一句话总结
现有 Agent Skill 要么手写、要么由 LLM 一次性生成或者无约束自修改,SkillOpt 把技能文档视为可训练的外部状态,用有界编辑 + 验证门控 + 拒绝缓冲 + 慢速更新构成完整的文本空间优化器,在 52 个评测格子上达到全部最优
- 论文标题:SkillOpt: Executive Strategy for Self-Evolving Agent Skills
- 论文地址 :https://arxiv.org/abs/2605.23904
- 作者背景:微软、上海交通大学、同济大学、复旦大学
- 代码地址 :https://github.com/microsoft/SkillOpt
一、动机
前沿语言模型越来越多地被部署为 Agent ------ 不只是回答问题,而是多步执行:调用工具、读写文件、遵循领域规范、格式化输出。在这种场景下,领域适配的核心对象不再是模型权重或 prompt 片段,而是 Agent 执行任务时依赖的程序性知识
Agent Skill 是这种程序性知识的自然载体:一段自然语言文档,打包了工具使用策略、领域启发式规则、输出约束和失败模式处理。模型参数冻结不动,通过外挂不同的 skill 文档来适配不同领域 ------ 类似于神经网络中的适配层
但现有的 skill 获取方式都有硬伤:
- 手写: 脆弱、覆盖不全、不可泛化
- LLM 一次性生成: 没有反馈闭环,质量不可控
- LLM 无约束自修改: 可能擦除有用规则、过拟合局部失败
