目录
- [为什么连单个 Amazon 商品页都不好抓](#为什么连单个 Amazon 商品页都不好抓)
- [这套架构为什么有效:Bright Data MCP + Dify](#这套架构为什么有效:Bright Data MCP + Dify)
- 前置准备
- [实战:搭建Amazon 商品详情页结构化提取工作流](#实战:搭建Amazon 商品详情页结构化提取工作流)
-
- [Step 1:登录亮数据,获取key](#Step 1:登录亮数据,获取key)
- [Step 2:在 Dify 中添加 Bright Data MCP 工具](#Step 2:在 Dify 中添加 Bright Data MCP 工具)
- [Step 3:创建 Dify工作流](#Step 3:创建 Dify工作流)
- [Step 4:测试结果与对比](#Step 4:测试结果与对比)
- 交付物:拿走就能用
- 成本分析:真正省下的是维护时间
- 总结
我第一次手动做 Amazon 采集的时候,自信得有点过头。
一开始我以为这只是个普通网页抓取任务:给一个商品 URL,拿到标题、价格、评分、评论数,再转成 JSON 就完事了。结果现实很快给我上了一课。商品页结构并不稳定,部分信息动态加载,不同类目字段位置还不一样;更麻烦的是,频繁请求后页面开始出现异常、数据缺失,调试时间远远超过我真正"用数据"的时间。后来我开始换一个思路:既然目标不是炫技写爬虫,而是稳定得到结构化商品数据,那就应该把采集层交给更成熟的基础设施。于是我把 Bright Data MCP 接进了 Dify,整个工作流才终于像一个能长期使用的方案。
