1、什么是Redis

Redis是R emote D ictionary Server(远程数据服务)的缩写,由意大利人 antirez(Salvatore Sanfilippo萨尔瓦托桑菲利波) 开发的一款 内存高速缓存数据库,该软件使用C语言编写,它的数据模型为 key-value。
它支持丰富的数据结构,比如 string list( 双向链表 ) hash(哈希) set(集合) sorted set(zset 有序集合 **),**可持久化(保存数据到磁盘中),保证了数据安全
Redis是一个Nosql 非关系数据库, key => value 键值对。
2、业务使用场合
**① Sort Set**排行榜应用,取top n操作,例如sina微博热门话题(取最热的前10个话题)
**② List**获得最新N个数据 或 某个分类的最新数据
**③ String**计数器应用
**④ Set**sns(social network site)获得共同好友
**⑤ Set**防攻击系统(ip判断)黑白名单等等
3、安装与配置Redis
官方网址:https://redis.io/
github: https://github.com/antirez/redis
准备redis服务器,更改IP以及主机名称,在hosts绑定IP与主机,时间同步,安装必备软件
bash
hostnamectl set-hostname redis && bash
nmcli c m ens160 ipv4.method manual ipv4.addresses 192.168.194.138/24 ipv4.gateway 192.168.194.2 ipv4.dns 223.5.5.5 connection.autoconnect yes
nmcli c up ens1601、安装方式
可以通过yum方式在线安装,也可以通过源码编译方式安装
bash
# 先安装epel-release源
dnf install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-$(rpm -E '%{rhel}').noarch.rpm安装必要的依赖
bash
sudo dnf install -y gcc make gcc-c++ tcl wget tar这里,采用源码编译方式安装:
bash
第一步:找到对应的安装包资源,使用wget命令下载,这里安装的7.4.0版本。
安装包资源地址:https://download.redis.io/releases/
第二步:上传Redis到Linux系统中
wget https://download.redis.io/releases/redis-7.4.0.tar.gz
第三步:配置=>编译=>安装
tar -zxvf redis-7.4.0.tar.gz
