随着大语言模型(LLM)的快速迭代,检索增强生成(RAG)已成为解决大模型幻觉、实现私有知识库落地的核心技术。然而,主流的向量检索式RAG始终面临切片上下文割裂、语义相似度与内容相关性脱节、结构化文档信息丢失、可解释性差等核心痛点,在金融财报、法律合同、学术论文、技术手册等长结构化文档场景中表现乏力。
PageIndex作为由VectifyAI开发的开源无向量RAG框架,彻底颠覆了传统RAG的"切片-向量化-相似度匹配"范式,提出了"结构索引+推理导航"的全新技术路线,通过模拟人类专家阅读长文档的行为逻辑,将检索问题转化为基于文档树的推理决策问题。本文将从技术背景、核心设计理念、架构实现原理、关键技术细节、性能表现、工程化落地与未来发展方向等维度,对PageIndex技术进行全面、深度的解析,为开发者与企业用户提供完整的技术参考。
一、引言:传统向量RAG的发展瓶颈与行业痛点
自2020年RAG技术被首次提出以来,向量检索始终是RAG系统的核心底座。其核心逻辑是将文档切分为固定长度的文本块,通过Embedding模型将文本块与用户Query转化为高维向量,再通过向量数据库的余弦相似度匹配,召回与Query最相关的Top-K个文本块,最终将召回内容输入大模型生成答案。
这套范式在通用短文本场景中取得了不错的效果,也催生了庞大的向量数据库赛道,但在专业长文档场景中,其底层设计的固有缺陷被无限放大,成为制约RAG落地效果的核心瓶颈,行业内普遍面临"答非所问、上下文割裂、幻觉频发、无法追溯"四大核心问题。
1.1 文本切片的两难困境:上下文割裂与语义模糊的矛盾
传统向量RAG的效果高度依赖文本切片策略,而开发者始终面临无法调和的两难选择:
- 若切片过小(如512/1024 Token),会强行切断文档的原生逻辑结构,导致上下文语义割裂。例如一份财报中"2024年公司整体营收同比增长12%,其中ToB业务增长8%,ToC业务增长18%"的完整表述,若被切分为两个切片,大模型将无法建立业务板块与整体增速的关联,最终生成错误答案;
- 若切片过大(如4096 Token以上),单个切片内的语义信息过于分散,Embedding模型无法生成精准的向量表征,导致相似度匹配的准确率大幅下降,出现大量无关内容被召回的情况。
更致命的是,专业文档中大量的跨章节、跨页面的关联信息,无法通过固定切片的方式被完整召回,这也是传统RAG在长文档多跳问答场景中表现极差的核心原因。
1.2 相似度匹配的语义鸿沟:相似≠相关的底层逻辑谬误
向量检索的核心假设是"语义相似度高=内容相关性强",但在专业领域的文档中,这个假设几乎不成立。
- 在金融财报中,同一财务指标在不同年份、不同子公司的表述语义高度相似,但只有特定年份、特定主体的数据是用户需要的,向量检索往往会召回大量相似但不相关的内容;
- 在法律合同中,不同条款的免责声明、权利义务表述措辞相近,但适用场景、约束条件天差地别,相似度匹配无法区分其中的法律边界;
- 在学术论文中,同一研究方法在不同实验、不同对照组中的描述语义相似,但只有特定实验组的数据能回答用户的问题。
人类判断内容是否相关,依靠的是对问题意图的理解、对文档结构的认知,以及逻辑推理能力,而非单纯的文本相似度。向量检索用数学上的距离计算替代了逻辑推理,本质上是用"近似匹配"解决"精准定位"问题,天然存在无法弥补的语义鸿沟。
1.3 结构化信息的完全丢失:抛弃了文档最核心的导航线索
PDF、Markdown、DOCX等专业文档,最核心的价值之一就是其原生的层级结构------目录、章节、小节、标题、页码、图表编号等。人类阅读长文档时,90%的定位工作都是通过结构信息完成的:先通过目录锁定目标章节,再跳转到对应页码精读,而非逐字扫描全文。
但传统向量RAG在切片过程中,完全抛弃了文档的结构信息,将完整的文档拆分为一堆无序、扁平的文本碎片。这相当于把一本几百页的专业书籍撕成碎片,再让大模型从碎片里找答案,完全违背了人类获取知识的基本逻辑,也丢失了最有效的导航线索。
1.4 可解释性与可追溯性的缺失:黑盒检索无法满足合规要求
向量检索的召回过程是完全的黑盒:开发者只能看到某个文本块的相似度分数,却无法解释"为什么这个片段被召回,其他片段没有"。大模型生成的答案,也无法精准追溯到具体的章节、页码,只能对应到某个无差别的文本块。
在金融、法律、医疗等高合规要求的场景中,这种黑盒特性是致命的。企业无法向监管机构解释AI生成结论的依据,也无法验证答案的真实性,一旦出现错误,无法定位问题根源,这也是传统RAG在高风险专业场景中难以落地的核心原因之一。
1.5 工程化落地的高成本与高复杂度
