

🔥个人主页:北极的代码(欢迎来访)
🎬作者简介:java后端学习者
✨命运的结局尽可永在,不屈的挑战却不可须臾或缺!
前言:
我们前面已经学习完了黑马点评的第一个业务功能,也就是根据短信验证登陆的业务功能,接下来我们继续学习,(最近忙着复习学校的课程,导致进度不是很快,还有就是算法题也挺头疼的,其次就是八股文,可能顾虑太多了,想同时进行,但还是没找到平衡点,再试试一星期吧,实在不行就舍弃一部分。)今天要学习的是商户查询缓存的业务功能。
摘要:
本文介绍了商户查询缓存功能的实现原理与应用场景。首先阐述了缓存的基本概念,通过做饭和冰箱的类比形象说明了缓存的作用。文章详细分析了缓存的优势(提升性能、减轻数据库压力)和挑战(数据一致性、缓存穿透等),并比较了本地缓存与Redis缓存的区别。
在技术实现部分,提供了完整的代码示例展示如何为商铺信息和类型添加Redis缓存,包括查询逻辑和更新策略。
重点讲解了三种缓存更新策略(主动更新、TTL过期、双写模式),推荐采用"先更新数据库再删除缓存"的最佳实践以避免数据不一致问题。
最后总结了不同缓存策略的适用场景,强调主动更新策略在保证数据一致性方面的优势。
商户查询缓存功能:
什么是缓存:
简单说,缓存就是临时存储数据的地方,目的是为了以后能更快地获取它。
想象一下:
没有缓存:就像每次做饭都要从种菜、养猪开始,效率极低。
有缓存:就像把做好的饭菜放在冰箱里,饿了直接拿出来热一下就能吃,又快又方便。
在计算机世界里,CPU有缓存,浏览器有缓存,而黑马点评项目 用的就是Redis缓存,用来存储像商铺信息、用户会话这类数据。
缓存的核心原理:快慢分层
计算机存储是一个金字塔结构,越往上越快,但容量越小、成本越高。
L1/L2/L3 缓存 :速度极快(纳秒级),集成在CPU内部。
内存 (如 Redis) :速度快(微秒级),容量较大。
硬盘 (如 MySQL) :速度慢(毫秒级),容量巨大。
缓存的目标就是:把最常用的数据从慢速的硬盘(MySQL)搬到快速的内存(Redis)中,从而加速访问。
使用缓存的好处
1. 性能飙升,用户体验好
读内存 :通常只需几十微秒
读硬盘 :通常需要几毫秒甚至几十毫秒
差距 :内存比硬盘快 100-1000倍 。用户打开页面从等2秒变成瞬间打开。
2. 减轻数据库压力,系统更稳
数据库的连接数是有限的(比如200个)。如果没有缓存,所有请求都冲击数据库,很容易把数据库压垮。
有了缓存后,80%以上的读请求都被缓存拦截,数据库的压力骤降,系统更稳定。
3. 应对高并发,支撑大流量
像双11这样的场景,每秒百万级请求,数据库根本无法承受。必须依靠缓存集群来扛住绝大部分的读请求。
4. 提高扩展性
当流量增长时,可以通过增加缓存节点(如Redis集群)来水平扩展读能力,成本相对较低。
使用缓存的坏处与挑战
1. 数据一致性问题(最核心的挑战)本章讲解
缓存是数据的"副本",当数据库中的数据发生变化时,如何保证缓存中的数据也同步更新?
