2. 布隆过滤器
2.1 什么是布隆过滤器
有些场景下,有大量数据需要判断是否存在,而这些数据不是整型,那么位图就不能使用了。
使用红黑树、哈希表等内存空间可能不够。
这些场景就需要布隆过滤器来解决。
布隆过滤器: 是由布隆(Burton Howard Bloom)在1970年提出的,一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你"某样东西一定不存在或者可能存在"。
它是用多个哈希函数,将一个数据映射到位图结构中。
此种此式不仅可以提升查询效率,也可以节省大量的内存空间。
布隆过滤器的思路就是把key先映射转成哈希整型值,再映射一个位,如果只映射一个位的话,冲突率会比较多,所以可以通过多个哈希函数映射多个位,降低冲突率。
- 布隆过滤器这里跟哈希表不一样,它无法解决哈希冲突的,因为他压根就不存储这个值,只标记映射的位。
- 它的思路是尽可能降低哈希冲突。判断一个值key在是不准确的,判断一个值key不在是准确的。
哈希表解决哈希冲突,是哈希表里面,在映射的位置,存储了原始数据,能直接比对。
位图无法解决哈希冲突,判断在可能产生误判,是在映射的位置,只有在不在的0、1信息。
比如说,字符串或者结构对象,不能直接跟某个bit位建立映射关系。
那就需要走两层映射。
先把这个对象,转换成整型,再把整型映射到位图中。
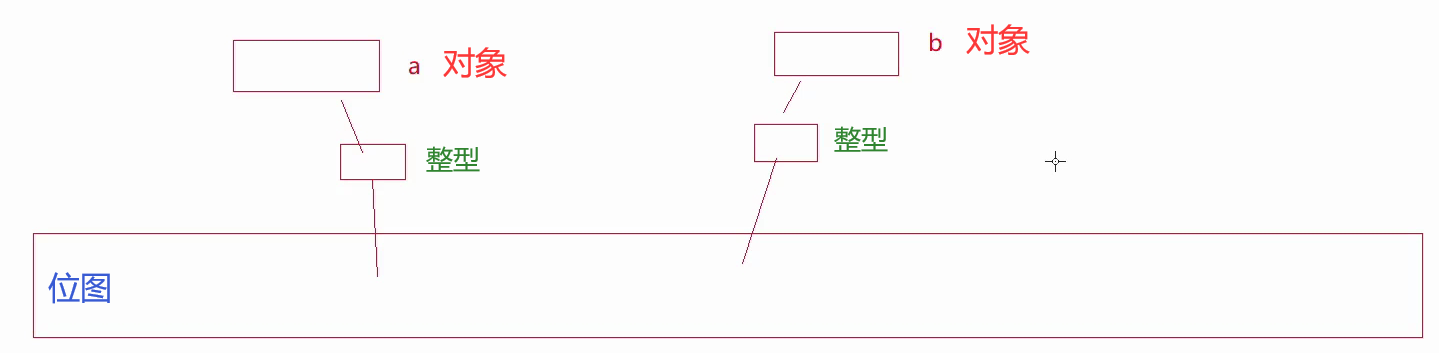
问题就是存在哈希冲突------两个不同的对象映射到同一个整型。
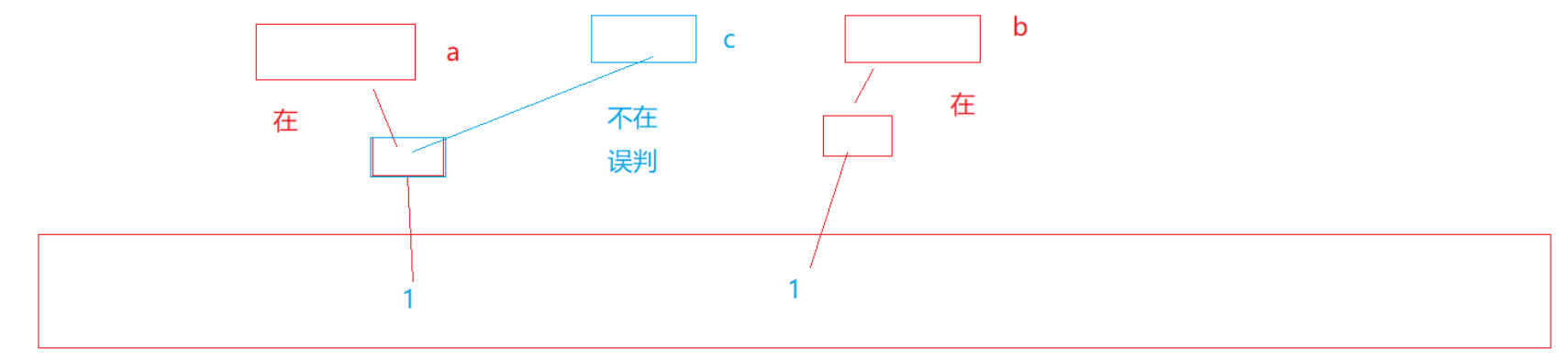
此时如果c并不在集合中,那就不应该在位图中找到它的映射。
但是c转换的整型和a一致,就会导致误判。
这就是位图-双映射的特点:
- 判断c不在,那c一定不在。
- 但是判断c在,其实c不一定真的在;(误判)
判断一个值在是不准确的,可能存在误判。
但是判断一个值不在是准确的。
- 布隆过滤器希望尽可能减少位图-双映射结构由于哈希冲突产生的误判,降低误判率。
- 它的思路是通过多个哈希函数映射多个位,降低冲突率。
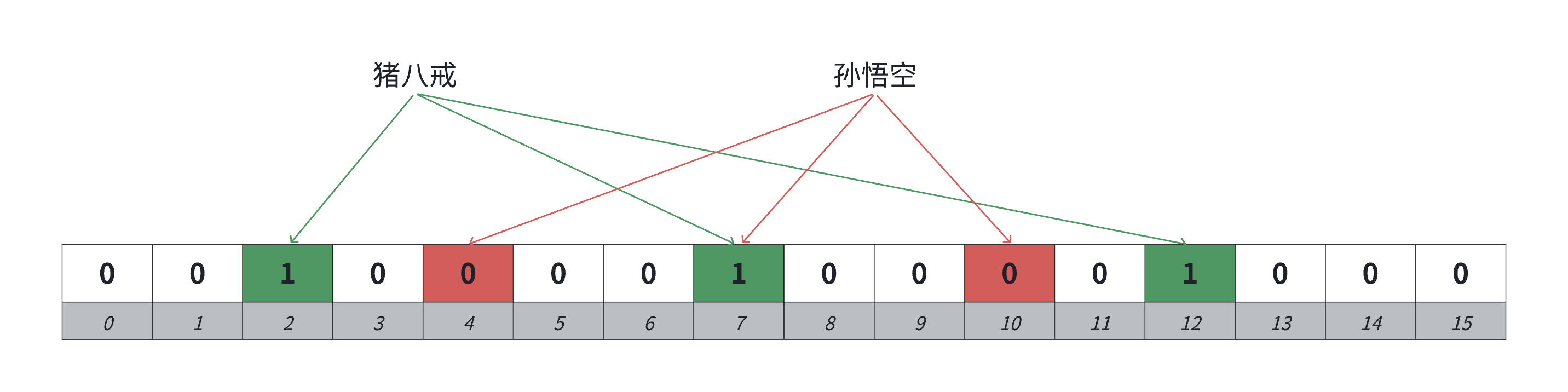
如果只映射一个位,比如"猪八戒"和"孙悟空"都映射到bit7,他们映射的位是共同映射的,直接产生哈希冲突。
如果猪八戒在,孙悟空不在,那就会误判为孙悟空在。
如果每个值通过3个哈希函数,映射3个位,可以看到孙悟空映射的3个位,只有bit7是1,其余2个位都是0,这就能说明孙悟空不在。
【说明】这样只能降低冲突率,不能完全避免冲突。
可能孙悟空不在,但是它映射的3个位恰好分别和猪八戒、沙和尚、金蝉子的某一位重合,而这3个人物都在,那孙悟空不在也在了,产生误判。
下面来看看:
- 哈希函数到底给几个?(每个对象映射几个位)
- 位图给多大合适?
哈希函数太多,每个对象映射的位就多,就需要位图大一点。
否则位图里面大部分都是1,误判率就会更高。
2.2 布隆过滤器器误判率推导
**【说明】**这个比较复杂,涉及概率论、极限、对数运算,求导函数等知识,有兴趣且数学功底比较好的可以看细看一下,其他同学记一下结论即可!
【推导过程】
【假设】
m:容器的大小(单位:bit)。
n:插入到容器中的元素个数。
k:哈希函数的个数。


【结论】
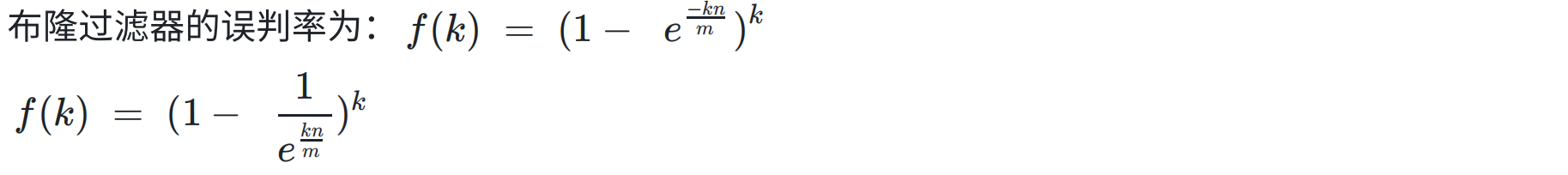
由误判率公式可知:
- 在k一定的情况下,当n增加时,误判率增加,m增加时,误判率减少。
