数据库系统(三)
参考资料:
数据库操作命令详解:CREATE、ALTER、DROP 的使用与实践 - 技术栈
【MySQL】DQL-查询语句全解 基础/条件/分组/排序/分页查询 (附带代码演示&案例练习)-腾讯云开发者社区-腾讯云
SQL------数据控制语言DCL(GRANT,REVOKE,COMMIT,ROLLBACK)_Wen先森的技术博客_51CTO博客
面试官灵魂一问: MySQL 的 delete、truncate、drop 有什么区别? - 知乎
目录
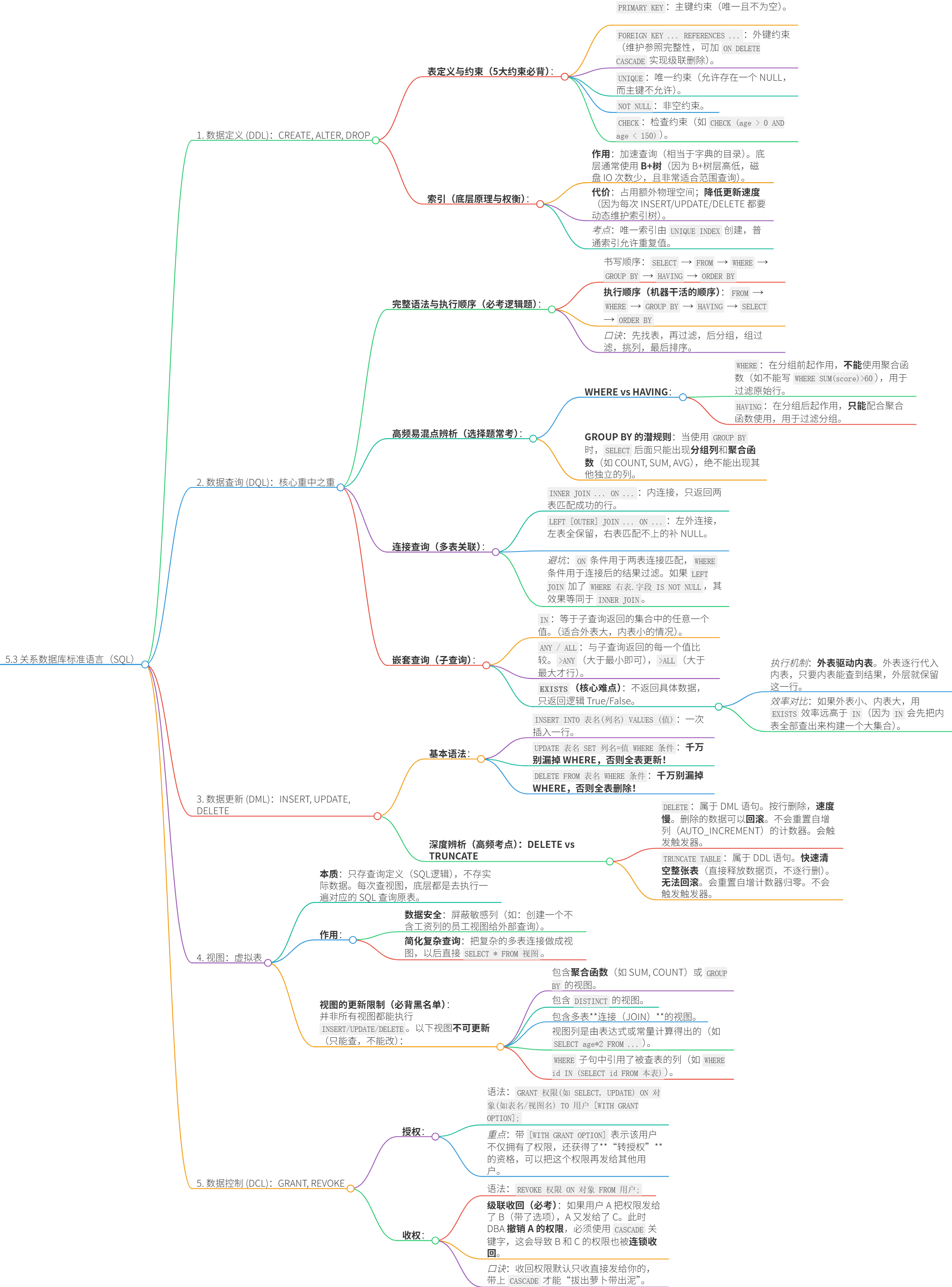
[5.3 关系数据库标准语言(SQL)](#5.3 关系数据库标准语言(SQL))
[1. 数据定义 (DDL):CREATE, ALTER, DROP](#1. 数据定义 (DDL):CREATE, ALTER, DROP)
[2. 数据查询 (DQL)](#2. 数据查询 (DQL))
[1. )基本查询](#1. )基本查询)
[2. )条件查询](#2. )条件查询)
[3. )分组查询](#3. )分组查询)
[4. )排序查询](#4. )排序查询)
[5. )分页查询](#5. )分页查询)
[6. )连接查询(多表关联)](#6. )连接查询(多表关联))
[7. )嵌套查询(子查询)](#7. )嵌套查询(子查询))
[3. 数据操纵 (DML):INSERT, UPDATE, DELETE](#3. 数据操纵 (DML):INSERT, UPDATE, DELETE)
[4. 视图:虚拟表](#4. 视图:虚拟表)
[5. 数据控制 (DCL):GRANT, REVOKE](#5. 数据控制 (DCL):GRANT, REVOKE)
5.3 关系数据库标准语言(SQL)
之前总结的SQL语法内容链接:SQL学习文档-CSDN博客
注:SQL是非过程化语言,你只管说"要什么",不管"怎么找"。
底层找的动作由 数据模型与关系理论 - 软考备战(三十)-CSDN博客 5.2.3讲的关系代数完成。
1. 数据定义 (DDL):CREATE, ALTER, DROP
|--------------|----------|----------------------------------|
| 命令 | 核心功能 | 简要说明 |
| CREATE | 创建 | 创建新的数据库、表、视图、索引等对象。 |
| ALTER | 修改 | 修改已有对象的结构,例如添加、删除或修改字段。 |
| DROP | 删除 | 永久删除数据库对象(如表、索引),连同其数据一起删除。 |
| TRUNCATE | 清空 | 快速删除表中的所有数据,但保留表结构,通常比 DELETE 快。 |
表定义与约束
PRIMARY KEY
主键约束(唯一且不为空)。
FOREIGN KEY ... REFERENCES ...
外键约束(维护参照完整性,可加 ON DELETE CASCADE 实现级联删除)。
UNIQUE
唯一约束(允许存在一个 NULL,而主键不允许)。
NOT NULL
非空约束。
