本篇主要简单了解一下开发不部署。后面继续langgraph
14 开发
14.1 LangSmith Studio
在本地使用 LangChain 构建智能体时,如果能可视化 内部运作、实时 交互并随时调试,那会非常有帮助。LangSmith Studio 就是一个免费的可视化界面,专门用于在本地机器上开发和测试你的 LangChain 智能体。
Studio 会连接到你本地运行的智能体,向你展示智能体采取的每一步操作 :包括发送给模型的提示词、工具调用及其结果,以及最终的输出。你可以测试不同的输入、检查中间状态,并且无需编写额外代码或进行部署就能迭代优化智能体的行为。
本页面将介绍如何在本地 LangChain 智能体中设置 Studio
14.1.1 前置条件
在开始之前,请确保您已准备好以下内容:
- LangSmith 账户:请在 smith.langchain.com 免费注册或登录。
- LangSmith API 密钥:请参照"创建 API 密钥"指南进行操作。
如果您不希望数据被追踪至 LangSmith,请在应用程序的 .env 文件中设置 LANGSMITH_TRACING=false。禁用追踪后,所有数据都将保留在您的本地服务器上,不会外传
14.1.2 设置本地agentServer
1. 安装 LangGraph CLI
LangGraph CLI 提供了一个本地开发服务器(也叫 Agent Server),它的作用是将你的智能体连接到 Studio
# Python >= 3.11 is required.
pip install --upgrade "langgraph-cli[inmem]"2 准备agent
如果您已经有了一个 LangChain 智能体,可以直接使用它。本示例使用的是一个简单的邮件智能体
3 设置环境变量
Studio 需要一个 LangSmith API 密钥 才能连接你的本地智能体。请在项目的根目录 下创建一个 .env 文件,并将你在 LangSmith 获取的 API 密钥添加进去
4 创建LangGraph配置文件
LangGraph CLI 使用一个配置文件 来定位你的智能体并管理依赖项。请在你的应用目录中创建一个 langgraph.json 文件
{
"dependencies": ["."],
"graphs": {
"agent": "./src/agent.py:agent"
},
"env": ".env"
}create_agent 函数会自动返回一个编译好的 LangGraph 图 ,而这正是配置文件中 graphs 键所期望的内容
5. 安装依赖
python
#我使用的是本地ollama部署,这里根据具体情况安装
pip install langchain langchain-openai6 在studio里面查看agent
python
#启动开发服务将agent连接到studio
langgraph devSafari 会拦截指向本地主机(localhost)的连接,导致无法访问 Studio。为了解决这个问题,请在运行上述命令时添加 --tunnel 参数,以便通过安全隧道访问 Studio
服务器运行后,你的智能体即可通过以下两种方式访问:
- API 接口 :http://127.0.0.1:2024
- Studio 用户界面 (UI) :https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024