- 在m和n一定,在对误判率公式求导,误判率尽可能小的情况下,可以得到hash函数个数:**k = ln2(m/n)**时误判率最低。
- 期望的误判率p和插入数据个数n确定的情况下,再把上面的公式代入误判率公式可以得到,通过期望的误判率和插入数据个数n得到bit长度: m = −(n*lnp)/ ((ln2)^2)
【说明】
哈希函数个数一定时:
- 插入的元素越多,误判率越高;
- 容器越大,误判率越低;
m/n越大,误判率越低。
容器和容器内的元素个数一定时:
- 哈希函数太多,误判率高;
- 哈希函数太少:误判率高;
哈希函数的最佳个数k = ln2(m/n)时误判率最低。
在容器内元素个数n一定时,如果期望误判率为p,则需要容器的大小
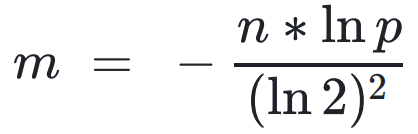
p属于【0,1】,lnp为负数,整个m是整数。
- n越大,m越大。
- p越小,m越大。
【两个公式的推导过程】

以上两个公式的推导过程尤其复杂,这里放两篇博客链接:
布隆过滤器(Bloom Filter)- 原理、实现和推导_ 布隆过滤器原理-CSDN博客
布隆过滤器BloomFilter 举例说明+证明推导_bloom filter 最佳hash函数数量 推导-CSDN博客
2.3 布隆过滤器代码实现
cpp
struct HashFuncBKDR
{
// 本算法由于在Brian Kernighan与Dennis Ritchie的《The C Programming Language》一书被展示而得名
// 是一种简单快捷的hash算法,也是Java目前采用的字符串的Hash算法累乘因子为31。
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash *= 31;
hash += ch;
}
return hash;
}
};
struct HashFuncAP
{
// 由Arash Partow发明的⼀种hash算法。
size_t operator()(const string& s)
{
size_t hash = 0;
for (size_t i = 0; i < s.size(); i++)
{
if ((i & 1) == 0) // 偶数位字符
{
hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));
}
else // 奇数位字符
{
hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >>
5)));
}
}
return hash;
}
};
struct HashFuncDJB
{
// 由Daniel J. Bernstein教授发明的⼀种hash算法。
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash = hash * 33 ^ ch;
}
return hash;
}
};
template<size_t N,
size_t X = 6,
class K = string,
class Hash1 = HashFuncBKDR,
class Hash2 = HashFuncAP,
class Hash3 = HashFuncDJB>
class BloomFilter
{
public:
void Set(const K& key)