cd redis-7.4.0
make -j$(nproc)
make PREFIX=/usr/local/redis install安装成功后,Redis 的可执行文件将被安装到 /usr/local/redis
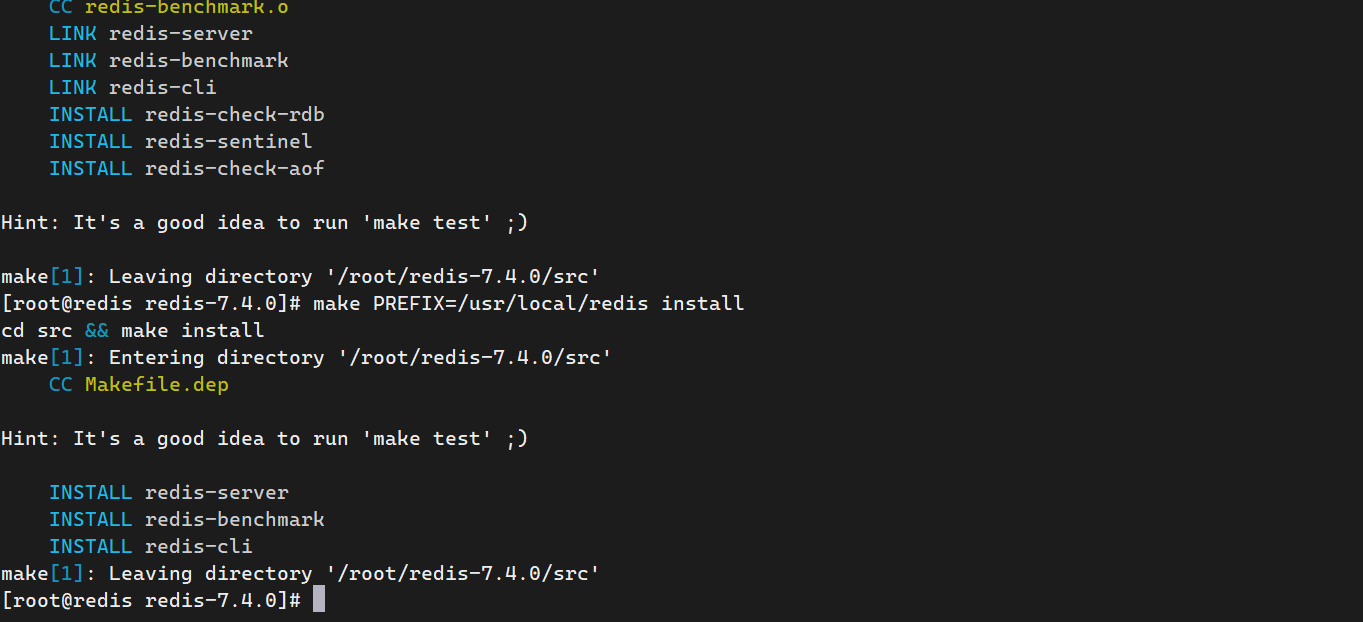
查看安装目录下Redis中有哪些文件
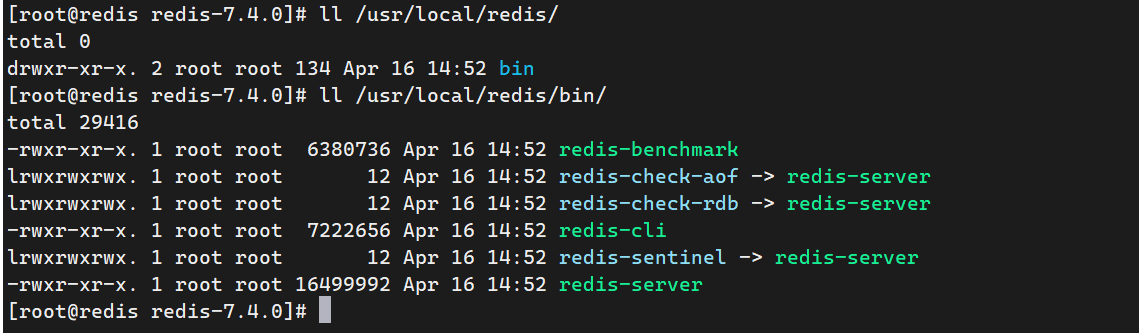
1、redis-server
作用:Redis 的主服务进程,负责启动数据库、处理客户端请求、管理数据存储等。
说明:这是 Redis 的核心程序。所有其他功能(如 Sentinel、AOF/RDB 检查)都复用这个二进制文件,通过不同启动方式实现不同功能。
2、redis-cli
作用:Redis 命令行客户端工具。
用途:
-
连接 Redis 服务器并执行命令(如 SET key value、GET key)。
-
管理服务器(如 SHUTDOWN 关闭服务、INFO 查看状态)。
-
调试和测试(如 MONITOR 实时查看命令流)。
bash
redis-cli ping # 返回 PONG 表示服务正常
bash
redis-cli # 进入交互式命令行3、redis-benchmark
作用:Redis 性能压测工具。
用途:模拟大量客户端并发请求,测试 Redis 的吞吐量(QPS)、延迟等性能指标。
示例:
bash
redis-benchmark -q -n 100000 -c 50 # 发送 10 万次 SET/GET 请求,50 并发4、redis-check-aof(符号链接 → redis-server)
作用:检查和修复 AOF(Append-Only File) 持久化文件。
用途:
-
当 AOF 文件因意外崩溃损坏时,用此工具尝试修复。
-
会扫描 AOF 文件并重建合法的命令序列。
使用方式:
bash
redis-check-aof --fix /var/lib/redis/appendonly.aof5、redis-check-rdb(符号链接 → redis-server)
作用:检查 RDB(Redis Database) 快照文件的完整性。
用途:
-
验证 RDB 文件是否损坏。
-
可解析 RDB 文件内容(需配合 --dump 等参数)。
使用方式:
bash
redis-check-rdb /var/lib/redis/dump.rdb6、redis-sentinel(符号链接 → redis-server)
作用:Redis 高可用(HA)组件,用于监控主从实例、自动故障转移。
用途:
-
监控 Redis 主节点是否宕机。
-
自动将从节点提升为主节点(Failover)。
-
通知客户端新的主节点地址。
注意:需单独配置 sentinel.conf 文件启动。
🔍 为什么有些是符号链接?