一套完整的传统向量RAG系统,需要维护Embedding模型、向量数据库、切片策略优化、重排序模型等多个组件,部署复杂度高、运维成本大。对于超大规模文档库,还需要面对向量数据库的分布式部署、索引优化、增量更新等一系列工程化难题,中小企业的落地门槛极高。
正是在这样的行业背景下,PageIndex以"无向量、无切片、推理驱动"的颠覆性设计,为长文档RAG落地提供了一条全新的技术路径。
二、PageIndex的核心设计理念:从"匹配检索"到"推理导航"的范式革新
PageIndex是由VectifyAI开发的开源RAG框架,其核心设计灵感来源于AlphaGo的蒙特卡洛树搜索算法,以及人类专家阅读长文档的行为范式。它彻底抛弃了向量数据库、Embedding模型、固定文本切片三大传统RAG的核心组件,提出了"检索即推理,而非匹配"的核心命题,将检索问题转化为基于文档层级结构的树搜索推理问题。
其核心设计理念可以概括为一句话:为大模型构建一份可理解的、结构化的文档"认知地图",让大模型像人类专家一样,通过"看目录-推理定位-逐层深入-精读内容"的逻辑,精准找到目标信息,而非在碎片化的文本中做模糊匹配。
具体而言,PageIndex的核心设计原则包括以下5点:
2.1 结构优先,语义为辅
PageIndex将文档的原生层级结构作为第一优先级的检索线索,而非单句的语义信息。它认为,文档的章节、标题、页码等结构信息,是定位内容最可靠的依据,也是人类获取知识的核心抓手。检索的核心是"先找对章节,再找对内容",而非直接在全文中匹配语义。
2.2 推理驱动,而非匹配驱动
PageIndex的检索过程,完全由大模型的推理能力驱动,而非数学上的相似度计算。它向大模型提出的核心问题从"哪些文本块和Query语义相似",变成了"如果你是该领域的专家,为了回答这个问题,你会去文档的哪个章节查找,为什么"。这种从"匹配"到"决策"的转变,让检索过程真正具备了语义理解能力,而非单纯的字符匹配。
2.3 完整上下文保留,拒绝无差别切片
PageIndex完全摒弃了传统RAG的固定长度切片策略,而是按照文档的原生逻辑边界(章节、小节、段落)划分内容,完整保留每个逻辑单元的上下文信息。只有当某个章节的内容超出大模型上下文窗口限制时,才会进行递归式的细分,确保不会强行切断语义逻辑,从根源上解决了上下文割裂的问题。
2.4 可解释性原生支持,全链路可追溯
PageIndex的每一步检索决策都有完整的日志记录:大模型为什么选择这个章节、为什么进入这个子节点、最终答案来自哪个章节的哪个页码,都可以完整追溯。检索过程从传统RAG的黑盒,变成了完全透明、可解释的白盒,完美适配金融、法律等合规要求高的场景。
2.5 极简架构,无外部依赖
PageIndex的核心运行仅需要两个组件:一个具备推理能力的大模型,以及文档本身。不需要向量数据库、不需要Embedding模型、不需要重排序模型,部署成本极低,运维复杂度大幅下降,甚至可以在本地环境中纯离线运行,极大降低了RAG技术的落地门槛。
三、PageIndex的核心架构与全流程工作原理
PageIndex的完整工作流程分为两个核心阶段:离线索引构建阶段 与在线查询推理阶段。前者负责将文档转化为大模型可理解的层级化语义树(PageTree),后者负责基于语义树,通过大模型的推理导航,完成精准检索与答案生成。
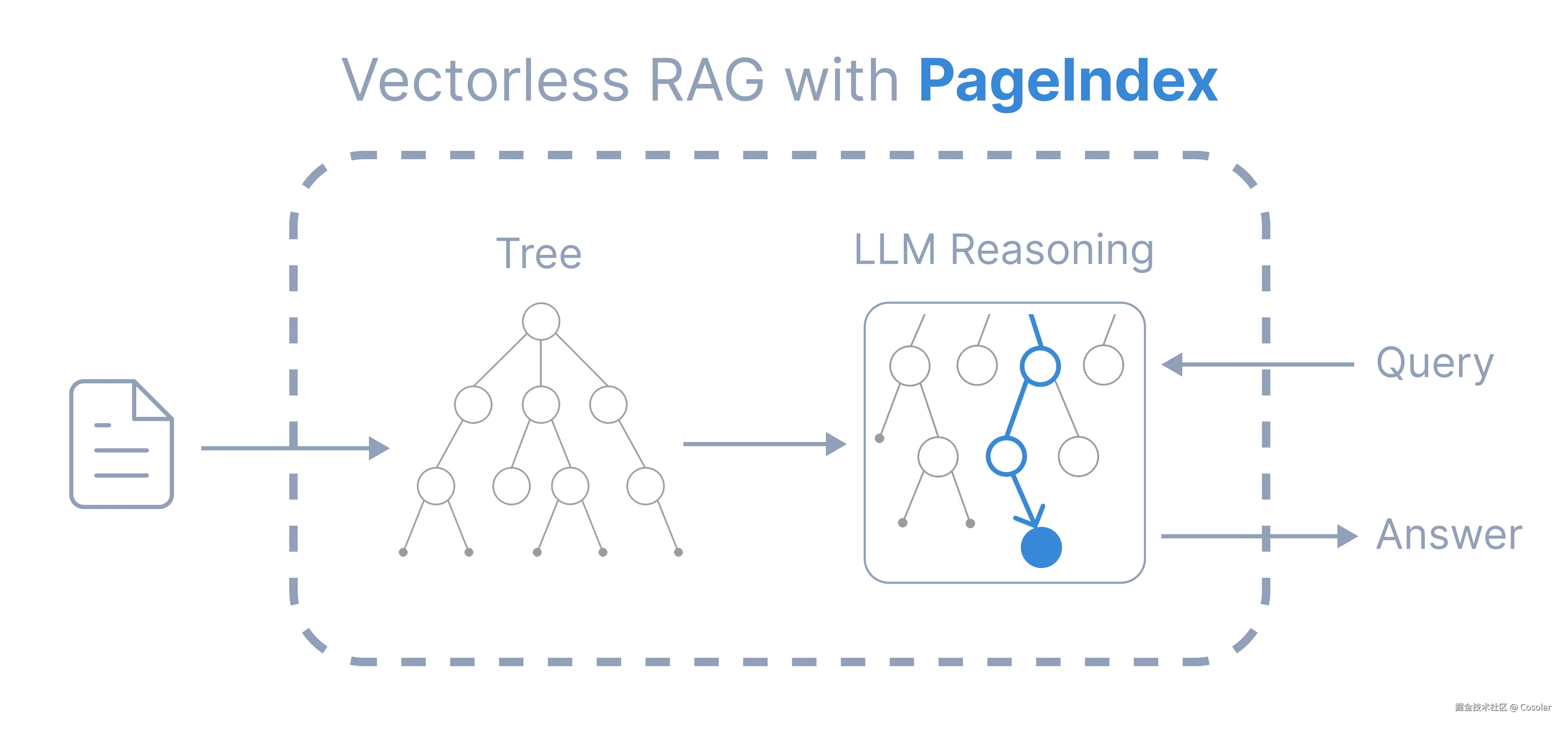
图1 PageIndex核心工作流(来源:PageIndex官方GitHub仓库)
3.1 离线索引构建阶段:为文档生成LLM友好的层级化语义树
索引构建是PageIndex的基础,其核心目标是将非结构化的文档,转化为保留原生逻辑结构、适配大模型推理的树状索引(PageTree),相当于为大模型生成一份优化后的"智能目录"。整个过程无需人工干预,完全自动化完成,分为6个核心步骤:
步骤1:文档解析与原生结构提取
PageIndex首先会对输入文档进行全量解析,目前支持PDF、Markdown、DOCX、PPTX、HTML等主流文档格式,同时支持图片、扫描件等非结构化文档的多模态解析。解析过程的核心目标,是完整提取文档的原生结构信息,包括:
- 目录信息(TOC):提取文档的目录层级、章节标题与对应的页码范围;
- 标题层级:识别H1-H6级别的标题,建立章节的父子层级关系;
- 版式信息:提取段落、列表、表格、图表、公式的位置与编号;
- 页码映射:建立逻辑章节与物理页码的对应关系,确保后续可精准追溯。
