
在天然气净化和温室气体控制中,氮气(N₂)与甲烷(CH₄)的分离一直是个"老大难"问题。两者的动力学直径极其接近(0.364 nm vs 0.381 nm),传统分离方法成本高、能耗大。而金属有机框架(MOFs)因其结构可调和超高孔隙率,被视为理想的吸附材料。
但问题来了:如何高效预测不同MOFs在不同条件下的N₂吸附能力? 实验太慢太贵,传统模型又不够准。近日,一项发表于 Scientific Reports 的研究给出了一个令人振奋的答案------用机器学习,尤其是XGBoost,实现超高精度预测。
01 研究背景:为什么N₂吸附预测如此重要?
-
天然气中N₂含量过高会降低热值,必须将其降至4%以下
-
CH₄和N₂的分子尺寸极接近,传统分离技术(如低温精馏)能耗巨大
-
MOFs是潜力巨大的吸附材料,但实验筛选耗时费力
✅ 需求:一种快速、准确、可泛化的N₂吸附预测方法
02 研究目的:建立一个高精度、可解释的N₂吸附预测模型
-
利用3246个实验数据点(65种MOFs)
-
输入:温度、压力、孔体积、比表面积
-
输出:N₂吸附量(mmol/g)
-
比较4种先进ML模型,选出最佳者
-
识别关键影响因素,验证模型可靠性
03 研究方法:四款主流机器学习模型同台竞技
| 模型 | 特点 |
|---|---|
