
🎬 博主名称 :键盘敲碎了雾霭
🔥 个人专栏 : 《C语言》《数据结构》 《C++》 《Matlab》 《Python》
⛺️指尖敲代码,雾霭皆可破

文章目录
- 一、必备基础知识
- 二、向量
-
- [2.1 向量的创建](#2.1 向量的创建)
-
- [2.1.1 直接输入法](#2.1.1 直接输入法)
- [2.1.2 冒泡法](#2.1.2 冒泡法)
- [2.2 向量的引用](#2.2 向量的引用)
-
- [2.2.1 单个元素引用](#2.2.1 单个元素引用)
- [2.2.2 多个元素引用](#2.2.2 多个元素引用)
- [2.3 元素的修改和删除](#2.3 元素的修改和删除)
-
- [2.3.1 修改](#2.3.1 修改)
- [2.3.2 删除](#2.3.2 删除)
- 三、矩阵
-
- [3.1 创建方法](#3.1 创建方法)
-
- [3.1.1 直接输入法](#3.1.1 直接输入法)
- [3.1.2 函数创建法](#3.1.2 函数创建法)
- [3.2 元素的引用](#3.2 元素的引用)
-
- [3.2.1 双下标索引](#3.2.1 双下标索引)
- [3.2.2 size函数](#3.2.2 size函数)
- [3.2.3 线性索引](#3.2.3 线性索引)
- [3.2.4 原始索引和线性索引的区别](#3.2.4 原始索引和线性索引的区别)
- [3.3 元素的修改和删除](#3.3 元素的修改和删除)
-
- [3.3.1 修改](#3.3.1 修改)
- [3.3.2 删除](#3.3.2 删除)
- [3.4 拼接和重复](#3.4 拼接和重复)
-
- [3.4.1 拼接](#3.4.1 拼接)
- [3.4.2 重复堆叠](#3.4.2 重复堆叠)
- [3.4.3 元素进行重复](#3.4.3 元素进行重复)
- [3.5 重构和重新排列](#3.5 重构和重新排列)
-
- [3.5.1 reshape](#3.5.1 reshape)
- [3.5.2 sort函数](#3.5.2 sort函数)
- [3.5.3 sortrows函数](#3.5.3 sortrows函数)
- [3.5.4 flip / fliplr / flipud函数](#3.5.4 flip / fliplr / flipud函数)
- [3.5.5 rot90函数](#3.5.5 rot90函数)
- 文章结语
一、必备基础知识
在层次分析法和主成分分析法中,都需要计算矩阵的特征值。因此,要想学好MATLAB,必须要学和矩阵相关的操作和相应的知识。
- 矩阵定义
由m乘以n个元素组成的m行n列的数表,称为mxn阶矩阵,当m=n时,我们称矩阵A为n阶方阵(n阶矩阵) - 同型矩阵