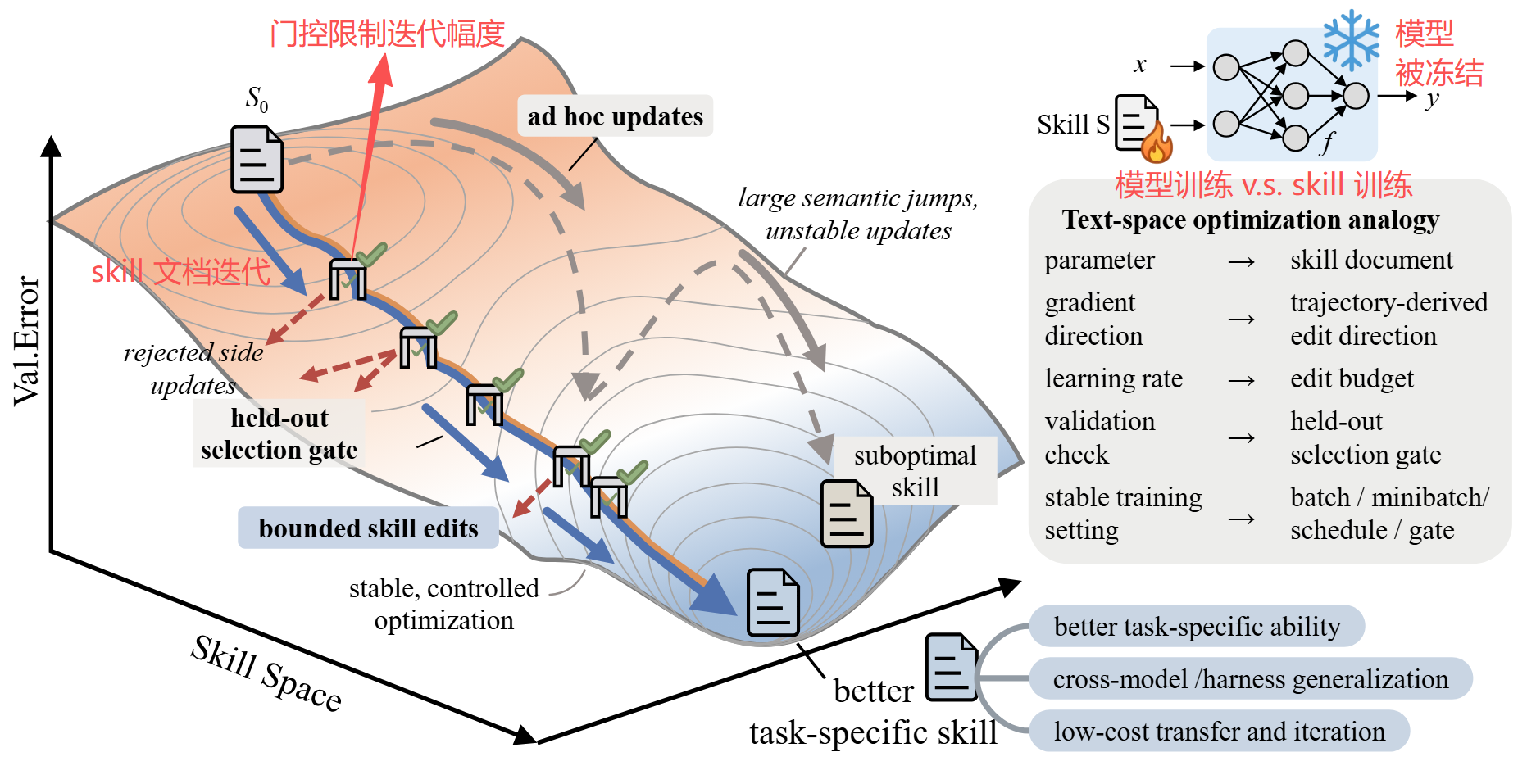
这三种方式的共同缺陷是:没有一个可控的迭代机制。不像训练神经网络时,有 learning rate 控制每步改多少、有 validation 防止过拟合、有 momentum 保持方向稳定;但在文本空间里,没有人做过类似的事
SkillOpt 的核心观点:既然 skill 是 Agent 的适配层,它就应该被当作可训练对象来优化,而不是一个手工产物
二、核心思路
SkillOpt 刻意模仿深度学习的训练范式,但把操作对象从数值权重替换为自然语言文档。这个类比不是修辞,而是真正的设计蓝图 ------ 每个环节都有明确的文本空间对应物:
| 深度学习概念 | SkillOpt 对应 |
|---|---|
| 前向传播 | 用当前 skill 执行一批任务,收集轨迹和分数 |
| 反向传播 | Optimizer 模型分析轨迹,生成结构化编辑提案 |
| Learning Rate | 编辑预算:每步最多改几条规则 |
| Validation | 在 held-out 集上验证,只有严格提升才接受 |
| Momentum | 跨 epoch 的 slow update:保留长期稳定的编辑方向 |
| 负反馈 | Rejected-edit buffer:失败编辑供后续参考 |
整个循环:target model 执行 → optimizer model 反思 → 提出编辑 → 裁剪到预算 → 验证门控 → 接受或拒绝。部署时只留下一个 完成迭代的 best_skill.md(300~2k token),零额外推理开销