| XGBoost | 梯度提升决策树,擅长处理复杂非线性关系 |
| CatBoost | 对类别特征友好,抗过拟合能力强 |
| DNN | 多层神经网络,适合高维数据 |
| GPR-RQ | 高斯过程回归,适合小样本但本研究中数据量大 |
使用5折交叉验证 + 网格搜索调参
训练集:2596点 / 测试集:650点
04 研究过程:从数据到模型的完整流程
原文 图1 清晰展示了研究流程:
图1(原文Page 4) :A diagrammatic representation of this research
包含:数据收集 → 数据预处理 → 模型训练(XGBoost/CatBoost/DNN/GPR)→ 模型评估(统计+图形)→ SHAP分析 → 杠杆法验证
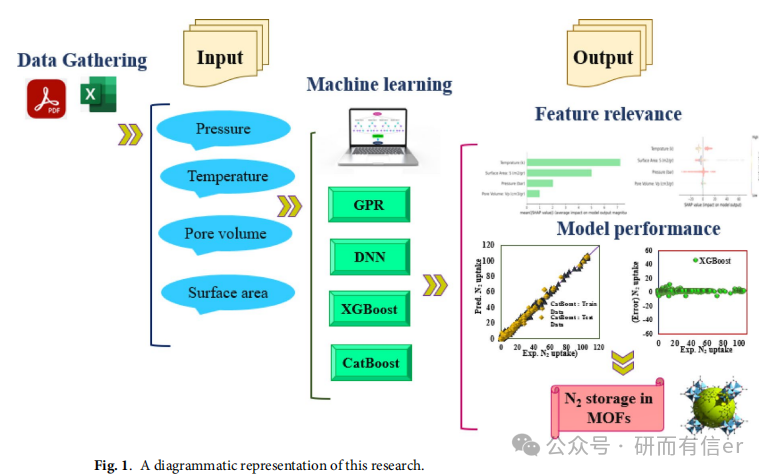
🔍 解读:研究流程非常规范,覆盖了数据清洗、建模、调参、评估、可解释性分析、异常检测等关键环节,是典型的"数据驱动材料预测"范式。
05 研究重难点
难点1:数据的异质性与分布不均
-
压力跨度极大:0.001 → 1054.7 bar
-
吸附量跨度也极大:0.000003 → 106.4 mmol/g
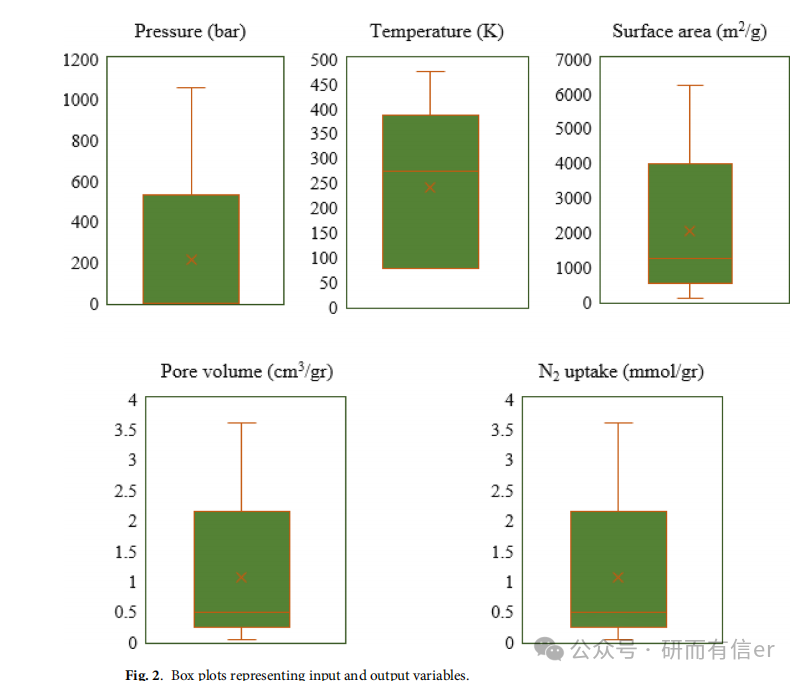
