摘要:
2026年4月16日,Anthropic 发布了其最新旗舰大模型 Claude Opus 4.7。

本次更新的核心在于引入了自适应推理路径与自验证机制,使得模型在处理长链逻辑任务时的稳定性大幅提升。
本文将通过多组 Benchmark 数据,深度对比 Opus 4.7 与其前代及 GPT-5.4 的技术差异,并拆解其在长文本抗漂移领域的底层逻辑。
一、 技术架构演进:从自回归到自验证
大模型在执行逻辑密集型任务时,容易因为自回归生成的预测性特质产生路径偏差。Claude Opus 4.7 针对这一痛点,在推理阶段引入了自验证(Self-Verification)机制。
当模型接收到高复杂度的 Prompt 时,底层架构会自动触发自适应思考路径。该机制允许模型在生成正式 Response 之前,先在内部隐空间内进行逻辑自审。
相比于旧版模型,4.7 版本在处理法律合规审计、金融风控建模等严谨场景时,逻辑断裂率降低了约 35%。这种先思考后输出的范式,是 AI 迈向工业级应用的关键。
二、 核心性能对标:多维度 Benchmark 分析
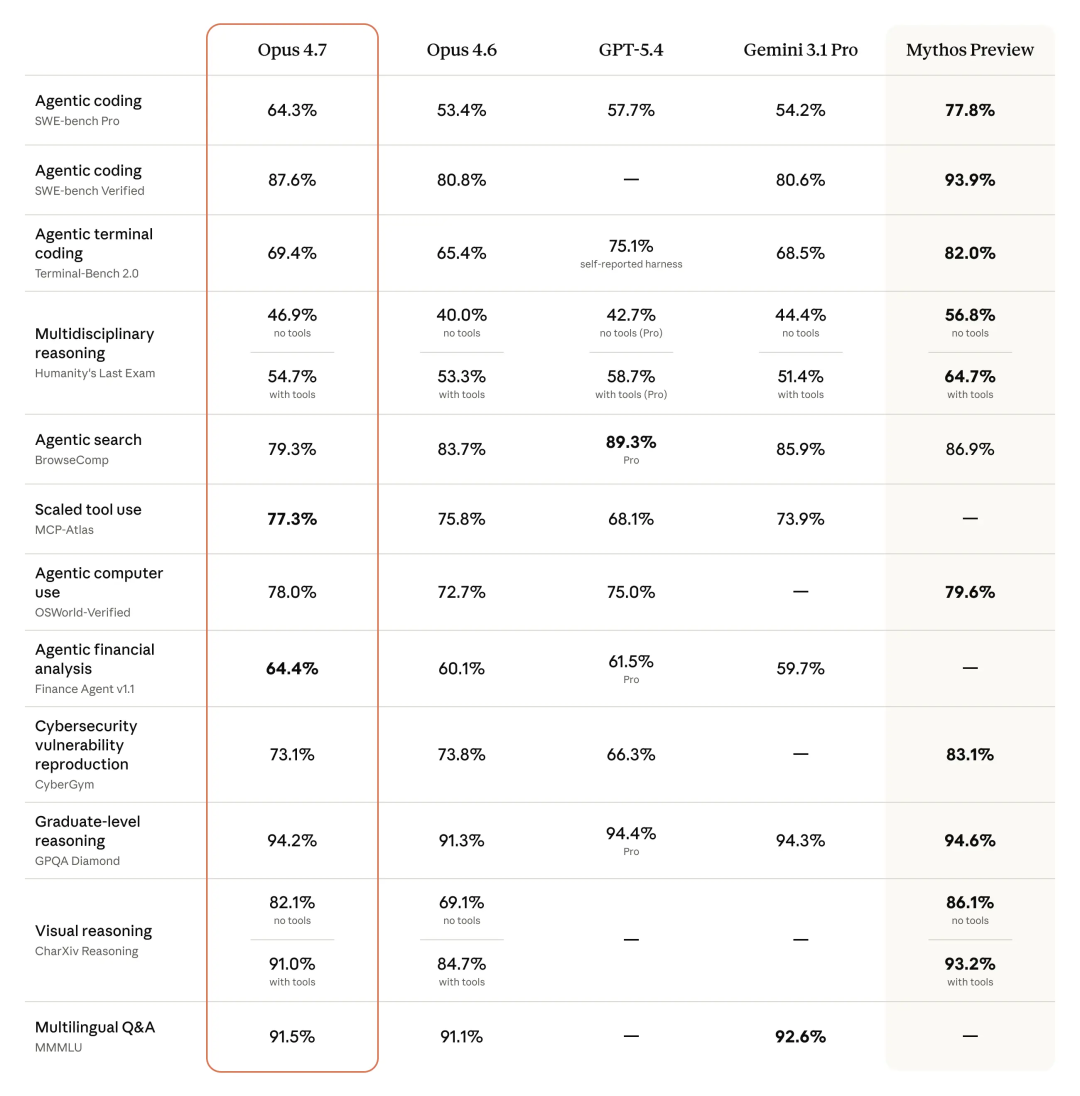 官方给出的本次升级的关键词:复杂任务 、更强视觉 、更稳的长链路执行 ,以及更少需要人工参与。
官方给出的本次升级的关键词:复杂任务 、更强视觉 、更稳的长链路执行 ,以及更少需要人工参与。
只要还在用大模型写文档、读截图、做演示、整理材料,Opus 4.7 带来的体验变化,很难绕开。
为了客观评价 Opus 4.7 的行业地位,我们选取了目前最主流的三个技术评测维度,将其与旧版及 GPT-5.4 进行横向对比。
表1:主流大模型核心性能评测数据对标(2026年4月)
| 指标维度 | Opus 4.6 | Opus 4.7 | GPT-5.4 (Turbo) | 测评意义 |
|---|---|---|---|---|
| SWE-bench Pro | 53.4% | 64.3% | 61.2% | 衡量自主修复工程 Bug 的能力 |