如果不更新 :用户看到的是脏数据(例如:你修改了商铺信息,但页面还是旧的)。
解决方案:需要复杂的缓存更新策略(如更新数据库后,立即删除或更新缓存)。
2. 缓存穿透
恶意查询一个缓存和数据库中都不存在的数据 (例如查询ID为
-1的商品)。
后果:每次请求都会穿透缓存,直接打到数据库,可能压垮数据库。
解决方案:缓存空对象、使用布隆过滤器。
3. 缓存雪崩
大量缓存同时失效,导致所有请求瞬间全部打到数据库。
常见原因:缓存服务器宕机,或大量key设置了相同的过期时间。
解决方案:给过期时间增加随机值、部署高可用集群。
4. 缓存击穿
某个热点数据(如爆款商品)的缓存恰好失效,此时大量并发请求同时打到数据库去查询这个数据。
后果:数据库瞬间压力巨大。
解决方案:使用互斥锁,只让一个线程去查数据库,其他线程等待。
5. 增加系统复杂度和维护成本
需要额外的缓存系统(如Redis服务器)。
代码逻辑变复杂:读数据要先读缓存,没命中再读数据库然后写缓存;写数据要考虑更新缓存。
需要考虑缓存淘汰策略(内存满了怎么办?如LRU)。
剩下的几个问题我们下一节再详细讲解。
在黑马点评项目中的应用
| 场景 | 无缓存 (查MySQL) | 有缓存 (查Redis) | 提升 |
|---|---|---|---|
| 查询商铺信息 | 慢,耗时高,数据库压力大 | 快,毫秒级响应,数据库无压力 | 性能提升10倍+ |
| 登录状态刷新 | 每次请求都查数据库验证Session | 基于Token (JWT或存Redis) | 无需查库,水平扩展能力强 |
| 秒杀/优惠券 | 无法应对高并发 | 利用Redis原子操作和Lua脚本 | 轻松应对高并发 |
本地缓存(JVM层面缓存)
定义 : 缓存数据存储在同一个应用程序的内存中。也就是跟写的Java代码在同一个Java虚拟机(JVM)里。
代表技术 : Caffeine(黑马点评中用的就是它)、Guava Cache、Ehcache。
特点:
极快: 不需要网络传输,直接从内存读,微秒级。
强耦合: 每个微服务/应用实例都有自己的缓存副本。
有上限: 受限于JVM堆内存大小,不能存太多。
使用场景:
黑马点评中查询商铺类型列表(这种数据很少变)。
热点参数、计数器、临时状态。
2. 分布式缓存(进程外缓存)
定义 : 缓存数据存储在独立的缓存服务器上,应用程序通过网络请求访问它。
代表技术 : Redis(黑马点评中的核心)、Memcached。
特点:
共享性: 多个应用实例(比如10个订单服务)可以共享同一份缓存数据。
大容量: 独立于应用内存,可以存几十GB甚至更多。
网络开销: 需要网络IO,比本地缓存慢一点(毫秒级),但远快于数据库。
使用场景:
- 黑马点评中的商铺详情、优惠券库存、用户登录状态(Session共享)、短信验证码。
3. 客户端缓存
定义 : 缓存数据存储在调用方的机器上。
代表技术: 浏览器缓存(HTTP Cache)、客户端App本地存储。
特点: 最接近用户,延迟最低,但数据安全性差,不可控。
使用场景: 网页静态资源(图片、CSS、JS)、App首页数据。
按计算机体系结构分类(宏观视角)
如果是在面试或学习计算机基础,这个分类也很重要。
| 层级 | 介质 | 速度 | 容量 | 典型例子 |
|---|---|---|---|---|
| CPU缓存 | SRAM(静态随机存取存储器) | 纳秒级 | KB-MB | L1、L2、L3 Cache |
| 操作系统缓存 | 内存 | 微秒级 | 内存大小 | Page Cache(页缓存) |
| 数据库缓存 | 内存 | 微秒级 | 配置决定 | MySQL Buffer Pool |
| 应用缓存 | 内存(进程内/进程外) | 微秒-毫秒 | 可配置 | Caffeine、Redis |
| 网络缓存 | 硬盘/内存 | 毫秒级 | 很大 | CDN、HTTP缓存、代理缓存 |
本地缓存 vs Redis缓存:核心区别
这是你在黑马点评中需要重点区分的,我帮你总结了一个表格:
| 对比维度 | 本地缓存 (Caffeine) | 分布式缓存 (Redis) |
|---|---|---|
| 数据存储位置 | 应用进程的内存中 | 独立的Redis服务器内存中 |
| 数据一致性 | 弱。实例A改了数据,实例B可能还是旧数据 | 强。所有实例读同一个Redis,数据一致 |
| 性能 | 非常高(无网络IO,纳秒/微秒级) | 高(有网络IO,毫秒级) |
| 容量限制 | 小(受限于JVM堆内存,几GB) | 大(独立服务器,几十GB甚至TB) |
| 生命周期 | 随应用进程生灭 | 独立于应用,重启应用缓存还在 |
| 典型用途 | 少量、极少变化、机器级数据 | 大量、共享、需要持久化/集群的数据 |
黑马点评中的实战分类
在这个项目中,你会看到两种缓存同时使用,各有分工:
本地缓存(Caffeine) -> 店铺类型查询
为什么?因为店铺类型(比如"美食"、"电影")很少变化,而且数据量极小。用本地缓存最快,不用每次查Redis增加网络开销。
代码位置:
ShopTypeController->queryTypeList()。Redis缓存 -> 几乎所有其他业务
商铺详情:需要共享,且数据量大。
登录状态:微服务架构下,需要共享Token/Session。
优惠券秒杀:需要原子操作和计数。
用户签到:利用Redis的Bitmap数据结构。
总结一句话
本地缓存 :是你的私人笔记本,自己用最快,但别人看不到你写的。
Redis缓存 :是办公室的共享白板,大家都看得到、写得上,但走过去写需要时间。
浏览器缓存:是你家冰箱里的食物,只有你自己吃。
完整的技术栈分层
从代码到硬件,应该是这样分层的:
| 层面 | 技术 | 作用 | 类比 |
|---|---|---|---|
| 应用层(你的代码) | Controller, Service | 业务逻辑 | 饭店的厨师 |
| Web容器层 | Tomcat | 接收HTTP请求,管理线程池,调用你的代码 | 饭店的前台+传菜员 |
| JVM层 | JVM内存 | 运行Java代码,管理堆内存 | 厨房的操作台 |
| 本地缓存 | Caffeine | JVM堆内存中的一块区域 | 灶台上的调料架 |
| 分布式缓存 | Redis | 独立进程,通过网络访问 | 中央仓库 |
| 数据库 | MySQL | 硬盘持久化存储 | 冰箱+冷库 |
关于tomcat的一些了解
Tomcat 在缓存架构中的角色
Tomcat 本身不是缓存,但它和缓存有密切关系:
1. Tomcat 管理着"本地缓存"的生存环境
java
java
// 这段代码运行在 Tomcat 内的 JVM 中
@Configuration
public class CacheConfig {
@Bean
public Cache<String, Object> localCache() {
// 这个缓存存在 Tomcat 的 JVM 堆内存里
return Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build();
}
}2. Tomcat 的线程池影响缓存效率
Tomcat 默认有 200 个线程处理请求。如果缓存命中率高,这些线程很快就能返回结果,Tomcat 就能处理更多并发。
3. 多 Tomcat 实例下的缓存问题
在生产环境中,你通常会有多个 Tomcat 实例(集群):
text
负载均衡器 (Nginx) ↓ ┌─────────┼─────────┐ ↓ ↓ ↓ Tomcat1 Tomcat2 Tomcat3 (本地缓存A) (本地缓存B) (本地缓存C) ↓ ↓ ↓ └─────────┼─────────┘ ↓ Redis (共享缓存)问题来了:
本地缓存(Caffeine):Tomcat1 改了数据,Tomcat2 的本地缓存还是旧的 → 数据不一致
Redis:所有 Tomcat 共享,数据一致
这就是为什么黑马点评里:
店铺类型(很少变)→ 用本地缓存
店铺详情(可能变)→ 用 Redis