Redis 通过 同一个二进制文件(redis-server) 根据启动时的 程序名(argv0) 判断运行模式:
-
如果以 redis-sentinel 启动 → 运行 Sentinel 模式
-
如果以 redis-check-aof 启动 → 运行 AOF 检查模式
-
其他情况 → 默认运行 Redis 服务器模式
这样设计可以减少磁盘占用,避免重复代码。
|-----------------|-------|--------------|
| 文件名 | 类型 | 功能说明 |
| redis-server | 可执行文件 | Redis 主服务 |
| redis-cli | 可执行文件 | 命令行客户端 |
| redis-benchmark | 可执行文件 | 性能压测工具 |
| redis-check-aof | 符号链接 | AOF 文件修复工具 |
| redis-check-rdb | 符号链接 | RDB 文件检查工具 |
| redis-sentinel | 符号链接 | 高可用监控与故障转移组件 |
2、修改配置
bash
sudo mkdir -p /usr/local/redis/conf
cd /root/redis-7.4.0
sudo cp redis.conf /usr/local/redis/conf/
# 修改配置
sudo vim /usr/local/redis/conf/redis.conf
88: bind 127.0.0.1 -::1 --> bind 0.0.0.0
310: daemonize no --> daemonize yes 设置为后台运行
# 添加redis到环境变量
sudo vim /etc/profile
export PATH="$PATH:/usr/local/redis/bin"
source /etc/profile
#过量使用内存设置为0!在低内存环境下,后台保存可能失败
sudo vim /etc/sysctl.conf
vm.overcommit_memory = 1 # 允许Redis申请更多的内存资源
sysctl -p说明:
vm.overcommit_memory
这个参数是 linux 系统在分配内存时的一种策略控制,直接关系到 Redis 这样的应用能不能顺利启动、正常运行。
默认值为0:系统会根据当前内存使用情况、总内存和交换空间的比例,"评估"是否允许分配内存。如果它"觉得"你分配太多内存了,就拒绝了,
哪怕物理内存其实还够。Redis 启动时会尝试申请大量内存,比如它的最大内存限制值(maxmemory),即使暂时还没用到。