Chrome启动有跨域问题,win10上加--tunnel要报错,使用下面的命令临时启动一个浏览器,
chrome.exe --user-data-dir="F:\tmp" --disable-web-security可以先登录一下langsmith系统,然后再在浏览器上。输入控制台输出的地址,出现类似下面的界面,就是成功了
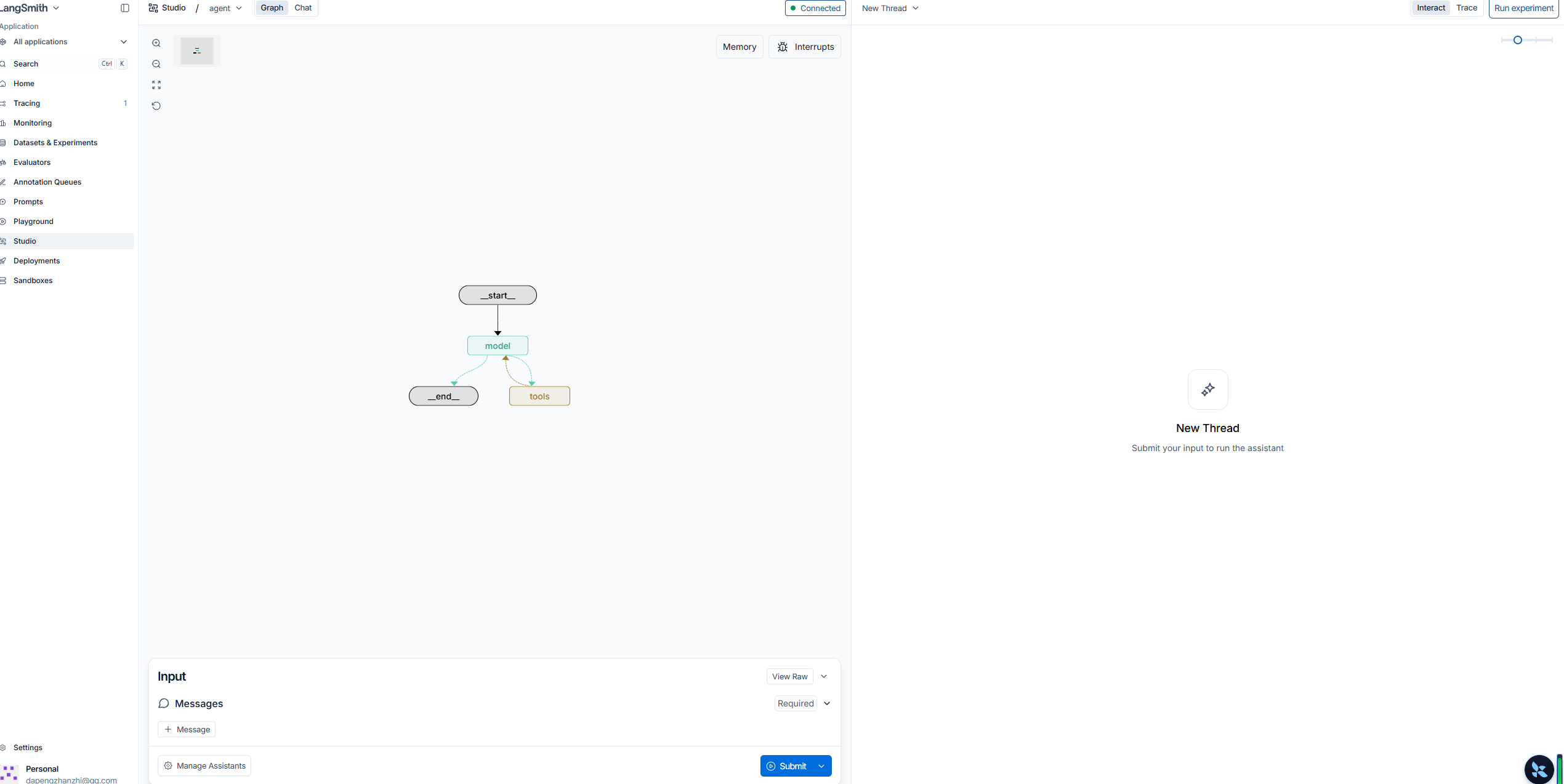
当 Studio 连接到你的本地代理时,你可以快速迭代并优化代理的行为。你可以运行测试输入,并检查完整的执行轨迹,包括提示词、工具参数、返回值以及 Token 用量和延迟指标。当出现问题时,Studio 会捕获异常及其周围的上下文状态,帮助你理解发生了什么。
开发服务器支持热重载------当你在代码中修改提示词或工具签名时,Studio 会立即反映这些更改。你可以从任何步骤重新运行对话线程,从而测试你的更改,而无需从头开始。这种工作流不仅适用于简单的单工具代理,也能扩展到复杂的多节点图。
有关如何运行 Studio 的更多信息,请参考 LangSmith 文档中的以下指南:
- 运行应用程序
- 管理助手
- 管理线程
- 迭代提示词
- 调试 LangSmith 轨迹
- 向数据集添加节点
14.1.3 视频指导
14.2 测试
测试代理主要有以下几种方法:
- 单元测试:使用内存中的模拟对象,隔离地测试代理中微小且确定的部分,以便快速、确定性地验证具体行为。
- 集成测试:通过真实的网络调用来测试代理,以确认各个组件能否协同工作、凭证和架构是否匹配,以及延迟是否在可接受范围内。
- 评估:使用评估器来评判代理的执行轨迹,可以通过确定性匹配或借助大语言模型作为裁判来进行。
由于代理应用通常会将多个组件链接在一起,并且必须应对大语言模型非确定性所带来的不稳定性,因此它们往往更侧重于集成测试。
14.2.1 单元测试
单元测试就是把代理里那些微小且确定的部分隔离开来单独测。你可以通过一个内存里的"假模型"来替代真实的大语言模型(也就是所谓的夹具 fixture),这样你就能像写剧本一样,精确地预设好它的回复(无论是文本、工具调用还是报错)。这么一来,你的测试跑起来就会飞快、完全免费,而且不需要 API 密钥也能无限重复验证
14.2.1.1 模拟聊天模型
LangChain 提供了 GenericFakeChatModel 用于模拟文本响应。它接受一个由响应(AIMessage 对象或字符串)组成的迭代器,并在每次调用时返回其中一个。它同时支持常规用法和流式用法
from langchain_core.language_models.fake_chat_models import GenericFakeChatModel
model = GenericFakeChatModel(messages=iter([
AIMessage(content="", tool_calls=[ToolCall(name="foo", args={"bar": "baz"}, id="call_1")]),
"bar"
]))
model.invoke("hello")
# AIMessage(content='', ..., tool_calls=[{'name': 'foo', 'args': {'bar': 'baz'}, 'id': 'call_1', 'type': 'tool_call'}])如果我们再次调用该模型,它将返回迭代器中的下一项
model.invoke("hello, again!")