这篇文章我会用一个非常聚焦的场景来演示:输入单个 Amazon 商品详情页 URL 或 ASIN,自动提取商品标题、价格、评分、评论数、卖点等信息,并用 LLM 进一步整理成结构化 JSON 和可读摘要。 如果你做跨境电商数据工程、商品入库、选品分析,或者只是想减少手写抓取逻辑,这个方案会比"再维护一套脚本"更实用。你也可以先注册 Bright Data 免费试用,拿到测试额度后直接跟着文末模板跑起来。
为什么连单个 Amazon 商品页都不好抓
很多人第一次看这个需求,会觉得它比"多平台采集"简单得多。表面上确实如此,但 Amazon 商品详情页真正难的地方,不在于能不能拿到 HTML,而在于能不能稳定提取出可复用的数据结构。
| 难点 | 具体表现 |
|---|---|
| 动态渲染 | 价格/库存异步加载,静态抓取拿不到数据 |
| 页面结构差异 | 类目不同导致字段位置乱变,解析规则极易失效 |
| 反爬限制 | 高频请求即封 IP,导致数据缺失或异常 |
| 信息分散 | 核心字段(标题/评分/卖点)分散在不同 DOM 模块 |
| 非结构化 | HTML 源码 ≠ 可入库数据,清洗成本极高 |
我后来发现,真正耗时间的从来不是"抓一次",而是为了后续维护不断修补抓取逻辑。如果只做 demo,脚本当然能跑;但如果目标是做成一个能重复使用的数据工作流,采集稳定性、字段标准化和可扩展性比"有没有代码"重要得多。
这套架构为什么有效:Bright Data MCP + Dify
先用一句话解释 MCP:MCP 就像 AI 工作流和外部工具之间的万能转接头。