当矩阵A,B的行数和列数都相同时,我们称矩阵A,B为同型矩阵 - 矩阵A的转置矩阵(A^T或A')
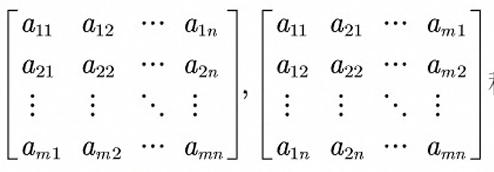
- 向量的定义
向量是矩阵的特例,行向量的行数为1,列向量的列数为1. - 向量的模
√a1²+a22+...+an2 - 矩阵的加减法
矩阵同型时才能相加减。
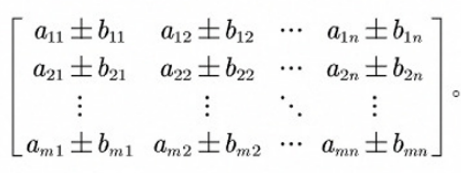
- 数与矩阵的乘法
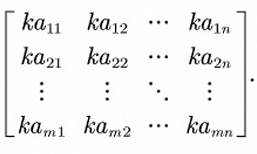
- 矩阵与矩阵的乘法
A矩阵的每一行乘以B矩阵的每一列,两个矩阵的乘法必须满足左边矩阵的列数与右边矩阵的行数相等
cij = ai1b1j + ai2b2j +...+ ainbmj(i =1,2,...,m;j =1,2...,s)
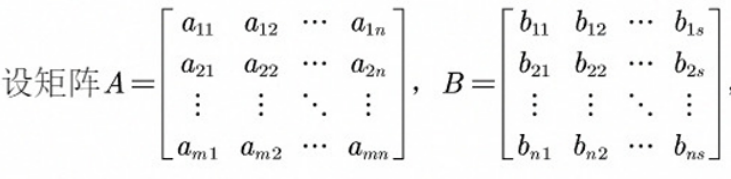
- 单位矩阵
单位矩阵一定为方阵

- 矩阵的逆
设A是n阶矩阵,若存在n阶矩阵B,使得BA=E或AB=E,则称矩阵A可逆,矩阵B称为矩阵A的逆矩阵,记为B=A^-1. - 特征值和特征向量
设n阶方阵A满足以下条件:存在数入(λ可为复数)和非零n维列向量x,使得Ax=λx成立,则称数λ是方阵A的特征值,称x为方阵A对应于特征值入的特征向量。注意,特征向量并不唯一,kx(k≠0)也是方阵A对应于特征值λ的特征向量
二、向量
2.1 向量的创建
2.1.1 直接输入法
若元素之间用空格(可以有多个空格)、逗号分隔,则创建的是行向量
若用分号、回车键分隔,则创建的是列向量
2.1.2 冒泡法
A:step:B(步长为1时可以省略)
A是起始值,step是每次递增或递减的步长,B是终止值(不一定刚好停在这里)
注意以下易错点:
matlab
1:2:8 % 每次增加2,到了7后,如果再增加2的话结果等于9,比8要大,所以到了7就停止了。
matlab
1:10:3 % 从1开始,增加10等于11,比3还要大,所以返回1
matlab
5:2:1 % A:step:B 若A > B且步长step > 0,则会返回空的向量
matlab
10:-100:5 % 步长为-100,因为10-100 = -90比5还要小,所以返回10
matlab
10:-10:50 % 若A < B且步长step < 0,则会返回空的向量
matlab
1:0:2 % 若step = 0,则返回空的向量。创建空的向量[]
- 利用MATLAB函数创建(在图上取点方便,因为会自动计算等差数列的步长)
linspace (a,b,n): 该命令用来创建一个行向量,向量中的第一个元素为a,最后一个元素为b,形成总数为n个元素的线性间隔的向量。(n不写时,默认为100)