| GPQA (Hard) | 79.1% | 85.2% | 84.5% | 衡量研究生级物理/数理推理 |
| Vision Resolution | 1024px | 2576px | 1800px | 衡量高密图表与 UI 稿解析能力 |
| 长文本抗漂移得分 | 82.0 | 94.5 | 89.8 | 衡量 1M 上下文内的逻辑一致性 |
从数据来看,Opus 4.7 在 SWE-bench Pro 这一极具工程含金量的指标上反超了 GPT-5.4。这意味着在处理包含多文件依赖、跨模块调用的复杂代码库修复时,Opus 4.7 具备更强的全局感知力。
三、 1M 上下文管理与抗漂移优化
处理百万级 Token 的上下文时,模型往往会面临"中段迷失"的问题。Opus 4.7 通过优化 KV Cache 的动态加权算法,提升了长程注意力的准确性。
在针对长文档的精准召回测试中,Opus 4.7 实现了 99.9% 的海量信息检索准确率。更重要的是,它解决了长对话中的指令疲劳问题。
即使对话轮次超过 100 轮,模型依然能严格遵循文首定义的技术栈约束。对于开发者而言,这意味着可以将整个代码仓或数千页的技术文档直接喂给模型,而无需担心它在后期产生逻辑漂移。
四、 开发者避坑:Tokenizer 更新对成本的影响
在进行架构迁移时,必须注意本次更新对 Tokenizer(分词器) 的重构。
Opus 4.7 采用了更精细化的分词策略,旨在提升多语言和特殊字符的编码效率。但在实际测试中,我们发现相同的业务语料,在 4.7 版本下的 Token 消耗量比旧版增加了约 20%-28%。这意味着即使 API 单价(5/25)未变,你的实际账单也会上浮。
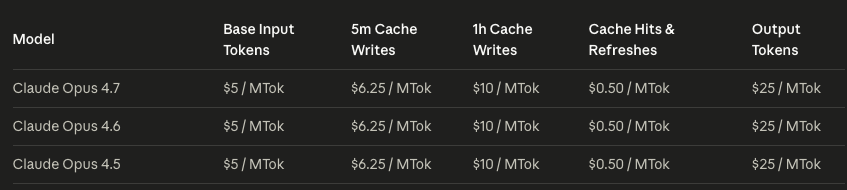
对于高频调用的企业级项目,建议接入 poloapi 这种具备多模型流量调度和精细化账单分析的 API 聚合平台。通过其提供的灰度对比功能,可以清晰观测到不同版本在同一业务场景下的成本波动,从而优化 Prompt 结构以降低冗余 Token 的产出。