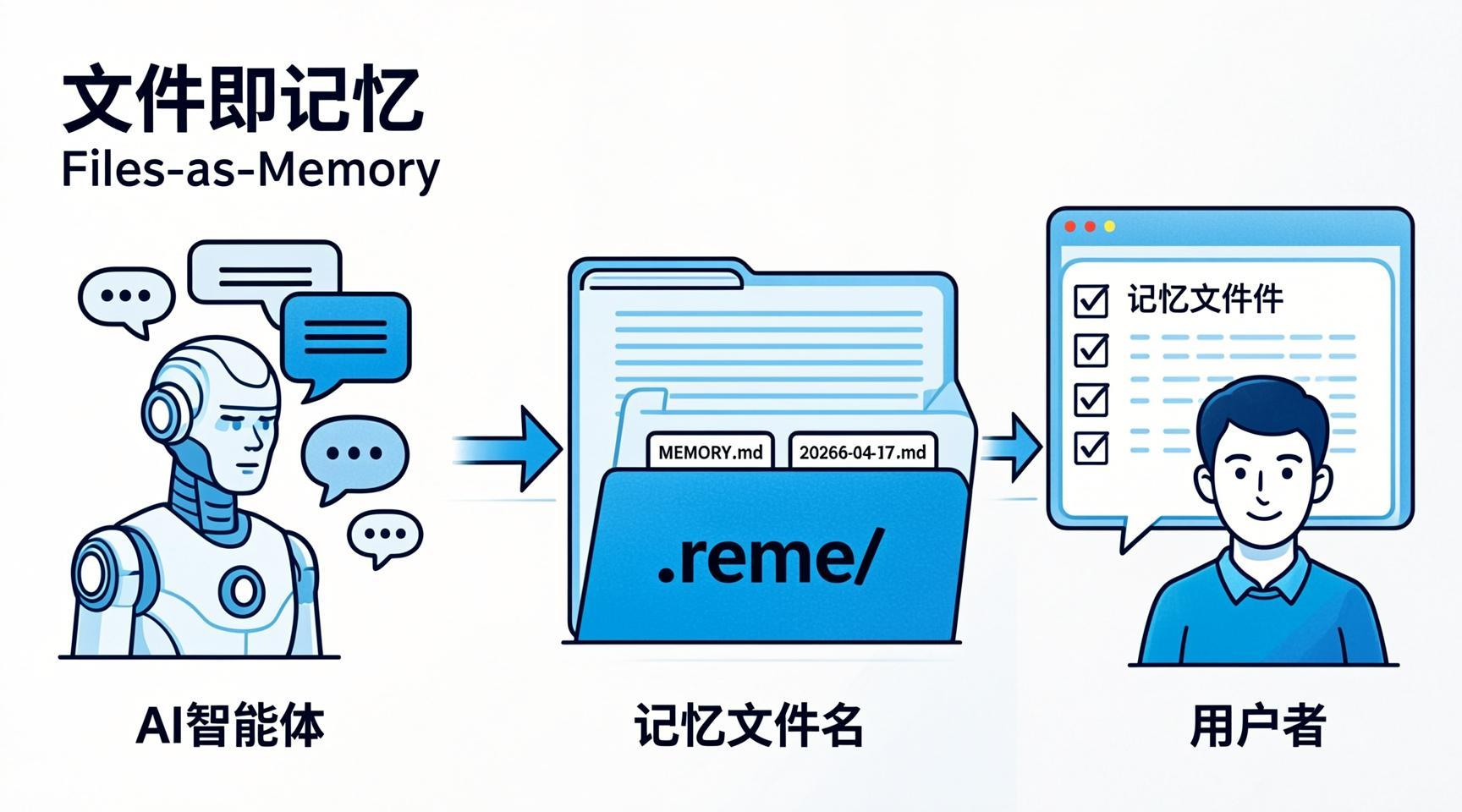
当所有记忆框架都在追求更复杂的存储架构时,阿里 AgentScope 团队却选择了一条"返璞归真"的路:把 Agent 的记忆直接存成 Markdown 文件 。ReMe(Remember Me, Refine Me)是一个极致的"透明化"记忆框架------所有长期记忆都以人类可读的 Markdown 格式保存在
.reme/目录中,用户可以随时打开查看、手动修改、甚至批量迁移。本文深度拆解 ReMe 的双轨设计(文件 + 向量)、三种记忆分类(个人/任务/工具)、0.7+0.3 的混合检索策略,以及"记忆扩展效应"如何让 8B 小模型跑赢 14B 大模型。如果你关心记忆的可审计性、可编辑性和迁移自由,ReMe 将为你打开一扇全新的门。
在深度拆解了 Text2Mem(标准化指令集)、Mem0(双存储中间件)和 Letta(OS 虚拟内存 + Git 版本化)之后,今天我们来看一个理念截然不同的框架------ReMe。
ReMe 的核心理念可以用一句话概括:"文件即记忆" 。它不追求 Letta 那样的 OS 隐喻复杂度,也不像 Mem0 那样把知识图谱和向量库作为黑盒,而是把 Agent 的长期记忆直接保存为人类可读的 Markdown 文件------用户可以直接打开、阅读、编辑、甚至复制到另一个 Agent 实例。
这套方案由阿里云通义千问的 AgentScope 团队开发,由上海交通大学与阿里通义的研究者联合提出,目前已正式集成到 AgentScope 1.0 中,作为其长期记忆的默认实现之一。GitHub 星标 1.8K,采用 Apache 2.0 开源协议,ReMe 正在成为"可审计 AI 记忆"方向上的标杆项目。
这一篇,我们就来完整拆解 ReMe 的设计哲学、核心机制、性能数据与真实局限。
一、设计哲学:记忆不是"黑盒",而是"可编辑的文件"
ReMe 要解决的核心痛点非常明确:
- 上下文窗口有限:长对话中早期信息被截断或丢失。
- Agent 无状态:每次新对话都从零开始,无法继承历史。
这些痛点本栏目已经讨论过很多次,但 ReMe 给出的答案和之前的框架完全不同。它的价值主张是:把"记忆"做成一个既可语义检索、又可人工读写/迁移的长期存储系统。
这带来一个革命性的变化:运维团队可以直接查看和修改 Agent 的记忆,降低黑盒风险 。你可以像管理代码一样,用 Git 来版本控制 Agent 的记忆文件;出问题时,你可以直接打开 .reme/MEMORY.md,手动修正一条错误记忆,而不用去调试复杂的向量库或知识图谱。
二、整体架构:四层结构 + 双轨设计
ReMe 的系统架构可以划分为四个清晰的层次:
基础设施层
记忆代理层
应用编排层
用户入口层
ReMe / ReMeApp
Python API & CLI
Application → ServiceContext → Flow 编排引擎
ReMeSummarizer
统一调度器
DelegateTask
ReMeRetriever
BaseVectorStore
Local/Chroma/Qdrant/ES
BaseEmbeddingModel
BaseLLM
FileStore
这里最值得注意的是记忆代理层 ------记忆的提取与检索不是硬编码的规则管线,而是由 LLM 驱动的 ReAct Agent 自主完成的智能流程。这意味着"该记住什么、怎么总结、如何检索"本身就是一个需要智能决策的任务。
ReMe 最独特的地方在于它的 "双轨设计" :
| 轨道 | 功能 | 特点 |
|---|---|---|
| 文件轨(File Track) | 长期记忆以 Markdown 文件持久化 | 人类可读、可手动编辑、便于审计和迁移 |