matlab
linspace(100,1,10) % 如果a>b,则步长是负数-
logspace(a,b,n) :创建一个行向量,其第一个元素为
10^a,最后一个元素为10^b,形成总数为n个元素的等比数列向量。 (n不写时,默认为50) -
区别
linspace生成的向量的最后一个元素一定是b ,而使用冒号法a:step:b生成的向量的最后元素不一定是b。
绘制sin(x)在区间0, 2上的图形,x的范围是0到 2 ,我们使用linspace(0,2pi)生成的向量的最后一个元素一定是 2 ;如果使用冒号法令x=0:0.1:2pi,那么x向量的最后一个元素和 2 有一个微小的差异
2.2 向量的引用
如何提取向量中的单个元素和提取向量中的多个元素呢?
在MATLAB中,可以使用length函数或numel 函数来计算向量中包含的元素个数。
matlab下标从零开始

2.2.1 单个元素引用
提取向量a中单个元素的方法很简单,只需要利用a(ind)命令
创建向量用中括号,提取元素要用小括号,数组索引必须为正整数或逻辑值
2.2.2 多个元素引用
我们也可以利用向量的索引来同时提取多个位置的元素,这时候只需要将ind设置成一个向量,ind中放入我们想要提取的元素的索引,然后使用a(ind)命令即可。
- end的使用
不想使用length函数或者numel函数来计算向量中元素的个数,那我能不能提取出a中奇数位置的元素呢?这时候就需要用到一个特殊的关键字:end。它有很多种用法,在这里end可以用来替代向量的最后一个索引。
使用了end,不能将要取元素的索引赋值给indx=1:end,只能在a后面的小括号中使用end来替代数组的最后一个索引 - 注意
matlab
% a(11) % 索引超出数组元素的数目(10)。
a([]) % 如果是提取空向量的话,结果也为空。2.3 元素的修改和删除
有了向量元素的引用,我们可以利用等号赋值的方法对引用位置的元素进行修改和删除。
2.3.1 修改
| 请依次执行下面的代码 | 修改后的向量 a |
|---|---|
a(1) = 4 % 第一个元素改成 4 |
[4 4 8 16 32 64 128 256 512 1024] |
a([1,3]) = [50 60] % 第 1 个位置元素改成 50;第 3 个位置元素改成 60 |
[50 4 60 16 32 64 128 256 512 1024] |
a(1:3) = [5 6] % 赋值时,左右两侧的元素个数要相同,左边引用了 3 个位置,右侧的向量长度为 2 |
MATLAB 报错:无法执行赋值,因为左侧和右侧的元素数目不同。 |
a(2:4) = 100 % 如果右边为常数,则将指定位置的元素全部变成这个常数。 |