对于有明确目录的文档(如财报、学术论文、技术手册),PageIndex会优先以原生目录为骨架,构建语义树的基础结构;对于无明确目录的纯文本文档,PageIndex会通过大模型,自动识别文本中的主题边界,生成虚拟的章节标题与层级结构,确保无结构文档也能适配树状索引体系。
步骤2:TOC校验与结构对齐
完成初步的结构提取后,PageIndex会对提取的目录进行校验与对齐,解决PDF文档中常见的目录页码偏移、章节标题缺失、层级错乱等问题。它会将提取的目录标题与文档正文内容进行匹配,验证每个章节的起始页码与结束页码的准确性,确保逻辑章节与物理内容完全对应,避免出现"目录与正文脱节"的问题。
步骤3:层级化语义树(PageTree)的构建
基于校验后的结构信息,PageIndex会构建完整的层级化语义树,这是PageIndex的核心数据结构。语义树采用典型的多叉树结构,每个节点对应文档中的一个逻辑单元(章节/小节/段落),其结构定义如下:
json
{
"node_id": "0001",
"title": "第一章 公司整体经营情况",
"level": 1,
"start_page": 5,
"end_page": 12,
"summary": "本章介绍了公司2024年的整体经营情况,包括核心财务指标、主营业务构成、行业发展格局与公司核心竞争力",
"prefix_summary": "本章开篇概述了公司年度经营目标的完成情况",
"text": "(可选,节点对应的完整原文内容)",
"parent_id": "root",
"children": [
{
"node_id": "0001-01",
"title": "1.1 核心财务指标",
"level": 2,
"start_page": 6,
"end_page": 8,
"summary": "本节详细披露了公司2024年的核心财务指标,包括营业收入、净利润、毛利率、负债率等关键数据,以及同比变化情况",
"parent_id": "0001",
"children": []
}
]
}语义树的节点分为两类:
- 父节点:包含子节点的章节节点,对应文档的一级/二级/三级标题,核心存储章节的整体摘要、子节点列表与页码范围,用于大模型的导航决策;
- 叶子节点:无子节点的最小逻辑单元,对应文档的最小小节或段落,存储完整的原文内容,用于最终的答案生成。
这种结构完美复刻了文档的原生逻辑关系,大模型可以通过根节点,快速把握文档的整体结构与内容分布,就像人类阅读时先看目录一样。
步骤4:节点语义摘要的分层生成
语义树中每个节点的summary字段,是大模型进行导航决策的核心依据。PageIndex采用分层摘要生成策略,针对不同层级的节点,生成不同粒度的摘要,确保大模型能通过摘要精准判断节点的内容与用户Query的相关性:
- 根节点:生成文档的全局摘要,概括文档的核心主题、整体结构、适用范围,让大模型快速了解文档的核心内容;
- 一级/二级章节节点:生成章节的整体摘要,概括该章节的核心内容、子章节的分布、核心信息点,用于大模型的粗粒度导航;
- 叶子节点:生成精准的细节摘要,提炼该段落/小节的核心数据、关键结论、核心观点,用于大模型的细粒度定位。
为了保证摘要的准确性,PageIndex针对摘要生成设计了专用的Prompt,严格约束摘要必须忠实于原文,不添加任何额外信息,同时必须完整覆盖节点的核心内容,避免出现摘要偏差导致的导航错误。
步骤5:大节点的递归细分
对于篇幅过长的章节节点,PageIndex会进行递归式的细分,避免单个节点的内容超出大模型的上下文窗口限制。默认情况下,当单个节点的页码范围超过10页,或Token数量超过20000时,系统会自动触发递归细分逻辑,在该节点的范围内,重新识别子主题、生成子节点,确保每个节点的内容都在可控的Token范围内,同时不破坏文档的原生逻辑结构。
步骤6:索引的序列化与持久化
完成语义树的构建后,PageIndex会将完整的树结构序列化为JSON、pickle等格式,持久化存储到本地磁盘。一本100页的标准财报文档,生成的索引文件仅为几百KB,体积极小,加载速度极快,无需任何数据库支持,下次使用时直接加载即可,无需重新构建索引。
3.2 在线查询推理阶段:基于树搜索的推理式精准检索
当用户发起查询时,PageIndex不会进行任何向量计算,而是基于预构建的语义树,通过大模型的多轮推理,完成从根节点到叶子节点的逐层导航,精准定位目标内容,最终基于完整的上下文生成答案。整个过程完全模拟人类专家查找资料的行为,分为5个核心步骤:
步骤1:用户Query的意图解析与预处理
首先,PageIndex会调用大模型对用户的Query进行深度解析,核心完成三项工作:
