作为编程新手,我们每天打开浏览器刷网页、用 APP 加载数据,背后都离不开HTTP 协议。
1:HTTP是什么
HTTP全称HyperText Transfer Protocol,超文本传输协议,是客户端(浏览器、APP)和服务器之间通信的统一规则。
简单来说,客户端想要获取或者提交数据,就按照HTTP格式发送请求,服务器收到请求后就处理并且返回响应。
HTTP协议是一个无连接,无状态的协议(两种核心特性)。
1:无连接
每次请求默认新建连接,请求完成后断开(HTTP/1.1优化为默认长连接)。
2:无状态
服务器不记录客户端信息,每次请求都是"新对话",需靠Cookie/Session实现登录等状态留存。
2:认识URL:我们天天用的"网址"
平时说的网址就是 URL,它的完整结构拆解后超清晰:
协议 :// 登录信息 @ 服务器地址: 端口 /文件路径?查询参数#片段
举个例子:
http://user:pass@www.example.com:80/dir/index.html?uid=1#ch1
协议:http/https(加密)
服务器地址:域名/IP
端口:http默认80,https默认443
查询参数:?后传数据给服务器
urlencode转义规则
URL中/ ? : @是特殊字符,直接用会冲突,必须转义:将字符转16进制,加%拼接,比如+转成%2B
uldecode是反向操作,把转义字符还原。
3:HTTP请求和响应:通信核心格式
HTTP通信只有请求(客户端->服务器)和响应(服务器->客户端)两种报文,格式固定,拆成4部分:
1:HTTP请求格式
请求行:请求方法 + URL + HTTP版本
请求头:Key:Value 键值对(附加信息)
空行:必须存在,分隔请求头和请求体
请求体:提交的数据(GET无,POST有)
2:HTTP响应格式
响应行:HTTP版本 + 状态码 + 状态描述
响应头:Key:Value 键值对(附加信息)
空行:必须存在,分隔响应头和响应体
响应体:返回的网页/数据(HTML、JSON等)
示例:
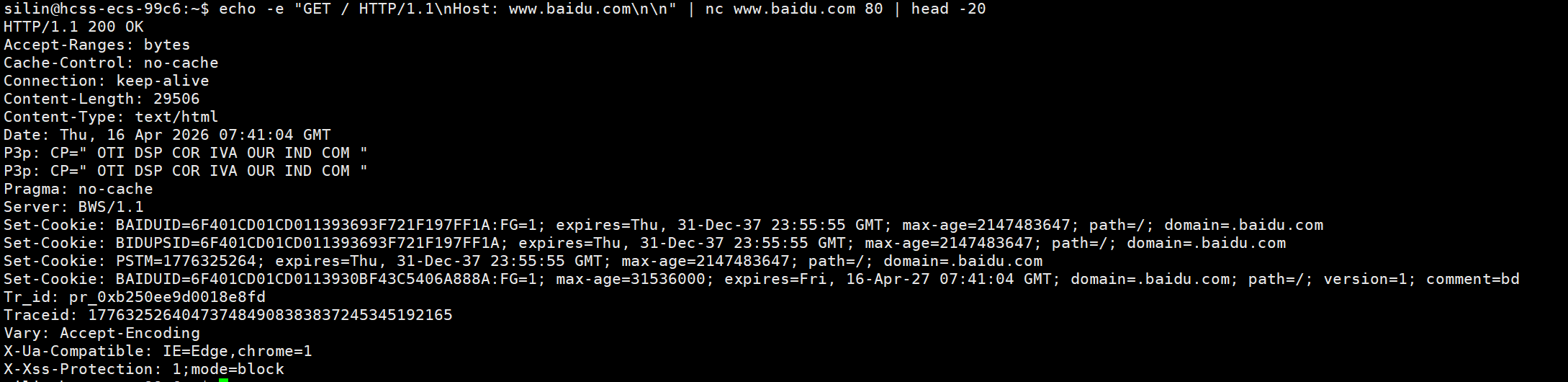
解释上述示例
命令:
1:echo -e "GET / HTTP/1.1\nHost: www.baidu.com\n\n"这是在手动构造 HTTP 请求报文:
GET / HTTP/1.1
Host: www.baidu.comGET / HTTP/1.1:请求行,说明用 GET 方法获取根路径资源,协议版本是 HTTP/1.1Host: www.baidu.com:请求头(HTTP/1.1 强制要求),告诉服务器你要访问的是哪个域名(因为一个 IP 可能挂多个网站)- 最后的
\n\n:空行,用来分隔请求头和请求体(GET 请求没有请求体,所以空行就代表请求结束) 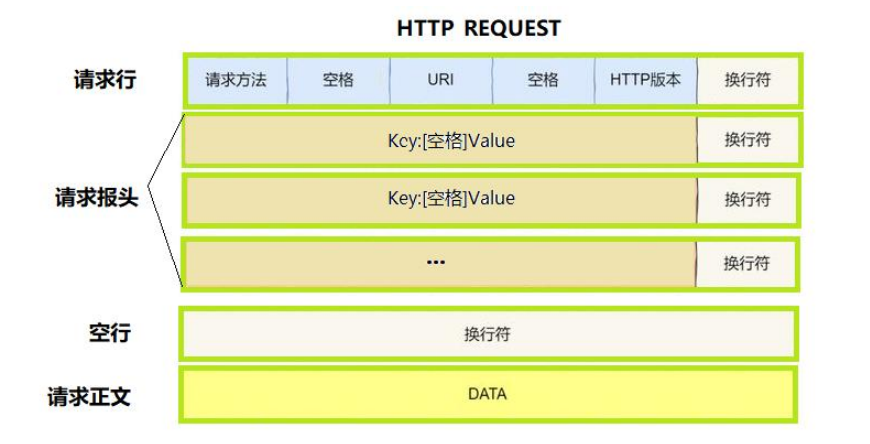
2:nc www.baidu.com 80:用netcat(网络瑞士军刀)和百度服务器的 80 端口(HTTP 默认端口)建立 TCP 连接,把前面构造的请求发过去,再接收服务器的响应
3:head -20:只取响应的前 20 行,避免被后面的 HTML 响应体刷屏,方便查看响应头
返回结果:
bash
HTTP/1.1 200 OK ← 响应行(状态码200,请求成功)
Accept-Ranges: bytes
Cache-Control: no-cache
Connection: keep-alive ← 响应头(连接保持长连接)
Content-Length: 29506 ← 响应体的长度(后面HTML的大小)
Content-Type: text/html ← 响应体的类型是网页
Date: Thu, 16 Apr 2026 07:41:04 GMT
Server: BWS/1.1 ← 服务器软件是百度自研的BWS
Set-Cookie: BAIDUID=xxx... ← 服务器给客户端设置Cookie,用来跟踪会话
...(其他响应头)4:常用的HTTP方法:客户端的"操作指令"
HTTP 定义了多种请求方法,GET 和 POST 是日常最常用:
| 方法 | 核心作用 | 特点 |
|---|---|---|
| GET | 获取资源(查) | 无请求体,参数放 URL,数据量小 |
| POST | 提交数据(增 / 改) | 有请求体,参数更安全,数据量大 |
| HEAD | 仅获取响应头 | 不返回正文,验证 URL 有效性 |
| PUT | 上传 / 更新文件 | 修改服务器资源 |
| DELETE | 删除资源 | 删除服务器文件 |
5:HTTP状态码:服务器的"反馈信号"
状态码是 3 位数字,分 5 类,一眼看懂请求结果:
- 1xx:信息类 → 请求正在处理
- 2xx:成功类 → 请求正常完成
- 3xx:重定向 → 跳转到新地址
- 4xx:客户端错误 → 网址错 / 无权限
- 5xx:服务器错误 → 服务器崩溃 / 故障
最常见状态码
- 200 OK:请求成功,正常返回数据
- 301/302:重定向(301 永久、302 临时)
- 404 Not Found:访问的网址不存在
- 403 Forbidden:没有访问权限