# AIMessage(content='bar', ...)14.2.1.2 内存保存检查点
为了在测试过程中启用持久化,你可以使用 InMemorySaver 检查点器。这允许你模拟多轮对话,以测试依赖于状态的行为
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model,
tools=[],
checkpointer=InMemorySaver()
)
# First invocation
agent.invoke(
{"messages": [HumanMessage(content="I live in Sydney, Australia")]},
config={"configurable": {"thread_id": "session-1"}}
)
# Second invocation: the first message is persisted (Sydney location), so the model returns GMT+10 time
agent.invoke(
{"messages": [HumanMessage(content="What's my local time?")]},
config={"configurable": {"thread_id": "session-1"}}
)14.2.1.3 下一步
请前往"集成测试"部分,了解如何使用真实的模型提供商 API 来测试你的智能体
14.2.2 集成测试
集成测试用于验证你的智能体是否能与模型 API 及外部服务正确协作。与使用伪造对象和模拟对象的单元测试不同,集成测试会发起实际的网络调用,以确认各组件能够协同工作、凭据有效且延迟在可接受范围内。
由于大语言模型的响应具有非确定性,集成测试需要采用与传统软件测试不同的策略。本指南将介绍如何组织、编写和运行智能体的集成测试。关于为 LangChain 本身贡献代码时的一般测试基础设施,请参阅"代码贡献"
14.2.2.1 分离单元测试与集成测试
集成测试速度较慢且需要 API 凭据,因此应将它们与单元测试分开。这样你就可以在每次更改时运行快速的单元测试,而将集成测试保留给 CI(持续集成)或部署前的检查。
使用 pytest 标记来标记集成测试
import pytest
@pytest.mark.integration
def test_agent_with_real_model():
agent = create_agent("claude-sonnet-4-6", tools=[get_weather])
result = agent.invoke({
"messages": [HumanMessage(content="What's the weather in SF?")]
})
assert len(result["messages"]) > 1配置 pytest 以识别该标记,并在默认运行中排除集成测试
#pytest.ini
[pytest]
markers =
integration: tests that call real LLM APIs
addopts = -m "not integration"
#pyproject.toml
[tool.pytest.ini_options]
markers = [
"integration: tests that call real LLM APIs"
]
addopts = "-m 'not integration'"显式运行集成测试
pytest -m integration14.2.2.2 管理API keys
集成测试需要真实的 API 凭据。请从环境变量中加载它们,以确保密钥不会进入源代码管理。使用 conftest.py 中的 fixture(夹具)来验证所需的密钥是否可用
import os
import pytest
@pytest.fixture(autouse=True)
def check_api_keys():
if not os.environ.get("OPENAI_API_KEY"):
pytest.skip("OPENAI_API_KEY not set")对于本地开发,请将密钥存储在 .env 文件中,并使用 python-dotenv 进行加载
#.env
OPENAI_API_KEY=sk-...
#conftest.py
from dotenv import load_dotenv
load_dotenv()将 .env 添加到你的 .gitignore 文件中,以避免提交凭据。在 CI 中,请通过你的服务提供商的密钥管理功能(例如 GitHub Actions secrets)注入密钥。
14.2.2.3 断言结构,而不是内容
大语言模型的响应在每次运行之间都会有所不同。与其断言完全匹配的输出字符串,不如验证响应的结构属性:消息类型、工具调用名称、参数结构和消息数量
def test_agent_calls_weather_tool():
agent = create_agent("claude-sonnet-4-6", tools=[get_weather])
result = agent.invoke({
"messages": [HumanMessage(content="What's the weather in SF?")]
})
messages = result["messages"]
tool_calls = [
tc
for msg in messages
if hasattr(msg, "tool_calls")
for tc in (msg.tool_calls or [])
]
assert any(tc["name"] == "get_weather" for tc in tool_calls)
assert isinstance(messages[-1], AIMessage)
assert len(messages[-1].content) > 0若需进行更严格的轨迹断言,请使用 AgentEvals 评估器,它支持无序和超集等模糊匹配模式
14.2.2.4 降低消耗和延迟
-
使用较小的模型 :对于仅需验证工具调用和响应结构的测试,请使用
gemini-3.1-flash-lite-preview或同等模型。 -
设置
maxTokens:限制响应长度,以避免生成长且昂贵的补全内容。 -
限制测试范围:每个测试只验证一种行为。当单轮测试就足够时,避免使用串联多个大语言模型调用的端到端场景。
-
有选择地运行:利用上述的测试分离方法,仅在 CI 或部署前运行集成测试,而不是在每次保存文件时都运行。
agent = create_agent(
"gemini-3.1-flash-lite-preview",
tools=[get_weather],
model_kwargs={"max_tokens": 256},
)
14.2.2.5 记录和重放http调用
对于在 CI 中频繁运行的测试,你可以在首次运行时录制 HTTP 交互,并在后续运行中回放它们,而无需进行真实的 API 调用。这消除了初始录制之后的成本和延迟。
vcrpy 将 HTTP 请求/响应对记录到 YAML "cassette" 文件中。pytest-recording 插件将此功能与 pytest 集成。
请设置你的 conftest.py 以过滤 cassette 文件中的敏感信息
import pytest
@pytest.fixture(scope="session")
def vcr_config():
return {
"filter_headers": [
("authorization", "XXXX"),
("x-api-key", "XXXX"),
],
"filter_query_parameters": [
("api_key", "XXXX"),
("key", "XXXX"),
],
}配置你的项目以识别 vcr 标记
#pytest.ini
[pytest]
markers =
vcr: record/replay HTTP via VCR
addopts = --record-mode=once
#pyproject.toml
[tool.pytest.ini_options]
markers = [
"vcr: record/replay HTTP via VCR"
]
addopts = "--record-mode=once"--record-mode=once 选项会在首次运行时录制 HTTP 交互,并在后续运行中回放它们
@pytest.mark.vcr()
def test_agent_trajectory():
agent = create_agent("claude-sonnet-4-6", tools=[get_weather])
result = agent.invoke({
"messages": [HumanMessage(content="What's the weather in SF?")]