{
size_t hash1 = Hash1()(key) % M;
size_t hash2 = Hash2()(key) % M;
size_t hash3 = Hash3()(key) % M;
_bs.set(hash1);
_bs.set(hash2);
_bs.set(hash3);
}
bool Test(const K& key)
{
size_t hash1 = Hash1()(key) % M;
if (_bs.test(hash1) == false)
return false;
size_t hash2 = Hash2()(key) % M;
if (_bs.test(hash2) == false)
return false;
size_t hash3 = Hash3()(key) % M;
if (_bs.test(hash3) == false)
return false;
return true; // 存在误判(有可能3个位都是跟别⼈冲突的,所以误判)
}
// 获取公式计算出的误判率
double getFalseProbability()
{
double p = pow((1.0 - pow(2.71, -3.0 / X)), 3.0);
return p;
}
private:
static const size_t M = X * N;
// 我们实现位图是⽤vector,也就是堆上开的空间
bit::bitset<M> _bs;
//std::bitset<M> _bs;
// vs下std的位图是开的静态数组,M太⼤会存在崩的问题
// 解决⽅案就是bitset对象整体new⼀下,空间就开到堆上了
//std::bitset<M>* _bs = new std::bitset<M>;
};
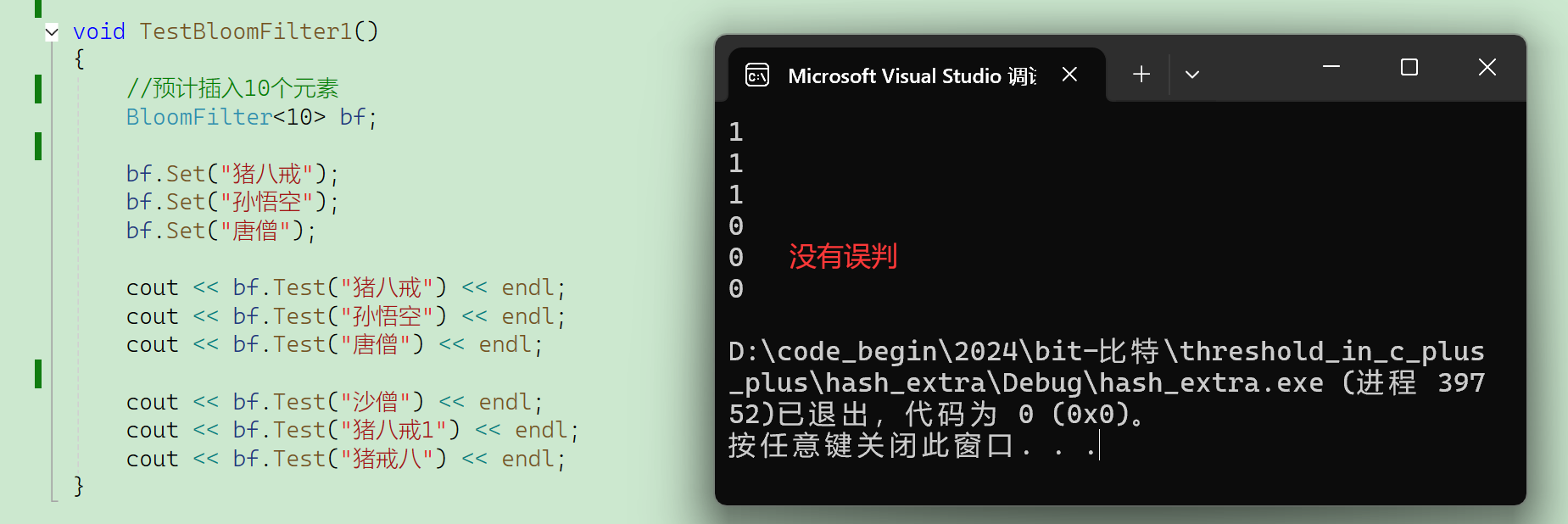
void TestBloomFilter1()
{
string strs[] = { "百度","字节","腾讯" };
BloomFilter<10> bf;
for (auto& s : strs)
{
bf.Set(s);
}
for (auto& s : strs)
{
cout << bf.Test(s) << endl;
}
for (auto& s : strs)
{
cout << bf.Test(s + 'a') << endl;
}
cout << bf.Test("摆渡") << endl;
cout << bf.Test("百渡") << endl;
}
void TestBloomFilter2()
{
srand(time(0));
const size_t N = 10000000;
BloomFilter<N> bf;
//BloomFilter<N, 3> bf;
//BloomFilter<N, 10> bf;
std::vector<std::string> v1;
std::string url = "https://www.cnblogs.com/-clq / archive / 2012 / 05 / 31 / 2528153.html";
/*std::string url = "https://www.baidu.com/s?ie=utf-
8 & f = 8 & rsv_bp = 1 & rsv_idx = 1 & tn = 65081411_1_oem_dg & wd = ln2 & fenlei = 256 & rsv_pq = 0x8d9962