- 500 服务器内部错误
6:核心HTTP Header:通信的"附加信息"
Header 是键值对,用来传递请求 / 响应的额外信息,新手必记这几个:
- Host:告诉服务器要访问的主机名
- User-Agent:客户端信息(浏览器、系统版本)
- Content-Type:数据格式(表单 / JSON / 网页)
- Location:重定向目标地址(配合 3xx 状态码)
- Cookie:存储客户端状态,实现登录、记住账号
7:HTTP版本进化
HTTP 从 1991 年诞生至今,迭代 5 个版本,核心优化传输性能:
- HTTP/0.9:仅支持 GET,纯文本,无 Header
- HTTP/1.0:新增 POST/HEAD、Header、状态码
- HTTP/1.1:默认长连接、多路复用,支持多域名共享 IP
- HTTP/2:二进制帧、头部压缩、服务器推送
- HTTP/3:基于 UDP+QUIC,解决 TCP 线头阻塞问题
8:写一个HTTP服务器(简单项目级别,前后端分离)
只要按 HTTP 格式构造响应,就能写一个返回hello world的服务器。
下面是项目的连接文件
1:HttpServer.h
cpp
#ifndef HTTPSERVER_H
#define HTTPSERVER_H
#include<string>
//HTTP服务器类
class HttpServer{
private:
int port;//监听端口
int server_fd;//服务器socket文件描述符
//初始化Socket(创建,绑定,监听)
bool initSocket();
//自动获取服务器公网IP
std::string getPublicIP();
//前后端分离,读取前端html文件,构造响应
std::string readFrontEndFile();
//解析并处理客户端请求
void handleClient(int client_fd);
public:
//构造函数
HttpServer(int port);
//启动服务器
void start();
//关闭服务器
void stop();
};
#endif //HTTPSERVER_H2:HttpServer.cpp
cpp
#include "../include/HttpServer.h"
#include <iostream>
#include <fstream>
#include <sstream>
#include <cstring>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
// 缓冲区大小(读取浏览器请求)
#define BUFFER_SIZE 4096
// 构造函数,初始化端口
HttpServer::HttpServer(int port) : port(port), server_fd(-1) {}
// 获取服务器公网IP
std::string HttpServer::getPublicIP()
{
char buffer[128] = {0};
// 调用Linux命令查看公网IP
FILE *fp = popen("curl -s ifconfig.me", "r");
if (fp)
{
fgets(buffer, sizeof(buffer), fp);
pclose(fp);
}
if (strlen(buffer) == 0)
{
return "请手动查询公网IP";
}
return std::string(buffer);
}
// 1/初始化socket Tcp服务器(HTTP基于TCP)
bool HttpServer::initSocket()
{
// 1:创建socket文件描述符
server_fd = socket(AF_INET, SOCK_STREAM, 0);
if (server_fd == -1)
{
std::cerr << "Socket 创建失败" << std::endl;
return false;
}
// 2:设置端口复用(防止重启报错)
int opt = 1;
setsockopt(server_fd, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt));
// 3:绑定服务器IP和端口
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(port);
if (bind(server_fd, (struct sockaddr *)&address, sizeof(address)) < 0)
{
std::cerr << "端口绑定失败" << std::endl;
return false;
}
// 4:监听端口(最大连接数5)
if (listen(server_fd, 5) < 0)
{
std::cerr << "监听失败" << std::endl;
return false;
}
// 自动打印公网IP
std::string ip = getPublicIP();
std::cout<<"================================"<<std::endl;