在这次方案里,Dify 负责工作流编排,Bright Data MCP 负责把 Bright Data 的采集能力接进来,而 Bright Data 背后处理的则是更复杂的网页访问、反爬、代理和解析问题。
本次实战流程极简清晰:
- 用户输入 Amazon 商品 URL
- Dify Workflow 进行流程编排
- Bright Data MCP Server 处理代理、解封、渲染
- 调用 Bright Data Web Scraper API 抓取 Amazon 页面
- LLM 自动解析字段
- 输出标准结构化 JSON
这套架构的优势包括:
- 一次配置,多平台复用
- 无需维护爬虫逻辑
- 自动处理反爬
- 支持 AI 工作流
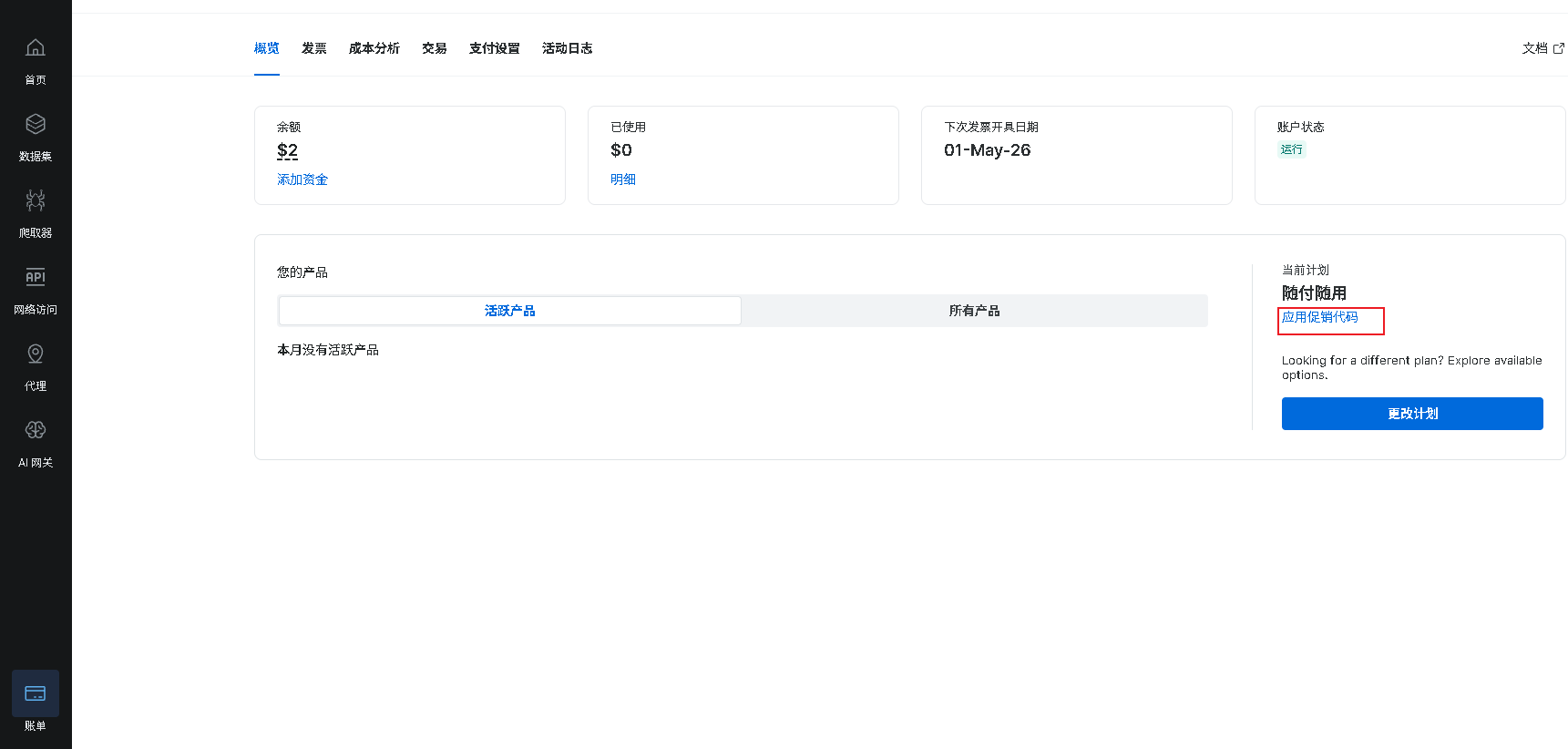
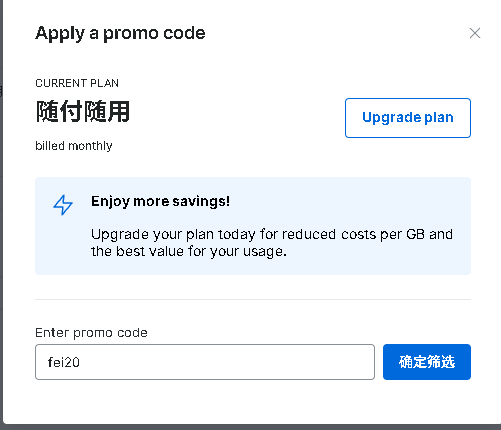
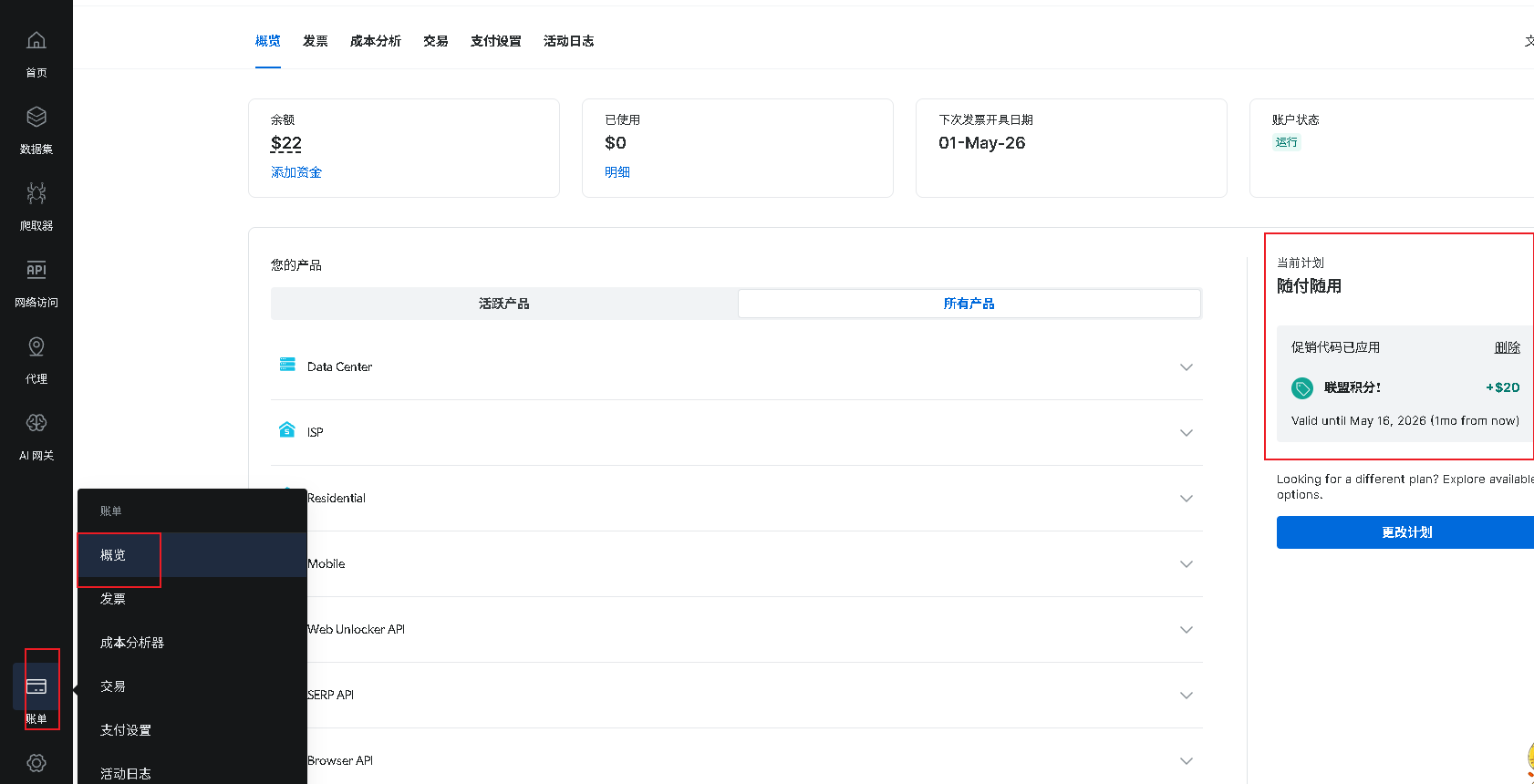
👉 立即免费注册 Bright Data,用这个连结注册输入折扣码可以有20美金的试用,折扣码是fei20。下载本文模板
,5分钟内搭建你的多平台数据采集流水线。只为成功采集的数据付费。
前置准备
开始前,我准备了下面几样东西:
- 一个 Bright Data 账号:你需要注册一个账号来获取 API Key。如果你还没有,可以先通过这个链接注册,用这个链接注册输入折扣码可以有20美金的试用,折扣码是fei20,足够跑很多次请求:点击注册 Bright Data 获取免费额度
- 一个 Dify 账号(云端或自部署都可以,这里博主使用云端的方式)