CHECK
检查约束(如 CHECK (age > 0 AND age < 150))。
索引(底层原理与权衡)
可以加速查询(相当于字典的目录),但是占用额外物理空间,降低更新速度。
(因为每次 INSERT/UPDATE/DELETE 都要动态维护索引树)
B+树具体内容链接:树和二叉树 - 软考备战(十三)-CSDN博客
底层通常使用 B+树(因为 B+树层高低,磁盘 IO 次数少,且非常适合范围查询)。
唯一索引由 UNIQUE INDEX 创建,普通索引允许重复值。
2. 数据查询 (DQL)
emp 表:id(员工ID), name(姓名), salary(薪资), age(年龄), dept_id(部门ID)
dept 表:id(部门ID), dept_name(部门名称)
|------------|----------|------------------------------------------------------------------|
| 命令 | 核心功能 | 简要说明 |
| SELECT | 查询 | 从一个或多个表中检索特定的数据列和行,可结合 WHERE、GROUP BY、HAVING、ORDER BY 等子句进行复杂查询。 |
完整语法与执行顺序
书写顺序
SELECT -> FROM -> WHERE -> GROUP BY -> HAVING -> ORDER BY
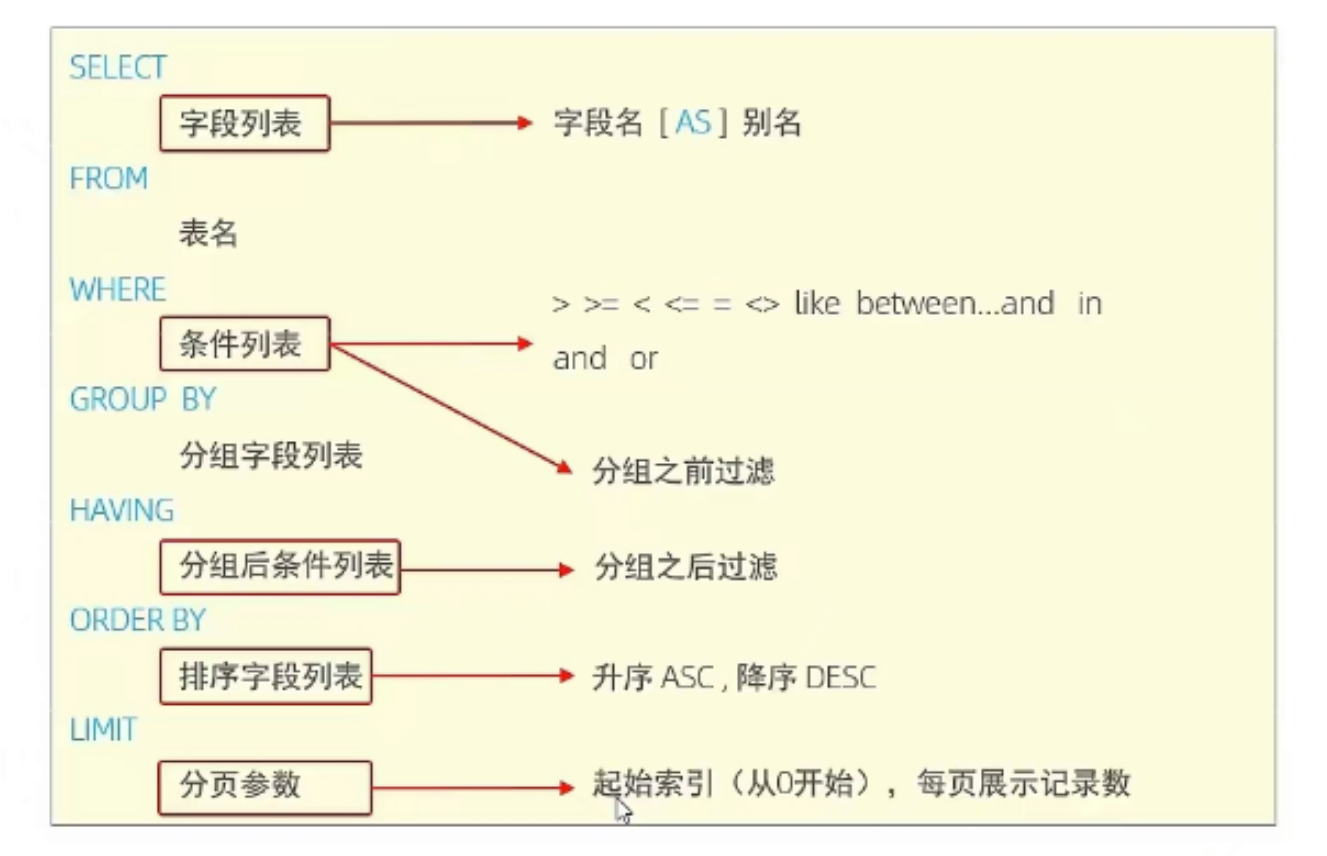
执行顺序(机器干活的顺序)
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY

口诀
先找表,再过滤,后分组,组过滤,挑列,最后排序
F W G H O S (From -> Where -> Group -> Having -> Order -> Select(提取) -> Limit
1. )基本查询
最简单的数据检索,包含去重、算术运算、别名等。
|----------------------|------------|---------------------------------------------------|
| 语法 / 关键字 | 作用 | 示例 |
| SELECT ... | 查询指定列 | SELECT name, salary FROM emp; |
| * | 查询所有列 | SELECT * FROM emp; |
| DISTINCT | 去除重复记录 | SELECT DISTINCT dept_id FROM emp; |
| AS | 起别名(AS可省略) | SELECT name AS '姓名', salary*12 AS '年薪' FROM emp; |
2. )条件查询
使用 WHERE 子句过滤符合条件的数据。
|----------|-----------------------|---------------------------------------------------------|
| 分类 | 关键字 / 运算符 | 示例 |