})
assert any(
tc["name"] == "get_weather"
for msg in result["messages"]
if hasattr(msg, "tool_calls")
for tc in (msg.tool_calls or [])
)首次运行会进行真实的网络调用,并在 tests/cassettes/ 目录下生成 cassette 文件。后续运行则会回放已录制的响应。
当你修改提示词、添加新工具或更改预期的轨迹时,已保存的 cassette 文件将过时,导致现有的测试失败。此时请删除相应的 cassette 文件并重新运行测试,以录制新的交互内容
14.2.2.6 下一步
了解如何在 Evals 中使用确定性匹配或"LLM 作为评判者"评估器来评估智能体的轨迹
14.2.3 智能体评估
评估("Evals")通过评估智能体的执行轨迹(即它生成的消息和工具调用序列)来衡量其性能。与验证基本正确性的集成测试不同,评估会根据参考答案或评分标准对智能体行为进行打分,这使得它们在更改提示词、工具或模型时,对于捕捉回归问题非常有用。
评估器是一个函数,它接收智能体的输出(以及可选的参考输出)并返回一个分数
def evaluator(*, outputs: dict, reference_outputs: dict):
output_messages = outputs["messages"]
reference_messages = reference_outputs["messages"]
score = compare_messages(output_messages, reference_messages)
return {"key": "evaluator_score", "score": score}gentevals 包为智能体轨迹提供了预置的评估器。你可以通过执行轨迹匹配(确定性比较)或使用 LLM 评判(定性评估)来进行评估:
| 方法 | 适用场景 |
|---|---|
| 轨迹匹配 | 你已知预期的工具调用,并希望进行快速、确定性且无成本的检查 |
| LLM 作为评判者 | 你希望评估整体质量和推理能力,而没有严格的预期要求 |
14.2.3.1 安装AgentEvals
pip install agentevals14.2.3.2 轨迹匹配评估器
AgentEvals 提供了 create_trajectory_match_evaluator 函数,用于将你的智能体轨迹与参考轨迹进行匹配。该函数包含四种模式:
| 模式 | 描述 | 适用场景 |
|---|---|---|
| strict | 精确匹配消息结构和工具调用的顺序(消息内容可以不同) | 测试特定序列(例如:先查询策略再进行授权) |
| unordered | 与参考轨迹具有相同的消息结构和工具调用,但工具调用的顺序可以是任意的 | 验证信息检索,且顺序无关紧要的情况 |
| subset | 智能体仅调用参考轨迹中的工具(无额外调用) | 确保智能体未超出预期范围 |
| superset | 智能体至少调用了参考轨迹中的工具(允许额外调用) | 验证是否采取了最低限度的必要操作 |
from langchain.agents import create_agent
from langchain.tools import tool
from langchain.messages import HumanMessage, AIMessage, ToolMessage
from agentevals.trajectory.match import create_trajectory_match_evaluator
@tool
def get_weather(city: str):
"""Get weather information for a city."""
return f"It's 75 degrees and sunny in {city}."
agent = create_agent("claude-sonnet-4-6", tools=[get_weather])严格匹配
严格模式确保轨迹包含相同的消息(顺序一致且工具调用相同),但允许消息内容存在差异。当你需要强制执行特定的操作序列时(例如要求在授权操作之前先进行策略查找),这种模式非常有用
python
evaluator = create_trajectory_match_evaluator(
trajectory_match_mode="strict",
)
def test_weather_tool_called_strict():
result = agent.invoke({
"messages": [HumanMessage(content="What's the weather in San Francisco?")]
})
reference_trajectory = [
HumanMessage(content="What's the weather in San Francisco?"),
AIMessage(content="", tool_calls=[
{"id": "call_1", "name": "get_weather", "args": {"city": "San Francisco"}}
]),
ToolMessage(content="It's 75 degrees and sunny in San Francisco.", tool_call_id="call_1"),
AIMessage(content="The weather in San Francisco is 75 degrees and sunny."),
]
evaluation = evaluator(
outputs=result["messages"],
reference_outputs=reference_trajectory
)
# {
# 'key': 'trajectory_strict_match',
# 'score': True,
# 'comment': None,
# }
assert evaluation["score"] is True无顺序匹配
无序模式允许以任意顺序执行相同的工具调用。当你想验证是否检索到了特定信息但不在乎顺序时,这种模式非常有用。例如,一个智能体通过不同的工具调用来查询某城市的天气和活动
python
@tool
def get_events(city: str):
"""Get events happening in a city."""
return f"Concert at the park in {city} tonight."
agent = create_agent("claude-sonnet-4-6", tools=[get_weather, get_events])
evaluator = create_trajectory_match_evaluator(
trajectory_match_mode="unordered",
)
def test_multiple_tools_any_order():
result = agent.invoke({
"messages": [HumanMessage(content="What's happening in SF today?")]