- 大模型的api
- 基础认知:了解什么是 API,和MCP(Model Context Protocol)的基本概念。以及基本的 Dify 工作流操作能力。(本文会手把手教)
Bright Data后台输入折扣码位置:
实战:搭建Amazon 商品详情页结构化提取工作流
接下来是干货环节------我会按实际搭建流程,逐一展示操作步骤,让读者能直接复现并应用。
Step 1:登录亮数据,获取key
https://get.brightdata.com/mcpserver-fei
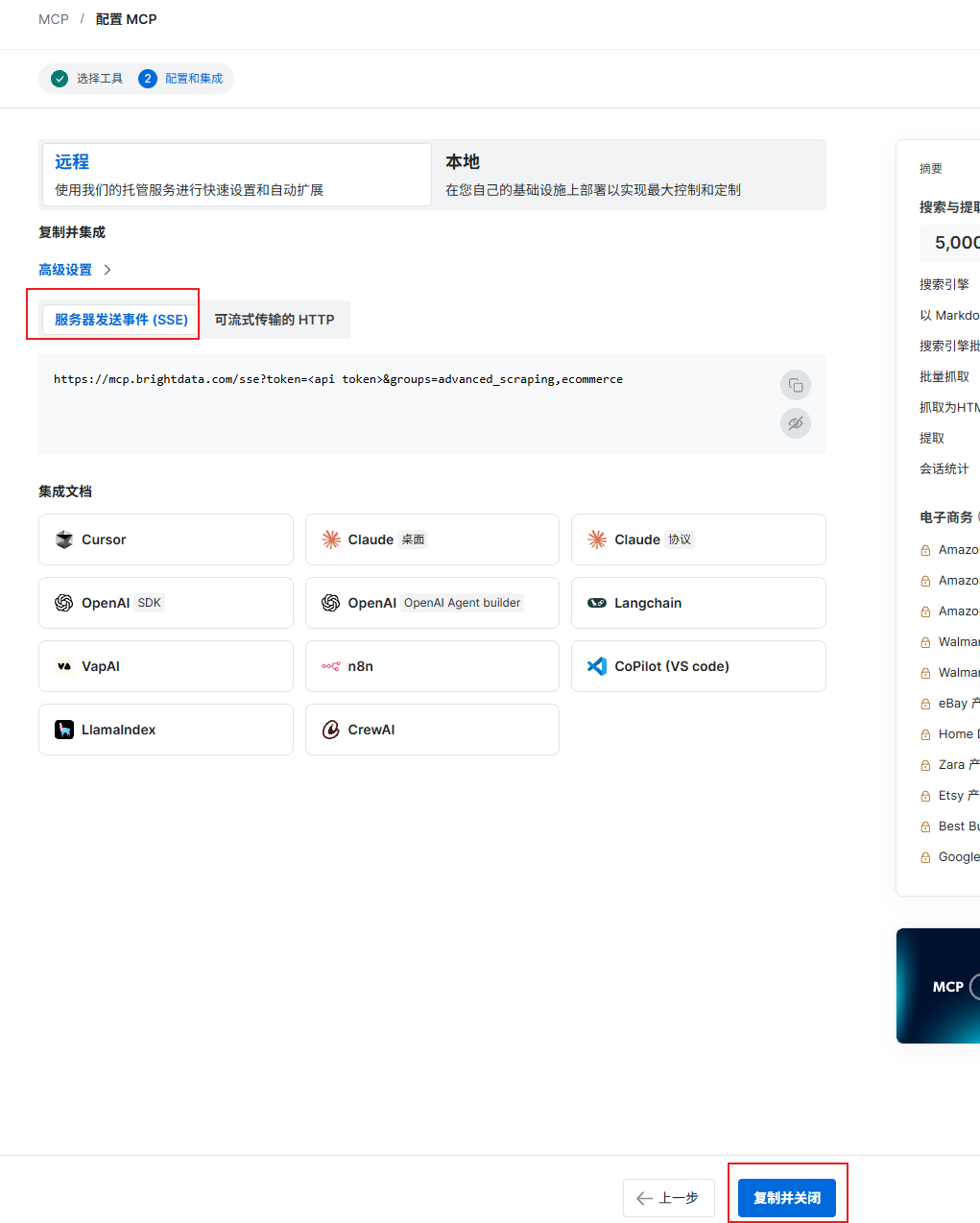
登录 Bright Data 控制台,进入 MCP 配置页面,勾选电子商务,并且点击继续配置,获取sse地址。
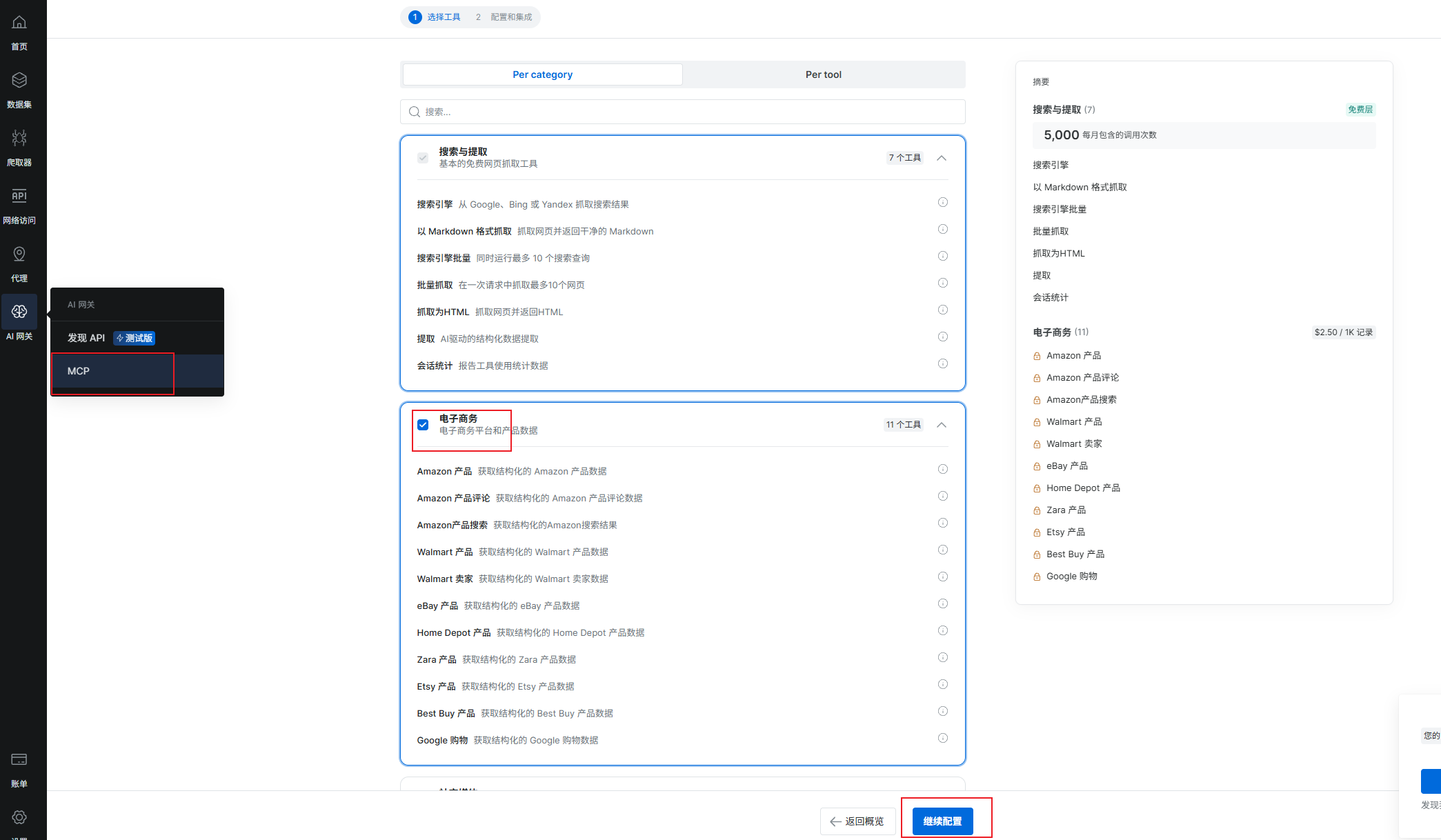
点击复制并关闭
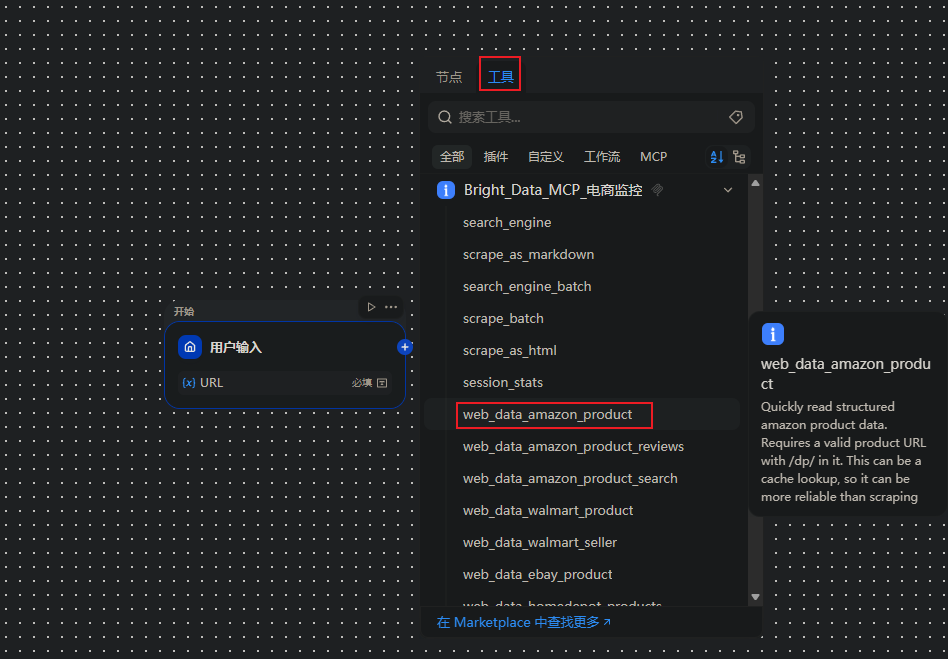
Step 2:在 Dify 中添加 Bright Data MCP 工具
打开 Dify → 工具 → 添加MCP服务 ,粘贴sse链接,输入自定义名称、唯一标识,点击添加并授权。连接成功后,即可在工作流中直接调用 Bright Data 采集能力。
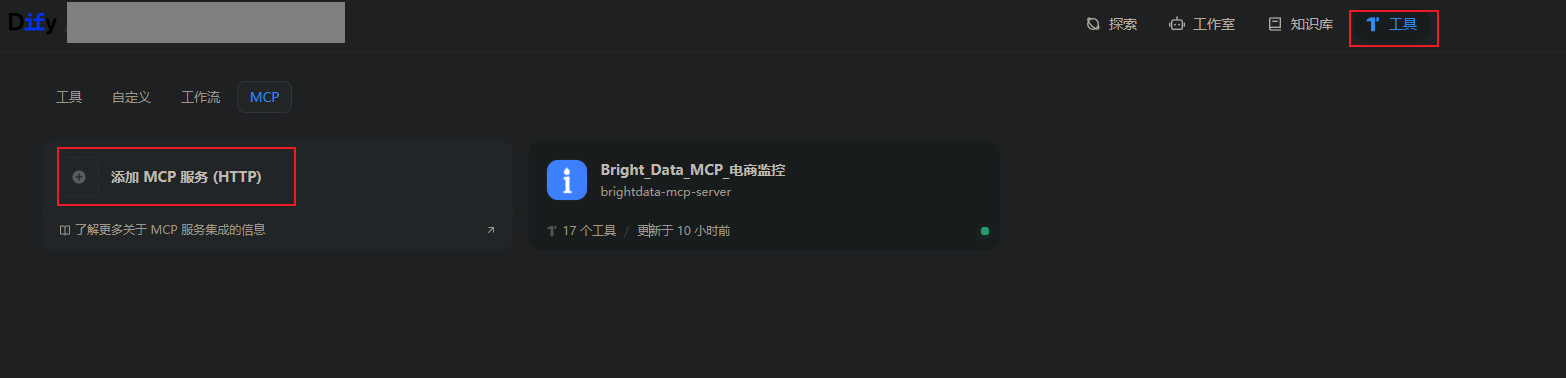
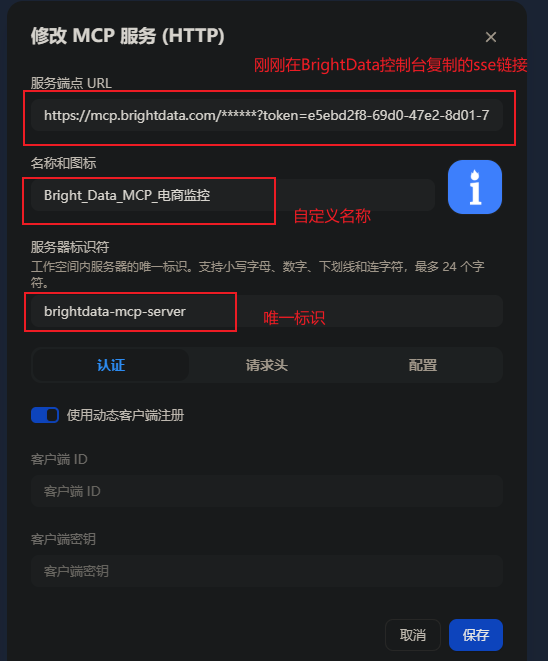
这一步的意义非常大:
之后工作流里不再需要自己拼代理、处理请求细节,而是把采集当成一个标准工具节点来用。
Step 3:创建 Dify工作流