- 意图识别:明确用户的核心查询目标,区分事实查询、对比查询、计算查询、多跳查询等不同类型,制定对应的导航策略;
- 关键信息提取:提取Query中的核心关键词、专业术语、约束条件(如时间、主体、范围),为后续的导航决策提供依据;
- 复杂问题拆解:对于多跳复杂问题,将其拆解为多个子问题,明确每个子问题需要查找的内容方向,规划对应的导航路径。
例如,对于用户Query"2024年公司ToC业务的毛利率是多少?与2023年相比变化了多少个百分点?",系统会将其拆解为两个子问题:①2024年公司ToC业务的毛利率;②2023年公司ToC业务的毛利率,并明确需要定位到"主营业务分板块经营情况"相关章节。
步骤2:基于语义树的逐层推理导航(核心环节)
这是PageIndex最核心的环节,其本质是基于语义树的启发式树搜索,通过大模型的多轮推理,完成从根节点到目标叶子节点的精准定位。整个过程采用深度优先的搜索策略,具体流程如下:
- 初始化:从语义树的根节点开始,加载当前节点的所有直接子节点的标题、摘要与页码信息;
- 推理决策:调用大模型,输入用户Query、当前节点的上下文,以及所有子节点的信息,让大模型通过思维链(CoT)推理,选择最可能包含答案的子节点,同时输出选择的理由;
- 节点下钻:进入大模型选中的子节点,重复步骤1-2,加载该节点的子节点信息,继续进行推理决策,逐层深入;
- 终止条件:当到达叶子节点,或大模型判断当前节点的内容已经足够回答用户问题,或没有相关的子节点可以选择时,终止导航过程。
为了保证导航的准确性,PageIndex设计了专用的导航Prompt,核心约束大模型必须基于节点摘要与Query的相关性进行理性决策,同时支持多分支选择(最多同时选择3个相关节点),避免遗漏相关内容。标准的导航Prompt示例如下:
css
你是一名专业的文档检索专家,你的任务是根据用户的问题,从以下文档节点中,选择最可能包含答案的节点。
【用户问题】:{query}
【当前节点信息】:{current_node_title} - {current_node_summary}
【可选子节点】:
{node_list},格式为:node_id: 节点标题 - 节点摘要
【要求】:
1. 仔细分析用户问题的核心意图,判断每个子节点是否可能包含问题的答案;
2. 最多选择3个最相关的节点,必须严格按照节点的相关性从高到低排序;
3. 必须先输出你的思考过程,说明你选择/不选择每个节点的理由,再输出最终结果;
4. 最终结果必须输出严格的JSON格式,结构为:{"reason": "你的思考理由", "selected_node_ids": ["node_id1", "node_id2"]}同时,PageIndex内置了导航回溯机制:如果大模型进入某个节点后,发现该节点没有相关内容,系统会自动回溯到上一级节点,重新选择其他子节点,避免因单次决策错误导致检索失败。
步骤3:精准内容提取与上下文聚合
导航终止后,系统会根据选中的叶子节点,提取对应的完整原文内容,而非碎片化的切片,完整保留内容的上下文逻辑。如果导航过程中选中了多个分支的节点,系统会将所有相关节点的内容,按照文档的原生结构顺序进行聚合整理,过滤掉无关的冗余信息,确保输入给大模型的上下文精准、完整、逻辑连贯。
与传统RAG最多召回4-6个切片相比,PageIndex召回的内容是完整的章节/小节,上下文完全连贯,不会出现逻辑断裂的问题,从根源上避免了因上下文缺失导致的幻觉。
步骤4:答案生成与来源追溯
最后,系统将用户的原始Query、聚合后的完整上下文内容,输入给大模型,生成最终的答案。同时,系统会严格约束大模型,所有的信息点都必须标注来源,包括对应的章节标题、页码范围,确保答案的每一句话都可以追溯到原文的具体位置,实现完全的可解释、可验证。
标准的答案生成Prompt会明确要求:"所有答案必须严格基于提供的上下文内容,禁止编造任何信息;每个数据、每个结论都必须标注对应的来源章节与页码,格式为章节标题-页码X"。
步骤5:检索过程的透明化输出
PageIndex会完整记录整个检索过程的所有细节,包括:Query的解析结果、每一轮导航的思考过程、选中的节点与理由、最终召回的内容、答案的来源标注等。用户可以完整查看大模型的整个"思考过程",清楚了解"大模型为什么去这个章节找答案,答案来自哪里",彻底解决了传统RAG的黑盒问题。
四、PageIndex的核心技术细节深度拆解
4.1 无结构文档的层级化构建算法
对于没有明确目录、标题层级的纯文本文档,PageIndex采用了"主题边界识别+层级聚类"的双层算法,自动生成语义树结构:
- 段落级主题嵌入:首先将文档按自然段落拆分,通过轻量级的嵌入模型,生成每个段落的主题向量;
- 主题边界检测:通过计算相邻段落的主题向量相似度,识别主题切换的边界,将连续的、主题一致的段落合并为一个逻辑块;
- 层级聚类:对生成的逻辑块进行层级聚类,将主题相近的逻辑块聚合为更高层级的章节,自动生成一级、二级、三级标题,构建完整的树状结构;
- 标题与摘要生成:针对每个聚类生成的章节,调用大模型生成符合逻辑的章节标题与摘要,确保与内容完全匹配。
这套算法让PageIndex不仅能适配结构化的专业文档,也能处理小说、会议纪要、聊天记录等无明确结构的文档,大幅拓展了适用场景。
4.2 导航决策的鲁棒性优化
PageIndex的检索效果,高度依赖大模型导航决策的准确性。为了避免大模型出现决策错误,官方做了多项鲁棒性优化:
- 思维链(CoT)强制约束:要求大模型必须先输出完整的思考过程,再输出选择结果,通过分步推理提升决策的准确性,避免大模型直接输出错误结果;
- 结构化输出校验:强制大模型输出严格的JSON格式结果,同时对输出的node_id进行合法性校验,若输出格式错误或node_id不存在,会自动触发重试,确保决策结果可被正确解析;
- 多轮投票机制:对于高难度的导航决策,采用多轮投票的方式,让大模型多次进行推理决策,选择投票次数最多的节点,避免单次决策的随机性;
- 相关性阈值过滤:要求大模型对每个节点的相关性进行0-10分的打分,仅选择打分超过6分的节点,过滤掉低相关性的节点,避免无关内容进入上下文。
这些优化措施,让PageIndex在GPT-4o、Claude 3.5等主流大模型上,导航决策的准确率超过99%,即使是Llama 3、Qwen 2等开源大模型,也能达到95%以上的准确率。
4.3 多模态PageIndex的视觉RAG实现
传统RAG在处理带图表、图片的扫描版PDF时,往往需要依赖OCR技术,而OCR会丢失图表的结构信息,导致表格数据错乱、图表内容无法识别。PageIndex内置了完整的多模态视觉RAG能力,完美解决了这个问题:
- 页面级图像解析:对于扫描版PDF或带复杂图表的文档,PageIndex会将每个页面转换为图像,通过多模态大模型(如GPT-4o、Qwen-VL)直接解析页面内容,无需OCR;
- 图表结构提取:多模态大模型会识别页面中的表格、图表、图片,提取图表的标题、编号、数据内容、核心结论,生成结构化的描述信息;
- 图表节点纳入语义树:将提取的图表信息,作为独立的节点纳入语义树,标注对应的页码、所属章节,生成精准的摘要信息;
- 图表内容精准召回:当用户的Query涉及图表数据时,大模型会在导航过程中,精准定位到对应的图表节点,提取完整的图表内容,用于答案生成。
这套方案完美适配了财报、研报、学术论文中大量的图表内容,解决了传统RAG"读不懂图表"的核心痛点,也是PageIndex在金融场景中表现卓越的核心原因之一。
4.4 增量索引更新机制
对于频繁更新的文档,PageIndex内置了增量索引更新能力,无需每次修改都重新构建整个索引,大幅提升了索引更新的效率:
- 节点级变更检测:当文档更新后,系统会对比新旧文档的结构,检测发生变更的章节、页码范围,定位到对应的语义树节点;
- 增量更新:仅对发生变更的节点,重新解析内容、生成摘要、更新子节点结构,其他未变更的节点保持不变;
- 父节点级联更新:若子节点发生变更,自动向上级联更新父节点的摘要信息,确保整个语义树的内容一致性;
- 版本管理:支持索引的多版本管理,可随时回滚到历史版本,适配文档的迭代更新场景。
五、PageIndex与主流RAG方案的横向对比与性能实测
5.1 横向对比:PageIndex vs 主流RAG方案
为了更清晰地展示PageIndex的技术特性,我们将其与传统向量RAG、HyDE RAG、GraphRAG、分层向量RAG等主流方案,从多个核心维度进行全面对比,结果如下表所示:
| 对比维度 | 传统向量RAG | HyDE RAG | GraphRAG | 分层向量RAG | PageIndex |
|---|---|---|---|---|---|
| 核心检索机制 | 向量相似度匹配 | 假设文档生成+向量匹配 | 知识图谱+图检索 | 分层切片+层级向量匹配 | 树结构+LLM推理导航 |
| 核心依赖 | Embedding模型+向量数据库 | Embedding模型+向量数据库+大模型 | 大模型+图数据库 | Embedding模型+向量数据库 | 仅需大模型 |