630072789f & rsv_t = ceda1rulSdBxDLjBdX4484KaopD % 2BzBFgV1uZn4271RV0PonRFJm0i5xAJ % 2F
Do & rqlang = en & rsv_enter = 1 & rsv_dl = ib & rsv_sug3 = 3 & rsv_sug1 = 2 & rsv_sug7 = 100 & rsv_sug2 =
0 & rsv_btype = i & inputT = 330 & rsv_sug4 = 2535";*/
//std::string url = "猪⼋戒";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}
for (auto& str : v1)
{
bf.Set(str);
}
// v2跟v1是相似字符串集(前缀⼀样),但是后缀不⼀样
v1.clear();
for (size_t i = 0; i < N; ++i)
{
std::string urlstr = url;
urlstr += std::to_string(9999999 + i);
v1.push_back(urlstr);
}
size_t n2 = 0;
for (auto& str : v1)
{
if (bf.Test(str)) // 误判
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集 前缀后缀都不⼀样
v1.clear();
for (size_t i = 0; i < N; ++i)
{
//string url = "zhihu.com";
string url = "孙悟空";
url += std::to_string(i + rand());
v1.push_back(url);
}
size_t n3 = 0;
for (auto& str : v1)
{
if (bf.Test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
cout << "公式计算出的误判率:" << bf.getFalseProbability() << endl;
}
int main()
{
TestBloomFilter2();
return 0;
}【课堂演示】
【基本框架】
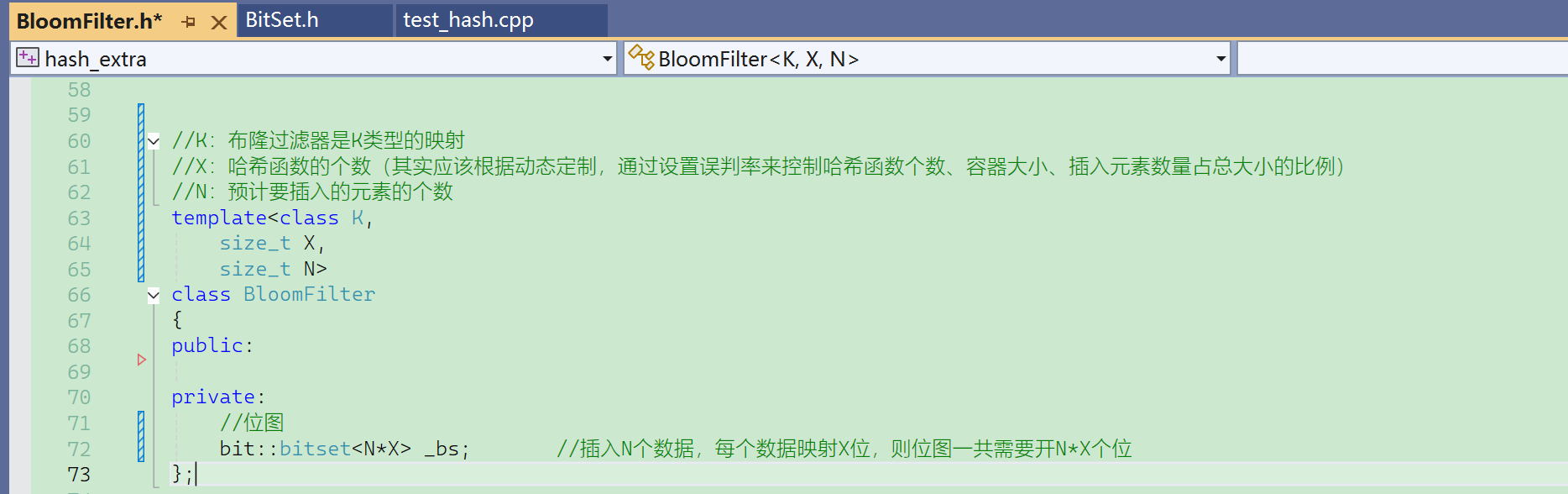
这个X不是哈希函数的个数,是m/n,所以N*X是m。
【2个基本接口------set、test】
注意定义M的时候,必须加上static,否则会报错。
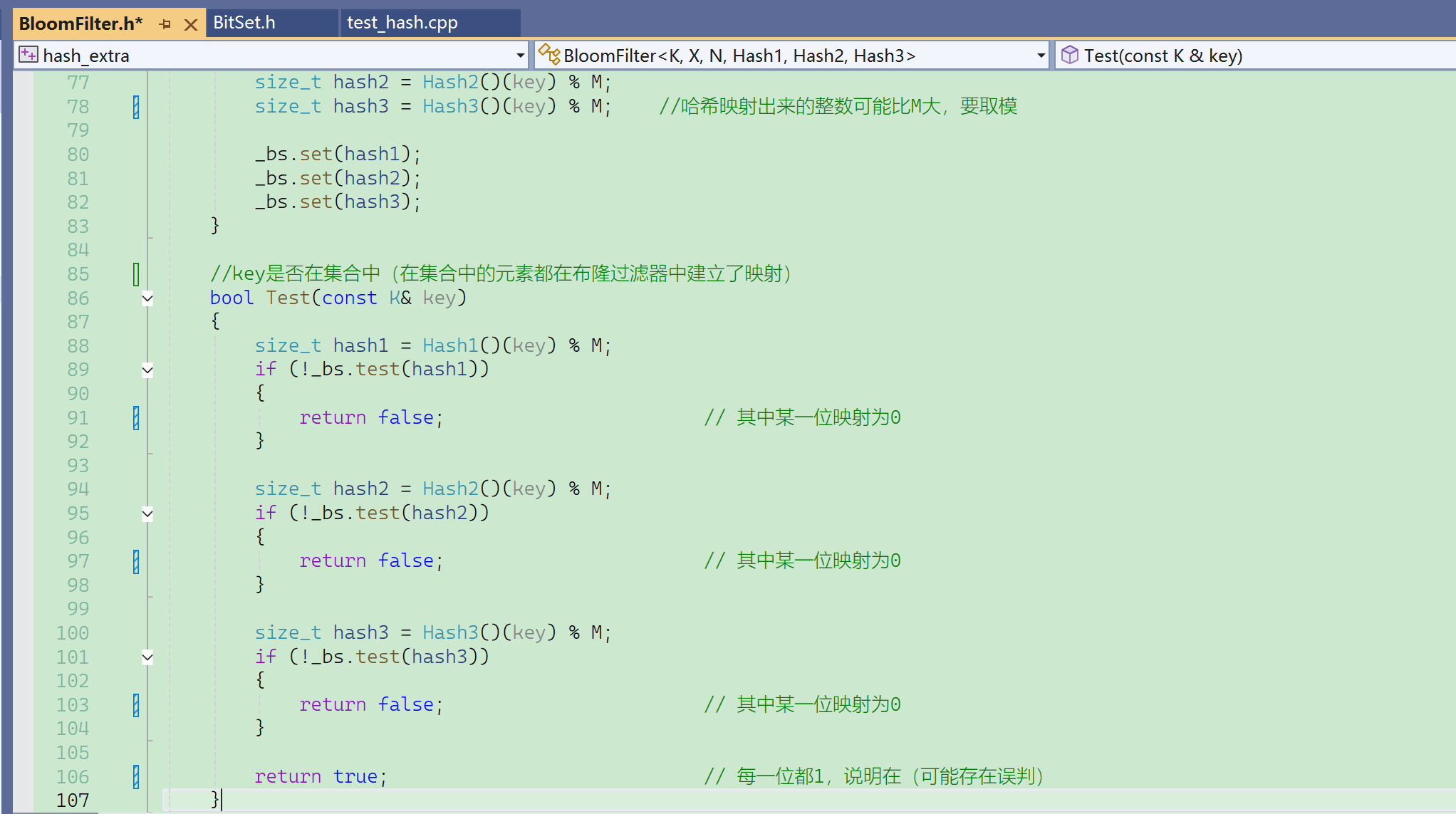
【模版参数缺省值】
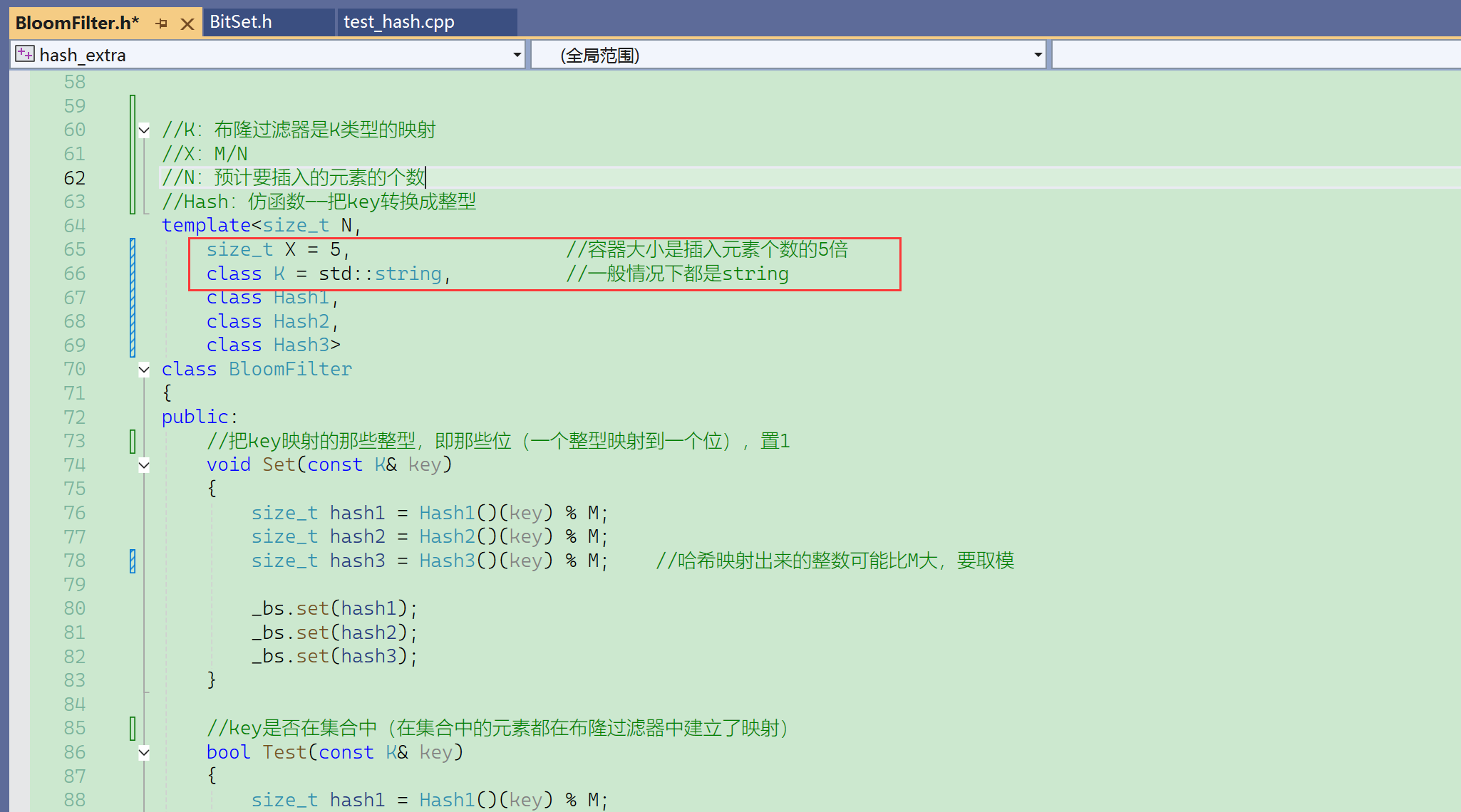
仿函数的缺省值:
cpp
struct HashFuncBKDR
{
// @detail 本 算法由于在Brian Kernighan与Dennis Ritchie的《The CProgramming Language》
// 一书被展示而得 名,是一种简单快捷的hash算法,也是Java目前采用的字符串的Hash算法累乘因子为31。
size_t operator()(const std::string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash *= 31;
