扩散模型与可控生成:从AI涂鸦到精准作画的技术革命
你是否惊叹于Midjourney能根据一句文字生成堪比大师的画作?是否好奇Stable Diffusion如何将你的线稿瞬间变成高清插画?是否见过ControlNet精准控制人物姿态和建筑结构的神奇效果?这些现象级应用的背后,都离不开扩散模型(Diffusion Models) 这一AI生成技术的核心引擎。
如果说生成模型是AI的"画笔",那么扩散模型就是目前最锋利的那一支。而ControlNet、LoRA等条件控制技术,则让这支画笔从"随机涂鸦"进化为"精准作画",真正实现了"所想即所得"。本文将带你从零开始,系统了解生成模型的发展历程、扩散模型的核心原理,以及可控生成的关键技术,揭开AI画图背后的技术奥秘。
1 生成模型全景:五大流派的百年竞逐
生成模型的目标是让计算机学习数据的分布,从而生成与真实数据相似的新样本。简单来说,就是让AI学会"创造"------创造图像、视频、音频、文本等各种形式的内容。
1.1 生成模型的五大流派与历史脉络
自深度学习兴起以来,生成模型领域涌现出了五大主流技术流派,它们在不同时期各领风骚,共同推动了AI生成技术的进步:
| 技术流派 | 提出时间 | 代表模型 | 核心思想 | 优势 | 局限性 |
|---|---|---|---|---|---|
| 变分自编码器(VAE) | 2013年 | VAE、β-VAE | 基于概率建模,将数据编码到潜空间再解码生成 | 训练稳定,潜空间连续可解释 | 生成图像模糊,细节不足 |
| 生成对抗网络(GAN) | 2014年 | DCGAN、StyleGAN、CycleGAN | 生成器与判别器对抗训练,互相博弈提升 | 生成图像清晰度高,细节丰富 | 训练不稳定,容易模式崩溃 |
| 归一化流(Normalizing Flows) | 2014年 | RealNVP、Glow | 通过可逆变换将数据映射到简单分布 | 精确的对数似然,生成过程可逆 | 计算成本高,模型复杂度大 |
| 自回归模型 | 2016年 | PixelCNN、GPT | 逐像素/逐token生成,建模序列依赖 | 生成质量高,序列建模能力强 | 生成速度慢,并行性差 |
| 扩散模型 | 2020年 | DDPM、Stable Diffusion、Sora | 逐步加噪再逐步去噪,基于概率扩散 | 训练稳定,文本对齐好,可控性强 | 原始采样速度慢,需加速优化 |
1.2 为什么扩散模型最终胜出?
在2021年之前,GAN一直是图像生成领域的绝对王者,尤其是StyleGAN生成的人脸几乎达到了以假乱真的程度。但为什么最终是扩散模型后来居上,成为了AI生成技术的主流?
核心原因在于扩散模型解决了GAN的两大致命缺陷:
- 训练稳定性:GAN的训练是一个"零和博弈",生成器和判别器需要达到微妙的平衡,稍有不慎就会出现模式崩溃(生成的样本千篇一律)或梯度消失。而扩散模型的训练是一个简单的回归任务,目标是预测噪声,训练过程非常稳定。
- 可控性与多样性:GAN很难在生成质量和多样性之间取得平衡,而且难以精确控制生成内容的结构和细节。扩散模型天然支持多种条件控制(文本、图像、姿态等),并且可以通过调整采样步数和参数,在质量和多样性之间灵活切换。
此外,扩散模型还具有文本对齐更好 、易于扩展到视频和3D等优势,这使得它成为了目前最适合通用生成任务的技术框架。
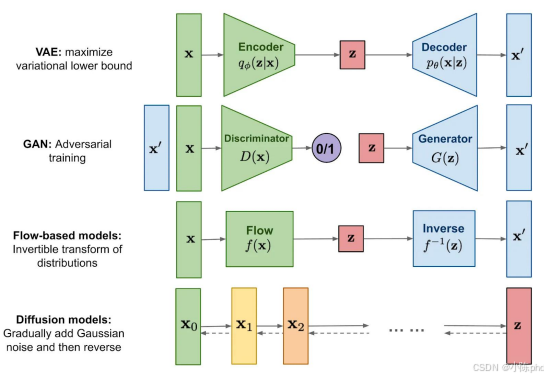
2 基础生成模型:VAE与GAN的奠基之路