| 向量轨(Vector Track) | 向量数据库存储 embedding,支持语义检索 | 高效检索、实时召回、支持混合检索 |
这两个轨道是协同工作的:文件轨是"可审计的真实记录",向量轨是"快速检索的索引"。当用户通过向量检索找到相关记忆后,系统可以定位到原始 Markdown 文件中的具体位置,保持完全可追溯。
三、三种记忆类型:个人 / 任务 / 工具
ReMe 在 AgentScope 中的实现提供了三种专门的记忆类型,各司其职:
ReMe
三种记忆类型
个人记忆 Personal
用户偏好
习惯记录
个人事实
任务记忆 Task
执行轨迹
成功模式
失败经验
工具记忆 Tool
工具调用记录
使用指南
参数建议
3.1 个人记忆(Personal Memory)
存储用户的偏好、习惯和个人事实。例如:"用户喜欢 Python"、"用户通常在下午 3 点后回复邮件"。这些信息跨会话持久化,让 Agent 越来越了解用户。
3.2 任务记忆(Task Memory)
从任务执行轨迹中学习,记录成功的模式和失败的教训。例如:"上次执行数据清洗时,先做缺失值检测再做归一化,效果更好"或"调用这个 API 时参数 order=desc 会导致超时"。
3.3 工具记忆(Tool Memory)
记录工具执行的结果,生成更好的使用指南。例如:"search_web 工具对中文查询需要加上 site:zh 限制才能得到高质量结果"。
这种三层分类的设计,让 ReMe 的记忆系统不再是"一个大池子什么都往里面扔",而是有组织、有结构、各司其职的知识体系。在学术研究中,ReMe 甚至被形式化为一个五元组------每个经验包含触发场景、核心内容、分类关键词、置信度评分、相关工具,通过 LLM-as-a-Judge 验证后存入向量库。
四、核心检索:0.7 向量 + 0.3 BM25 混合检索
ReMe 的记忆检索采用了一个精心调配的混合检索策略:
- 向量语义检索(权重 0.7) :捕获语义相似的模糊匹配。比如"我喜欢编程"和"我对写代码有热情"在向量空间中是近似的。
- BM25 关键词检索(权重 0.3) :精确匹配关键词、日期、人名等。比如"2026 年 3 月"和"张三"。
为什么是 0.7 : 0.3 的权重配比?这是经过大量实验验证的经验值。纯向量检索(权重 1.0)在精确关键词查询上表现不佳;纯 BM25(权重 0.0)则完全丧失了语义理解能力。0.7:0.3 的配比在大多数场景下提供了最佳的精度-召回平衡。
用户查询
向量检索
语义相似
BM25检索
关键词匹配
加权融合
0.7×向量 + 0.3×BM25
返回排序结果
这种混合检索方式在实践中被证明非常有效,尤其在处理包含专有名词、日期、代码片段等精确信息的查询时,BM25 的补充作用不可替代。
五、工作流:从对话到记忆的完整闭环
ReMe 的记忆生命周期包含一个完整的闭环:
2. 经验重用
- 经验获取
- 经验精炼
定期评估
剔除过时经验
合并重复记忆
更新置信度评分
Agent 执行任务
生成执行轨迹
成功/失败记录
Summarizer
多维度蒸馏
LLM-as-Judge
验证质量
写入向量库 + 文件
新任务查询
混合检索
向量+BM25
重排序+重写
注入Agent上下文
5.1 经验获取:多维度蒸馏
ReMe 的核心创新之一是 "多维度蒸馏" ------不只是简单地记录"发生了什么",而是深入分析:
- 成功模式:识别出成功的策略,提炼为可复用的经验
- 失败原因:分析失败的关键触发因素,生成警示性经验
- 对比见解:比较成功与失败轨迹的关键差异
5.2 经验重用:检索 → 重排序 → 重写
当 Agent 面对新任务时,ReMe 通过三步将历史经验适配到当前场景:
- 检索:混合检索召回 top-K 相关经验
- 重排序:根据当前任务上下文重新评估相关性
- 重写:将经验改写为适应当前任务的精确指令