这时 linux 系统"评估"你内存不够,就会阻止 Redis 启动,报错:
参数值设为 1:系统不管三七二十一,你说要分配内存,它就答应。哪怕内存其实根本不够,它也会先允许你申请下来。
如果设置为 1,系统允许进程分配"看起来够但实际上不够"的内存。如果很多程序都这么做,等真正用内存时可能会爆掉系统(内存溢出或 OOM)。
但 Redis 一般是可你可控的服务,设置 maxmemory 限制总量就没事。
Redis 推荐设置 vm.overcommit_memory = 1,就是为了避免系统"瞎担心内存不够"导致 Redis 启动失败。
3、启动Redis
bash
#查看版本
redis-cli -v
#启动
redis-server /usr/local/redis/conf/redis.conf
#查看服务进程
ps -ef | grep redis
封装redis.service脚本(使用这个配置文件是为了让systemctl来启动redis)
bash
sudo vim /etc/systemd/system/redis.service
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
配置未完成以后,以后我们就可以直接使用systemctl start redis来实现redis启动操作。
pkill redis-server
systemctl start redis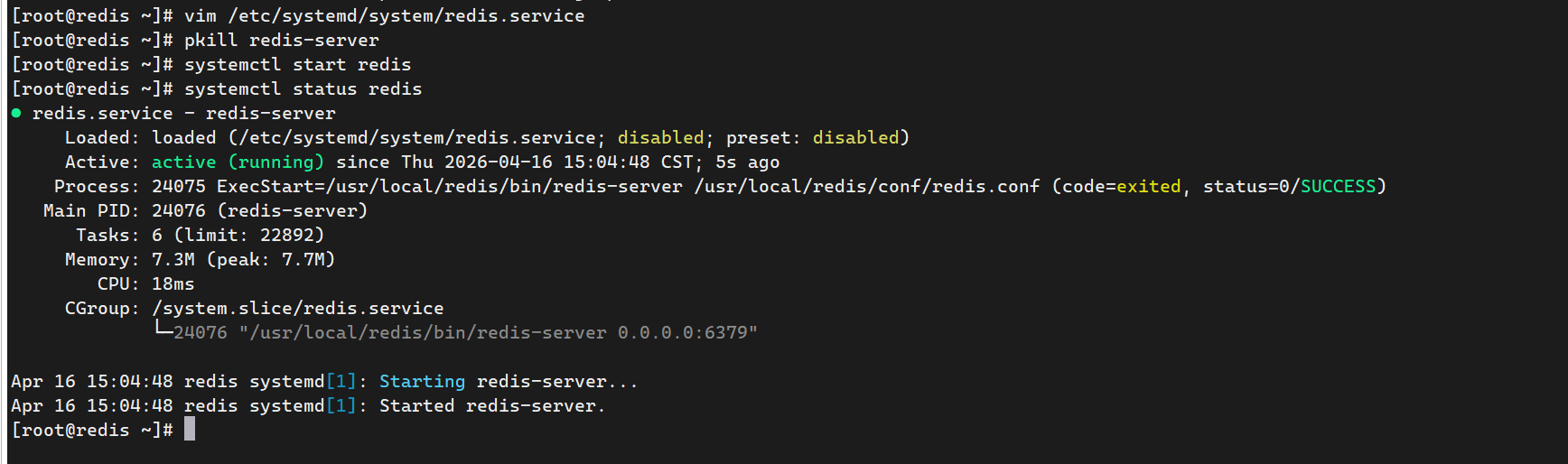
配置服务文件的参数说明
bash
[Unit]
# 服务的简要描述,会显示在 systemctl status 等命令的输出中
Description=redis-server
# 指定该服务在哪些目标之后启动
# network.target 表示在网络功能就绪后再启动 Redis,确保绑定 IP 时网络已可用
After=network.target
[Service]
# 进程启动类型
# forking 表示 ExecStart 启动的进程会 fork 出一个子进程作为主进程,然后父进程退出
# Redis 默认配置 daemonize yes 时就是这种模式,systemd 会跟踪 fork 出的子进程
Type=forking
# 启动服务时执行的命令
# /usr/local/redis/bin/redis-server 是 Redis 可执行文件
# /usr/local/redis/conf/redis.conf 是配置文件路径
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