虽然扩散模型已经成为主流,但VAE和GAN作为生成模型的两大基石,它们的思想和技术仍然被广泛应用于现代扩散模型中。例如,Stable Diffusion的核心架构就使用了VAE来压缩图像,而GAN的对抗训练思想也被用于提升扩散模型的生成质量。
2.1 VAE:变分自编码器的数学魔法
2.1.1 传统自编码器(AE)的局限
传统自编码器由编码器(Encoder)和解码器(Decoder)两部分组成:
- 编码器将输入图像压缩成一个低维的潜向量(z)
- 解码器将潜向量还原成原始图像
它的目标是最小化重建误差,让输出图像尽可能接近输入图像。但传统AE有一个致命的问题:潜空间是碎片化的。
每张图像都会占据潜空间中的一小块区域,区域之间没有任何联系。当我们随机采样一个潜向量时,很可能会落到"无主之地",解码出来的结果会是毫无意义的噪声。
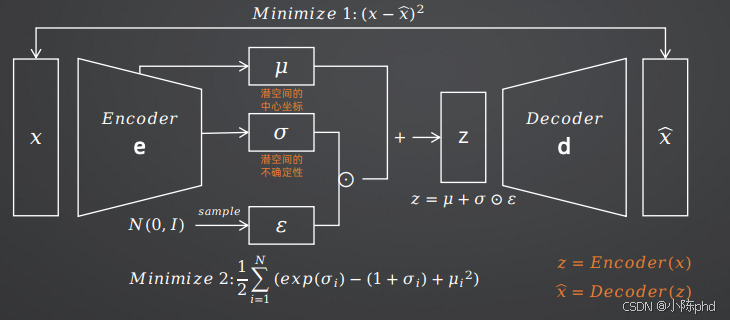
2.1.2 VAE的核心思想:概率化潜空间
VAE(变分自编码器)的创新之处在于,它将潜空间从"确定性的点"变成了"概率分布"。
对于每张输入图像x,编码器不再输出一个固定的潜向量z,而是输出一个高斯分布的均值(μ)和方差(σ²)。然后我们从这个分布中采样一个潜向量z,再送入解码器生成图像。
为了解决潜空间碎片化的问题,VAE引入了KL散度约束 ,强制让所有的分布都尽可能接近标准正态分布N(0, I)。这样,整个潜空间就变成了一个连续、规则的空间,任意采样一个点都能解码出有意义的图像。

2.1.3 VAE的损失函数详解
VAE的损失函数由两部分组成:
L=Eq(z∣x)\[−logp(x∣z)\]⏟重建损失+β⋅DKL(q(z∣x)∥p(z))⏟KL散度损失\]\[ L = \\underbrace{E_{q(z\|x)}\[-log p(x\|z)\]}_{\\text{重建损失}} + \\beta \\cdot \\underbrace{D_{KL}(q(z\|x) \\parallel p(z))}_{\\text{KL散度损失}} \]\[L=重建损失 Eq(z∣x)\[−logp(x∣z)\]+β⋅KL散度损失 DKL(q(z∣x)∥p(z))
- 重建损失:衡量生成图像与原始图像的相似度,目标是让重建效果尽可能好
- KL散度损失:衡量编码器输出的分布与标准正态分布的差异,目标是让潜空间更规则
- β参数 :用于平衡两部分损失的权重
- β=1:标准VAE
- β>1:更强的KL约束,潜空间更规则,但重建会更模糊
- β<1:弱化KL约束,模型更重视重建,生成图像更清晰
2.2 GAN:生成对抗网络的"猫鼠游戏"
GAN(生成对抗网络)的核心思想是"对抗训练",它由两个神经网络组成:生成器(Generator) 和判别器(Discriminator) 。
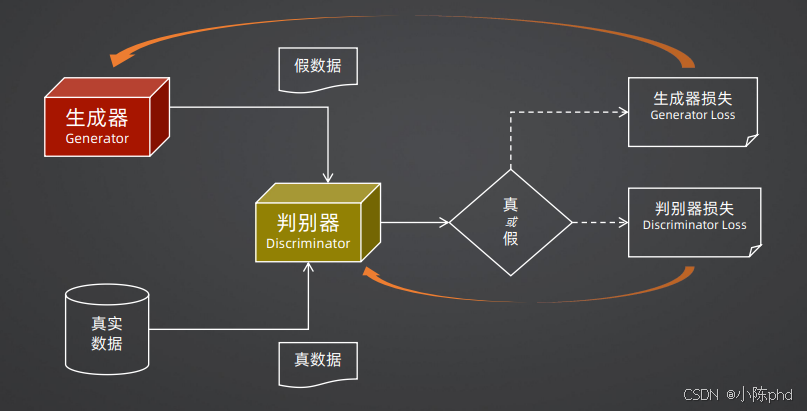
- 生成器:接收随机噪声作为输入,生成假样本,目标是"骗过"判别器
- 判别器:接收真实样本和生成器生成的假样本,目标是准确区分真假
这就像一场猫鼠游戏:生成器努力让自己生成的样本越来越像真的,判别器努力提高自己的鉴别能力。在不断的对抗训练中,两者的能力都会越来越强,最终生成器生成的样本几乎可以以假乱真。
2.2.1 GAN家族的经典成员
GAN自提出以来,衍生出了众多变种,其中最具影响力的有:
| 模型 | 提出时间 | 核心创新 | 典型应用 |
|---|---|---|---|