hash += ch;
}
return hash;
}
};
struct HashFuncAP
{
// 由Arash Partow发明的一种hash算法。
size_t operator()(const std::string& s)
{
size_t hash = 0;
for (size_t i = 0; i < s.size(); i++)
{
if ((i & 1) == 0) // 偶数位字符
{
hash ^= ((hash << 7) ^ (s[i]) ^ (hash >> 3));
}
else // 奇数位字符
{
hash ^= (~((hash << 11) ^ (s[i]) ^ (hash >> 5)));
}
}
return hash;
}
};
struct HashFuncDJB
{
// 由Daniel J. Bernstein教授发明的一种hash算法。
size_t operator()(const std::string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash = hash * 33 ^ ch;
}
return hash;
}
};
3个哈希函数,3 ≈ 5 * ln2 ≈ 5 * 0.7 = 3.5,3/ln2 = 4.3,向上取整到5,m大一点误判率小。
【测试1】
打印观察:
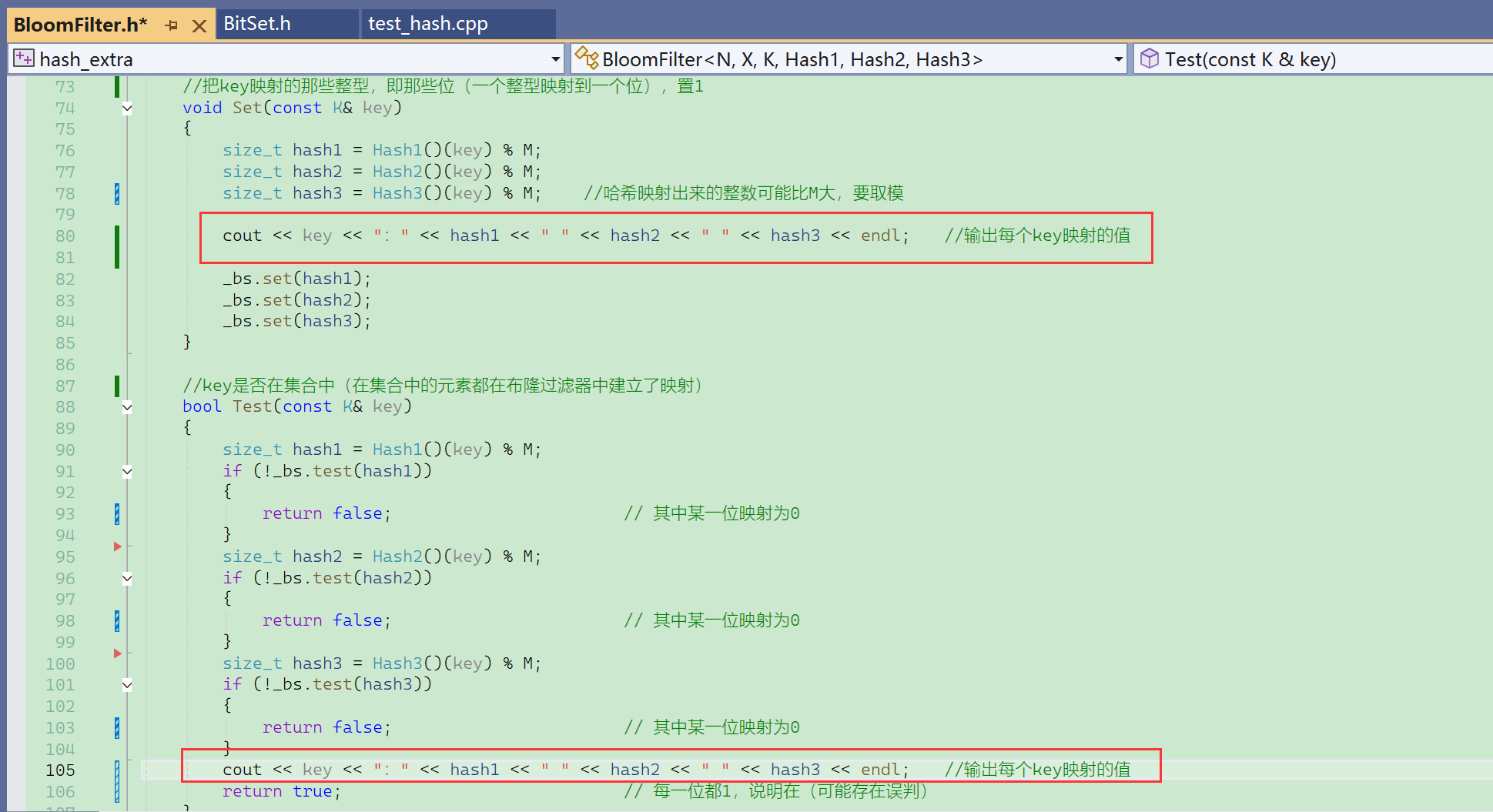
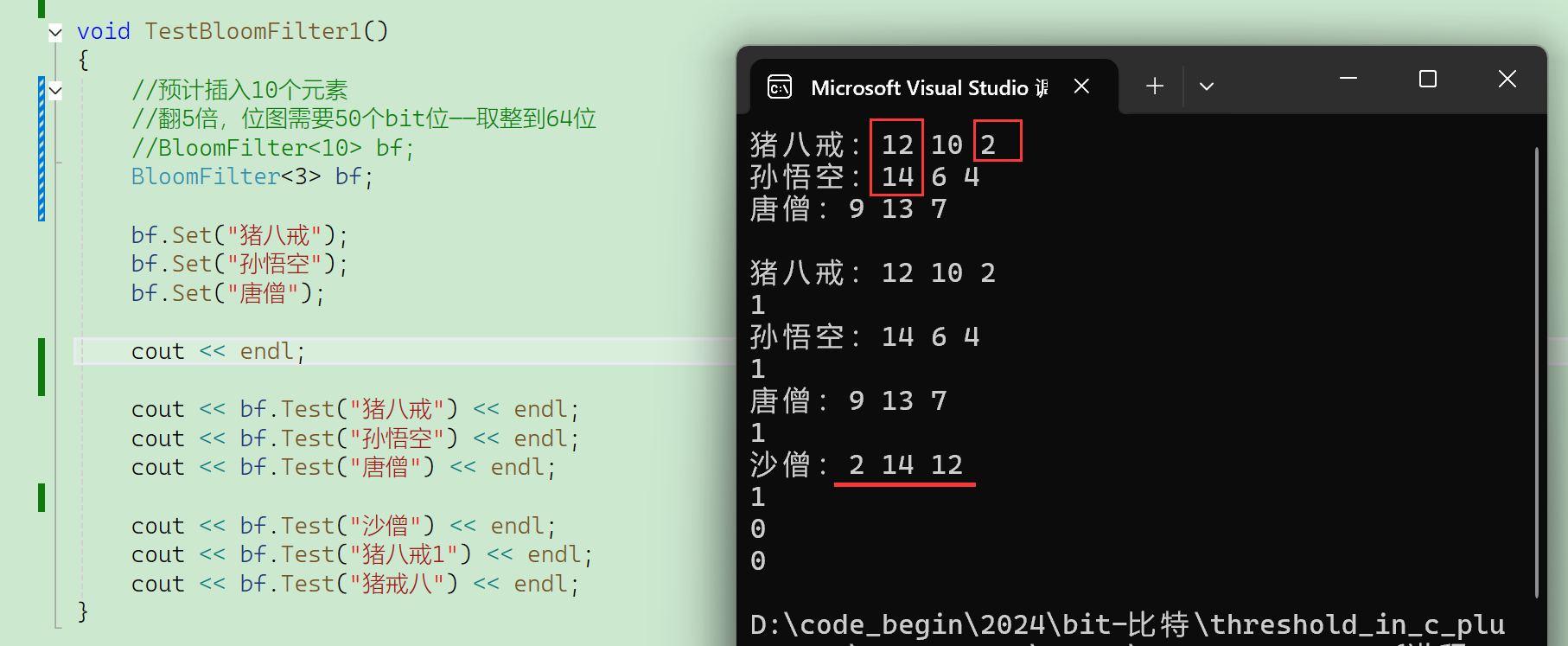
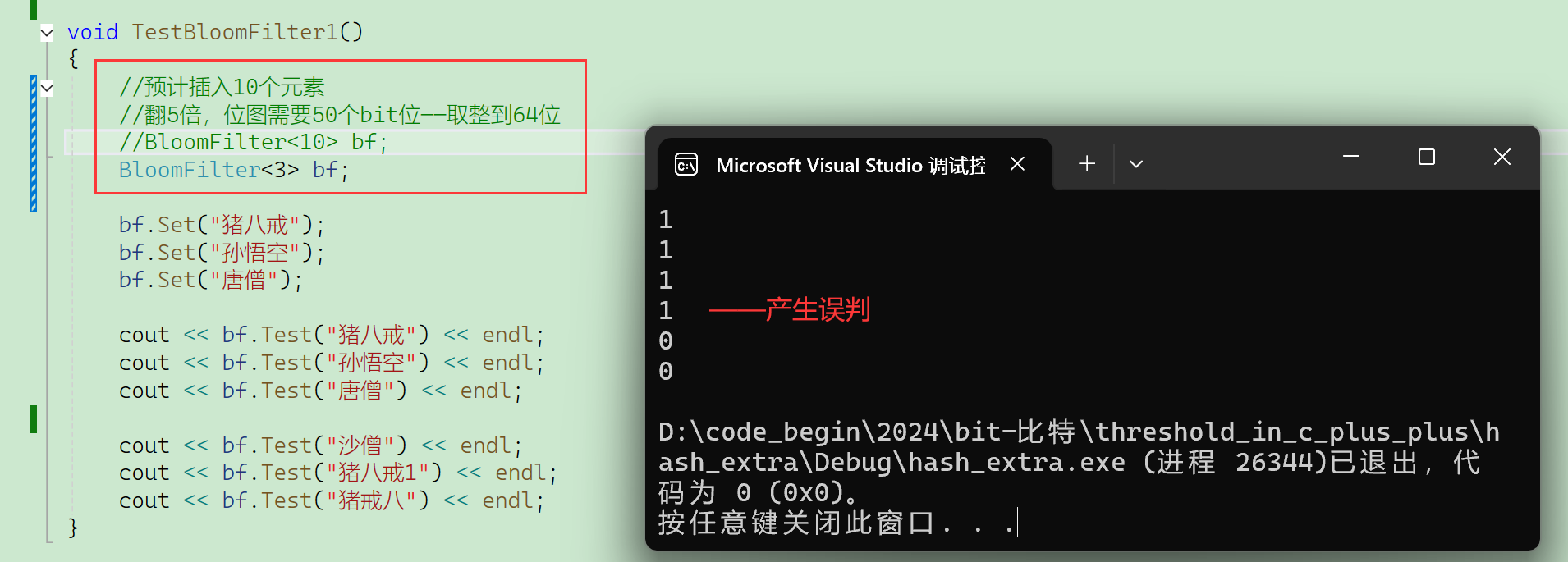
可以看到插入的3个元素,a的3个hash值和b的3个hash值之间,冲突率还是比较低的。
调整一下test函数,在返回之前把hash1、hash2、hash3打印了:

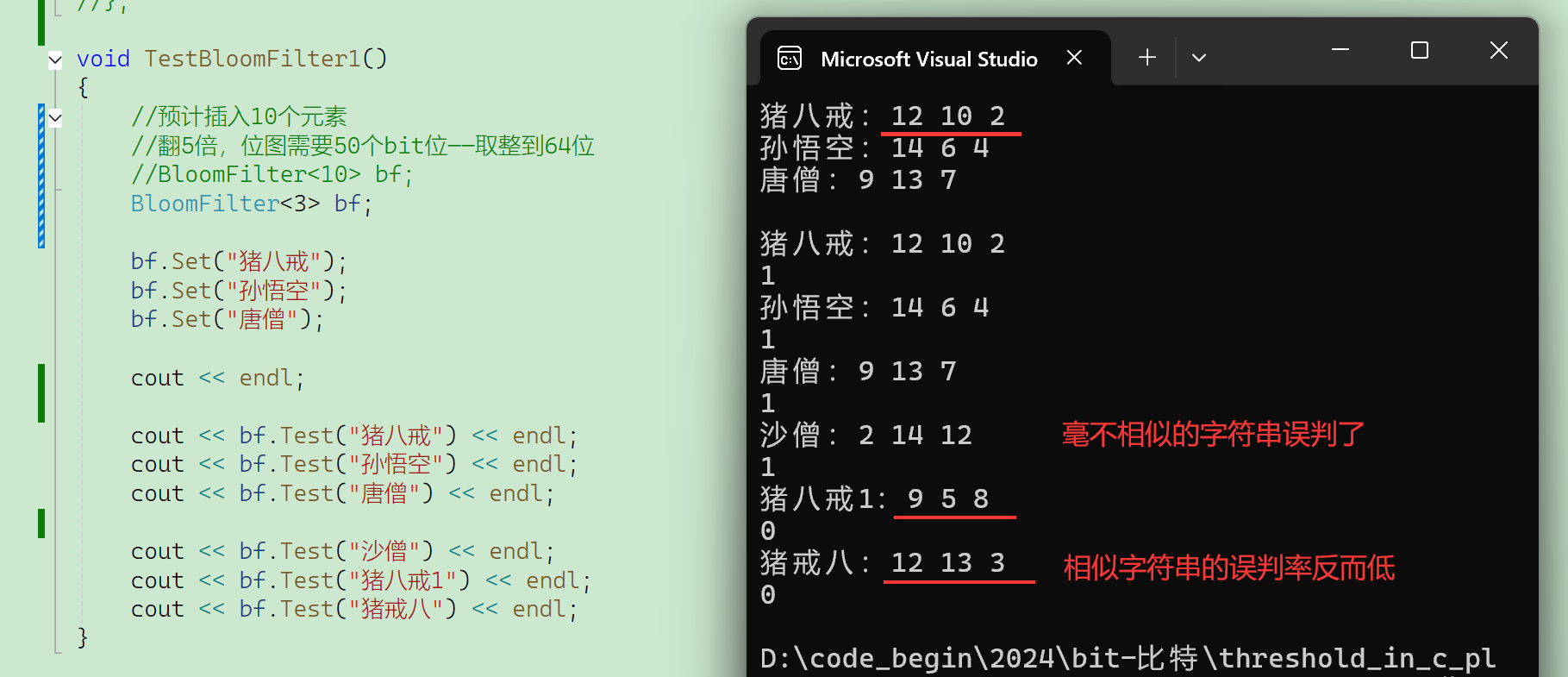
再看看容量大一倍(32------>64,这里bit::bitset最小位图就是32位)
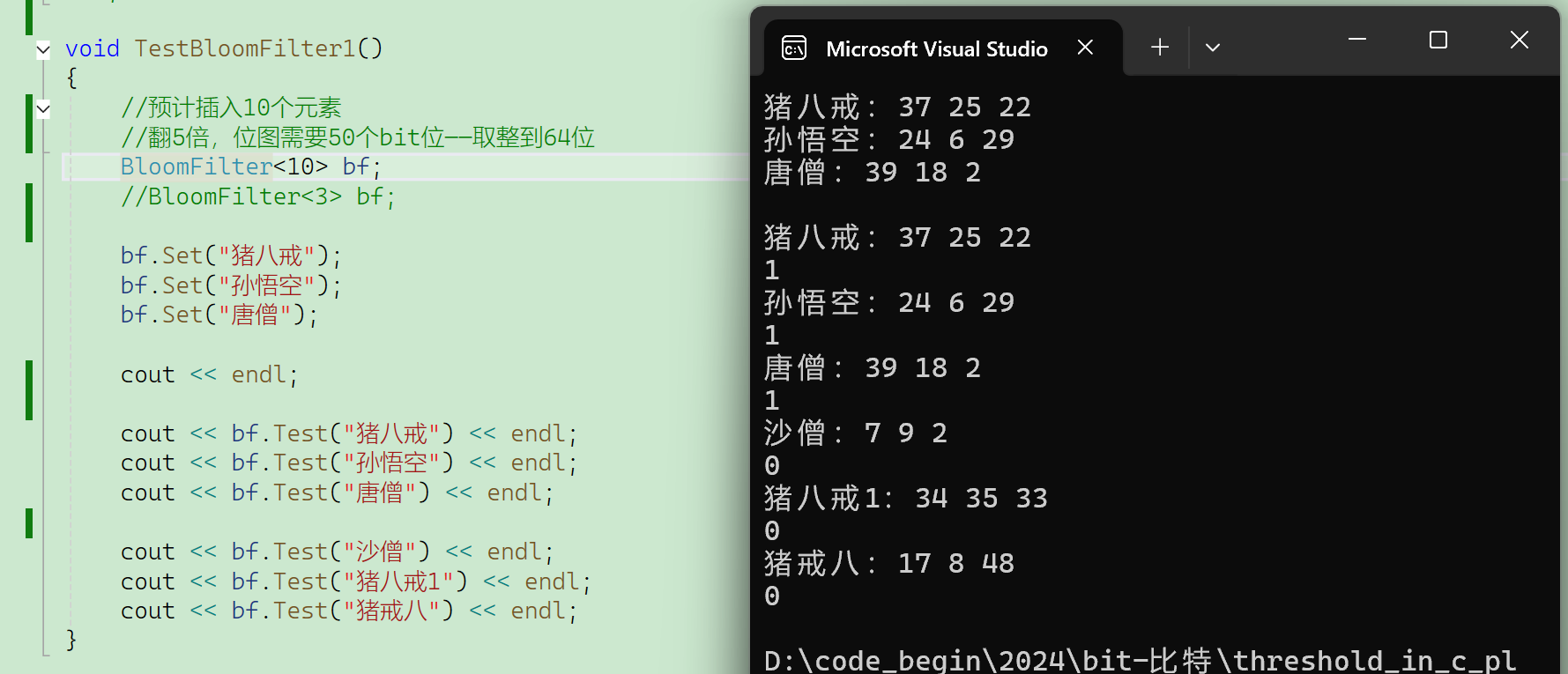
然后进行下一步测试,set和test函数里面的两行输出代码先注释掉。
【测试2】
cpp
void TestBloomFilter2()
{
srand(time(0));
//预计插入100万个数据
//翻5倍,位图需要500万个bit位------610KB左右
//const size_t N = 1000000;
const size_t N = 100000;
BloomFilter<N> bf;
//BloomFilter<N, 3> bf;
//BloomFilter<N, 10> bf;
std::vector<std::string> v1;
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
//std::string url = "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=65081411_1_oem_dg&wd=ln2&fenlei=256&rsv_pq=0x8d9962630072789f&rsv_t=ceda1rulSdBxDLjBdX4484KaopD%2BzBFgV1uZn4271RV0PonRFJm0i5xAJ%2FDo&rqlang=en&rsv_enter=1&rsv_dl=ib&rsv_sug3=3&rsv_sug1=2&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=330&rsv_sug4=2535";