三、实现方案
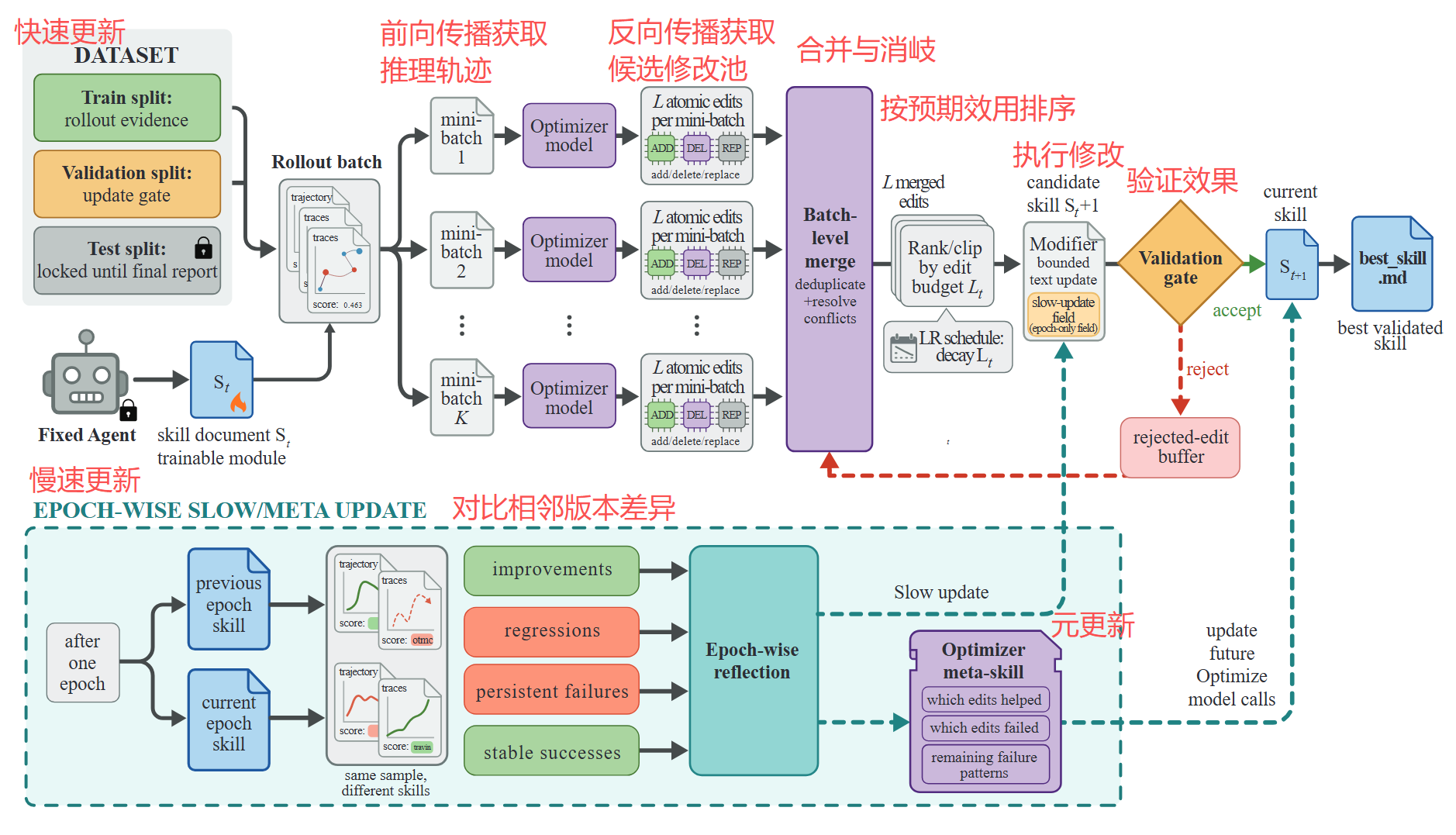
3.1 前向传播
每步从训练集采样一批任务,target model 带着当前 skill 执行。执行框架(harness)记录完整轨迹:消息、工具调用、观察结果、最终答案、验证反馈。这批轨迹就是本步的 "梯度信号" 来源
3.2 反向传播
一个独立的前沿 LLM 充当 optimizer(只在离线训练时运行,部署时不参与)。它将轨迹转化为 skill 编辑:
- 把失败和成功轨迹分开,各自切成 minibatch
- 失败 minibatch 暴露反复出现的系统性错误(比如 Agent 总是搜索了错误来源、写错答案格式、不验证工具返回)
- 成功 minibatch 保留已经有效的行为模式
- 每个 minibatch 返回结构化的 add / delete / replace 编辑
- 层次化合并:先组内去重,再跨组合并(失败修正优先)
为什么用 minibatch 而不是逐条分析?单条轨迹容易产生 "个案补丁",即只对特定问题做针对性修复。Minibatch 能暴露反复出现的系统性错误模式,生成的规则才是可泛化的
3.3 编辑预算
合并后的编辑池被 optimizer 按预期效用排序,然后截断到预算上限(比如每步最多改 4 条规则)。这是和无约束重写的关键区别:
- 无约束重写可能一次擦除有用规则、引入矛盾指令、或过拟合到某个局部失败
- 有界更新保持连续性,每一版 skill 和上一版足够接近,后续 optimizer 才能从版本历史中学习
3.4 验证门控
每个候选 skill 必须在 held-out 集上评估。只有严格大于当前最高分才被接受,平局也算拒绝。这个门控非常保守,保证 skill 不会静默漂移
被拒绝的编辑不是浪费,它们会进入 rejected-edit buffer,后续 reflection 会看到 "之前试过什么、为什么没用",避免重复走老路
3.5 长期方向
除了上述直接学习当前 batch 教训的流程以外,SkillOpt 还模仿了优化算法中的动量概念,以 "慢速更新" 的方式学习跨 epoch 的长期规律
每个 epoch 结束时,系统会对比前后表现,将稳定的编辑方向写入一个受保护字段,后续 step 级别的编辑不能覆盖它
短期波动不会冲掉长期积累的经验。
四、实验结果
4.1 实验设置
- 6 个 benchmark:SearchQA、SpreadsheetBench、OfficeQA、DocVQA、LiveMath、ALFWorld
- 7 个 target model:GPT-5.5 / 5.4 / 5.4-mini / 5.4-nano / 5.2、Qwen3.5-4B、Qwen3.6-35B-A3B
- 3 种执行模式:直接 chat、Codex harness、Claude Code harness