| 逻辑运算 | AND OR NOT | SELECT * FROM emp WHERE age > 25 AND salary < 10000; |
| 范围查询 | BETWEEN...AND... | SELECT * FROM emp WHERE salary BETWEEN 5000 AND 10000; |
| 集合查询 | IN(...) NOT IN(...) | SELECT * FROM emp WHERE dept_id IN (10, 20, 30); |
| 模糊查询 | LIKE ( %任意多字符, _单个字符) | SELECT * FROM emp WHERE name LIKE '张%'; (查张姓) |
| 空值判断 | IS NULL IS NOT NULL | SELECT * FROM emp WHERE dept_id IS NOT NULL; |

3. )分组查询
将数据按某个列分组,配合聚合函数进行统计分析。
|----------------------|-----------------------------------------------|-----------------------------------------------------------------------------|
| 关键字 / 函数 | 作用 | 示例 |
| GROUP BY | 按列分组 | SELECT dept_id FROM emp GROUP BY dept_id; |
| 聚合函数 | COUNT()计数, SUM()求和, AVG()平均, MAX()最大, MIN()最小 | SELECT dept_id, COUNT(*), AVG(salary) FROM emp GROUP BY dept_id; |
| HAVING | 分组后 过滤(不能用WHERE) | SELECT dept_id, COUNT(*) AS cnt FROM emp GROUP BY dept_id HAVING cnt > 5; |

WHERE vs HAVING 区别
WHERE 在分组前过滤,不能使用聚合函数。
HAVING 在分组后过滤,专门配合聚合函数使用。
GROUP BY 的潜规则
当使用 GROUP BY 时,SELECT 后面只能出现分组列和聚合函数(如 COUNT, SUM, AVG),绝不能出现其他独立的列。
4. )排序查询
将查询结果按指定列进行升序或降序排列。
|----------------------|----------------|-------------------------------------------------------|
| 语法 / 关键字 | 作用 | 示例 |
| ORDER BY | 指定排序的列 | SELECT * FROM emp ORDER BY salary; |
| ASC | 升序(默认值,可省略) | SELECT * FROM emp ORDER BY salary ASC; |