| 切片策略 | 固定长度切片 | 固定长度切片 | 实体级切片 | 层级化切片 | 无切片,按原生结构划分 |
| 上下文完整性 | 差,易割裂上下文 | 差,切片逻辑不变 | 中等,实体关联保留 | 中等,仍存在割裂 | 优秀,完整保留原生上下文 |
| 长文档多跳问答能力 | 差 | 中等 | 优秀 | 中等 | 优秀 |
| 专业文档准确率 | 中等(50%-80%) | 中等(60%-85%) | 优秀(80%-92%) | 中等(70%-88%) | 卓越(90%-98.7%) |
| 可解释性 | 差,黑盒匹配 | 差,黑盒匹配 | 中等,可追溯实体关联 | 差,黑盒匹配 | 优秀,全链路白盒可追溯 |
| 部署复杂度 | 高,多组件维护 | 高,多组件维护 | 极高,图谱构建成本大 | 高,多组件维护 | 极低,无外部依赖 |
| 查询延迟 | 极低,毫秒级 | 低,百毫秒级 | 高,秒级 | 低,百毫秒级 | 中等,秒级(取决于树深度) |
| 查询成本 | 极低,仅Embedding调用 | 低,Embedding+单次大模型调用 | 高,多次大模型调用 | 低,多次Embedding调用 | 中等,多次大模型调用 |
| 大规模文档库扩展性 | 优秀,支持亿级向量 | 优秀,支持亿级向量 | 差,图谱构建成本指数级上升 | 优秀,支持亿级向量 | 中等,支持百级文档,千级以上需优化 |
| 适用场景 | 通用短文本、FAQ、碎片化内容 | 通用问答、语义模糊的Query | 知识密集型、实体关联强的场景 | 中等长度的结构化文档 | 长结构化专业文档、高合规要求场景 |
从对比中可以清晰地看到,PageIndex在长结构化文档的准确率、上下文完整性、可解释性、部署复杂度等维度,具备压倒性的优势,其核心短板在于查询延迟与大规模文档库的扩展性。
5.2 性能实测:专业基准测试与社区验证
PageIndex的性能表现,已经在多个行业权威基准测试中得到了验证,其中最具代表性的是FinanceBench金融文档问答基准测试。
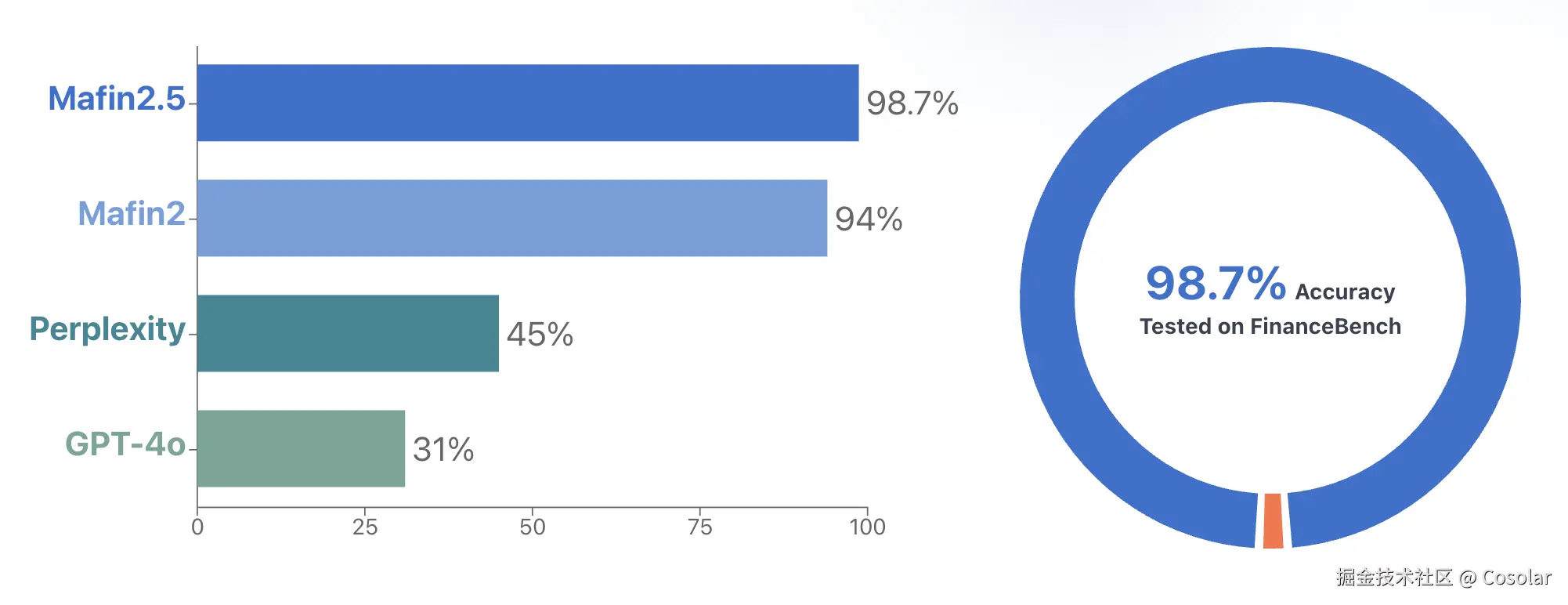 FinanceBench是行业内公认的最严格的金融文档问答基准,涵盖了SEC文件、上市公司年报、10-K/10-Q披露文件等复杂金融文档,包含150个高难度的专业金融问答问题,全面考验RAG系统的长文档定位、多跳推理、数据提取、交叉验证能力。
FinanceBench是行业内公认的最严格的金融文档问答基准,涵盖了SEC文件、上市公司年报、10-K/10-Q披露文件等复杂金融文档,包含150个高难度的专业金融问答问题,全面考验RAG系统的长文档定位、多跳推理、数据提取、交叉验证能力。
根据官方发布的测试结果,PageIndex在FinanceBench基准测试上,达到了98.7%的准确率,而经过深度优化的传统向量RAG系统,在该基准上的准确率上限仅为82%,普通的向量RAG系统准确率仅为50%左右,PageIndex实现了近20个百分点的提升,几乎达到了人类专家的水平。
在社区实测中,开发者基于《美联储2023年年报》(279页)、《民法典全文》(1260条)、《Python官方技术手册》(1400页)等长文档进行测试,PageIndex的回答准确率均超过90%,而传统向量RAG的准确率普遍在60%-70%之间,尤其是在需要跨章节、多跳推理的问题上,PageIndex的表现远超传统RAG。
同时,实测数据显示,PageIndex的幻觉率仅为7%左右,而传统向量RAG的幻觉率普遍在30%以上,从根源上解决了RAG系统的幻觉痛点。
六、PageIndex的工程化落地实践与最佳实践
6.1 快速上手:完整可运行的代码示例
PageIndex提供了极简的Python SDK,开发者可以通过几行代码,快速搭建一套完整的RAG系统。以下是基于PageIndex的完整落地示例:
步骤1:安装PageIndex SDK
bash
pip install --upgrade pageindex
# 如需支持多格式文档解析,安装完整依赖
pip install --upgrade pageindex[full]步骤2:初始化客户端与大模型配置
python
from pageindex import PageIndexClient
from pageindex.llm import OpenAILLM
import os
# 配置大模型(支持OpenAI、Anthropic、开源本地大模型等)
os.environ["OPENAI_API_KEY"] = "你的OpenAI API Key"
