算法进阶:哈夫曼编码、红黑树与B树核心解析
前言
本文基于课程内容,聚焦数据结构中哈夫曼树与编码压缩 、红黑树的平衡原理 、B树/B+树的磁盘存储优化逻辑三大核心模块。
一、哈夫曼树与哈夫曼编码:无损数据压缩原理
哈夫曼树(最优二叉树)是带权路径长度(WPL)最短的二叉树,也是无损数据压缩的核心基础,课程通过完整案例演示了其构建与编码流程。
1.1 核心概念与构建规则
- 关键定义 :
- 节点权值:代表数据的出现频次/重要程度
- 路径长度:根节点到该节点的边数
- 带权路径长度(WPL):所有叶子节点的「权值 × 路径长度」之和,WPL越小,树的压缩效率越高
- 构建步骤 :
- 按权值从小到大排序所有叶子节点
- 取权值最小的两个节点合并为新节点,新节点权值为两节点之和
- 将新节点放回序列重新排序,重复步骤2,直到只剩一个根节点
1.2 哈夫曼树实操与WPL计算
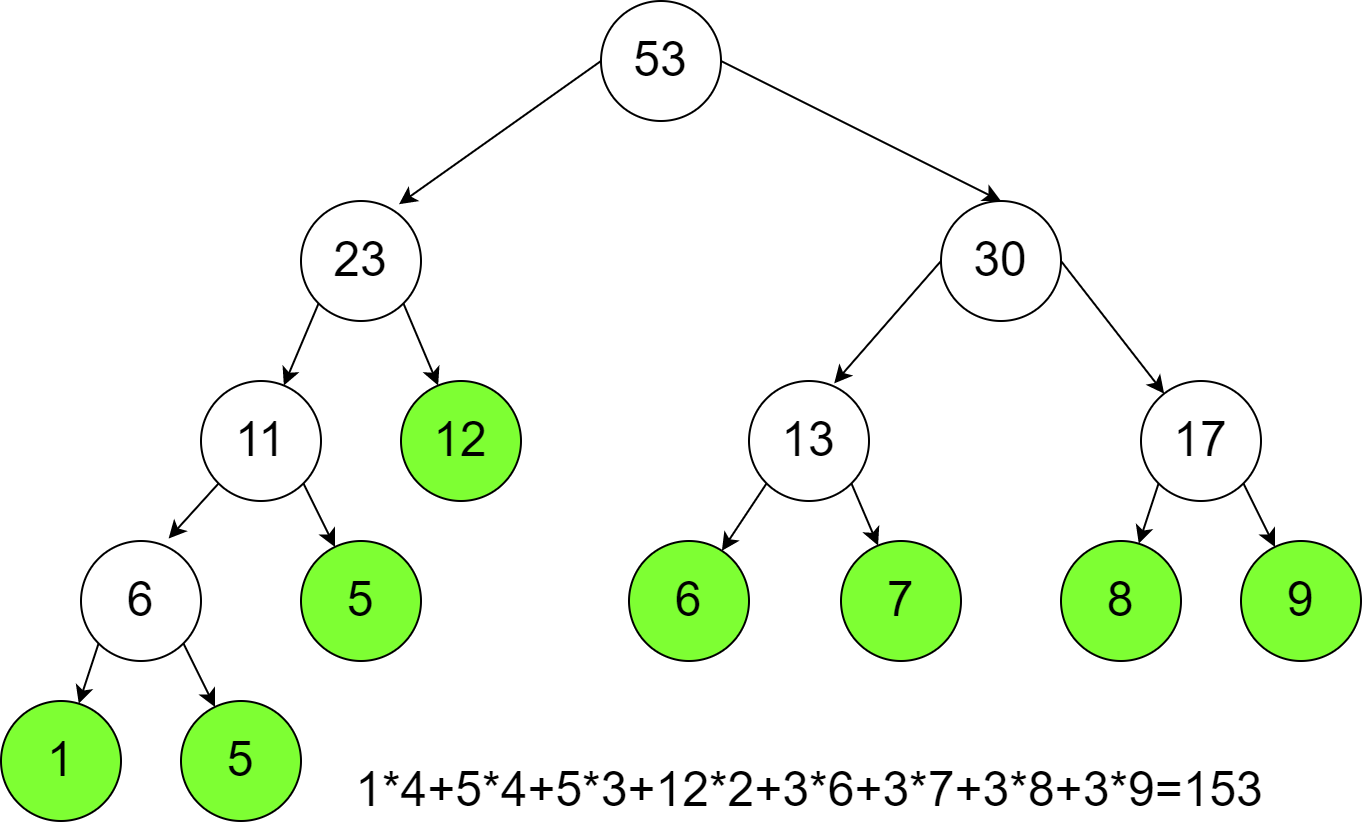
图中绘制的哈夫曼树中,叶子节点权值为1、5、5、12、6、7、8、9,完整WPL计算如下:
WPL=1×4+5×4+5×3+12×2+6×3+7×3+8×3+9×3=4+20+15+24+18+21+24+27=153 \begin{align*} \text{WPL} &= 1 \times 4 + 5 \times 4 + 5 \times 3 + 12 \times 2 + 6 \times 3 + 7 \times 3 + 8 \times 3 + 9 \times 3 \\ &= 4 + 20 + 15 + 24 + 18 + 21 + 24 + 27 \\ &= 153 \end{align*} WPL=1×4+5×4+5×3+12×2+6×3+7×3+8×3+9×3=4+20+15+24+18+21+24+27=153
该值即为整棵树的带权路径长度,代表了编码的理论总长度。
1.3 哈夫曼编码与压缩实现
哈夫曼编码是一种不定长前缀编码 ,核心逻辑是:高频字符分配短编码,低频字符分配长编码,且无任何编码是其他编码的前缀,避免解码歧义。
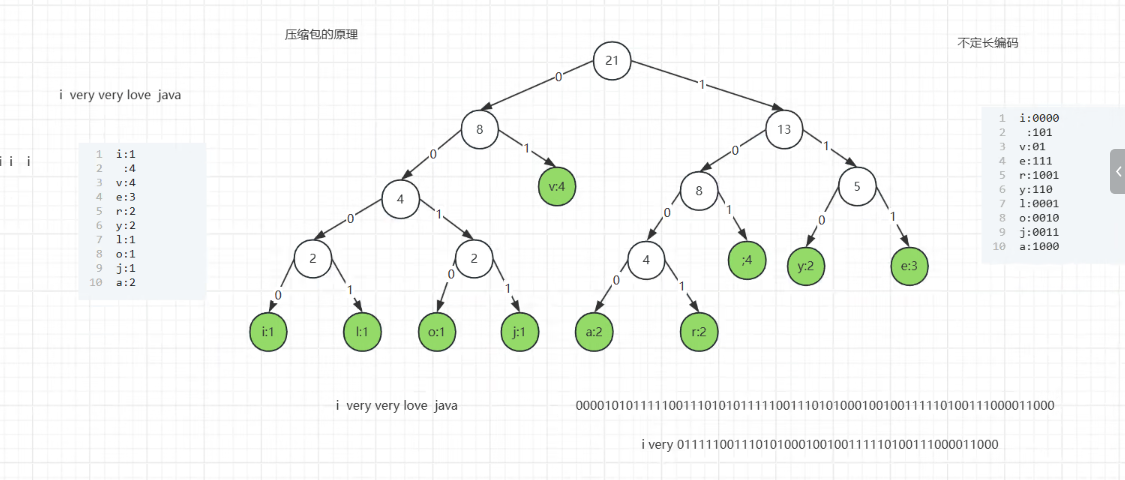
- 案例文本
i very very love java的编码流程:- 统计字符频次,生成权值表
- 构建哈夫曼树,约定左分支为
0、右分支为1 - 遍历树生成编码,如
i:0000、空格:101、v:01
- 压缩效果对比:定长ASCII编码总长度为
21×8=168位,哈夫曼编码仅需约60位,压缩率超60%,这就是ZIP等压缩工具的底层原理。
二、红黑树:工业界的实用平衡二叉树