# 为服务设置独立的 /tmp 和 /var/tmp 临时目录
# 服务只能访问自己的临时文件,其他服务的临时文件对它是不可见的,增强安全性
PrivateTmp=true
[Install]
# 定义该服务在哪个运行级别下被启用
# multi-user.target 表示多用户命令行模式
# 执行 systemctl enable redis-server 时,会创建软链接到该 target 的 wants 目录
WantedBy=multi-user.target补充说明 :这个配置要求 Redis 配置文件中的 daemonize 必须设置为 yes,因为 Type=forking 配合的就是后台守护进程模式。如果改成 Type=simple,则需要设置 daemonize no,让 Redis 在前台运行
4、6379端口
Redis数据库服务的默认TCP端口号
5、命令行客户端简单使用
redis属于c/s架构软件,telnet可以连接redis,没有本身redis-cli更加好用
① 简单的数据操作
string类型:字符串类型、文本类型,用于保存文本信息
bash
# redis-cli
127.0.0.1:6379 > set name devops
OK
127.0.0.1:6379 > get name
"devops"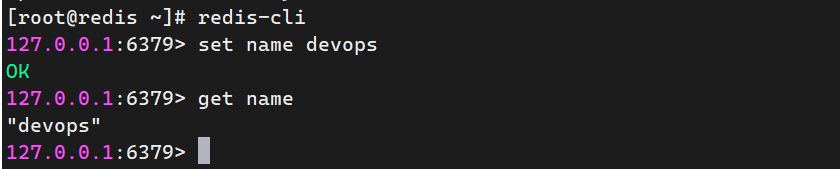
② 查看操作语法帮助
bash
# 127.0.0.1:6379 > help
# 127.0.0.1:6379 > help set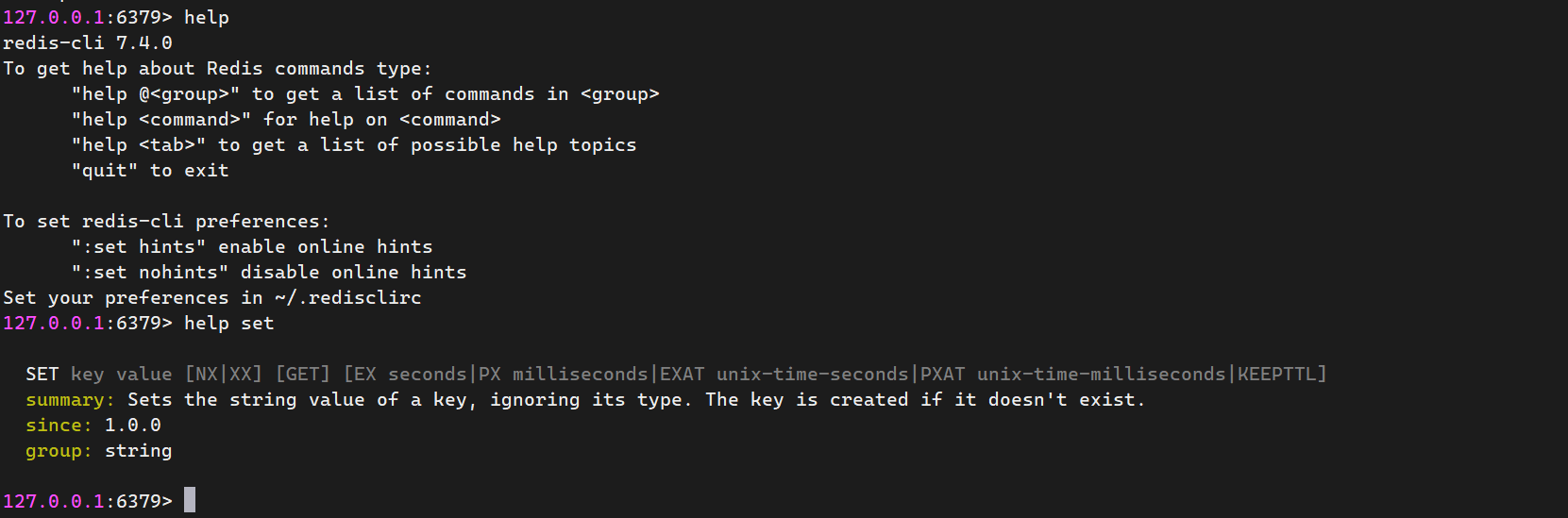
③ 系统状态信息
bash
# 127.0.0.1:6379 > info 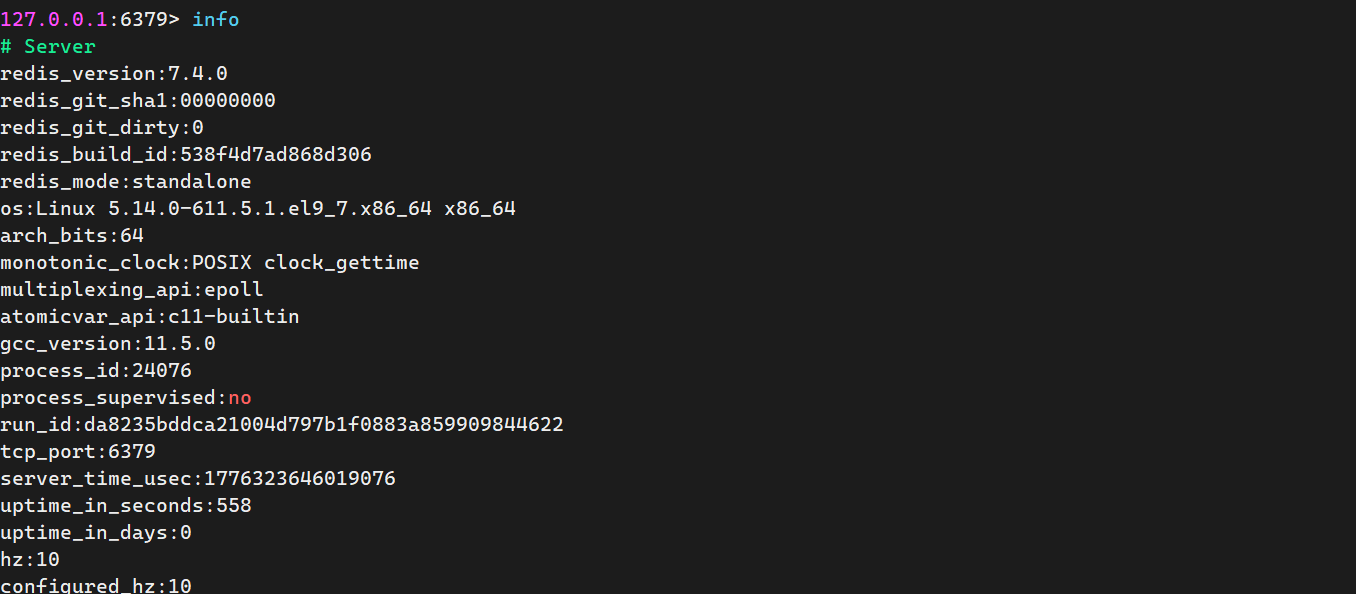
④ 退出
bash
# 127.0.0.1:6379 > quit
4、数据结构类型操作
格式:set key value
1、key(键名)
内存:NoSQL数据库,存储形式,键值对,类似身份证(不能重复,必须唯一)
key的命名规则不同于一般语言,键盘上除了空格、\n换行符外其他的大部分字符都可以使用。
但是像"my key"和"mykey\n"这样包含空格和换行的key是不允许的。
注意:
- key不要太长。占内存,查询慢。
- key不要太短。像u:1000:pwd:123456 就不如 user:1000:password:123456可读性好
| 命令 | 语法示例 | 说明 |
|---|---|---|
KEYS |
KEYS pattern |
(线上慎用) 查找匹配模式的所有键。如 KEYS user:*。 |