在工作室创建一个空白应用的工作流(如果你不想一步一步配置,文末会提供博主的DSL文件,可直接下载导入)

工作流节点设计如下:
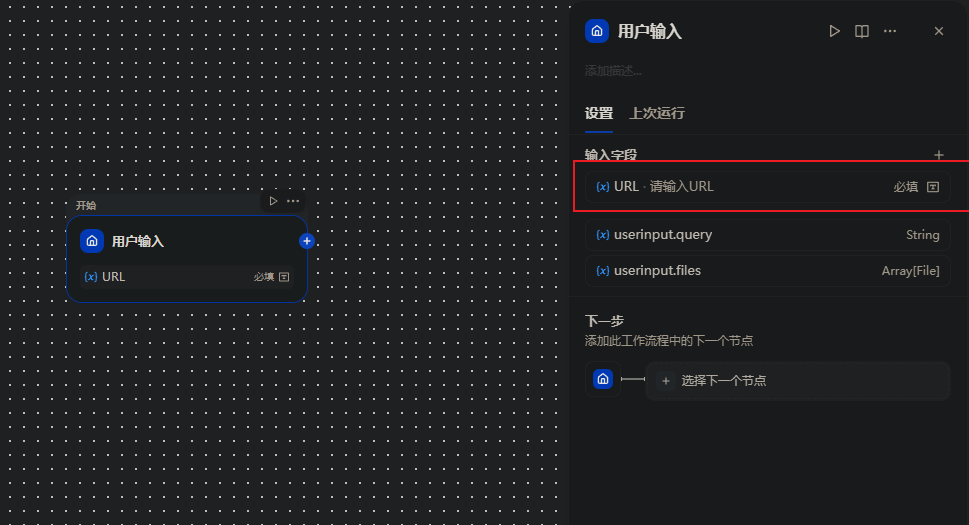
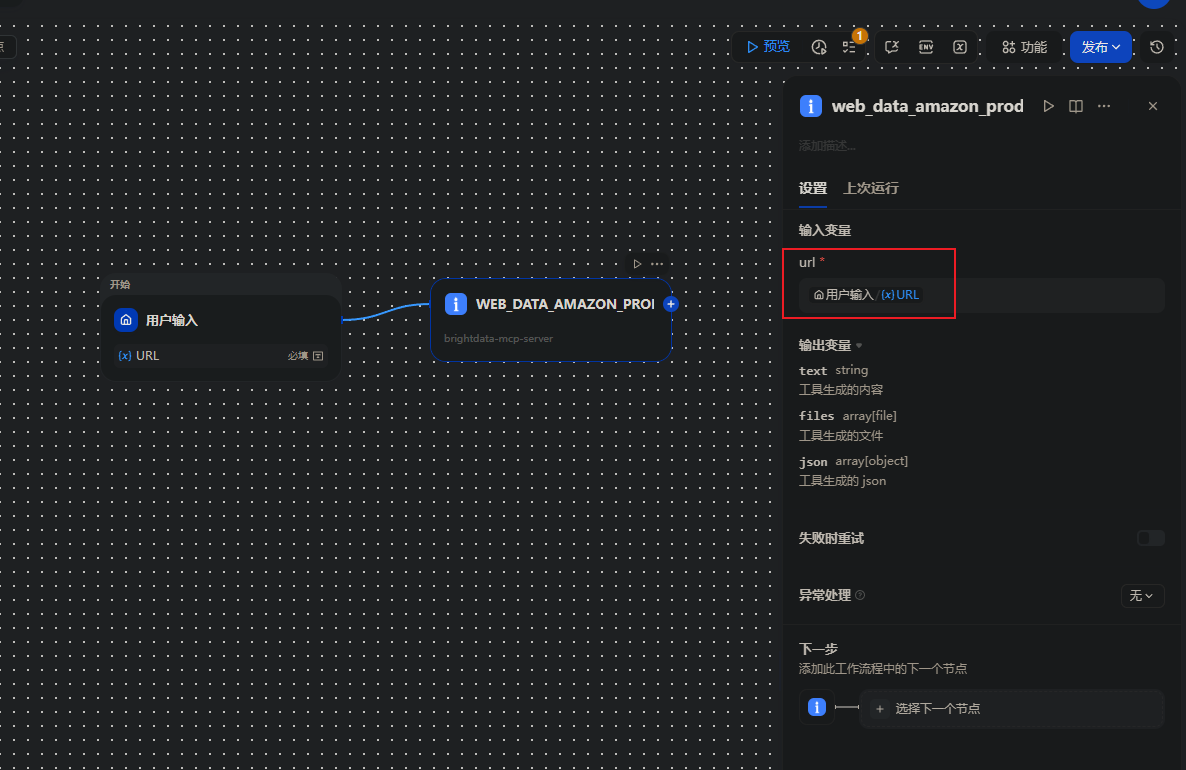
1.输入节点:添加「文本输入」,接收 Amazon 商品详情页 URL
2.MCP 工具节点:选择 Bright Data Web Scraper API,传入目标 URL
3.LLM 节点:提取标题、价格、评分、销量、品牌、卖点等
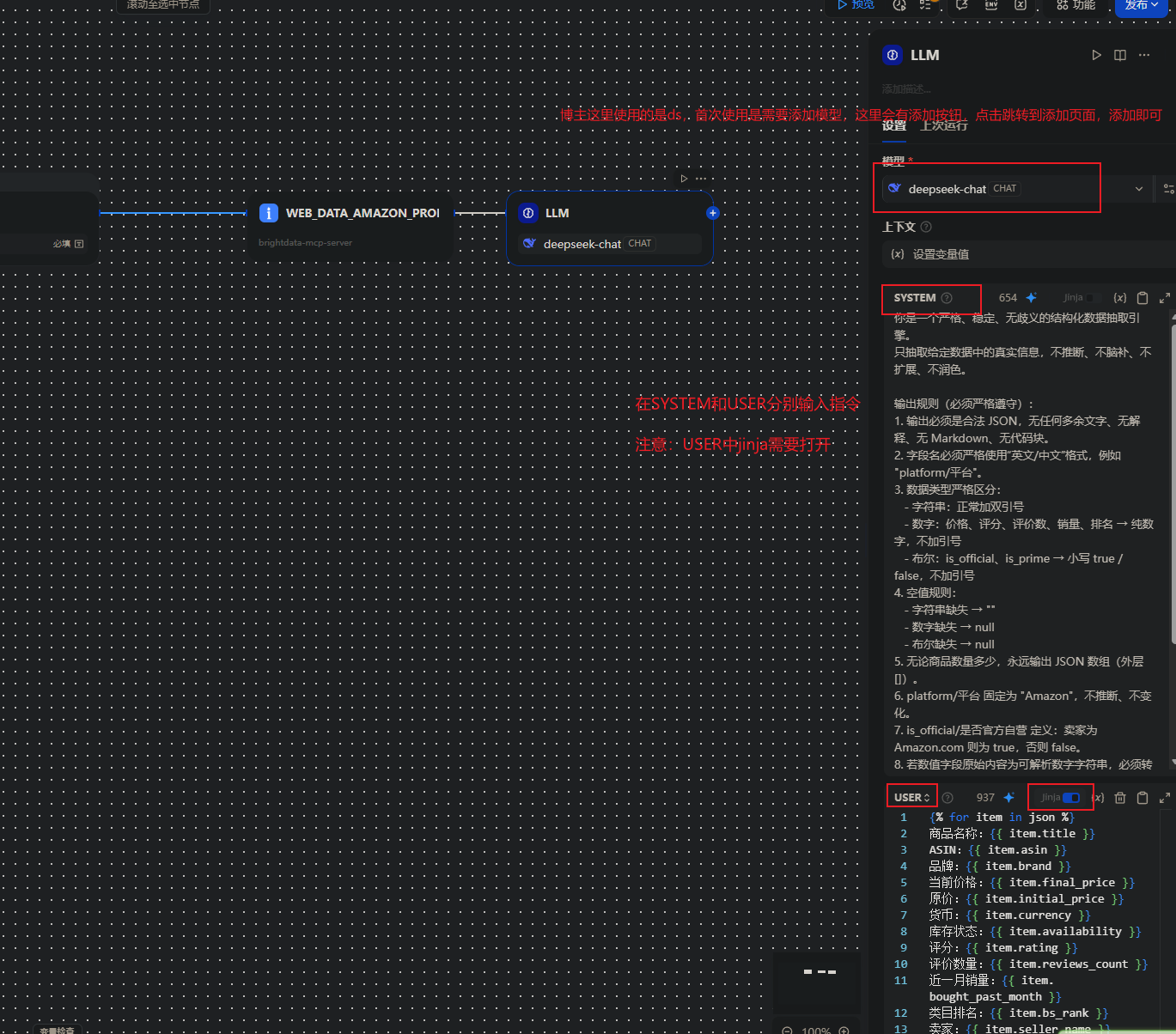
设置结构化输出:
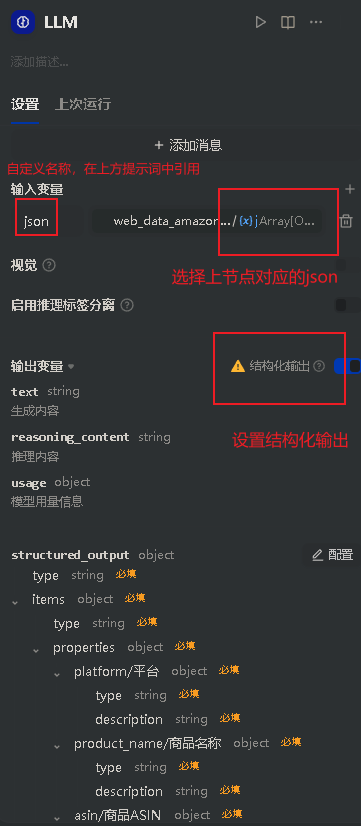
4.输出节点:输出标准结构化 JSON
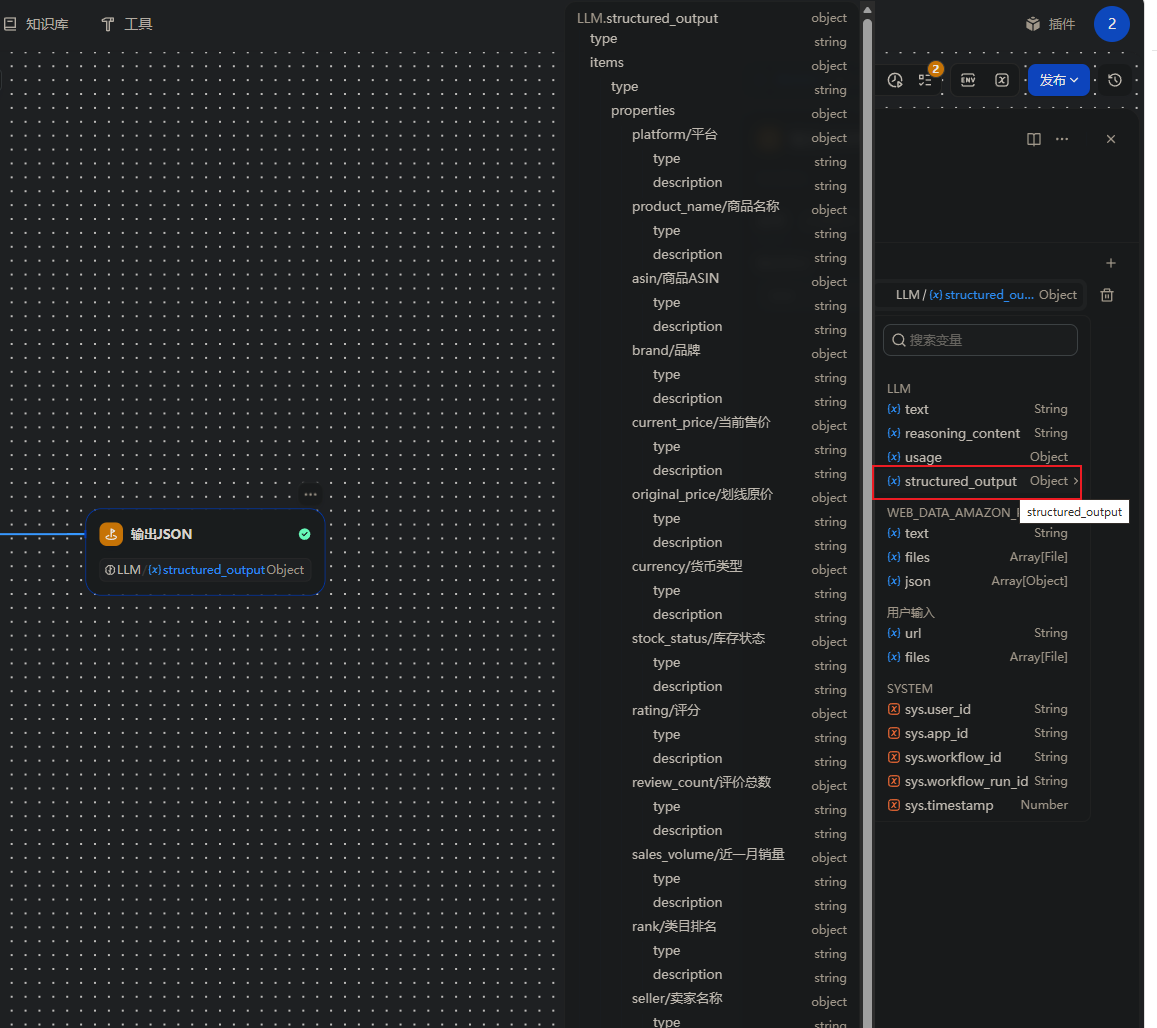
5.输出节点:输出CSV文本
针对上游节点输出的 JSON 数据,我们在最后添加了一个代码节点。通过运行博主提供的 Python 脚本,将非结构化的 JSON 列表序列化为结构清晰的 CSV 文本,以便后续导出使用。
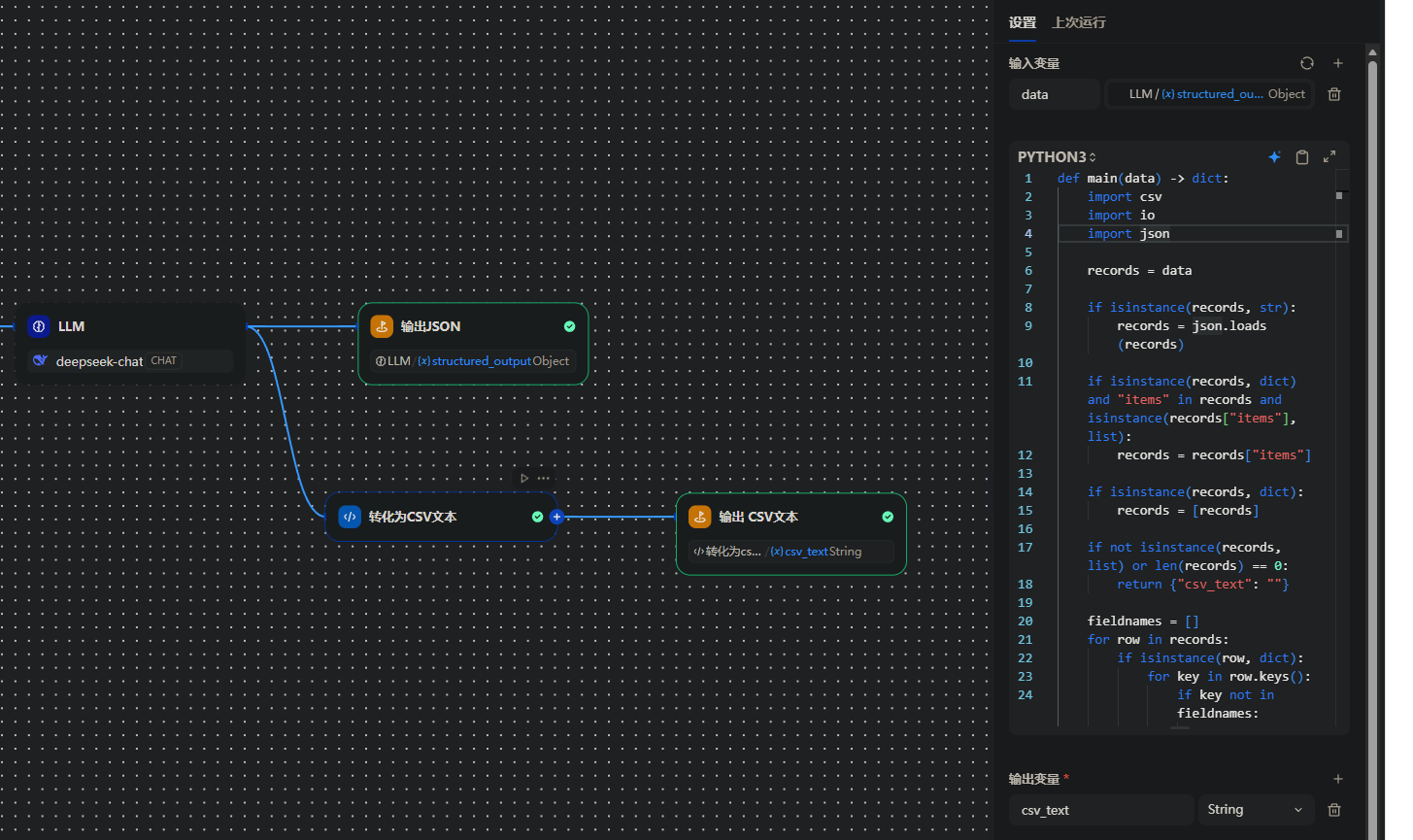
执行结果:
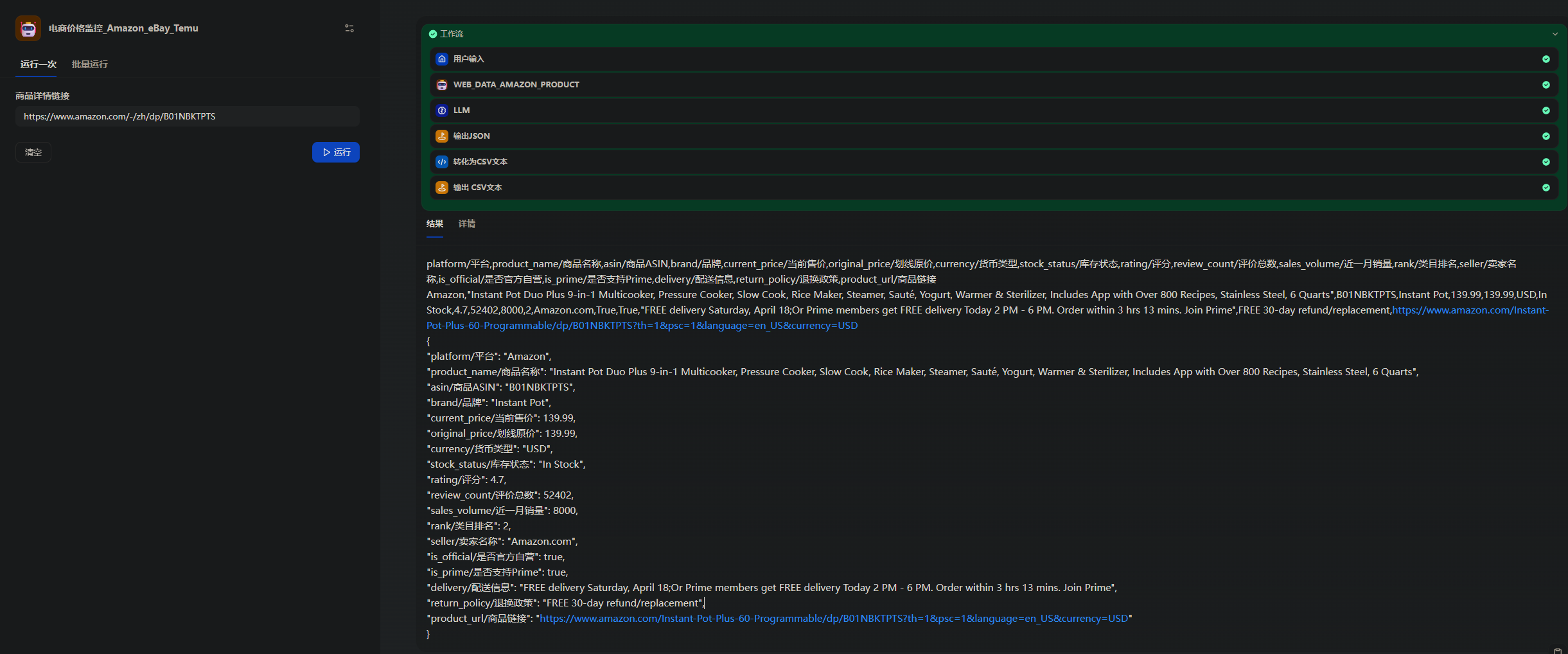
拿到标准化的 Amazon 商品 JSON 后,这套工作流已经完成了最核心、最难的数据采集与结构化解析。基于这份干净的 JSON 数据,你可以在 Dify 中继续扩展出价格监控、竞品对比、库存预警、Listing 优化、选品库沉淀等真实业务场景,全程无需重新编写爬虫,只需增加判断、定时、报表或通知等轻量节点,即可将数据转化为可直接落地的运营决策。