5.3 经验精炼:持续优化
记忆不是"只增不减"的档案库。ReMe 持续评估经验池,剔除过时信息、合并重复记忆、更新置信度评分,确保经验库在长期使用中保持"高价值、低噪音"。
六、性能数据与"记忆扩展效应"
ReMe 的学术版本(由上海交通大学与阿里通义团队联合提出)在多个基准上取得了 SOTA 成绩:
- REMem 在四个情景记忆基准上,分别比 Mem0 和 HippoRAG 2 高出 3.4% 和 13.4% 的绝对提升。
- 在 BFCL-V3 与 AppWorld 基准上的实验表明,ReMe 显著优于现有方法,刷新了智能体记忆系统 SOTA。
但最引人注目的,是研究者发现的 "记忆扩展效应"(Memory-Scaling Effect) :
配备 ReMe 的 Qwen3-8B 模型,在 Avg@4 和 Pass@4 指标上分别超越无记忆的更大模型 Qwen3-14B 达 8.83% 与 7.29%。
这意味着:高质量的自进化记忆,可以在一定程度上替代模型规模的盲目增长。与其花更多钱调用更大的模型,不如花更少的钱做好记忆层------这在成本敏感的生产环境中,是一个极具颠覆性的结论。
七、适用场景与局限
✅ 强烈推荐 ReMe 的场景
- 对记忆可审计性、可解释性要求极高的场景:如金融、法律、医疗领域,记忆操作需要留下清晰的审计线索。ReMe 的文件化设计天然支持合规审计。
- 需要手动干预 Agent 记忆的场景:如果你希望运维团队能直接查看、修改甚至回滚 Agent 的记忆,ReMe 是目前唯一的选择。
- 多 Agent 记忆迁移场景:Markdown 文件可以轻松复制、打包、迁移到另一个 Agent 实例,无需复杂的数据库导出导入。
- 个人知识管理和数字助手:用户可以直接查看 Agent 记住了什么,修正错误记忆,对记忆拥有完全的控制感。
⚠️ 谨慎评估后使用的场景
- 高并发写入场景:文件存储在高并发场景下可能不如专业数据库高效。如果每秒有数千条记忆写入,文件 I/O 可能成为瓶颈。
- 超大规模记忆库:当记忆条目达到百万级以上时,纯文件存储的检索和管理效率可能下降,需要结合更专业的向量数据库后端。
- 需要复杂关系推理的场景:与 Mem0 的知识图谱不同,ReMe 没有显式的关系推理能力,更多依赖语义检索。
❌ 不太适合的场景
- 对延迟极度敏感的实时系统:ReMe 的混合检索和 LLM 驱动的记忆代理层会增加额外的延迟,不适合毫秒级响应场景。
- 完全托管的需求:ReMe 更偏向自托管方案,如果你想要一个完全托管的记忆 API 服务,Mem0 的托管版可能更适合。
八、ReMe vs Mem0:两种哲学的碰撞
基于我们在第 3 篇对 Mem0 的深度拆解,这里做一个直接的对比:
| 维度 | ReMe | Mem0 |
|---|---|---|
| 一句话定位 | Agent 的上下文管理 + 工作记忆框架 | AI 应用的个性化记忆层 |
| 核心问题 | "对话太长,上下文溢出了怎么办?" | "如何记住用户的偏好和事实?" |
| 记忆来源 | 对话流中自动提取(压缩副产品) | 开发者显式调用 memory.add() |
| 记忆粒度 | 文件级(Markdown 文档) | 事实级(一条条独立的 fact) |
| 可编辑性 | ⭐⭐⭐⭐⭐ 直接编辑 Markdown | ⭐⭐ 通过 API 修改 |
| 可审计性 | ⭐⭐⭐⭐⭐ 文件即审计记录 | ⭐⭐⭐ 有变更历史 |
| 检索能力 | 混合检索(向量 + BM25) | 双存储(向量 + 知识图谱) |
| 关系推理 | 依赖语义相似 | 知识图谱显式关系 |
| 部署复杂度 | 中等(自托管) | 低(有托管版) |
两者的选择本质上取决于一个核心问题:你更需要"可控性"还是"自动化"?