| DESC | 降序 | SELECT * FROM emp ORDER BY salary DESC; |
| 多列排序 | 按第一列排,相同则按第二列排 | SELECT * FROM emp ORDER BY dept_id ASC, salary DESC; |

5. )分页查询
物理上将数据分段返回,避免一次性加载过多数据导致内存溢出(常用于前端表格翻页)。
|----------------|-----------------------------------------------|---------------------------------------------------------------------------------------|
| 数据库 | 语法公式 | 示例(查询第 2 页,每页 5 条) |
| MySQL | LIMIT 偏移量, 每页条数 *(公式:LIMIT (页码-1)*条数, 条数)* | SELECT * FROM emp LIMIT 5, 5; |
| Oracle | ROWNUM 伪列 | SELECT * FROM (SELECT a.*, ROWNUM rn FROM emp a WHERE ROWNUM <= 10) WHERE rn > 5; |
| SQL Server | OFFSET...FETCH | SELECT * FROM emp ORDER BY id OFFSET 5 ROWS FETCH NEXT 5 ROWS ONLY; |

注意: 不同数据库的分页语法不通用。
6. )连接查询(多表关联)
当需要的数据分散在多张表中时,通过主外键关系将表拼接到一起。
假设:emp.dept_id 关联 dept.id
|----------|-----------------------|------------------------|----------------------------------------------------------------------------------------------|
| 连接类型 | 关键字 | 作用描述 | 示例 |
| 内连接 | INNER JOIN ... ON ... | 只返回两表中能匹配上的交集数据 | SELECT e.name, d.dept_name FROM emp e INNER JOIN dept d ON e.dept_id = d.id; |
| 左外连接 | LEFT JOIN ... ON ... | 返回左表全部数据,右表匹配不上的补 NULL | SELECT e.name, d.dept_name FROM emp e LEFT JOIN dept d ON e.dept_id = d.id; (能查出没有部门的员工) |
| 右外连接 | RIGHT JOIN ... ON ... | 返回右表全部数据,左表匹配不上的补 NULL | SELECT e.name, d.dept_name FROM emp e RIGHT JOIN dept d ON e.dept_id = d.id; (能查出没有任何员工的空部门) |
