1、问题现象
HR 推送到 OA 系统的待办,存在这样一个现象:
待办事项虽然已经审批完成,但不会立刻从待办列表中消失,而是要过几秒刷新后才会消失。
1.1、原因分析
排查后确认,根因是:
统一待办中心接口响应较慢。
进一步分析发现,OFS_TODO_DATA 和 OFS_DONE_DATA 两张表中,syscode、flowid、receiver 这三个字段存在重复数据风险,也缺少最终的唯一约束控制,影响了相关处理效率。
1.2、处理思路
本次处理思路很简单:
-
先确认正式库表所在模式和数据量
-
通过 Navicat 将正式表导出,再导入测试库验证
-
在测试库先演练
-
正式执行前先备份表
-
删除重复数据
-
删除旧普通索引,改建唯一索引
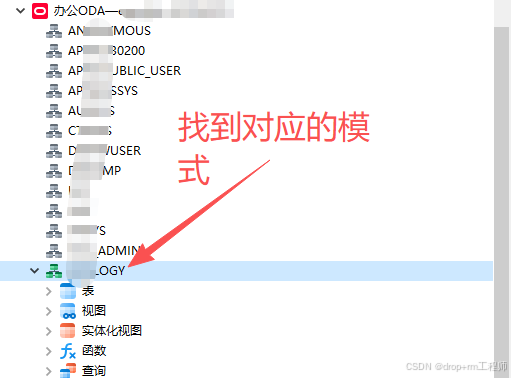
1.3、确认表所在模式
先确认表属于哪个 schema:
select owner, table_name
from all_tables
where table_name = 'OFS_DONE_DATA';确认正式库对象在 ECOLOGY 模式下。
1.4、确认测试环境数据量
本次测试环境使用的是 ECOLOGY1 模式。
select count(*) cnt from ECOLOGY1.OFS_TODO_DATA;