| DCGAN | 2015年 | 用卷积层取代全连接层,让GAN更适合图像生成 | 基础图像生成 |
| Pix2Pix | 2016年 | 条件GAN,实现图像到图像的转换 | 素描转照片、黑白转彩色 |
| CycleGAN | 2017年 | 不需要成对数据的图像转换 | 马转斑马、夏天转冬天、照片转莫奈风格 |
| WGAN-GP | 2017年 | 引入Wasserstein距离和梯度惩罚,解决训练不稳定问题 | 通用GAN训练 |
| StyleGAN | 2018年 | 风格化生成,通过控制不同层级的特征来控制图像风格 | 超真实人脸生成 |
2.2.2 StyleGAN:GAN时代的巅峰之作
StyleGAN是NVIDIA在2018年推出的人脸生成模型,它生成的人脸质量之高,至今仍令人惊叹。StyleGAN的核心创新是风格解耦:
- 将图像生成过程分解为不同的层级,低层级控制整体结构(脸型、发型),高层级控制细节(眼睛、嘴巴、皮肤纹理)
- 通过调整不同层级的风格向量,可以精确控制生成人脸的各种特征
后续的StyleGAN2解决了"水波纹伪影"问题,StyleGAN3则解决了"混叠"问题,进一步提升了生成质量和一致性。

3 扩散模型:AI画图的核心引擎
2020年,DDPM(Denoising Diffusion Probabilistic Model)的发表标志着扩散模型时代的到来。虽然最初的DDPM生成速度极慢(需要上千步才能出一张图),但它展现出的训练稳定性和生成质量,让研究者们看到了巨大的潜力。
3.1 扩散模型的基本原理:"逐步去污"的智慧
扩散模型的灵感来源于物理学中的扩散现象:一滴墨水滴入水中,会逐渐扩散均匀,最终变成一杯浑浊的水。这个过程是不可逆的,但我们可以训练一个模型来模拟它的逆过程------从浑浊的水中还原出原来的墨水。
3.1.1 前向扩散过程:逐步加噪
前向扩散过程是一个确定性的过程 :我们从一张干净的图像x₀开始,逐步向其中添加高斯噪声,经过T步(通常T=1000)后,图像会变成完全的高斯噪声xTx_TxT。
xt=αtxt−1+1−αtϵt\]\[ x_t = \\sqrt{\\alpha_t}x_{t-1} + \\sqrt{1-\\alpha_t}\\epsilon_t \]\[xt=αt xt−1+1−αt ϵt
其中,αtα_tαt是一个预先设定的常数,随着t的增大而逐渐减小;εtε_tεt是服从标准正态分布的噪声。
这个过程的关键在于,我们可以直接计算出任意时刻t的带噪图像xtx_txt,而不需要一步步迭代:
xt=αˉtx0+1−αˉtϵ\]\[ x_t = \\sqrt{\\bar{\\alpha}_t}x_0 + \\sqrt{1-\\bar{\\alpha}_t}\\epsilon \]\[xt=αˉt x0+1−αˉt ϵ
其中,(αˉt=∏i=1tαi)(\bar{\alpha}t = \prod{i=1}^t \alpha_i)(αˉt=∏i=1tαi)。
3.1.2 反向扩散过程:逐步去噪
反向扩散过程是我们需要训练模型来学习的过程:从完全的高斯噪声xTx_TxT开始,逐步预测并去除每一步的噪声,最终还原出干净的图像x₀。
扩散模型的核心训练目标 非常简单:给定带噪图像xtx_txt和时间步t,预测添加到图像上的噪声ε。
训练完成后,我们就可以通过以下迭代公式来生成图像:
xt−1=1αt(xt−1−αt1−αˉtϵθ(xt,t))+σtz\]\[ x_{t-1} = \\frac{1}{\\sqrt{\\alpha_t}}(x_t - \\frac{1-\\alpha_t}{\\sqrt{1-\\bar{\\alpha}_t}}\\epsilon_\\theta(x_t, t)) + \\sigma_t z \]\[xt−1=αt 1(xt−1−αˉt 1−αtϵθ(xt,t))+σtz
其中,εθ(xt,t)ε_θ(x_t, t)εθ(xt,t)是模型预测的噪声,σtzσ_t zσtz是一个小的随机噪声项,用于增加生成结果的多样性。
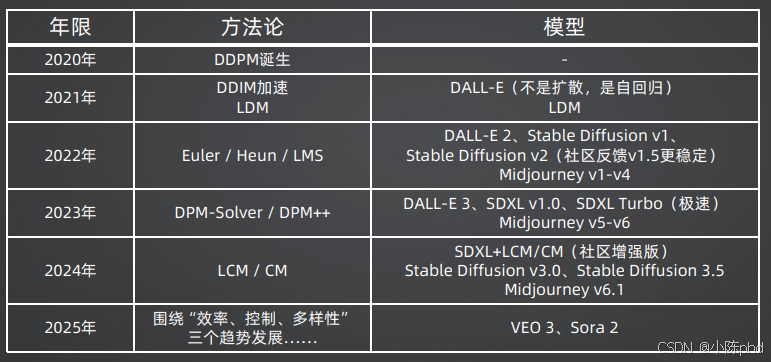
3.2 扩散模型的技术演进路线
从2020年DDPM诞生到今天,扩散模型的技术演进主要围绕**"效率"和"控制"**两大主题展开,形成了两条清晰的技术路线:
| 年份 | 方法论 | 代表模型 | 核心突破 |
|---|---|---|---|
| 2020年 | DDPM诞生 | DDPM | 奠定扩散模型的基础理论框架 |
| 2021年 | 潜空间扩散(LDM) | LDM | 将扩散过程从像素空间转移到潜空间,计算量降低10-100倍 |
| 2021年 | 确定性采样 | DDIM | 将随机扩散转为确定性轨迹,采样步数从1000步减少到50步 |
| 2022年 | 高阶ODE解法 | Euler、Heun、LMS | 进一步减少采样步数,提升生成质量 |
| 2023年 | 更高效的ODE解法 | DPM-Solver、DPM++ | 工业界首选,20-30步即可生成高质量图像 |
| 2024年 | 一致性模型 | LCM、CM | 无需数值积分,1-4步即可出图,实现实时生成 |
3.2.1 A路线:从DDPM到Stable Diffusion
这条路线的核心是降低计算成本,让扩散模型能够在消费级显卡上运行。
2021年提出的LDM(Latent Diffusion Model) 是一个里程碑式的突破。它的核心思想是:
- 先用一个预训练的VAE将高分辨率的图像压缩到低维的潜空间
- 在潜空间中进行扩散和去噪过程
- 最后用VAE的解码器将潜空间特征还原成高分辨率图像
这样做的好处是,潜空间的维度比像素空间小得多(例如,512x512的RGB图像压缩后变成64x64的特征图),计算量可以降低两个数量级,而生成质量几乎没有损失。
Stable Diffusion 就是基于LDM架构开发的,它于2022年开源,彻底引爆了AI生成技术的革命。Stable Diffusion的核心架构是:
CLIP文本编码器 + LDM扩散模型 + VAE编解码器 + DDIM采样器目前Stable Diffusion已经发展到了3.5版本,主流版本的显存要求如下:
- SD 1.5:4GB显存即可运行
- SDXL 1.0:8GB显存
- SD 3.5 Medium:10GB显存
- SD 3.5 Large:32GB显存
3.2.2 B路线:从DDIM到LCM的加速革命
这条路线的核心是提升采样速度,让扩散模型能够实现实时生成。
- DDIM:2021年提出,将扩散过程从随机的SDE(随机微分方程)转为确定性的ODE(常微分方程),采样步数从1000步减少到50步
- DPM-Solver:2023年提出,是一种高阶的ODE数值解法,20步即可生成与DDIM 50步相当的质量,成为目前工业界的首选采样器
- LCM(Latent Consistency Model):2024年提出,彻底抛弃了数值积分的思路,训练模型直接学会"跳步"生成,1-4步即可出图,实现了实时生成