Tomcat 本身自带的缓存
Tomcat 作为 Web 服务器,也提供了一些缓存机制:
1. 静态资源缓存
xml
<!-- Tomcat 的 context.xml --> <Resources> <PreResources className="org.apache.catalina.webresources.Cache" cacheMaxSize="10000" <!-- 缓存静态资源 --> /> </Resources>2. Session 缓存(存储用户会话)
java
// Tomcat 默认把 Session 存在内存中 HttpSession session = request.getSession(); session.setAttribute("user", user); // 存在 Tomcat 内存里问题:多 Tomcat 实例下,Session 不共享(用户第一次请求打到 Tomcat1,第二次打到 Tomcat2 就丢了)。
解决方案:用 Redis 存 Session(黑马点评用的 JWT Token 方案)
浏览器缓存 vs Tomcat/JVM缓存 vs Redis缓存
现在来完整对比这三者:
| 对比维度 | 浏览器缓存 | 本地缓存(Caffeine) | Redis缓存 |
|---|---|---|---|
| 存储位置 | 用户硬盘/内存 | Tomcat的JVM堆内存 | 独立Redis服务器 |
| 谁管理 | 浏览器自动+JS手动 | 你的Java代码 | 你的Java代码+Redis |
| 访问速度 | 极快(本地读,无网络) | 极快(微秒级,无网络) | 快(毫秒级,有网络) |
| 容量限制 | 有限(几MB到几百MB) | 小(JVM堆内存限制) | 大(独立服务器内存) |
| 数据共享 | 只有当前用户能看到 | 当前Tomcat实例的所有用户 | 所有Tomcat实例的所有用户 |
| 生命周期 | 手动清除或自动过期 | 随Tomcat重启清空 | 独立于应用重启 |
| 适用场景 | 静态资源、用户偏好、离线数据 | 应用级热点数据(如店铺类型) | 共享业务数据(如库存、登录态) |
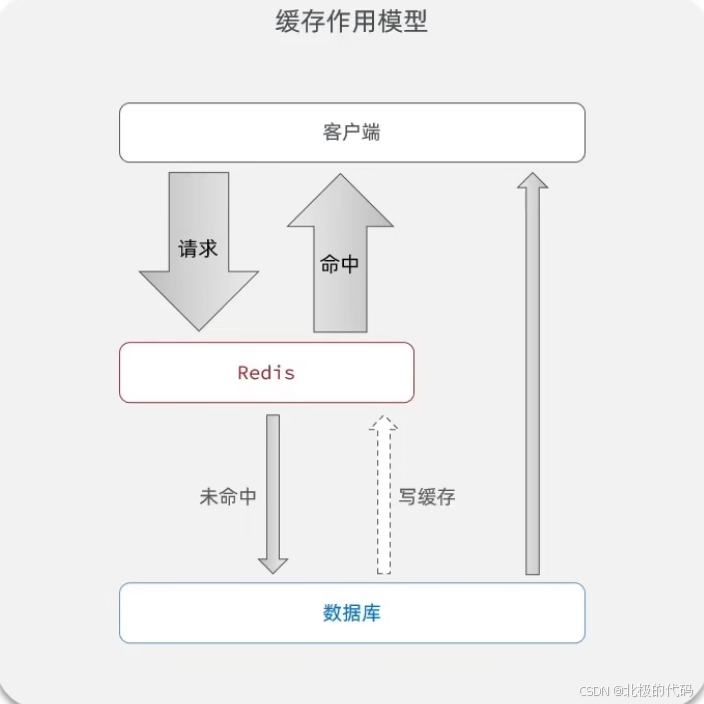
项目添加Redis缓存:
模型如图:
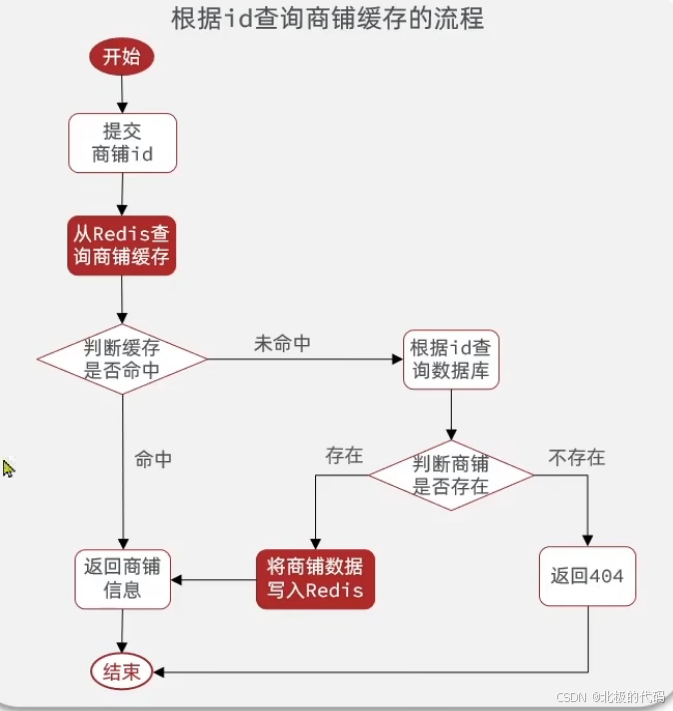
具体的添加商户缓存的实现流程:
代码实现:
java
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
/**
* 根据id查询商铺信息
* @param id 商铺id
* @return
*/
public Result queryById(Long id) {
String key = RedisConstants.CACHE_SHOP_KEY+ id;
//从Redis中查询商品缓存信息
String shopJson = stringRedisTemplate.opsForValue().get(key);
//判断缓存是否存在
if(StrUtil.isNotBlank(shopJson)){
//存在,直接返回
//将json转为对象
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
}
//不存在,查询数据库
Shop shop = getById(id);
if (shop== null){
return Result.fail("商铺信息不存在");}
//写入缓存
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop));
return Result.ok(shop);
}
}这里主要是Service层的代码实现,因为是在这里实现主要的业务操作,然后这里需要注意的是,我们从Redis中查到的是json格式的,要转成对象,有的对这些不是很了解,或者说忘记了,我们在这里提及一下:
为什么要转成对象?