DEL |
DEL key [key ...] |
删除一个或多个键。 |
EXISTS |
EXISTS key |
检查键是否存在。 |
EXPIRE |
EXPIRE key seconds |
给键设置过期时间(秒)。 |
TTL |
TTL key |
查看键的剩余过期时间(秒)。 |
TYPE |
TYPE key |
返回键存储的数据类型。 |
RENAME |
RENAME oldkey newkey |
重命名键。 |
SCAN |
SCAN cursor MATCH pattern |
(生产推荐) 迭代遍历键,不会阻塞服务器。 |
2、string
string是redis最基本的类型
redis的string可以包含任何数据。包括jpg图片 base64或者序列化的对象
| 命令 | 语法示例 | 说明 |
|---|---|---|
SET |
SET key value |
设置键值,可附加EX(秒)、PX(毫秒)、NX(不存在才设)等参数。 |
GET |
GET key |
获取键的值。 |
INCR / DECR |
INCR key |
将值解析为整数并加1/减1,常用于计数。 |
APPEND |
APPEND key value |
向已有字符串值末尾追加内容。 |
SETNX |
SETNX key value |
仅当键不存在时 设置值,用于分布式锁。 |
典型场景:缓存对象、计数器、分布式锁。
3、list
key value(value1,value2,value3)
list类型其实就是一个双向链表。通过push(进,就是添加),pop(出,就是删除)操作从链表的头部或者尾部添加删除元素
这使得list既可以用作栈,也可以用作队列
同一端进出,先进后出,后进先出 ==> 栈(相当于有底的木桶)
一端进,另外一端出,先进先出 ==> 队列 (相当于水管,两端开口,模拟日上生活中的排队)
字符串链表,有序可重复,支持两端操作。
| 命令 | 语法示例 | 说明 |
|---|---|---|
LPUSH / RPUSH |
LPUSH key value |
从左/右端插入元素。 |
LPOP / RPOP |
LPOP key |
从左/右端弹出元素。 |
LRANGE |
LRANGE key start stop |
获取指定索引范围的元素(0 -1表示全部)。 |
LLEN |
LLEN key |
返回列表长度。 |
LTRIM |
LTRIM key start stop |
修剪列表,仅保留指定范围的元素。 |
典型场景:消息队列、最新动态时间轴。
4、set
作用:求交集、并集、差集!!!