% 第 2 至 4 号位置的元素改为了 100 [50 100 100 100 32 64 128 256 512 1024] |
a(13) = 88 % 把索引为 13 的元素赋值为 88,如果超过了最大索引,则会自动拓展向量的大小 |
[2 4 8 16 32 64 128 256 512 1024 0 0 88] % 索引 11 和 12 的位置会自动用 0 进行赋值 |
2.3.2 删除
| 操作代码 | 执行后向量 a |
|---|---|
a(1) = [] % 删除 a 的第一个元素 |
[100 100 100 32 64 128 256 512 1024] |
a(end-1:end) = [] % 删除 a 中最后两个元素 |
[100 100 100 32 64 128 256] |
- 注意点
a(1,3)代表访问1行3列的元素(超过就报错)
a(1,3)代表访问索引为1和索引为3的元素
修改会扩容,删除不会
matlab
a = [2 4 8 16 32];
a(8) = 10
a = [2 4 8 16 32];
a(2,4) = 16三、矩阵
3.1 创建方法
3.1.1 直接输入法
要以中括号" "作为标识符号,矩阵的所有元素必须都在中括号内。矩阵的同行元素之间用空格或逗号分隔,行与行之间用分号或回车键分隔。
3.1.2 函数创建法
- zeros、ones和eye
这三个函数分别用来创建全为0的矩阵、全为1的矩阵和单位矩阵(单位矩阵:主对角线元素为 1 且其他位置元素为 0)
zeros(n)可以创建一个n行n列全为0的矩阵;
zeros(m,n)可以创建一个m行n列全为0的矩阵。
ones 和eye的用法类似
- rand、randi和randn
这三个函数分别用来创建均匀分布的随机数、均匀分布的随机整数和标准正态分布的随机数,以后会大量用到
rand函数可用来创建区间0和1内均匀分布的随机数
rand(n)可以创建一个n行n列的随机数矩阵;rand(m,n)可以创建一个m行n列的随机数矩阵。
randi函数是用来创建均匀分布的随机整数
其最一般的使用方法为:randi(imin,imax,m,n),可以用来创建一个m行n列的随机数矩阵,该随机数矩阵中的每个元素都是从区间imin,imax内随机抽取的整数。
如果imin等于1,那么可以简写为randi(imax,m,n),如果m和n相同,即生成一个n行n列的方阵,那么可以直接写成randi(imin,imax,n)。
randn函数用来创建标准正态分布(标准正态分布:以0为均值、以1为标准差的正态分布,记为N(0,1))的随机数,其使用方法和rand函数一样
- diag和blkdiag