})
reference_trajectory = [
HumanMessage(content="What's happening in SF today?"),
AIMessage(content="", tool_calls=[
{"id": "call_1", "name": "get_events", "args": {"city": "SF"}},
{"id": "call_2", "name": "get_weather", "args": {"city": "SF"}},
]),
ToolMessage(content="Concert at the park in SF tonight.", tool_call_id="call_1"),
ToolMessage(content="It's 75 degrees and sunny in SF.", tool_call_id="call_2"),
AIMessage(content="Today in SF: 75 degrees and sunny with a concert at the park tonight."),
]
evaluation = evaluator(
outputs=result["messages"],
reference_outputs=reference_trajectory,
)
assert evaluation["score"] is True子集或者超集匹配
超集和子集模式用于匹配部分轨迹。超集模式验证智能体是否至少调用了参考轨迹中的工具,并允许额外的工具调用。子集模式则确保智能体没有调用参考轨迹之外的任何工具
python
@tool
def get_detailed_forecast(city: str):
"""Get detailed weather forecast for a city."""
return f"Detailed forecast for {city}: sunny all week."
agent = create_agent("claude-sonnet-4-6", tools=[get_weather, get_detailed_forecast])
evaluator = create_trajectory_match_evaluator(
trajectory_match_mode="superset",
)
def test_agent_calls_required_tools_plus_extra():
result = agent.invoke({
"messages": [HumanMessage(content="What's the weather in Boston?")]
})
# Reference only requires get_weather, but agent may call additional tools
reference_trajectory = [
HumanMessage(content="What's the weather in Boston?"),
AIMessage(content="", tool_calls=[
{"id": "call_1", "name": "get_weather", "args": {"city": "Boston"}},
]),
ToolMessage(content="It's 75 degrees and sunny in Boston.", tool_call_id="call_1"),
AIMessage(content="The weather in Boston is 75 degrees and sunny."),
]
evaluation = evaluator(
outputs=result["messages"],
reference_outputs=reference_trajectory,
)
assert evaluation["score"] is True14.2.3.3 LLM作为评估器
你可以使用 create_trajectory_llm_as_judge 函数,通过 LLM 来评估智能体的执行路径。与轨迹匹配评估器不同,它不需要参考轨迹,但如果有的话,也可以提供
#无轨迹引用
from agentevals.trajectory.llm import create_trajectory_llm_as_judge, TRAJECTORY_ACCURACY_PROMPT
evaluator = create_trajectory_llm_as_judge(
model="openai:o3-mini",
prompt=TRAJECTORY_ACCURACY_PROMPT,
)
def test_trajectory_quality():
result = agent.invoke({
"messages": [HumanMessage(content="What's the weather in Seattle?")]
})
evaluation = evaluator(
outputs=result["messages"],
)
assert evaluation["score"] is True
#有参照轨迹
from agentevals.trajectory.llm import create_trajectory_llm_as_judge, TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE
evaluator = create_trajectory_llm_as_judge(
model="openai:o3-mini",
prompt=TRAJECTORY_ACCURACY_PROMPT_WITH_REFERENCE,
)
evaluation = evaluator(
outputs=result["messages"],
reference_outputs=reference_trajectory,
)所有的 agentevals 评估器都支持 Python asyncio。只需在函数名的 create_ 后面加上 async,即可使用异步版本
14.2.3.4 在LangSmith运行评估
为了跟踪随时间推移进行的实验,可以将评估器的结果记录到 LangSmith。首先,请设置所需的环境变量
python
export LANGSMITH_API_KEY="your_langsmith_api_key"
export LANGSMITH_TRACING="true"LangSmith 提供了两种主要的运行评估的方法:pytest 集成和 evaluate 函数
python
#pytest 集成
import pytest
from langsmith import testing as t
from agentevals.trajectory.llm import create_trajectory_llm_as_judge, TRAJECTORY_ACCURACY_PROMPT
trajectory_evaluator = create_trajectory_llm_as_judge(
model="openai:o3-mini",
prompt=TRAJECTORY_ACCURACY_PROMPT,
)
@pytest.mark.langsmith
def test_trajectory_accuracy():
result = agent.invoke({
"messages": [HumanMessage(content="What's the weather in SF?")]
})
reference_trajectory = [
HumanMessage(content="What's the weather in SF?"),
AIMessage(content="", tool_calls=[
{"id": "call_1", "name": "get_weather", "args": {"city": "SF"}},
]),
ToolMessage(content="It's 75 degrees and sunny in SF.", tool_call_id="call_1"),
AIMessage(content="The weather in SF is 75 degrees and sunny."),
]
t.log_inputs({})
t.log_outputs({"messages": result["messages"]})
t.log_reference_outputs({"messages": reference_trajectory})
trajectory_evaluator(
outputs=result["messages"],
reference_outputs=reference_trajectory
)
python
#pytest运行评估
pytest test_trajectory.py --langsmith-output使用评估函数
创建一个 LangSmith 数据集并使用 evaluate 函数。该数据集必须遵循以下模式:
- input :
{"messages": [...]}------ 用于调用智能体的输入消息。 - output :
{"messages": [...]}------ 智能体输出中的预期消息历史。对于轨迹评估,你可以选择仅保留助手(assistant)消息
python
from langsmith import Client
from agentevals.trajectory.llm import create_trajectory_llm_as_judge, TRAJECTORY_ACCURACY_PROMPT
client = Client()
trajectory_evaluator = create_trajectory_llm_as_judge(
model="openai:o3-mini",
prompt=TRAJECTORY_ACCURACY_PROMPT,
)
def run_agent(inputs):
return agent.invoke(inputs)["messages"]
experiment_results = client.evaluate(
run_agent,
data="your_dataset_name",
evaluators=[trajectory_evaluator]
)若要进一步了解如何评估你的智能体,请参阅 LangSmith 官方文档
14.3 聊天UI
Agent Chat UI 是一个基于 Next.js 开发的应用程序,它为与任何 LangChain 智能体交互提供了一个对话式界面。它支持实时聊天、工具可视化,以及时间旅行调试和状态分叉等高级功能。Agent Chat UI 与使用 create_agent 创建的智能体无缝协作,只需最少的设置即可为你的智能体提供交互式体验,无论是在本地运行还是在部署环境(如 LangSmith)中。Agent Chat UI 是开源的,可以根据你的应用需求进行调整
14.3.1 快熟开始
最快的入门方式是使用托管版本:
- 访问Agent Chat UI
- 输入你的部署 URL 或本地服务器地址来连接你的智能体
- 开始聊天 ------ 界面将自动检测并渲染工具调用和中断
14.3.2 本地开发
若需进行定制或本地开发,你可以在本地运行 Agent Chat UI:
python
# Create a new Agent Chat UI project
npx create-agent-chat-app --project-name my-chat-ui
cd my-chat-ui
# Install dependencies and start
pnpm install
pnpm dev或者
python
# Clone the repository
git clone https://github.com/langchain-ai/agent-chat-ui.git
cd agent-chat-ui
# Install dependencies and start
pnpm install
pnpm dev0] web:dev: ▲ Next.js 15.5.15
[0] web:dev: - Local: http://localhost:3000
[0] web:dev: - Network: http://192.168.1.6:3000
[0] web:dev:
[0] web:dev: ✓ Starting...