原文 图2(Page 8):Box plots of input/output variables
可见数据存在明显偏态和离群值,对模型鲁棒性提出高要求
难点2:模型的可解释性
-
黑箱模型难以用于材料设计
-
引入 SHAP分析 解释预测逻辑
难点3:避免过拟合
- 采用K-fold交叉验证 + 早停法(DNN)+ 正则化(XGBoost)
06 研究结论:XGBoost全面胜出
性能对比表(原文 Table 5,Page 11)
| 模型 | R² | RMSE | MAE | SD |
|---|---|---|---|---|
| XGBoost | 0.9984 | 0.6085 | 0.1664 | 0.60 |
| GPR-RQ | 0.9979 | 0.6941 | 0.1832 | 0.69 |
| CatBoost | 0.9968 | 0.8607 | 0.3808 | 0.86 |
| DNN | 0.9940 | 1.1868 | 0.3764 | 1.19 |
✅ XGBoost 在所有指标上均优于其他模型
07 关键图表解读
图6(原文Page 12):Cross-plots
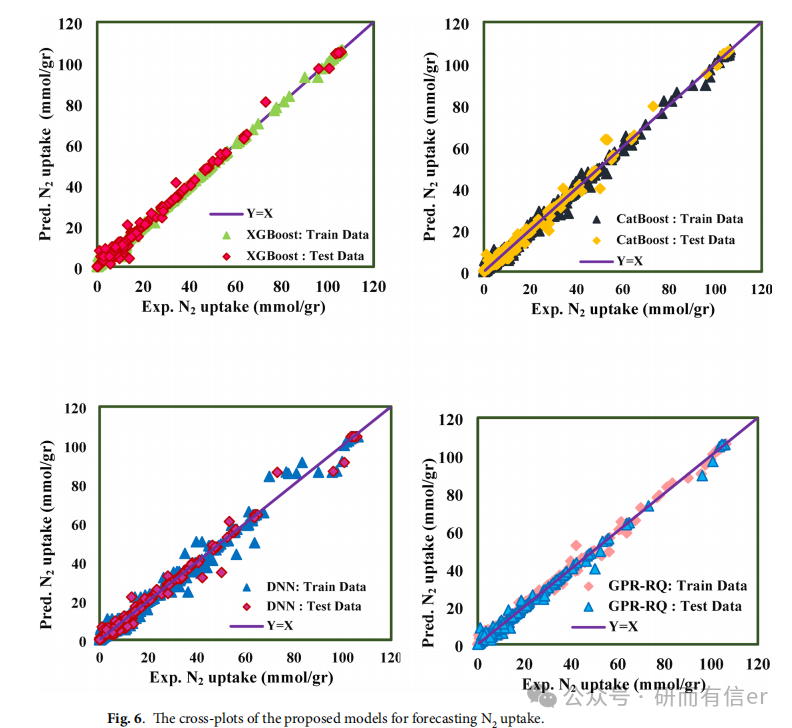
预测值 vs 实验值沿45°线分布越集中,模型越准