//std::string url = "猪八戒";
for (size_t i = 0; i < N; ++i)
{
//在url的基础上追加数字
v1.push_back(url + std::to_string(i));
}
//建立布隆映射
for (auto& str : v1)
{
bf.Set(str);
}
// 1、先给一组相似字符串集------前缀一样,但是后缀不一样
// 清除v1的数据(不用了),给v1一组相似数据(肯定没被映射过的)
v1.clear();
for (size_t i = 0; i < N; ++i)
{
std::string urlstr = url;
urlstr += std::to_string(9999999 + i);
v1.push_back(urlstr);
}
size_t n2 = 0;
for (auto& str : v1)
{
if (bf.Test(str)) // 现在的v1全没映射过,test通过则必然是误判
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 2、先给一组不相似字符串集------前缀后缀都不一样
// 清除v1的数据(不用了),给v1一组不相似数据(肯定没被映射过的)
v1.clear();
for (size_t i = 0; i < N; ++i)
{
//string url = "zhihu.com";
string url = "孙悟空";
url += std::to_string(i + rand());
v1.push_back(url);
}
size_t n3 = 0;
for (auto& str : v1)
{
if (bf.Test(str)) // 现在的v1全没映射过,test通过则必然是误判
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
//cout << "公式计算出的误判率:" << bf.getFalseProbability() << endl;
}最后用公式计算误判率函数还没写,先注释掉。
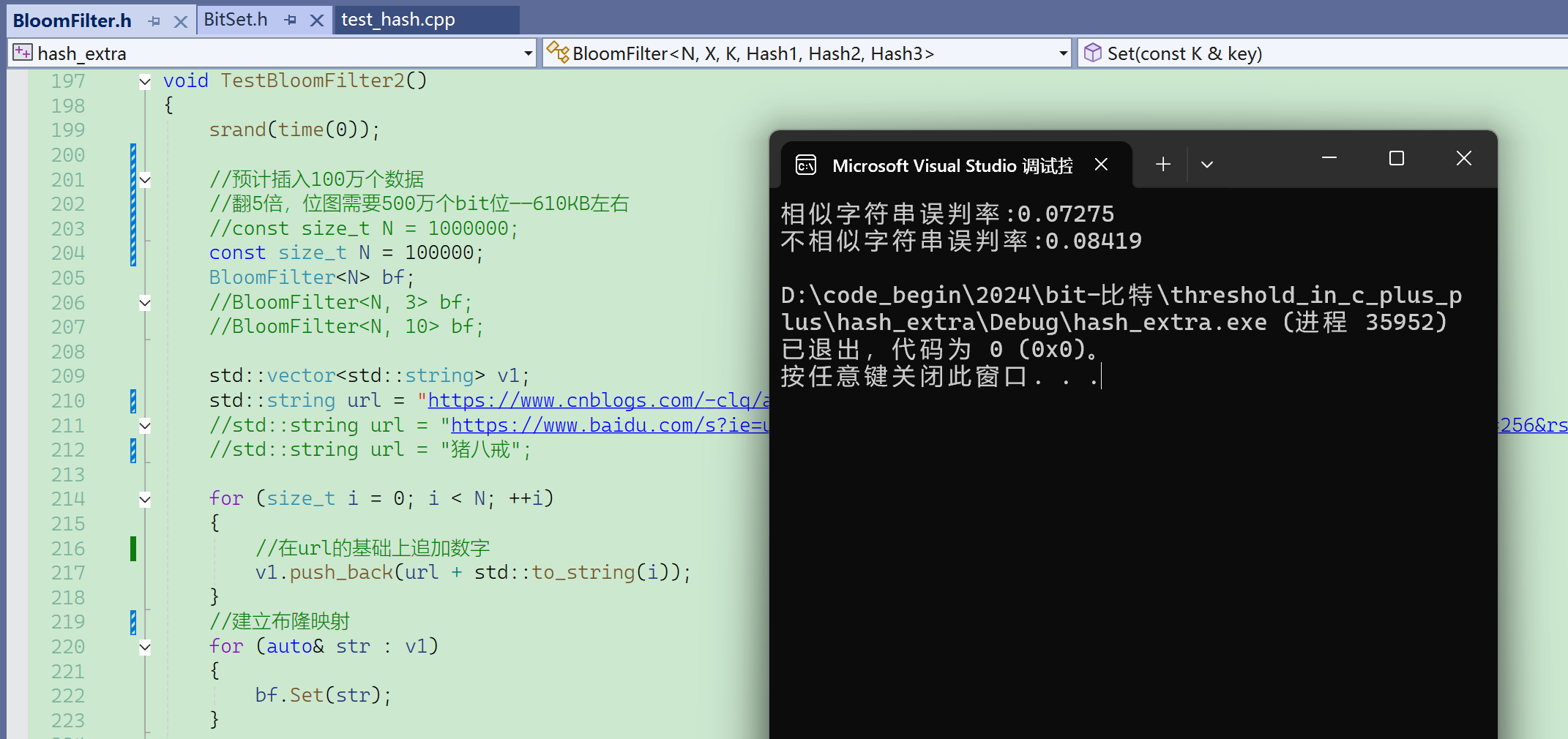
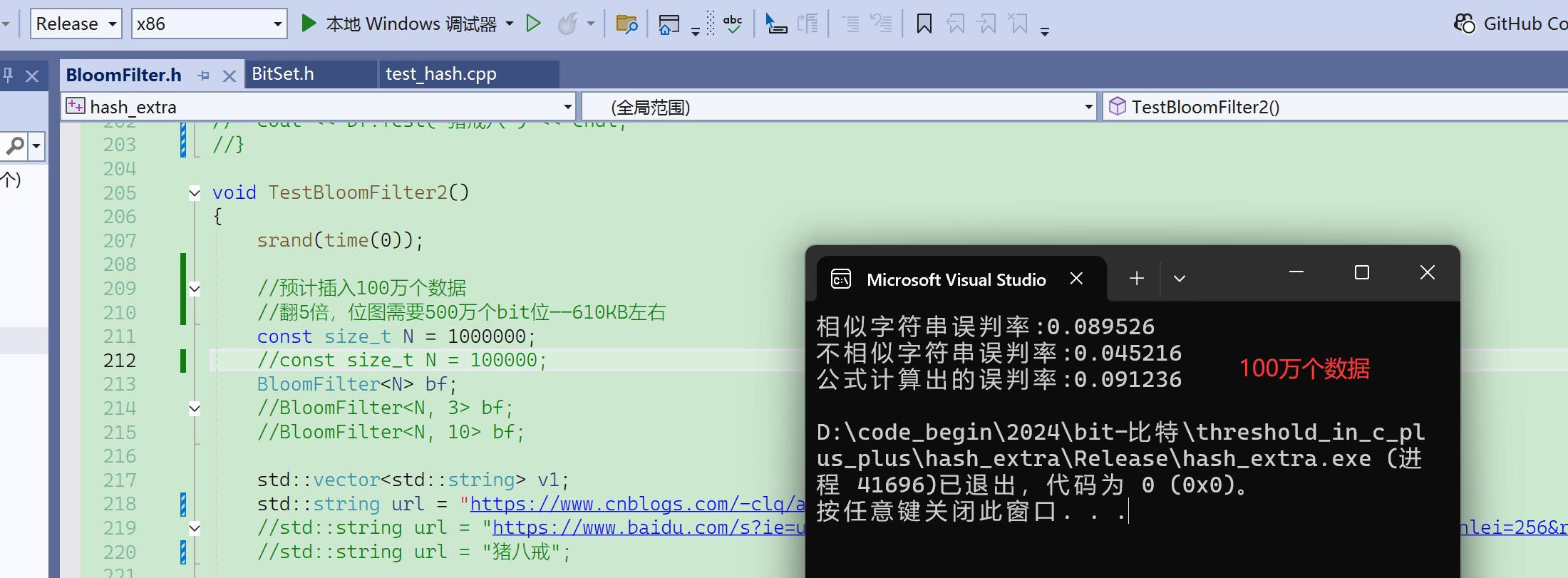
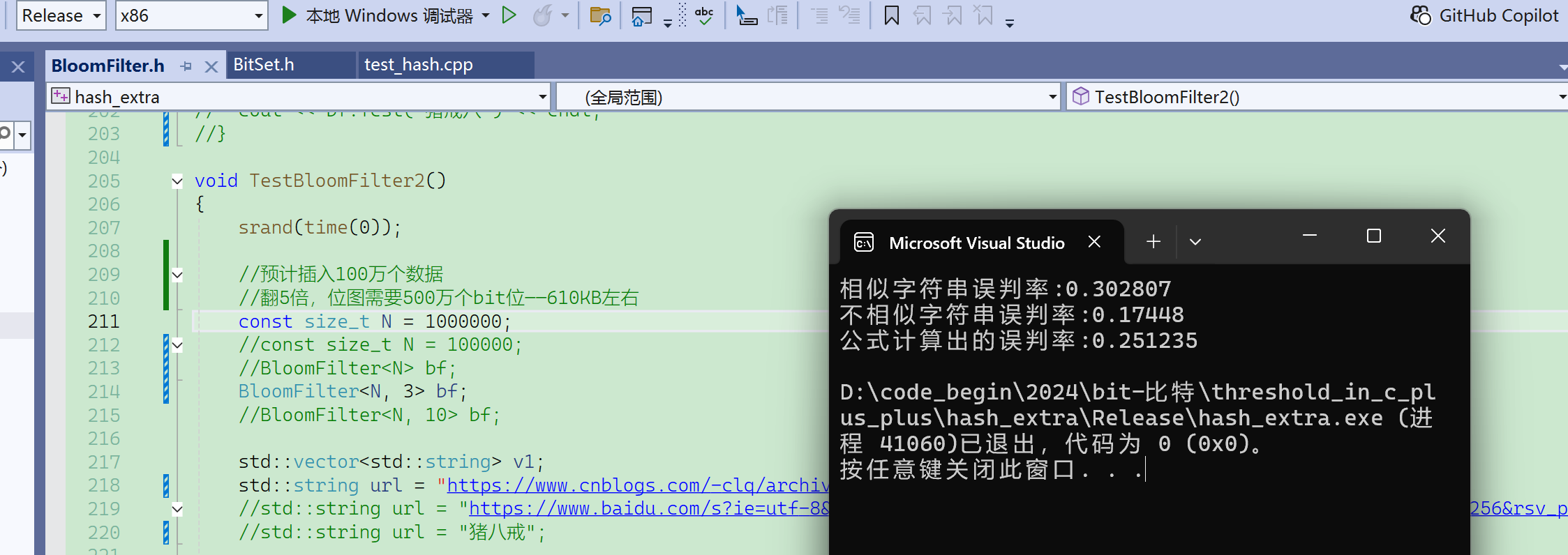
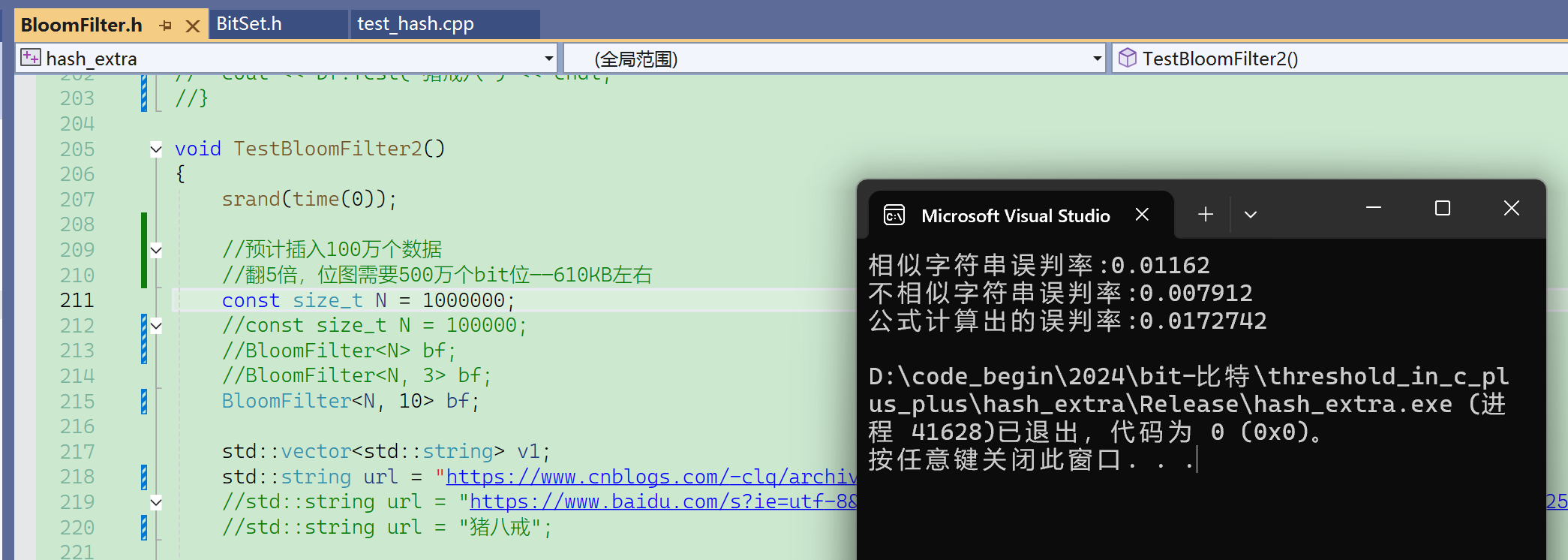
扩大数据量,100万个数据:
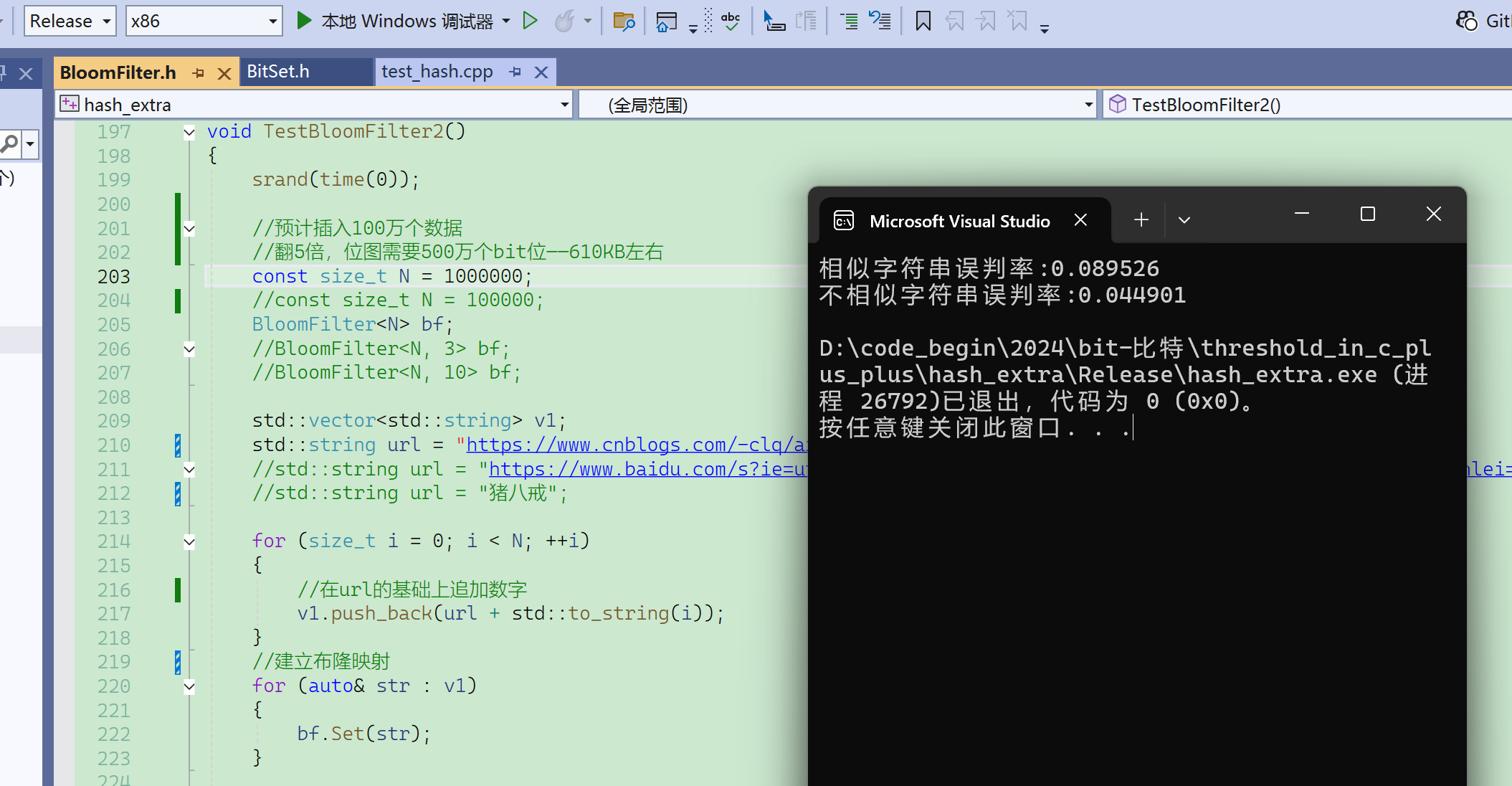
Debug下太慢,换成release了。
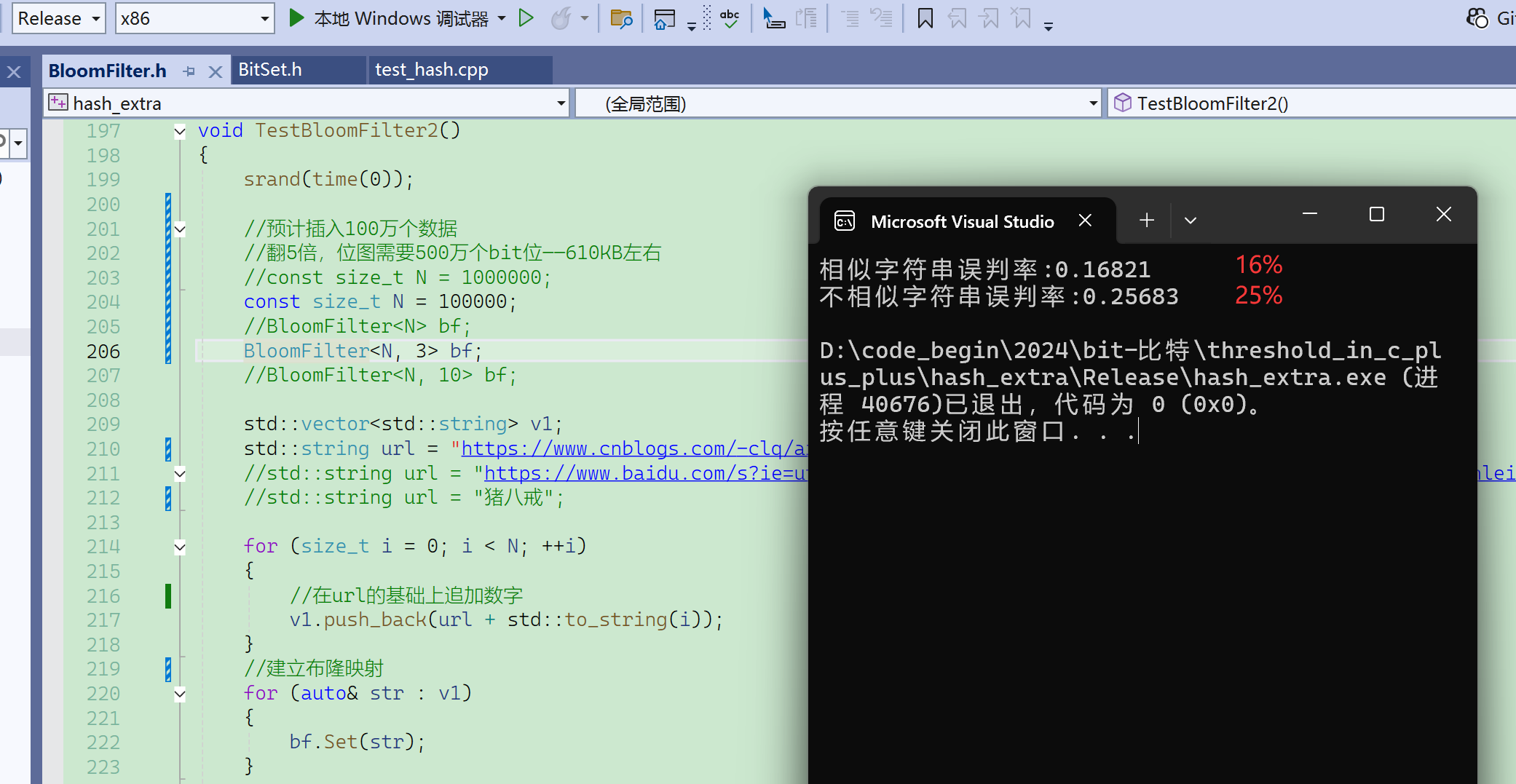
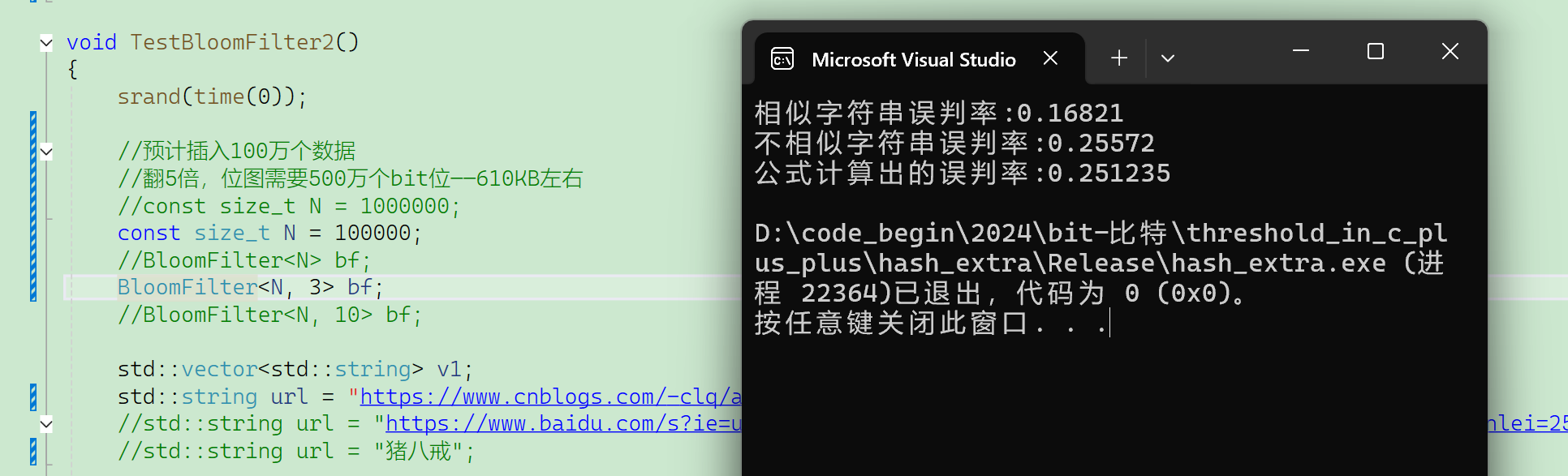
现在m/n使用默认值5,如果给值3,那误判率会升高很多:
如果给值10,那误判率会下降很多:
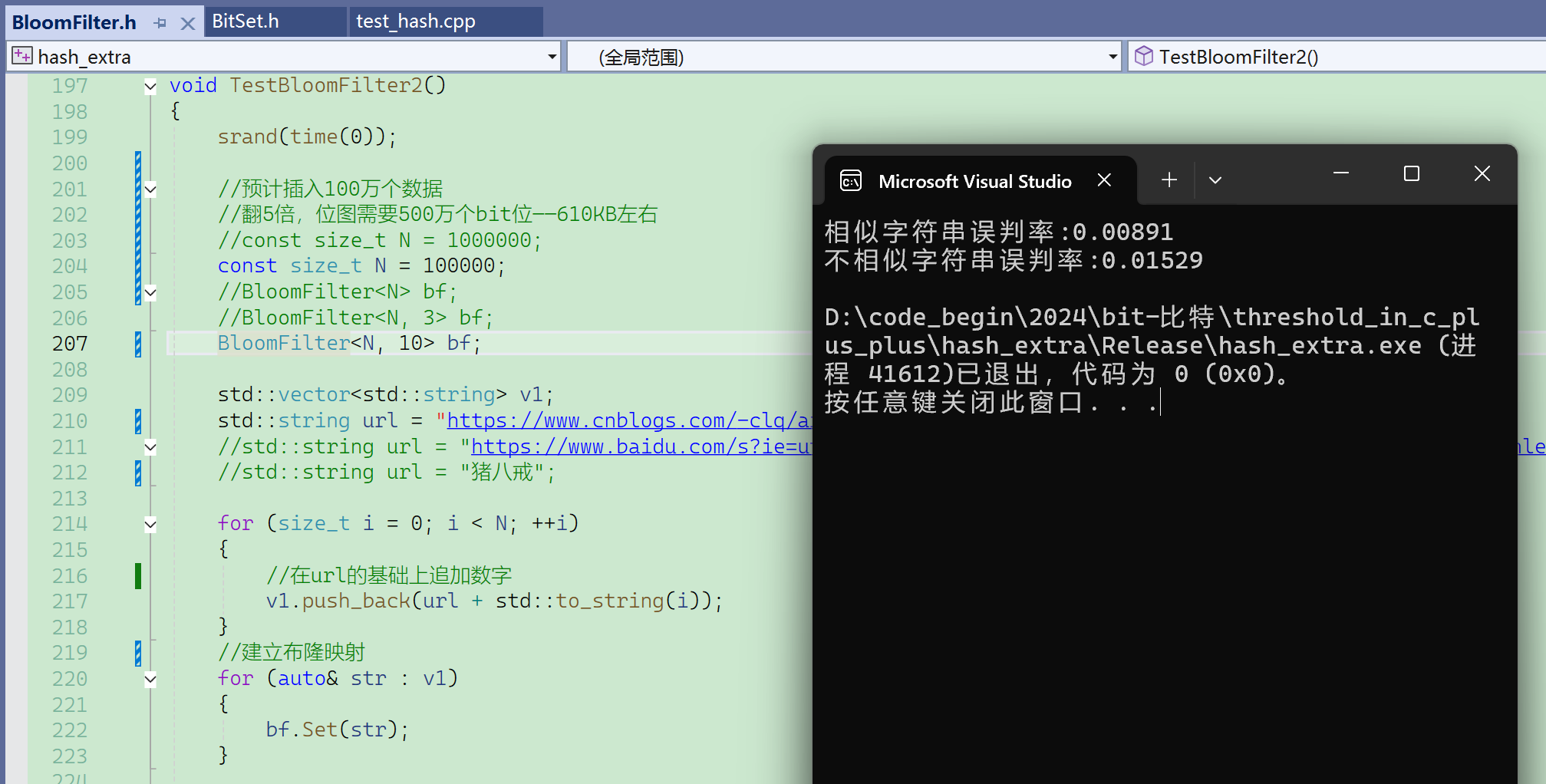