推荐写法:
使用上述的 JOIN ... ON ... 标准语法,淘汰老式的 SELECT * FROM emp, dept WHERE emp.dept_id = dept.id
(容易漏写条件导致笛卡尔积)
7. )嵌套查询(子查询)
一个查询(内查询)的结果,作为另一个查询(外查询)的条件。
常用于解决复杂的逻辑判断。
|-----------------------|-------------------------|---------------------------------------------------------------------------------------------------------|
| 分类 | 特点 | 示例 |
| WHERE 后的标量子查询 | 内查询返回单个值(一行一列) | SELECT * FROM emp WHERE salary = (SELECT MAX(salary) FROM emp); (查工资最高的人) |
| WHERE 后的列子查询 | 内查询返回一列多行,需用 IN | SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE dept_name = '研发部' OR dept_name = '产品部'); |
| FROM 后的表子查询 | 内查询返回多行多列,当作一张临时表使用 | SELECT * FROM (SELECT name, salary FROM emp WHERE age > 25) AS temp WHERE temp.salary > 8000; |
在实际开发中,子查询虽然逻辑直观,但往往可以被改写为 连接查询(JOIN),大多数情况下 JOIN 的执行效率优于子查询。
IN
等于子查询返回的集合中的任意一个值。
(适合外表大,内表小的情况)
ANY / ALL
与子查询返回的每一个值比较。
>ANY(大于最小即可),>ALL(大于最大才行)。
EXISTS
不返回具体数据,只返回逻辑 True/False。
-执行机制:
外表驱动内表。外表逐行代入内表,只要内表能查到结果,外层就保留这一行。
-效率对比:
如果外表小、内表大,用 EXISTS 效率远高于 IN(因为 IN 会先把内表全部查出来构建一个大集合)。
3. 数据操纵 (DML):INSERT, UPDATE, DELETE
|------------|----------|------------------------------|
| 命令 | 核心功能 | 简要说明 |
| INSERT | 插入 | 向表中插入新的数据记录。 |
| UPDATE | 更新 | 修改表中已有的数据记录。 |
| DELETE | 删除 | 删除表中的数据记录,可以配合 WHERE 条件精确删除。 |
基本语法
INSERT INTO 表名(列名) VALUES (值)
一次插入一行。
UPDATE 表名 SET 列名=值 WHERE 条件
千万别漏掉 WHERE,否则全表更新!