XGBoost 的点最贴近对角线,说明预测几乎无偏
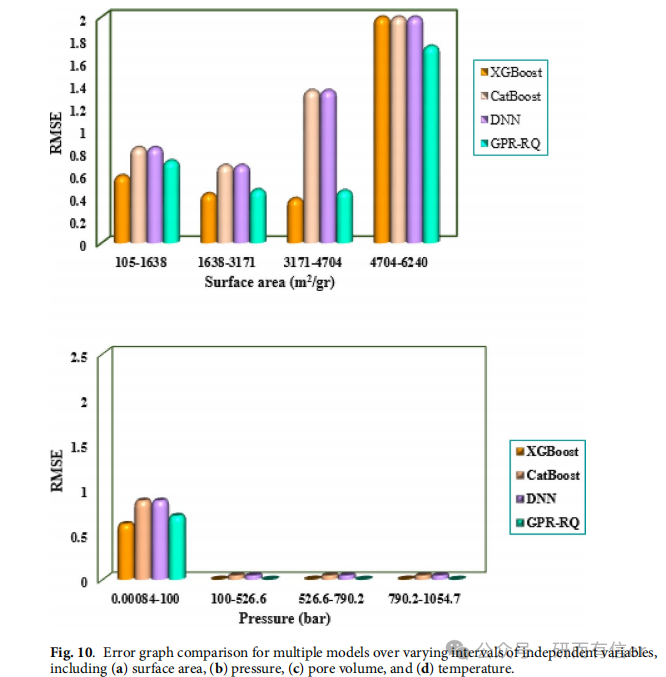
图7(原文Page 13):Error distribution
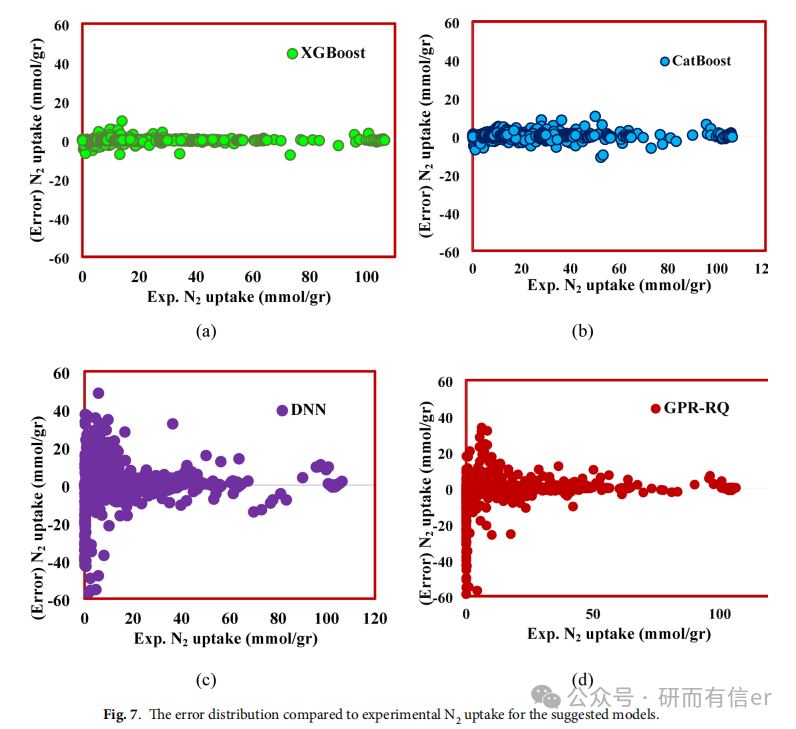
XGBoost 的误差集中在零线附近,范围最小(-7.63 ~ 9.86)
图9(原文Page 14):Taylor diagram
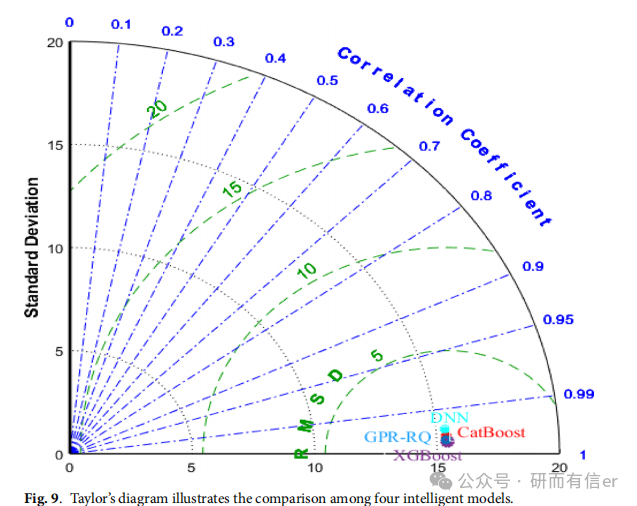
XGBoost 的点最接近"观测点",综合了高相关系数、低RMSE、匹配标准差
图11(原文Page 17):SHAP分析
(a) 特征重要性 :温度 > 压力 > 比表面积 > 孔体积
(b) 特征影响方向:温度越高,SHAP值越负 → 吸附量越低
图12(原文Page 18):Shapley dependency plot
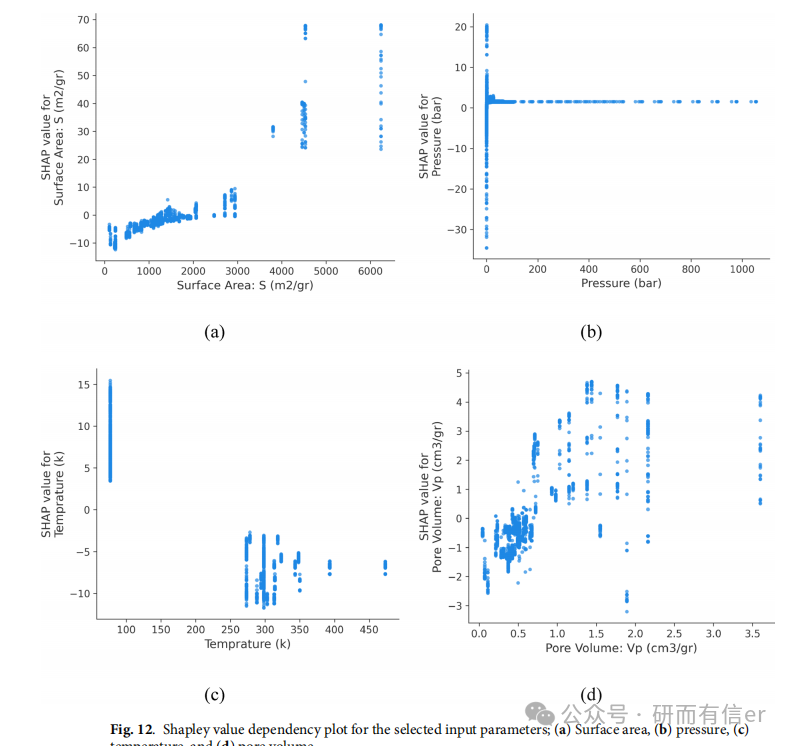
-
比表面积 ↑ → SHAP值 ↑ → 吸附量 ↑
-
温度 ↑ → SHAP值 ↓ → 吸附量 ↓
图13(原文Page 19):Pressure effect
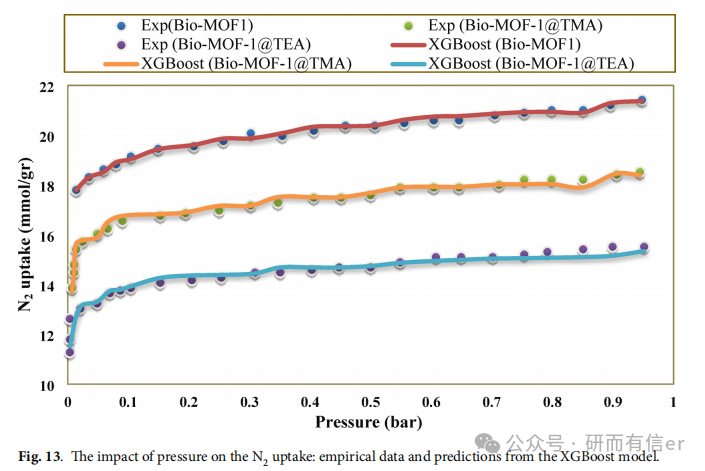