- 7 个 baseline:No skill、Human skill、LLM skill、Trace2Skill、TextGrad、GEPA、EvoSkill
4.2 主实验
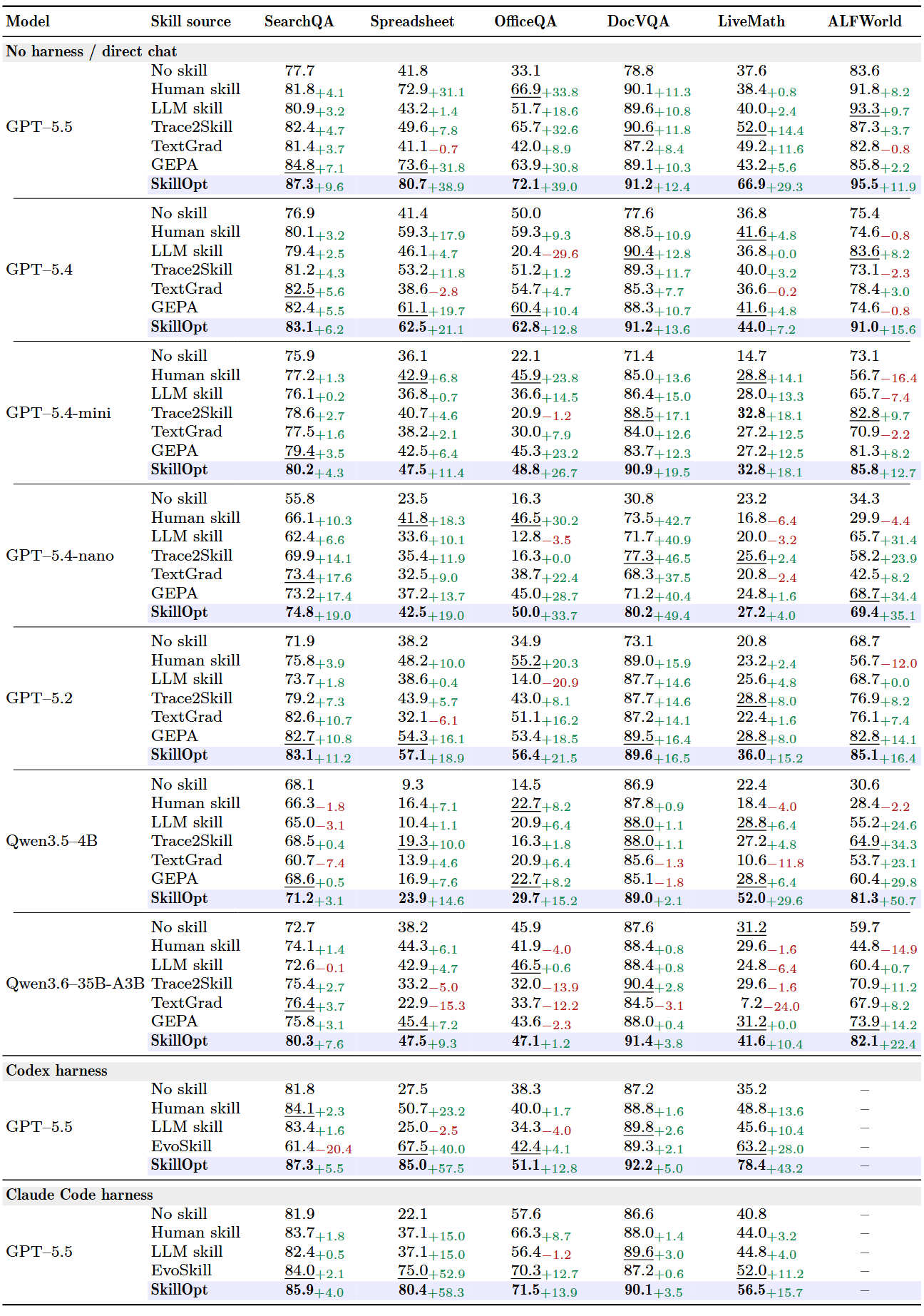
52 个 (模型×benchmark×harness) 格子全部最优或并列最优。
GPT-5.5 在直接 chat 模式下,六个 benchmark 平均从 58.8 提升到 82.3(+23.5 分)。把每个格子最强的 baseline 挑出来构成 oracle,SkillOpt 平均还高 +5.4 分。
程序性任务收益最大,这类任务有严格格式要求和多步工具调用,正是 skill 能发挥最大价值的地方
小模型收益相对更大:GPT-5.4-nano 在 DocVQA 上接近翻倍、ALFWorld 上接近翻三倍。这说明小模型不是缺能力,而是缺程序性纪律,一个简洁的 skill 就能弥补
4.3 消融实验
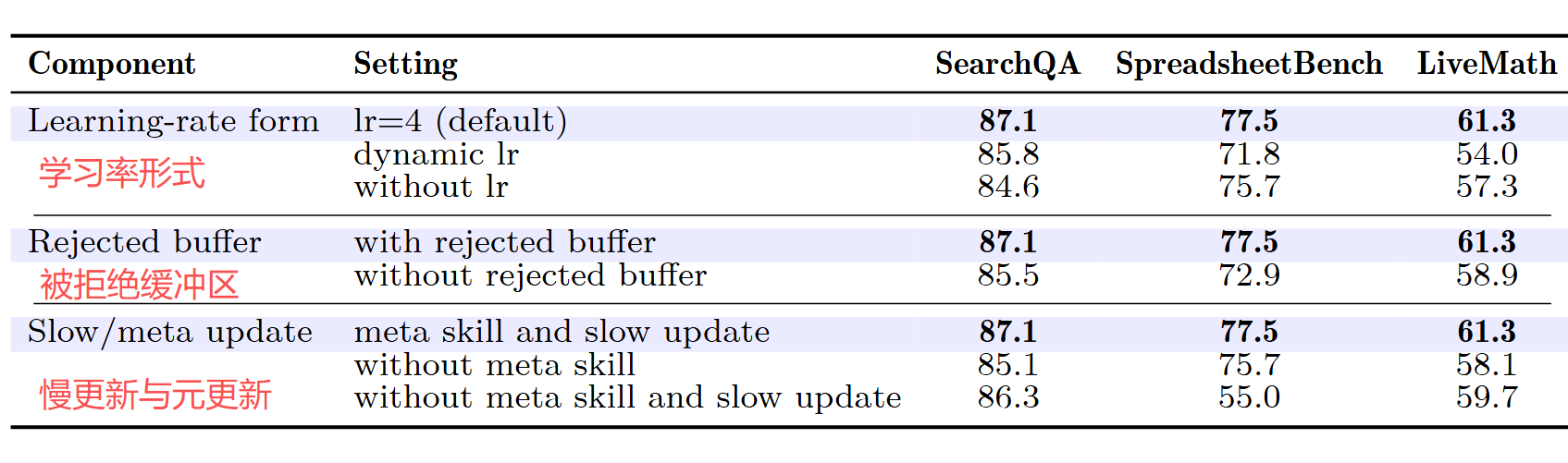
Slow update 的衰退最为剧烈,是消融中最大的一项,说明跨 epoch 的长期记忆对程序性任务至关重要。相比之下,具体用什么 batch size 或 schedule 影响不大,性能在合理范围内都很稳定
4.4 泛化性
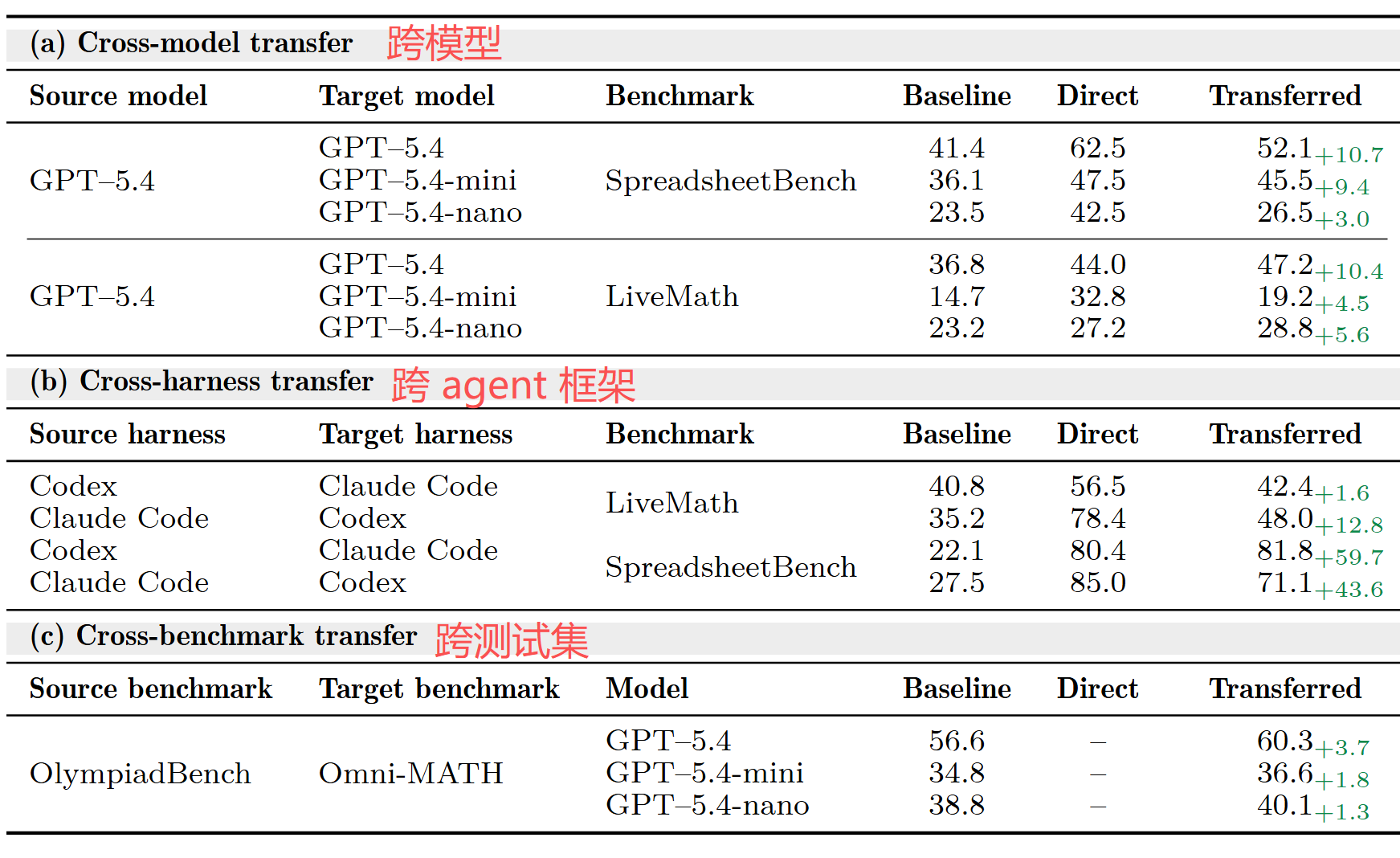