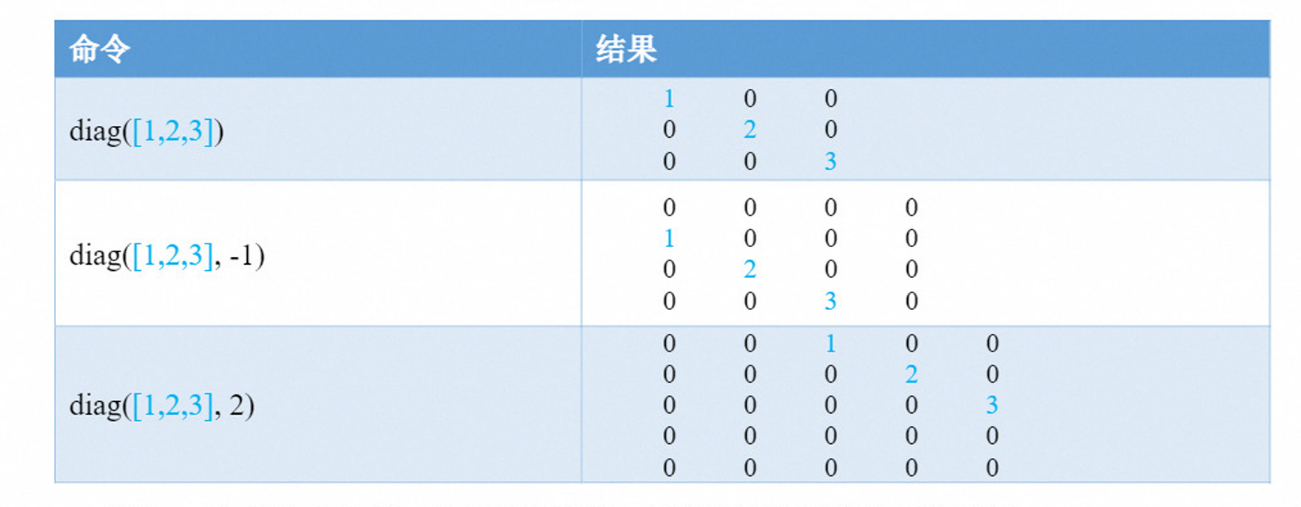
diag函数可用来创建对角矩阵或者获取矩阵的对角元素
如果输入的第一个参数是向量,则表示创建对角矩阵
diag(v,k) 将向量v的元素放置在第k条对角线上,其他位置元素为0。 k=0 表示主对角线,k>0 位于主对角线上方,k<0 位于主对角线下方。如果k=0, 可以直接写成diag(v)
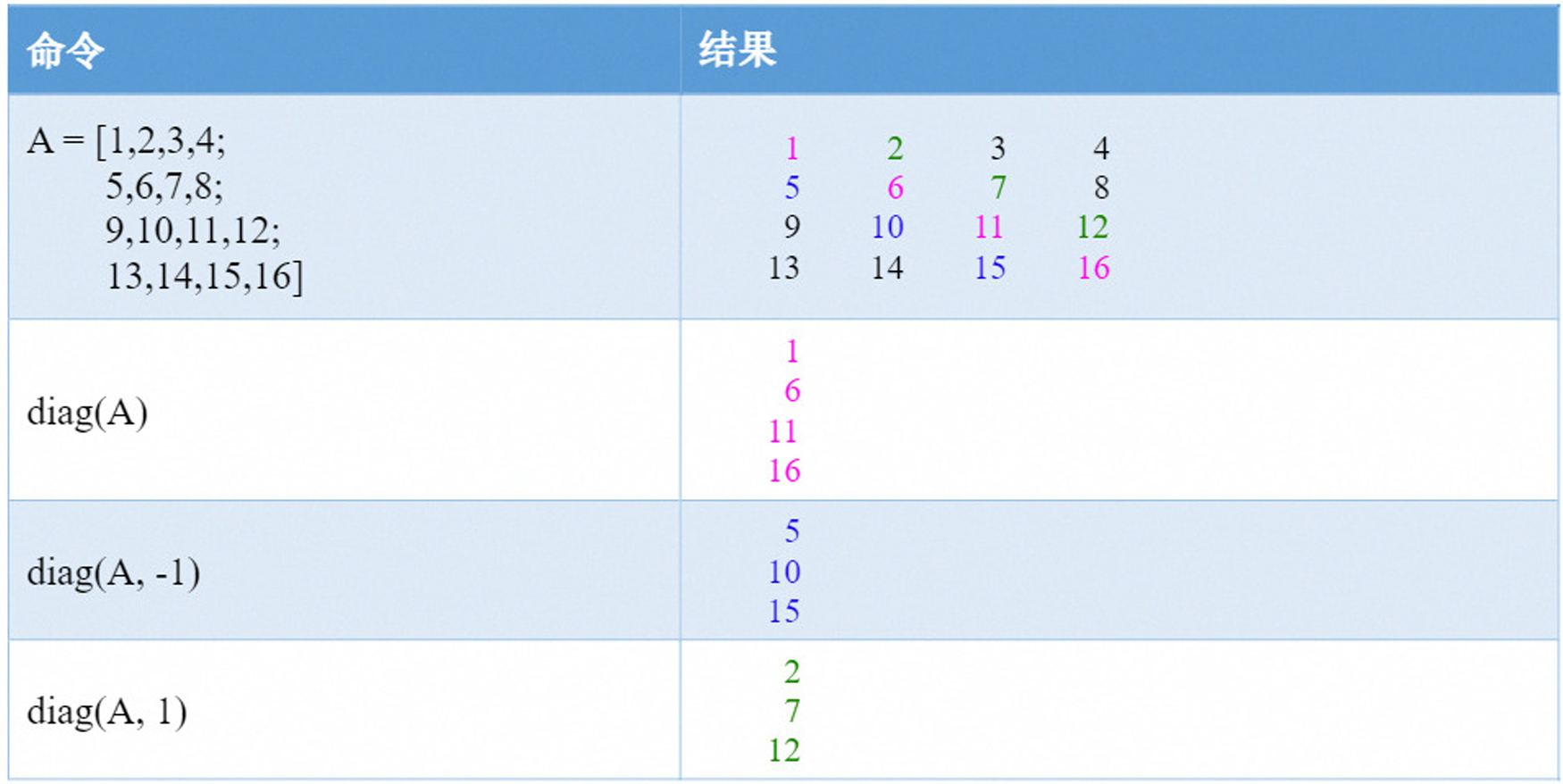
如果输入的第一个参数是矩阵,则表示获取矩阵的对角元素。
diag(A,k) 返回A的第k条对角线上元素的构成的列向量 。 k表示对角线编号,我们将其指定为一个整数。k=0 表示主对角线,k>0 位于主对角线上方,k<0 位于主对角线下方。 如果k=0, diag(A, 0)可以直接写成diag(A)。
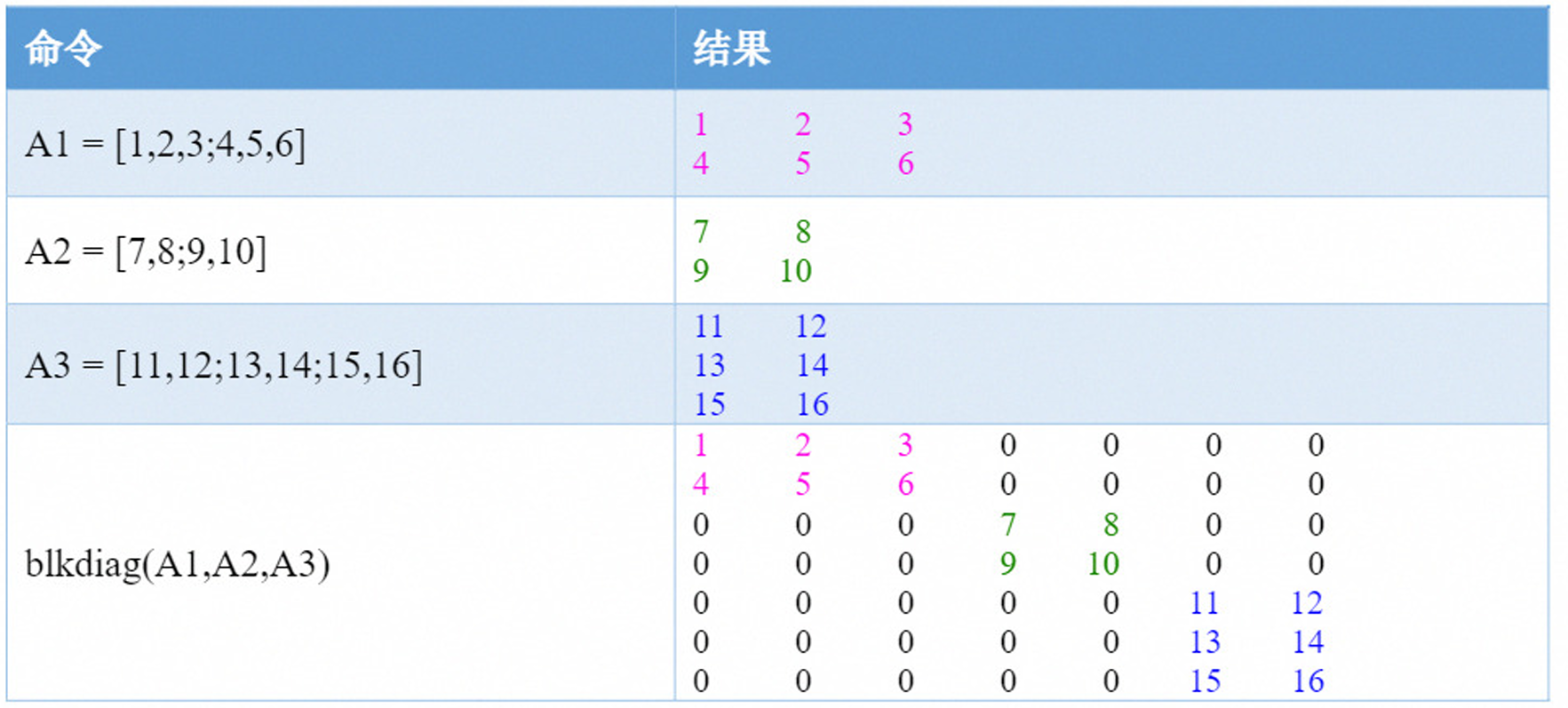
blkdiag函数可用来创建分块对角矩阵
3.2 元素的引用
3.2.1 双下标索引
矩阵元素所处的行(row)和列(column)来进行引用矩阵的某一个元素,方式为:a(row_ind, column_ind). 与向量类似,end也可以用来替代最后一个索引,通常和冒号法一起使用。与向量类似
length函数来计算向量中包含的元素个数。那么,怎么计算一个矩阵的大小呢?
3.2.2 size函数
size(A) 返回一个行向量,其元素是 A 的相应维度的长度,即使A是一个向量,size(A)返回的结果也是一个向量,而不是向量的长度。
matlab
A = ones(4,6) % 全为1的矩阵
s = size(A) % 返回[4,6],表示有4行和6列size(A,dim)返回在维度dim上的长度。dim=1表示行;dim=2表示列
注意:length函数和numel函数也可以用在矩阵上。length函数会返回行和列的较大值:对上面的A矩阵,length(A)返回4;numel函数会返回矩阵中元素的总数,numel(A)返回12
补充一种用法,size函数可以有两个返回值,第一个返回的元素用来保存行数;第二个返回的元素用来保存列数
matlab
A = zeros(3,5)
[r, c] = size(A)%r=3,c=5补充:

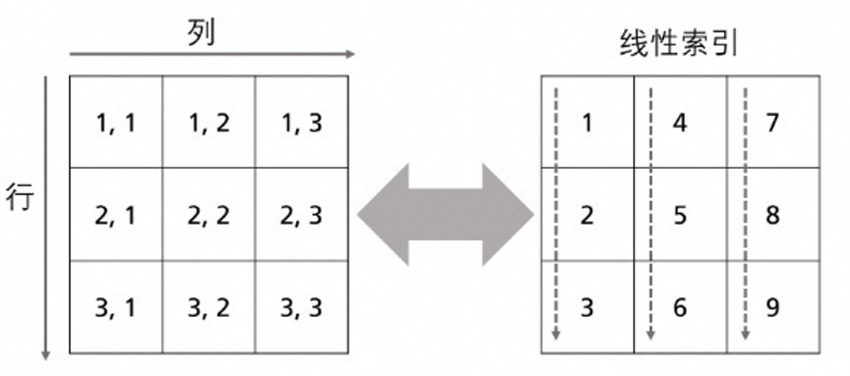
3.2.3 线性索引
在MATLAB中,矩阵的数据在计算机的内存中被存储为单列。以下图为例,下面的矩阵虽然显示为3X3矩阵,但MATLAB在内存中将它存储为单列,由它的各列顺次连接而成。
matlab
A = randi(100,3,5)
A(5)
A(2:7)
A(1:2:end)补充:
A(:)命令可以将A中的所有元素按照线性索引的方式重构成一个列向量(A可以是向量或矩阵)
3.2.4 原始索引和线性索引的区别
sub2ind和ind2sub函数可用于在矩阵的原始索引(双下标)和线性索引之间进行转换
ind = sub2ind(sz,row,col) 针对大小为 sz 的矩阵返回由 row 和 col 指定的行列下标的对应线性索引 ind。此处,sz 是包含两个元素的向量,其中 sz(1) 指定行数,sz(2) 指定列数。
matlab
sub2ind([3,3],2,2)
sub2ind([3,3],1,3)row,col = ind2sub(sz,ind) 返回数组 row 和 col,其中包含与大小为 sz 的矩阵的线性索引 ind 对应的等效行和列下标。此处,sz 是包含两个元素的向量,其中 sz(1) 指定行数,sz(2) 指定列数。
matlab
[row,col] = ind2sub([3,3], 5)
[row,col] = ind2sub([3,3], 7) 3.3 元素的修改和删除
3.3.1 修改
我们可以直接利用等号赋值的方法对矩阵中引用位置的元素进行修改
matlab
A = [1:4;2:5;3:6]
A(4) = 10
A(1:2:end) = 0
A([3,5,6]) = [8 88 888]注意,如果你在赋值时将一个或多个元素置于矩阵现有的行和列索引的边界之外,则会将矩阵的大小进行拓展,MATLAB会将没有赋值的位置的元素自动用0填充,使其保持为完整的矩形
3.3.2 删除
* **通过双下标索引时**,等号右侧变成空向量[],则可以删除对应位置的元素。需要注意的是,通常只能删除矩阵的整行或者整列,否则会报错。- 通过线性索引,使用线性索引删除后,MATLAB会将矩阵中剩下的元素按照线性索引的顺序放入到一个向量中。另外,使用线性索引可以删除任意位置的元素,不需要删除矩阵的一整行或者一整列。返回行向量
3.4 拼接和重复
3.4.1 拼接
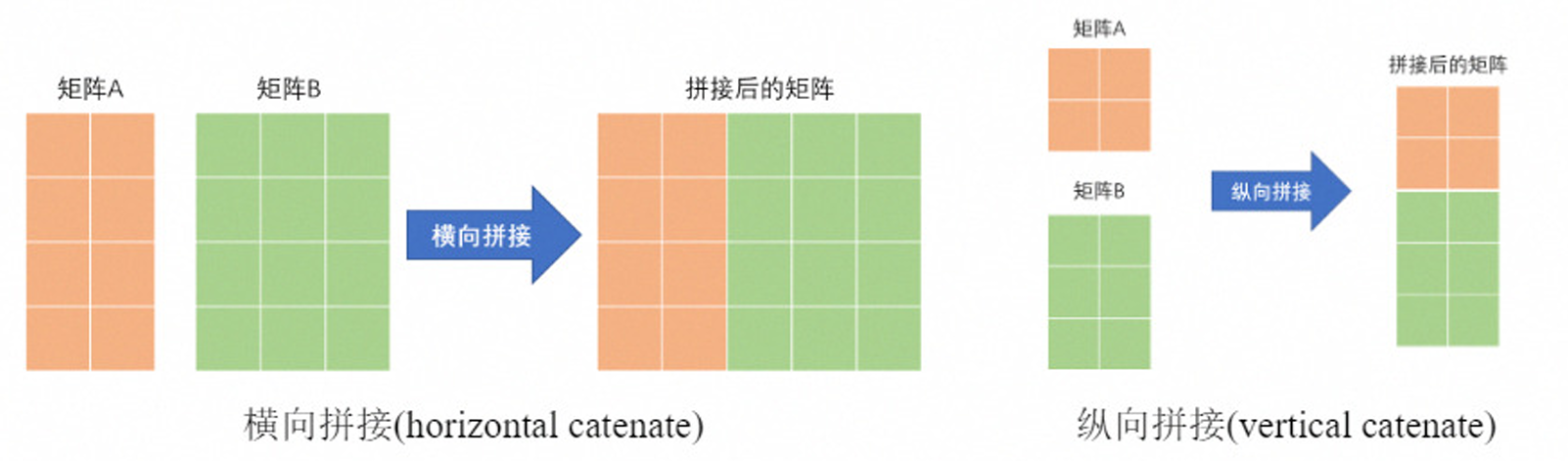
- 横向拼接
横向拼接要求矩阵的行数相同,拼接前,大小不匹配会报错
在MATLAB中,我们可以使用命令A, B 或 A B对矩阵A和B进行横向拼接,也可以使用MATLAB中的内置函数:horzcat(A,B); - 纵向拼接
纵向拼接要求矩阵的列数相同,拼接前,大小不匹配会报错
我们可以使用命令A; B对矩阵A和B进行纵向拼接,也可以使用MATLAB中的内置函数:vertcat(A,B)
补充:
命令**cat(dim,A,B)**表示沿维度 dim 方向将矩阵B拼接到矩阵A的末尾。