select count(*) cnt from ECOLOGY1.OFS_DONE_DATA;2、Navicat 导出正式库表CSV文件
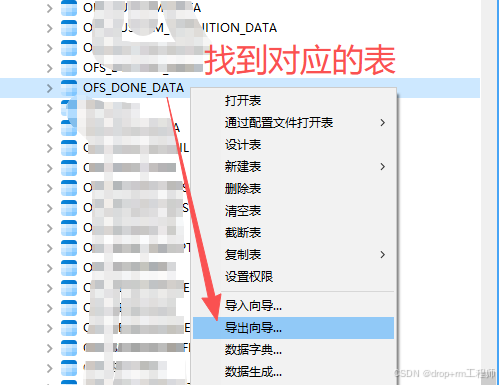
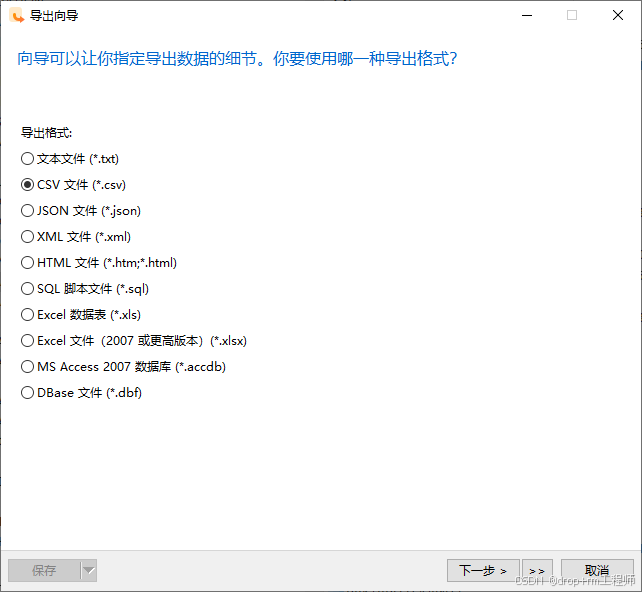
对于小表测试验证,CSV 更方便;对于需要留档、修改 schema 名或重复执行的场景,SQL 脚本更合适。
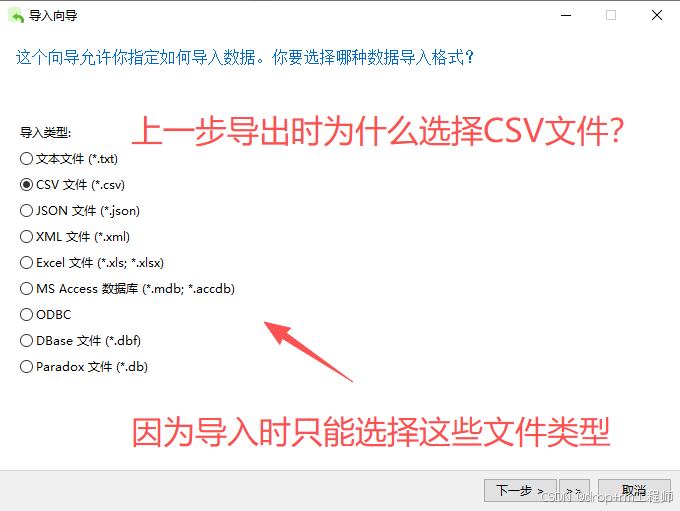
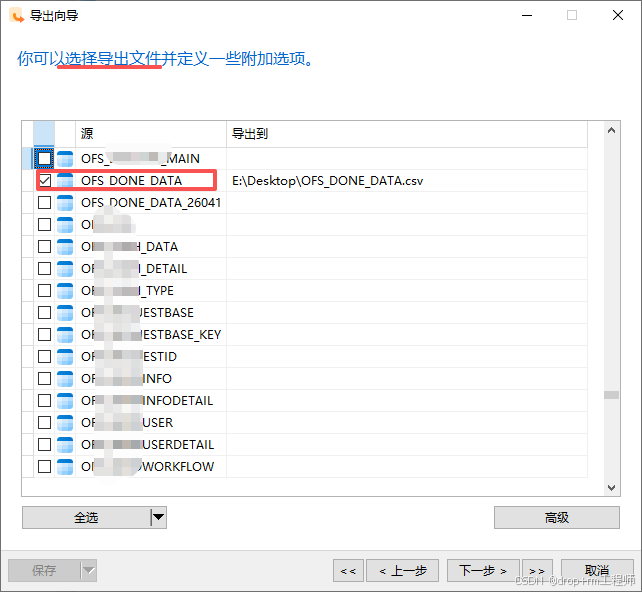
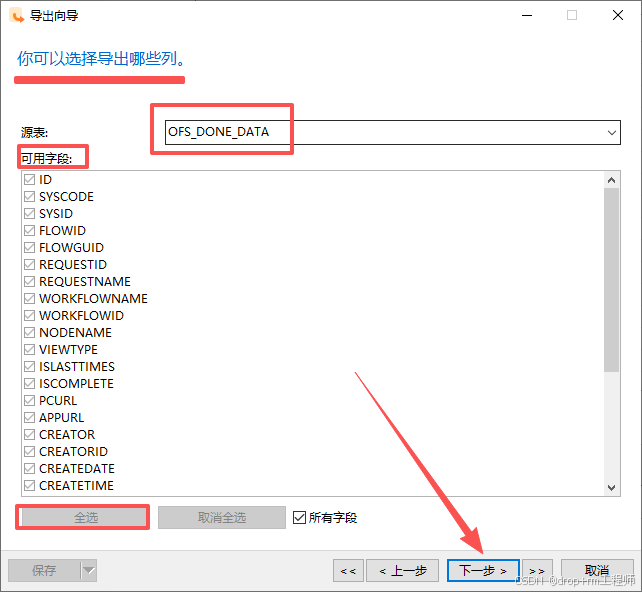
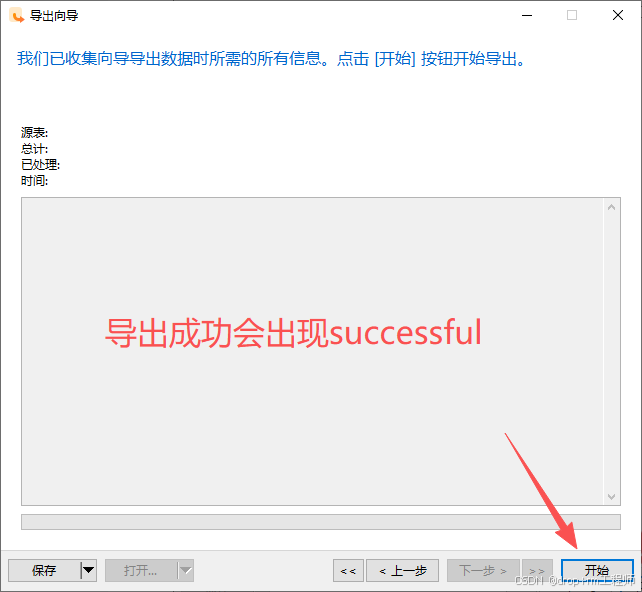

3、Navicat 导入测试库表CSV文件
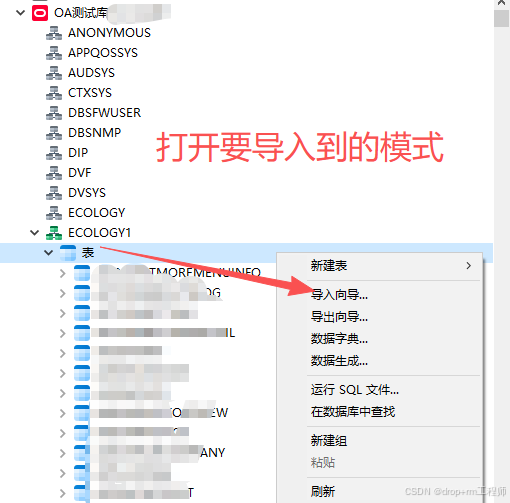
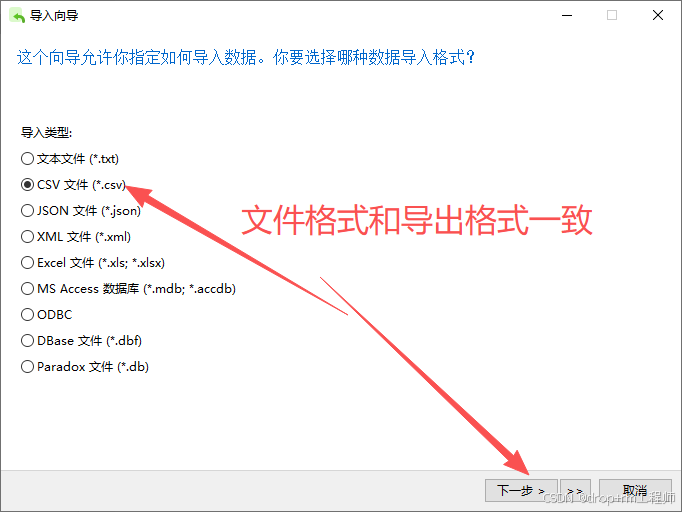
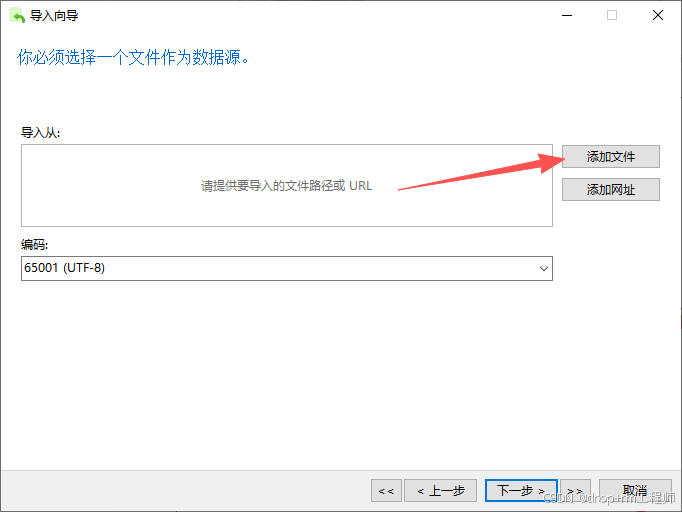
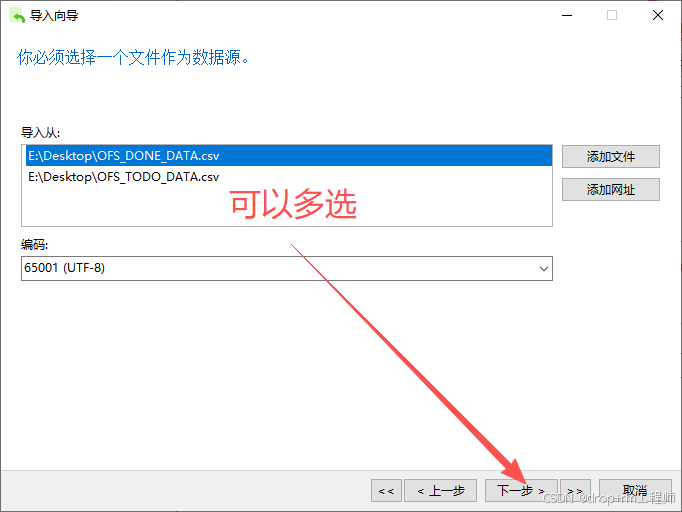
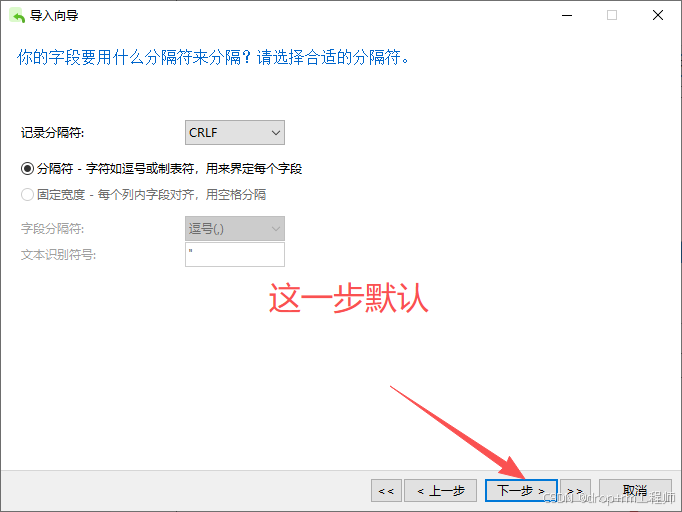