DELETE FROM 表名 WHERE 条件
千万别漏掉 WHERE,否则全表删除!
DELETE vs TRUNCATE

DELETE
属于 DML 语句。
按行删除,速度慢。
删除的数据可以回滚。
不会重置自增列(AUTO_INCREMENT)的计数器。
会触发触发器。
TRUNCATE TABLE
属于 DDL 语句。
快速清空整张表(直接释放数据页,不逐行删)。
无法回滚。
会重置自增计数器归零。不会触发触发器。
4. 视图:虚拟表
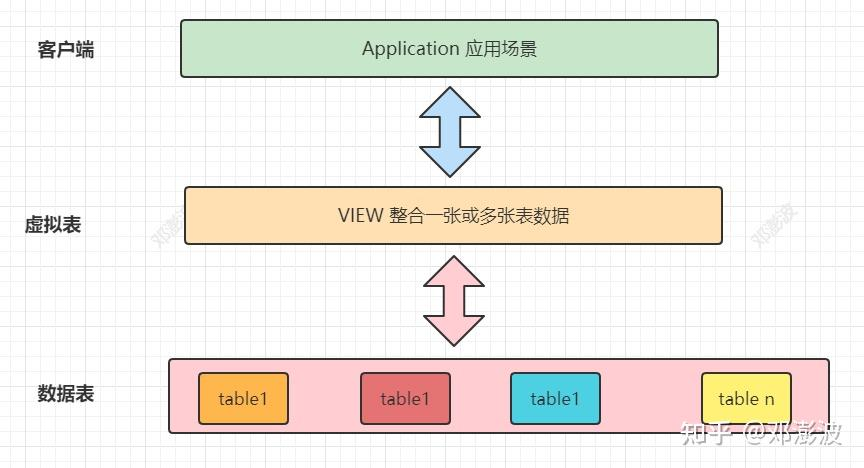
本质
只存查询定义(SQL逻辑),不存实际数据。
每次查视图,底层都是去执行一遍对应的 SQL 查询原表。
作用
数据安全
屏蔽敏感列(如:创建一个不含工资列的员工视图给外部查询)。
简化复杂查询
把复杂的多表连接做成视图,以后直接 SELECT FROM 视图。
视图的更新限制
当视图中的数据发生变化时,数据表中的数据也会发生变化,反之亦然。
并非所有视图都能执行 INSERT/UPDATE/DELETE。
以下视图不可更新(只能查,不能改):
- 包含聚合函数(如 SUM, COUNT)或 GROUP BY 的视图。
- 包含 DISTINCT 的视图。
- 包含多表连接(JOIN)的视图。
视图列
由表达式或常量计算得出的(如 SELECT age2 FROM ...)。
WHERE 子句中引用了被查表的列(如 WHERE id IN (SELECT id FROM 本表))。
5. 数据控制 (DCL):GRANT, REVOKE
|------------|----------|------------------------------------|
| 命令 | 核心功能 | 简要说明 |
| GRANT | 授予权限 | 将特定的权限(如 SELECT, INSERT)授予某个用户或角色。 |
| REVOKE | 撤销权限 | 取消之前授予某个用户或角色的权限。 |
授权
语法
GRANT 权限(如 SELECT, UPDATE) ON 对象(如表名/视图名) TO 用户 WITH GRANT OPTION;
重点
带 WITH GRANT OPTION 表示该用户不仅拥有了权限,还获得了"转授权"的资格,可以把这个权限再发给其他用户。
收权
语法
REVOKE 权限 ON 对象 FROM 用户;
级联收回
如果用户 A 把权限发给了 B(带了选项),A 又发给了 C。
此时 DBA 撤销 A 的权限,必须使用 CASCADE 关键字,这会导致 B 和 C 的权限也被连锁收回。
收回权限默认只收直接发给你的,带上 CASCADE 才能"拔出萝卜带出泥"。