可以通过控制参数X来控制误判率。 (开的位数和插入数据个数之间的比率)
还可以借助公式来计算误判率。
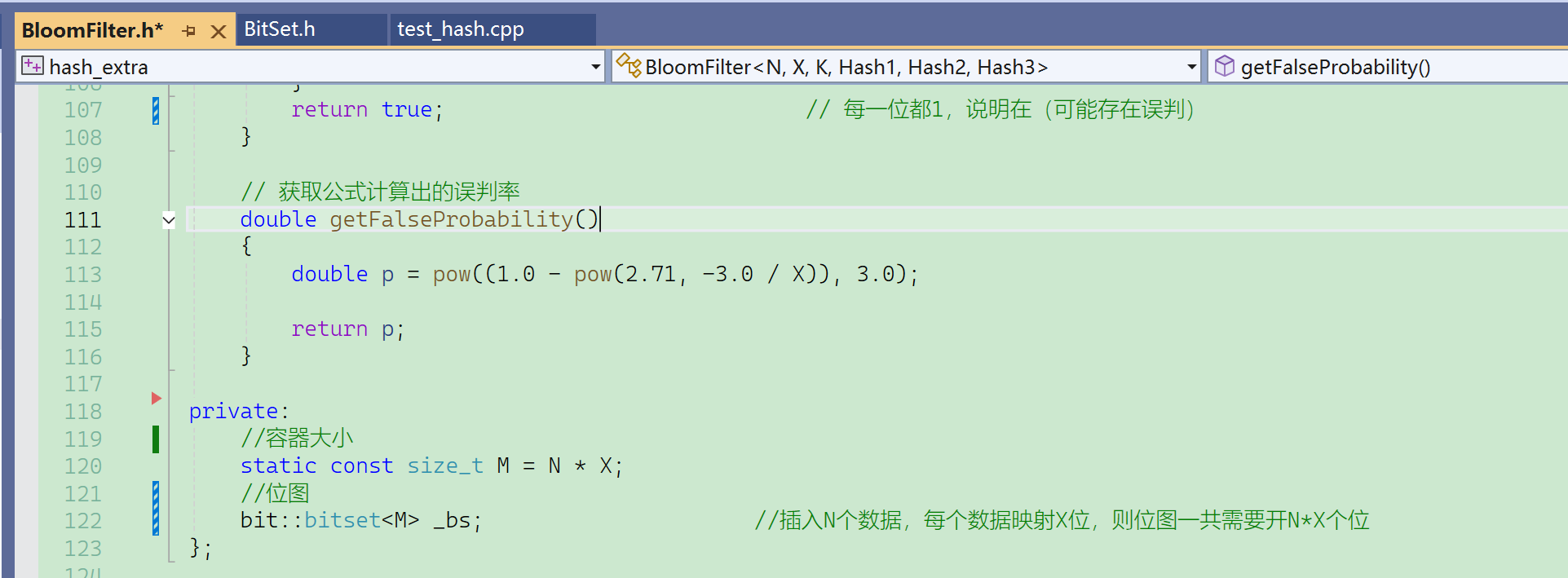
先来看看默认情况,X==5的时候:
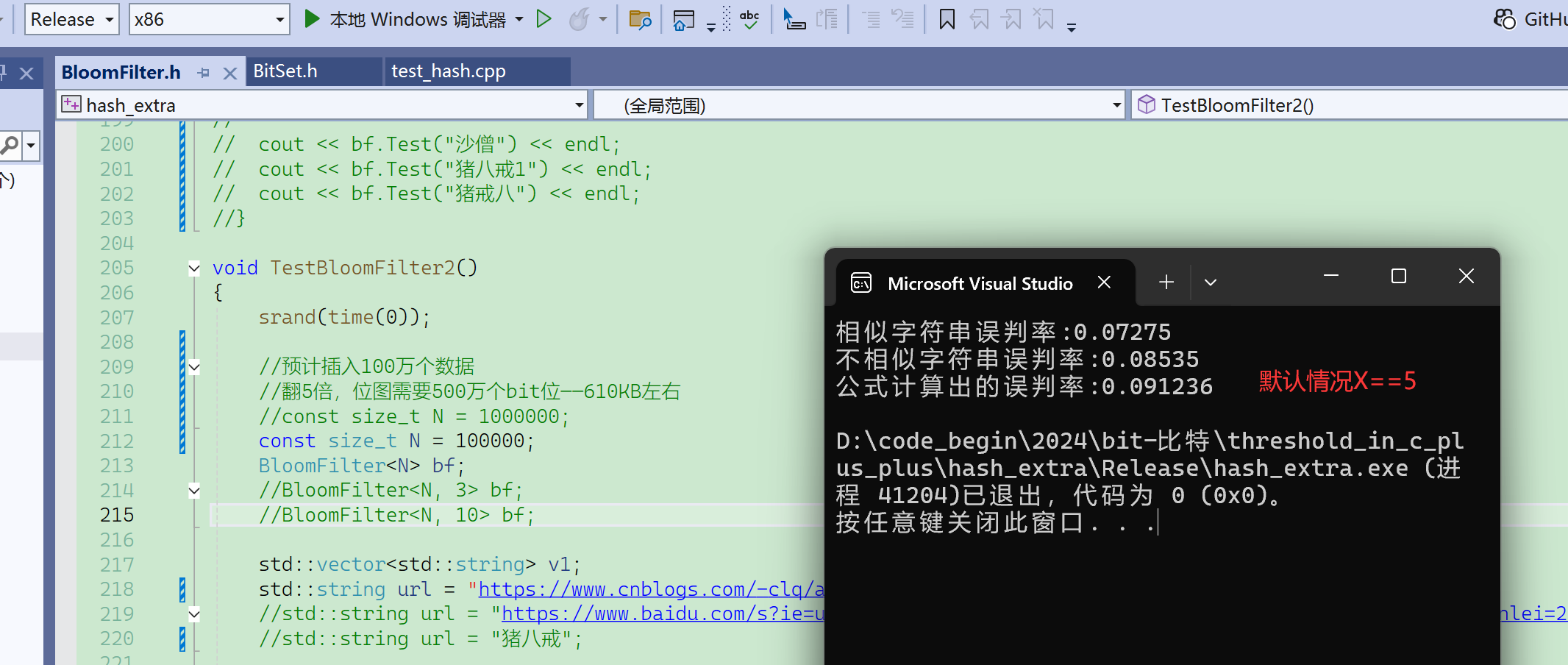
再看看给不同的X值:
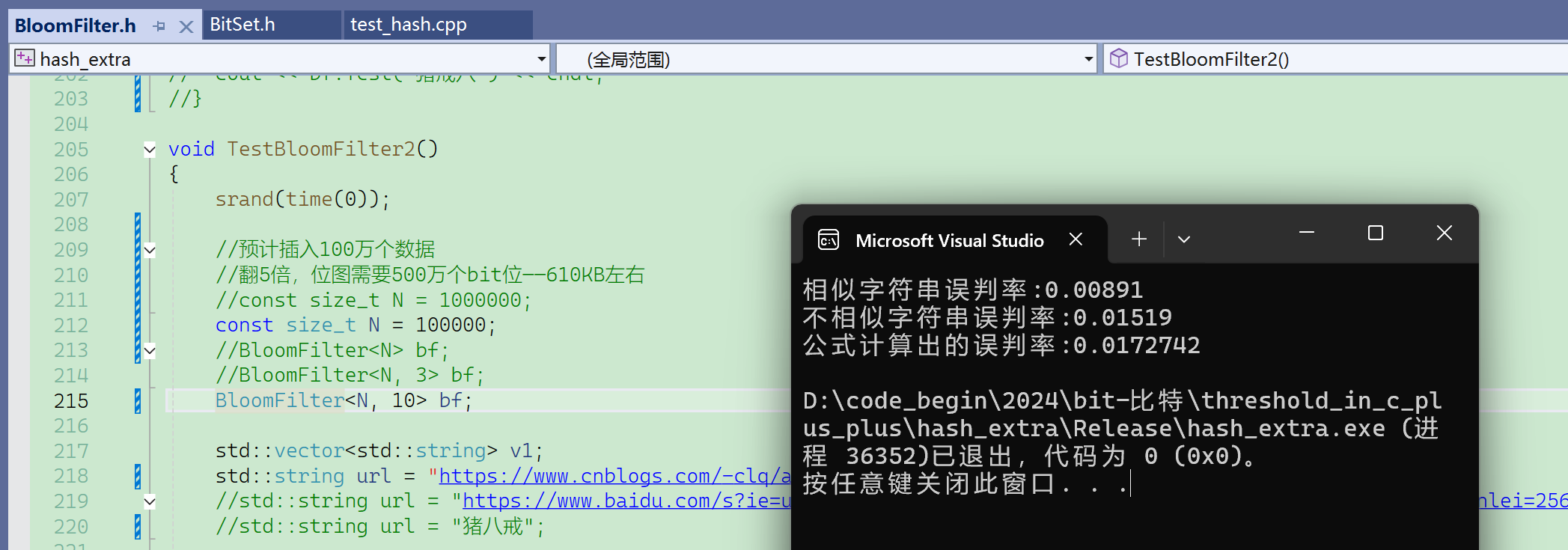
数据量小的时候,不相似字符串误判率更高:
数据量大的时候,相似字符串误判率更高:
布隆过滤器的实现,有的地方的实现是给一个新参数------误判率p。
你可以要求误判率是多少。然后内部计算容器大小 m = f(p, n)。
然后根据误判率,确定用几个哈希函数 K = f(m/n, lnp)。
哈希函数多写几个,set和test的逻辑做成动态的。
2.4 布隆过滤器删除问题
布隆过滤器默认是不支持删除的------不支持reset()。
【原因】
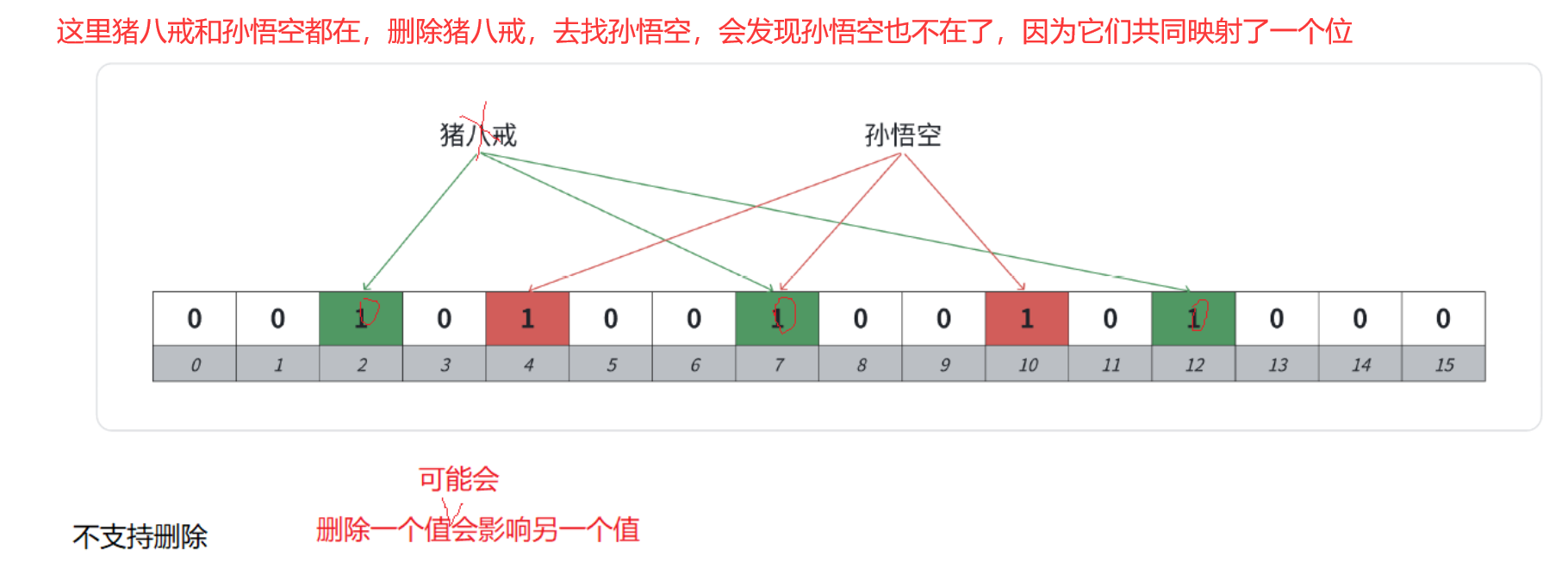
因为比如"猪八戒"和"孙悟空"都映射在布隆过滤器中,他们映射的位有一个位是共同映射的(冲突的),如果我们把孙悟空删掉,那么再去查找"猪八戒"会查找不到,因为那么"猪八戒"间接被删掉了。
【解决方案】
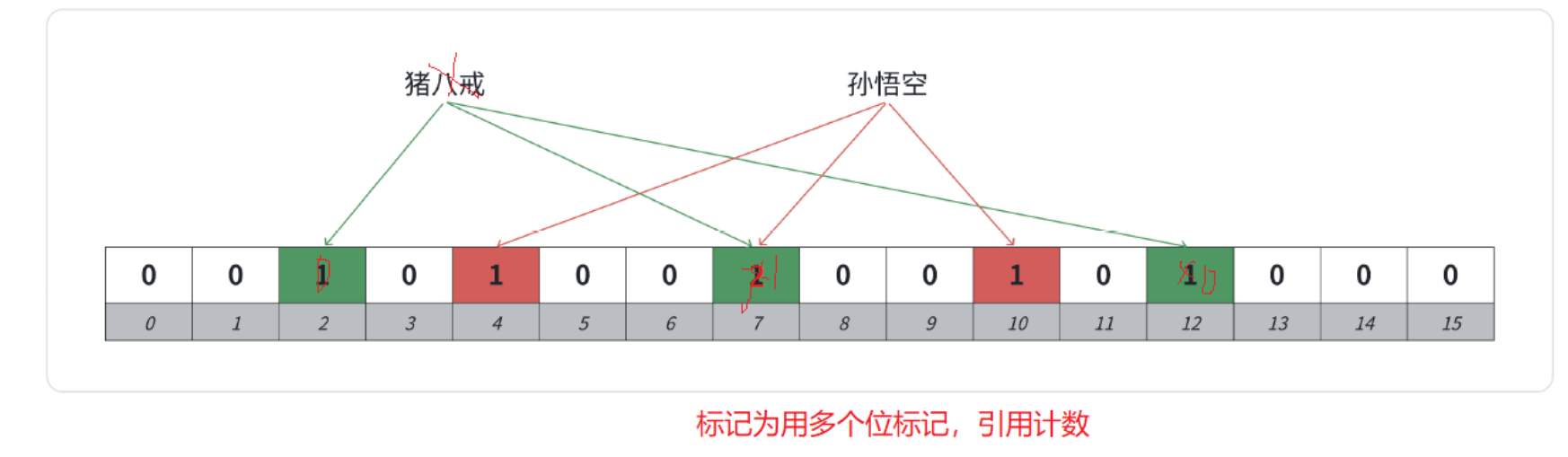
可以考虑计数标记的方式:一个位置用多个位标记,记录映射这个位的计数值,删除时,仅仅减减计数,那么就可以某种程度支持删除。
【缺陷】
但是这个方案也有缺陷:
- 一个位只能存储0/1,无法计数,实现计数要把原来1个hash计算出来的1个位用多个位去存储,才能进行计数,这就增加了空间成本。
- 如果一个值不在布隆过滤器中,我们去删除,减减了映射位的计数,那么会影响已存在的值,也就是说,一个确定存在的值,可能会变成确定不存在,这里就很坑。
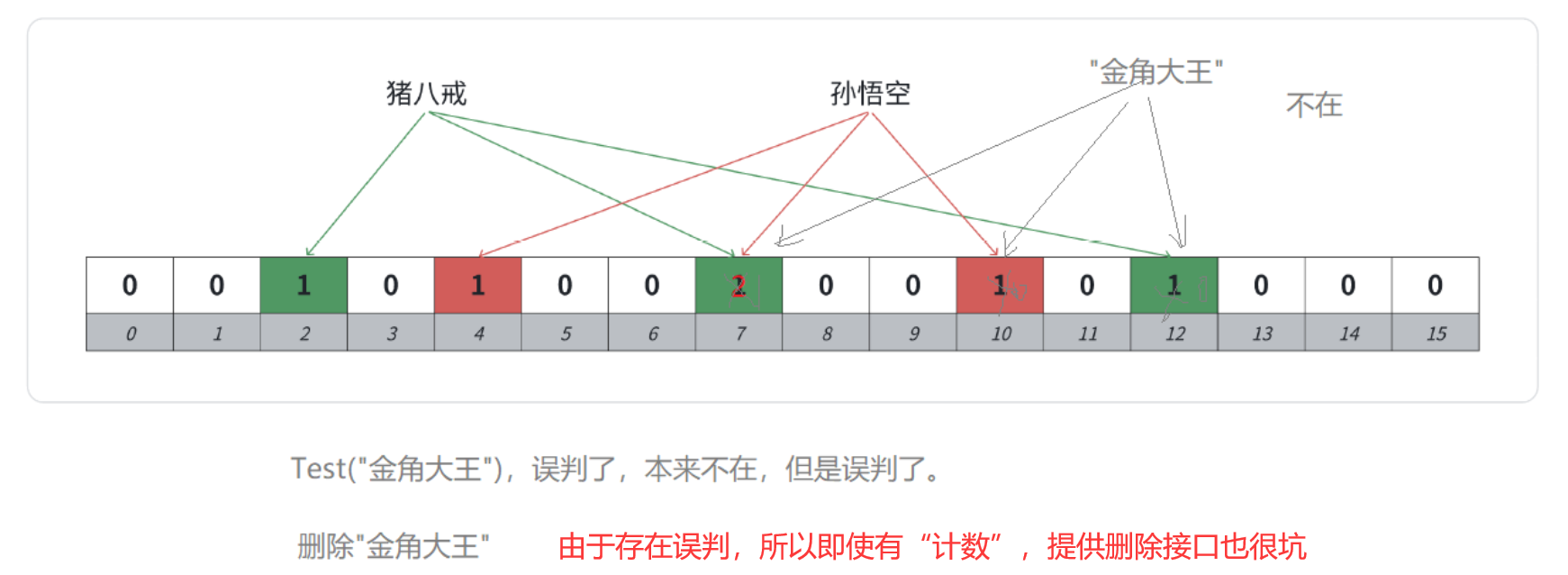
也就是说,
- 不用"计数",删除一个在的对象(映射的所有位),可能导致其他在的对象被删。
- 用了"计数",删除一个"误判在"的对象(映射的所有位),也可能导致其他在的对象被删。
当然也有人提出,我们可以考虑计数方式支持删除,但是定期重建一下布隆过滤器,这样也是一种思路。
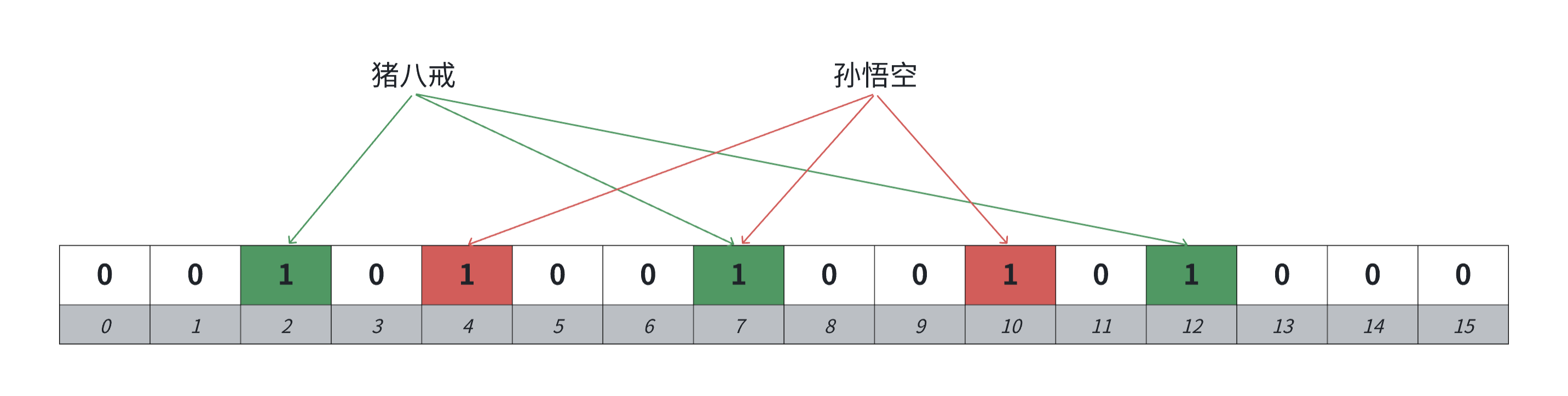
例如:
虽然删除金角大王,导致找猪八戒和孙悟空找不到了。
定期重建,例如24h重建一次,夜间访问量少的时候,关闭服务器进行数据重建。
第二天就能找到猪八戒和孙悟空了。
前提是第二天它们的位没有像第一天一样被误删,天天被误删,就天天都找不到,即使在里面。
2.5 布隆过滤器的应用
2.5.1 布隆过滤器的优缺点
**【优点】**效率高,节省空间,相比位图,可以适用于各种类型的标记过滤。
**【缺点】**存在误判(在是不准确的,不在是准确的),不好支持删除。
2.5.2 布隆过滤器在实践中的一些应用
• 爬虫系统中URL去重
在爬虫系统中,为了避免重复爬取相同的URL,可以使用布隆过滤器来进行URL去重。
爬取到的URL可以通过布隆过滤器进行判断,已经存在的URL则可以直接忽略,避免重复的网络请求和数据处理。
爬虫:用程序去模拟我们人工对一些网站的访问行为,然后获取服务器返回的网页信息,然后解析网页信息,拿到想要的数据或资源。(前置知识:登录服务、网络、前端、......)