Step 4:测试结果与对比
我用同一个商品页分别测试了"自己写脚本解析"和"Bright Data MCP + Dify 工作流"两种方案。虽然这里只演示单商品详情页,但差距依然很明显。
👉 立即免费注册 Bright Data,用这个连结注册输入折扣码可以有20美金的试用,折扣码是fei20。下载本文模板
,5分钟内搭建你的多平台数据采集流水线。只为成功采集的数据付费。
| 指标 | DIY 脚本 | Bright Data MCP + Dify |
|---|---|---|
| 首次可用时间 | 数小时到数天 | 30 分钟内 |
| 字段稳定性 | 易受页面变化影响 | 高 |
| 维护成本 | 持续修规则 | 很低 |
| 扩展到更多字段 | 要继续改代码 | 改提示词即可 |
| 输出可读性 | 偏原始 | 可直接生成结构化摘要 |
最明显的变化是:我终于不用把"抓页面"当成本职工作了。
👉 立即免费注册 Bright Data,用这个连结注册输入折扣码可以有20美金的试用,折扣码是fei20。下载本文模板
,5分钟内搭建你的多平台数据采集流水线。只为成功采集的数据付费。
交付物:拿走就能用
本文提供可直接下载导入的 Dify 工作流模板:
- workflow_amazon_price_monitor.yml(Amazon 商品详情采集模板)
- README.md(配置说明)