- 选 ReMe:如果你需要随时查看、修改、迁移 Agent 的记忆,需要完整的审计追踪,需要低成本运行------ReMe 的"文件即记忆"是最佳选择。
- 选 Mem0:如果你希望"开箱即用",不需要关心记忆的存储细节,让系统自动完成实体提取和关系构建------Mem0 的托管体验更友好。
九、代码示例:5 分钟上手 ReMe
python
from agentscope.memory import ReMePersonalLongTermMemory
from agentscope.model import DashScopeChatModel, DashScopeEmbeddingModel
# 初始化模型
chat_model = DashScopeChatModel(
model_name="qwen-max",
api_key="your-api-key"
)
embedding_model = DashScopeEmbeddingModel(
model_name="text-embedding-v3",
api_key="your-api-key"
)
# 创建个人长期记忆
async with ReMePersonalLongTermMemory(
model=chat_model,
embedding_model=embedding_model,
user_name="alice"
) as memory:
# 记录记忆(自动压缩+持久化)
await memory.record("用户说他们喜欢用 Python 做数据分析")
await memory.record("用户的下一个项目 deadline 是 6 月 1 日")
# 检索记忆
results = await memory.retrieve("用户喜欢什么编程语言?")
for r in results:
print(f"记忆内容: {r.content}")
print(f"来源文件: {r.metadata['file_path']}") # 直接定位到 Markdown 文件更棒的是,ReMe 的记忆文件就放在你的本地目录中:
markdown
<!-- .reme/MEMORY.md 内容示例 -->
# Alice 的个人记忆
- 用户喜欢用 Python 做数据分析(置信度:0.95)
- 用户的下一个项目 deadline 是 2026-06-01(置信度:0.90)你可以随时打开这个文件,手动修改、删除或添加内容------系统会自动同步更新向量索引。
十、小结:透明化,是 Agent 记忆的下一个分水岭
在 Text2Mem 定义了"记忆的语法"、Mem0 提供了"记忆的操作系统"、Letta 探索了"记忆的虚拟化"之后,ReMe 走出了一条截然不同的路:把记忆还给用户。
"文件即记忆"的设计,看似是一种"返璞归真",实则是对当前 AI 记忆系统"黑盒化"趋势的一种深刻反思。当 Agent 越来越多地介入我们的工作与生活,它的记忆不应该是一个无人知晓的"黑箱"------用户有权知道 Agent 记住了什么,也有权修改和删除那些错误的记忆。
ReMe 的可审计性和可编辑性,恰恰是 Agent 走向真正"可信 AI"的必经之路。正如研究者所发现的"记忆扩展效应"所揭示的:高质量的记忆比大规模的模型更重要------而高质量记忆的前提,恰恰是"透明"。
下一篇,我们将迎来模块一的压轴之作------memU 。在所有记忆框架中,memU 的范式最为激进:它不再满足于让 Agent"被动地存取记忆",而是让记忆本身变成一个 24/7 全天候运行的后台 Agent,主动观察、学习、推送建议。这是一种颠覆性的"主动记忆"范式,还是过度设计的空中楼阁?我们下篇见分晓。
如果你觉得这篇文章有帮助,欢迎点赞、收藏。你在生产环境中用过 ReMe 吗?对"文件即记忆"的设计怎么看?欢迎在评论区留下你的观点和经验。