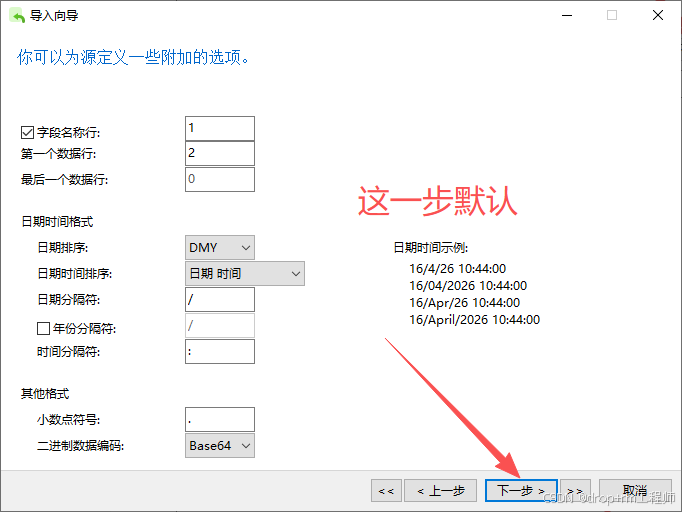
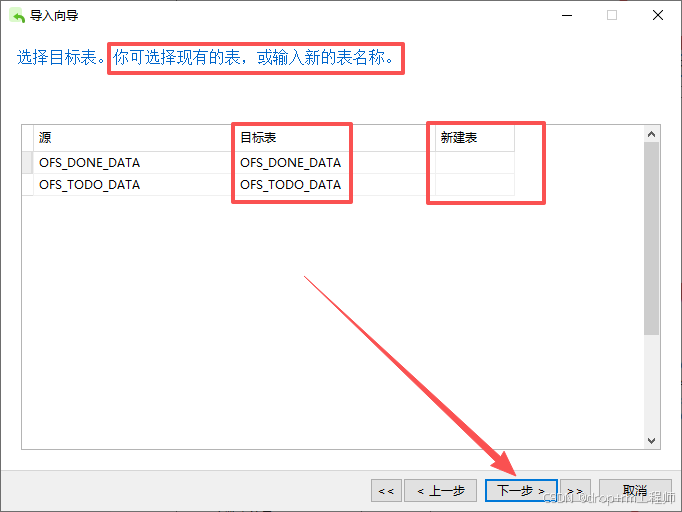
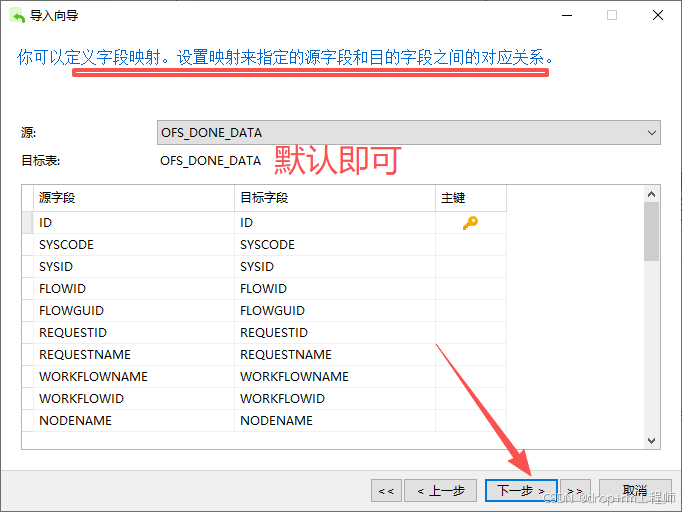
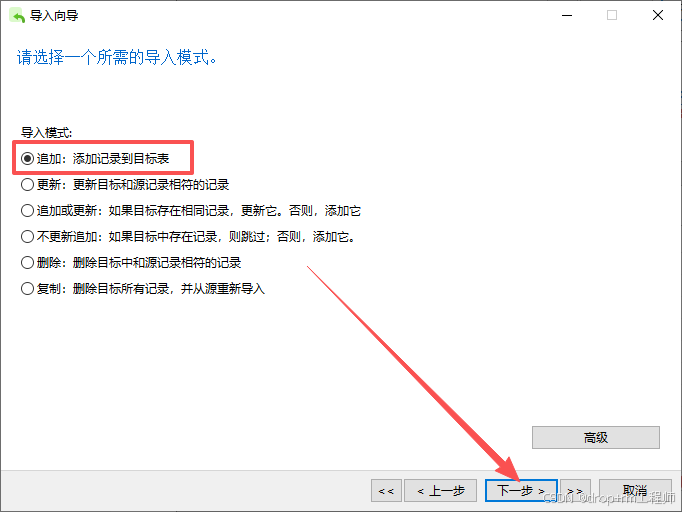
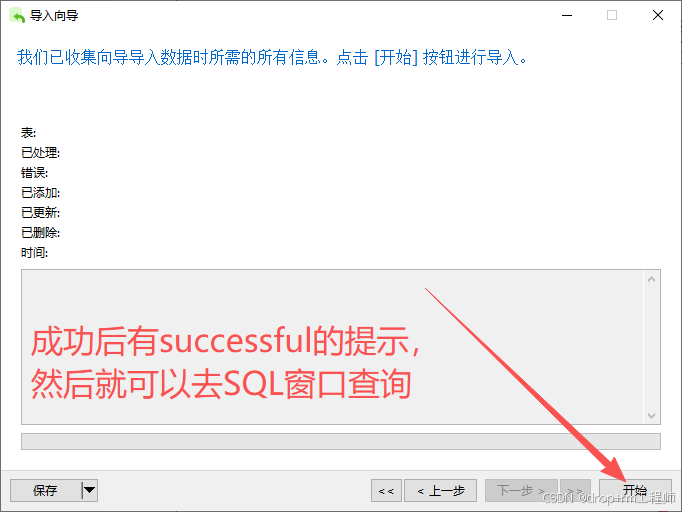
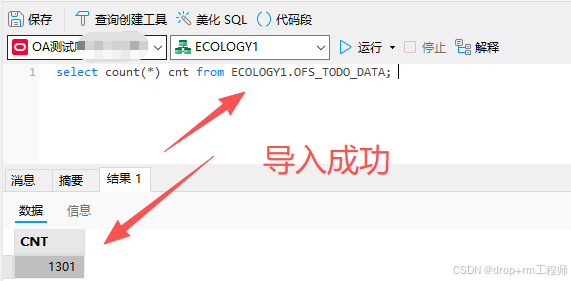
4、正式执行前先备份表
这里放你 备份表操作 的截图。
这一步非常关键。
正式处理前,先备份表,防止删除重复数据或索引调整过程中出现误操作。
需要注意的是:
CREATE TABLE AS SELECT 只备份表结构和数据,不会自动备份原表索引。
5、处理第1个表:OFS_TODO_DATA
1)备份表
CREATE TABLE OFS_TODO_DATA_260416 AS
SELECT * FROM OFS_TODO_DATA;2)尝试建立普通索引
CREATE INDEX idx_dtd_sfr_unique
ON OFS_TODO_DATA(syscode,flowid,receiver);执行报错:
ORA-01408: such column list already indexed说明这组三字段已经存在相关索引,需要先检查原有索引情况:
select index_name, uniqueness, status
from user_indexes
where table_name = 'OFS_TODO_DATA'
order by index_name;3)删除重复数据
DELETE FROM OFS_TODO_DATA
WHERE id NOT IN (
SELECT MIN(id)
FROM OFS_TODO_DATA
GROUP BY syscode, flowid, receiver
);4)确认重复数据是否已清理完成
select syscode, flowid, receiver, count(*)
from OFS_TODO_DATA
group by syscode, flowid, receiver
having count(*) > 1;查询结果为空,说明重复数据已经删除干净。
5)提交
COMMIT;6)删除已有普通索引
DROP INDEX SYSID_WORKFLOWID_FLOWID;
COMMIT;
DROP INDEX SYSCODE_FLOWID_RECEIVER;
COMMIT;7)建立唯一索引
CREATE UNIQUE INDEX idx_dtd_sfr_unique
ON OFS_TODO_DATA(syscode,flowid,receiver);8)检查最终索引状态
select index_name, uniqueness, status
from user_indexes
where table_name = 'OFS_TODO_DATA'
order by index_name;6、处理第2个表:OFS_DONE_DATA
1)备份表
CREATE TABLE OFS_DONE_DATA_260416 AS
SELECT * FROM OFS_DONE_DATA;2)尝试建立普通索引
CREATE INDEX idx_dtd_sfr_unique_done
ON OFS_DONE_DATA(syscode,flowid,receiver);同样报错:
ORA-01408: such column list already indexed查询已有索引:
select index_name, uniqueness, status
from user_indexes
where table_name = 'OFS_DONE_DATA'
order by index_name;3)删除重复数据
DELETE FROM OFS_DONE_DATA
WHERE id NOT IN (
SELECT MIN(id)
FROM OFS_DONE_DATA
GROUP BY syscode, flowid, receiver
);4)提交并检查重复数据
COMMIT;
select syscode, flowid, receiver, count(*)
from OFS_DONE_DATA
group by syscode, flowid, receiver
having count(*) > 1;查询为空,说明重复数据已经处理完成。
5)删除原普通索引
DROP INDEX SYSCODE_FLOWID_RECEIVER_DONE;6)建立唯一索引
CREATE UNIQUE INDEX idx_dtd_sfr_unique_done
ON OFS_DONE_DATA(syscode,flowid,receiver);7)检查最终索引状态
select index_name, uniqueness, status
from user_indexes
where table_name = 'OFS_DONE_DATA'
order by index_name;7、这次处理的两个重点
1)Navicat 导出导入表CSV
先通过 Navicat 把正式表导出,再导入测试环境验证。
2)正式执行前先备份表
这一步看起来普通,但非常重要:
CREATE TABLE 备份表 AS SELECT * FROM 原表;它虽然不会备份索引,但能快速保留一份数据副本,足够作为本次变更的回退保障。