下载链接:https://github.com/youyoufeifei/amazon-product-data-collection-workflow.git
下载模板文件后,在 Dify 中导入,会发现两处异常,如下图:
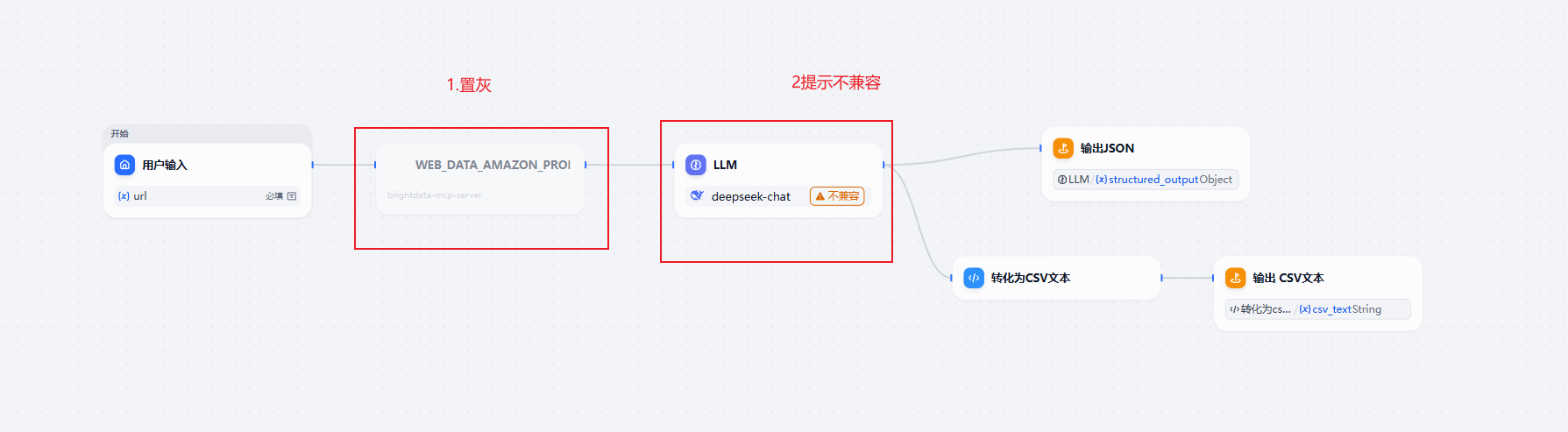
1.置灰原因
Bright Data MCP 工具在 Dify 中的名称与服务器标识符与模板的不一致导致的
解决方法1:
修改 Bright Data MCP 工具的名称与服务器标识符,与模板的保持一致;随后刷新页面,重新导入即可。
模板的mcp配置:
名称:Bright_Data_MCP_电商监控
服务器标识符:brightdata-mcp-server
解决方法2:点击该节点右上角三个点,选择更改节点->工具->web_data_amazon_produc;随后在输入变量中选择用户输入的url即可。
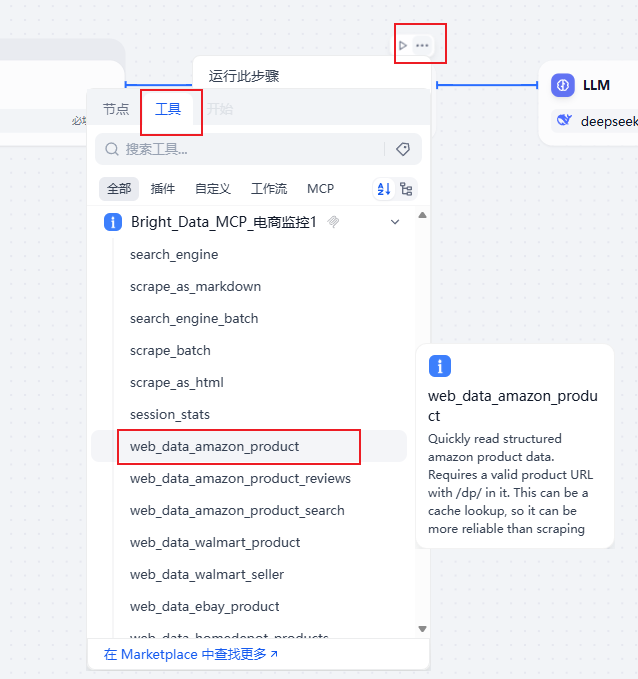
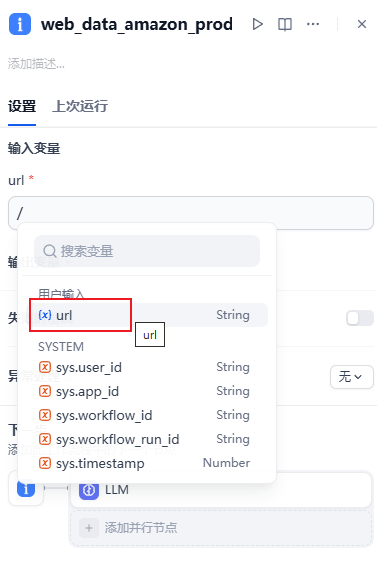
2.模型不兼容
模板默认使用我的数据源(DS)与模型,导入后请:
进入 LLM 节点
将模型切换为你已配置好的自己的模型
若未配置模型,需先在 Dify 后台完成模型接入,否则工作流会报错。
并且在LLM节点下方,json的变量值需要重新选择。
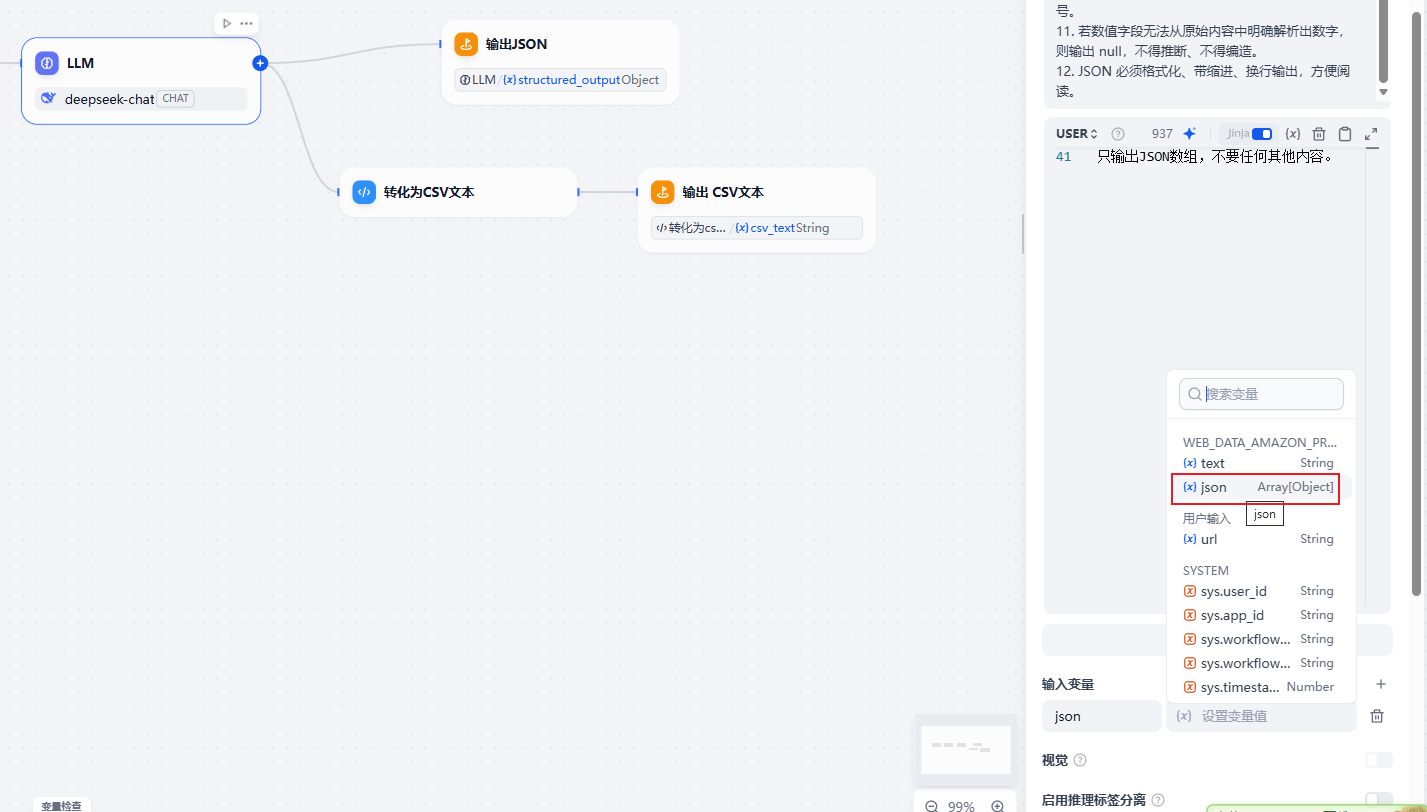
成本分析:真正省下的是维护时间
如果只看"抓一个 Amazon 页面",很多人会低估维护成本。现实是,DIY 方案真正贵的地方不在请求本身,而在:
- 规则失效后的修复时间