LCM的出现让AI画图从"分钟级"进入了"秒级",为实时交互应用(如AI绘画软件、虚拟人直播)奠定了基础。
4 可控生成:让AI听懂你的指令
早期的扩散模型虽然生成质量很高,但可控性很差。你输入"一只猫",它可能生成各种姿势、各种品种的猫,但很难精确控制猫的姿态、位置和背景。为了解决这个问题,研究者们开发了一系列条件控制技术,让AI能够真正听懂你的指令。
4.1 固定目标生成:让模型记住"特定事物"
固定目标生成的目标是让模型学会生成一个特定的物体、人物或风格,例如"我的狗"、"梵高的风格"、"某个特定的logo"。
目前主流的固定目标生成方法有三种,它们在训练成本、效果和灵活性上各有优劣:
| 方法 | 训练数据量 | 训练时间 | 模型大小 | 效果 | 灵活性 |
|---|---|---|---|---|---|
| Textual Inversion | 3-5张 | 几分钟 | ~100KB | 一般 | 只能控制风格/物体,不能控制结构 |
| LoRA | 5-10张 | 十几分钟 | ~10-100MB | 好 | 灵活,可组合多个LoRA |
| DreamBooth | 10-20张 | 几小时 | 完整模型 | 最好 | 生成最稳定,绑定最牢固 |
4.1.1 LoRA:轻量级微调的王者
LoRA(Low-Rank Adaptation,低秩适配)是目前最流行的轻量级微调方法。它的核心思想是:
- 冻结预训练扩散模型的所有权重
- 在Transformer的注意力层中插入两个小的低秩矩阵
- 训练时只更新这两个低秩矩阵的参数
这样做的好处是:
- 训练成本极低:只需要训练很少的参数,在消费级显卡上即可完成
- 模型体积小:训练好的LoRA权重只有几十MB,方便分享和传播
- 可组合性强:可以同时加载多个LoRA,组合不同的风格和特征
4.1.2 DreamBooth:个性化生成的利器
DreamBooth是一种更强大的个性化生成方法,它可以让模型"记住"一个特定的主体。
DreamBooth的训练流程是:
- 准备3-5张同一主体的不同角度的照片
- 给这个主体分配一个唯一的稀有标识符,例如"V"
- 用这些照片和包含"a V dog"等格式的文本对模型进行微调
训练完成后,你就可以用"a V dog in the beach"、"a V dog wearing sunglasses"等提示词,生成这个特定主体在各种场景下的照片。
4.2 结构约束生成:ControlNet的革命
如果说LoRA和DreamBooth解决了"生成什么"的问题,那么ControlNet 就解决了"怎么生成"的问题------它可以精确控制生成图像的结构、姿态、布局和几何形状。
4.2.1 ControlNet解决的痛点
在ControlNet出现之前,扩散模型生成的图像结构经常失控:人物姿势怪异、建筑比例失调、手部畸形等问题非常普遍。这是因为文本提示词很难精确描述复杂的空间结构和几何关系。
ControlNet的出现彻底改变了这一局面。它允许你输入额外的结构信息(如线稿、深度图、人体姿态图、边缘图等),让扩散模型严格按照这个结构来生成图像。
4.2.2 ControlNet的核心原理
ControlNet的核心思想是**"冻结预训练模型+可训练控制分支"**:
- 冻结预训练的Stable Diffusion模型的所有权重,保留它已经学到的丰富的生成知识
- 添加一个可训练的控制分支,这个分支与预训练模型的结构完全相同