[1] agents:dev:
[1] agents:dev: Welcome to
[1] agents:dev:
[1] agents:dev: ╦ ┌─┐┌┐┌┌─┐╔═╗┬─┐┌─┐┌─┐┬ ┬
[1] agents:dev: ║ ├─┤││││ ┬║ ╦├┬┘├─┤├─┘├─┤
[1] agents:dev: ╩═╝┴ ┴┘└┘└─┘╚═╝┴└─┴ ┴┴ ┴ ┴.js
[1] agents:dev:
[1] agents:dev: - 🚀 API: http://localhost:2024
[1] agents:dev: - 🎨 Studio UI: https://smith.langchain.com/studio?baseUrl=http://localhost:202414.3.3 连接agent
在浏览器山上输入地址:http://localhost:3000 启动 Agent Chat UI 后,你需要对其进行配置以连接到你的智能体:
- Graph ID :输入你的图名称(可在你的
langgraph.json文件中的graphs下找到)。 - Deployment URL :你的智能体服务器端点(例如,本地开发使用
http://localhost:2024,或你的已部署智能体的 URL)。 - LangSmith API key (可选):添加你的 LangSmith API 密钥(如果你使用的是本地智能体服务器,则不需要)。
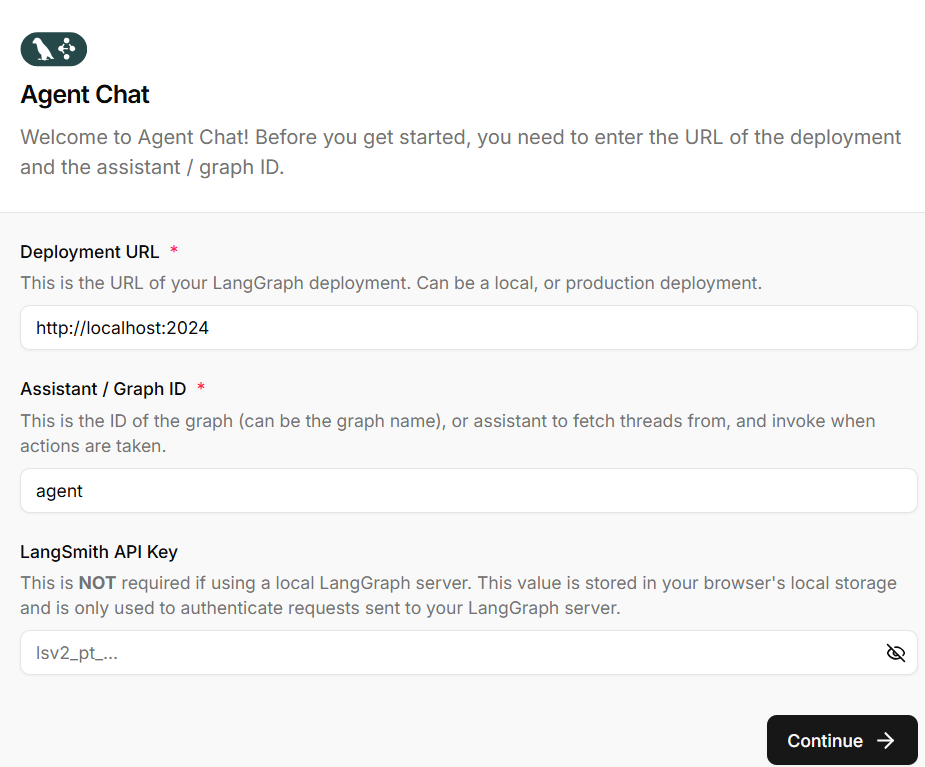
agent chat ui 配置.env中加NEXT_PUBLIC_LANGCHAIN_TRACING_V2=false防止连接前端连接公网,需要重启浏览器,不然会有缓存。
配置完成后,Agent Chat UI 将自动获取并显示来自你的智能体的任何已中断的线程
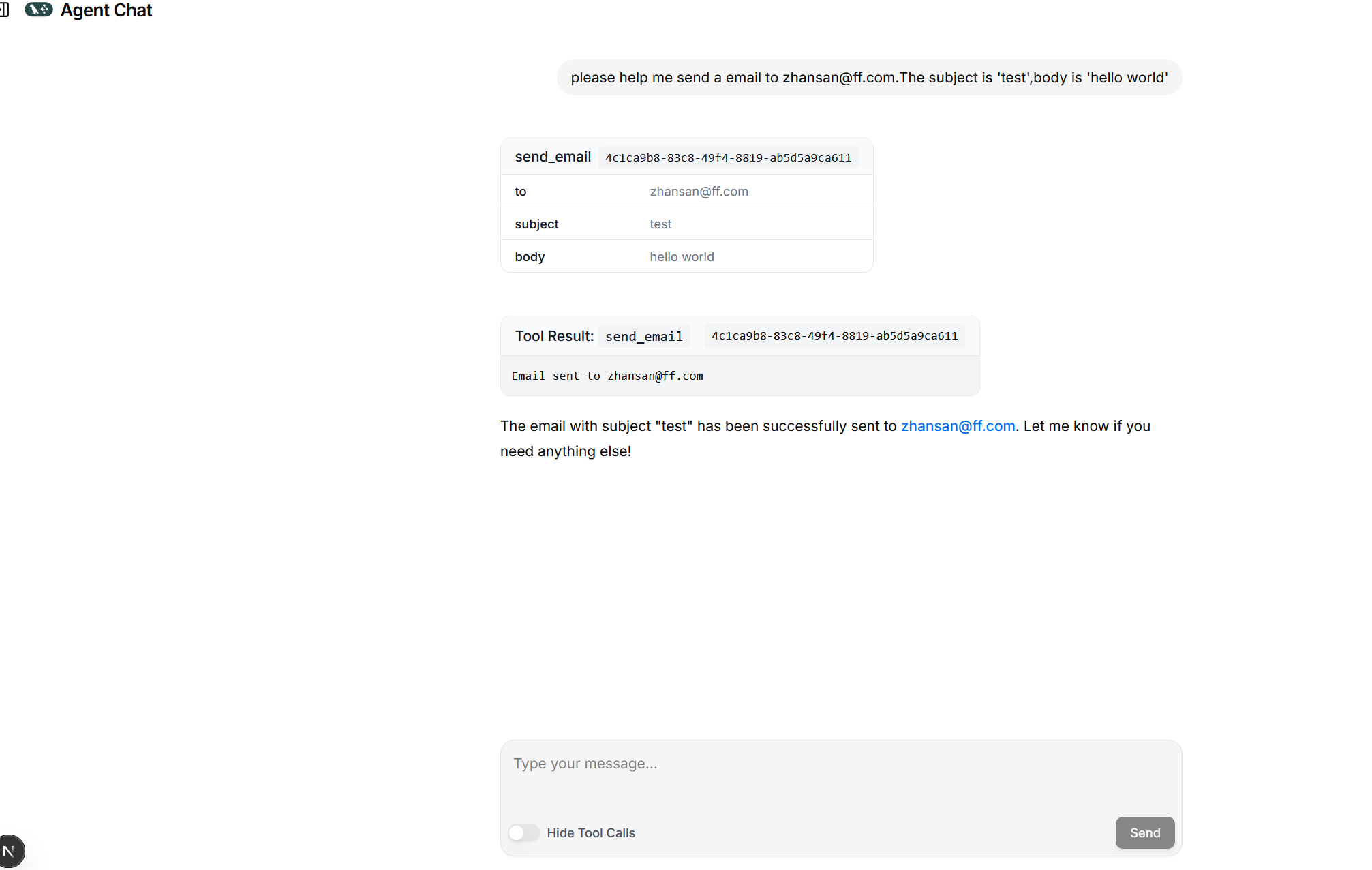
输入消息后,调用了工具说明确实触发了工具调用
Agent Chat UI 具备开箱即用的功能,可直接渲染工具调用和工具结果消息。若要自定义显示的消息,请参阅"在聊天中隐藏消息"部分