redis的set是string类型的无序集合。集合里不允许有重复的元素
set元素最大可以包含(2的32次方-1)个元素。
关于set集合类型除了基本的添加删除操作,其他常用的操作还包含集合的取并集(union),交集(intersection),差集(difference)。通过这些操作可以很容易的实现sns中的好友推荐功能。
|------------------|-----------------------|------------------------------------|
| 操作 | 含义 | 示例 |
| 并集(Union) | A ∪ B:A 和 B 中所有不重复的元素 | A={1,2,3}, B={3,4,5} → {1,2,3,4,5} |
| 交集(Intersection) | A ∩ B:同时在 A 和 B 中的元素 | → {3} |
| 差集(Difference) | A - B:在 A 中但不在 B 中的元素 | → {1,2} |
A − B = A − (A ∩ B)
就是:集合 A 对集合 B 的差集,等于从 A 中去掉 A 与 B 的交集部分。
字符串的无序集合,唯一性,支持集合运算。
| 命令 | 语法示例 | 说明 |
|---|---|---|
SADD |
SADD key member |
添加一个或多个成员。 |
SREM |
SREM key member |
移除一个或多个成员。 |
SMEMBERS |
SMEMBERS key |
(慎用,元素多时会阻塞) 返回集合所有成员。 |
SISMEMBER |
SISMEMBER key member |
判断成员是否在集合中。 |
SINTER |
SINTER key1 key2 |
返回多个集合的交集。 |
SUNION |
SUNION key1 key2 |
返回多个集合的并集。 |
SPOP |
SPOP key [count] |
随机移除并返回集合中的一个或多个元素。 |
典型场景:点赞用户集合、共同好友计算、抽奖系统。
5、zset(Sorted Set)
和set一样,zset(Sorted Set)也是string类型元素的集合 => 有序集合,元素不允许重复
不同的是每个元素都会关联一个权值(分值)。
通过权值可以有序的获取集合中的元素,可以通过score值进行排序
类似Set但每个成员关联一个分数 (Score),用于排序,成员唯一。
| 命令 | 语法示例 | 说明 |
|---|---|---|
ZADD |
ZADD key score member |
添加带分数的成员。 |
ZRANGE |
ZRANGE key start stop |
按索引范围(分数从低到高)返回成员。 |
ZREVRANGE |
ZREVRANGE key start stop |
按索引范围(分数从高到低)返回成员。 |
ZRANGEBYSCORE |
ZRANGEBYSCORE key min max |
按分数范围返回成员。 |
ZREM |
ZREM key member |
移除成员。 |
ZRANK |
ZRANK key member |
返回成员的排名(分数从低到高)。 |
ZINCRBY |
ZINCRBY key increment member |
增加成员的分数。 |
典型场景:实时排行榜、延迟队列。
6、hash(哈希)
作用:使用redis不仅可以做缓存,还可以做数据库,除了可以使用string,还可以使用hash结构,比string压缩效率和使用效率更高。
hash存储数据和关系型数据库(mysql),存储的一条数据的结构极为相似
键值对集合,适合存储对象,可单独操作字段。
| 命令 | 语法示例 | 说明 |
|---|---|---|
HSET |
HSET key field value |
设置一个或多个字段值。 |
HGET |
HGET key field |
获取单个字段的值。 |
HGETALL |
HGETALL key |
(慎用) 获取所有字段和值。 |
HDEL |
HDEL key field |
删除一个或多个字段。 |
HINCRBY |
HINCRBY key field increment |
将字段的整数值增加指定量。 |
HEXISTS |
HEXISTS key field |
检查字段是否存在。 |
HKEYS / HVALS |
HKEYS key |
获取所有字段名 / 获取所有字段值。 |
HEXPIRE |
HEXPIRE key seconds FIELDS num field |
(Redis 7.4新特性) 为Hash中的单个字段设置过期时间。 |
典型场景:存储用户信息、购物车、文章元数据。
快速记忆与总结
| 数据类型 | 核心特点 | 关键记忆口诀 |
|---|---|---|
| String | 键值对 | 万物皆可字符串,计数锁存全靠它。 |
| List | 有序可重 | 头尾能推能弹,时间线队列自然来。 |
| Set | 无序唯一 | 去重点赞加好友,交集并集算关系。 |
| ZSet | 有序唯一带分数 | 分数决定排位赛,排行榜上显神通。 |
| Hash | 字段值对 | 对象存储省空间,字段更新最灵活。 |
这些命令都可以通过使用 help @数据类型来查看帮助语法
5、数据持久化操作
Redis的持久化,简单说就是把内存中的数据保存到硬盘上,防止服务器重启或宕机后数据全部丢失。
Redis本身是一个基于内存的数据库,读写极快,但内存的数据一断电就没了。持久化就是为了解决这个"易失性"问题。
Redis官方提供了两种主要的持久化机制,它们可以单独使用,也可以组合使用。
1. RDB(Redis DataBase)快照
原理是什么?