dim = 1时表示从上自下沿着行方向拼接,即纵向拼接,因此cat(1,A,B)等价于vertcat(A,B);dim = 2时表示从左自右沿着列方向拼接,即横向拼接,因此cat(2,A,B)等价于horzcat(A,B)。
3.4.2 重复堆叠
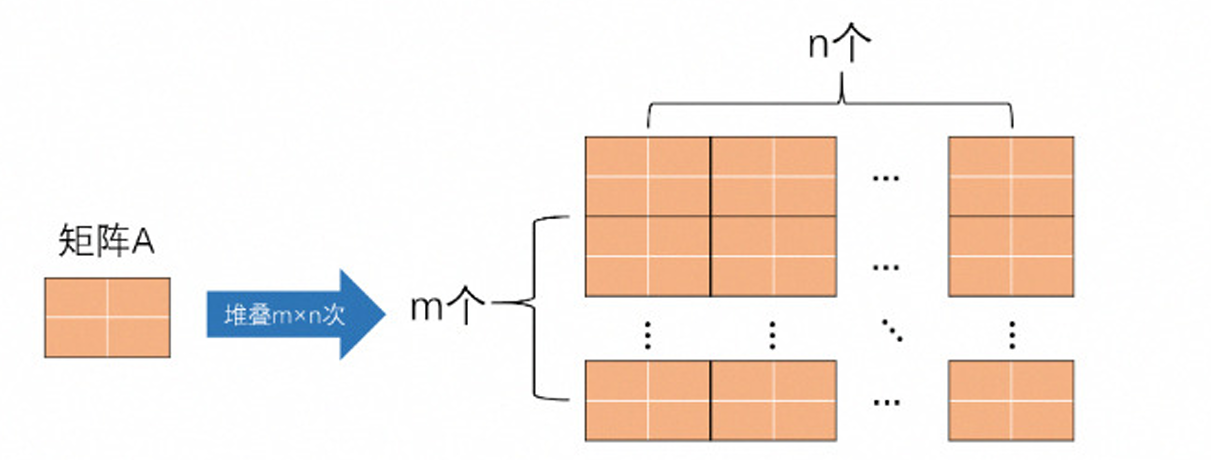
对同一个矩阵进行重复的堆叠的代码为repmat(A,m,n)。
该函数表示:矩阵A的内容堆叠在m行n列的新矩阵中,这个新矩阵每一行由n个A组成,每一列由m个A组成
3.4.3 元素进行重复
repelem包括在向量和矩阵中适用
- repelem(v,n)重复向量v中的元素:
当n为一个正整数时,表示把向量v中的每一个元素都重复n次;
n也可以为一个向量,其长度必须和v的长度相在这里插入代码片同,它可以将v的每个元素指定重复n对应元素的次数。
matlab
v = [5,3,8];
repelem(v,2)
repelem(v,[2,1,4])- repelem(A,m,n)重复矩阵A中的元素
m和n分别表示沿着行方向(从上至下)和列方向(从左至右)将矩阵元素重复的次数,这里的m和n可以是正整数,也可以是向量。
如果m是向量,则m的长度要和矩阵A的行数相同;如果n是向量,则n的长度要和矩阵A的列数相同。
3.5 重构和重新排列
3.5.1 reshape
reshape函数实际上是按矩阵的线性索引来重新组织矩阵元素的。也就是说,它先取矩阵A的第一列,然后是第二列,依此类推,再按新的维度重新组织这些元素。因此,转换后的B矩阵中的元素和A矩阵中的元素是完全相同的,即A(:)和B(:)的结果完全相同。
补充:我们不需要自己来计算转换后的矩阵有多少行或多少列。可以只给出转换后的行数,列数用空向量\[\]代替;或者只给出转换后的列数,行数用空向量\[\]代替
matlab
A = 1:12;
reshape(A,3,[ ])
reshape(A,[ ],4)
reshape(A,3,4)转换后的行数和列数的乘积不等于原始矩阵中元素的个数,那么MATLAB就会报错
3.5.2 sort函数
- 对向量排序
matlab
sort(v) 可以将向量v按照从小到大的顺序进行升序排列
sort(v,'descend')可以将向量v按照从大到小的顺序进行降序排列另外sort函数可以有两个返回值,基本用法为:[sort_v , ind] = sort(v)这里,sort_v是排序后的向量,ind是排序后的向量中的每个元素在v向量中的索引。sort_v向量的方向和sort函数中输入的v向量的方向一致
应用场景:有10名同学,序号分别是1号、2号一直到10号。已知这10名同学的成绩构成的向量为:84 70 61 90 69 78 88 74 92 76,问:清风班上哪三名同学的分数最高,分数分别是多少?这10名同学在班上的排名是多少?
