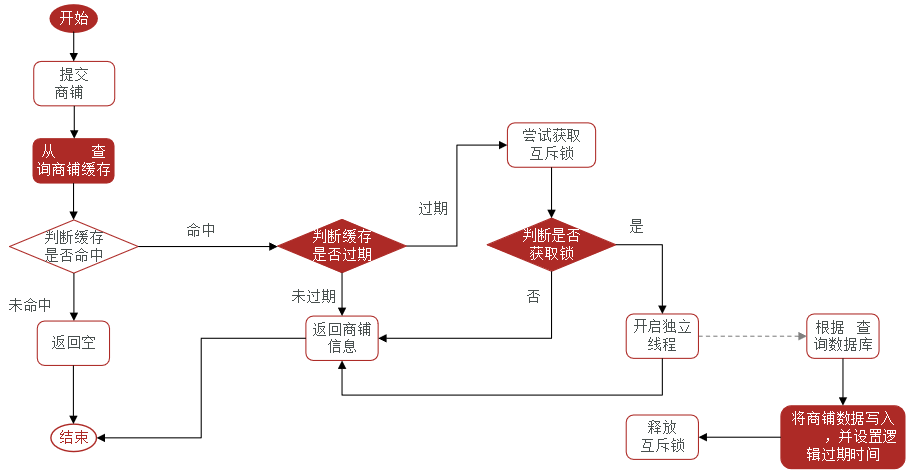
优点:线程无需等待,性能较好;
缺点:不保证一致性;有额外内存消耗;实现复杂;
五、可能的问题
我只做关键字回答,实际需要阐开描述,同时结合场景。
1、什么是缓存穿透 ? 怎么解决 ?
一直查询缓存和数据库都不存在的数据,导致多数请求直接到达数据库;
缓存空值,但其内存消耗大,且数据可能不一致;因此也常用布隆过滤方法,布隆过滤内存占用少,但实现起来复杂,可能有误判;本项目缓存主要用在缓存店铺类型等数据,没有高一致性需求,所以采用的是缓存空值的办法。
2、能介绍一下 布隆过滤器 吗?
布隆过滤器主要是用于检索一个元素是否在一个集合中;
底层原理是,先初始化一个比较大的数组,里面存放的是二进制0或1;
当一个key来了之后,经过3次hash计算,吧计算得到的值放在数组相应位置上,并把数组中原来的0改为1,这样,三个数组的位置就能标明一个key的存在。查找的过程也是一样的;
但是,布隆过滤器有可能会产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%,误判的原因是不同key三次hash的值可能一样,不是一一对应,就是恰好三个相互对上了。
3、什么是缓存击穿 ?怎么解决?
热点key失效;互斥锁,但性能差,可能死锁,所以还有逻辑过期方法,可能有短暂不一致性,要根据需求选择解决方案;
4、什么是缓存雪崩?怎么解决?
大量key同时失效或Redis宕机;随机TTL;集群;限流;多级缓存;
5、详细说明你是如何设计Redis缓存的?比如数据结构选择、Key命名规则、过期时间设置等?
(1)数据结构选择
对于商家信息、热门菜品这类完整的JSON对象,我们主要使用 String 类型来存储,因为它是二进制安全的,可以完整地序列化和反序列化整个对象,操作效率也很高。对于需要频繁修改部分字段(比如菜品销量)的场景,我们使用了 Hash 类型。
(2)Key命名规则
我们采用了清晰的、可读的、统一的命名规范。例如:
商家信息:cache:shop:{id} (例如 cache:shop:10)
菜品信息:cache:dish:{id} (例如 cache:dish:100)
店铺类型列表:cache:shop-type:list
(3)过期时间设置
基础过期时间 + 随机扰动;
商家信息这类变更不频繁的数据,设置基础过期时间为 30分钟;
避免大量缓存同时失效导致雪崩,在基础时间上增加了一个1-5分钟的随机值,让缓存错峰失效;
6、为什么选择"更新数据库后主动删除缓存"而不是更新缓存?或者说为什么不先删除缓存再更新数据库?有没有考虑过延迟双删?
(1)选择删除缓存而不是更新缓存是因为没有必要,下次读请求到来时更新缓存即可,万一下一次读其实很遥远,直接更新缓存有点浪费。
(2)如果先删除缓存,再更新数据库,在并发情况下,线程一删除完缓存后还没更新数据库,但线程二也来访问,且发现缓存中没有数据,读取数据库中旧的数据放入缓存中,此时线程一才更新完数据库,则出现了数据不一致,且这种事件发生的概率大,因为写数据库是慢于写缓存的。
虽然先更新数据库再删除缓存也会出现类似的问题:线程一更新数据库之前,线程二刚好发现缓存不存在,且读取了数据库旧的数据,且线程一更新数据库,并删除缓存之后,线程二才将旧的数据库的信息缓存进去,显然这种情况发生的概率极低,实际中很难出现线程一已经更新了数据库并且删除了缓存,线程二才更新完缓存的情况。
(3)延时双删指的是,对于写操作,先把缓存中的数据删除,然后更新数据库,最后再延时删除缓存中的数据。其中,这个延时多久不太好确定。在延时的过程中,可能会出现脏数据,并不能保证强一致性,所以没有采用它。
7、缓存预热具体是怎么做的?预热的数据来源是什么?预热时机如何选择?
(1)在业务刚上线的时候,我们最好提前把数据缓起来,而不是等待用户访问才来触发缓存构建,这就是所谓的缓存预热。
(2)数据来源:直接从mysql数据库中获取需要预热的数据。主要是两类:静态数据 (如店铺类型列表)和动态热点数据(我们通过后台运营统计出的近期访问量最高的一些商家和菜品)。
(3)实现方法:定时任务,使用Spring的@Scheduled注解定时执行;
(4)预热时机:
每日凌晨低谷期: 定时任务会在每天凌晨2点,当系统流量最低的时候自动运行,预热当天的热点数据。
活动前手动触发: 如果已知第二天有大型促销活动,我们会提前分析出可能的热点商品,并在活动开始前通过管理后台手动执行预热任务,确保活动开始时缓存已是满载状态。
8、其他redis高频问题
(1)双写一致性
(2)Redis持久性
(3)数据过期策略
(4)数据淘汰策略
请参考黑马官方提供的八股文视频教程及八股文链接:Docs