XGBoost 完美复现了"压力↑ → 吸附量↑"的物理趋势
图14(原文Page 19):Leverage analysis
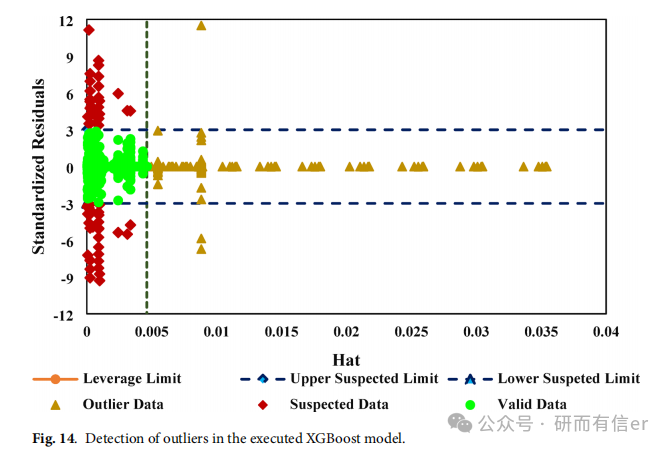
仅2.1%的点落在适用域外,模型鲁棒性极高
08 未来展望
尽管本研究已取得极佳效果,仍有以下方向值得深入:
-
更多结构特征
如金属种类、配体类型、孔径分布、拓扑结构等
-
跨气体迁移学习
将N₂模型迁移到CO₂、CH₄、H₂等气体吸附预测中
-
主动学习 + 实验验证闭环
模型推荐 → 合成测试 → 数据反哺 → 模型迭代
-
可解释性深化
结合图神经网络(GNN)或注意力机制,揭示结构与性能的物理关联
-
工业流程集成
将模型嵌入PSA工艺模拟,实现实时吸附预测与优化
总结一句话
XGBoost + 高质量MOF数据集 = N₂吸附预测的当前最优解,R²高达0.9984,温度是关键。
如果你想获取论文原文、代码复现或数据集,欢迎在评论区留言或私信。
关注我们,获取更多AI+材料科学的干货内容。
注:更多关于机器学习水泥基的前沿知识小编之前有推荐,可以详查置顶文章:建议所有化学材料领域硕博士都去学一遍,以后搞MOF不懂这个等于白干
如果您觉得文章不错,欢迎点赞、关注、收藏及转发~