RDB 的原理是快照 。你可以把它理解为:在某个特定时刻,给 Redis 的整个内存数据拍一张照片,然后把这张照片保存为一个压缩的二进制文件(dump.rdb)。
它的核心触发机制是fork() + 写时复制:
-
Redis 调用
fork()函数,创建一个子进程。 -
此时,父子进程共享同一块内存数据。
-
子进程开始遍历内存数据,并将其写入硬盘的临时文件。
-
在此期间,主进程 (父进程)依然可以处理客户端的读写请求。当有写入操作时,操作系统会利用写时复制机制,只为被修改的那一小部分内存数据创建副本,父子进程大部分数据依然共享,因此内存占用不会瞬间翻倍。
-
子进程写完后,用临时文件替换掉旧的 RDB 文件,完成持久化。
优点与缺点
| 优点 | 缺点 |
|---|---|
| 文件紧凑,恢复极快 :适合做灾难恢复 和冷备份。 | 数据丢失窗口大:如果两次快照之间宕机了,这段时间的写操作就彻底丢了。 |
对性能影响小 :主进程只负责 fork 和接收请求,磁盘 I/O 全交给子进程。 |
fork 瞬间可能阻塞 :如果内存数据非常大(几十 GB),fork 创建子进程的瞬间耗时较长,可能导致 Redis 短暂卡顿。 |
2. AOF(Append Only File)日志
原理是什么?
AOF 的原理是记录每次写操作的日志。它不是记录最终的数据状态,而是记录"数据是怎么被修改的"这个过程。
它的工作流程是:
-
Redis 执行一条写命令(例如
SET name zhangsan)。 -
Redis 先将这条命令追加写入 AOF 缓冲区。
-
根据配置的刷盘策略,将缓冲区里的命令写入磁盘的 AOF 文件末尾。
优点与缺点
| 优点 | 缺点 |
|---|---|
数据更安全 :可以做到最多丢失 1 秒的数据(如果配置为 everysec)。 |
文件体积大:AOF 文件记录的是过程,比 RDB 的压缩快照要大得多。 |
| 可读性好:AOF 文件里就是纯文本的 Redis 命令,误操作后甚至可以直接修改文件来恢复数据。 | 恢复速度慢 :宕机重启时,需要把 AOF 里的命令一条条重放一遍,比直接加载 RDB 文件要慢很多。 |
💡 关于刷盘策略的补充
AOF 提供了三种刷盘配置,需根据业务安全级别权衡:
appendfsync always:每写一条命令刷一次盘。最安全但最慢,基本不用于生产环境。
appendfsync everysec:每秒刷一次盘。生产标配,平衡了性能与安全,最多丢 1 秒数据。
appendfsync no:由操作系统决定何时刷盘。最快但不安全。
3. 混合持久化(Redis 4.0+ 的默认选择)
由于 RDB 和 AOF 各有优劣,从 Redis 4.0 开始引入了混合持久化模式。
原理是什么?
它结合了两者的优点:在 AOF 重写时,先以 RDB 格式写入当前内存的快照,再把重写期间的增量写命令以 AOF 格式追加在后面。
这样,生成的文件前半部分是压缩的二进制快照(RDB),后半部分是文本日志(AOF)。
优势
-
恢复速度快:大部分数据用 RDB 快照加载,速度接近 RDB。
-
数据丢失少:快照之后的那部分日志是 AOF 格式,保证了数据安全性。
选型总结对比
| 机制 | 文件体积 | 恢复速度 | 数据安全性 | 默认文件 |
|---|---|---|---|---|
| RDB | 小 | 极快 | 较差(丢得多) | dump.rdb |
| AOF | 大 | 慢 | 较好(丢得少) | appendonly.aof |
| 混合持久化 | 中等 | 快 | 好 | appendonly.aof(内容混合) |