核心原因:JSON是死的,对象是活的
java
java
// JSON字符串(死的) - 只是一堆文本
String shopJson = "{\"id\":1,\"name\":\"海底捞\",\"price\":100}";
// Java对象(活的) - 有行为、有类型
Shop shop = new Shop();
shop.setId(1);
shop.setName("海底捞");
shop.calculateDiscount(); // 对象可以有方法!具体对比
| 维度 | JSON字符串 | Java对象 |
|---|---|---|
| 类型安全 | ❌ 编译期不检查字段名 | ✅ 字段类型编译期确定 |
| 方法调用 | ❌ 不能调用业务方法 | ✅ 可以调用 shop.getPrice() |
| IDE支持 | ❌ 无代码提示 | ✅ 有代码补全、重构支持 |
| 性能 | ⚠️ 每次需要重新解析 | ✅ 直接访问内存字段 |
| 可读性 | ❌ 大段字符串难以调试 | ✅ 对象结构清晰 |
给店铺类型查询业务添加缓存:
代码实现:
java
@Service
public class ShopTypeServiceImpl extends ServiceImpl<ShopTypeMapper, ShopType> implements IShopTypeService {
@Resource
private StringRedisTemplate stringRedisTemplate;
/**
* 获取所有商铺类型
* @return
*/
public List<ShopType> queryTypeListWithCache() {
List<String> shopTypesJsonList = stringRedisTemplate.opsForList().range("cache:shop:types", 0, -1);
// 判断缓存中是否有数据
if (shopTypesJsonList != null && !shopTypesJsonList.isEmpty()) {
// 缓存中有数据
return shopTypesJsonList.stream().map(shopTypesJson -> JSONUtil.toBean(shopTypesJson, ShopType.class))
.collect(Collectors.toList());
}
// 缓存中没有数据
// 查询数据库
List<ShopType> shopTypes = query().orderByAsc("sort").list();
// 将数据写入缓存
stringRedisTemplate.opsForList().leftPushAll("cache:shop:types", shopTypes.stream().map(shopType -> JSONUtil.toJsonStr(shopType)).collect(Collectors.toList()));
return shopTypes;
}
}这里我们使用的是List集合来接受redis数据,也可以用String
Redis中存储的样子
redis
# 在Redis中,List就像一个数组 key: "cache:shop:types" value: ["商品1", "商品2", "商品3", "商品4", "商品5"] 索引0 索引1 索引2 索引3 索引4 索引-5 索引-4 索引-3 索引-2 索引-1
String存储JSON
java
// 方案1:用 String 存 JSON 数组(推荐)
String key = "cache:shop:types";
String shopTypesJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopTypesJson)) {
return JSONUtil.toList(shopTypesJson, ShopType.class);
}
// 写入时
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shopTypes), 30, TimeUnit.MINUTES);缓存更新策略:
为什么需要缓存更新策略?