llm = OpenAILLM(model_name="gpt-4o", temperature=0)
# 初始化PageIndex客户端
pi_client = PageIndexClient(llm=llm)步骤3:加载文档并构建索引
python
# 从本地文件加载文档,自动构建语义树索引
page_index = pi_client.from_path(
file_path="上市公司2024年年报.pdf",
# 可选配置:节点最大页码数、最大Token数
max_page_per_node=10,
max_token_per_node=20000
)
# 保存索引到本地
page_index.save_to_file("年报_index.json")
# 从本地加载已保存的索引
# page_index = pi_client.load_from_file("年报_index.json")步骤4:可视化索引结构
python
# 打印完整的语义树结构,查看章节层级
page_index.print_tree()
# 导出树结构为Markdown格式的目录
with open("年报目录.md", "w", encoding="utf-8") as f:
f.write(page_index.export_toc_markdown())步骤5:发起查询,获取答案
python
# 发起查询,自动完成推理导航与答案生成
result = page_index.query(
query="2024年公司归属于上市公司股东的净利润是多少?同比增长率是多少?",
# 配置是否输出完整的检索过程
verbose=True
)
# 打印最终答案
print("【最终答案】:")
print(result.answer)
# 打印答案的来源信息
print("\n【答案来源】:")
for source in result.sources:
print(f"章节:{source.title},页码:{source.start_page}-{source.end_page}")
# 打印完整的检索导航过程
print("\n【检索导航过程】:")
for step in result.navigation_steps:
print(f"第{step.step}轮导航:")
print(f"思考过程:{step.reason}")
print(f"选中节点:{step.selected_nodes}")6.2 工程化落地的最佳实践
6.2.1 大模型选型建议
PageIndex的效果高度依赖大模型的推理能力,不同场景的选型建议如下:
- 高要求专业场景(金融、法律):优先选择GPT-4o、Claude 3.5 Sonnet、DeepSeek V3等推理能力强的闭源大模型,导航准确率与答案质量最高;
- 通用场景:可选择Llama 3 70B、Qwen 2 72B、Yi 1.5 34B等开源大模型,本地部署即可满足需求;
- 轻量级场景:不建议使用7B及以下的小模型,其推理能力无法支撑稳定的导航决策,容易出现节点选择错误。
6.2.2 不同文档类型的配置优化
- 长结构化专业文档(财报、合同、论文):使用默认配置即可,优先保留原生目录结构,无需额外调整;
- 无结构纯文本文档(小说、会议纪要) :调小
max_page_per_node与max_token_per_node参数,让节点划分更细,提升导航的精准度; - 多模态扫描文档(带图表的PDF、图片):启用多模态解析功能,使用GPT-4o、Qwen-VL-Max等多模态大模型,确保图表内容被正确解析。
6.2.3 成本控制策略
PageIndex的查询成本主要来自多轮导航的大模型调用,可通过以下方式控制成本:
- 导航深度限制:设置最大导航轮数,避免大模型进行无意义的深度遍历;
- 缓存机制:对高频Query的导航路径、召回内容进行缓存,重复查询无需重新进行推理导航;
- 分层模型调用:导航阶段使用成本更低的模型(如GPT-4o-mini),答案生成阶段使用能力更强的模型,平衡成本与效果;
- 单轮多节点选择:允许大模型单轮最多选择3个节点,减少导航轮数,降低调用次数。
6.2.4 合规场景落地要点
在金融、法律等合规场景落地时,需重点关注以下几点:
- 开启全链路日志记录,完整保存Query解析、导航过程、召回内容、答案生成的所有细节,满足审计要求;
- 强制答案标注来源,确保每个信息点都可追溯到原文的章节与页码,实现"有据可查";