红黑树是一种自平衡的二叉搜索树,相比AVL树,它放弃了严格的高度平衡,通过颜色规则保证了近似平衡,实现了更高的插入/删除效率,是Java TreeMap、HashMap的核心底层结构。
2.1 红黑树的五大核心性质
- 每个节点要么是红色,要么是黑色
- 根节点必须是黑色
- 所有叶子节点(NIL节点)都是黑色
- 红色节点的两个子节点必须都是黑色(即不能有连续的红色节点)
- 从任一节点到其所有叶子节点的路径上,黑色节点的数量相同(黑高一致)
2.2 性质带来的平衡效果
红黑树不限制左右子树的高度差,但通过上述规则,保证了从根到叶子的最长路径不超过最短路径的2倍,从而确保查询、插入、删除的时间复杂度稳定在O(logn),同时避免了AVL树频繁旋转带来的性能开销。
2.3 红黑树的调整机制
当节点插入/删除破坏红黑树性质时,会通过以下两种方式恢复平衡:
- 变色:修改节点颜色,解决连续红色节点或黑高不一致问题
- 旋转:结合变色操作,通过左旋/右旋调整树结构,恢复平衡
三、B树与B+树:磁盘存储的优化利器
B树(多路平衡查找树)及其变体B+树,是数据库索引、文件系统的核心数据结构,其设计完全针对磁盘I/O的性能瓶颈优化。
3.1 磁盘存储的性能痛点
磁盘的机械臂寻址时间远大于内存访问时间,一次随机磁盘I/O的耗时约为内存访问的10万倍。因此,减少磁盘I/O次数,是优化存储性能的核心目标。
3.2 B树的核心结构与优化逻辑
B树是一种多路平衡查找树,核心设计特点:
- 每个节点存储多个关键字(最多
m-1个,m为阶数),并对应m个子节点指针 - 节点内的关键字有序排列,支持多路查找
- 所有叶子节点位于同一层,树的高度远低于二叉搜索树
为什么适合磁盘存储?
B树的节点大小与磁盘块大小匹配(通常为4KB/8KB),一次磁盘I/O就能读取整个节点的数据,而较低的树高大幅减少了查询过程中的磁盘I/O次数。例如,4阶B树存储100万数据时,树高仅约5,查询最多仅需5次磁盘I/O,远优于二叉树的20次以上。
3.3 B+树:B树的优化升级
B+树是数据库索引的主流实现(如MySQL InnoDB),在B树的基础上做了关键优化:
- 关键字与数据分离:非叶子节点仅存储关键字,数据仅存放在叶子节点中,单个节点能存储更多关键字,进一步降低树高
- 叶子节点链表化:所有叶子节点通过指针串联成有序链表,支持高效的范围查询和全表扫描
B+树的优势对比:
| 特性 | B树 | B+树 |
|---|---|---|
| 关键字存储 | 非叶子节点也存储关键字 | 仅叶子节点存储关键字 |
| 数据存储 | 所有节点均可存储数据 | 仅叶子节点存储数据 |
| 范围查询效率 | 需遍历多个节点,效率较低 | 叶子节点链表直接遍历,效率极高 |
| 磁盘I/O次数 | 较多 | 更少,非叶子节点更紧凑 |