核心问题:数据不一致
缓存是数据库的"副本",当数据库数据变化时,缓存如果不更新,就会出现数据不一致。
java
java
// 场景:管理员修改了店铺类型
// 数据库:id=1 的 name 从 "美食" 改为 "餐饮"
// 问题:缓存中还是旧数据
缓存:{"id":1,"name":"美食"} // 脏数据!
数据库:{"id":1,"name":"餐饮"} // 最新数据
// 用户查询时,从缓存读到的是"美食"(错误!)真实案例影响
| 场景 | 问题 | 后果 |
|---|---|---|
| 商品价格修改 | 缓存还是旧价格 | 用户下单价格错误 |
| 库存扣减 | 缓存库存未更新 | 超卖问题 |
| 用户信息修改 | 缓存是旧信息 | 显示错误信息 |
| 店铺类型改名 | 缓存是旧名称 | 前端显示混乱 |
二、三种缓存更新策略
1. 主动更新(Cache Aside Pattern)- 最常用
核心思想:由业务代码主动控制缓存的更新
java
java
@Service
public class ShopTypeService {
@Autowired
private StringRedisTemplate redisTemplate;
// 查询:先查缓存,再查数据库
public List<ShopType> queryTypeList() {
String key = "cache:shop:types";
String json = redisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(json)) {
return JSONUtil.toList(json, ShopType.class);
}
// 查数据库
List<ShopType> list = query().orderByAsc("sort").list();
// 写缓存
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(list), 30, TimeUnit.MINUTES);
return list;
}
// 更新:先更新数据库,再删除缓存
@Transactional
public void updateType(ShopType shopType) {
// 1. 更新数据库
updateById(shopType);
// 2. 删除缓存(而不是更新缓存)
String key = "cache:shop:types";
redisTemplate.delete(key);
}
}流程图:
text
更新操作:
用户修改数据 → 更新数据库 → 删除缓存
↓
下次查询 → 缓存未命中 → 查数据库 → 写缓存(得到最新数据)
查询操作:
用户查询 → 查缓存 → 命中返回
↓ 未命中
查数据库 → 写缓存 → 返回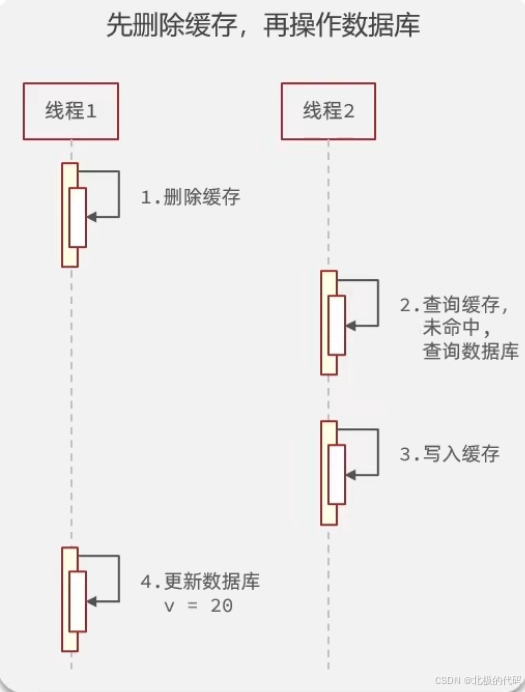
2. 被动更新(TTL过期)
核心思想:设置过期时间,自动失效
java
java
// 写入缓存时设置过期时间
redisTemplate.opsForValue().set(key, json, 30, TimeUnit.MINUTES);
// 30分钟后自动过期
// 下次查询会重新加载最新数据优点: 简单,无需手动删除
缺点: 30分钟内数据可能不一致
3. 双写模式(Write Through)
核心思想:更新数据库的同时,也更新缓存
java
java
@Transactional
public void updateType(ShopType shopType) {
// 1. 更新数据库
updateById(shopType);
// 2. 更新缓存(而不是删除)
String key = "cache:shop:types";
List<ShopType> newList = query().orderByAsc("sort").list();
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(newList), 30, TimeUnit.MINUTES);
}缺点: 性能较差(每次更新都要查数据库重建缓存)
三、主动更新的最佳实践
黑马点评中的标准写法
java
java