15 使用langSmith部署
15.1 部署
当你准备将 LangChain 智能体部署到生产环境时,LangSmith 提供了一个专为智能体工作负载设计的托管平台。传统的托管平台通常是为无状态、短生命周期的 Web 应用程序构建的,而 LangGraph 则是专门为需要持久化状态和后台执行的有状态、长周期智能体打造的。LangSmith 负责处理基础设施、扩展和运维方面的琐事,让你可以直接从代码仓库进行部署
15.1.1 前置条件
在开始之前,请确保你已具备以下条件:
- 一个 GitHub 账号
- 一个 LangSmith 账号(注册免费)
15.1.2 部署智能体
- 进入 LangSmith 部署页面:登录 LangSmith。在左侧边栏中,选择 Deployments(部署)。
- 创建新部署:点击 + New Deployment(+ 新建部署)按钮。此时会弹出一个侧边栏,你可以在其中填写必填字段。
- 关联代码仓库:如果你是首次使用,或者要添加一个之前未连接过的私有仓库,请点击 Add new account(添加新账户)按钮,并按照说明连接你的 GitHub 账户。
- 部署仓库:选择你应用程序所在的仓库。点击 Submit(提交)以开始部署。此过程可能需要大约 15 分钟才能完成。你可以在"部署详情"视图中检查进度状态
- 测试API:
1 安装依赖
pip install langgraph-sdk2 发送消息
from langgraph_sdk import get_sync_client # or get_client for async
client = get_sync_client(url="your-deployment-url", api_key="your-langsmith-api-key")
for chunk in client.runs.stream(
None, # Threadless run
"agent", # Name of agent. Defined in langgraph.json.