- 不稳定数据带来的重复验证
- 工程师持续维护的隐性成本
对比下来更像是这样:
| 方案 | 前期投入 | 月均维护 | 成本结构 |
|---|---|---|---|
| 自建脚本 | 快则几小时,复杂则几天 | 持续修补 | 工程时间成本高 |
| Bright Data MCP + Dify | 不到 1 天 | 很低 | 按成功采集付费 |
对我来说,这种模式最大的优势不是"更便宜"三个字,而是更可控。
尤其当你的目标是做商品入库、选品分析、数据标准化时,稳定性通常比"自己写了多少代码"重要得多。
总结
这次实战的 3 个核心结论:
- 价值在结构化:单商品页也值得工作流化,核心在于清洗而非抓取。
- 解放生产力:Bright Data MCP 解决采集层难题,告别脆弱的爬虫维护。
- 流水线思维:Dify 将提取、清洗、摘要串联,实现数据复用。
如果你也想把 Amazon 商品页转成结构化 JSON、CSV 或商品摘要,而不是继续在脚本细节里消耗时间,可以先注册 Bright Data 试用额度,然后直接导入本文模板,五分钟内跑通你自己的 Amazon 数据采集 AI 工作流。
👉 立即免费注册 Bright Data,用这个连结注册输入折扣码可以有20美金的试用,折扣码是fei20。下载本文模板
,5分钟内搭建你的多平台数据采集流水线。只为成功采集的数据付费。
👉 下载本文配套 Dify Workflow Template:
https://github.com/youyoufeifei/amazon-product-data-collection-workflow.git