Codex 训练的 SpreadsheetBench skill 迁移到 Claude Code 后,甚至超过了 Claude Code 的 in-domain 优化结果(81.8 vs 80.4)。这说明 skill 编码的是领域级程序性知识,不是某个执行环境的特定命令配方
4.5 Skill 产物分析
各 benchmark 下代表性的学成规则:

实际运行中,skill 文档一般只接受了 1-4 次编辑,最终文档也不会无序膨胀(token 数 379 ~ 1995,中位数在 920 左右),因为 validation gate 做了严格筛选,最终只有极少数通过了 held-out 检验。但最终提升是巨大的
五、启发
- Skill-as-trainable-state:把 skill 当权重训练而非手工维护,是 Agent 领域适配的新范式
- 有界更新 + 验证门控 = 稳定优化:这是文本空间优化能够稳定工作的关键。无约束重写不仅不稳定,还可能擦除好的规则
- 小模型的性能潜力:像 gpt-nano 这种小尺寸模型,在经过 1-4 次编辑后得到了几十分的提升。这说明它很多时候不是能力不够,而是缺少程序性纪律,并且这能通过优化 skill 文档来弥补
- Skill 是领域知识,不是环境命令:跨模型、跨 harness、跨 benchmark 的正向迁移证明了这一点
局限:目前 validation gate 依赖可自动评分的 benchmark。对于开放式任务(写作、创意类),没有明确的正确答案来做门控,需要探索偏好驱动或无奖励的验证方式