input={
"messages": [{
"role": "human",
"content": "What is LangGraph?",
}],
},
stream_mode="updates",
):
print(f"Receiving new event of type: {chunk.event}...")
print(chunk.data)
print("\n\n")
from langgraph_sdk import get_sync_client # or get_client for async
client = get_sync_client(url="your-deployment-url", api_key="your-langsmith-api-key")
for chunk in client.runs.stream(
None, # Threadless run
"agent", # Name of agent. Defined in langgraph.json.
input={
"messages": [{
"role": "human",
"content": "What is LangGraph?",
}],
},
stream_mode="updates",
):
print(f"Receiving new event of type: {chunk.event}...")
print(chunk.data)
print("\n\n")LangSmith 还提供了其他的托管选项,包括自托管和混合模式。如需更多信息,请参阅平台设置概览
15.2 观测
在使用 LangChain 构建和运行智能体时,你需要清楚地了解它们的行为表现:比如调用了哪些工具、生成了什么提示词,以及它们是如何做出决策的。使用 create_agent 构建的 LangChain 智能体默认支持通过 LangSmith 进行追踪,这是一个用于捕获、调试、评估和监控大语言模型应用行为的平台。
追踪记录会记下智能体执行的每一个步骤,从最初的用户输入到最终的回答,涵盖了所有的工具调用、模型交互以及决策节点。这些执行数据能帮你排查问题、评估不同输入下的性能表现,并监控生产环境中的使用模式。
本指南将向你展示如何为 LangChain 智能体启用追踪功能,并利用 LangSmith 来分析它们的执行情况
15.2.1 准备工作
在开始之前,请确保你已具备以下条件:
- 一个 LangSmith 账号:在 smith.langchain.com 免费注册或登录。
- 一个 LangSmith API 密钥:请参照"创建 API 密钥"指南进行操作。
15.2.2 开启追踪
所有的 LangChain 智能体都原生支持 LangSmith 追踪功能。要启用它,只需设置以下环境变量即可
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY=<your-api-key>15.2.3 快速开始
不需要编写任何额外的代码就能将追踪记录发送到 LangSmith。只需像往常一样运行你的智能体代码即可
python
from langchain.agents import create_agent
def send_email(to: str, subject: str, body: str):
"""Send an email to a recipient."""
# ... email sending logic
return f"Email sent to {to}"
def search_web(query: str):
"""Search the web for information."""
# ... web search logic
return f"Search results for: {query}"
agent = create_agent(
model="gpt-4.1",
tools=[send_email, search_web],
system_prompt="You are a helpful assistant that can send emails and search the web."
)
# Run the agent - all steps will be traced automatically
response = agent.invoke({
"messages": [{"role": "user", "content": "Search for the latest AI news and email a summary to john@example.com"}]
})默认情况下,追踪记录会被记录到名为 default 的项目中。若要配置自定义的项目名称,请参阅"记录到项目"相关文档
15.2.4 选择性追踪
你可以利用 LangSmith 的 tracing_context 上下文管理器,选择只追踪特定的调用或应用程序的某些部分
python
import langsmith as ls
# This WILL be traced
with ls.tracing_context(enabled=True):
agent.invoke({"messages": [{"role": "user", "content": "Send a test email to alice@example.com"}]})
# This will NOT be traced (if LANGSMITH_TRACING is not set)
agent.invoke({"messages": [{"role": "user", "content": "Send another email"}]})15.2.5 记录到项目
静态方式
你可以通过设置 LANGSMITH_PROJECT 环境变量,为你的整个应用程序指定一个自定义的项目名称
python
export LANGSMITH_PROJECT=my-agent-project动态方式
你可以通过编程方式为特定操作设置项目名称
python
import langsmith as ls
with ls.tracing_context(project_name="email-agent-test", enabled=True):
response = agent.invoke({
"messages": [{"role": "user", "content": "Send a welcome email"}]
})15.2.6 添加跟踪元数据
你可以用自定义的元数据和标签来给你的追踪记录添加注释
python
response = agent.invoke(
{"messages": [{"role": "user", "content": "Send a welcome email"}]},
config={
"tags": ["production", "email-assistant", "v1.0"],
"metadata": {
"user_id": "user_123",
"session_id": "session_456",
"environment": "production"
}
}
)tracing_context 同时也接受标签和元数据,以便进行更细粒度的控制
python
with ls.tracing_context(
project_name="email-agent-test",
enabled=True,
tags=["production", "email-assistant", "v1.0"],
metadata={"user_id": "user_123", "session_id": "session_456", "environment": "production"}):
response = agent.invoke(
{"messages": [{"role": "user", "content": "Send a welcome email"}]}
)这些自定义的元数据和标签将会被附加到 LangSmith 中的追踪记录上
若想深入了解如何利用追踪记录来调试、评估和监控你的智能体,请参阅LangSmith 官方文档
总结
到此为止,langchain基本框架了解完毕。这个玩意要工程化还得动一番脑子。