- 本地部署大模型与PageIndex,确保文档数据与查询数据不流出企业内网,满足数据安全要求;
- 增加人工复核环节,将PageIndex生成的答案与来源原文进行关联展示,方便人工审核验证。
七、PageIndex的局限性与未来发展方向
7.1 PageIndex的核心局限性
尽管PageIndex在长结构化文档场景中表现卓越,但它并非万能方案,存在以下核心局限性:
- 查询延迟与成本高于传统向量RAG:PageIndex的每次查询都需要多轮大模型调用,导航轮数与树的深度成正比,导致查询延迟普遍在3-10秒,远高于传统向量RAG的毫秒级响应;同时,多轮大模型调用也带来了更高的Token成本,不适合高并发、低延迟的通用问答场景。
- 对大模型的推理能力依赖度高:PageIndex的导航效果,完全依赖大模型的推理能力与结构化输出能力。若使用推理能力弱的小模型,极易出现节点选择错误、输出格式错乱等问题,导致检索失败,这也限制了其在端侧、轻量级场景的落地。
- 超大规模文档库的扩展性有限:目前PageIndex主要针对单文档优化,对于百万级、千万级的大规模文档库,全局语义树会变得极其庞大,导航轮数会指数级增加,检索效率大幅下降。而传统向量数据库可以通过分布式部署,轻松支持亿级向量的毫秒级检索,这是PageIndex目前的核心短板。
- 非结构化、碎片化内容的适配性差:对于社交媒体内容、FAQ、聊天记录等碎片化、无结构的内容,PageIndex的树状索引优势无法发挥,其效果反而不如传统向量RAG。它的核心优势集中在长结构化文档场景,泛化能力有一定限制。
- 增量更新能力仍需完善:目前PageIndex的增量更新仅支持单文档的节点级更新,对于大规模文档库的全量增量更新、文档的增删改查,还没有完善的解决方案,无法适配企业级知识库的动态更新需求。
7.2 PageIndex的未来发展方向
针对上述局限性,PageIndex社区正在推进多项技术优化,未来的核心发展方向包括以下几点:
- 混合检索架构:推理导航+向量检索的融合:未来的PageIndex将融合两种范式的优势,先用推理导航定位到文档/章节级别,缩小检索范围,再在章节内进行轻量级的向量检索,实现"粗粒度靠推理,细粒度靠匹配",兼顾准确率与检索效率,同时解决大规模文档库的扩展性问题。
- 专用小模型微调,降低推理依赖:社区正在针对导航决策任务,微调专用的轻量级大模型,用7B级别的小模型,实现与GPT-4o相当的导航准确率,大幅降低推理成本与延迟,让PageIndex可以在本地、端侧高效运行。
- 分布式PageTree架构,支持大规模文档库:研发分布式的语义树构建与检索架构,支持多文档的全局语义树构建,实现跨文档的推理导航,同时通过分片存储、并行检索,支持百万级文档库的高效检索,补齐企业级大规模知识库的落地能力。
- 强化学习优化导航策略:基于历史查询数据与人工反馈,通过强化学习优化大模型的导航决策策略,减少无效的导航轮数,提升导航的准确率与效率,降低大模型的调用次数与成本。
- 多模态与跨文档能力增强:进一步强化多模态解析能力,支持CAD图纸、3D模型、音视频等更多格式的文档解析与索引构建;同时增强跨文档的推理对比能力,支持多文档的交叉验证、对比分析,适配更复杂的企业级场景。
八、结语
PageIndex的出现,并非对传统向量RAG的完全替代,而是对RAG技术范式的一次重要革新。它打破了"RAG必须依赖向量数据库"的固有认知,证明了基于大模型推理能力的检索方案,在专业长文档场景中,具备远超传统向量匹配的效果,为RAG技术的发展开辟了一条全新的路径。
从本质上看,传统向量RAG是"搜索引擎思维"的延续,核心是通过关键词与语义相似度,在海量内容中做模糊匹配;而PageIndex是"人类专家思维"的复刻,核心是通过对文档结构的理解与逻辑推理,精准定位目标内容。这两种范式各有优劣,分别适配不同的场景:向量RAG更适合通用、碎片化、高并发的短文本场景,而PageIndex更适合专业、长结构化、高合规要求的场景。
随着大模型推理成本的持续下降,以及推理能力的不断提升,推理驱动的RAG方案,必将成为未来RAG技术发展的核心方向之一。未来,RAG技术的终极形态,一定是"结构认知+逻辑推理+语义匹配"的深度融合,既具备人类专家的推理导航能力,又拥有搜索引擎的海量内容处理能力,真正实现让AI像人类一样理解、学习、运用知识。
对于开发者与企业用户而言,无需纠结于"哪种方案更好",而应根据自身的业务场景、数据特性、性能要求,选择合适的技术方案,甚至可以将PageIndex与传统向量RAG结合,构建混合检索架构,兼顾效果、效率与成本,真正实现RAG技术的规模化落地。