std::cout << "服务器启动成功,监听窗口:" << port << std::endl;
std::cout << "你的服务器公网IP:" << ip << std::endl;
std::cout << "浏览器访问地址:http://:" << ip << ":" << port << std::endl;
std::cout<<"================================"<<std::endl;
return true;
}
// 前端处理函数
std::string HttpServer::readFrontEndFile()
{
std::ifstream file("web/index.html");
if (!file.is_open())
{
return "<h1>前端文件未找到!</h1>";
}
std::stringstream buffer;
buffer << file.rdbuf();
file.close();
return buffer.str();
}
// 处理客户端请求
void HttpServer::handleClient(int client_fd)
{
char buffer[BUFFER_SIZE] = {0};
read(client_fd, buffer, sizeof(buffer));
// 打印请求
std::cout << "\n====浏览器HTTP请求====\n"
<< buffer << "\n=====================\n";
// 1:读取独立前端页面
std::string html = readFrontEndFile();
// 2:标准HTTP响应协议
std::string response =
"HTTP/1.1 200 OK\r\n"
"Content-Type: text/html; charset=utf-8\r\n"
"Connection: close\r\n"
"\r\n" +
html;
// 发送给浏览器
write(client_fd, response.c_str(), response.size());
close(client_fd);
}
// 启动服务器
void HttpServer::start()
{
if (!initSocket())
return;
struct sockaddr_in client_addr;
socklen_t addr_len = sizeof(client_addr);
while (true)
{
int client_fd = accept(server_fd, (struct sockaddr *)&client_addr, &addr_len);
std::cout << "新链接:" << inet_ntoa(client_addr.sin_addr) << std::endl;
handleClient(client_fd);
}
}
// 关闭服务器
void HttpServer::stop()
{
if (server_fd != -1)
close(server_fd);
}3:main.cpp
cpp
#include "../include/HttpServer.h"
#define PORT 8080
int main()
{
HttpServer server(PORT);
server.start();
server.stop();
return 0;
}4:前端文件
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>前后端分离 HTTP服务器</title>
<style>
* {margin: 0; padding: 0; box-sizing: border-box;}
body {
font-family: Arial;
background: #f0f2f5;
padding: 40px;
}
.container {
max-width: 900px;
margin: 0 auto;
background: white;
padding: 40px;
border-radius: 12px;
box-shadow: 0 4px 20px rgba(0,0,0,0.1);
}
h1 {
color: #2d8cf0;
text-align: center;
margin-bottom: 20px;
}
.hello {
font-size: 28px;
color: #00b42a;
text-align: center;
margin: 30px 0;
}
.tip {
text-align: center;
color: #666;
margin-top: 20px;
}
</style>
</head>
<body>
<div class="container">
<h1>C++ 前后端分离 HTTP 服务器</h1>
<div class="hello">👋 Hello World</div>
<div class="tip">前端文件独立存放在 web/ 文件夹,后端仅负责读取!</div>
</div>
</body>
</html>