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Autowired
private StringRedisTemplate redisTemplate;
// 查询单个店铺(带缓存)
@Override
public Result queryById(Long id) {
String key = CACHE_SHOP_KEY + id;
// 1. 从缓存查询
String shopJson = redisTemplate.opsForValue().get(key);
// 2. 缓存命中
if (StrUtil.isNotBlank(shopJson)) {
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
// 3. 缓存未命中,查数据库
Shop shop = getById(id);
if (shop == null) {
return Result.fail("店铺不存在");
}
// 4. 写入缓存(设置过期时间)
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop),
CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);
}
// 更新店铺(先更新数据库,再删除缓存)
@Override
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺ID不能为空");
}
// 1. 更新数据库
updateById(shop);
// 2. 删除缓存
String key = CACHE_SHOP_KEY + id;
redisTemplate.delete(key);
return Result.ok();
}
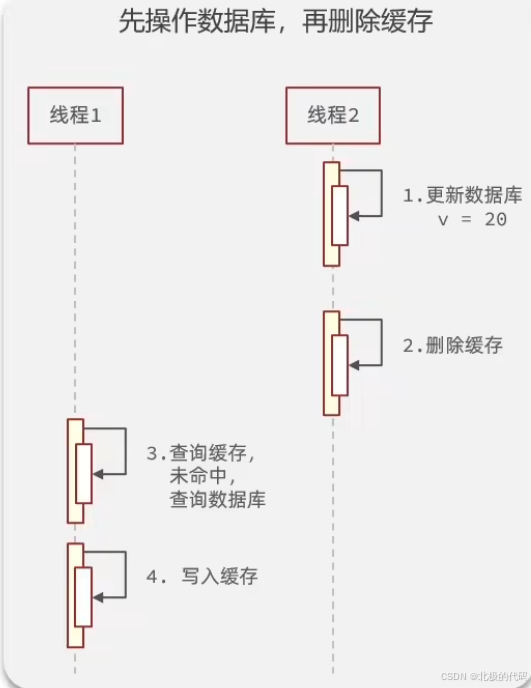
}为什么是"先更新数据库,再删除缓存"?
| 对比维度 | 先删缓存,再更新DB | 先更新DB,再删缓存 |
|---|---|---|
| 并发问题 | 会导致缓存脏数据 | 只会短暂不一致 |
| 脏数据持续时间 | 可能很长(直到过期或再次删除) | 不存在脏数据 |
| 不一致窗口 | 从删缓存到更新DB完成 | 从更新DB到删缓存 |
| 风险等级 | 🔴 高 | 🟢 低 |
java
java
// 方案A:先删缓存,再更新数据库(有问题!)
public void updateA(Shop shop) {
redisTemplate.delete(key); // 1. 先删缓存
updateById(shop); // 2. 再更新数据库
}
// 问题:删缓存后、更新数据库前,有查询请求
// 查询发现缓存为空 → 查数据库(旧数据)→ 写缓存(脏数据)
// 结果:缓存又变成旧数据了!
// 方案B:先更新数据库,再删缓存(推荐!)
public void updateB(Shop shop) {
updateById(shop); // 1. 先更新数据库
redisTemplate.delete(key); // 2. 再删缓存
}
// 优点:即使查询请求进来,读到的也是旧缓存(还没删)
// 等更新完成后删除缓存,下次查询会加载新数据
// 短暂不一致可以接受四、缓存更新策略对比
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 主动删除 | 实时性高,数据一致性好 | 需要写代码,有短暂不一致窗口 | 大部分业务 |
| TTL过期 | 简单,无需维护 | 实时性差,窗口期内数据不一致 | 不重要的数据 |
| 双写更新 | 缓存始终最新 | 性能差,事务复杂 | 读写比例接近1:1 |
总结
| 问题 | 答案 |
|---|---|
| 推荐顺序 | 先更新数据库,再删除缓存 |
| 为什么不推荐先删缓存? | 并发会导致缓存脏数据 |
| 不一致窗口多长? | 从更新DB到删缓存,毫秒级 |
| 如何保证最终一致? | 设置过期时间兜底 |
| 删除失败怎么办? | 重试 + 消息队列 |
一句话记住:先更新数据库再删除缓存,即使有短暂不一致,也不会产生脏数据;而先删缓存再更新数据库,在并发下会产生难以消除的脏数据。