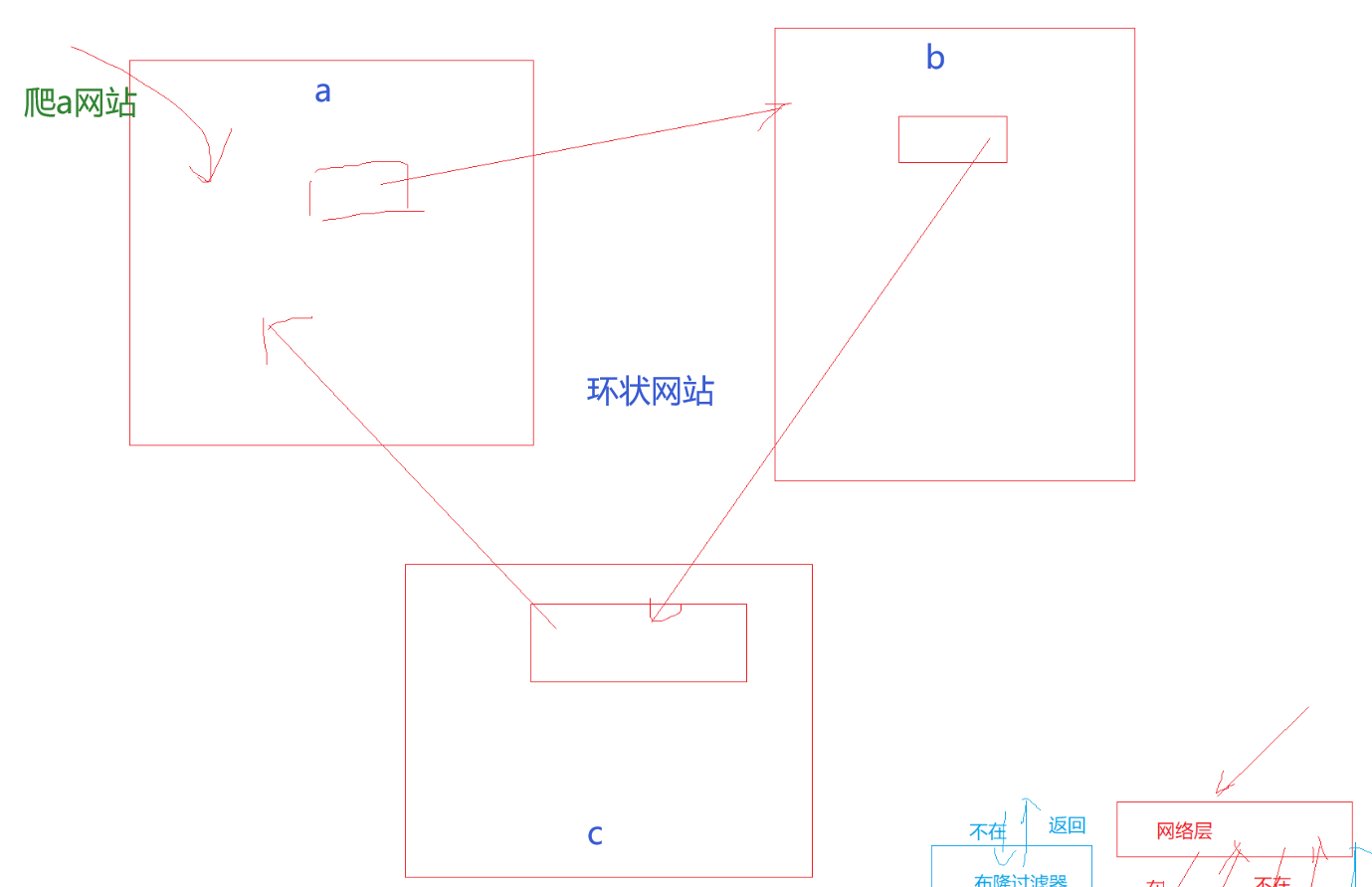
爬a网站,拿到子链接,指向b网站,拿到子链接,指向c网站,拿到子链接,指向a网站......
这时就需要记录下沿途的url,已经爬过的就不再爬了,没爬过的再去爬。
避免陷入死循环。
使用布隆过滤器就可以应对大量url的查找,存储空间还不用太多,节省空间并且快。
但是这时可能存在误判,一个网站没爬过,但是被判断爬过了,就爬漏了。
• 垃圾邮件过滤
在垃圾邮件过滤系统中,布隆过滤器可以用来判断邮件是否是垃圾邮件。
大量的垃圾邮件,存储到数据库里去判断太慢了。
系统可以将已知的垃圾邮件的特征信息存储在布隆过滤器中,当新的邮件到达时,可以通过布隆过滤器快速判断是否为垃圾邮件,从而提高过滤的效率。
可能导致误判,判断是垃圾邮件,是不准确的,正常邮件可能被判断为垃圾邮件。
这些都是能一定程度上容忍误判的场景。
• 预防缓存穿透
在分布式缓存系统中,布隆过滤器可以用来解决缓存穿透的问题。
**缓存穿透:**是指恶意用户请求一个不存在的数据,导致请求直接访问数据库,造成数据库压力过大。
布隆过滤器可以先判断请求的数据是否存在于布隆过滤器中,如果不存在,直接返回不存在,避免对数据库的无效查询。
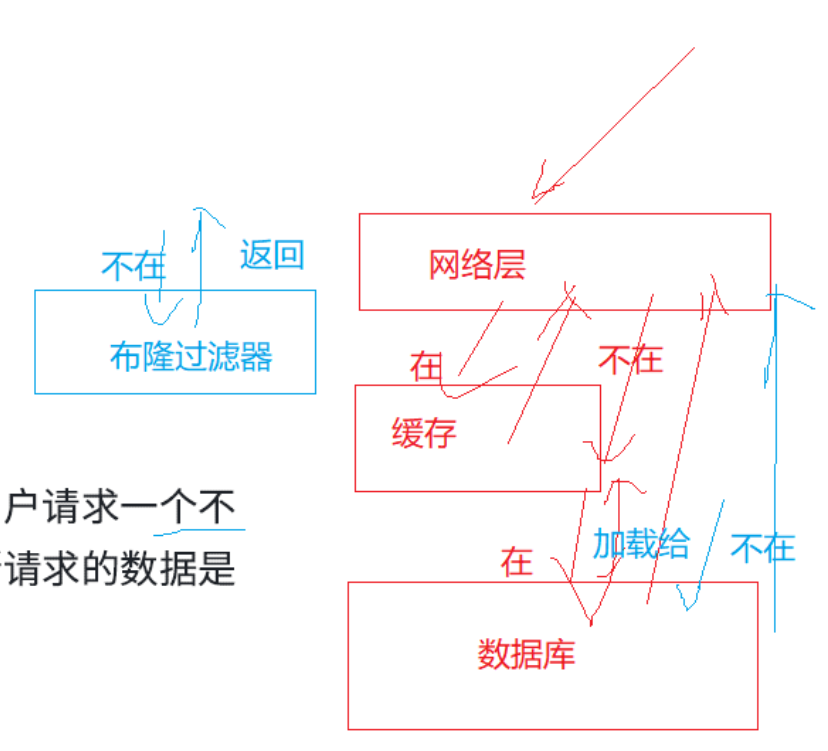
一般高性能的服务器,数据都是存储在数据库。
外部向网络层请求数据,网络层直接去数据库里面找太慢,所以一般都有中间缓存。
中间缓存里面都是一些"热数据"------高访问量的数据,会从数据库加载到缓存。
数据访问是先去看缓存有没有,缓存没有再去看数据库,数据库里有,就会返回给访问者,同时加载一份数据备份到缓存,下次再来访问,就能直接从缓存里面拿数据。
恶意用户了解了你的服务器的底层机制,还知道有些数据不在数据库,然后大量请求,就需要先问缓存,再问数据库,数据库再回馈无数据的信息。
请求那些不在数据库的数据,成本最高。
缓存本来是缓解服务器压力的,一直请求不在数据库的数据,那大量的压力全给到数据库,就会导致数据库压力过大,数据库崩溃,或者别人请求不进来等情况。
可以在缓存之上加一个布隆过滤器。(布隆过滤器包含所有数据的映射------但是消耗空间很少)
布隆过滤器可以先判断请求的数据是否存在于布隆过滤器中,如果不存在(准确),直接返回不存在,避免对数据库的无效查询;如果在(不准确),再去访问缓存、数据库。
• 对数据库查询提效
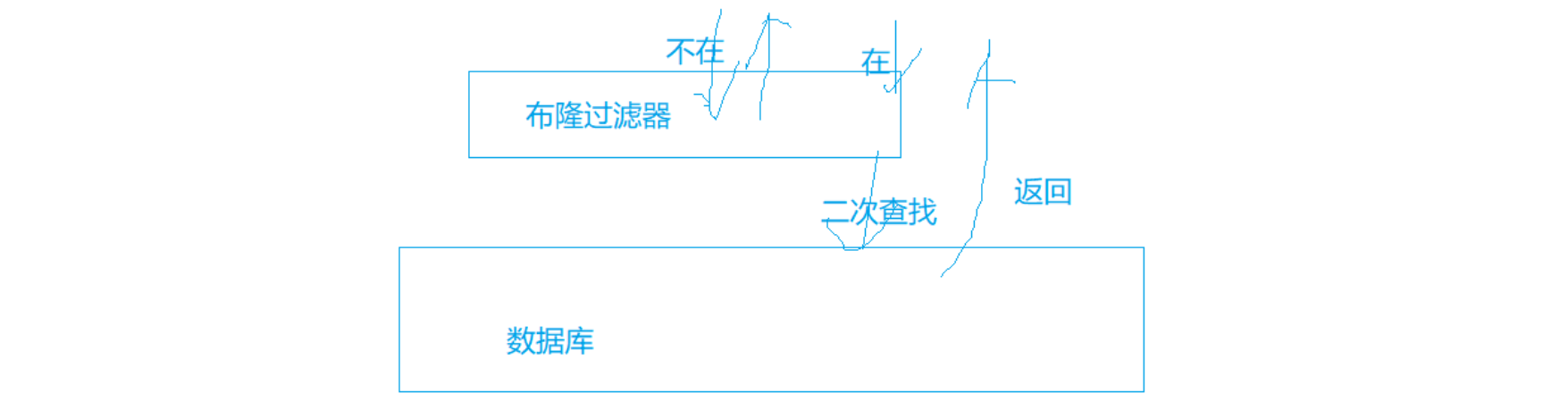
假设没有缓存的数据库,访问数据库(磁盘中),是大量的IO操作,就会比较慢。
在数据库中,布隆过滤器还可以用来加速查询操作。
例如:一个app要快速判断一个电话号码是否注册过,可以使用布隆过滤器来判断一个用户电话号码是否存在于表中。
如果不在(准确),可以直接返回不存在,避免对数据库进行无用的查询操作。
如果在(不准确),再去数据库查询进行二次确认。
完