matlab
score = [84 70 61 90 69 78 88 74 92 76];
[sort_score, ind] = sort(score,'descend')
[sort_ind, new_ind] = sort(ind)对于普通排名:4 1 1 3 5 或者中国式排名 3 1 1 2 4不适用
(普通排名的并列排名会占据名次的数字位置,而中国式排名中的并列排名不占用名次)
- 对矩阵A排序
sort(A,dim)
dim = 1时,沿着行方向(从上至下)对矩阵的每一列按照从小到大的顺序分别进行排序,不写时默认为1
dim = 2时,沿着列方向(从左至右)对矩阵的每一行按照从小到大的顺序分别进行排序
可以有两个返回值,代表的含义和对向量排序类似,表示排序后的元素在原矩阵所在行或所在列中的索引。
matlab
A = [4 1 8 7 8 2;
3 7 8 6 4 2;
8 7 8 4 7 6;
1 6 3 1 8 5]
sort(A) % 沿着行方向(从上至下)对矩阵的每一列按照从小到大的顺序分别进行排序
sort(A,2) % dim = 2时,沿着列方向(从左至右)对矩阵的每一行按照从小到大的顺序分别进行排序
sort(A,'descend') % 更改为降序排列
[sort_A , ind] = sort(A)3.5.3 sortrows函数
sortrows 可以基于矩阵的某一列对矩阵进行排序。
默认情况下,sortrows(score)等价于sortrows(score, 1:size(score,2)),即sortrows(score, 1,2,3,4)
实例:
matlab
sort_score2 = sortrows(score,1)%基于第一科的成绩按升序进行排序
sort_score4 = sortrows(score,[1,3])%当第一科成绩相同时,基于第三科成绩升序排列。如果第一科和第三科都相同,就保持在矩阵中出现的先后顺序
sort_score5 = sortrows(score,[1,3],'descend')%第一科的成绩进行降序排列。当第一科成绩相同时,基于第三科成绩降序排列。如果第一科和第三科都相同,就保持在矩阵中出现的先后顺序。
sort_score6 = sortrows(score,[1,3],{'descend','ascend'})%基于第一科的成绩进行降序排列。当第一科成绩相同时,基于第三科成绩升序排列。如果第一科和第三科都相同,就保持在矩阵中出现的先后顺序。- sort与sortrows的区别
sort函数会对矩阵的每一列分别进行排序;
sortrows函数是基于某一列进行排序的,排序后得到的新矩阵的同一行元素不会改变。
3.5.4 flip / fliplr / flipud函数
这三个函数用于对矩阵进行翻转
flip:翻转元素的顺序; fliplr:将数组从左向右翻转 ;flipud:将数组从上向下翻转
后面两个函数是flip函数的特例。
- flip(A)
如果 A 为向量,flip(A) 将沿向量的长度方向翻转元素顺序。(等价于A(end:-1:1))
如果 A 为矩阵,flip(A) 将反转每列元素的顺序。 - flip(A,dim)
如果 A 为矩阵,flip(A,1) 将沿着行方向对矩阵A上下翻转,
flip(A,2) 将沿着列方向对矩阵A左右翻转。
若要对向量A中的元素进行翻转且向量的方向不变,那么可以直接使用flip(A).若要对矩阵A进行翻转,那么flip(A)、flip(A,1)和flipud(A)都能对矩阵A进行上下翻转;flip(A,2)和fliplr(A)能对矩阵A进行左右翻转。
3.5.5 rot90函数
matlab
C = [5 8 7; 4 2 6; 3 5 8; 6 4 1]
rot90(C) % 逆时针方向旋转90度
rot90(C,2) % 逆时针方向旋转90*2=180度
rot90(C,3) % 逆时针方向旋转90*3=270度
rot90(C,-1) % 逆时针旋转-90度;等价于顺时针旋转90度文章结语
感谢你读到这里~我是「键盘敲碎了雾霭」,愿这篇文字帮你敲开了技术里的小迷雾 💻
如果内容对你有一点点帮助,不妨给个暖心三连吧👇
👍 点赞 | ❤️ 收藏 | ⭐ 关注
(听说三连的小伙伴,代码一次编译过,bug绕着走~)
你的支持,就是我继续敲碎技术雾霭的最大动力 🚀
🐶 小彩蛋:
/^ ^\
/ 0 0 \
V\ Y /V
/ - \
/ |
V__) ||摸一摸毛茸茸的小狗,赶走所有疲惫和bug~我们下篇见 ✨