- 控制分支接收条件输入(如姿态图),提取结构特征,并将这些特征注入到预训练模型的每一层
- 训练时只更新控制分支的参数,预训练模型的参数保持不变
这样做的好处是:
- 不会破坏预训练模型的生成能力
- 训练成本低,只需要训练控制分支
- 可以为不同的控制条件训练不同的ControlNet模型,按需加载
4.2.3 常见的ControlNet控制条件
目前已经有很多成熟的ControlNet模型,支持各种不同的控制条件:
- Canny边缘检测:输入线稿,生成对应结构的彩色图像
- 人体姿态(OpenPose):输入人体骨骼图,生成对应姿态的人物
- 深度图(Depth):输入深度图,生成对应空间结构的场景
- 法线图(Normal):输入法线图,控制物体的表面朝向和光照
- 语义分割图(Segmentation):输入语义分割图,控制不同区域的内容
5 工具生态与领域应用
随着扩散模型技术的成熟,一个庞大的工具生态已经形成,让普通用户也能轻松使用AI生成技术。同时,扩散模型也正在从图像生成向视频、3D、音频等多个领域扩展。
5.1 两大主流工具对比:Diffusers vs ComfyUI
目前最流行的扩散模型工具主要有两个,它们分别面向不同的用户群体:
| 对比项 | Diffusers | ComfyUI |
|---|---|---|
| 开发者 | Hugging Face | ComfyOrg社区 |
| 适合人群 | 开发者、研究者 | 设计师、创作者、普通用户 |
| 核心功能 | 提供Python API,支持各种扩散模型和控制技术 | 可视化节点界面,通过拖拽节点构建生成管线 |
| 操作方式 | 代码式,需要编写Python脚本 | 图形化界面,无需编程 |
| 优势 | 灵活、可编程,适合二次开发和部署 | 直观、上手快,参数调节方便,支持复杂管线 |
| 劣势 | 有编程门槛,不适合创意探索 | 不适合大规模训练和批量部署 |
5.2 扩散模型的跨领域扩展
扩散模型的思想不仅适用于图像生成,还可以扩展到几乎所有的生成任务:
- 文生图:Stable Diffusion、Midjourney、DALL-E 3
- 文生视频:Sora、VEO、Pika
- 文生3D:DreamFusion、Instant3D
- 文生音乐:Stable Audio、Suno
- 语音合成:Fish Speech、ElevenLabs
其中,文生视频是目前最热门的研究方向。2024年OpenAI发布的Sora展示了扩散模型在视频生成领域的巨大潜力,它可以生成长达1分钟、分辨率高达1080p的连贯视频,并且能够准确模拟物理规律和复杂的场景动态。
6 总结与展望
从VAE和GAN的奠基,到扩散模型的爆发,再到ControlNet和LoRA等可控生成技术的成熟,AI生成技术在短短几年内取得了令人瞩目的进步。今天,我们已经可以用AI生成高质量的图像、视频、音频和3D模型,这些技术正在深刻改变设计、影视、游戏、教育等众多行业。
未来,扩散模型技术将继续朝着三个方向发展:
- 更高的效率:随着LCM等加速技术的不断进步,AI生成将从"秒级"进入"实时级",实现真正的交互式生成
- 更强的可控性:更精细的结构控制、更准确的语义对齐、更灵活的风格组合,让AI真正成为人类的创意助手
- 统一的生成模型:将图像、视频、音频、文本等多种模态统一到一个模型中,实现多模态的联合生成和理解
AI生成技术的革命才刚刚开始,它将释放人类无限的创造力,让"所想即所得"成为现实。